
23-剖析Python中的模块导入机制、Python是如何加载模块的
23-剖析Python中的模块导入机制、Python是如何加载模块的
楔子
上一篇我们介绍了生成器,本来这里应该介绍协程的,但是大致阅读了一下,感觉如果从源码的角度来介绍协程的话,工作量太大。而且个人精力有限,所以推荐我写的这一篇博客:https://www.cnblogs.com/traditional/p/11828780.html,是用来介绍asyncio的,当然也从Python的角度介绍了Python中的协程。
这一次我们说一下Python模块的加载机制,我们之前所考察的所有内容都具有一个相同的特征,那就是它们都局限在一个py文件中。然而现实中不可能只有一个py文件,而是存在多个,而多个py文件之间存在引用和交互,这些也是程序的一个重要组成部分。那么这里我们就来分析,Python中模块的导入机制。
在这里我们必须强调一点,Python中一个单独的py文件、或者pyd文件,我们称之为一个 *模块* ;而多个模块组合起来放在一个目录中,这个目录我们称之为 *包* 。
但是不管是模块,还是包,它们在Python的底层都是PyModuleObject结构体实例,类型为PyModule_Type,而在Python中则都是一个<class 'module'>对象。
1 | //Objects/moduleobject.c |
所以模块和包导入进来之后也是一个对象,下面我们通过Python来演示一下。
1 | import os |
因此不管是模块还是包,在Python中都是一样的,我们后面会详细说。总之它们都是一个PyModuleObject,只不过为了区分,我们把单独的py文件、pyd文件叫做模块,一个目录叫做包,但是在Python的底层则并没有区分那么明显,它们都是一样的。
所以为了不产生歧义,我们这里做一个约定,从现在开始本系列中出现的”模块”:指的就是单独的可导入文件;出现的”包”:指的就是目录;而”模块”和”包”组合起来,我们称之为module对象,因为这两者本来就是<class 'module'>的实例对象。
import前奏曲
我们以一个简单的import为序幕,看看相应的字节码;
1 | import sys |
我们发现对应的字节码真的是简单无比。先不管开头的两个LOAD_CONST,我们在第三行看到了IMPORT_NAME,这个可以类比之前的LOAD_NAME。表示将sys这个module对象加载进来,然后通过STORE_NAME存储在当前的local名字空间中,然后当我们调用sys.path的时候,虚拟机就能很轻松地通过sys来获取path这个属性所对应的值了。因此就像我们之前说的那样,创建函数、类、导入模块等等,它们本质上和通过赋值语句创建一个变量是没有什么区别的,关键就是这个IMPORT_NAME,我们看看它的实现,知道从哪里看吗?我们说Python中所有指令集的实现都在 *ceval.c* 的那个无限for循环的巨型switch中。
1 | case TARGET(IMPORT_NAME): { |
因此重点在import_name这个函数中,但是在此之前我们需要重点关注一下这个fromlist和level,而这一点我们可以从Python的层面来介绍。我们知道在python中,我们导入一个模块直接通过import关键字即可, 但是除了import,我们还可以使用__import__函数来进行导入,这个__import__是解释器使用的一个函数,不推荐我们直接使用,但是我想说的是import os就等价于os = import(“os”)。
1 | os = __import__("os") |
但是问题来了:
1 | m1 = __import__("os.path") |
为什么会这样呢?我们来看看__import__这个函数的解释,这个是pycharm给抽象出来的。
1 | def __import__(name, globals=None, locals=None, fromlist=(), level=0): |
大意就是,此函数会由import语句调用,当我们import的时候,解释器底层就会调用__import__。比如import os表示将”os”这个字符串传入__import__中,从指定目录加载os.py(也可能是os.pyd、或者一个名为os的目录也可以)得到一个module对象,并将返回值再次赋值给符号os,也就是os = import(“os”)。虽然我们可以通过这种方式来导入模块,但是Python不建议我们这么做。而globals参数则是确定import语句包的上下文,一般直接传globals()即可,但是locals参数我们基本不用,不过一般情况下globals和locals我们都不用管。
fromlist我们刚才已经说了,import(“os.path”),如果是这种情况的话,那么导入的不是os.path,还是os这个外层模块。如果想导入os.path,那么只需要给fromlist传入一个非空列表即可,其实不仅仅是非空列表,只要是一个非空的可迭代对象就行。而level如果是0,那么表示仅执行绝对导入,如果是一个正整数,表示要搜索的父目录的数量。一般这个值也不需要传递。
那这个方法有什么作用呢?假设如果我们有一个字符串a,其值为”pandas”,我想导入这个模块,该怎么做呢?显然就可以使用这种方式,但是这种方式导入的话,python官方不推荐使用__import__,而是希望我们使用一个叫做importlib的模块。
1 | import importlib |
扯了这么多,我们来看看之前源码中说的import_name。
1 | //ceval.c |
然后我们看到底层又调用了 *PyImport_ImportModuleLevelObject* ,我们来看一下它的实现。
1 | //Python/import.c |
