
22-Python中的生成器对象
22-Python中的生成器对象
楔子
下面我们来聊一聊Python中的生成器,它是我们理解后面协程的基础,生成器的话,估计大部分人在写程序的时候都想不到用。但是一旦用好了,确实能给程序带来性能上的提升,那么我们就来看一看吧。
生成器
基本用法
我们知道,一个函数如果它的内部出现了yield关键字,那么它就不再是普通的函数了,而是一个生成器函数。当我们调用的时候,就会创建一个生成器对象。
生成器对象一般用于处理循环结构,应用得当的话可以极大优化内存使用率。比如:我们读取一个大文件。
1 | def read_file(file): |
这个版本的函数,直接将里面的内容全部读取出来了,返回了一个列表。如果文件非常大,那么内存的开销可想而知。
于是我们可以通过yield关键字,将函数变成一个生成器。
1 | def read_file(file): |
观察生成器的运行行为
那么生成器是怎么做到的呢?我们继续考察一下。
1 | def read_file(file): |
因此生成器和之前我们说的迭代器是类似的,毕竟生成器就是一个特殊的迭代器。
原谅我写到这里有点懈怠了,有点累了。所以这里后面只对生成器的底层实现进行剖析,至于一些Python层面的东西就不说了。
任务上下文
在经典的线程模型中,每个线程都有一个独立的执行流,只能执行一个任务。如果一个程序需要同时处理多个任务,可以借助多线程或者多进程技术。假设一个站点需要同时服务于多个客户端连接,可以为每个连接创建一个独立的线程进行处理。
但不管是线程还是进程,切换时都会带来巨大的性能开销:用户态和内核态的切换、执行上下文保存和恢复、CPU刷新缓存等等。因此,使用进程或者线程来驱动多个小任务的执行,显然不是一个理想的选择。
那么,除了进程和线程,还有其它的解决方案吗?显然是有的,答案就是协程。不过在讨论之前,我们先来总结多任务执行体系的关键之处。
