24-Python运行时的环境初始化
楔子
我们之前分析了Python的核心–字节码、以及虚拟机的剖析工作,但这仅仅只是一部分,而其余的部分则被遮在了幕后。记得我们在分析虚拟机的时候,曾这么说过:
当Python启动后,首先会进行 “运行时环境” 的初始化,而关于 “运行时环境” 的初始化是一个非常复杂的过程。并且 “运行时环境” 和 “执行环境” 是不同的, “运行时环境” 是一个全局的概念,而 “执行环境” 是一个栈帧。关于”运行时环境”我们后面将用单独的一章进行剖析,这里就假设初始化动作已经完成,我们已经站在了Python虚拟机的门槛外面,只需要轻轻推动一下第一张骨牌,整个执行过程就像多米诺骨牌一样,一环扣一环地展开。
所以这次,我们将回到时间的起点,从Python的应用程序被执行开始,一步一步紧紧跟随Python的轨迹,完整地展示Python在启动之初的所有动作。当我们根据Python完成所有的初始化动作之后,也就能对Python执行引擎执行字节码指令时的整个运行环境了如执掌了。
线程环境初始化
我们知道线程是操作系统调度的最小单元,那么Python中的线程又是怎么样的呢?
线程模型
我们之前介绍栈帧的时候说过,通过Python启动一个线程,那么底层会通过C来启动一个线程,然后启动操作系统的一个原生线程(OS线程)。所以Python中的线程实际上是对OS线程的一个封装,因此Python中的线程是货真价实的。
然后Python还提供了一个PyThreadState(线程状态)对象,维护OS线程执行的状态信息,相当于是OS线程的一个抽象描述。虽然真正用来执行的线程及其状态肯定是由操作系统进行维护的,但是Python虚拟机在运行的时候总需要另外一些与线程相关的状态和信息,比如是否发生了异常等等,这些信息显然操作系统是没有办法提供的。而PyThreadState对象正是Python为OS线程准备的、在虚拟机层面保存其状态信息的对象,也就是线程状态对象。而在Python中,当前活动的OS线程对应的PyThreadState对象可以通过PyThreadState_GET获得,有了线程状态对象之后,就可以设置一些额外信息了。具体内容,我们后面会说。
当然除了线程状态对象之外,还有进程状态对象,我们来看看两者在Python底层的定义是什么?它们位于 *Include/pystate.h* 中。
1
2
| typedef struct _is PyInterpreterState;
typedef struct _ts PyThreadState;
|
里面的 *PyInterpreterState* 表示进程状态对象, *PyThreadState* 表示线程状态对象。但是我们看到它们都是typedef起得一个别名,而定义的结构体 *struct _is* 位于 *Include/cpython/pystate.h* 中, *struct _ts* 位于 *Include/internal/pycore_pystate.h*中。
线程状态对象:
1
2
3
4
5
6
7
8
9
10
11
12
| struct _ts {
struct _ts *prev;
struct _ts *next;
PyInterpreterState *interp;
struct _frame *frame;
int recursion_depth;
uint64_t id;
};
|
进程状态对象:
1
2
3
4
5
6
7
8
9
| struct _is {
struct _is *next;
struct _ts *tstate_head;
int64_t id;
PyObject *audit_hooks;
};
|
我们说 *PyInterpreterState* 对象是对进程的模拟, *PyThreadState* 是对线程的模拟。我们之前分析虚拟机的时候说过其执行环境,如果再将运行时环境加进去的话。
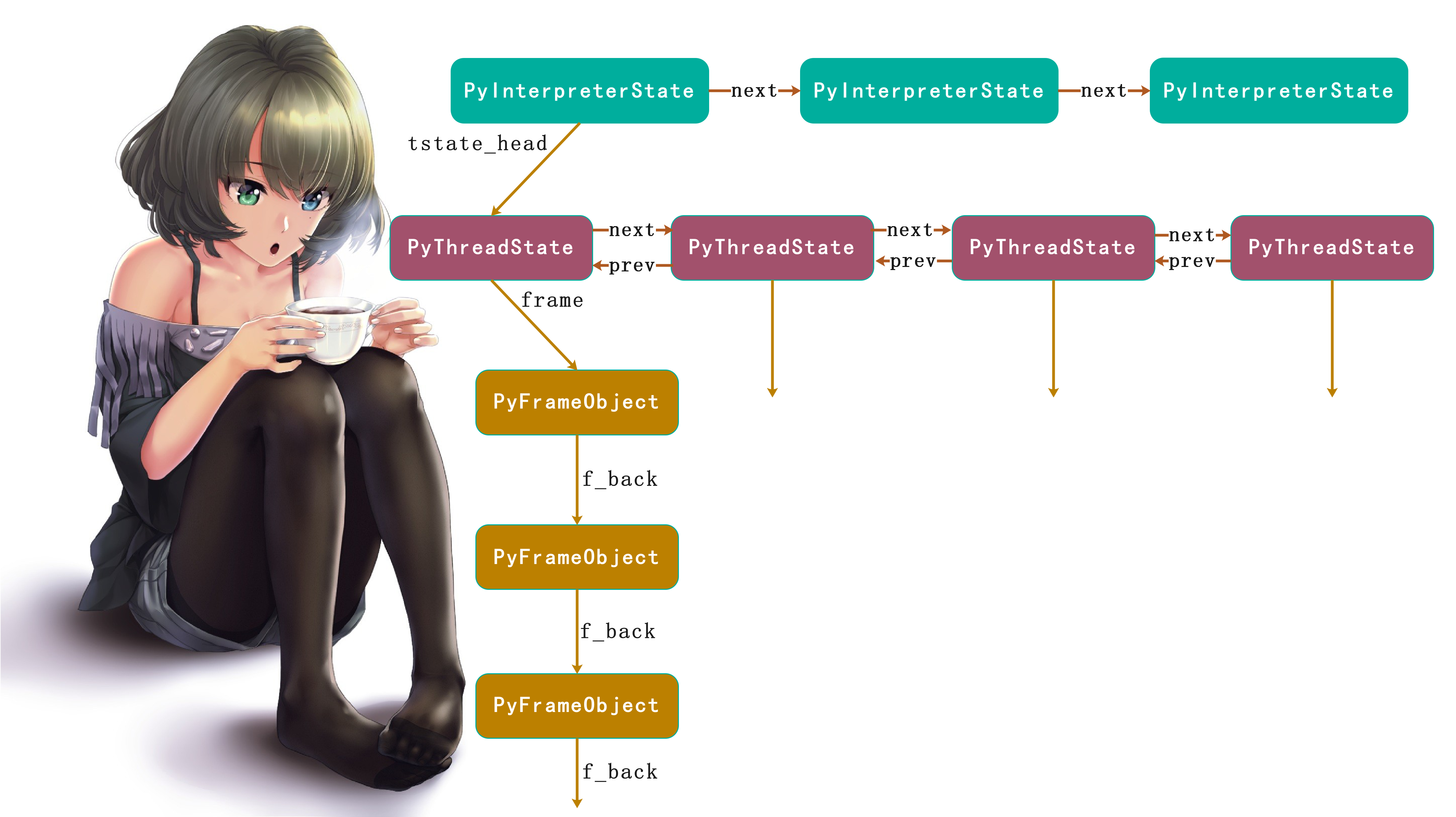
线程环境的初始化
在Python启动之后,初始化的动作是从 *Py_NewInterpreter* 函数开始的,然后这个函数调用了 *new_interpreter* 函数完成初始化,我们分析会先从 *new_interpreter* 函数开始,当然 *Py_NewInterpreter* 里面也做了一些工作,具体的后面会说。
我们知道在Windows平台上,当执行一个可执行文件时,操作系统首先创建一个进程内核。同理在Python中亦是如此,会在 *new_interpreter* 中调用 *PyInterpreterState_New* 创建一个崭新的 *PyInterpreterState*对象。该函数位于 *Python/pystate.c* 中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| PyInterpreterState *
PyInterpreterState_New(void)
{
PyInterpreterState *interp = PyMem_RawMalloc(sizeof(PyInterpreterState));
if (interp == NULL) {
return NULL;
}
return interp;
}
|
关于进程状态对象我们不做过多解释,只需要知道Python解释器在启动时,会创建一个、或者多个 *PyInterpreterState* 对象,然后通过内部的next指针将多个 *PyInterpreterState* 串成一个链表结构。
