
05-Python整数的底层实现
05-Python整数的底层实现
这次我们来分析一下Python中的整数是如何实现的,我们知道Python中的整数是不会溢出的,换句话说,它可以计算无穷大的数。只要你的内存足够,它就能计算,但是对于C来说显然是不行的,可Python底层又是C实现的,那么它是怎么做到整数不会溢出的呢?
既然想知道答案,那么看一下Python中的整型在底层是怎么定义的就行了。
int实例对象的底层实现
Python中的整数底层对应的结构体是PyLongObject,它位于longobject.h中。
1 | //longobject.h |
别的先不说,就冲里面的ob_size我们就可以思考一番。首先Python中的整数有大小、但应该没有长度的概念吧,那为什么会有一个ob_size呢?从结构体成员来看,这个ob_size指的应该就是ob_digit数组的长度,而这个ob_digit数组显然只能是用来维护具体的值了。而数组的长度不同,那么对应的整数占用的内存也不同。所以答案出来了,整数虽然没有我们生活中的那种长度的概念,但它是个变长对象,因为不同的整数占用的内存可能是不一样的。
因此这个ob_size它指的是底层数组的长度,因为Python中整数对应的值在底层是使用数组来存储的。尽管它没有字符串、列表那种长度的概念,或者说无法对整型使用len方法,但它是个变长对象。
那么下面的重点就在这个ob_digit数组了,我们要从它的身上挖掘信息,看看Python中整数对应的值(比如123),是怎么放在这个数组里面的。不过首先我们要看看这个digit是个什么类型,它同样定义在longintrepr.h中
1 | //PYLONG_BITS_IN_DIGIT是一个宏,如果你的机器是64位的,那么它会被定义为30,32位机器则会被定义为15 |
而我们的机器现在基本上都是64位的,所以PYLONG_BITS_IN_DIGIT会等于30,因为digit等价于uint32_t(unsigned int),所以它是一个无符号32位整型。
所以ob_digit这个数组是一个无符号32位整型数组,长度为1。当然这个数组具体多长则取决于你要存储的Python整数有多大,因为C中数组的长度不属于类型信息,你可以看成是长度n,而这个n是多少要取决于你的整数大小。显然整数越大,这个数组就越长,那么占用空间就越大。
搞清楚了PyLongObject里面的所有成员,那么下面我们就来分析ob_digit是怎么存储Python中的整数,以及Python中的整数为什么不会溢出。
不过说实话,关于Python的整数不会溢出这个问题,其实相信很多人已经有答案了,因为底层是使用数组存储的嘛,而数组的长度又没有限制,所以当然不会溢出啦。
另外,还存在一个问题,那就是digit是一个无符号32位整型,那负数怎么存储?别着急,我们会举栗说明,将上面的疑问一一解答。