另外关于module对象的导入方式,Python也提供了非常丰富的写法,比如:
1 | import numpy |
从import的目标来说,可以是”包”,也可以是模块。而模块可以通过py文件作为载体,也可以通过dll(pyd)或者so等二进制文件作为载体,下面我们就来一一介绍。
import机制的黑盒探测
同C++的namespace,Python通过模块和包来实现对系统复杂度的分解,以及保护名字空间不受污染。通过模块和包,我们可以将某个功能、某种抽象进行独立的实现和维护,在module对象的基础之上构建软件,这样不仅使得软件的架构清晰,而且也能很好的实现代码复用。
标准import
Python内建module
sys这个模块恐怕是使用最频繁的module对象之一了,我们就从这位老铁入手。Python中有一个内置函数dir,这个小工具是我们探测import的杀手锏。如果你在交互式环境下输入dir(),那么会打印当前local名字空间的所有符号,如果有参数,则将参数视为对象,输出该对象的所有属性。我们先来看看import动作对当前名字空间的影响:
1 | dir() |
我们看到当我们进行了import动作之后,当前的local名字空间增加了一个sys符号。而且通过type操作,我们看到这个sys符号指向一个module对象,我们说在底层它是一个PyModuleObject。当然虽然写着类型是<class 'module'>,但是我们在Python中是无法直接使用module这个类的。不过它既然是一个class,那么就一定继承object,并且元类为type。
1 | sys.__class__.__class__ |
这与我们的分析是一致的。言归正传,我们看到import机制影响了当前local名字空间,使得加载的module对象在local空间成为可见的。实际上,这和我们创建一个变量的时候,也会影响local名字空间。引用该module的方法正是通过module的名字,即这里的sys。
不过这里还有一个问题,我们来看一下:
1 | sys |
我们看到sys是内置的,说明模块除了真实存在文件之外,还可以内嵌在解释器里面。但既然如此,那为什么我们不能直接使用,还需要导入呢?其实不光是sys,在Python初始化的时候,就已经将一大批的module对象加载到了内存中。但是为了使得当前local名字空间能够达到最干净的效果,Python并没有将这些符号暴露在local名字空间中,而是需要用户显式的使用import机制来将这个符号引入到local名字空间中,才能让程序使用这个符号背后的对象。
我们知道,凡是加载进内存的module对象都保存在sys.modules里面,尽管当前的local空间里面没有,但是sys.modules里面是跑不掉的。
1 | import sys |
一开始这些module对象是不在local空间里面的,除非我们显式导入,但是即便我们导入,这些module对象也不会被二次加载,因为已经在初始化的时候就被加载到内存里面了。因此对于已经在sys.modules里面的module对象来说,导入的时候只是加到local空间里面去,所以代码中的os和os_的id是一样的。如果我们在Python启动之后,导入一个sys.modules中不存在的module对象,那么才会进行加载、然后同时进入local空间和sys.modules。
用户自定义module
我们知道,对于那些内嵌在解释器里面的module对象,如果import,只是将该module对象暴露在了local名字空间中。下面我们看看对于那些没有在初始化的时候加载到内存的module对象进行import的时候,会出现什么样动作。这里就以模块为例,当然正如我们之前说的,一个模块的载体可以是py文件或者二进制文件,py文件可以是自己编写的、也可以是标准库中的、或者第三方库中的。不过我们目前不区分那么多,通过自己编写的py文件作为例子,探探路。
1 | # a.py |
调用type的结果显示,import机制确实创建了一个新的module对象。而且也确实如我们之前所说,Python对a这个module对象或者模块,不仅将其引入进当前的local名字空间中,而且这个被动态加载的模块也在sys.module中拥有了一席之地,而且它们背后隐藏的是同一个PyModuleObject对象。然后我们再来看看这个module对象:
1 | import a |
这里可以看到,module对象内部实际上是通过一个dict在维护所有的module对象{名字: 属性值},里面有module的元信息(名字、文件路径)、以及module对象里面的内容。对,说白了,同class一样,module也是一个名字空间。
另外如果此时你查看a.py所在目录的__pycache__目录,你会发现里面有一个a.pyc,说明Python在导入的时候先生成了pyc,然后导入了pyc。并且我们通过dir(a)查看的时候,发现里面有一个__builtins__符号,那么这个__builtins__和我们之前说的那个__builtins__是一样的吗?
1 | import a |
尽管它们都叫__builtins__,但一个是module对象,一个是字典。我们通过__builtins__获取的是一个module对象,里面存放了int、str、globals等内建对象和内建函数等等,我们直接输入int、str、globals和通过__builtins__.int,__builtins__.str,__builtins__.globals的效果是一样的,我们输入__builtins__可以拿到这个内置模块,通过这个内置模块去获取里面的内容,当然也可以直接获取里面的内容,因为这些已经是全局的了。
但是a.__dict__["__builtins__"]是一个字典,这就说明两个从性质上就是不同的东西,但即便如此,就真的一点关系也没有吗?