一个程序想要同时处理多个任务,必须提供一种能够记录任务执行进度的机制。在经典线程模型中,这个机制由CPU提供:
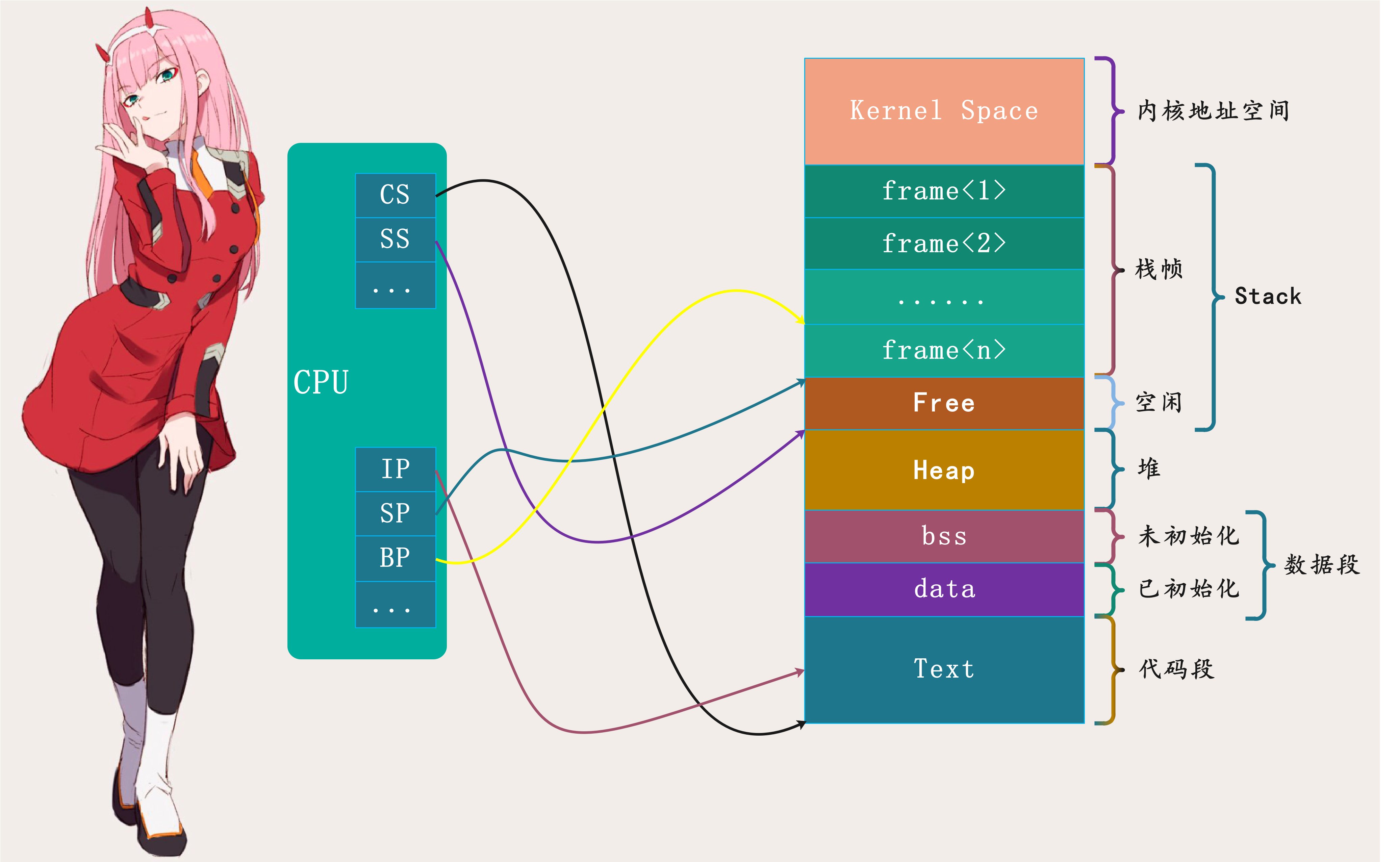
如上图,程序内存空间分为代码、数据、堆以及栈等多个段,*CPU* 中的 *CS* 寄存器指向代码段,*SS* 寄存器指向栈段。当程序任务(线程)执行时,*IP* 寄存器指向代码段中当前正被执行的指令,*BP* 寄存器指向当前栈帧,*SP* 寄存器则指向栈顶。
有了 *IP* 寄存器,*CPU* 可以取出需要执行的下一条指令;有了 *BP* 寄存器,当函数调用结束时,*CPU* 可以回到调用者继续执行。因此,*CPU* 寄存器与内存地址空间一起构成了任务执行上下文,记录着任务执行进度。当任务切换时,操作系统先将 *CPU* 当前寄存器保存到内存,然后恢复待执行任务的寄存器。
至此,我们已经受到一些启发:生成器不是可以记住自己的执行进度吗?那么,是不是可以用生成器来实现任务执行流?由于生成器在用户态运行,切换成本比线程或进程小很多,是组织微型任务的理想手段。
现在,我们用生成器来写一个玩具协程,以此体会协程的运行机制:
1 | def producer(n): |
我们创建一个生产包子的生产者,和一个消费包子的消费者,然后进行初始化。当我们调用next函数的时候,就可以驱动它们执行了。
1 | print(next(p)) # 生产者生产第1包子 |
当遇到第一个yield语句时,让出执行权,并将yield后面的值返回。但是在实例项目中,一般在遇到网络I/O时,才会让出执行权。
而且我们看到,我们还扮演着调度器的角色。
1 | print(next(p)) # 生产者生产第2包子 |
我们再次通过next驱动生成器执行,然后遇到yield之后继续暂停,将yield后面的值返回,并将执行权交给我们。
1 | print(next(p)) |
