09-解密Python中字典和集合的底层实现,深度分析哈希表 楔子 Python的字典是一种映射型容器对象,保存了键(key)到值(value)的映射关系。通过字典,我们可以快速的实现值的查找,json这种数据结构也是借鉴了Python中的字典。而且字典在Python中是经过高度优化的,因为Python底层也在大量的使用字典这种数据结构。
那么这次我们就来全面分析一下Python中的字典。
基本使用 我们先来回顾一下字典的基本使用,然后再来分析它的一些特性以及底层实现。
创建一个字典:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 d = {"a" : 1 , "b" : 2 } print (d) d = dict (a=1 , b=2 , c=3 , d=4 ) print (d) d1 = dict ({"a" : 1 , "b" : 2 }, c=3 , d=4 ) d2 = dict ([("a" , 1 ), ("b" , 2 )], c=3 , d=4 ) print (d1) print (d2) d = {**{"a" : 1 , "b" : 2 }, "c" : 3 , **{"d" : 4 }} print (d) d = dict (**{"a" : 1 , "b" : 2 }, c=3 , **{"d" : 4 }) print (d) try : d = dict (**{1 : 1 }) except Exception as e: print (e) d = {**{1 : 1 , 2 : 2 }, **{(1 , 2 , 3 ): "嘿嘿" }} print (d)
字典支持的操作:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 d = {} d["name" ] = "古明地觉" d["where" ] = "东方地灵殿" print (d) print (d["name" ]) d["name" ] = "古明地恋" print (d) del d["name" ]d.pop("where" ) print (d)
当然字典支持的操作远不止上面那些,但是这些Python层面上的东西想必所有人都了如指掌了,因为字典支持的操作,仅仅相当于是一些API的调用罢了,对着文档查一遍、操作一波就完事了。我们重点是要分析字典这种数据结构在底层的实现方式,以及它背后的一些原理,这才是我们需要关注的。
首先字典的底层是借助哈希表实现的,什么是哈希表我们后面会详细说,总之字典的添加元素、删除元素、查找元素等操作的平均时间复杂度是O(1)。当然了,在哈希不均匀的情况下,最坏时间复杂度是O(n),但是这种情况很少发生。
我们来测试一下字典的执行效率,看看它和列表之间的区别。一个有1千万个键值对的字典。然后对两者使用in来查询某个元素是否存在,
我们测试的方式是,使用if … in …来查询一个元素是否存在,看看它们的耗时如何。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 import timeimport numpy as npdef test (count: int , value: int ): """ :param count: 循环次数 :param value: 查询的元素 :return: """ lst = list (np.random.randint(0 , 2 ** 30 , size=1000 )) d = dict .fromkeys(lst) t1 = time.perf_counter() for _ in range (count): value in lst t2 = time.perf_counter() print ("列表查询耗时:" , round (t2 - t1, 2 )) t1 = time.perf_counter() for _ in range (count): value in d t2 = time.perf_counter() print ("字典查询耗时:" , round (t2 - t1, 2 )) test(10 ** 3 , 22333 ) """ 列表查询耗时: 0.13 字典查询耗时: 0.0 """ test(10 ** 4 , 22333 ) """ 列表查询耗时: 1.22 字典查询耗时: 0.0 """ test(10 ** 5 , 22333 ) """ 列表查询耗时: 12.68 字典查询耗时: 0.01 """ test(10 ** 5 * 2 , 22333 ) """ 列表查询耗时: 25.72 字典查询耗时: 0.01 """
我们看到字典的查询速度非常快,从测试中我们看到,随着循环次数越来越多,列表所花费的总时间越来越长。但是字典由于查询所花费的时间极少,查询速度非常快,所以即便循环50万次,花费的总时间也不过才0.01秒左右。
此外字典还有一个特点,就是它的”快”不会受到数据量的影响,你从含有一万个键值对的字典中查找,和你从含有一千万个键值对的字典中查找,两者花费的时间几乎是没有区别的。
那么字典到底是使用了什么黑科技,才能达到这么快的效果呢?想要知道答案的话,那就从字典在底层的内部结构中寻找吧。
初识哈希表 **由于映射型容器的使用场景非常广泛,几乎所有现代语言都支持映射型容器,而且特别关注”键”的搜索效率。例如:C++标准模板库中的 *map* 就是一种关联式容器,内部基于红黑树实现。红黑树是一种平衡二叉树,能够提供良好的操作效率,插入、删除、搜索等关键操作的时间复杂度均为*O*(*l*o*g*2*n*)
,Linux的epoll也是使用了红黑树。
**而对于Python来讲,映射型容器指的就是字典,我们说字典在Python内部是被高度优化的。因为不光我们在用,Python虚拟机在运行时也重度依赖字典,比如:自定义类、以及其实例对象都有自己的属性字典,还有名字空间本质上也是一个字典,因此Python对字典的要求会更加苛刻。所以Python在实现字典时采用的数据结构肯定是要优于红黑树的(至少在添加、删除、查询元素等方面),也就是说它的时间复杂度是优于红黑树的。时间复杂度优于*O*(*l*o*g*2*n*)
的数据结构有哪些呢?没错,你应该已经猜到了,就是散列表、又称哈希表。
所以在介绍字典之前,我们需要介绍一下哈希表。当然这里只是先大致介绍一下,能够一个宏观的认识,为了在理解字典时能够方便一些。至于更详细的内容,我们会在本文的后面介绍。
我们在介绍元组的时候,说元组可以作为字典的key,但是列表不可以,就是因为列表是不可哈希的。哈希表的原理是将key通过哈希函数进行运算转换为一个数值,用这个数值来充当索引,因此这就有一个前提,就是你的值不可以变。而列表是个可变对象,因此它不可以作为字典的key。
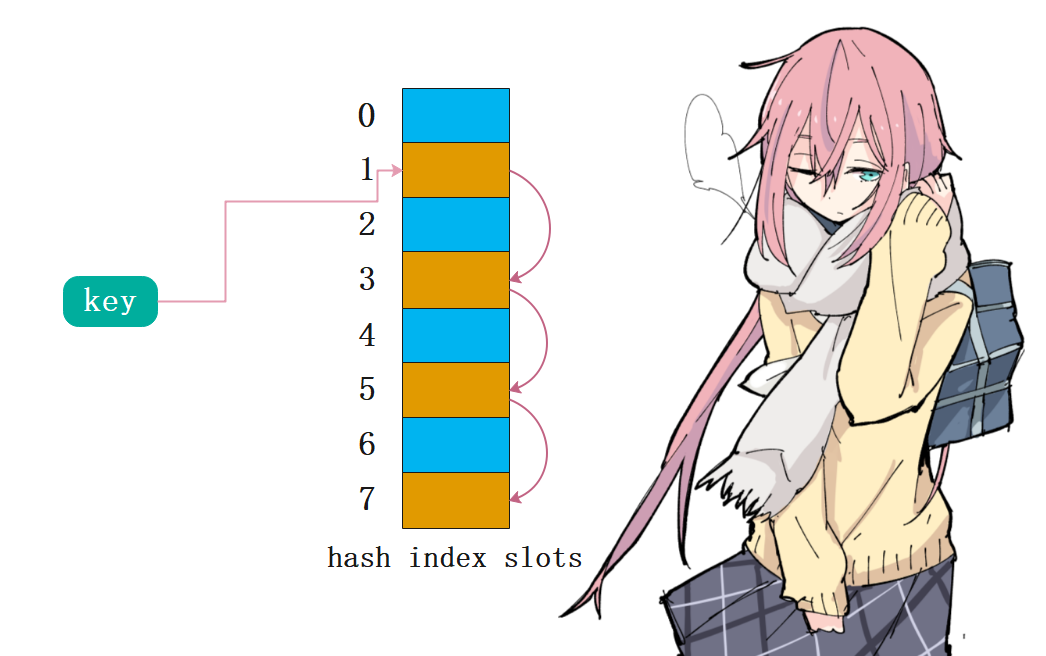
直接这么说的话,可能会感到很迷,我们画一张图。
我们发现除了key、value之外,还有一个index。其实哈希表本质上也是使用了索引的思想,我们知道虽然列表在遍历的时候是个时间复杂度为O(n)的操作,但是通过索引定位元素则是一个时间复杂度为O(1)的操作,不管你列表有多长,通过索引总是能瞬间定位到指定元素。所以哈希表实际上也是使用了数组(列表)的思想,会把这个key通过哈希函数映射成一个数值,作为索引。至于它是怎么映射的,我们后面再谈,现在我们就假设是按照我们接下来说的方法映射的。
比如我们这里有一个能容纳10个元素的字典(这里假设容量为10其实是不准确的,容量应该是2的n次方,但是这里只是介绍哈希表,所以不管了),我们先设置d[“satori”]=82,那么会对”satori”这个字符串进行一个哈希运算,然后再对10、也就是和当前的总容量进行取模,这样的话是不是能够得到一个小于10的数呢?假设是5,那么就存在索引为5地方。然后又进行d[“koishi”]=83,那么按照同样的规则运算得到8,那么就存在索引为8的位置,同理第三次设置d[“mashiro”]=80,对mashiro进行哈希、取模,得到2,那么存储在索引为2的地方。
同理当我们根据键来获取值的时候,比如:d[“satori”],那么同样会对字符串”satori”进行哈希、取模,得到索引发现是5,直接把索引为5的value给取出来。
当然这种方式肯定存在缺陷,比如:
不同的值进行哈希、取模运算之后得到的结果一定是不同的吗?在运算之后得到索引的时候,发现这个位置已经有人占了怎么办?取值的时候,索引为5,可如果索引为5对应的key和我们指定获取的key不一致怎么办?