在调用 *PyInterpreterState_New* 成功创建 *PyInterpreterState*之后,会再接再厉,调用 *PyThreadState_New* 创建一个全新的线程状态对象,相关函数定义同样位于 *Python/pystate.c* 中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
| PyThreadState *
PyThreadState_New(PyInterpreterState *interp)
{
return new_threadstate(interp, 1);
}
static PyThreadState *
new_threadstate(PyInterpreterState *interp, int init)
{
_PyRuntimeState *runtime = &_PyRuntime;
PyThreadState *tstate = (PyThreadState *)PyMem_RawMalloc(sizeof(PyThreadState));
if (tstate == NULL) {
return NULL;
}
if (_PyThreadState_GetFrame == NULL) {
_PyThreadState_GetFrame = threadstate_getframe;
}
tstate->interp = interp;
tstate->frame = NULL;
tstate->recursion_depth = 0;
tstate->id = ++interp->tstate_next_unique_id;
tstate->prev = NULL;
tstate->next = interp->tstate_head;
if (tstate->next)
tstate->next->prev = tstate;
interp->tstate_head = tstate;
return tstate;
}
|
和 *PyInterpreterState_New* 相同, *PyThreadState_New* 申请内存,创建 *PyThreadState* 对象,并且对其中每个成员进行初始化。而且其中的prev指针和next指针分别指向了上一个线程状态对象和下一个线程状态对象。而且也肯定会存在某一时刻,存在多个 *PyThreadState* 对象形成一个链表,那么什么时刻会发生这种情况呢?显然用鼻子想也知道这是在Python启动多线程(下一章分析)的时候。
此外我们看到Python在插入线程状态对象的时候采用的是头插法。
我们说Python设置了从线程中获取函数调用栈的操作,所谓函数调用栈就是我们前面章节说的PyFrameObject对象链表。而且在源码中,我们看到了 *PyThreadState* 关联了 *PyInterpreterState* , *PyInterpreterState* 也关联了 *PyInterpreterState* 。到目前为止,仅有的两个对象建立起了联系。对应到Windows,或者说操作系统,我们说进程和线程建立了联系
在 *PyInterpreterState* 和 *PyThreadState* 建立了联系之后,那么就很容易在 *PyInterpreterState* 和*PyThreadState* 之间穿梭。并且在Python运行时环境中,会有一个变量(先买个关子)一直维护着当前活动的线程,更准确的说是当前活动线程(OS线程)对应的 *PyThreadState* 对象。初始时,该变量为NULL。在Python启动之后创建了第一个 *PyThreadState* 之后,会用该 *PyThreadState* 对象调用 *PyThreadState_Swap* 函数来设置这个变量,函数位于 *Python/pystate.c* 中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| PyThreadState *
PyThreadState_Swap(PyThreadState *newts)
{
return _PyThreadState_Swap(&_PyRuntime.gilstate, newts);
}
PyThreadState *
_PyThreadState_Swap(struct _gilstate_runtime_state *gilstate, PyThreadState *newts)
{
PyThreadState *oldts = _PyRuntimeGILState_GetThreadState(gilstate);
_PyRuntimeGILState_SetThreadState(gilstate, newts);
return oldts;
}
#define _PyRuntimeGILState_GetThreadState(gilstate) \
((PyThreadState*)_Py_atomic_load_relaxed(&(gilstate)->tstate_current))
#define _PyRuntimeGILState_SetThreadState(gilstate, value) \
_Py_atomic_store_relaxed(&(gilstate)->tstate_current, \
(uintptr_t)(value))
|