再次驱动生成器执行,但是发现已经找不到下一个yield了,所以抛出StopIteration异常告诉我们生成器已经将全部的值都生成了。
以上通过一个小例子,感受一下生成器的运行原理,它可以帮我们更好地理解后面的协程。因为协程的思想和生成器本质是一样的,而且在早期Python还没有提供原生协程的时候,就是通过生成器来模拟的协程。
字节码解密生成器
上面我们简单的考察了一下生成器的运行时行为,发现了它神秘的一面。生成器可以通过yield关键字暂停,并且还可以通过next函数重新恢复执行(从上一次暂停的位置),这个特性可以用来实现协程。
生成器的创建
而理解协程,首先要理解生成器。
1 | def gen(): |
我们创建一个简单的生成器函数,当我们调用的时候就会得到一个生成器对象。
1 | def gen(): |
关于普通函数和生成器函数,有一个非常生动的栗子。普通函数可以想象成一匹马,只要调用了,那么不把里面的代码执行完毕誓不罢休;而生成器函数则好比一头驴,调用的时候并没有动,只是返回一个生成器对象,然后需要每次拿鞭子抽一下
(调用一次next)才往前走一步。另外我们可以把生成器看成是可以暂停的函数,其中的yield就类似于return,只不过可以有多个yield。当执行到一个yield时,将值返回、同时暂停在此处,然后当使用next函数驱动时,从暂停的地方继续执行,直到找到下一个yield。如果找不到下一个yield,就会抛出StopIteration异常。
那么老规矩,肯定要看一下字节码。
1 | 1 0 LOAD_CONST 0 (<code object gen at 0x00000188E73D1450, file "generator", line 1>) |
字节码指令依旧是分为两部分,我们先来看看模块的。很简单,就是创建一个生成器对象,而且我们发现字节码和调用一个普通函数的字节码是一样的。那么Python是如何知道这是一个生成器函数呢?显然秘密就在CALL_FUNCTION里面。