1 | import a |
我们看到还是有一点关系的,和类、类的实例对象一样,每一个module对象也有自己的属性字典__dict__,记录了自身的元信息、里面存放的内容等等。对于a.__dict__["__builtins__"]来说,拿到的就是__builtins__.__dict__,所以说__builtins__是一个模块,但是这个模块有一个__dict__属性字典,而这个字典是可以通过module对象.__dict__["__builtins__"]来获取的,因为任何一个模块都可以使用__builtins__里面的内容,并且所有模块对应的__builtins__都是一样的。所以当你直接打印a.__dict__的时候会输出一大堆内容,因为输出的内容里面不仅有当前模块的内容,还有__builtins__.__dict__。
1 | import a |
所以可以把模块的属性字典,看成是local空间、内置空间的组合。
嵌套import
我们下面来看一下import的嵌套,所谓import的嵌套就是指,假设我import a,但是在a中又import b,我们来看看这个时候会发生什么有趣的动作。
1 | # a.py |
在a.py中导入sys,在另一个模块导入a,打印字节码指令,我们只看到了IMPORT_NAME 0 (a),似乎并没有看到a模块中的动作。我们说了,使用dis模块查看的字节码是分层级的,只能看到import a这个动作,a里面做了什么是看不到的。
1 | import a |
首先我们import a,那么a模块就在当前模块的属性字典里面了,我们通过a这个符号是可以直接拿到其对应的模块的。但是在a中我们又import sys,那么这个sys模块就已经在a模块对应的属性字典里面了,也就是说,我们这里通过a.sys是可以直接拿到sys模块的。但是,我们第二次导入sys的时候,会怎么样呢?首先我们在a中已经导入了sys,那么sys这个模块就已经在sys.modules里面了。那么当我们再导入sys的时候,就直接从sys.modules里面去找了,因此不会二次加载。为了更直观的验证,我们再举一个例子:
1 | # a.py |
以上是三个文件,每个文件只有一行代码:
1 | import a |
当导入一个不在sys.modules的模块时,会先从硬盘中加载相应的文件,然后逐行解释执行里面的内容,构建PyModuleObject对象,加入到sys.modules里面。当第二次导入的时候,直接将符号暴露在当前的local空间中,就不会再执行里面的内容了。
所以我们可以把sys.modules看成是一个大仓库,任何导入了的模块都在这里面。如果再导入的话,在sys.modules里面找到了,就直接返回即可,这样可以避免重复加载。
导入包
我们写的多个逻辑或者功能上相关的函数、类可以放在一个模块里面,那么多个模块是不是也可以组成一个包呢?如果说模块是管理class、函数、一些变量的机制,那么包就是管理模块的机制,当然啦,多个小的包又可以聚合成一个较大的包。
因此在Python中,模块是由一个单独的文件来实现的,可以是py文件、或者二进制文件。而对于包来说,则是一个目录,里面容纳了模块对应的文件,这种方式就是把多个模块聚合成一个包的具体实现。
现在我有一个名为test_import的模块,里面有一个a.py:

a.py内容如下
1 | a = 123 |
现在我们来导入它
1 | import test_import |
在Python2中,这样是没办法导入的,因为如果一个目录要成为Python中的包,那么里面必须要有一个__init__文件,但是在Python3中没有此要求。而且我们发现print之后,显示的也是一个module对象,因此Python对于模块和包的底层定义其实是很灵活的,并没有那么僵硬。
1 | import test_import |
然而此时神奇的地方出现了,我们调用test_import.a的时候,告诉我们没有a这个属性。很奇怪,我们的test_import里面不是有a.py吗?首先python导入一个包,会先执行这个包的__init__文件,只有在__init___文件中导入了,我们才可以通过包名来调用。如果这个包里面没有__init__文件,那么你导入这个包,是什么属性也用不了的。光说可能比较难理解,我们来演示一下。我们先来创建__init__文件,但是里面什么也不写。
1 | import test_import |
此时我们又看到了神奇的地方,我们在test_import目录里面创建了__init__文件之后,再打印test_import,得到结果又变了,告诉我们这个包来自于该包里面的__init__文件。所以就像我们之前说的,Python对于包和模块的概念区分的不是很明显,我们把包就当做该包下面的__init__文件即可,这个__init__中定义了什么,那么这个包里面就有什么。
1 | # test_import/__init__.py |
from . import a这句话表示导入test_import这个下面的a.py,但是直接像import sys那样import a不行吗?答案是不行的,至于为什么我们后面说。我们在__init__.py中导入了sys模块、a模块,定义了name属性,那么就等于将sys、a、name加入到了test_import这个包的local空间里面去了。因为我们说过,对于Python中的包,那么其等价于里面的__init__文件,这个文件有什么,那么这个包就有什么。既然我们在__init__.py中导入了sys、a模块,定义了name,那么这个文件的属性字典里面、或者也可以说local空间里面就有了"sys": sys, "a": a, "name": "satori"这三个entry,而我们又说了__init__.py里面有什么,那么通过包名就能够调用什么。所以:
1 | import test_import |
相对导入与绝对导入
我们刚才使用了一个from . import a的方式,这个.表示当前文件所在的目录,这行代码就表示,我要导入a这个模块,不是从别的地方导入,而是从该文件所在的目录里面导入。如果是..就表示该目录的上一层目录,三个.、四个.依次类推。我们知道a模块里面还有一个a这个变量,那如果我想在__init__.py中导入这个变量该怎么办呢?直接from .a import a即可,表示导入当前目录里面的a模块里面的a变量。如果我们导入的时候没有.的话,那么表示绝对导入,Python虚拟机就会按照sys.path定义的路径去找。假设我们在__init__.py当中写的是不是from . import a,而是import a,那么会发生什么后果呢?