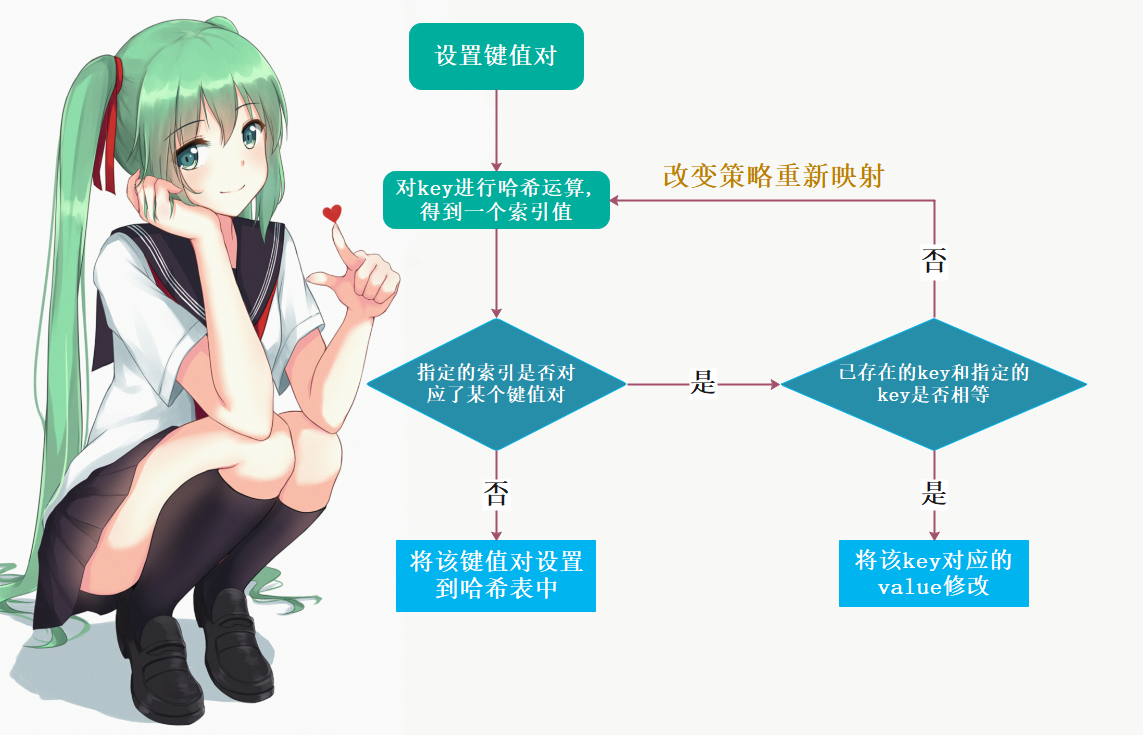
所以哈希值是有冲突的,如果一旦冲突,那么Python底层会改变策略重新映射,直到映射出来的索引没有人用。比如我们设置一个新的key、value,d[“tomoyo”]=88,可是我们对”tomoyo”这个key进行映射之后得到的结果也是5,而索引为5的地方已经被key为”satori”的键给占了,那么Python就会改变规则来对”tomoyo”重新进行运算,找到一个空位置进行添加。但如果我们再次设置d[“satori”]=100,那么对satori进行映射得到的结果也是5,而key是一致的,那么就会把对应的值进行修改。
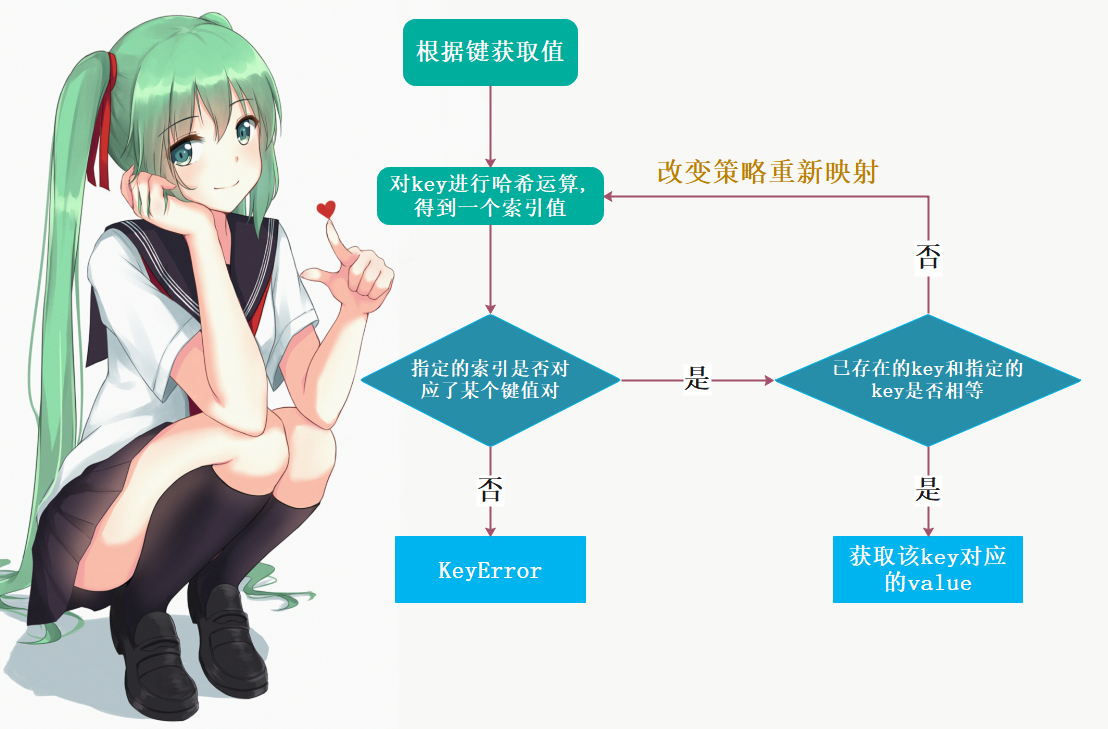
同理,当我们获取值的时候,d[“tomoyo”],对key进行映射,得到索引。但是发现key不是”tomoyo”而是”satori”,于是改变规则(这个规则跟设置key冲突时,采用的规则是一样的),重新映射,得到索引,然后发现key是一致的,于是将值取出来。
但如果我们指定了一个不存在的key,那么哈希映射,找到对应索引,发现没有key,证明我们指定的key是不存在的。但如果有的话,发现key和我们指定的key不相等,说明哈希运算得到索引只是碰巧一样,但由于key不一样,因此会改变规则重新运算,得到新的索引。然而发现没有对应的key,于是报错:指定的key不存在。
所以从这里就已经能说明问题了,就是把key转换成类似列表的索引。可能有人问,这些值貌似不是连续的啊,对的,肯定不是连续的。并不是说你先存,你的索引就小、就在前面,这是由key进行哈希运算之后的结果决定的。而且容量有10个,目前我们只存了4个元素,那么哈希表、或者说字典会不会扩容呢?当然,既然是可变对象,当然会扩容。并且它还不是像列表那样,容量不够才扩容,而当元素个数达到容量的三分之二的时候就会扩容。
我们可以认为字典底层还是使用了索引的思想,字典不可能会像列表那样,元素之间是连续的,一个一个挨在一起的。既然是哈希运算,得到的值肯定是随机的。容量为10,尽管有6个是空着的,但是没关系,我们只要保证设置的元素整体上是有序的即可。就好比有10张桌椅,小红坐在第3张,小明坐在第8张,尽管有空着的,但是没关系,就让它空着。只要我到第3张桌椅能够找到小红、第8张可以找到小明即可。这些桌椅的位置就可以看成是索引,只要我通过索引能够找到对应的元素即可。但是容量为10,为什么不能全部占满之后再扩容呢?试想一下,既然是随机的,那么肯定会出现哈希值碰撞,并且当元素个数到达三分之二之后,这种碰撞的概率非常大。因此当容量到达三分之二的时候,就会申请一份更大的空间,以便来容纳新的元素。
所以我们发现哈希表实际上就是一种空间换时间的方法,如果容量为100,那么就相当于有100个位置,每个元素都进行哈希映射,找到自己的位置。各自的位置都是不固定的,也许会空出来很多元素,但是无所谓,只要保证这些元素在100个位置上是相对有序、通过哈希运算得到索引之后,可以在相应的位置找到它即可。
所以相信应该所有人都能明白为什么哈希表的时间复杂度是O(1)了,就是因为使用了索引的思想,每一个索引都是连续的,只不过一部分索引没有相应的key、value罢了。但这无所谓,因为索引和key、value是一一对应的,通过索引我们能瞬间定位到指定的key,再来检测key是否存在以及和我们指定的key是否一致。如果不存在,那么不好意思,证明这个地方根本没有key、value,说明我们指定了一个不存在的key。而且由于元素个数达到容量的三分之二的时候,碰撞的概率非常大,因此几乎不可能出现容量正好都排满的情况,否则那要改变规则、重复映射多少次啊。
一句话总结:哈希表就是一种空间换时间的方法
设置键值对如下图所示:
根据键获取值,如下图所示:
字典的底层结构–PyDictObject 下面我们来看看字典在底层对应的结构体PyDictObject,位于Include/dictobject.h中,它的实现还是很复杂的。
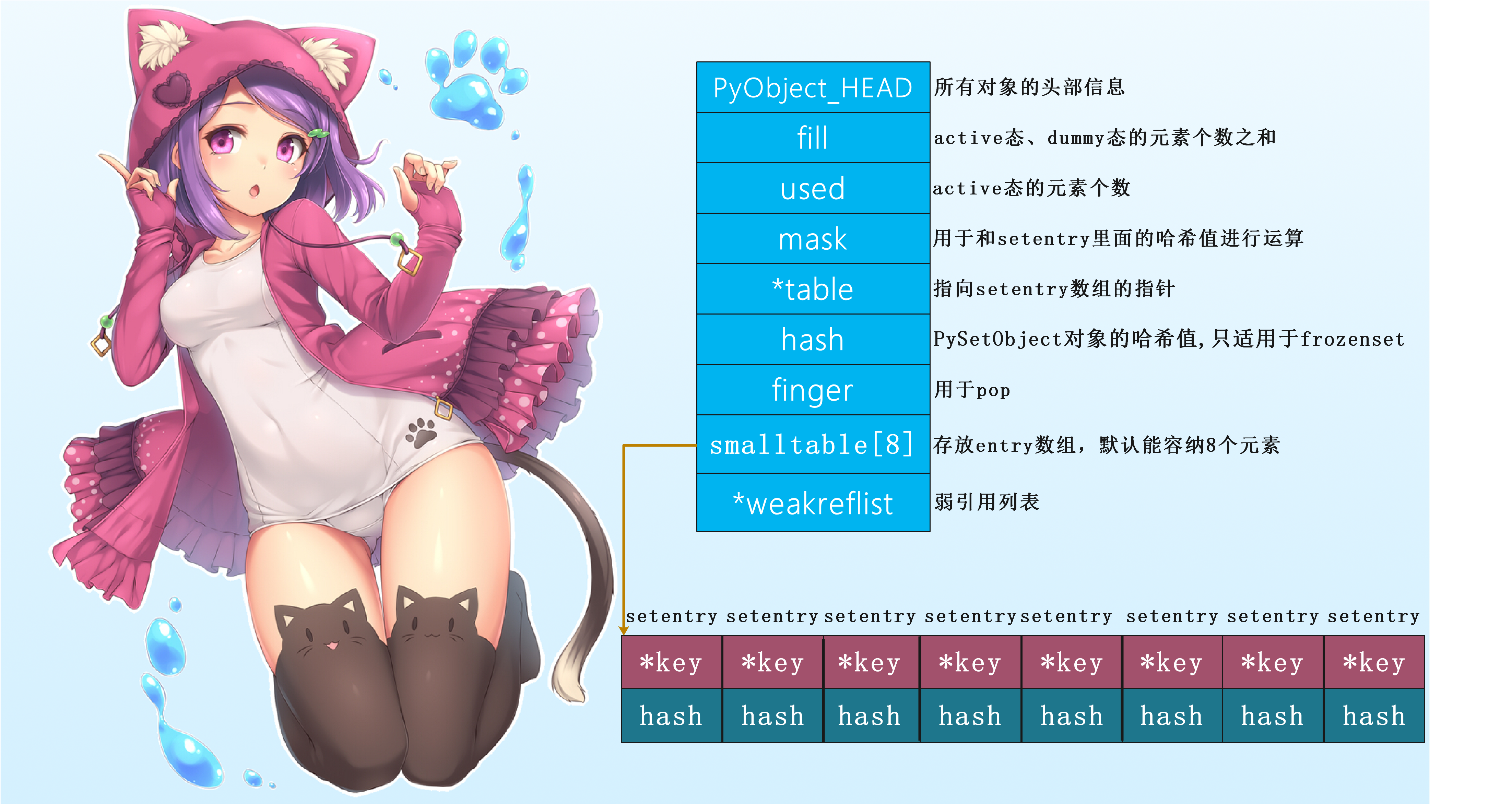
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 typedef struct { PyObject_HEAD Py_ssize_t ma_used; uint64_t ma_version_tag; PyDictKeysObject *ma_keys; PyObject **ma_values; } PyDictObject;
所以名字起得很形象,结合表的话,键和值就存在一起;分离表的话,键和值就存在不同的地方。至于为什么这么做,后面会解释。