由于我们已经分析过函数了,所以CALL_FUNCTION下一步会调用什么就不多说了,直接用我们之前的一张图:
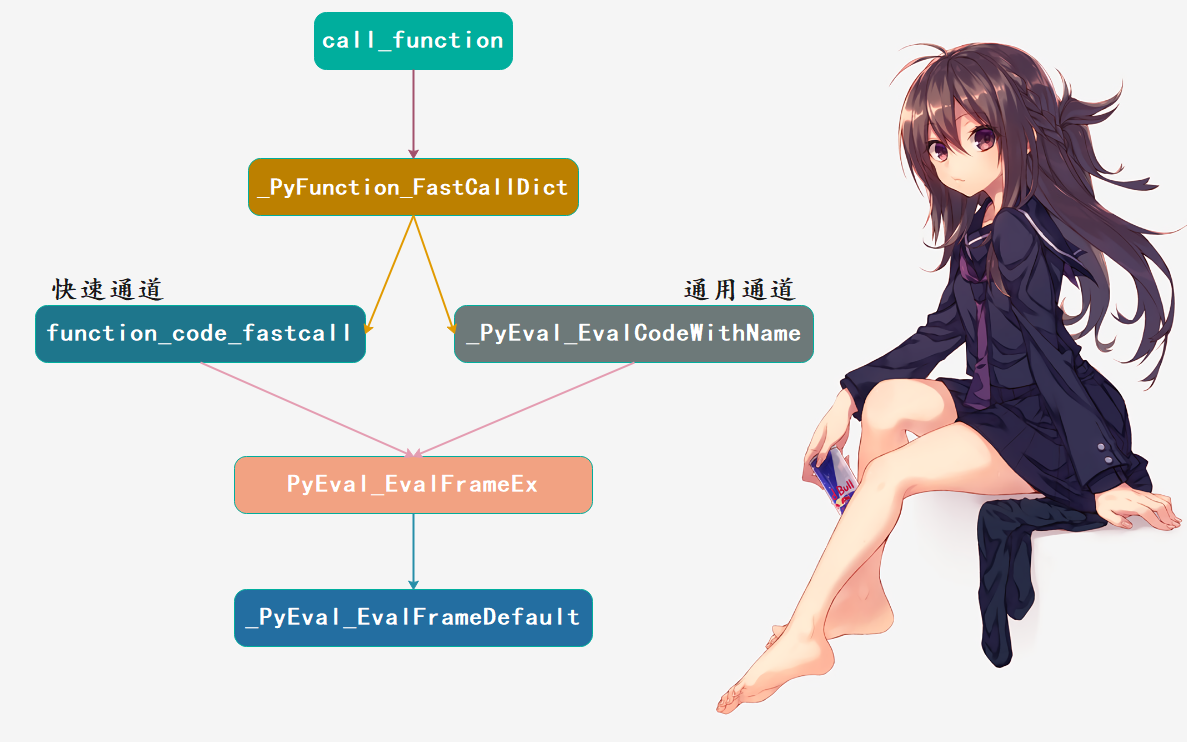
CALL_FUNCTION中,它会调用Objects/call.c中的call_function函数。call_function函数可以根据被调用对象的类型进行区别处理,可分为:类方法、函数对象、普通可调用对象等等。
在这个例子中,被调用的是函数对象。因此call_function内部会调用位于Objects/call.c中的 *_PyFunction_FastCallDict* 函数,而它则进一步调用位于 *Python/ceval.c* 中的 *_PyEval_EvalCodeWithName* 函数,该函数会为PyFunctionObject创建一个栈帧,然后检查co_flags。如果带有 *CO_GENERATOR* 、*CO_COROUTINE* 或 *CO_ASYNC_GENERATOR*,那么便创建生成器返回。
1 | PyObject * |
其中的 *co_flags* 是PyCodeObject中的一个域,显然它是在编译时由语法规则确定的。我们之前说它是用来判断参数特征的,但其实它还可以用来判断函数特征。
1 | //Include/code.h |
我们看到 *CO_GENERATOR* 的值为0x0020。
1 | print(gen.__code__.co_flags & 0x0020) # 32 |
如果不是生成器函数,那么结果为0;现在结果不为0,说明是生成器函数。
下面我们可以看看生成器的底层定义了,位于 *Include/genobject.h* 中。
1 |
|
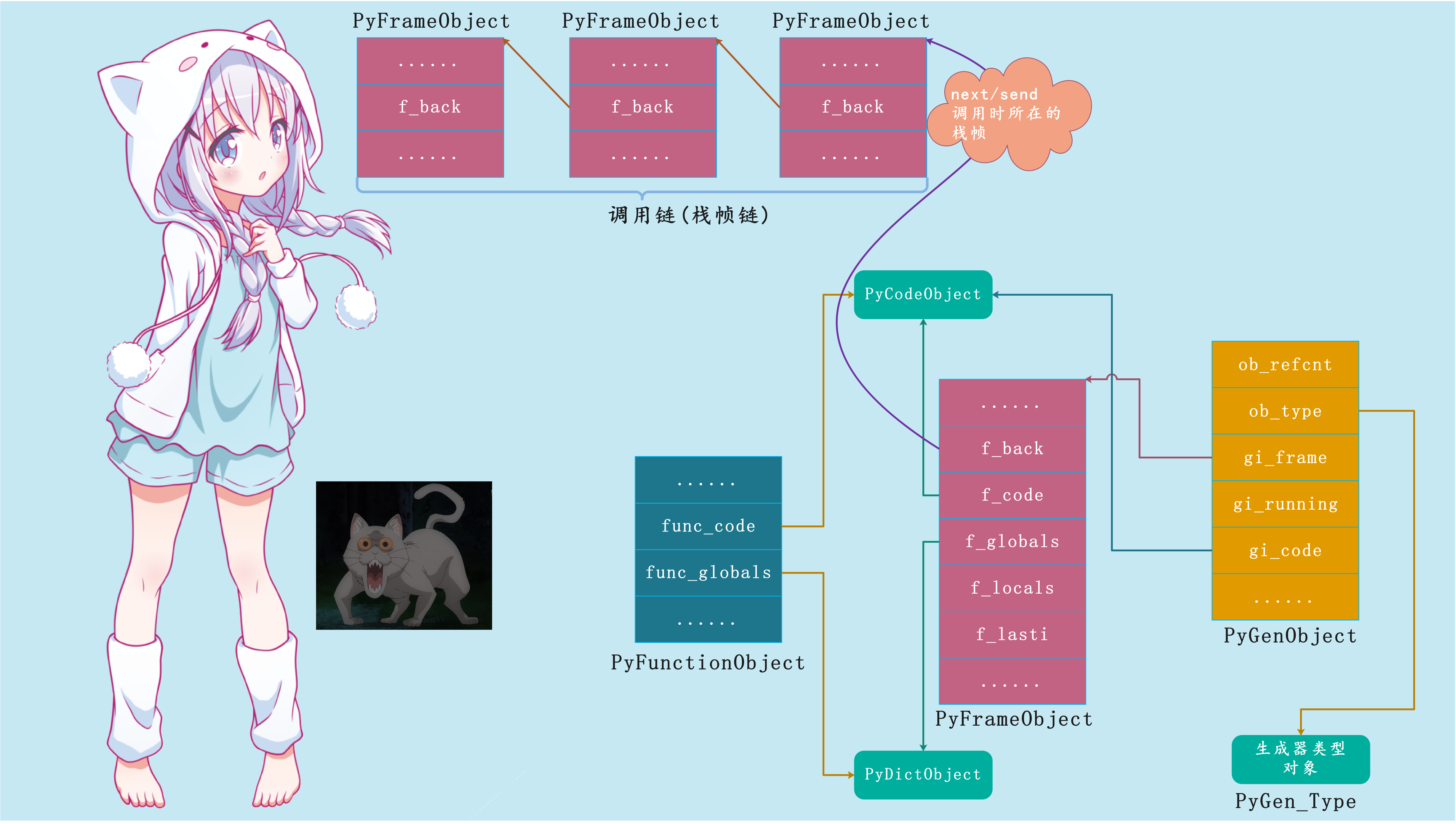
所以我们可以画出一张模型图:
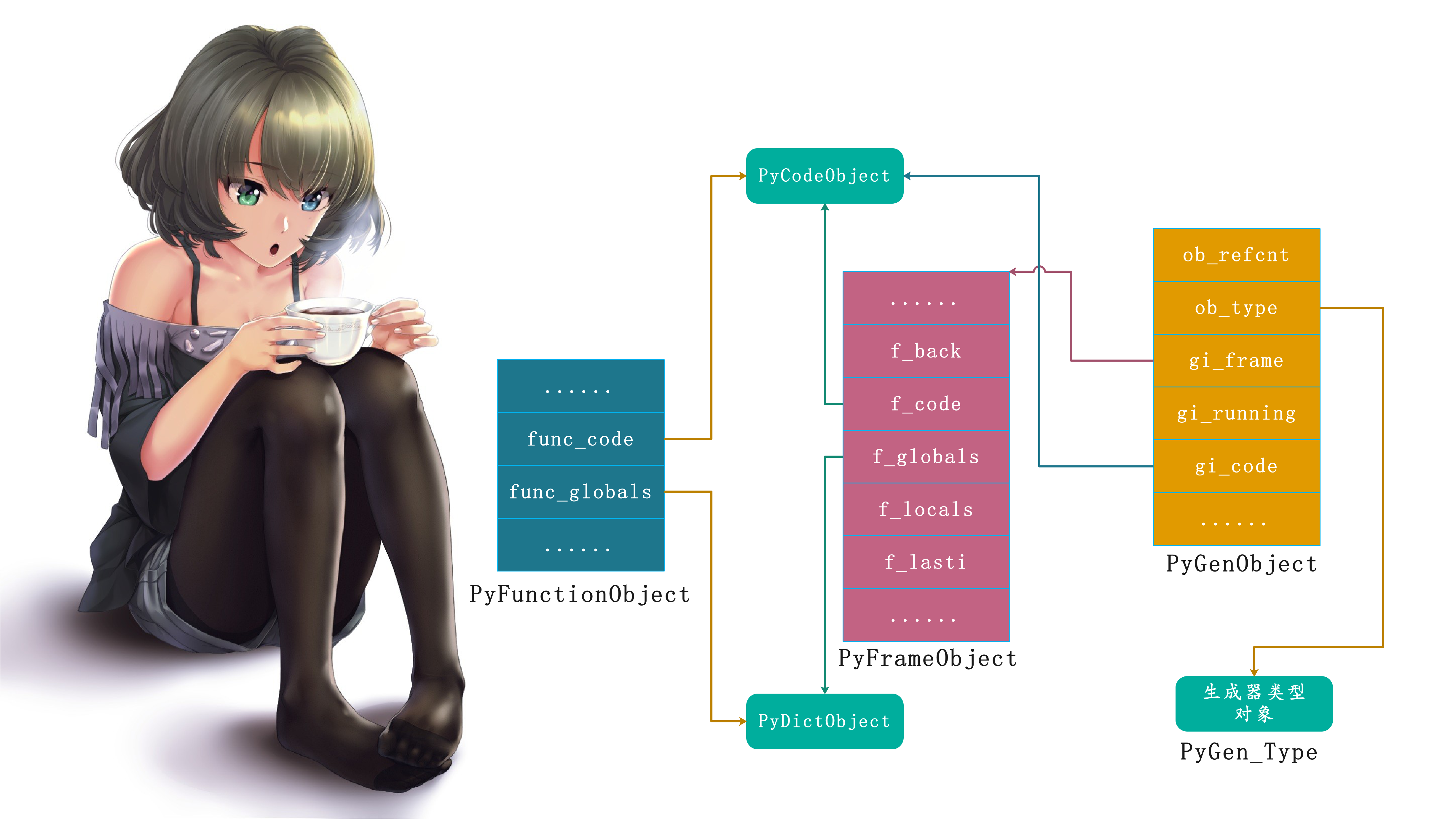