1 | import test_import |
我们发现报错了,告诉我们没有a这个模块,可是我们明明在module包里面定义了呀。还记得之前说的导入一个模块、导入一个包会做哪些事情吗?导入一个模块,会将该模块里面”拿过来”执行一遍,导入包会将该包里面的__init__.py文件”拿过来”执行一遍。注意:我们把”拿过来”三个字加上了引号。
我们在test_import同级目录的py文件中导入了test_import,那么就相当于把里面的__init__拿过来执行一遍(当然只有第一次导入的时候才会这么做),然后它们具有单独的空间,是被隔离的,调用需要使用符号test_import来调用。但是正如我们之前所说,是”拿过来”执行,所以这个__init__.py里面的内容是”拿过来”,在当前的py文件(在哪里导入的就是哪里)中执行的。所以由于import a这行代码表示绝对导入,就相当于在当前模块里面导入,会从sys.path里面搜索,但是a是在test_import包里面,那么此时还能找到这个a吗?显然是不能的。那from . import a为什么就好使呢?因为这种导入表示相对导入,就表示要在__init__.py所在目录里面找,那么不管在什么地方导入这个包,由于这个__init__.py的位置是不变的,所以from . import a这种相对导入的方式总能找到对应的a。至于标准库、第三方模块、第三方包,因为它是在sys.path里面的,在哪儿都能找得到,所以可以绝对导入,貌似也只能绝对导入。并且我们知道每一个模块都有一个__file__属性(除了内嵌在解释器里面的模块),当然包也是。如果你在一个模块里面print(__file__),那么不管你在哪里导入这个模块,打印的永远是这个模块的路径;包的话,则是指向内部的__init__.py文件。
另外关于相对导入,一个很重要的一点,一旦一个模块出现了相对导入,那么这个模块就不能被执行了,它只可以被导入。
1 | import sys |
此时如果我试图执行__init__.py,那么就会给我报出这个错误。另外即便导入一个内部具有”相对导入”的模块,那么此模块和导入的模块也不能在同一个包内,我们要执行的当前模块至少要在导入模块的上一级,否则执行的当前模块也会报出这种错误。为什么会有这种情况,很简单。想想为什么会有相对导入,就是希望这些模块在被其它地方导入的时候能够准确记住要导入的包的位置。那么这些模块肯定要在一个共同的包里面,然后我们在包外面使用。所以我们导入一个具有相对导入的模块时候,那么我们当前模块和要导入的模块绝对不能在同一个包里面。
import的另一种方式
我们要导入test_import包里面的a模块,除了可以import test_import(_init__.py里面导入了a),还可以通过import test_import.a的方式,另外如果是这种导入方式,那么module里面可以没有__init__.py文件,因为我们导入test_import包的时候,是通过test_import来获取a,所以必须要有__init__.py文件、并且里面导入a。但是在导入test_import.a的时候,就是找test_import.a,所以此时是可以没有__init__.py文件的。
1 | # test_import/__init__.py |
此时test_import包里面的__init__.py只定义了一个变量,下面我们来通过test_import.a的形式导入。
1 | import test_import.a |
惊了,我们在导入test_import.a的时候,也把test_import导入进来了,为了更直观的看到现象,我们在__init__.py里面打印一句话。
1 | # test_import/__init__.py |
所以一个有趣的现象就产生了,我们是导入test_import.a,但是把test_import也导入进来了。而且通过打印的顺序,我们看到是先导入了test_import,然后再导入test_import下面的a。如果我们在__init__.py中也导入了a会怎么样?
1 | # test_import/__init__.py |
所以通过test_import.a的方式来导入,即使没有__init__.py文件依旧是可以访问的,因为这是我在import的时候指定的。我们可以看一下sys.modules
1 | import test_import.a |
不过问题来了,为什么在导入test_import.a的时候,会将test_import也导入了进来呢?并且还可以直接使用test_import,毕竟这不是我们期望的结果,因为导入test_import.a的话,那么我们只是想使用test_import.a,不打算使用test_import,那么Python为什么要这么做呢?