整个结构体实际上是看不出来啥的,主要的原因就在那个PyDictKeysObject,我们需要再来看看它长什么样子。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 typedef struct _dictkeysobject PyDictKeysObject ;struct _dictkeysobject { Py_ssize_t dk_refcnt; Py_ssize_t dk_size; dict_lookup_func dk_lookup; Py_ssize_t dk_usable; Py_ssize_t dk_nentries; char dk_indices[]; };
而我们说一个键值对在底层对应一个entry,而这个entry指的就是PyDictKeyEntry对象,我们看看这个结构体长什么样子。
1 2 3 4 5 6 typedef struct { Py_hash_t me_hash; PyObject *me_key; PyObject *me_value; } PyDictKeyEntry;
显然ma_key和ma_value就是键和值,我们之前说Python中变量、以及容器内部的元素都是泛型指针PyObject *,其中也包括字典,这里也得到了证明。但是我们看到entry除了有键和值之外,还有一个me_hash,它表示键对应的哈希值,这样可以避免重复计算。
至此,字典的整个底层结构就非常清晰了。
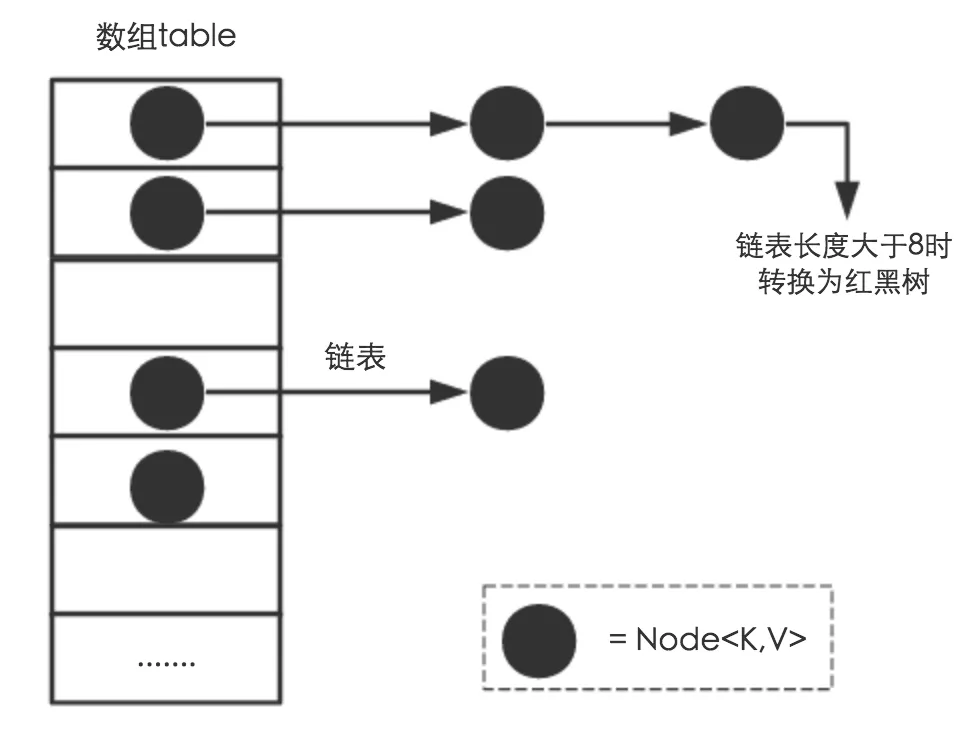
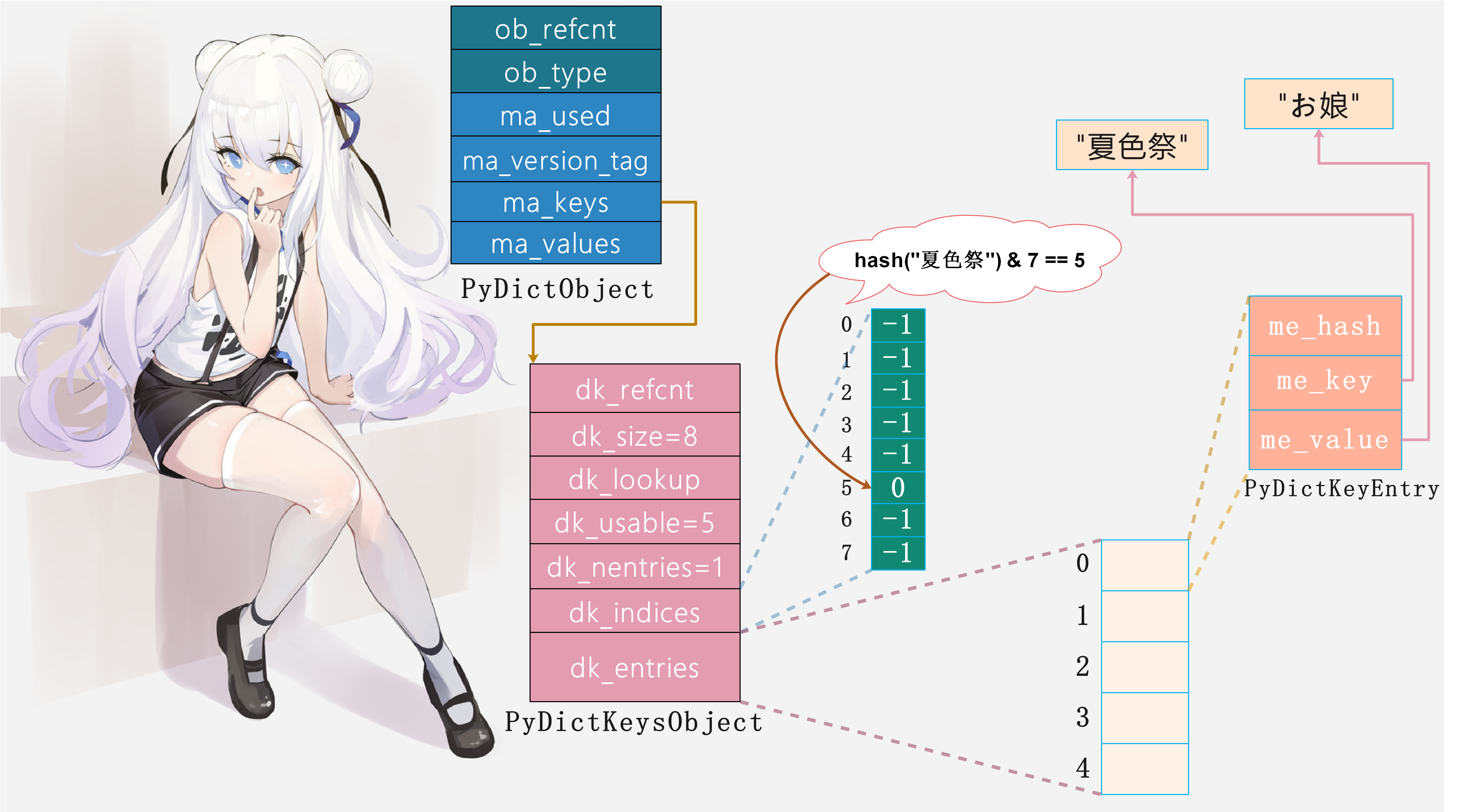
字典的真正实现藏在PyDictKeysObject中,它的内部包含两个关键数组:一个是哈希索引数组dk_indices 键值对数组dk_entries (entry)按照先来后到的顺序保存在键值对数组中,而哈希索引数组则保存”键值对”在”键值对数组”中的索引。另外,哈希索引数组中的一个位置我们称之为一个”槽”,比如图中的哈希索引数组便有8个槽,它字典的数量是相等的。
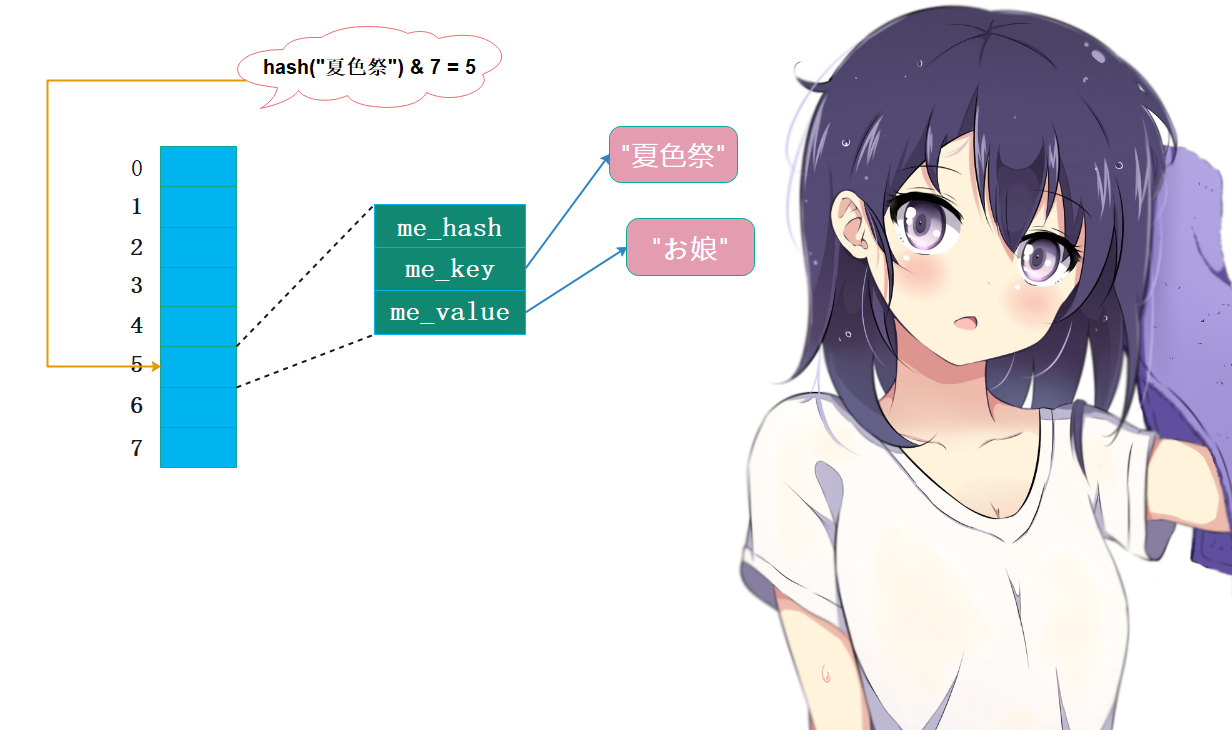
比如我们往空字典(但是容量已经有了, 初始是8个, 不过可用的数量为5个)中插入键值对"夏色祭": "お娘"的时候,Python会执行以下步骤:
1. 将键值对保存在dk_entries中,由于初始字典是空的,所以会保存在dk_entries数组中索引为0的位置2. 通过哈希函数将键"夏色祭"映射成一个数值,作为索引,假设是53. 将插入的键值对在数组中的索引0,保存在哈希索引数组中索引为5的槽中
然后当我们在查找键”夏色祭”对应的值的时候,便可瞬间定位。过程如下:
1. 通过哈希函数将键"夏色祭"映射成数值,也就是索引。因为在设置的时候索引是5,所以在获取的时候映射出来的索引肯定也是52. 找到哈希索引数组中索引为5的槽,得到其保存的0,这里的0对应键值对数组的索引3. 找到键值对数组中索引为0的位置,取出PyDictKeyEntry中的me_value,也就是值(当然肯定要先比较key、也就是me_key是否一致, 不一致则重新映射。当然如果该位置为NULL, 那么直接报出KeyError)
由于哈希值计算 数组定位
当然我们在上面的”初识哈希表”这一部分,为了避免牵扯太多,所以说的相对简化了。比如:”mashiro”: 80,我们说”mashiro”映射出来的索引是2,那么键值对就直接存在索引为2的地方。这实际上是简化了,因为这相当于把”哈希索引数组”和”键值对数组”合在一块了。而在早期的Python中,它也确实是这么做的。
但是从上面字典的结构图中我们看到,实际上是先将”键值对”按照先来后到的顺序存在一个数组(键值对数组)中,然后再把其索引存放在另一个数组(哈希索引数组)中索引为2("mashiro"映射出来的索引是2)的地方。所以在查找的时候,映射出来的索引2其实是哈希索引数组对应的索引。然后对应的槽也存储了一个索引,这个索引是键值对数组对应的索引,假设是4,所以会再根据索引4从键值对数组中获取指定的PyDictKeyEntry对象,再根据该对象获取指定的value。
所以可以看出两者整体思想是基本类似的,理解起来没有什么区别,甚至第一种方式实现起来还会更简单一些。但为什么采用后者这种实现方式,以及这两者之间的区别,我们在后面还会专门分析,之所以采用后者主要是基于内存的考量。
容量策略 根据字典的行为我们断定,字典肯定和列表一样有着”预分配机制”。因为可以扩容,那么为了避免频繁申请内存,所以在扩容的是时候会将容量申请的比键值对个数要多一些。那么字典的容量策略是怎么样的呢?