然后我们看到这两个宏里面出现了 *_Py_atomic_load_relaxed* 、 *_Py_atomic_store_relaxed* 和 *&(gilstate)->tstate_current* ,这些又是什么呢?还有到底哪个变量在维护这当前的活动线程对应的状态对象呢?其实那两个宏已经告诉你了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
struct _gilstate_runtime_state {
_Py_atomic_address tstate_current;
};
#define _Py_atomic_load_relaxed(ATOMIC_VAL) \
_Py_atomic_load_explicit((ATOMIC_VAL), _Py_memory_order_relaxed)
#define _Py_atomic_store_relaxed(ATOMIC_VAL, NEW_VAL) \
_Py_atomic_store_explicit((ATOMIC_VAL), (NEW_VAL), _Py_memory_order_relaxed)
#define _Py_atomic_load_explicit(ATOMIC_VAL, ORDER) \
atomic_load_explicit(&((ATOMIC_VAL)->_value), ORDER)
#define _Py_atomic_store_explicit(ATOMIC_VAL, NEW_VAL, ORDER) \
atomic_store_explicit(&((ATOMIC_VAL)->_value), NEW_VAL, ORDER)
|
介绍完中间部分的内容,那么我们可以从头开始分析Python运行时的初始化了,我们说它是在 *new_interpreter* 函数中调用 *_PyRuntime_Initialize* 函数时开始的,函数位于 *Python/pylifecycle.c* 中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| PyThreadState *
Py_NewInterpreter(void)
{
PyThreadState *tstate = NULL;
PyStatus status = new_interpreter(&tstate);
if (_PyStatus_EXCEPTION(status)) {
Py_ExitStatusException(status);
}
return tstate;
}
|
另外里面出现了一个 *PyStatus*, 表示程序执行的状态, 会检测是否发生了异常,该结构体定义在 *Include/cpython/initconfig.h* 中。
1
2
3
4
5
6
7
8
9
10
| typedef struct {
enum {
_PyStatus_TYPE_OK=0,
_PyStatus_TYPE_ERROR=1,
_PyStatus_TYPE_EXIT=2
} _type;
const char *func;
const char *err_msg;
int exitcode;
} PyStatus;
|
然后我们的重点是 *new_interpreter*函数,我们进程状态对象的创建就是在这个函数里面发生的,该函数位于*Python/pylifecycle.c*中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| static PyStatus
new_interpreter(PyThreadState **tstate_p)
{
PyStatus status;
status = _PyRuntime_Initialize();
if (_PyStatus_EXCEPTION(status)) {
return status;
}
PyInterpreterState *interp = PyInterpreterState_New();
PyThreadState *tstate = PyThreadState_New(interp);
PyThreadState *save_tstate = PyThreadState_Swap(tstate);
}
|
Python在初始化运行时环境时,肯定也要对类型系统进行初始化等等,整体是一个非常庞大的过程。有兴趣的话,可以追根溯源对着源码阅读以下。
到这里,我们对 *new_interpreter* 算是有了一个阶段性的成功,我们创建了代表进程和线程概念的 *PyInterpreterState* 和 *PyThreadState* 对象,并且在它们之间建立的联系。下面, *new_interpreter* 将进行入另一个环节,设置系统module。
创建__builtins__
在 *new_interpreter* 中当Python解释器创建了 *PyInterpreterState* 和 *PyThreadState* 对象之后,就会开始设置系统的__builtins__了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| static PyStatus
new_interpreter(PyThreadState **tstate_p)
{
PyObject *modules = PyDict_New();
if (modules == NULL) {