至此生成器对象的创建过程已经浮出水面,与普通函数对象一样,当生成器函数gen被调用时,Python将为其创建栈帧对象,用于维护函数执行上下文。PyCodeObject对象、全局名字空间、局部名字空间、以及运行时栈都在里面。
但和普通函数不同的是,gen函数的PyCodeObject对象带有生成器标识,在调用的时候,Python不会立刻执行PyCodeObject对象里面的字节码,栈帧对象也不会被接入到调用链中,所以f_back字段此时是空的。相反,Python创建了一个生成器对象,并将其作为函数结果返回。
我们可以使用Python来验证在我们得到的结论。
1 | g = gen() |
生成器的执行
当执行g = gen()之后,返回生成器对象并交给变量g指向,这个时候还没有开始执行。
1 | g = gen() |
栈帧对象 *f_lasti* 字段记录当前字节码执行进度,*-1* 表示尚未开始执行。
在使用Python时我们知道,借助 *next* 内建函数或者 *send* 方法可以启动生成器,并驱动它不断执行。这意味着,生成器执行的秘密可以通过这两个函数找到。
我们先从 *next* 函数入手,作为内建函数,它定义于 *Python/bltinmodule.c* 源文件,*C* 语言函数 *builtin_next* 是也。*builtin_next* 函数逻辑非常简单,除了类型检查等一些样板式代码,最关键的是这一行:
1 | res = (*it->ob_type->tp_iternext)(it); |
这行代码表明,*next* 函数实际上调用了生成器类型对象的 *tp_iternext* 函数完成工作。
next(g)等价于g.next()、等价于g.class.next(g)。
1 | g = gen() |