在Object/dictobject.c源文件中我们可以看到一个宏定义:
1 #define PyDict_MINSIZE 8
从这个宏定义中我们可以得知,一个字典的最小容量是8,或者说内部哈希表的长度最小是8。
哈希表越密集,哈希冲突则越频繁,性能也就越差。因此,哈希表必须是一种 稀疏 的表结构,越稀疏则性能越好。但由于 “内存开销” 的制约,哈希表不可能无限地稀疏,所以需要在时间和空间上进行权衡。实践经验表明,一个1/2到2/3满的哈希表,性能较为理想——以相对合理的 “内存” 换取相对高效的 “执行性能”。
为保证哈希表的稀疏程度,进而控制哈希冲突频率, Python 通过 宏USABLE_FRACTION 将哈希表内元素控制在2/3以内。宏USABLE_FRACTION 根据哈希表规模n,计算哈希表可存储元素的个数,也就是 键值对数组 的长度。以长度为 8 的哈希表为例,最多可以保持 5 个键值对,超出则需要扩容。
而USABLE_FRACTION 是一个非常重要的宏定义,位于源文件 *Objects/dictobject.c* 中:
1 #define USABLE_FRACTION(n) (((n) << 1)/3)
哈希表规模一定是2的n次方,也就是说 *Python* 采用”翻倍扩容”的策略。例如,长度为 *8* 的哈希表扩容后,长度变为 *16* 。
最后,我们来考察一个空字典所占用的内存空间。*Python* 为空字典分配了一个长度为 *8* 的哈希表,因而也要占用相当多的内存,主要有以下几个部分组成:
PyDictObject中有6个成员,一个8字节,加起来共48字节PyDictKeysObject中有7个成员,除了两个数组之外,剩余的每个成员也是一个8字节,所以加起来40字节而剩余的两个数组,一个是char类型的数组dk_indices,里面1个元素占1字节;还有一个PyDictKeyEntry类型的数组dk_entries,里面一个元素占24字节,因为PyDictKeyEntry里面有三个成员,一个8字节。但是注意:字典容量为8,说明哈希索引数组长度为8,但是键值对数组dk_entries长度是5,至于原因我们上面分析的很透彻了。因此这两个数组加起来总共是 8 + 24 * 5 = 128字节
所以一个空字典占用的内存是:48 + 40 + 128 = 216字节,我们来测试一下:
1 2 3 4 >>> d = dict ()>>> d.__sizeof__()216 >>>
但是注意:我们说空字典容量为8,但前提它不是通过Python/C API创建的,如果是d = {}这种方式,那么初始容量就是0,显然此时只有48字节,因为ma_keys此时是NULL。
1 2 3 4 >>> d = {}>>> d.__sizeof__()48 >>>
另外,我们看到在计算内存的时候使用的不是sys.getsizeof,而是对象的__sizeof__方法,这两者有什么区别呢?答案是使用sys.getsizeof计算出来内存大小会比调用对象的__sizeof__方法计算出来的内存大小多出16个字节。
1 2 3 4 5 6 7 8 >>> import sys>>> >>> sys.getsizeof(dict ()), dict ().__sizeof__()(232 , 216 ) >>> >>> sys.getsizeof({}), {}.__sizeof__()(64 , 48 ) >>>
之所以会出现这种情况,是因为sys.getsizeof将垃圾回收器的开销也考虑进去了。
我们说Python底层是通过引用计数来判断对象是否被回收,但是引用计数有一个致命缺陷就是它无法解决循环引用的问题,所以Python内部的gc就是专门用来解决循环引用的。如果创建了一个可能会发生循环引用的对象,那么Python会将该对象挂在链表上,当然链表总共有三条,分别是零代链表、一代链表、二代链表。
先将对象挂在零代链表上,Python的gc一旦发动,那么会采用三色标记模型来对零代链表上的对象进行标记–清除,将那些发生了循环引用的对象的引用计数减一。
而这样的链表为什么有三条呢?试想一下,gc发动的成本也是很高的,如果在gc的洗礼下还能活下来的对象,说明其暂时是较稳的,没有必要每次都对其进行检测。所以会将零代链表中比较稳定的对象移动到一代链表中,同理二代链表也是同理。当清理零代链表达到10次的时候,会清理一次一代链表,清理一代链表达到10次的时候会清理一次二代链表。这样的技术在Python中也被成为分代技术。
而移动到链表中的对象,除了 PyObject 之外还会有一个额外的 PyGC_Head,所以 sys.getsizeof 计算结果多出的16字节,就是这个 PyGC_Head 所占的大小(在后续介绍GC的时候会说)。
但是整型、浮点型、字符串等等,它们使用sys.getsizeof和调用__sizeof__计算出来的结果是一样的。
1 2 3 4 5 >>> sys.getsizeof(123 ), (123 ).__sizeof__()(28 , 28 ) >>> >>> sys.getsizeof("matsuri" ), "matsuri" .__sizeof__()(56 , 56 )
至于为什么一样,想必你已经猜到了,因为整型、字符串这种对象是不可能发生循环引用的,只有容器对象才会有可能发生循环引用。我们说Python中的gc是专门针对可能发生循环引用的对象的,对于不会发生循环引用的对象来说,不会参与gc,一个引用计数足够了,所以它们使用两种方式计算出的结果是一样的。
关于垃圾回收,是一门很复杂的学问,我们这里简单提一下。在该系列的后续,我们会详细的探讨Python中的垃圾回收。
内存优化 我们说在Python早期,哈希表并没有分成两个数组实现,而是由一个键值对数组实现,这个数组也承担哈希索引的角色:
我们看到这种结构不正是我们在介绍哈希表的时候说的吗?一个键值对数组既用来存储,又用来充当索引,无需分成两个步骤,而且这种方式也似乎更简单、更直观。而我们说Python在早期确实是通过这种方式实现的哈希表,只是这种实现方式有一个弊端,就是太耗费内存了。
我们说哈希表必须保持一定程度的稀疏,最多只有2/3满,这意味着至少要浪费1/3的空间。
所以Python为了尽量节省内存,将键值对数组压缩到原来的2/3,只用来存储,而对key进行映射得到的索引由另一个数组(哈希索引数组)来存储。因为键值对数组里面一个元素要占用24字节,而哈希索引数组在容量不超过256的时候,里面一个元素只占一个字节;容量不超过65536的时候,里面一个元素只占两个字节,其它以此类推。由于哈希索引数组里面的元素大小比键值对数组里面的元素大小要小很多,所以将哈希表分成两个数组(避免键值对数组的浪费)来实现会更加的节省内存。我们可以举个栗子计算一下,假设我们容量是2 * 16 = 65536的哈希表。
如果是通过第一种方式,只用一个数组来存储的话:
1 2 3 4 5 6 >>> 2 ** 16 * 24 1572864 >>> >>> 2 ** 16 * 24 // 3 524288 >>>
如果是通过第二种方式,使用两个数组来存储的话:
1 2 3 >>> 2 ** 16 * 24 * 2 / 3 + 2 ** 16 * 2 1179648 >>>
所以一个数组存储比两个数组存储要多用393216字节的内存,因此Python选择使用两个数组来进行存储。
小结 我们通过考察字典的搜索效率,并深入源码研究其内部哈希表的实现,得到以下结论:
字典是一种高效的映射式容器,每秒完成高达 *200* 多万次搜索操作;字典内部由哈希表实现,哈希表的稀疏特性意味着昂贵的内存开销;为优化内存使用,Python将哈希表分为 哈希索引数组 和 键值对数组,也就是通过两个数组来实现;哈希表在 1/2 到 2/3 满时,性能较为理想,较好地平衡了 内存开销 与 搜索效率;
深入哈希表 通过字典的底层实现,我们找到字典快速、高效的秘密–哈希表。对于映射式容器,一般是通过平衡搜索树或哈希表实现。而Python的字典选用了哈希表,主要是考虑到在搜索方面哈希表的效率更高。因为我们说Python底层重度依赖字典,所以对字典在搜索、设置元素方面的性能,要求的更加苛刻。
但是由于哈希表的稀疏特性,导致其会有巨大的内存牺牲,而为了优化,Python别出心裁的将哈希表分成两部分来实现,分别是:哈希索引数组和键值对数组。
但是显然这当中还有很多细节我们没有说,比如:哈希函数到底是怎么将一个键映射成索引的?哈希冲突了怎么办?哈希攻击又是什么?以及删除操作(没有表面想的那么简单)如何实现?而下面我们就来攻破这些难题,深入理解哈希表。
哈希值 Python内置函数hash会返回对象的哈希值,哈希表依赖于哈希值。
而根据哈希表的性质,我们知道键对象必须满足以下两个条件,否则哈希表便无法正常工作。
1. 哈希值在对象的整个生命周期内不可以改变2. 可比较,如果两个对象相等(使用==操作符结果为True),那么它们的哈希值一定相同
满足这两个条件的对象便是”可哈希(hashable)”对象,只有可哈希对象才可以作为哈希表的键(key)。因此像字典、集合等底层由哈希表实现的对象,其元素必须是可哈希对象。
Python中内置的不可变对象都是可哈希对象,比如:整数、浮点数、字符串、元组(元组里面也要是不可变对象)等等,而像可变对象,比如列表、字典等等便不可作为哈希表的键。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 >>> {1 : 1 , "xxx" : [1 , 2 , 3 ], 3.14 : 333 } {1 : 1 , 'xxx' : [1 , 2 , 3 ], 3.14 : 333 } >>> >>> {[]: 123 } Traceback (most recent call last): File "<stdin>" , line 1 , in <module> TypeError: unhashable type : 'list' >>> >>> {(1 , 2 , 3 ): 123 } {(1 , 2 , 3 ): 123 } >>> {(1 , 2 , 3 , []): 123 } Traceback (most recent call last): File "<stdin>" , line 1 , in <module> TypeError: unhashable type : 'list' >>>
而我们自定义的类的实例对象也是可哈希的,且哈希值是通过对象的地址计算得到的。
1 2 3 4 5 6 7 class A : pass a1 = A() a2 = A() print (hash (a1), hash (a2))
而且Python也支持我们重写哈希函数,比如:
1 2 3 4 5 6 7 8 9 10 11 12 class A : def __hash__ (self ): return 123 a1 = A() a2 = A() print (hash (a1), hash (a2)) print ({a1: 1 , a2: 2 })
并且我们看到虽然哈希值一样,但是在作为字典的键的时候,如果发生了冲突,会改变规则。注意:我们自定义的类的实例对象默认都是可哈希的,但如果类里面重写了__eq__方法,且没有重写__hash__方法的话,那么这个类的实例对象就不可哈希了。
1 2 3 4 5 6 7 8 9 10 11 12 class A : def __eq__ (self, other ): return True a1 = A() a2 = A() try : print (hash (a1), hash (a2)) except Exception as e: print (e)
为什么会有这种现象呢?首先我们说在没有重写__hash__方法的时候,哈希值默认是根据对象的地址计算得到的。而且对象如果相等(使用==操作符会得到True),那么哈希值一定是一样的。但是我们重写了__eq__,相当于控制了==操作符的比较结果,两个对象是否相等就是由我们来控制了,可哈希值却还是根据地址计算得到的。两个对象地址不同,哈希值不同,但是对象却可以相等、又可以不相等,这就导致了矛盾。因此在重写了__eq__、但是没有重写__hash__的情况下,其实例对象便不可哈希了。
但如果重写了__hash__,那么哈希值计算方式就不再通过地址计算了,因此此时是可以哈希的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class A : def __eq__ (self, other ): return True def __hash__ (self ): return 123 a1 = A() a2 = A() print ({a1: 1 , a2: 2 }) """ 此时我们看到字典里面只有一个元素了,因为我们说重写了__hash__方法之后,计算得到哈希值都是一样的 但是在没有重写__eq__的情况下,默认都是不相等的。如果哈希值一样,但是对象不相等,所以会重新映射。 而我们重写了__eq__,返回的结果是True,所以Python认为对象是相等的,由于key的不重复性,保留了后面的键值对 """
