12-剖析字节码指令,从不一样的角度观测Python源代码的执行过程 上一章中,我们通过_PyEval_EvalFrameDefault看到了Python虚拟机的整体框架,那么这一章我们将深入到_PyEval_EvalFrameDefault的各个细节当中,深入剖析Python的虚拟机,在本章中我们将剖析Python虚拟机是如何完成对一般表达式的执行的。这里的一般表达式包括最基本的对象创建语句、打印语句等等。至于if、while等表达式,我们将其归类于控制流语句,对于Python中控制流的剖析,我们将留到下一章。
简单回顾 这里我们通过问与答的方式,简单回顾一下前面的内容。
请问 Python 程序是怎么运行的?是编译成机器码后在执行的吗?
不少初学者对 *Python* 存在误解,以为它是类似 *Shell* 的解释性脚本语言,其实并不是。虽然执行 *Python* 程序的 称为 *Python* 解释器,但它其实包含一个 “编译器” 和一个 “虚拟机”。
当我们在命令行敲下 python xxxx.py 时,*python* 解释器中的编译器首先登场,将 *Python* 代码编译成 *PyCodeObject* 对象。*PyCodeObject* 对象包含 字节码 以及执行字节码所需的 名字 以及 常量。
当编译器完成编译动作后,接力棒便传给 虚拟机。虚拟机 维护执行上下文,逐行执行 字节码 指令。执行上下文中最核心的 名字空间,便是由 虚拟机 维护的。
因此,*Python* 程序的执行原理其实更像 *Java*,可以用两个词来概括—— 虚拟机和字节码。不同的是,*Java* 编译器 *javac* 与 虚拟机 *java* 是分离的,而 *Python* 将两者整合成一个 *python* 命令。
pyc 文件保存什么东西,有什么作用?
Python 程序执行时需要先由 编译器 编译成 *PyCodeObject* 对象,然后再交由 虚拟机 来执行。不管程序执行多少次,只要源码没有变化,编译后得到的 *PyCodeObject* 对象就肯定是一样的。因此,*Python* 将 *PyCodeObject* 对象序列化并保存到 *pyc* 文件中。当程序再次执行时,*Python* 直接从 *pyc* 文件中加载代码对象,省去编译环节。当然了,当 *py* 源码文件改动后,*pyc* 文件便失效了,这时 *Python* 必须重新编译 *py* 文件。
如何查看 Python 程序的字节码?
Python 标准库中的 *dis* 模块,可以对 *PyCodeObject* 对象 以及 函数进行反编译,并显示其中的 字节码。
其实dis.dis最终反编译的就是字节码,只不过我们可以传入一个函数,会自动获取其字节码。比如:函数foo,我们可以dis.dis(foo)、dis.dis(foo.code )、dis.dis(foo.code .co_code),最终都是对字节码进行反编译的。
在这里我们说几个常见的字节码指令,因为它太常见了以至于我们这里必须要提一下,然后再举例说明。
LOAD_CONST: 加载一个常量LOAD_FAST: 在局部作用域中(比如函数)加载一个当前作用域的局部变量LOAD_GLOBAL: 在局部作用域(比如函数)中加载一个全局变量或者内置变量LOAD_NAME: 在全局作用域中加载一个全局变量或者内置变量STORE_FAST: 在局部作用域中定义一个局部变量, 来建立和某个对象之间的映射关系STORE_GLOBAL: 在局部作用域中定义一个global关键字声明的全局变量, 来建立和某个对象之间的映射关系STORE_NAME: 在全局作用域中定义一个全局变量, 来建立和某个对象之间的映射关系