return _PyStatus_ERR("can't make modules dictionary");
}
interp->modules = modules;
PyObject *sysmod = _PyImport_FindBuiltin("sys", modules);
if (sysmod != NULL) {
interp->sysdict = PyModule_GetDict(sysmod);
if (interp->sysdict == NULL) {
goto handle_error;
}
Py_INCREF(interp->sysdict);
PyDict_SetItemString(interp->sysdict, "modules", modules);
if (_PySys_InitMain(runtime, interp) < 0) {
return _PyStatus_ERR("can't finish initializing sys");
}
}
PyObject *bimod = _PyImport_FindBuiltin("builtins", modules);
if (bimod != NULL) {
interp->builtins = PyModule_GetDict(bimod);
if (interp->builtins == NULL)
goto handle_error;
Py_INCREF(interp->builtins);
}
}
|
整体还是比较清晰和直观的,另外我们说内置名字空间是由进程来维护的,因为进程就是用来为线程提供资源的。但是我们也能看出,这意味着一个进程内的多个线程共享同一个内置作用域,显然这是非常合理的,不可能每开启一个线程,就为其创建一个__builtins__。我们来从Python的角度证明这一点:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| import threading
import builtins
def foo1():
builtins.list, builtins.tuple = builtins.tuple, builtins.list
def foo2():
print(f"猜猜下面代码会输出什么:")
print("list:", list([1, 2, 3, 4, 5]))
print("tuple:", tuple([1, 2, 3, 4, 5]))
f1 = threading.Thread(target=foo1)
f1.start()
f1.join()
threading.Thread(target=foo2).start()
"""
猜猜下面代码会输出什么:
list: (1, 2, 3, 4, 5)
tuple: [1, 2, 3, 4, 5]
"""
|
我们说所有的内建对象和内置函数都在内置名字空间里面,我们可以通过 import builtins获取、也可以直接通过__builtins__这个变量来获取。我们在foo1中把list和tuple互换了,而这个结果显然也影响到了foo2函数。这也说明了__builtins__是属于进程级别的,它是被多个线程共享的。所以是interp -> modules = modules,当然这个modules是sys.modules,因为不止内置名字空间,所有的module对象都是被多个线程共享的。
而对__builts__的初始化时在 *_PyBuiltin_Init* 函数中进行的,它位于 *Python/bltinmodule.c* 中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
| PyObject *
_PyBuiltin_Init(void)
{
PyObject *mod, *dict, *debug;
const PyConfig *config = &_PyInterpreterState_GET_UNSAFE()->config;
if (PyType_Ready(&PyFilter_Type) < 0 ||
PyType_Ready(&PyMap_Type) < 0 ||
PyType_Ready(&PyZip_Type) < 0)
return NULL;
mod = _PyModule_CreateInitialized(&builtinsmodule, PYTHON_API_VERSION);
if (mod == NULL)
return NULL;
dict = PyModule_GetDict(mod);
SETBUILTIN("None", Py_None);
SETBUILTIN("Ellipsis", Py_Ellipsis);
SETBUILTIN("NotImplemented", Py_NotImplemented);
SETBUILTIN("False", Py_False);
SETBUILTIN("True", Py_True);
SETBUILTIN("bool", &PyBool_Type);
SETBUILTIN("memoryview", &PyMemoryView_Type);
SETBUILTIN("bytearray", &PyByteArray_Type);
SETBUILTIN("bytes", &PyBytes_Type);
SETBUILTIN("classmethod", &PyClassMethod_Type);
SETBUILTIN("complex", &PyComplex_Type);