同样的,我们再来看一个Python中字典的例子
1 2 3 4 5 6 7 d = {1 : 123 } d[1.0 ] = 234 print (d) d[True ] = 345 print (d)
天哪,这是咋回事?因为整数在计算哈希的时候,得到结果就是其本身;而浮点数显然不是,但如果浮点数的小数点后面只有一个0,那么它和整数是等价的。因此两者的哈希值一样,而3和3.0在Python中也是相等的,因此它们视为同一个key,所以相当于是替换。同理True也是一样,我们说它bool继承自int,所以它等价于1,比如:9 + True = 10,因为True的哈希值和1也是一样的,而且也是相等的,索引d[True] = 345也是更新。
但是问题来了,值更新了我们可以理解,字典里面只有一个元素也可以理解,但是为什么key一直是1呢?理论上最终结果应该是True才对啊。
其实这算是Python偷了个懒吧(开个玩笑),因为key的哈希值是一样的,并且也相等,所以Python不会对key进行替换。从字典在设置元素的时候我们也知道,如果对key映射成索引之后发现哈希索引数组的此位置没有人用,那么就按照先来后到的顺序将”键值对”存在键值对数组中,再将其索引存在哈希索引数组的指定的槽中;如果有人用了,但是对应的key不想等,则重新映射找一个新位置;如果有人用了、并且相等,则说明是同一个key,那么把value换掉即可。所以在替换元素的整个过程中,根本没有涉及到对键的修改,因此上面那个例子的最终结果,value会变、但键依旧是1,而不是True。
理想的哈希函数必须保证哈希值尽量均匀地分布于整个哈希空间中,越是相近的值,其哈希值差别应该越大。
所以一个好的哈希函数对实现哈希表起到至关重要的作用。
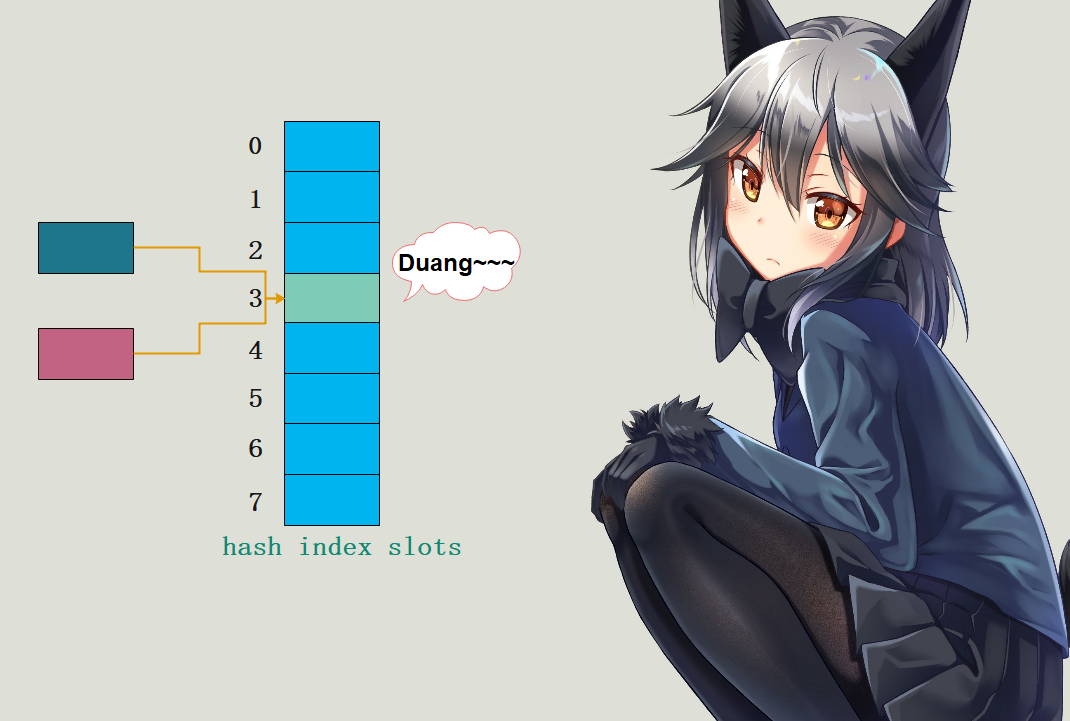
哈希冲突 一方面,不同的对象,哈希值有可能相同,另一方面,与哈希值空间相比,哈希表的槽位是非常有限的。因此,存在多个键被映射到哈希索引的同一槽位的可能性,这便是索引冲突
解决哈希冲突的常用方法有两种:
分离链接法(separate chaining)开放寻址法(open addressing)
Python采用的便是开放寻址法。
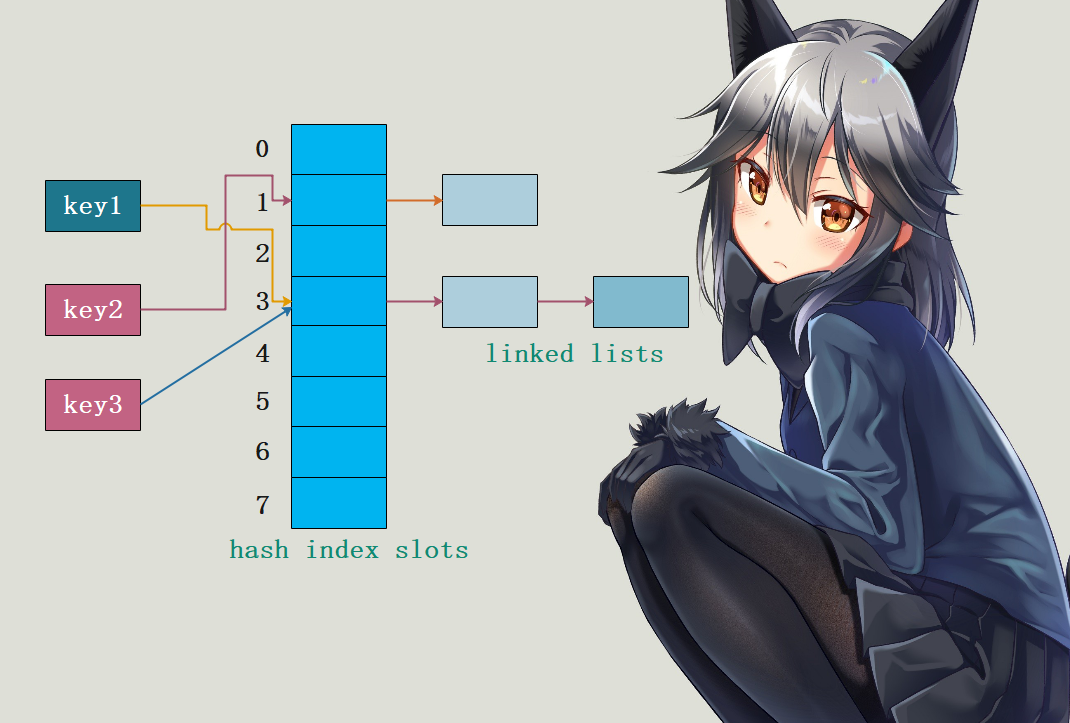
分离链接法 “分离链接法”为每个哈希槽维护一个链表,所有哈希到同一槽位的键保存到对应的链表中:
如上图所示,哈希索引数组的每一个槽都连接着一个链表,初始状态为空,哈希表某个槽位对应的”键”则保存在对应的链表中。例如:key1和key3都哈希到下标为3的槽位,依次保存在对应的链表中;key2被哈希到下标为1的槽位。
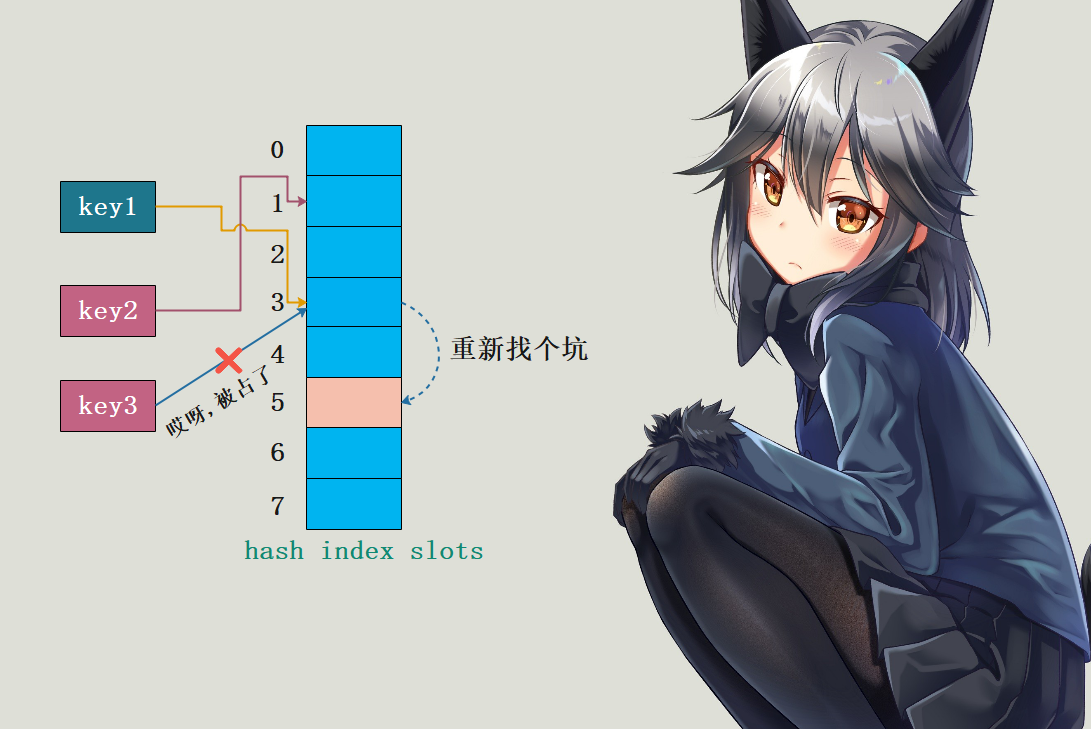
开放寻址法 Python依旧是将key映射成索引存在哈希索引数组的槽中,如果发现槽被占了,那么就尝试另一个。
*key3被哈希到槽位为3的时候,发现这个坑被key1给占了,所以只能重新找个坑了。但是为什么找到5呢?显然在解决哈希冲突的时候是有策略的,一般而言,如果是第i次尝试,那么会在首槽的基础上加上一个偏移量*d*i*
**。比如哈希之后索引是n,那么首槽就是n,然而n这个槽被占了,于是重新映射,重新映射之后的索引就是n + *d**i****,所以可以看出探测方式因函数*d*i*
而异。
而常见的探测函数有两种:
线性探测(linear probing)平方探测(quadratic probing)
*线性探测很好理解,*d*i*
*是一个线性函数,例如:*d*i*
= 2 * i
*哈希之后对应的槽是1,但是被占了,这个时候会在首槽的基础上加一个偏移量*d*i*
。第1次尝试,偏移量是2;第2次尝试,偏移量是4;第3次尝试,偏移量是6。然后再加上首槽的1,所以尝试之后的位置分别是3、5、7。
*平方探测也很好理解,*d*i*
*是一个平方函数,例如:*d*i* = *i*2
。同理如果是平方探测,首槽还是1,那么冲突之后重试的槽就是1 + 1、1 + 4、 1+ 9。
线性探测和平方探测很简单,平方探测似乎更胜一筹。因为如果哈希表存在局部热点,探测很难快速跳过热点区域,而平方探测则可以解决这一点。但是这两种方法其实都不够好–因为固定的探测序列加大了冲突的概率。
key1和key2都哈希到槽1,而由于探测序列是相同的,因此冲突概率很高。所以Python对此进行了优化,探测函数参考对象哈希值,生成不同的探测序列,进一步降低哈希冲突的可能性:
探测函数 Python为哈希表搜索提供了多种探测函数,lookdict、lookdict_unicode、lookdict_index,一般通用的是lookdict。lookdict_unicode是专门针对key为字符串的entry,lookdict_index针对key为整数的entry,可以把lookdict_unicode、lookdict_index看成lookdict的特殊实现,只不过key是整数和字符串的场景非常常见,因此为其单独实现了一个函数。
注意: 我们对字典无论是设置值还是获取值,都需要进行搜索。
我们这里重点看一下lookdict的函数实现,它位于 *Objects/dictobject.c* 源文件内。关键代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 static Py_ssize_t _Py_HOT_FUNCTIONlookdict (PyDictObject *mp, PyObject *key, Py_hash_t hash, PyObject **value_addr) { size_t i, mask, perturb; PyDictKeysObject *dk; PyDictKeyEntry *ep0; top: dk = mp->ma_keys; ep0 = DK_ENTRIES(dk); mask = DK_MASK(dk); perturb = hash; i = (size_t )hash & mask; for (;;) { Py_ssize_t ix = dk_get_index(dk, i); if (ix == DKIX_EMPTY) { *value_addr = NULL ; return ix; } if (ix >= 0 ) { PyDictKeyEntry *ep = &ep0[ix]; assert(ep->me_key != NULL ); if (ep->me_key == key) { *value_addr = ep->me_value; return ix; } if (ep->me_hash == hash) { PyObject *startkey = ep->me_key; Py_INCREF(startkey); int cmp = PyObject_RichCompareBool(startkey, key, Py_EQ); Py_DECREF(startkey); if (cmp < 0 ) { *value_addr = NULL ; return DKIX_ERROR; } if (dk == mp->ma_keys && ep->me_key == startkey) { if (cmp > 0 ) { *value_addr = ep->me_value; return ix; } } else { goto top; } } } perturb >>= PERTURB_SHIFT; i = (i*5 + perturb + 1 ) & mask; } Py_UNREACHABLE(); }
哈希攻击 *Python* 在 *3.3* 以前, 哈希算法只根据对象本身计算哈希值。因此,只要 *Python* 解释器相同,对象哈希值也肯定相同。
如果一些别有用心的人构造出大量哈希值相同的 *key* ,并提交给服务器,会发生什么事情呢?例如,向一台 *Python 2 Web* 服务器 *post* 一个 *json* 数据,数据包含大量的 *key* ,所有 *key* 的哈希值相同。这意味着哈希表将频繁发生哈希冲突,性能由 O(1)急剧下降为 O(N),这便是哈希攻击。
问题虽然很严重,但是好在应对方法比较简单–直接往对象身上撒把盐(salt)即可。具体做法如下:
1. Python解释器进程启动后,产生一个随机数作为盐2. 哈希函数同时参考对象本身以及随机数计算哈希值
这样一来,攻击者无法获悉解释器内部的随机数,也就无法构造出哈希值相同的对象了!*Python* 自 *3.3* 以后,哈希函数均采用加盐模式,杜绝了哈希攻击的可能性。*Python* 哈希算法在 *Python/pyhash.c* 源文件中实现,有兴趣的可以自己去了解一下。
以我当前使用的Python3.8为例,在执行hash("夏色祭")的时候,每次执行得到的结果都是不一样的。
元素删除 通过前面的学习,我们现在已经知道哈希表就是通过相应的函数将需要搜索的键映射为一个索引,最终通过索引去访问连续的内存区域。而对于哈希表这种数据结构,最终目的就是加速键的搜索过程。用于映射的函数就是哈希函数,映射之后的值就是哈希值,再由哈希值得到索引(不过为了方便,我们有时会将哈希函数映射的结果直接称为索引)。因此在哈希表的实现中,哈希函数的优劣将直接决定哈希表搜索效率的高低。
并且我们知道,当键值对数量越多,在映射成索引之后就越容易出现冲突。而我们之前说如果冲突了,就改变规则重新映射。事实上,Python也确实是这么做的,这种方法叫做开放寻址法。当发生冲突时,Python会通过一个二次探测函数f,计算下一个候选位置addr,如果可用就插入进去。如果不可用,会继续使用探测函数,直到找到一个可用的位置。通过多次使用探测函数f,从一个位置可以到达多个位置,我们认为这些位置就形成了一个”冲突探测链(探测序列)”。比如当我们插入一个key=”satori”的键值对,在a位置发现不行,又走b位置,发现也被人占了,于是到达c位置,发现没有key,于是就占了c这个位置。那么a -> b -> c便形成了一条冲突探测链,同理我们查找的时候也会按照这个顺序进行查找。
显然上面这些东西,现在理解起来已经没什么难度了,但是问题来了。
如果我此时把上面b位置的entry给删掉的话,会引发什么后果?首先我们知道,b位置上的key和我们指定的”satori”这个key的哈希值是一样的,不然它们也不会映射到同一个槽。当我们直接获取d[“satori”],肯定会先走a位置,发现有人但key又不是”satori”,于是重新映射;然后走到b,发现还不对,再走到c位置,发现key是”satori”,于是就把值取出来了。显然这符合我们的预期,但是,我要说但是了。
如果我们把b位置上的entry删掉呢?那么老规矩,映射成索引,先走到a位置发现坑被占;于是又走到b位置,结果发现居然没有内容,那么直接就报出了一个KeyError。所以继续寻找的前提是,这个地方要存储了entry,并且存在的entry -> me_key和指定的key不相同,但如果没有的话,就说明根本没有这个key,直接KeyError。然而”satori”这个key确实是存在的,因此发生这种情况我们就说探测链断裂。本来应该走到c的,但是由于b没有元素,因此探测函数在b处就停止了。
因此我们发现,当一个元素只要位于任何一条探测链当中,在删除元素时都不能真正意义上的删除,而是一种”伪删除”操作。
1 2 3 4 5 6 typedef struct { Py_hash_t me_hash; PyObject *me_key; PyObject *me_value; } PyDictKeyEntry;
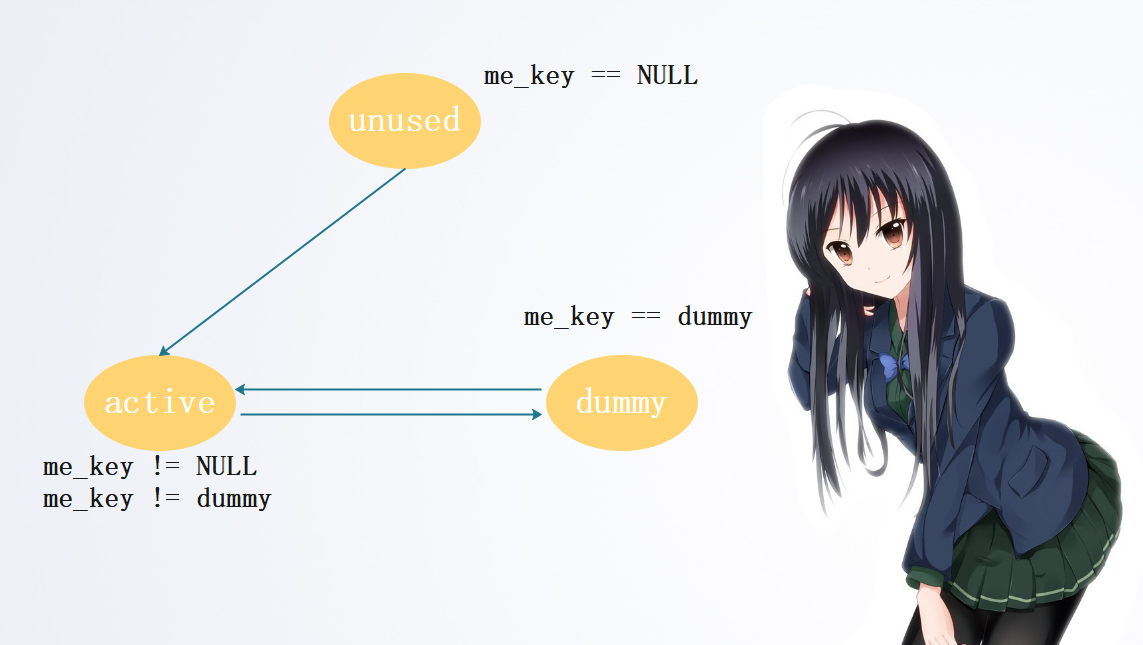
在Python中,当一个PyDictObject对象发生变化时,其中的entry会在三种不同的状态之间进行切换:unused态、active态、dummy态。