然后下面的我们就来看看这些指令:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 name = "夏色祭" def foo (): gender = "female" print (gender) print (name) import disdis.dis(foo) 9 0 LOAD_CONST 1 ('female' ) 2 STORE_FAST 0 (gender) 10 4 LOAD_GLOBAL 0 (print ) 6 LOAD_FAST 0 (gender) 8 CALL_FUNCTION 1 10 POP_TOP 11 12 LOAD_GLOBAL 0 (print ) 14 LOAD_GLOBAL 1 (name) 16 CALL_FUNCTION 1 18 POP_TOP 20 LOAD_CONST 0 (None ) 22 RETURN_VALUE
0 LOAD_CONST 1 ('female'): 加载常量"female", 所以是LOAD_CONST2 STORE_FAST 0 (gender): 在局部作用域中定义一个局部变量gender, 所以是STORE_FAST4 LOAD_GLOBAL 0 (print): 在局部作用域中加载一个内置变量print, 所以是LOAD_GLOBAL6 LOAD_FAST 0 (gender): 在局部作用域中加载一个局部变量gender, 所以是LOAD_FAST14 LOAD_GLOBAL 1 (name): 在局部作用域中加载一个全局变量name, 所以是LOAD_GLOBAL
1 2 3 4 5 6 7 8 9 10 11 12 13 name = "夏色祭" def foo (): global name name = "马自立三舅" import disdis.dis(foo) 10 0 LOAD_CONST 1 ('马自立三舅' ) 2 STORE_GLOBAL 0 (name) 4 LOAD_CONST 0 (None ) 6 RETURN_VALUE
0 LOAD_CONST 1 ('马自立三舅'): 加载一个字符串常量, 所以是LOAD_CONST2 STORE_GLOBAL 0 (name): 在局部作用域中定义一个被global关键字声明的全局变量, 所以是STORE_GLOBAL
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 s = """ name = "夏色祭" print(name) """ import disdis.dis(compile (s, "xxx" , "exec" )) 2 0 LOAD_CONST 0 ('夏色祭' ) 2 STORE_NAME 0 (name) 3 4 LOAD_NAME 1 (print ) 6 LOAD_NAME 0 (name) 8 CALL_FUNCTION 1 10 POP_TOP 12 LOAD_CONST 1 (None ) 14 RETURN_VALUE
0 LOAD_CONST 0 ('夏色祭'): 加载一个字符串常量, 所以是LOAD_CONST2 STORE_NAME 0 (name): 在全局作用域中定义一个全局变量name, 所以是STORE_NAME4 LOAD_NAME 1 (print): 在全局作用域中加载一个内置变量print, 所以是LOAD_NAME6 LOAD_NAME 0 (name): 在全局作用域中加载一个全局变量name, 所以是LOAD_NAME
因此LOAD_CONST、LOAD_FAST、LOAD_GLOBAL、LOAD_NAME、STORE_FAST、STORE_GLOBAL、STORE_NAME它们是和加载常量、变量和定义变量之间有关的,可以说常见的不能再常见了,你写的任何代码在反编译之后都少不了它们的身影,至少会出现一个。因此有必要提前解释一下,它们分别代表的含义是什么。
Python 中变量交换有两种不同的写法,示例如下。这两种写法有什么区别吗?那种写法更好?