事实上,这对Python而言是必须的,根据我们对Python虚拟机的执行原理的了解,Python要想执行test_import.a,那么肯定要先从local空间找到test_import,然后才能找到a,如果不找到test_import的话,那么对a的查找也就无从谈起。可问题是sys.modules里面是
test_import.a啊,这是一个整体啊。事实上尽管是一个整体,但并不是说有一个模块,这个模块就叫做test_import.a。准确的说import test_import.a表示先导入test_import,然后再将test_import下面的a加入到test_import的属性字典里面。我们说当module这个包里面没有__init__.py的时候,那个这个包是无法使用的,因为属性字典里面没有相关属性,但是当我们import test_import.a的时候,Python会先导入test_import这个包,然后自动帮我们把a这个模块加入到module这个包的属性字典里面。但之所以会有”test_import.a”这个key,显然也是为了解决重复导入的问题。
假设test_import这个包里面有a和b两个py文件,那么我们执行import test_import.a和import test_import.b会进行什么样的动作应该就了如指掌了吧。执行import test_import.a,那么会先导入test_import,然后把a加到test_import的属性字典里面,执行import test_import.b,还是会先导入包test_import,但是包test_import在上一步已经被导入了,所以此时直接会从sys.modules里面获取,然后再把b加入到test_import的属性字典里面。所以如果__init__.py里面有一个print的话,那么两次导入显然只会print一次,这种现象是由Python对包中的模块的动态加载机制决定的。还是那句话,一个包你就看成是里面的__init__.py文件即可,Python对于包和模块的区分不是特别明显。
1 | # test_import目录下有__init__.py文件 |
我们看到如果包里面有__init__.py文件,那么这个包的__file__属性就是其内部的__init__.py文件,打印这个包,显示的也是其内部的__init__.py模块。如果没有__init__.py文件,那么这个包的__file__就是一个None,打印这个包,显示其是一个名字空间。另外,我们知道任何一个模块(即使里面什么也不写)的属性字典里面都是有__builtins__属性的,因为可以直接使用内置的对象、函数等等。而__init__.py也是属于一个模块,所以它也有__builtins__属性的,由于一个包指向了内部的__init__.py,所以这个包的属性字典也是有__builtins__属性的。但如果这个包没有__init__.py文件,那么这个包是没有__builtins__属性的。
1 | # 没有__init__.py文件 |
路径搜索树
假设我有这样的一个目录结构:

那么Python会将这个结构进行分解,得到一个类似于树状的节点集合:
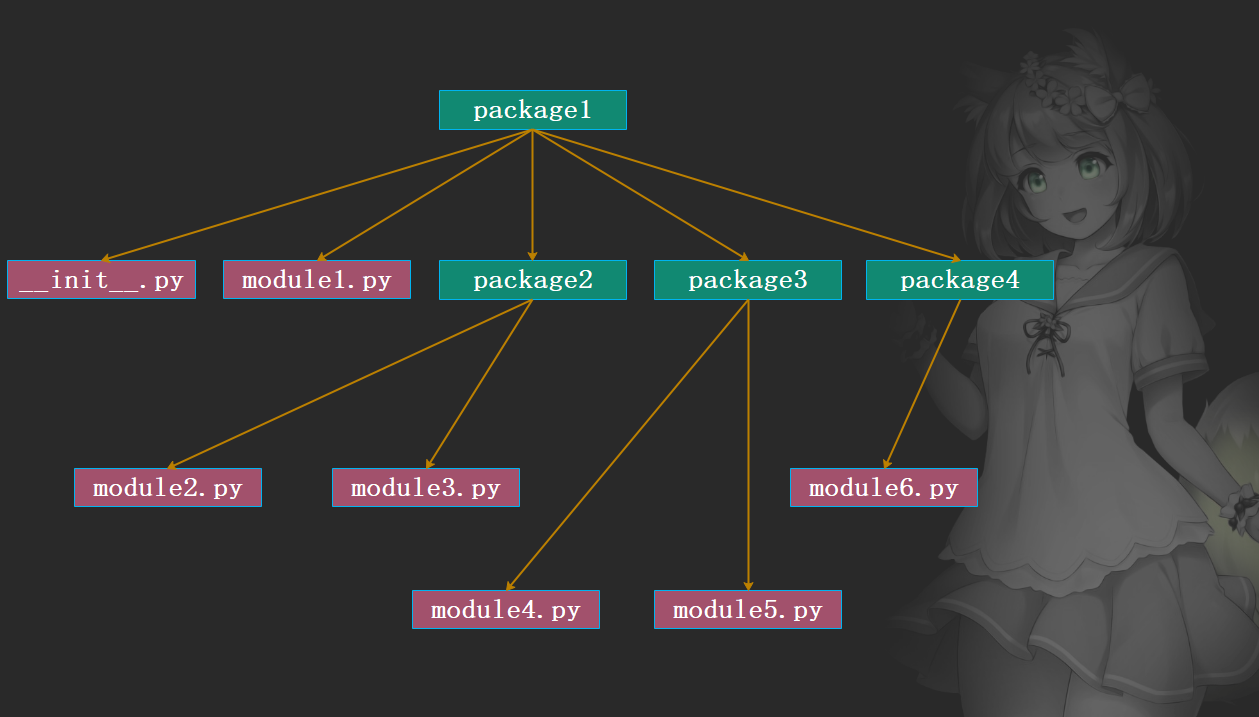
然后从左到右依次去sys.modules中查找每一个符号所对应的module对象是否已经被加载,如果一个包被加载了,比如说包test_import被加载了,那么在包test_import对应的PyModuleObject中会维护一个元信息__path__,表示这个包的路径。比如我搜索A.a,当加载进来A的时候,那么a只会在A.__path__中进行,而不会在Python的所有搜索路径中执行了。
1 | import test_import |
from与import
在Python的import中,有一种精确控制所加载的对象的方法,通过from和import的结合,可以只将我们期望的module对象、甚至是module对象中的某个符号,动态地加载到内存中。这种机制使得Python虚拟机在当前名字空间中引入的符号可以尽可能地少,从而更好地避免名字空间遭到污染。
按照我们之前所说,导入test_import下面的a模块,我们可以使用import test_import.a的方式,但是此时a是在test_import的名字空间中,不是在我们当前模块的名字空间中。也就是说我们希望能直接通过符号a来调用,而不是test_import.a,此时通过from ... import ...联手就能完美解决。
1 | from test_import import a |
我们看到,确确实实将a这个符号加载到当前的名字空间里面了,但是在sys.modules里面却没有a。还是之前说的,a这个模块是在test_import这个包里面的,你不可能不通过包就直接拿到包里面的模块,因此在sys.modules里面的形式其实还是test_import.a这样形式,只不过在当前模块的名字空间中是a,a被映射到sys.modules[“test_import.a”],另外我们看到除了test_import.a,test_import也导入进来了,这个原因我们之前也说过了,不再赘述。所以我们发现即便我们是from ... import ...,还是会触发整个包的导入。只不过我们导入谁(假设从a导入b),就把谁加入到了当前模块的名字空间里面(但是在sys.modules里面是没有b的,而是a.b),并映射到sys.modules[“a.b”]。
所以我们见识到了,即便是我们通过from test_import import a,还是会导入test_import这个包的,只不过test_import这个包是在sys.modules里面,并没有暴露到local空间中。
此外我们from test_import import a,导入的这个a是一个模块,但是模块a里面还有一个变量a,我们不加from,只通过import的话,那么最深也只能import到一个模块,不可能说直接import模块里面的某个变量、方法什么的。但是from ... import ...的话,却是可以的,比如我们from test_import.a import a,这句就表示我要导入test_import.a模块里面变量a。