当一个entry的me_key和me_value都是NULL的时候,entry处于unused态。unused态表明该entry中并没有存储key、value,并且在此之前也没有存储过它们,每一个entry在初始化的时候都会处于这个状态。不过me_value的话,即使不是unused态也可能为NULL,更准确的说不管何时它都可能会NULL,这取决于到底是combined table、还是split table。我们说如果是分离表的话,value是不存在这里的,只有key存在这里,因此me_value永远是NULL。而如果是结合表,那么key和value都存在这里面。所以对于me_key,只可能在unused的时候才可能会NULL。当entry存储了key时,那么此时entry便从unused态变成了active态。当entry中的key(value)被删除后,状态便从active态变成dummy态。注意:这里是dummy,删除了并不代表就能够回到unused态,来存储其他key了。我们也说了,unused态是指当前没有、并且之前也没有存储过。key被删除后,会变成dummy,否则就会发生我们之前说的探测链断裂。至于这个dummy到底是啥,我们后面说。总是entry进入dummy态,就是我们刚才提到的伪删除技术。当Python沿着某条探测链搜索时,如果发现一个entry处于dummy态,就会明白虽然当前的entry是无效的,但是后面的entry可能是有效的,所以不会直接就停止搜索、报错,而是会继续搜索,这样就保证了探测链的连续性。至于报错,是在找到了unused状态的entry时才会报错,因为这里确实一直都没有存储过key,但是索引确实是这个位置,这说明当前指定的key就真的不存在哈希表中,此时才会报错。
unused态只能转换为active态;active态只能转换为dummy态;dummy态只能转化为active态。
哈希槽位状态常量在 *Objects/dict-common.h* 头文件中定义:
1 2 3 #define DKIX_EMPTY (-1) #define DKIX_DUMMY (-2) #define DKIX_ERROR (-3)
但是问题来了,如果一个entry被删除了,那么它就变成了dummy态。而我们说dummy态是可以转为active态的,要如何转化呢?如果新来了一个entry,这个entry在存储的时候发生冲突,那么会沿着冲突探测链查找,在查找的时候要是遇到了处于dummy态entry,那么原来处于dummy态的entry就会变成active态。
换句话说,对于处理dummy态的entry,Python压根不会主动理会,只是说这个元素被标记为删除了,但是内存还会继续占用。如果新来的entry,没有发生冲突,一上来就有位置可以存储,那么是不会理会dummy态entry的。只有当发生冲突的时候,正好撞上了dummy态的entry,才会将dummy态的entry给替换掉。此时entry就变成了active态,然后内部维护的就是新的键值对。
如果哈希表满了,那么就申请新的存储单元,然后将所有的active态的entry都搬过去,而处于dummy态的entry则直接丢弃。之所以可以丢弃,是因为dummy状态的entry存在是为了保证探测链不断裂,但是现在所有的active都拷贝到新的内存当中了,它们会形成一条新的探测链,因此也就不需要这些dummy态的entry了。至于到底是扩容、缩容、还是容量不变,取决于当前哈希表的entry个数。但是无论怎么样,当新的哈希表创建之后,便又有新的存储单元可用了。
PyDictObject的创建与维护 PyDictObject的创建 Python内部通过PyDict_New来创建一个新的dict对象。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 PyObject * PyDict_New (void ) { PyDictKeysObject *keys = new_keys_object(PyDict_MINSIZE); if (keys == NULL ) return NULL ; return new_dict(keys, NULL ); } static PyDictKeysObject *new_keys_object (Py_ssize_t size) { PyDictKeysObject *dk; Py_ssize_t es, usable; assert(size >= PyDict_MINSIZE); assert(IS_POWER_OF_2(size)); usable = USABLE_FRACTION(size); if (size <= 0xff ) { es = 1 ; } else if (size <= 0xffff ) { es = 2 ; } #if SIZEOF_VOID_P > 4 else if (size <= 0xffffffff ) { es = 4 ; } #endif else { es = sizeof (Py_ssize_t); } if (size == PyDict_MINSIZE && numfreekeys > 0 ) { dk = keys_free_list[--numfreekeys]; } else { dk = PyObject_MALLOC(sizeof (PyDictKeysObject) + es * size + sizeof (PyDictKeyEntry) * usable); if (dk == NULL ) { PyErr_NoMemory(); return NULL ; } } DK_DEBUG_INCREF dk->dk_refcnt = 1 ; dk->dk_size = size; dk->dk_usable = usable; dk->dk_lookup = lookdict_unicode_nodummy; dk->dk_nentries = 0 ; memset (&dk->dk_indices[0 ], 0xff , es * size); memset (DK_ENTRIES(dk), 0 , sizeof (PyDictKeyEntry) * usable); return dk; } static PyObject *new_dict (PyDictKeysObject *keys, PyObject **values) { PyDictObject *mp; assert(keys != NULL ); if (numfree) { mp = free_list[--numfree]; assert (mp != NULL ); assert (Py_TYPE(mp) == &PyDict_Type); _Py_NewReference((PyObject *)mp); } else { mp = PyObject_GC_New(PyDictObject, &PyDict_Type); if (mp == NULL ) { DK_DECREF(keys); free_values(values); return NULL ; } } mp->ma_keys = keys; mp->ma_values = values; mp->ma_used = 0 ; mp->ma_version_tag = DICT_NEXT_VERSION(); assert(_PyDict_CheckConsistency(mp)); return (PyObject *)mp; }
插入元素 我们对PyDictObject对象的操作都是建立在搜索的基础之上的,插入和删除也不例外。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 static int insertdict (PyDictObject *mp, PyObject *key, Py_hash_t hash, PyObject *value) { PyObject *old_value; PyDictKeyEntry *ep; Py_INCREF(key); Py_INCREF(value); if (mp->ma_values != NULL && !PyUnicode_CheckExact(key)) { if (insertion_resize(mp) < 0 ) goto Fail; } Py_ssize_t ix = mp->ma_keys->dk_lookup(mp, key, hash, &old_value); if (ix == DKIX_ERROR) goto Fail; assert(PyUnicode_CheckExact(key) || mp->ma_keys->dk_lookup == lookdict); MAINTAIN_TRACKING(mp, key, value); if (_PyDict_HasSplitTable(mp) && ((ix >= 0 && old_value == NULL && mp->ma_used != ix) || (ix == DKIX_EMPTY && mp->ma_used != mp->ma_keys->dk_nentries))) { if (insertion_resize(mp) < 0 ) goto Fail; ix = DKIX_EMPTY; } if (ix == DKIX_EMPTY) { assert(old_value == NULL ); if (mp->ma_keys->dk_usable <= 0 ) { if (insertion_resize(mp) < 0 ) goto Fail; } Py_ssize_t hashpos = find_empty_slot(mp->ma_keys, hash); ep = &DK_ENTRIES(mp->ma_keys)[mp->ma_keys->dk_nentries]; dk_set_index(mp->ma_keys, hashpos, mp->ma_keys->dk_nentries); ep->me_key = key; ep->me_hash = hash; if (mp->ma_values) { assert (mp->ma_values[mp->ma_keys->dk_nentries] == NULL ); mp->ma_values[mp->ma_keys->dk_nentries] = value; } else { ep->me_value = value; } mp->ma_used++; mp->ma_version_tag = DICT_NEXT_VERSION(); mp->ma_keys->dk_usable--; mp->ma_keys->dk_nentries++; assert(mp->ma_keys->dk_usable >= 0 ); assert(_PyDict_CheckConsistency(mp)); return 0 ; } if (_PyDict_HasSplitTable(mp)) { mp->ma_values[ix] = value; if (old_value == NULL ) { assert(ix == mp->ma_used); mp->ma_used++; } } else { assert(old_value != NULL ); DK_ENTRIES(mp->ma_keys)[ix].me_value = value; } mp->ma_version_tag = DICT_NEXT_VERSION(); Py_XDECREF(old_value); assert(_PyDict_CheckConsistency(mp)); Py_DECREF(key); return 0 ; Fail: Py_DECREF(value); Py_DECREF(key); return -1 ; }
以上是插入元素,但我们看到无论是插入元素、还是设置元素,insertdict都是可以胜任。但是请注意一下参数,有一个hash参数,这个hash是从什么地方获取的呢?答案是,在调用这个insertdict之前其实会首先调用PyDict_SetItem
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 int PyDict_SetItem (PyObject *op, PyObject *key, PyObject *value) { PyDictObject *mp; Py_hash_t hash; if (!PyDict_Check(op)) { PyErr_BadInternalCall(); return -1 ; } assert(key); assert(value); mp = (PyDictObject *)op; if (!PyUnicode_CheckExact(key) || (hash = ((PyASCIIObject *) key)->hash) == -1 ) { hash = PyObject_Hash(key); if (hash == -1 ) return -1 ; } return insertdict(mp, key, hash, value); }