1 2 3 4 5 6 7 a, b = b, a tmp = a a = b b = tmp
这两种写法都能实现变量交换,表面上看第一种写法更加简洁明了,似乎更优。那么,在优雅的外表下是否隐藏着不为人知的性能缺陷呢?想要找到答案,唯一的途径是研究字节码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 # 写法一 1 0 LOAD_NAME 0 (b) 2 LOAD_NAME 1 (a) 4 ROT_TWO 6 STORE_NAME 1 (a) 8 STORE_NAME 0 (b) # 写法二 1 0 LOAD_NAME 0 (a) 2 STORE_NAME 1 (tmp) 2 4 LOAD_NAME 2 (b) 6 STORE_NAME 0 (a) 3 8 LOAD_NAME 1 (tmp) 10 STORE_NAME 2 (b)
从字节码上看,第一种写法需要的指令条目要少一些:先将两个变量依次加载到栈,然后一条 *ROT_TWO* 指令将栈中的两个变量交换,最后再将变量依次写回去。注意到,变量加载的顺序与 *=* 右边一致,写回顺序与 *=* 左边一致。
1 2 3 4 5 6 7 8 9 10 11 12 case TARGET (ROT_TWO) : { PyObject *top = TOP(); PyObject *second = SECOND(); SET_TOP(second); SET_SECOND(top); FAST_DISPATCH(); }
而且,*ROT_TWO* 指令只是将栈顶两个元素交换位置,执行起来比 *LOAD_NAME* 和 *STORE_NAME* 都要快。
至此,我们可以得到结论了——第一种变量交换写法更优:
代码简洁明了, 不拖泥带水不需要辅助变量 tmp, 节约内存ROT_TWO 指令比 LOAD_NAME 和 STORE_NAME 组成的指令对更有优势,执行效率更高
请解释 is 和 == 这两个操作的区别。
我们知道 *is* 是 对象标识符 ( *object identity* ),判断两个引用是不是引用的同一个对象,等价于 *id(a) == id(b)* ;而 *==* 操作符判断两个引用所引用的对象是不是相等,等价于调用魔法方法 *a.eq (b)* 。因此,*==* 操作符可以通过 *eq * 魔法方法进行覆写( *overriding* ),而 *is* 操作符无法覆写。
从字节码上看,这两个语句也很接近,区别仅在比较指令 *COMPARE_OP* 的操作数上:
1 2 3 4 5 6 7 8 9 10 11 # a is b 1 0 LOAD_NAME 0 (a ) 2 LOAD_NAME 1 (b ) 4 COMPARE_OP 8 (is ) 6 POP_TOP # a == b 1 0 LOAD_NAME 0 (a ) 2 LOAD_NAME 1 (b ) 4 COMPARE_OP 2 (== ) 6 POP_TOP
*COMPARE_OP* 指令处理逻辑在 *Python/ceval.c* 源文件中实现,关键函数是 *cmp_outcome*:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 static PyObject *cmp_outcome (int op, PyObject *v, PyObject *w) { int res = 0 ; switch (op) { case PyCmp_IS: res = (v == w); break ; default : return PyObject_RichCompare(v, w, op); } v = res ? Py_True : Py_False; Py_INCREF(v); return v; }
举个栗子:
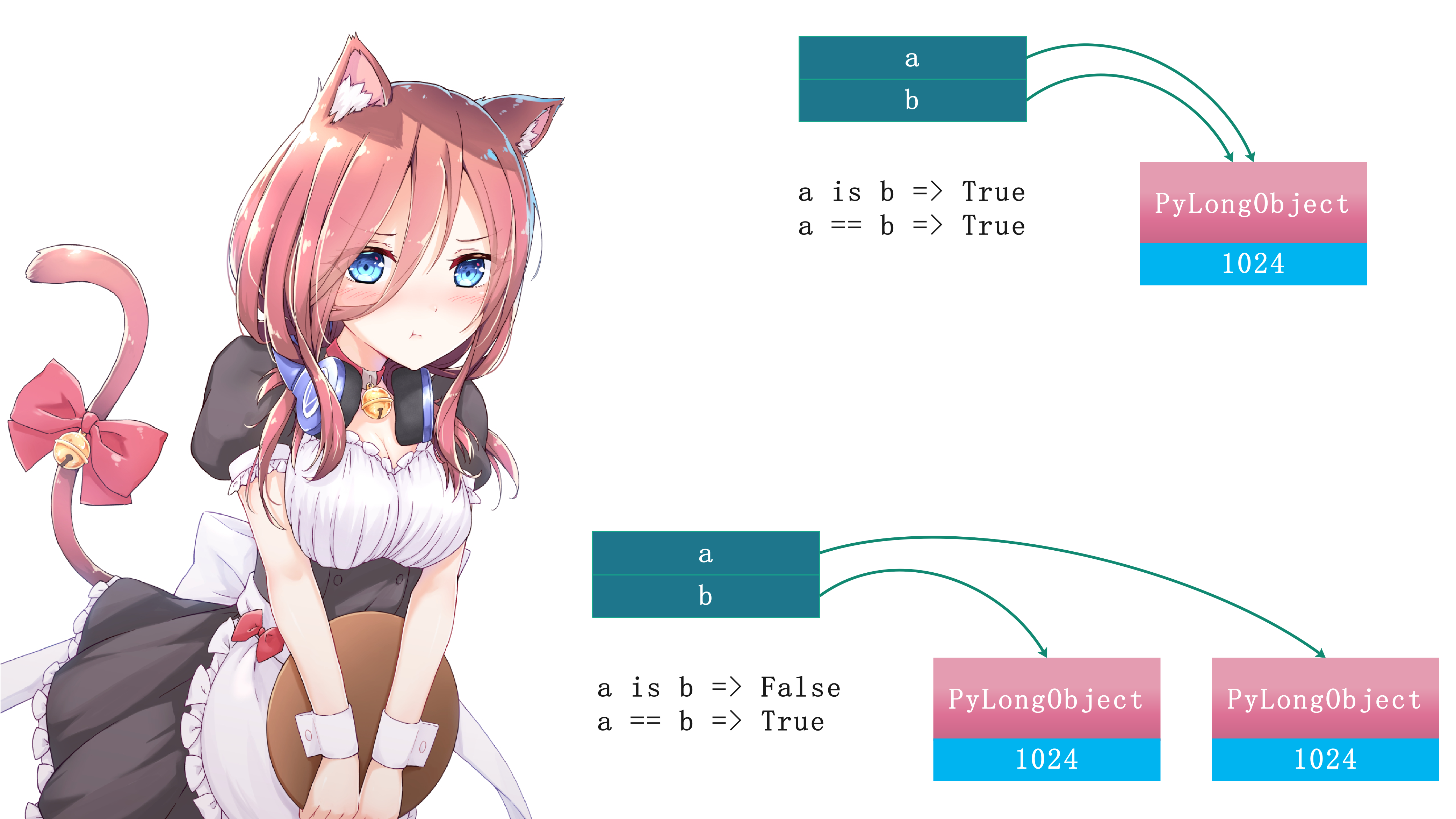
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 >>> a = 1024 >>> b = a>>> a is bTrue >>> a == bTrue >>> >>> >>> >>> a = 1024 >>> b = int ('1024' )>>> a is bFalse >>> a == bTrue >>>
用一张图看一下它们之间的区别:
一般而言如果a is b成立,那么a == b多半成立,可能有人好奇,a is b成立说明a和b指向的是同一个对象了,那么a == b表示该对象和自己进行比较,结果为啥不相等呢?以下面两种情况为例:
1 2 3 4 5 6 7 8 9 class Girl : def __eq__ (self, other ): return False g = Girl() print (g is g) print (g == g)
1 2 3 4 5 6 7 8 9 10 11 12 13 import mathimport numpy as npa = float ("nan" ) b = math.nan c = np.nan print (a is a, a == a) print (b is b, b == b) print (c is c, c == c)
在 Python 中与 None 比较时,为什么要用 is None 而不是 == None ?