首先如果你是Python的设计者,要保证整数不会溢出,你会怎么办?我们把问题简化一下,假设有一个8位的无符号整数类型,我们知道它能表示的最大数字是255,但这时候如果我想表示256,要怎么办?
可能有人会想,那用两个数来存储不就好了。一个存储255,一个存储1,将这两个数放在数组里面。这个答案的话,虽然有些接近,但其实还有很大偏差:那就是我们并不能简单地按照大小拆分的,256拆分为255和1,要是265就拆分成255和10,而是要通过二进制的方式,我们来简单看一下。
1 | 我们知道8位整数最大就是 2 ^ 8 - 1,也就是它的八位全部都是1,结果是255 |
而Python底层也是类似这种做法,但是考虑的会更加全面。下面就以Python中的整数为例,看看底层数组的存储方式。
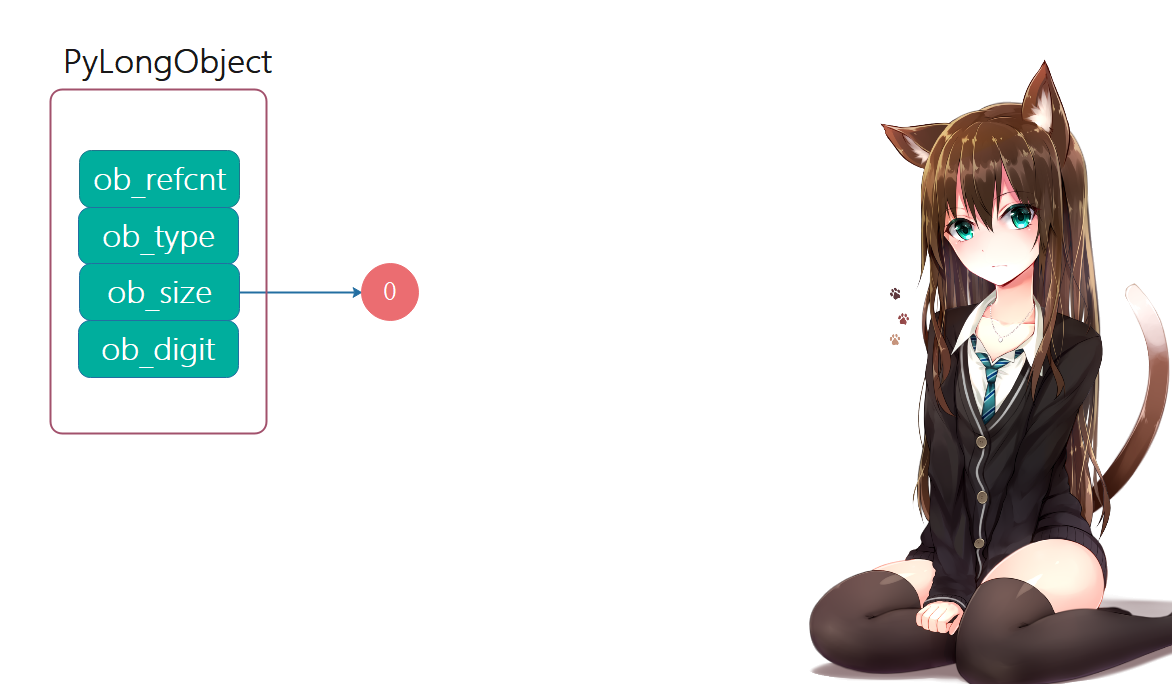
整数0:
注意:当要表示的整数为0时,ob_digit这个数组为空,不存储任何值,ob_size为0,表示这个整数的值为0,这是一种特殊情况。
整数1:
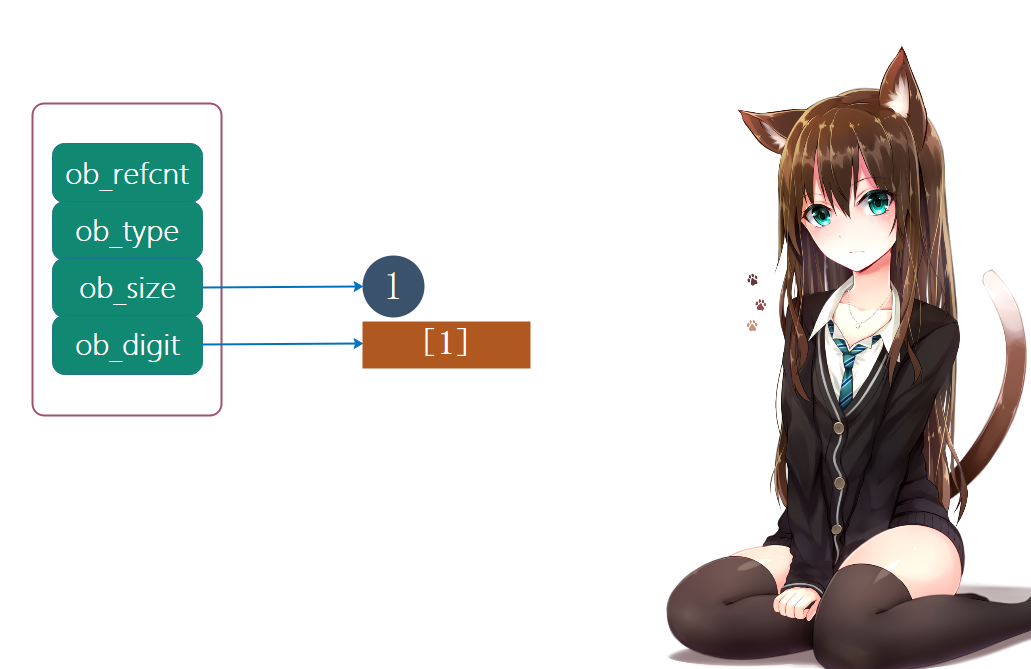
当然存储的值为1时,ob_size的值就是1,此时ob_digit数组就是[1]。
整数-1:
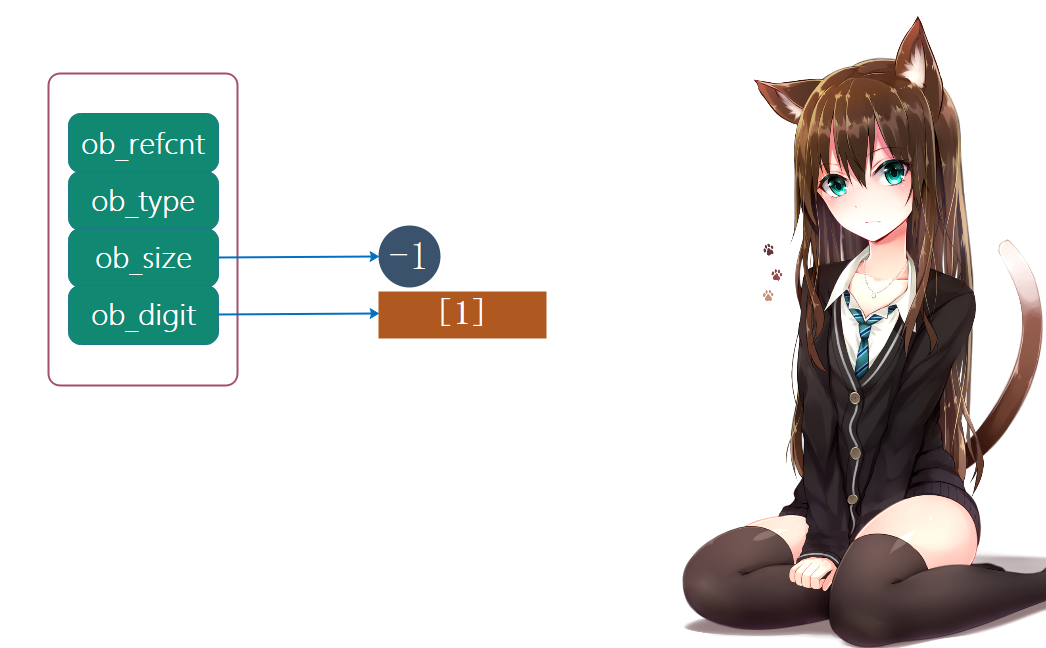
我们看到ob_digit数组没有变化,但是ob_size变成了-1,没错,整数的正负号是通过这里的ob_size决定的。ob_digit存储的其实是绝对值,无论n取多少,-n和n对应的ob_digit是完全一致的,但是ob_size则互为相反数。所以ob_size除了表示数组的长度之外,还可以表示对应整数的正负。
所以我们之前说整数越大,底层的数组就越长。更准确的说是绝对值越大,底层数组就越长。所以Python在比较两个整型的大小时,会先比较ob_size,如果ob_size不一样则可以直接比较出大小来。显然ob_size越大,对应的整数越大,不管ob_size是正是负,都符合这个结论,可以想一下。
整数2 ^ 30 -1:
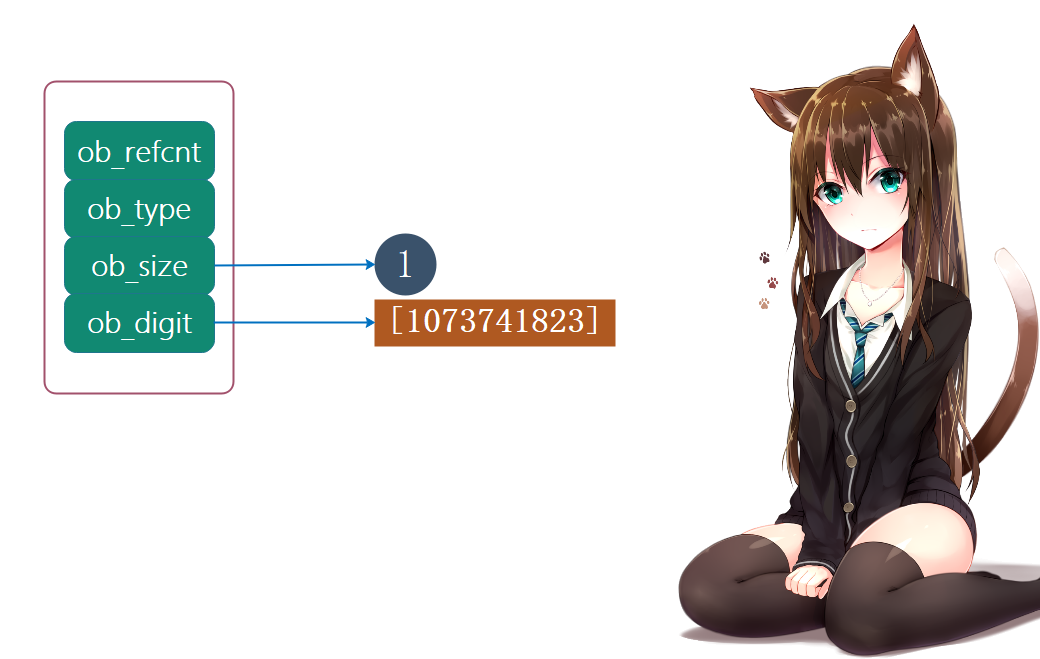
如果想表示2 ^30 - 1(^这里代指幂运算,当然对于Python程序猿来说两个星号也是幂运算,表达的意义是一样的),那么也可以使用一个digit表示。虽然如此,但为什么突然举2 ^ 30 - 1这个数字呢?答案是,虽然digit是4字节、32位,但是Python只用30个位。
之所以这么做是和加法进位有关系,如果32个位全部用来存储其绝对值,那么相加产生进位的时候,可能会溢出,比如有一个将32个位全部占满的整数
(2 ^ 32 - 1),即便它只加上1,也会溢出。这个时候为了解决这个问题,就需要先强制转换为64位再进行运算。但如果只用30个位的话,那么加法是不会溢出的,或者说相加之后依旧可以用32位整数保存。因为30个位最大就是2 ^ 30 - 1,即便两个这样的值相加,结果也是(2 ^ 30 - 1) * 2,即:2 ^ 31 - 2。而32个位的话最大是2 ^ 32 - 1,所以肯定不会溢出的;如果一开始30个位就存不下,那么数组中会有两个digit。