我们说如果entry个数达到容量的三分之二,那么会调整容量,如何调整呢?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 #define GROWTH_RATE(d) ((d)->ma_used*3) static int insertion_resize (PyDictObject *mp) { return dictresize(mp, GROWTH_RATE(mp)); } static int dictresize (PyDictObject *mp, Py_ssize_t minsize) { Py_ssize_t newsize, numentries; PyDictKeysObject *oldkeys; PyObject **oldvalues; PyDictKeyEntry *oldentries, *newentries; for (newsize = PyDict_MINSIZE; newsize < minsize && newsize > 0 ; newsize <<= 1 ) ; if (newsize <= 0 ) { PyErr_NoMemory(); return -1 ; } oldkeys = mp->ma_keys; mp->ma_keys = new_keys_object(newsize); if (mp->ma_keys == NULL ) { mp->ma_keys = oldkeys; return -1 ; } assert(mp->ma_keys->dk_usable >= mp->ma_used); if (oldkeys->dk_lookup == lookdict) mp->ma_keys->dk_lookup = lookdict; numentries = mp->ma_used; oldentries = DK_ENTRIES(oldkeys); newentries = DK_ENTRIES(mp->ma_keys); oldvalues = mp->ma_values; if (oldvalues != NULL ) { for (Py_ssize_t i = 0 ; i < numentries; i++) { assert(oldvalues[i] != NULL ); PyDictKeyEntry *ep = &oldentries[i]; PyObject *key = ep->me_key; Py_INCREF(key); newentries[i].me_key = key; newentries[i].me_hash = ep->me_hash; newentries[i].me_value = oldvalues[i]; } DK_DECREF(oldkeys); mp->ma_values = NULL ; if (oldvalues != empty_values) { free_values(oldvalues); } } else { if (oldkeys->dk_nentries == numentries) { memcpy (newentries, oldentries, numentries * sizeof (PyDictKeyEntry)); } else { PyDictKeyEntry *ep = oldentries; for (Py_ssize_t i = 0 ; i < numentries; i++) { while (ep->me_value == NULL ) ep++; newentries[i] = *ep++; } } assert(oldkeys->dk_lookup != lookdict_split); assert(oldkeys->dk_refcnt == 1 ); if (oldkeys->dk_size == PyDict_MINSIZE && numfreekeys < PyDict_MAXFREELIST) { DK_DEBUG_DECREF keys_free_list[numfreekeys++] = oldkeys; } else { DK_DEBUG_DECREF PyObject_FREE(oldkeys); } } build_indices(mp->ma_keys, newentries, numentries); mp->ma_keys->dk_usable -= numentries; mp->ma_keys->dk_nentries = numentries; return 0 ; }
我们再来看一下改变dict内存空间的一些动作:
首先要确定table的大小,很显然这个大小一定要大于minsize,这个minsize通过我们已经看到了,是通过宏定义的,是已用entry的3倍根据新的table,重新申请内存将原来的处于active状态的entry拷贝到新的内存当中,而对于处于dummy状态的entry则直接丢弃。可以丢弃的原因我们上面也说过了。主要是因为哈希表扩容了,会申请的一个新的数组,直接将原来的active态的entry组成一条新的探测链即可,因此也就不需要这些dummy态的entry了
删除元素 插入元素(设置元素)如果明白了,删除元素我觉得都可以不需要说了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 int PyDict_DelItem (PyObject *op, PyObject *key) { Py_hash_t hash; assert(key); if (!PyUnicode_CheckExact(key) || (hash = ((PyASCIIObject *) key)->hash) == -1 ) { hash = PyObject_Hash(key); if (hash == -1 ) return -1 ; } return _PyDict_DelItem_KnownHash(op, key, hash); } int _PyDict_DelItem_KnownHash(PyObject *op, PyObject *key, Py_hash_t hash) { Py_ssize_t ix; PyDictObject *mp; PyObject *old_value; if (!PyDict_Check(op)) { PyErr_BadInternalCall(); return -1 ; } assert(key); assert(hash != -1 ); mp = (PyDictObject *)op; ix = (mp->ma_keys->dk_lookup)(mp, key, hash, &old_value); if (ix == DKIX_ERROR) return -1 ; if (ix == DKIX_EMPTY || old_value == NULL ) { _PyErr_SetKeyError(key); return -1 ; } if (_PyDict_HasSplitTable(mp)) { if (dictresize(mp, DK_SIZE(mp->ma_keys))) { return -1 ; } ix = (mp->ma_keys->dk_lookup)(mp, key, hash, &old_value); assert(ix >= 0 ); } return delitem_common(mp, hash, ix, old_value); } static int delitem_common (PyDictObject *mp, Py_hash_t hash, Py_ssize_t ix, PyObject *old_value) { PyObject *old_key; PyDictKeyEntry *ep; Py_ssize_t hashpos = lookdict_index(mp->ma_keys, hash, ix); assert(hashpos >= 0 ); mp->ma_used--; mp->ma_version_tag = DICT_NEXT_VERSION(); ep = &DK_ENTRIES(mp->ma_keys)[ix]; dk_set_index(mp->ma_keys, hashpos, DKIX_DUMMY); ENSURE_ALLOWS_DELETIONS(mp); old_key = ep->me_key; ep->me_key = NULL ; ep->me_value = NULL ; Py_DECREF(old_key); Py_DECREF(old_value); assert(_PyDict_CheckConsistency(mp)); return 0 ; }
流程非常清晰,也很简单。先使用PyDict_DelItem计算hash值,再使用_PyDict_DelItem_KnownHash计算出索引,最后使用delitem_common获取相应的entry,删除维护的元素,并将entry从active态设置为dummy态,同时还会调整ma_used(已用entry)的数量
PyDictObject缓存池 从介绍PyLongObject的小整数对象池的时候,我们就说过,不同的对象都有自己的缓存池,比如列表,当然字典也不例外。
1 2 3 4 5 #ifndef PyDict_MAXFREELIST #define PyDict_MAXFREELIST 80 #endif static PyDictObject *free_list[PyDict_MAXFREELIST];static int numfree = 0 ;
PyDictObject的缓存池机制其实和PyListObject的缓存池是类似的,开始时,这个缓存池什么也没有,直到第一个PyDictObject对象被销毁时,这个PyDictObject缓冲池里面才开始接纳被缓冲的PyDictObject对象。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 static void dict_dealloc (PyDictObject *mp) { PyObject **values = mp->ma_values; PyDictKeysObject *keys = mp->ma_keys; Py_ssize_t i, n; PyObject_GC_UnTrack(mp); Py_TRASHCAN_SAFE_BEGIN(mp) if (values != NULL ) { if (values != empty_values) { for (i = 0 , n = mp->ma_keys->dk_nentries; i < n; i++) { Py_XDECREF(values[i]); } free_values(values); } DK_DECREF(keys); } else if (keys != NULL ) { assert(keys->dk_refcnt == 1 ); DK_DECREF(keys); } if (numfree < PyDict_MAXFREELIST && Py_TYPE(mp) == &PyDict_Type) free_list[numfree++] = mp; else Py_TYPE(mp)->tp_free((PyObject *)mp); Py_TRASHCAN_SAFE_END(mp) }
和PyListObject对象的缓冲池机制一样,缓冲池中只保留了PyDictObject对象。如果维护的是从系统堆中申请的内存空间,那么Python将释放这份内存空间,归还给系统堆。如果不是,那么仅仅只需要调整维护的对象的引用计数即可。
其实在创建一个PyDictObject对象时,如果缓冲池中有可用的对象,也会直接从缓冲池中取,而不需要再重新创建。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 static PyObject *new_dict (PyDictKeysObject *keys, PyObject **values) { PyDictObject *mp; assert(keys != NULL ); if (numfree) { mp = free_list[--numfree]; assert (mp != NULL ); assert (Py_TYPE(mp) == &PyDict_Type); _Py_NewReference((PyObject *)mp); } ... ... ...