None 是一种特殊的内建对象,它是单例对象,整个运行的程序中只有一个。因此,如果一个变量等于 *None*,那么*is None*一定成立,内存地址是相同的。
*Python* 中的 *==* 操作符对两个对象进行相等性比较,背后调用 *eq * 魔法方法。在自定义类中,eq 方法可以被覆写:
1 2 3 4 5 6 7 8 9 class Girl : def __eq__ (self, other ): return True g = Girl() print (g is None ) print (g == None )
而且最重要的一点,我们在介绍is和 == 之间区别的时候说过,Python的is在底层是比较地址是否相等,所以对于C而言只是判断两个变量间是否相等、一个 == 操作符即可;但是对于Python的==,在底层则是需要调用PyObject_RichCompare函数,然后进一步取出所维护的值进行比较。所以通过is None来判断会在性能上更有优势一些,再加上None是单例对象,使用is判断是最合适的。我们使用jupyter notebook测试一下两者的性能吧:
1 2 3 4 5 6 %timeit name is None 31.6 ns ± 1.62 ns per loop (mean ± std. dev. of 7 runs, 10000000 loops each)%timeit name == None 36.6 ns ± 2.8 ns per loop (mean ± std. dev. of 7 runs, 10000000 loops each)
复杂内建对象的创建 像整数对象、字符串对象在创建时的字节码,相信都已经理解了。总共两条指令:直接先LOAD常量,然后STORE(两者组成entry放在local名字空间中)。
但是问题来了,像列表、字典这样的对象,底层是怎么创建的呢?显然它们的创建要更复杂一些,两条指令是不够的。下面我们就来看看列表、字典在创建时对应的字节码是怎样的吧。
不过在此之前我们需要看一些宏,这是PyFrame_EvalFrameEx(调用了_PyEval_EvalFrameDefault)在遍历指令序列co_code时所需要的宏,里面包括了对栈的各种操作,以及对PyTupleObject对象的元素的访问操作。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #ifndef Py_DEBUG #define GETITEM(v, i) PyTuple_GET_ITEM((PyTupleObject *)(v), (i)) #else #define GETITEM(v, i) PyTuple_GetItem((v), (i)) #endif #define BASIC_STACKADJ(n) (stack_pointer += n) #define STACKADJ(n) { (void)(BASIC_STACKADJ(n), \ lltrace && prtrace(TOP(), "stackadj" )); \ assert(STACK_LEVEL() <= co-> co_stacksize); } #define BASIC_PUSH(v) (*stack_pointer++ = (v)) #define PUSH(v) BASIC_PUSH(v) #define BASIC_POP() (*--stack_pointer) #define POP() ((void)(lltrace && prtrace(TOP(), "pop" )), \ BASIC_POP())
然后我们随便创建一个列表和字典吧。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 s = """ lst = [1, 2, "3", "xxx"] d = {"name": "夏色祭", "age": -1} """ import disdis.dis(compile (s, "xxx" , "exec" )) 2 0 LOAD_CONST 0 (1 ) 2 LOAD_CONST 1 (2 ) 4 LOAD_CONST 2 ('3' ) 6 LOAD_CONST 3 ('xxx' ) 8 BUILD_LIST 4 10 STORE_NAME 0 (lst) 3 12 LOAD_CONST 4 ('夏色祭' ) 14 LOAD_CONST 5 (-1 ) 16 LOAD_CONST 6 (('name' , 'age' )) 18 BUILD_CONST_KEY_MAP 2 20 STORE_NAME 1 (d) 22 LOAD_CONST 7 (None ) 24 RETURN_VALUE
首先对于列表来说,它是先将列表中的常量加载进来了,从上面的4个LOAD_CONST也能看出来。然后重点来了,我们看到有一行指令 BUILD_LIST 4,从名字上也能看出来这是要根据load进行来的4个常量创建一个列表,后面的4表示这个列表有4个元素。
但是问题来了,Python怎么知道这构建的是一个列表呢?元组难道不可以吗?答案是因为我们创建的是列表,不是元组,而且这个信息也体现在了字节码中。然后我们看看BUILD_LIST都干了些什么吧。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 case TARGET (BUILD_LIST) : { PyObject *list = PyList_New(oparg); if (list == NULL ) goto error; while (--oparg >= 0 ) { PyObject *item = POP(); PyList_SET_ITEM(list , oparg, item); } PUSH(list ); DISPATCH(); }