所以虽然将32位全部用完,可以只用一个digit表示更多、更大的整数,但是可能面临相加之后一个digit存不下的情况,于是只用30个位,如果数值大到30个位存不下的话,那么就会多使用一个digit。可能有人发现了,如果是用31个位的话,那么相加产生的最大值就是2 ^ 32 - 2,结果依旧可以使用一个32位整型存储啊,那Python为啥要牺牲两个位呢?答案是为了乘法运算。
1 | // 还记得这个宏吗?PYLONG_BITS_IN_DIGIT指的就是Python使用digit的位数 |
整数2 ^ 30:
问题来了,我们说digit只用30位,所以2 ^ 30 - 1是一个digit能存储的最大值,那么现在是2 ^ 30,所以数组中就要有两个digit了。
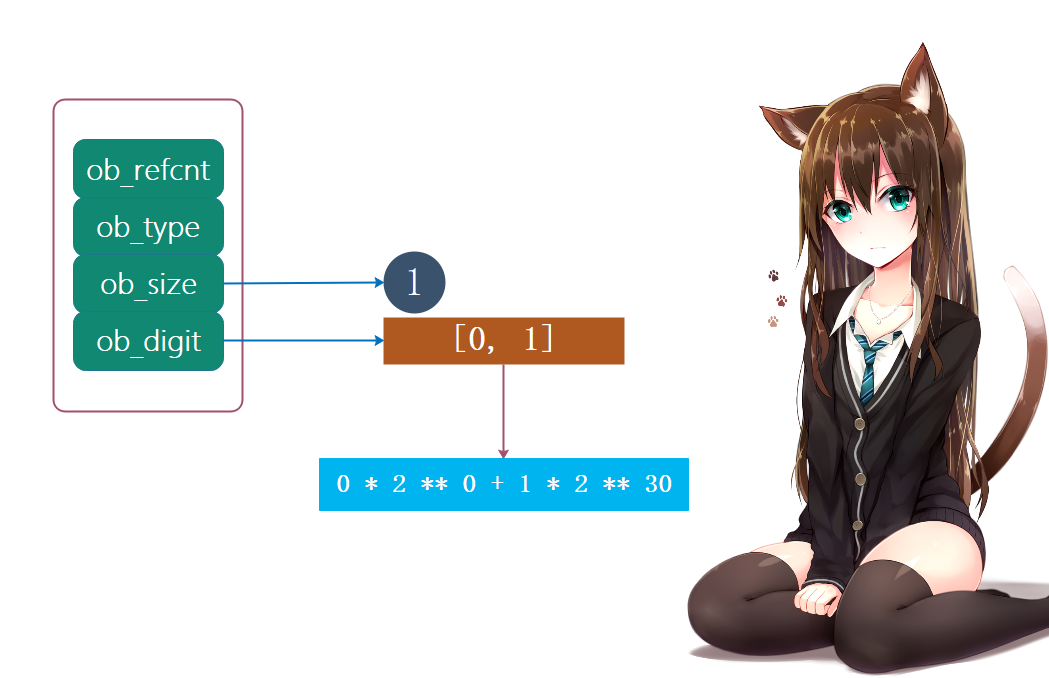
我们看到此时就用两个digit来存储了,此时的数组里面的元素就是0和1,而且充当高位的放在后面,因为我们说了使用新的digit来模拟更高的位。由于一个digit只用30位,那么数组中第一个digit的最低位就是1,第二个digit的最低位就是31,第三个digit的最低位就是61,以此类推,所以如果ob_digit为[a, b, c],那么对应的整数就为: a * 2 * 0 + b * 2 * 30 + c * 2 ** 60,如果ob_digit不止3个,那么就按照30个位往上加,比如ob_digit还有第四个元素d,那么就再加上d * 2 ** 90即可。**
再比如我们反推一下,如果a = 88888888888,那么底层数组ob_digit中的值是多少?
1 | import numpy as np |
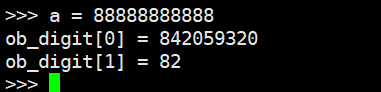
我们修改解释器源代码重新编译,通过在创建整数的时候打印ob_digit里面的元素的值,也印证了这个结论。
这个时候,我们可以分析整数所占的字节了。相信所有人都知道可以使用sys.getsizeof计算大小,但是这大小到底是怎么来的,估计会一头雾水。因为Python中对象的大小,是根据底层的结构体计算出来的。
我们说ob_refcnt、ob_type、ob_size这三个是整数所必备的,它们都是8字节,加起来24字节。所以任何一个整数所占内存都至少24字节,至于具体占多少,则取决于ob_digit里面的元素都多少个。
因此Python中整数所占内存 = 24 + 4 * ob_digit数组长度
1 | import sys |
小整数对象池