那么底层调用了哪个函数呢?我们说类型对象决定实例对象的行为,实例对象相关操作函数的指针都保存在类型对象中。生成器作为 *Python* 对象中的一员,当然也遵守这一法则。顺着生成器的类型对象 *PyGen_Type* ( *Objects/genobject.c* ),很快就可以找到 *gen_iternext* 函数。
另一方面, *g.send* 也可以启动并驱动生成器的执行,根据 *Objects/genobject.c* 中的方法定义,它底层调用 *_PyGen_Send* 函数:
1 | static PyMethodDef coro_methods[] = { |
不管 *gen_iternext* 函数还是 *_PyGen_Send* 函数,都是直接调用 *gen_send_ex* 函数完成工作的:
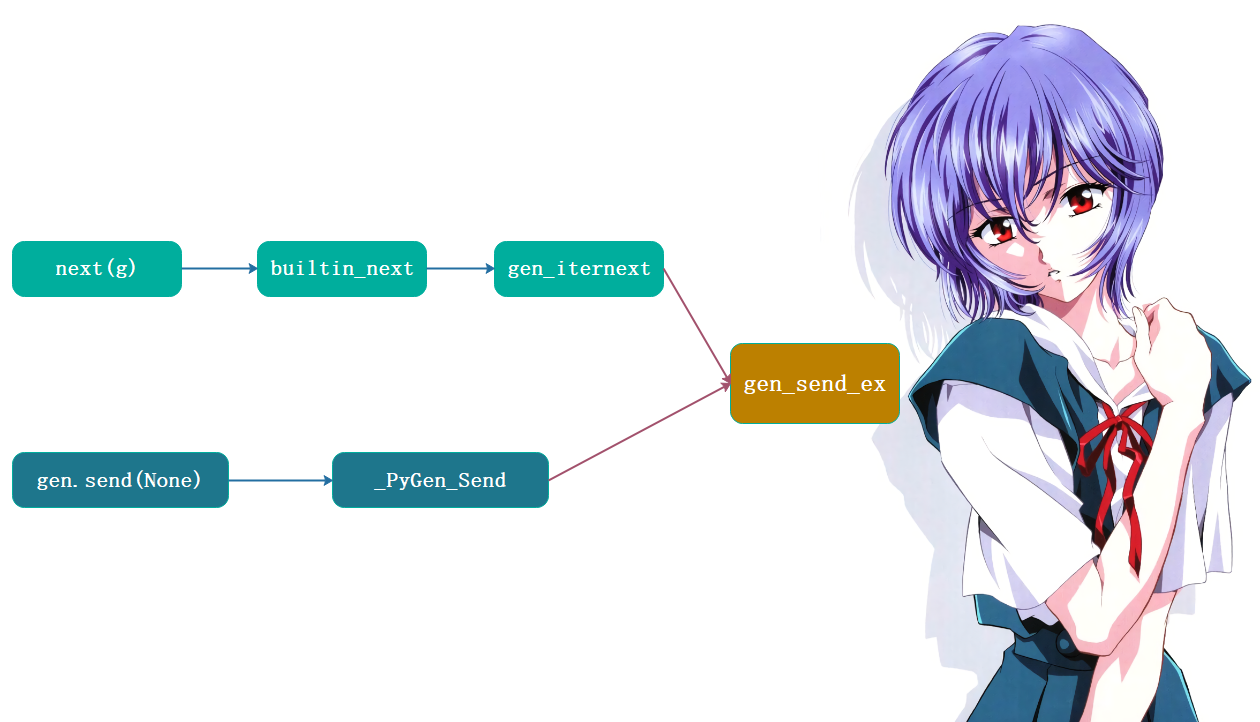
因为不管是哪一种方式驱动,最终都由 *gen_send_ex* 函数处理,*next* 和 *send* 的等价性也源于此。经过千辛万苦,我们终于找到了理解生成器运行机制的关键所在。不过这两者虽然是等价的,但是稍稍还有一点不同。
1 | def test(): |
这里简单提一下,具体细节可以自己去了解,比较简单。
此外,*gen_send_ex* 函数同样位于 *Objects/genobject.c* 源文件,函数挺长,但最关键的代码只有两行:
1 | f->f_back = tstate->frame; |
首先,第一行代码将生成器栈帧挂到当前调用链(或者说栈帧链)上;然后,第二行代码调用 *PyEval_EvalFrameEx* 开始在生成器栈帧对象中执行字节码;生成器栈帧对象保存着生成器执行上下文,其中 *f_lasti* 字段跟踪生成器代码对象的执行进度。