但BUILD_LIST之后,只改变了运行时栈,没有改变local空间。所以后面的STORE_NAME 0 (lst)表示将在local空间中建立一个 “符号lst” 到 “BUILD_LIST构建的PyListObject对象” 之间的映射,也就是组合成一个entry放在local空间中,这样我们后面才可以通过符号lst找到对应的列表。
STORE_NAME我们已经见过了,这里就不说了。其实STORE_XXX和LOAD_XXX都是非常简单的,像LOAD_GLOBAL、LOAD_FAST、STORE_FAST等等可以自己去看一下,没有任何难度,当然我们下面也会说。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 2 0 LOAD_CONST 0 (1 ) 2 LOAD_CONST 1 (2 ) 4 LOAD_CONST 2 ('3 ') 6 LOAD_CONST 3 ('xxx') 8 BUILD_LIST 4 10 STORE_NAME 0 (lst ) 3 12 LOAD_CONST 4 ('夏色祭') 14 LOAD_CONST 5 (-1 ) 16 LOAD_CONST 6 (('name', 'age')) 18 BUILD_CONST_KEY_MAP 2 20 STORE_NAME 1 (d ) 22 LOAD_CONST 7 (None ) 24 RETURN_VALUE
然后我们再看看字典的构建方式,首先依旧是加载两个常量,显然这个字典是value。然后注意:我们看到key是作为一个元组加载进来的。而且如果我们创建了一个元组,那么这个元组也会整体被LOAD_CONST,所以从这里我们也能看到列表和元组之间的区别,列表的元素是一个一个加载的,元组是整体加载的,只需要LOAD_CONST一次即可。BUILD_CONST_KEY_MAP 2毋庸置疑就是构建一个字典了,后面的oparg是2,表示这个字典有两个entry,我们看一下源码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 case TARGET (BUILD_CONST_KEY_MAP) : { Py_ssize_t i; PyObject *map ; PyObject *keys = TOP(); if (!PyTuple_CheckExact(keys) || PyTuple_GET_SIZE(keys) != (Py_ssize_t)oparg) { _PyErr_SetString(tstate, PyExc_SystemError, "bad BUILD_CONST_KEY_MAP keys argument" ); goto error; } map = _PyDict_NewPresized((Py_ssize_t)oparg); if (map == NULL ) { goto error; } for (i = oparg; i > 0 ; i--) { int err; PyObject *key = PyTuple_GET_ITEM(keys, oparg - i); PyObject *value = PEEK(i + 1 ); err = PyDict_SetItem(map , key, value); if (err != 0 ) { Py_DECREF(map ); goto error; } } Py_DECREF(POP()); while (oparg--) { Py_DECREF(POP()); } PUSH(map ); DISPATCH(); }
最后STORE_NAME 1 (d),显然是再将运行时栈中的字典弹出来,将符号d和弹出来的字典建立一个entry放在local空间中。
在所有的字节码指令都执行完毕之后,运行时栈会是空的,但是所有的信息都存储在了local名字空间中。
函数中的变量 我们之前定义的变量是在模块级别的作用域中,但如果我们在函数中定义呢?
1 2 3 4 5 6 7 8 9 10 def foo (): i = 1 s = "python" 2 0 LOAD_CONST 1 (1 ) 2 STORE_FAST 0 (i) 3 4 LOAD_CONST 2 ('python' ) 6 STORE_FAST 1 (s) 8 LOAD_CONST 0 (None ) 10 RETURN_VALUE
我们看到大致一样,但是有一点发生了变化, 那就是在将变量名和变量值映射的时候,使用的不再是STORE_NAME,而是STORE_FAST,显然STORE_FAST会更快一些。为什么这么说,这是因为函数中的局部变量总是固定不变的,在编译的时候就能确定局部变量使用的内存空间的位置,也能确定局部变量字节码指令应该如何访问内存,就能使用静态的方法来实现局部变量。其实局部变量的读写都在fastlocals = f -> f_localsplus上面。
1 2 3 4 5 6 7 8 9 10 11 case TARGET (STORE_FAST) { PyObject *value = POP(); SETLOCAL(oparg, value); FAST_DISPATCH(); } #define SETLOCAL(i, value) do { PyObject *tmp = GETLOCAL(i); \ GETLOCAL(i) = value; \ Py_XDECREF(tmp); } while (0) #define GETLOCAL(i) (fastlocals[i])
一般表达式 符号搜索 我们还是举个例子:
1 2 3 4 5 6 7 8 9 a = 5 b = a 1 0 LOAD_CONST 0 (5 ) 2 STORE_NAME 0 (a) 2 4 LOAD_NAME 0 (a) 6 STORE_NAME 1 (b) 8 LOAD_CONST 1 (None ) 10 RETURN_VALUE