由于分析过了浮点数以及浮点类型对象,因此int类型对象的实现以及int实例对象的创建啥的就不说了,可以自己去源码中查看,我们后面会着重介绍它的一些操作。还是那句话,Python中的API设计的很优美,都非常的相似,比如创建浮点数可以使用PyFloat_FromDouble、PyFloat_FromString等等,那么创建整数也可以使用PyLong_FromLong、PyLong_FromDouble、PyLong_FromString等等,直接去Objects中对应的源文件中查看即可。
这里说一下Python中的小整数对象池,我们知道Python中的整数属于不可变对象,运算之后会创建新的对象。
1 | a = 666 |
所以这种做法就势必会有性能缺陷,因为程序运行时会有大量对象的创建和销毁。根据浮点数的经验,我们猜测Python应该也对整数使用了缓存池吧。答案是差不多,只不过不是缓存池,而是小整数对象池
Python将那些使用频率高的整数预先创建好,而且都是单例模式,这些预先创建好的整数会放在一个静态数组里面,我们称为小整数对象池。如果需要使用的话会直接拿来用,而不用重新创建。注意:这些整数在Python解释器启动的时候,就已经创建了。
小整数对象池的实现位于longobject.c中。
1 |
|
NSMALLPOSINTS宏规定了对象池中正数的个数 (从 0 开始,包括 0 ),默认 257 个;NSMALLNEGINTS宏规定了对象池中负数的个数,默认5个;small_ints是一个整数对象数组,保存预先创建好的小整数对象;
以默认配置为例,Python解释器在启动的时候就会预先创建一个可以容纳262个整数的数组,并会依次初始化 -5 到 256(包括两端)之间的262个PyLongObject。所以小整数对象池的结构如下:

但是为什么要实现缓存从-5到256之间的整数呢?因为Python认为这个范围内的整数使用频率最高,而缓存这些整数的内存相对可控。因此这只是某种权衡,很多程序的开发场景都没有固定的正确答案,需要根据实际情况来权衡利弊。
1 | a = 256 |
256位于小整数对象池内,所以全局唯一,需要使用的话直接去取即可,因此它们的地址是一样的。但是257不再小整数对象池内,所以它们的地址不一样。
我们上面是在交互式下演示的,但如果有小伙伴不是通过交互式的话,那么会得到出乎意料的结果。
1 | a = 257 |
可能有人会好奇,为什么地址又是一样的了,257明明不在小整数对象池中啊。虽然涉及到了后面的内容,但是提前解释一下也是可以的。主要区别就在于一个是在交互式下执行的,另一个是通过 python3 xxx.py的方式执行的。
首先Python的编译单元是函数,每个函数都有自己的作用域,在这个作用域中出现的所有常量都是唯一的,并且都位于常量池中,由co_consts指向。虽然我们上面的不是函数,而是在全局作用域中,但是全局你也可以看成是一个函数,它也是一个独立的编译单元。同一个编译单元中,常量只会出现一次。