1 | from test_import.a import a |
我们导入的a是一个变量,并不是模块,所以sys.modules里面不会出现test_import.a.a这样的东西存在,但是这个a毕竟是从test_import.a里面导入的,所以test_import.a是会在sys.modules里面的,同理test_import.a表示从test_import的属性字典里面找a,所以test_import也是会进入sys.modules里面的。
最后还可以使用from test_import.a import *,这样的机制把一个模块里面所有的内容全部导入进来,本质和导入一个变量是一致的。但是在Python中有一个特殊的机制,比如我们from test_import.a import *,如果a里面定义了__all__,那么只会导入__all__里面指定的属性。
1 | # test_import/a.py |
我们注意到在__all__里面只指定了a和b,那么后续通过from test_import.a import \*的时候,只会导入a和b,而不会导入c。
1 | from test_import.a import * |
我们注意到:通过from ... import \*导入的时候,是无法导入c的,因为c没有在__all__中。但是即便如此,我们也可以通过单独导入,把c导入进来。只是不推荐这么做,像pycharm这种智能编辑器也会提示:'c' is not declared in __all__。因为既然没有在__all__里面,就证明这个变量是不希望被导入的,但是一般导入了也没关系。
符号重命名
我们导入的时候一般为了解决符号冲突,往往会起别名,或者说符号重命名。比如包a和包b下面都有一个模块叫做m,如果是from a import m和from b import m的话,那么两者就冲突了,后面的m会把上面的m覆盖掉,不然Python怎么知道要找哪一个m。所以这个时候我们会起别名,比如from a import m as m1、from b import m as m2,但是from a import \*是不支持as的。所以直接Python都是将module对象内部所以符号都暴露给了local名字空间,而符号重命名则是Python可以通过as关键字控制包、模块、变量暴露给local名字空间的方式。
1 | import test_import.a as a |
到结论我相信就应该心里有数了,不管我们有没有as,既然import test_import.a,那么sys.modules里面就一定有test_import.a,和test_import。其实理论上有包test_import就够了,但是我们说a是一个模块,为了避免多次导入所以也要加到sys.modules里面,而且a又是test_import包里面,所以是test_import.a。而我们这里as a,那么a这个符号就暴露在了当前模块的local空间里面,而且这个a就跟之前的test_import.a一样,指向了test_import包下面的a模块,无非是名字不同罢了。当然这不是重点,我们之前通过import test_import.a的时候,会自动把test_import也加入到当前模块的local空间里面,也就是说通过import test_import.a是可以直接使用test_import的,但是当我们加上了as之后,发现test_import包已经不能访问了。尽管都在sys.modules里面,但是对于加了as来说,此时的test_import这个包已经不在local名字空间里面了。一个as关键字,导致了两者的不同,这是什么原因呢?我们后面分解。
符号的销毁与重载
为了使用一个模块,无论是内置的还是自己写的,都需要import动态加载到内存,使用之后,我们也可能会删除,删除的原因一般是释放内存啊等等。在python中,删除一个对象可以使用del关键字,遇事不决del。
1 | l = [1, 2, 3] |
不光是列表、字典,好多东西del都能删除,甚至是删除某一个位置的值、或者方法。我们看到类的一个方法居然也能使用del删除,但是对于module对象来说,del能做到吗?显然是可以做到的,或者更准确的说法是符号的销毁和符号关联的对象的销毁是一个概念吗?Python已经向我们隐藏了太多的动作,也采取了太多的缓存策略,当然对于Python的使用者来说是好事情,因为把复杂的特性隐藏起来了,但是当我们想彻底的了解Python的行为时,则必须要把这些隐藏的东西挖掘出来。
1 | import test_import.a as a |
我们看到在del之后,a这个符号确实从local空间消失了,或者说dir已经看不到了。但是后面我们发现,消失的仅仅是a这个符号,至于test_import.a指向的PyModuleObject依旧在sys.modules里面岿然不动。然而,尽管它还存在于Python系统中,但是我们的程序再也无法感知到,但它就在那里不离不弃。所以此时Python就成功地向我们隐藏了这一切,我们的程序认为:test_import.a已经不存在了。
不过为什么Python要采用这种看上去类似模块池的缓存机制呢?因为组成一个完整系统的多个py文件可能都要对某个module对象进行import动作。所以要是从sys.modules里面删除了,那么就意味着需要重新从文件里面读取,如果不删除,那么只需要从sys.modules里面暴露给当前的local名字空间即可。所以import实际上并不等同我们所说的动态加载,它的真实含义是希望某个模块被感知,也就是”将这个模块以某个符号的形式引入到某个名字空间”。这些都是同一个模块,如果import等同于动态加载,那么Python对同一个模块执行多次动态加载,并且内存中保存一个模块的多个镜像,这显然是非常愚蠢的。
所以Python引入了全局的module对象集合–sys.modules,这个集合作为模块池,保存了模块的唯一值。当某个模块通过import声明希望感知到某个module对象时,Python将在这个池子里面查找,如果被导入的模块已经存在于池子中,那么就引入一个符号到当前模块的名字空间中,并将其关联到导入的模块,使得被导入的模块可以透过这个符号被当前模块感知到。而如果被导入的模块不在池子里,Python这才执行动态加载的动作。