首先源代码第一行对应的字节码指令无需介绍,但是第二行对应的指令变了,我们看到不再是LOAD_CONST,而是LOAD_NAME。其实也很好理解,第一行a = 5,而5是一个常量所以是LOAD_CONST,但是b = a,这里的a是一个变量名,所以是LOAD_NAME。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 case TARGET (LOAD_NAME) { PyObject *name = GETITEM(names, oparg); PyObject *locals = f->f_locals; PyObject *v; if (locals == NULL ) { PyErr_Format(PyExc_SystemError, "no locals when loading %R" , name); goto error; } if (PyDict_CheckExact(locals)) { v = PyDict_GetItem(locals, name); Py_XINCREF(v); } else { v = PyObject_GetItem(locals, name); if (v == NULL ) { if (!PyErr_ExceptionMatches(PyExc_KeyError)) goto error; PyErr_Clear(); } } if (v == NULL ) { v = PyDict_GetItem(f->f_globals, name); Py_XINCREF(v); if (v == NULL ) { if (PyDict_CheckExact(f->f_builtins)) { v = PyDict_GetItem(f->f_builtins, name); if (v == NULL ) { format_exc_check_arg( PyExc_NameError, NAME_ERROR_MSG, name); goto error; } Py_INCREF(v); } else { v = PyObject_GetItem(f->f_builtins, name); if (v == NULL ) { if (PyErr_ExceptionMatches(PyExc_KeyError)) format_exc_check_arg( PyExc_NameError, NAME_ERROR_MSG, name); goto error; } } } } PUSH(v); DISPATCH(); }
另外如果是在函数里面,那么b = a就既不是LOAD_CONST、也不是LOAD_NAME,而是LOAD_FAST。这是因为函数中的变量在编译的时候就已经确定,因此是LOAD_FAST。那么如果b = a在函数里面,而a = 5定义在函数外面呢?那么结果是LOAD_GLOBAL,因为知道这个a到底是定义在什么地方。
数值运算 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 a = 5 b = a c = a + b 1 0 LOAD_CONST 0 (5 ) 2 STORE_NAME 0 (a) 2 4 LOAD_NAME 0 (a) 6 STORE_NAME 1 (b) 3 8 LOAD_NAME 0 (a) 10 LOAD_NAME 1 (b) 12 BINARY_ADD 14 STORE_NAME 2 (c) 16 LOAD_CONST 1 (None ) 18 RETURN_VALUE
显然这里我们直接从 8 LOAD_NAME开始看即可,首先是加在两个变量,然后通过BINARY_ADD进行加法运算。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 case TARGET (BINARY_ADD) { PyObject *right = POP(); PyObject *left = TOP(); PyObject *sum; if (PyUnicode_CheckExact(left) && PyUnicode_CheckExact(right)) { sum = unicode_concatenate(left, right, f, next_instr); } else { sum = PyNumber_Add(left, right); Py_DECREF(left); } Py_DECREF(right); SET_TOP(sum); if (sum == NULL ) goto error; DISPATCH(); }
信息输出 最后看看信息是如何输出的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 a = 5 b = a c = a + b print (c) 1 0 LOAD_CONST 0 (5 ) 2 STORE_NAME 0 (a) 2 4 LOAD_NAME 0 (a) 6 STORE_NAME 1 (b) 3 8 LOAD_NAME 0 (a) 10 LOAD_NAME 1 (b) 12 BINARY_ADD 14 STORE_NAME 2 (c) 4 16 LOAD_NAME 3 (print ) 18 LOAD_NAME 2 (c) 20 CALL_FUNCTION 1 22 POP_TOP 24 LOAD_CONST 1 (None ) 26 RETURN_VALUE
我们直接从16 LOAD_NAME开始看,首先从builtins中加载变量print(本质上加载和变量绑定的对象),然后加载变量c,将两者压入运行时栈。