当a = 257的时候,会创建257这个整数、并放入常量池中;所以b = 257的时候就不会再创建了,因为常量池中已经有了,所以会直接从常量池中获取,因此它们的地址是一样的,因为是同一个PyLongObject。
1 | # Python3.6下执行, 该系列的所有代码都是基于Python3.8, 但是这里先使用Python3.6, 至于原因, 后面会说 |
此时f1和f2显然是两个独立的编译单元,256属于小整数对象池中的整数、全局唯一,因此即便不在同一个编译单元的常量池中,它的地址也是唯一的,因为它是预先定义好的,所以直接拿来用。但是257显然不是小整数对象池中的整数,而且不在同一个编译单元的常量池中,所以地址是不一样的。
而对于交互式环境来说,因为我们输入一行代码就会立即执行一行,所以任何一行可独立执行的代码都是一个独立的编译单元。注意:是可独立执行的代码,比如变量赋值、函数、方法调用等等;但如果是if、for、while、def等等需要多行表示的话,比如:if 2 > 1:,显然这就不是一行可独立执行的代码,它还依赖你输入的下面的内容。
1 | if 2 > 1: # 此时按下回车,我们看到不再是>>>, 而是..., 代表还没有结束, 还需要你下面的内容 |
但是像a = 1、foo()、lst.appned(123)这些显然它们是一行可独立执行的代码,因此在交互式中它们是独立的编译单元。
1 | a = 257 # 此时这行代码已经执行了,它是一个独立的编译单元 |
但是问题来了,看看下面的代码,a和b的地址为啥又一样了呢?666和777明显也不在常量池中啊。
1 | a = 666;b=666 |
显然此时应该已经猜到原因了,因为上面两种方式无论哪一种,都是在同一行,因此整体会作为一个编译单元,所以地址是一样的。
1 | def f1(): |
但是在Python3.8中,如果是通过 python xxx.py的方式执行的话,即便是大整数、并且不再同一个编译单元的常量池中,它们的地址也是一样的,说明Python在3.8版本的时候做了优化。
另外,如果没有特殊说明,那么我们这个系列的所有代码都是在Python3.8下执行的。说实话,我就是因为发现在Python3.8中,打印的地址都是一样的,才在上面试了一下Python3.6。但是Python3.8中具体是怎么优化的,这里就暂时不讨论了
(明明是你没有仔细研究)。
整数运算
整数溢出是程序开发中一大难题,由此引发的 BUG 不计其数,而且相当隐蔽。之前使用golang刷LeetCode的时候,怎么也通不过,最后发现是因为LeetCode后台有一个测试用例比较特殊,导致整数太大,golang中的int64存不下。而Python 选择从语言层面彻底解决这个痛点,殚心竭虑地设计了整数对象。而我们也探索了整数对象,并初步掌握了整数对象的内部结构。