关于字典的剖析我们就说到这里,其实内容还是很多的,尤其是哈希表背后的一些原理,值得好好体会一下。
PySetObject 由于集合和字典在底层使用的都是哈希表,所以我们放在一起说吧。
既然集合也使用了哈希表,那么它的查询性能也是很高的。由于哈希表我们已经说了很多了,所以我们下面就直接来看集合的底层结构吧。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 typedef struct { PyObject *key; Py_hash_t hash; } setentry; typedef struct { PyObject_HEAD Py_ssize_t fill; Py_ssize_t used; Py_ssize_t mask; setentry *table; Py_hash_t hash; Py_ssize_t finger; setentry smalltable[PySet_MINSIZE]; PyObject *weakreflist; } PySetObject;
PySetObject对象的创建 创建一个PySetObject对象可以使用PySet_New方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 PyObject * PySet_New (PyObject *iterable) { return make_new_set(&PySet_Type, iterable); } static PyObject *make_new_set (PyTypeObject *type, PyObject *iterable) { PySetObject *so; so = (PySetObject *)type->tp_alloc(type, 0 ); if (so == NULL ) return NULL ; so->fill = 0 ; so->used = 0 ; so->mask = PySet_MINSIZE - 1 ; so->table = so->smalltable; so->hash = -1 ; so->finger = 0 ; so->weakreflist = NULL ; if (iterable != NULL ) { if (set_update_internal(so, iterable)) { Py_DECREF(so); return NULL ; } } return (PyObject *)so; }
从以上步骤可以看出,初始化一个PySetObject对象主要初始化其内部的数据结构。
插入元素 插入元素,会调用PySet_Add:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 int PySet_Add (PyObject *anyset, PyObject *key) { if (!PySet_Check(anyset) && (!PyFrozenSet_Check(anyset) || Py_REFCNT(anyset) != 1 )) { PyErr_BadInternalCall(); return -1 ; } return set_add_key((PySetObject *)anyset, key); } static int set_add_key (PySetObject *so, PyObject *key) { Py_hash_t hash; if (!PyUnicode_CheckExact(key) || (hash = ((PyASCIIObject *) key)->hash) == -1 ) { hash = PyObject_Hash(key); if (hash == -1 ) return -1 ; } return set_add_entry(so, key, hash); } static int set_add_entry (PySetObject *so, PyObject *key, Py_hash_t hash) { setentry *table; setentry *freeslot; setentry *entry; size_t perturb; size_t mask; size_t i; size_t j; int cmp; Py_INCREF(key); restart: mask = so->mask; i = (size_t )hash & mask; entry = &so->table[i]; if (entry->key == NULL ) goto found_unused; freeslot = NULL ; perturb = hash; while (1 ) { if (entry->hash == hash) { PyObject *startkey = entry->key; assert(startkey != dummy); if (startkey == key) goto found_active; if (PyUnicode_CheckExact(startkey) && PyUnicode_CheckExact(key) && _PyUnicode_EQ(startkey, key)) goto found_active; table = so->table; Py_INCREF(startkey); cmp = PyObject_RichCompareBool(startkey, key, Py_EQ); Py_DECREF(startkey); if (cmp > 0 ) goto found_active; if (cmp < 0 ) goto comparison_error; if (table != so->table || entry->key != startkey) goto restart; mask = so->mask; } else if (entry->hash == -1 ) freeslot = entry; if (i + LINEAR_PROBES <= mask) { for (j = 0 ; j < LINEAR_PROBES ; j++) { entry++; if (entry->hash == 0 && entry->key == NULL ) goto found_unused_or_dummy; if (entry->hash == hash) { PyObject *startkey = entry->key; assert(startkey != dummy); if (startkey == key) goto found_active; if (PyUnicode_CheckExact(startkey) && PyUnicode_CheckExact(key) && _PyUnicode_EQ(startkey, key)) goto found_active; table = so->table; Py_INCREF(startkey); cmp = PyObject_RichCompareBool(startkey, key, Py_EQ); Py_DECREF(startkey); if (cmp > 0 ) goto found_active; if (cmp < 0 ) goto comparison_error; if (table != so->table || entry->key != startkey) goto restart; mask = so->mask; } else if (entry->hash == -1 ) freeslot = entry; } } perturb >>= PERTURB_SHIFT; i = (i * 5 + 1 + perturb) & mask; entry = &so->table[i]; if (entry->key == NULL ) goto found_unused_or_dummy; } found_unused_or_dummy: if (freeslot == NULL ) goto found_unused; so->used++; freeslot->key = key; freeslot->hash = hash; return 0 ; found_unused: so->fill++; so->used++; entry->key = key; entry->hash = hash; if ((size_t )so->fill*5 < mask*3 ) return 0 ; return set_table_resize(so, so->used>50000 ? so->used*2 : so->used*4 ); found_active: Py_DECREF(key); return 0 ; comparison_error: Py_DECREF(key); return -1 ; }
总结一下流程就是:
传入hash值,计算出索引值,通过索引值找到对应的entry如果entry->key=NULL,那么将hash和key存到对应的entry如果有key,但是值相同,则不插入,直接减少引入计数。因为不是字典,不存在更新一说如果有key,但是值不相同。那么从该索引往后的9个entry(i + 9 <= mask),如果存在key为NULL的entry,那么设置进去。如果以上条件都不满足,那么改变策略重新计算索引值,直到找到一个满足key为NULL的entry判断容量问题,如果active态+dummy态的entry个数不小于3/5 * mask,那么扩容,扩容的规则是active态的entry个数是否大于50000,是的话就二倍扩容,否则4倍扩容。
PySetObject扩容 我们之前说PySetObject会改变容量,那么它是如何改变的呢?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 static int set_table_resize (PySetObject *so, Py_ssize_t minused) { setentry *oldtable, *newtable, *entry; Py_ssize_t oldmask = so->mask; size_t newmask; int is_oldtable_malloced; setentry small_copy[PySet_MINSIZE]; assert(minused >= 0 ); size_t newsize = PySet_MINSIZE; while (newsize <= (size_t )minused) { newsize <<= 1 ; } oldtable = so->table; assert(oldtable != NULL ); is_oldtable_malloced = oldtable != so->smalltable; if (newsize == PySet_MINSIZE) { newtable = so->smalltable; if (newtable == oldtable) { if (so->fill == so->used) { return 0 ; } assert(so->fill > so->used); memcpy (small_copy, oldtable, sizeof (small_copy)); oldtable = small_copy; } } else { newtable = PyMem_NEW(setentry, newsize); if (newtable == NULL ) { PyErr_NoMemory(); return -1 ; } } assert(newtable != oldtable); memset (newtable, 0 , sizeof (setentry) * newsize); so->mask = newsize - 1 ; so->table = newtable; newmask = (size_t )so->mask; if (so->fill == so->used) { for (entry = oldtable; entry <= oldtable + oldmask; entry++) { if (entry->key != NULL ) { set_insert_clean(newtable, newmask, entry->key, entry->hash); } } } else { so->fill = so->used; for (entry = oldtable; entry <= oldtable + oldmask; entry++) { if (entry->key != NULL && entry->key != dummy) { set_insert_clean(newtable, newmask, entry->key, entry->hash); } } } if (is_oldtable_malloced) PyMem_DEL(oldtable); return 0 ; } static void set_insert_clean (setentry *table, size_t mask, PyObject *key, Py_hash_t hash) { setentry *entry; size_t perturb = hash; size_t i = (size_t )hash & mask; size_t j; while (1 ) { entry = &table[i]; if (entry->key == NULL ) goto found_null; if (i + LINEAR_PROBES <= mask) { for (j = 0 ; j < LINEAR_PROBES; j++) { entry++; if (entry->key == NULL ) goto found_null; } } perturb >>= PERTURB_SHIFT; i = (i * 5 + 1 + perturb) & mask; } found_null: entry->key = key; entry->hash = hash; }
删除元素 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 static PyObject *set_remove (PySetObject *so, PyObject *key) { PyObject *tmpkey; int rv; rv = set_discard_key(so, key); if (rv < 0 ) { if (!PySet_Check(key) || !PyErr_ExceptionMatches(PyExc_TypeError)) return NULL ; PyErr_Clear(); tmpkey = make_new_set(&PyFrozenSet_Type, key); if (tmpkey == NULL ) return NULL ; rv = set_discard_key(so, tmpkey); Py_DECREF(tmpkey); if (rv < 0 ) return NULL ; } if (rv == DISCARD_NOTFOUND) { _PyErr_SetKeyError(key); return NULL ; } Py_RETURN_NONE; } static int set_discard_key (PySetObject *so, PyObject *key) { Py_hash_t hash; if (!PyUnicode_CheckExact(key) || (hash = ((PyASCIIObject *) key)->hash) == -1 ) { hash = PyObject_Hash(key); if (hash == -1 ) return -1 ; } return set_discard_entry(so, key, hash); } static int set_discard_entry (PySetObject *so, PyObject *key, Py_hash_t hash) { setentry *entry; PyObject *old_key; entry = set_lookkey(so, key, hash); if (entry == NULL ) return -1 ; if (entry->key == NULL ) return DISCARD_NOTFOUND; old_key = entry->key; entry->key = dummy; entry->hash = -1 ; so->used--; Py_DECREF(old_key); return DISCARD_FOUND; }
可以看到集合添加、删除元素和字典是有些相似的,毕竟底层都是使用了hash表嘛。
集合的运算(交集) 在python中使用集合的时候,可以取两个集合的交集、并集、差集、对称差集等等,这里介绍一下交集,其余的可以自行看源码研究(Objects/setobject.c)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 static PyObject *set_intersection (PySetObject *so, PyObject *other) { PySetObject *result; PyObject *key, *it, *tmp; Py_hash_t hash; int rv; if ((PyObject *)so == other) return set_copy(so); result = (PySetObject *)make_new_set_basetype(Py_TYPE(so), NULL ); if (result == NULL ) return NULL ; if (PyAnySet_Check(other)) { Py_ssize_t pos = 0 ; setentry *entry; if (PySet_GET_SIZE(other) > PySet_GET_SIZE(so)) { tmp = (PyObject *)so; so = (PySetObject *)other; other = tmp; } while (set_next((PySetObject *)other, &pos, &entry)) { key = entry->key; hash = entry->hash; rv = set_contains_entry(so, key, hash); if (rv < 0 ) { Py_DECREF(result); return NULL ; } if (rv) { if (set_add_entry(result, key, hash)) { Py_DECREF(result); return NULL ; } } } return (PyObject *)result; } it = PyObject_GetIter(other); if (it == NULL ) { Py_DECREF(result); return NULL ; } while ((key = PyIter_Next(it)) != NULL ) { hash = PyObject_Hash(key); if (hash == -1 ) goto error; rv = set_contains_entry(so, key, hash); if (rv < 0 ) goto error; if (rv) { if (set_add_entry(result, key, hash)) goto error; } Py_DECREF(key); } Py_DECREF(it); if (PyErr_Occurred()) { Py_DECREF(result); return NULL ; } return (PyObject *)result; error: Py_DECREF(it); Py_DECREF(result); Py_DECREF(key); return NULL ; }
集合小结 可以看到,剖析集合的时候话很少。主要是有了剖析字典的经验,因此再剖析集合的时候就很简单了。并且在Python中还有一个frozenset,就是不可变的集合。但是不像列表和元组,元组还是有很多特殊的,并不单单只是不可变的列表,从具有自己独自的结构体就能看出来。而frozenset对象和set对象都是一个结构体,只有一个PySetObject,没有PyFrozenSetObject。我们在看PySetObject的时候,发现里面有一个hash成员,如果是frozenset的话,那么hash值是不为-1的,因为它不可以添加、删除元素,是不可变对象。由于比较相似,因此frozenset就不再说了,可以自己源码中研究,位置还是Object/setobject.c。