SETBUILTIN("dict", &PyDict_Type);
SETBUILTIN("enumerate", &PyEnum_Type);
SETBUILTIN("filter", &PyFilter_Type);
SETBUILTIN("float", &PyFloat_Type);
SETBUILTIN("frozenset", &PyFrozenSet_Type);
SETBUILTIN("property", &PyProperty_Type);
SETBUILTIN("int", &PyLong_Type);
SETBUILTIN("list", &PyList_Type);
SETBUILTIN("map", &PyMap_Type);
SETBUILTIN("object", &PyBaseObject_Type);
SETBUILTIN("range", &PyRange_Type);
SETBUILTIN("reversed", &PyReversed_Type);
SETBUILTIN("set", &PySet_Type);
SETBUILTIN("slice", &PySlice_Type);
SETBUILTIN("staticmethod", &PyStaticMethod_Type);
SETBUILTIN("str", &PyUnicode_Type);
SETBUILTIN("super", &PySuper_Type);
SETBUILTIN("tuple", &PyTuple_Type);
SETBUILTIN("type", &PyType_Type);
SETBUILTIN("zip", &PyZip_Type);
debug = PyBool_FromLong(config->optimization_level == 0);
if (PyDict_SetItemString(dict, "__debug__", debug) < 0) {
Py_DECREF(debug);
return NULL;
}
Py_DECREF(debug);
return mod;
#undef ADD_TO_ALL
#undef SETBUILTIN
}
|
整个 *PyBuiltin__Init* 函数的功能就是设置好__builtins_ module,而这个过程是分为两步的。
通过_PyModule_CreateInitialized函数创建PyModuleObject对象,我们知道这是Python中模块对象的底层实现;设置module,将python中所有的内建对象都塞到__builtins__中
但是我们看到设置的东西似乎少了不少,比如dir、hasattr、setattr等等,这些明显也是内置的,但是它们到哪里去了。别急,我们刚才说创建__builtins__分为两步,第一步是创建PyModuleObject,而使用的函数就是 *_PyModule_CreateInitialized* ,而在这个函数里面就已经完成了大部分设置__builtins__的工作。该函数位于 *Object/moduleobject.c* 。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
| PyObject *
_PyModule_CreateInitialized(struct PyModuleDef* module, int module_api_version)
{
const char* name;
PyModuleObject *m;
if (!PyModuleDef_Init(module))
return NULL;
name = module->m_name;
if (!check_api_version(name, module_api_version)) {
return NULL;
}
if (module->m_slots) {
PyErr_Format(
PyExc_SystemError,
"module %s: PyModule_Create is incompatible with m_slots", name);
return NULL;
}
if ((m = (PyModuleObject*)PyModule_New(name)) == NULL)
return NULL;
if (module->m_methods != NULL) {
if (PyModule_AddFunctions((PyObject *) m, module->m_methods) != 0) {
Py_DECREF(m);
return NULL;
}
}
if (module->m_doc != NULL) {
if (PyModule_SetDocString((PyObject *) m, module->m_doc) != 0) {
Py_DECREF(m);
return NULL;
}
}
m->md_def = module;
return (PyObject*)m;
}
|
根据上面的代码我们可以得出如下信息:
1. name:module对象的名称,在这里就是__builtins__2. module_api_version:python内部使用的version值,用于比较3. PyModule_New:用于创建一个PyModuleObject对象4. methods:该module中所包含的函数的集合,在这里是builtin_methods5. PyModule_AddFunctions:设置methods中的函数操作6. PyModule_SetDocString:设置docstring