剩下的逻辑我们显然之前就知道了,*PyEval_EvalFrameEx* 函数最终调用 *_PyEval_EvalFrameDefault* 函数执行 *frame* 对象中 *f_code* 内部的字节码。这个函数我们在虚拟机部分学习过,对它并不陌生。虽然它体量巨大,超过 *3* 千行代码,但逻辑却非常直白——内部由无限 *for* 循环逐条遍历字节码,然后交给内部的一个巨型switch case语句,根据不同的指令执行不同的case分支,每执行完一条字节码就自增 *f_lasti* 字段,直到字节码全部执行完毕、或者中间出现异常时结束循环。
生成器的暂停
我们知道,生成器可以利用 *yield* 语句,将执行权归还给调用者。因此,生成器暂停执行的秘密就隐藏在 *yield* 语句中。我们先来看看 *yield* 语句编译后,生成什么字节码。这里我们就直接分析上面生成器函数内部的字节码:
1 | 2 0 LOAD_GLOBAL 0 (print) |
我们看到每个 *yield* 语句编译后,都得到这样 *3* 条字节码指令:
1 | LOAD_FAST |
这里是LOAD_FAST,也可以是LOAD_CONST、LOAD_NAME等等,首先这里的LOAD_FAST是将变量指向的值压入运行时栈,设置在栈顶。另外这里变量就是yield右边的值,然后执行 *YIELD_VALUE* 指令,显然关键就在此处。
1 | case TARGET(YIELD_VALUE): { |
紧接着,*_PyEval_EvalFrameDefault* 函数将当前栈帧(也就是生成器的栈帧)从栈帧链中解开。注意到,*yield* 值被 *_PyEval_EvalFrameDefault* 函数返回,并最终被 *send* 方法或 *next* 函数返回给调用者。
生成器的恢复
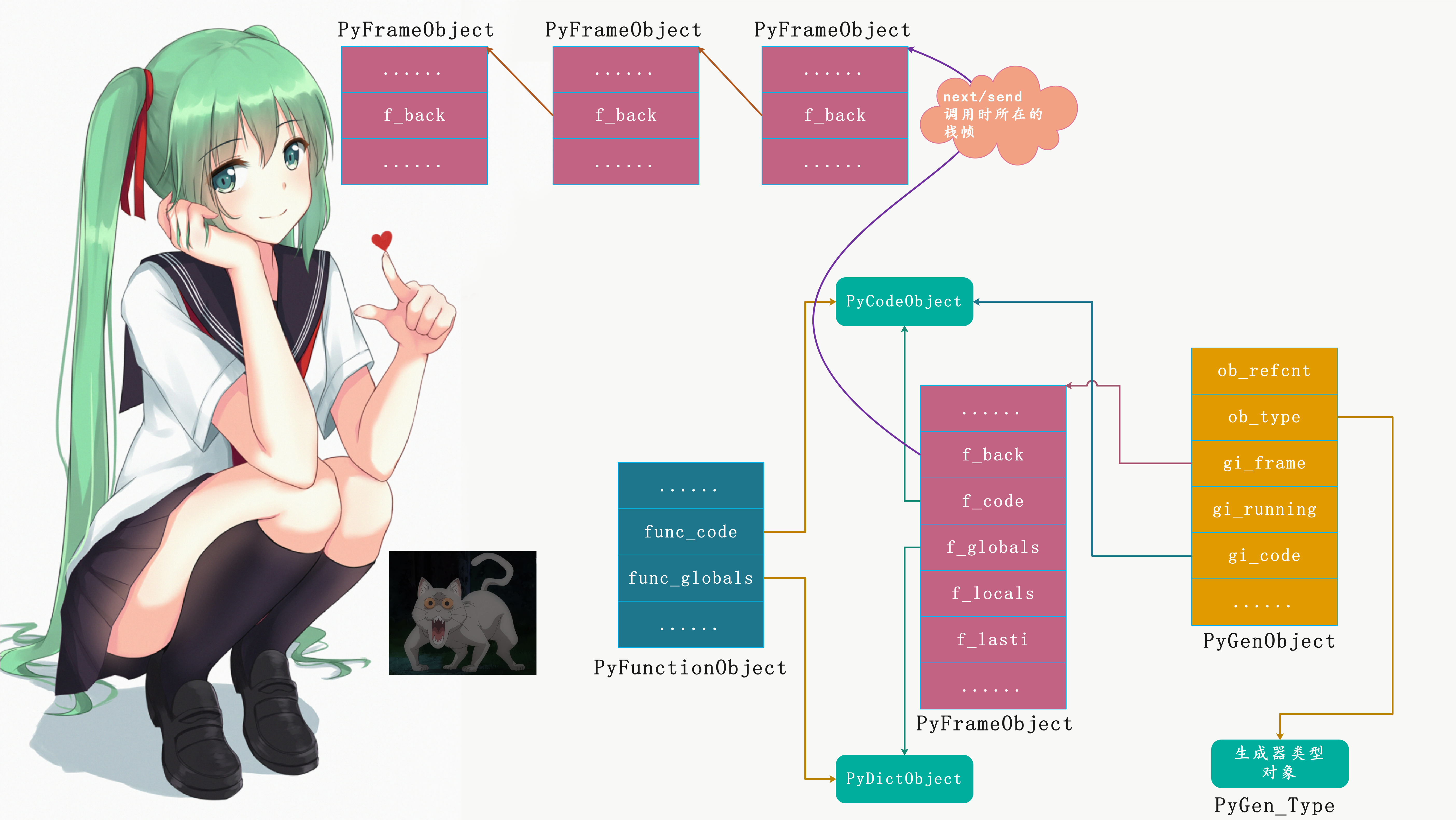
当我们再次调用 *next* 函数或者 *send* 方法时,生成器将恢复执行:
另外通过 *send* 方法,可以传入一个值,赋给yield所在语句的等号左边的变量,那么这是如何做到的呢?