Python中的整数是串联了多个C中的digit(uint32_t),通过一个C数组的形式来实现整数的表示。这么做的好处就是Python中的整数没有长度限制了,因此不会溢出(而浮点数使用C的double,所以它会溢出)。之所以不会溢出,是因为数组是没有长度限制的,所以只要你的内存足够,就可以算任意大的数。所以Python表示:存不下?会溢出?这都不是事儿,直接继续往数组里面塞digit就ok了。
这里再重温一下PyLongObject的数据结构,我们说它是一个变长对象。ob_size指的是数组的长度,并且它除了表示长度还能体现出整数的正负,而ob_digit这个数组只用来存储其绝对值。
但是说实话,用整数数组实现大整数的思路其实平白无奇,但难点在于大整数 数学运算 的实现,它们才是重点,也是也比较考验编程功底的地方。
所以我们在分析浮点数的时候,一直说整数要比浮点数复杂,原因就在于此。浮点数相加的话直接两个double相加即可,但是整数相加可就没有那么简单了。
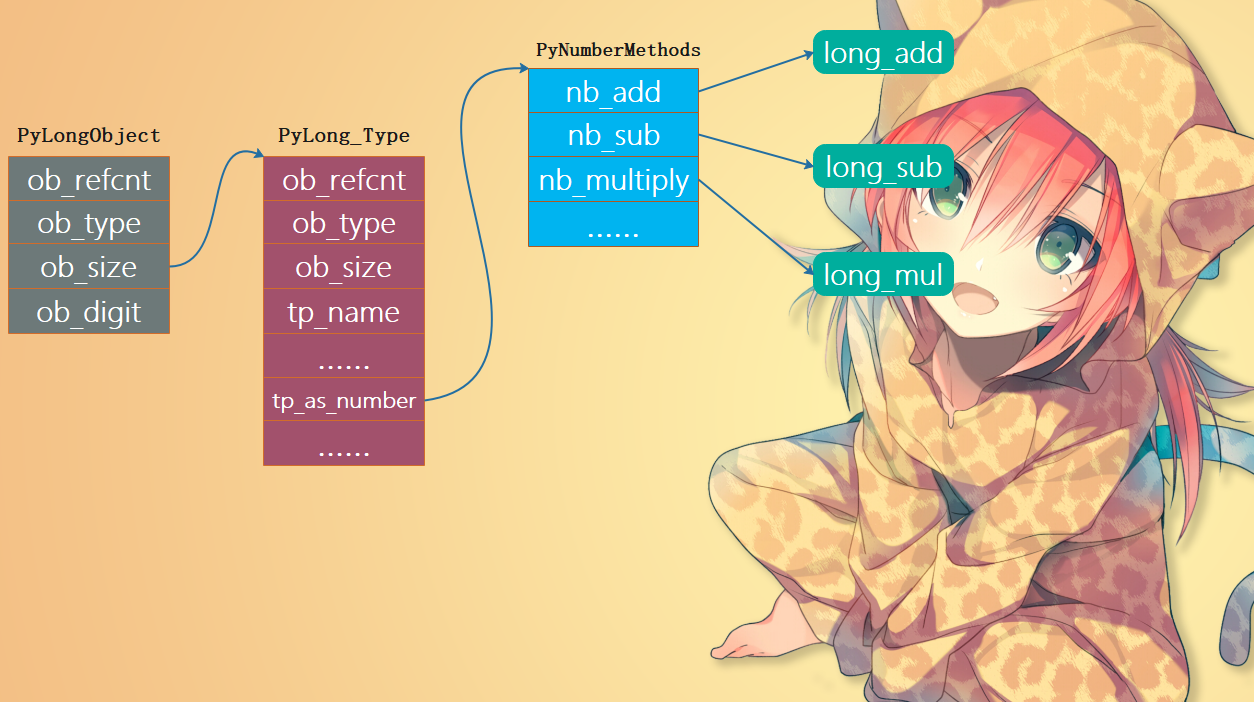
整数支持的操作定义在什么地方相信不用我说了,直接去longobject.c中查看就可以了,根据浮点数的经验我们知道PyLong_Type中的tp_as_number成员也指向了PyNumberMethods结构体实例,里面的成员都是指向与整型运算相关的函数的指针。
注意:图中有一个箭头画错了,应该是 ob_type 指向 PyLong_Type,但图中不小心变成了 ob_size。
整数的大小比较
先来看看Python中的整数在底层是如何比较的吧。
1 | static int |
所以我们看到Python中的整数就是按照上面这种方式比较的,总的来说就是先比较ob_size,ob_size不一样则可以直接比较。如果ob_size一样的话,那么会从后往前挨个比较数组中的元素,最终确定大小关系。
整数的相加
再来看看Python中的整数在底层是如何相加的,加法的实现显然是long_add,我们看一下。
1 | static PyObject * |
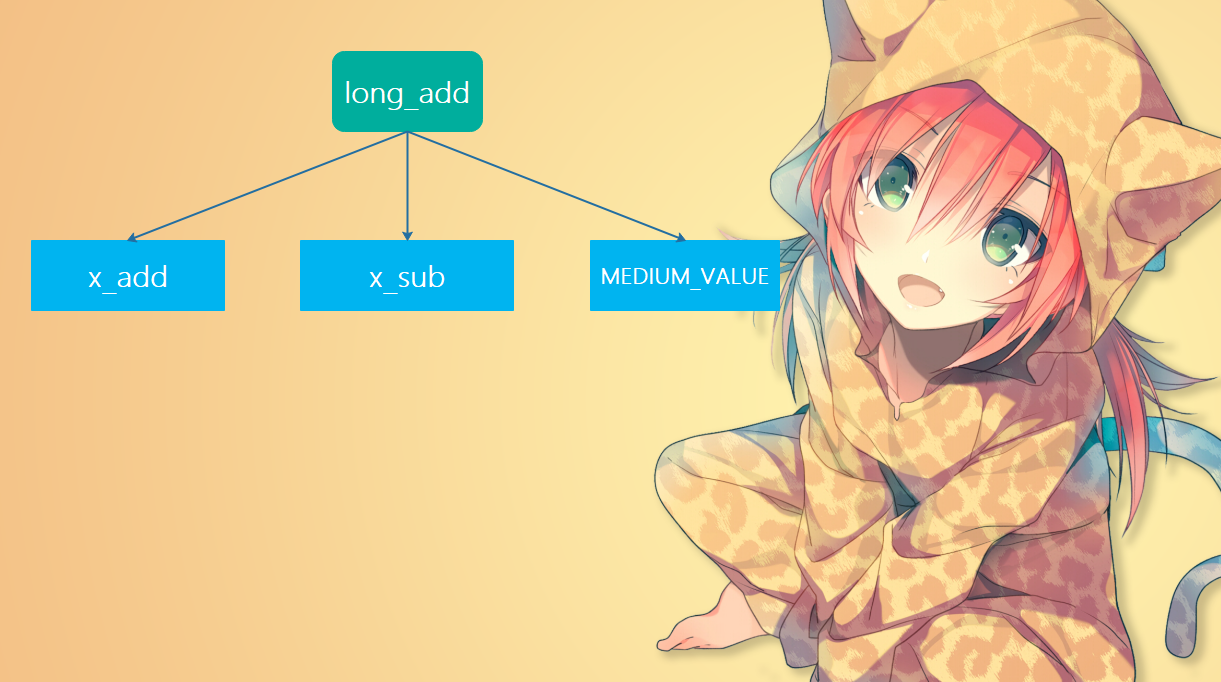
所以long_add这个函数并不长,但是调用了辅助函数x_add和x_sub,显然核心逻辑是在这两个函数里面。至于long_add函数,它的逻辑如下:
1. 定义一个变量z, 用于保存计算结果;2. 判断两个整数底层对应的数组是不是都不超过1, 如果是的话那么通过宏MEDIUM_VALUE直接将其转成C中的一个digit, 然后直接相加、返回即可。显然这里走的是快分支,或者快速通道;3. 但如果有一方ob_size绝对值不小于1, 那么判断两者的符号。如果都为负,那么通过x_add计算两者绝对值之和、再将ob_size乘上-1即可;4. 如果a的ob_size小于0, b的ob_size大于0, 那么通过x_sub计算b和a绝对值之差即可;5. 如果a的ob_size大于0, b的ob_size小于0, 那么通过x_sub计算a和b绝对值之差即可;6. 如果a的ob_size大于0, b的ob_size大于0, 那么通过x_add计算让b和a绝对值之和即可;