创建module对象
我们说Python中的module对象在底层cpython中对应的结构体是PyModuleObject对象,我们来看看它长什么样子吧,定义在 *Objects/moduleobject.c* 中。
1
2
3
4
5
6
7
| typedef struct {
PyObject_HEAD
PyObject *md_dict;
struct PyModuleDef *md_def;
PyObject *md_name;
} PyModuleObject;
|
而这个对象我们知道是通过PyModule_New创建的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
| PyObject *
PyModule_New(const char *name)
{
PyObject *nameobj, *module;
nameobj = PyUnicode_FromString(name);
if (nameobj == NULL)
return NULL;
module = PyModule_NewObject(nameobj);
Py_DECREF(nameobj);
return module;
}
PyObject *
PyModule_NewObject(PyObject *name)
{
PyModuleObject *m;
m = PyObject_GC_New(PyModuleObject, &PyModule_Type);
if (m == NULL)
return NULL;
m->md_def = NULL;
m->md_state = NULL;
m->md_weaklist = NULL;
m->md_name = NULL;
m->md_dict = PyDict_New();
if (module_init_dict(m, m->md_dict, name, NULL) != 0)
goto fail;
PyObject_GC_Track(m);
return (PyObject *)m;
fail:
Py_DECREF(m);
return NULL;
}
static int
module_init_dict(PyModuleObject *mod, PyObject *md_dict,
PyObject *name, PyObject *doc)
{
_Py_IDENTIFIER(__name__);
_Py_IDENTIFIER(__doc__);
_Py_IDENTIFIER(__package__);
_Py_IDENTIFIER(__loader__);
_Py_IDENTIFIER(__spec__);
if (md_dict == NULL)
return -1;
if (doc == NULL)
doc = Py_None;
if (_PyDict_SetItemId(md_dict, &PyId___name__, name) != 0)
return -1;
if (_PyDict_SetItemId(md_dict, &PyId___doc__, doc) != 0)
return -1;
if (_PyDict_SetItemId(md_dict, &PyId___package__, Py_None) != 0)
return -1;
if (_PyDict_SetItemId(md_dict, &PyId___loader__, Py_None) != 0)
return -1;
if (_PyDict_SetItemId(md_dict, &PyId___spec__, Py_None) != 0)
return -1;
if (PyUnicode_CheckExact(name)) {
Py_INCREF(name);
Py_XSETREF(mod->md_name, name);
}
return 0;
}
|
这里虽然创建了一个module对象,但是这仅仅是一个空的module对象,却并没有包含相应的操作和数据。我们看到只设置了name和doc等属性。
设置module对象
在PyModule_New结束之后,程序继续执行 *_PyModule_CreateInitialized* 下面的代码,然后我们知道通过 *PyModule_AddFunctions* 完成了对__builtins__几乎全部属性的设置。这个设置的属性依赖于第二个参数methods,在这里为builtin_methods。然后会遍历builtin_methods,并处理每一项元素,我们还是来看看长什么样子。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
static PyMethodDef builtin_methods[] = {
{"__build_class__", (PyCFunction)(void(*)(void))builtin___build_class__,
METH_FASTCALL | METH_KEYWORDS, build_class_doc},
{"__import__", (PyCFunction)(void(*)(void))builtin___import__, METH_VARARGS | METH_KEYWORDS, import_doc},
BUILTIN_ABS_METHODDEF