首先我们知道,*send* 方法被调用后,*Python* 先把生成器栈帧对象挂到栈帧链中,并最终调用 *PyEval_EvalFrameEx* 函数逐条执行字节码。在这个过程中,*send* 发送的数据会被放在生成器栈顶:
1 | g = gen() |
这里我们 *send* 一个字符串”matsuri”,当然我们的 *yield* 语句中没有出现赋值,所以这里的值没有变量接收。因此在YIELD_VALUE指令后面就是POP_TOP了,将栈顶的值直接弹出、丢弃。尽管我们没有尝试,但如果假设我们使用变量接收了会怎么样呢?不用想,显然YIELD_VALUE指令后面的POP_TOP会变成STORE_FAST,从栈顶取出 *send* 发来的值,并保存在局部变量中。
所以当出现 *next* 函数或者 *send* 方法时,这里会再次将生成器对象的栈帧插入到栈帧链中。
而且我们看到 *f_lasti* ,它负责保存执行进度,这个进度显然是指字节码指令的便宜量。一开始是 *-1* 表示生成器没有执行,后面的 *22* 、*40* 则对应各自的YIELD_VALUE。此外,我们看到随着生成器的执行,f_locals也在不断变化。
再接着生成器按照逻辑有条不紊的执行,每次遇到 *yield* 就将后面的值返回,并将生成器所在栈帧从栈帧链中移除,同时将f_back设置为空;当使用next函数或者send方法时,再将生成器所在栈帧插入到栈帧链中,然后f_back指向next(g)或者g.send(value)对应的栈帧。然后next(g)或者g.send(value)继续执行,在找到下一个yield之后,继续返回,然后再将生成器所在栈帧的f_back设置为空、并从栈帧链中移除,至于next(g)或者g.send(value),由于它们已经执行完毕,所在栈帧就被销毁了。然后代码继续执行,如果再遇到next(g)或者g.send(value),那么再重复相同的动作,周而复始,直到生成器执行完毕。
1 | g = gen() |
注意:一旦当生成器执行完毕之后,它的 *gi_frame* 会被设置为None。
1 | print(g.gi_frame) # <frame at 0x000002353BB469F0... |
生成器小结
至此,生成器执行、暂停、恢复的全部秘密皆已揭开。流程如下:
生成器函数编译后代码对象带有 CO_GENERATOR 标识如果函数代码对象带 CO_GENERATOR 标识,被调用时 Python 将创建生成器对象生成器创建的同时,Python 还创建一个栈帧对象,用于维护代码对象执行上下文调用 next函数或者send方法 驱动生成器执行,然后Python 将生成器栈帧对象插入栈帧链,f_back设置为调用的next函数或者send方法对应的栈帧, 开始执行字节码, 注意: 此时是在next函数或者send方法对应的栈帧中执行执行到yield语句时,说明next函数或者send方法执行完毕了; 那么将yield右边的值压入运行时栈栈顶, 并终止字节码执行, 退回到上一级栈帧; 并且还会将生成器所在栈帧的f_back设置为空, 以及设置f_lasti等成员yield值最终作为next函数或者send方法的返回值,被调用者取得当再次调用next函数或者send方法时,Python会将生成器栈帧重新插入到栈帧链中,f_back设置为调用的next函数或者send方法对应的栈帧,然后继续执行生成器内部的字节码。从什么地方开始执行呢?显然是上一次中断的位置,那么上一次中断的位置Python如何得知?没错,显然是通过f_lasti(字节码偏移量),直接从f_lasti处开始执行执行时,会从f_lasti、即上一次YIELD_VALUE处开始执行,并且会获得调用者通过send发来的值,然后继续往下执行代码执行权就这样在调用者和生成器间来回切换,然后一直周而复始,直至生成器执行完毕。执行完毕之后,gi_frame就被设置为None了。
yield和yield from
除了yield还有一个yield from,估计有人理解不清它们的作用,这里我们简单的提一句。由于我们现在是分析解释器,所以这些Python层面的语法知识,就简单说一下。另外之所以会提到yield from,主要是为了后面的协程做铺垫。
1 | def f1(): |
yield后面可以跟可迭代对象和不可迭代对象,而yield from后面必须跟可迭代对象。当执行时,会将yield后面的值作为一个整体迭代出来,而yield from则是迭代”可迭代对象里面的一个值”。我们再举个栗子:
1 | def foo1(): |
如果要是但看上面的吗?会发现yield from貌似没什么特殊的地方,但是yield from它还可以作为委托生成器。
委托生成器:负责在调用方和子生成器之间建立一个双向通道。
1 | def foo1(): |
这里在执行f2.next()的时候并没有经过foo2,因为它建立了一个双向通道,我们是直接找到foo1,同理foo1中yield后面的值也会直接返回给调用方。
一旦foo1中的代码执行完毕,理论上肯定会抛出StopIteration异常,但是有委托生成器。所以会将返回值交给委托生成器中的res,然后在委托生成器中继续寻找yield或者yield from。但是显然res = yield from foo1()这行代码下面已经没有yield或者yield from了,所以异常会由委托生成器抛出来。
1 | def foo1(): |
小结
这次我们介绍了生成器,分析了它的执行原理,相信你对生成器会有一个更深的认识。另外在项目中,可以多尝试使用生成器。