所以Python中整数的设计非常的巧妙,ob_digit虽然是用来维护具体数值,但是它并没有考虑正负,而是通过ob_size来表示整数的正负号。这样运算的时候,计算的都是整数的绝对值,因此实现起来会方便很多。将绝对值计算出来之后,再通过ob_size来判断正负号。
因此long_add将整数加法转成了 “绝对值加法(x_add)”和”绝对值减法(x_sub)”:
x_add(a, b), 计算两者的绝对值之和, 即:|a| + |b|;x_sub(a, b), 计算两者的绝对值之差, 即:|a| - |b|;
由于绝对值加、减法不用考虑符号对计算结果的影响,实现更为简单,这是Python将整数运算转化成绝对值运算的缘由。虽然我们还没看到x_add和x_sub是如何对整数的绝对值进行相加和相减运算的,但也能从中体会到程序设计中逻辑的 划分 与 组合 的艺术,优秀的代码真的很美。
那么下面我们的重心就在x_add和x_sub中了,看看它们是如何对大整数绝对值进行运算的。但是你可能会有疑问,大整数运算肯定很复杂,效率会差吧。显然这是必然的,整数数值越大,整数对象底层数组越长,运算开销也就越大。好在运算处理函数均以快速通道对小整数运算进行优化,将额外开销降到最低。
比如上面的long_add,如果a和b对应的整数的绝对值都小于等于2 ^ 30 - 1,那么会直接转成C中的整型进行运算,性能损耗极小。并且走快速通道的整数的范围是:-(2 ^ 30 - 1) ~ 2 ^ 30 - 1,即:-1073741823 ~ 1073741823,显然它可以满足我们绝大部分的运算场景。
绝对值加法x_add:
在介绍绝对值加法之前,先来看看几个宏,先不管它们是干什么的,会在x_add中有体现:
1 | //longintrepr.h |
此外,再想象一下我们平时算加法的时候是怎么算的:
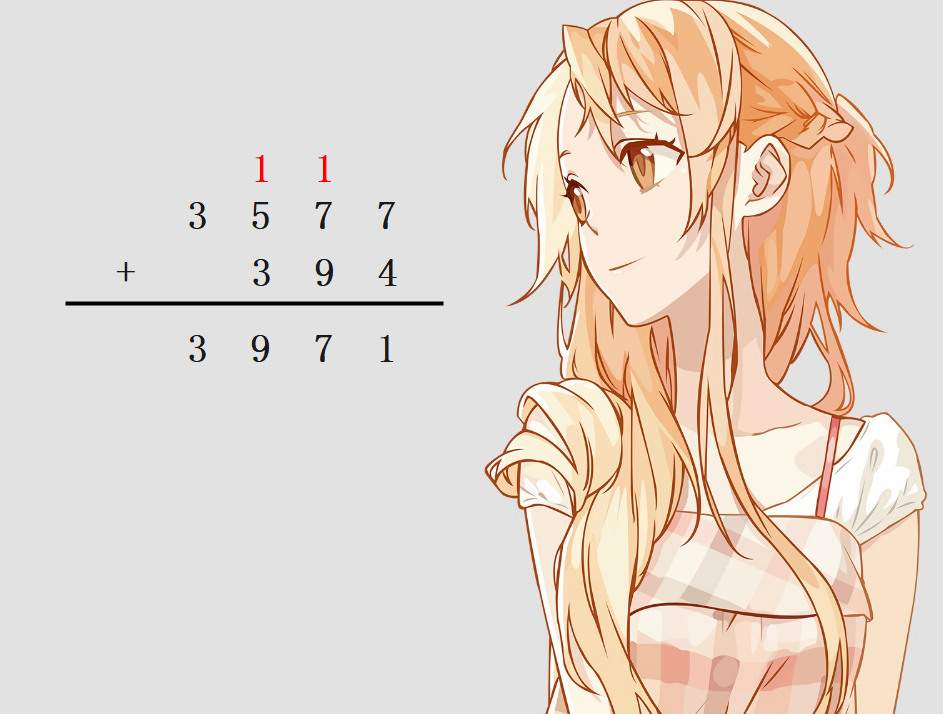
而x_add在逻辑和上面是类似的,下面分析x_add的实现:
1 | static PyLongObject * |
Python中的整数在底层实现的很巧妙,不理解的话可以多看几遍,然后我们在Python的层面上再反推一下,进一步感受底层运算的过程。
1 | # 假设有a和b两个整数, 当然这里是使用列表直接模拟的底层数组ob_digit |
看完绝对值加法x_add之后,再来看看绝对值减法x_sub,显然有了加法的经验之后再看减法会简单很多。
1 | static PyLongObject * |
所以Python整数在底层的设计确实很精妙,尤其是在减法的时候,强烈建议多看几遍回味一下。
整数的相减
整数的相减调用的是long_sub函数,显然long_sub和long_add的思路都是一样的,核心还是在x_add和x_sub上面,所以long_sub就没有什么可细说的了。