BUILTIN_ALL_METHODDEF
BUILTIN_ANY_METHODDEF
BUILTIN_ASCII_METHODDEF
BUILTIN_BIN_METHODDEF
{"breakpoint", (PyCFunction)(void(*)(void))builtin_breakpoint, METH_FASTCALL | METH_KEYWORDS, breakpoint_doc},
BUILTIN_CALLABLE_METHODDEF
BUILTIN_CHR_METHODDEF
BUILTIN_COMPILE_METHODDEF
BUILTIN_DELATTR_METHODDEF
{"dir", builtin_dir, METH_VARARGS, dir_doc},
BUILTIN_DIVMOD_METHODDEF
BUILTIN_EVAL_METHODDEF
BUILTIN_EXEC_METHODDEF
BUILTIN_FORMAT_METHODDEF
{"getattr", (PyCFunction)(void(*)(void))builtin_getattr, METH_FASTCALL, getattr_doc},
BUILTIN_GLOBALS_METHODDEF
BUILTIN_HASATTR_METHODDEF
BUILTIN_HASH_METHODDEF
BUILTIN_HEX_METHODDEF
BUILTIN_ID_METHODDEF
BUILTIN_INPUT_METHODDEF
BUILTIN_ISINSTANCE_METHODDEF
BUILTIN_ISSUBCLASS_METHODDEF
{"iter", (PyCFunction)(void(*)(void))builtin_iter, METH_FASTCALL, iter_doc},
BUILTIN_LEN_METHODDEF
BUILTIN_LOCALS_METHODDEF
{"max", (PyCFunction)(void(*)(void))builtin_max, METH_VARARGS | METH_KEYWORDS, max_doc},
{"min", (PyCFunction)(void(*)(void))builtin_min, METH_VARARGS | METH_KEYWORDS, min_doc},
{"next", (PyCFunction)(void(*)(void))builtin_next, METH_FASTCALL, next_doc},
BUILTIN_OCT_METHODDEF
BUILTIN_ORD_METHODDEF
BUILTIN_POW_METHODDEF
{"print", (PyCFunction)(void(*)(void))builtin_print, METH_FASTCALL | METH_KEYWORDS, print_doc},
BUILTIN_REPR_METHODDEF
BUILTIN_ROUND_METHODDEF
BUILTIN_SETATTR_METHODDEF
BUILTIN_SORTED_METHODDEF
BUILTIN_SUM_METHODDEF
{"vars", builtin_vars, METH_VARARGS, vars_doc},
{NULL, NULL},
};
|
怎么样,是不是看到了玄机。
总结一下就是:在 *Py_NewInterpreter* 中调用 *new_interpreter* 函数,然后在 *new_interpreter* 这个函数里面,通过 *PyInterpreterState_New* 创建 *PyInterpreterState* ,然后传递 *PyInterpreterState* 调用 *PyThreadState_New* 得到 *PyThreadState* 对象。
接着就是执行各种初始化动作,然后在 *new_interpreter* 中调用 *_PyBuiltin_Init* 设置内建属性,在代码的最后会设置大量的内置属性(函数、对象)。但是有几个却不在里面,比如:dir、getattr等等。所以中间调用的 *_PyModule_CreateInitialized* 不仅仅是初始化一个module对象,还会在初始化之后将我们没有看到的一些属性设置进去,在 *_PyModule_CreateInitialized* 里面,先是使用 *PyModule_New* 创建一个PyModuleObject,在里面设置了name和doc等属性之后,再通过 *PyModule_AddFunctions* 设置methods,在这里面我们看到了dir、getattr等内置属性。当这些属性设置完之后,退回到 *_PyBuiltin_Init* 函数中,再设置剩余的大量属性。之后,__builtins__就完成了。
另外 builtin_methods 是一个 PyMethodDef 类型的数组,里面是一个个的 PyMethodDef 结构体,而这个结构体定义在 *Include/methodobject.h* 中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| struct PyMethodDef {
const char *ml_name;
PyCFunction ml_meth;
int ml_flags;
const char *ml_doc;
};
typedef struct PyMethodDef PyMethodDef;