CALL_FUNCTION,表示函数调用,执行刚才的print,后面的1则是参数的个数。另外,当调用print的时候,实际上又创建了一个栈帧,因为只要是函数调用都会创建栈帧的。
1 2 3 4 5 6 7 8 9 10 11 case TARGET (CALL_FUNCTION) { PyObject **sp, *res; sp = stack_pointer; res = call_function(&sp, oparg, NULL ); stack_pointer = sp; PUSH(res); if (res == NULL ) { goto error; } DISPATCH(); }
然后POP_TOP表示从栈的顶端弹出函数的返回值,因为POP_TOP的上一步是一个call_function,也就是函数调用。而函数是有返回值的,在函数调用(call_function指令)执行完毕之后会自动将返回值设置在栈顶,而POP_TOP就是负责将上一步函数调用的返回值从栈顶弹出来。只不过我们这里是print函数返回的是None、我们不需要这个返回值,或者说我们没有使用变量接收,所以直接将其从栈顶弹出去即可。但如果我们是res = print(c),那么你会发现指令POP_TOP就变成了STORE_NAME,因为要将符号和返回值绑定起来放在local空间中。最后LOAD_CONST、RETURN_VALUE,无需解释了,就是返回值,不光是函数,类代码块、模块代码块在执行完毕之后也会返回一个值给调用者,只不过这个值通常是None。最后再来看看print是如何打印的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 static PyObject *builtin_print (PyObject *self, PyObject *const *args, Py_ssize_t nargs, PyObject *kwnames) { static const char * const _keywords[] = {"sep" , "end" , "file" , "flush" , 0 }; static struct _PyArg_Parser _parser ="|OOOO:print" , _keywords, 0 }; PyObject *sep = NULL , *end = NULL , *file = NULL , *flush = NULL ; int i, err; if (kwnames != NULL && !_PyArg_ParseStackAndKeywords(args + nargs, 0 , kwnames, &_parser, &sep, &end, &file, &flush)) { return NULL ; } if (file == NULL || file == Py_None) { file = _PySys_GetObjectId(&PyId_stdout); if (file == NULL ) { PyErr_SetString(PyExc_RuntimeError, "lost sys.stdout" ); return NULL ; } if (file == Py_None) Py_RETURN_NONE; } if (sep == Py_None) { sep = NULL ; } else if (sep && !PyUnicode_Check(sep)) { PyErr_Format(PyExc_TypeError, "sep must be None or a string, not %.200s" , sep->ob_type->tp_name); return NULL ; } if (end == Py_None) { end = NULL ; } else if (end && !PyUnicode_Check(end)) { PyErr_Format(PyExc_TypeError, "end must be None or a string, not %.200s" , end->ob_type->tp_name); return NULL ; } for (i = 0 ; i < nargs; i++) { if (i > 0 ) { if (sep == NULL ) err = PyFile_WriteString(" " , file); else err = PyFile_WriteObject(sep, file, Py_PRINT_RAW); if (err) return NULL ; } err = PyFile_WriteObject(args[i], file, Py_PRINT_RAW); if (err) return NULL ; } if (end == NULL ) err = PyFile_WriteString("\n" , file); else err = PyFile_WriteObject(end, file, Py_PRINT_RAW); if (err) return NULL ; if (flush != NULL ) { PyObject *tmp; int do_flush = PyObject_IsTrue(flush); if (do_flush == -1 ) return NULL ; else if (do_flush) { tmp = _PyObject_CallMethodId(file, &PyId_flush, NULL ); if (tmp == NULL ) return NULL ; else Py_DECREF(tmp); } } Py_RETURN_NONE; }
小结 这次我们就简单分析了一下字节码指令,介绍了一些常见的指令。