如果这样的话,难道一个模块在被加载之后,就不能改变了。假如在加载了模块a的时候,如果我们修改了模块a,难道Python程序只能先暂停再重启吗?显然不是这样的,python的动态特性不止于此,它提供了一种重新加载的机制,使用importlib模块,通过importlib.reload(module),可以实现重新加载并且这个函数是有返回值的,返回加载之后的模块。
1 | import sys |
首先我们的a模块里面啥也没有,但是我们在a.py里面增加了name变量,然后重新加载模块,所以a.name正确打印。然后我们在a.py再删除name属性,然后重新加载,但是我们看到name变量还在里面,还可以被调用。
那么根据这个现象我们是不是可以大胆猜测,python在reload一个模块的时候,只是将模块里面新的符号加载进来,而删除的则不管了,那么这个猜测到底正不正确呢,别急我们下面就来揭晓,并通过源码来剖析import的实现机制。
import机制的实现
从前面的黑盒探测我们已经对import机制有了一个非常清晰的认识,python的import机制基本上可以切分为三个不同的功能。
python运行时的全局模块池的维护和搜索解析与搜索模块路径的树状结构对不同文件格式的模块的动态加载机制
尽管import的表现形式千变万化,但是都可以归结为:import x.y.z的形式。因为import sys也可以看成是x.y.z的一种特殊形式。而诸如from、as与import的结合,实际上同样会进行import x.y.z的动作,只是最后在当前名字空间中引入符号时各有不同。所以我们就以import x.y.z的形式来进行分析。
我们说导入模块,是调用__import__,那么我们就来看看这个函数长什么样子。
1 | static PyObject * |
另外,PyArg_ParseTupleAndKeywords这个函数在python中是一个被广泛使用的函数,原型如下:
1 | //Python/getargs.c |
这个函数的目的是将args和kwds中所包含的所有对象按format中指定的格式解析成各种目标对象,可以是Python中的对象(PyListObject、PyLongObject等等),也可以是C的原生对象。
我们知道这个args实际上是一个PyTupleObject对象,包含了__import__函数运行所需要的参数和信息,它是Python虚拟机在执行IMPORT_NAME的时候打包而产生的,然而在这里,Python虚拟机进行了一个逆动作,将打包后的这个PyTupleObject拆开,重新获得当初的参数。Python在自身的实现中大量的使用了这样打包、拆包的策略,使得可变数量的对象能够很容易地在函数之间传递。
在解析参数的过程中,指定解析格式的format中可用的格式字符有很多,这里只看一下__import__用到的格式字符。其中s代表目标对象是一个char *,通常用来将元组中的PyUnicodeObject对象解析成char *,i则用来将元组中的PyLongObject解析成int,而O则代表解析的目标对象依然是一个Python中的合法对象,通常这表示 *PyArg_ParseTupleAndKeywords* 不进行任何的解析和转换,因为在PyTupleObject对象中存放的肯定是一个python的合法对象。至于|和:,它们不是非格式字符,而是指示字符,|指示其后所带的格式字符是可选的。也就是说,如果args中只有一个对象,那么__import__对 *PyArg_ParseTupleAndKeywords* 的调用也不会失败。其中,args中的那个对象会按照s的指示被解析为char *,而剩下的globals、locals、fromlist则会按照O的指示被初始化为Py_None,level是0。而:则指示”格式字符”到此结束了,其后所带字符串用于在解析过程中出错时,定位错误的位置所使用的。
在完成了对参数的拆包动作之后,然后进入了 *PyImport_ImportModuleLevelObject* ,这个我们在import_name中已经看到了,而且它也是先获取__builtin__里面的__import__函数指针。
另外每一个包和模块都有一个__name__和__path__属性
1 | import numpy as np |
__name__就是模块或者包名,如果包下面的包或者模块,那么就是包名.包名或者包名.模块名,至于__path__则是包所在的路径。但是这个和__file__又是不一样的,如果是__file__则是指向内部的__init__.py文件,没有则为None。但是对于模块来说,则没有__path__。
精力有限,具体的不再深入。我们下面从python的角度来理解一下吧
Python中的import操作
import 模块
1 | import sys |
这是我们一开始考察的例子,现在我们已经很清楚地了解了IMPORT_NAME的行为,在IMPORT_NAME指令的最后,python虚拟机会将PyModuleObject对象压入到运行时栈内,随后会将(sys, PyModuleObject)存放到当前的local名字空间中。
import 包
1 | import sklearn.linear_model.ridge |
这是我们一开始考察的例子,现在我们已经很清楚地了解了IMPORT_NAME的行为,在IMPORT_NAME指令的最后,python虚拟机会将PyModuleObject对象压入到运行时栈内,随后会将(sys, PyModuleObject)存放到当前的local名字空间中。