1 | static PyObject * |
所以关于什么时候调用x_add、什么时候调用x_sub,我们总结一下,总之核心就在于它们都是对绝对值进行运算的,掌握好这一点就不难了:
a + b
如果a是正、b是正,调用x_add(a, b),直接对绝对值相加返回结果如果a是负、b是负,调用x_add(a, b),但相加的是绝对值,所以long_add中在接收到结果之后还要对ob_size乘上-1如果a是正、b是负,调用x_sub(a, b),此时等价于a的绝对值减去b的绝对值。并且x_sub是使用绝对值大的减去绝对值小的,如果a的绝对值大,那么显然正常;如果a的绝对值小,x_sub中会交换,但同时也会自动变号,因此结果也是正常的。举个普通减法的例子:5 + -3, 那么在x_sub中就是5 - 3; 如果是3 + -5, 那么在x_sub中就是-(5 - 3), 因为发生了交换。但不管那种情况,符号都是一样的如果a是负、b是正,调用x_sub(b, a),此时等价于b的绝对值减去a的绝对值。所以这个和上面a是正、b是负是等价的。
所以符号相同,会调用x_add、符号不同会调用x_sub。
a - b
如果a是正、b是负,调用x_add(a, b)直接对a和b的绝对值相加即可如果a是正、b是正,调用x_sub(a, b)直接对a和b的绝对值相减即可,会根据绝对值自动处理符号,而a、b为正,所以针对绝对值处理的符号,也是a - b的符号如果a是负、b是正,调用x_add(a, b)对绝对值进行相加, 但是结果显然为负,因此在long_sub中还要对结果的ob_size成员乘上-1如果a是负、b是负,调用x_sub(a, b)对绝对值进行相减, 会根据绝对值自动处理符号, 但是在为负的情况下绝对值越大,其值反而越小, 因此针对绝对值处理的符号,和a - b的符号是相反的。所以最终在long_sub中,也要对结果的ob_size成员乘上-1。举个普通减法的例子:-5 - -3, 那么在x_sub中就类似于5 - 3; 如果是-3 - -5, 那么在x_sub中就类似于-(5 - 3), 因为发生了交换。但不管那种情况得到的值的正负号都是相反的,所以要再乘上-1
所以符号相同,会调用x_sub、符号不同会调用x_add。
所以可以仔细回味一下Python中整数的设计思想,以及运算方式。为什么只使用digit的30个位, 以及在相加、相减的时候是怎么做的。
当然还有乘法和除法,乘法Python内部采用的是效率更高的karatsuba算法,相当来说比较复杂,有兴趣可以自己查看一下。重点还是了解Python中的整数在底层是怎么存储的,以及为什么要这么存储。
小结
这一节我们介绍了整数的底层实现,并分析了Python中的整数为什么不会溢出,以及Python如何计算一个整数所占的字节。当然我们还说了小整数对象池,以及通过分析源码中的long_add和long_sub来了解底层是如何对整数进行运算的。