如果涉及的是对包的import动作,那么IMPORT_NAME的指令参数则是关于包的完整路径信息,IMPORT_NAME指令的内部将解析这个路径,并为sklearn、sklearn.linear_model,sklearn.linear_model.ridge都创建一个PyModuleObject对象,这三者都存在于sys.modules里面。但是我们看到STORE_NAME是sklearn,表示只有sklearn对应的PyModuleObject放在了当前模块的local空间里面,可为什么是sklearn呢?难道不应该是sklearn.linear_model.ridge吗?其实经过我们之前的分析这一点已经不再是问题了,因为import sklearn.linear_model.ridge并不是说导入一个模块或包叫做sklearn.linear_model.ridge,而是先导入sklearn,然后把linear_model放在sklearn的属性字典里面,把ridge放在linear_model的属性字典里面。同理sklearn.linear_model.ridge代表的是先从local空间里面找到sklearn,再从sklearn的属性字典中找到linear_model,然后在linear_model的属性字典里面找到ridge。而我们说,linear_model和ridge已经在对应的包的属性字典里面的了,我们通过sklearn一级一级往下找是可以找到的,因此只需要把skearn返回即可,或者说返回sklearn.linear_model.ridge本身就是不合理的,因为这表示导入一个名字就叫做sklearn.linear_model.ridge的模块或者包,但显然不存在,即便我们创建了,但是由于python的语法解析规范依旧不会得到想要的结果。不然的话,假设import test_import.a,那Python是导入名为test_import.a的模块或包呢?还是导入test_import下的a呢?
也正如我们之前分析的test_import.a,我们import test_import.a的时候,会把test_import加载进来,然后把a加到test_import的属性字典里面,然后只需要把test_import返回即可,因为我们通过test_import是可以找到a,而且也不存在我们期望的test_import.a,因为这个test_import.a代表的含义是从test_import的属性字典里面获取a,所以import test_import.a是必须要返回test_import的,而且只返回了test_import。至于sys.modules(一个字典)里面是存在字符串名为test_import.a的key的,这是为了避免重复加载所采取的策略,但它依旧表示从test_import里面获取a。
1 | import pandas.core |
from & import
1 | from sklearn.linear_model import ridge |
注意此时的LOAD_CONST 1不再是None了,而是一个元组。此时Python是将ridge放到了当前模块的local空间中,并且sklearn、sklearn.linear_model都被导入了,并且存在于sys.modules里面,但是sklearn却并不在当前local空间中,尽管这个对象被创建了,但是它被Python隐藏了。IMPORT_NAME是sklearn.linear_model,也表示导入sklearn,然后把sklearn下面的linear_model加入到sklearn的属性字典里面。其实sklearn没在local空间里面,还可以这样理解。只有import的时候,那么我们必须从头开始一级一级向下调用,所以顶层的包必须加入到local空间里面,但是from sklearn.linear_model import ridge是把ridge导出,此时ridge已经指向了sklearn下面的linear_model下面的ridge,那么此时就不需要sklearn了,或者说sklearn就没必要暴露在local空间里面了。并且sys.modules里面也不存在ridge这个key,存在的是sklearn.linear_model.ridge,暴露给当前模块的local空间里面的符号是ridge
import & as
1 | import sklearn.linear_model.ridge as xxx |
这个和带有from的import类似,sklearn,sklearn.linear_model,sklearn.linear_model.ridge都在sys.modules里面,但是我们加上了as xxx,那么这个xxx就直接指向了sklearn下面的linear_model下面的ridge,就不需要sklearn了。这个和上面的from & import类似,只有xxx暴露在了当前模块的local空间里面,sklearn虽然在sys.modules里面,但是在当前模块就无法访问了。
from & import & as
1 | from sklearn.linear_model import ridge as xxx |
这个我想连字节码都不需要贴了,和之前from & import一样,只是最后暴露给当前模块的local空间的ridge变成了我们自己指定的xxx。
与module对象有关的名字空间问题
同函数、类一样,每个PyModuleObject也是有自己的名字空间的。一个模块不能直接访问另一个模块的内容,尽管模块内部的作用域比较复杂,比如:遵循LEGB规则,但是模块与模块之间的划分则是很明显的。
1 | # test1.py |
执行test2.py之后,发现打印的依旧是”夏色祭”。我们说Python是根据LEGB规则,而print_name里面没有name,那么去外层找,test2.py里面的name是”神乐mea”,但是找到的依旧是test1.py里面的”夏色祭”。为什么?
还是那句话,模块与模块之间的作用域划分的非常明显,print_name是test1.py里面的函数,所以在返回name的时候,只会从test1.py中搜索,无论如何都是不会跳过test1.py、跑到test2.py里面的。
再来看个栗子:
1 | # test1.py |
很简单,直接把test1里面的变量修改了。因为这种方式,相当于直接修改test1内部的属性字典。
1 | # test1.py |
如果是from test1 import name, nicknames,那么相当于在当前的local空间中创建一个变量name和nicknames指向对应的对象。name = “神乐mea”相当于重新赋值了,而nicknames.remove则是在本地进行修改。
小结
总的来说,Python中module对象的导入还是很简单的,所以我们也没有涉及太多关于源码的知识。