|
对于这里面每一个 *PyMethodDef* ,*_PyModule_CreateInitialized* 都会基于它创建一个 *PyCFunctionObject* 对象, 这个对象Python对函数指针的包装, 当然里面好包含了其它信息。
1
2
3
4
5
6
7
8
| typedef struct {
PyObject_HEAD
PyMethodDef *m_ml;
PyObject *m_self;
PyObject *m_module;
PyObject *m_weakreflist;
vectorcallfunc vectorcall;
} PyCFunctionObject;
|
而 *PyCFunctionObject* 对象则是通过 *PyCFunction_New* 完成的,该函数位于 *Objects/methodobject.c* 中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
| PyObject *
PyCFunction_New(PyMethodDef *ml, PyObject *self)
{
return PyCFunction_NewEx(ml, self, NULL);
}
PyObject *
PyCFunction_NewEx(PyMethodDef *ml, PyObject *self, PyObject *module)
{
vectorcallfunc vectorcall;
switch (ml->ml_flags & (METH_VARARGS | METH_FASTCALL | METH_NOARGS | METH_O | METH_KEYWORDS))
{
case METH_VARARGS:
case METH_VARARGS | METH_KEYWORDS:
vectorcall = NULL;
break;
case METH_FASTCALL:
vectorcall = cfunction_vectorcall_FASTCALL;
break;
case METH_FASTCALL | METH_KEYWORDS:
vectorcall = cfunction_vectorcall_FASTCALL_KEYWORDS;
break;
case METH_NOARGS:
vectorcall = cfunction_vectorcall_NOARGS;
break;
case METH_O:
vectorcall = cfunction_vectorcall_O;
break;
default:
PyErr_Format(PyExc_SystemError,
"%s() method: bad call flags", ml->ml_name);
return NULL;
}
PyCFunctionObject *op;
op = free_list;
if (op != NULL) {
free_list = (PyCFunctionObject *)(op->m_self);
(void)PyObject_INIT(op, &PyCFunction_Type);
numfree--;
}
else {
op = PyObject_GC_New(PyCFunctionObject, &PyCFunction_Type);
if (op == NULL)
return NULL;
}
op->m_weakreflist = NULL;
op->m_ml = ml;
Py_XINCREF(self);
op->m_self = self;
Py_XINCREF(module);
op->m_module = module;
op->vectorcall = vectorcall;
_PyObject_GC_TRACK(op);
return (PyObject *)op;
}
|
在 *_PyBuiltin__Init* 之后,Python会把PyModuleObject对象中维护的那个PyDictObject对象抽取出来,将其赋值给 *interp -> builtins* 。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
PyObject *
PyModule_GetDict(PyObject *m)
{
PyObject *d;
if (!PyModule_Check(m)) {
PyErr_BadInternalCall();
return NULL;
}
d = ((PyModuleObject *)m) -> md_dict;
assert(d != NULL);
return d;
}
static PyStatus
new_interpreter(PyThreadState **tstate_p)
{
PyObject *bimod = _PyImport_FindBuiltin("builtins", modules);
if (bimod != NULL) {
interp->builtins = PyModule_GetDict(bimod);
if (interp->builtins == NULL)
goto handle_error;
Py_INCREF(interp->builtins);
}
else if (PyErr_Occurred()) {
goto handle_error;
}
}
|
以后Python在需要访问__builtins__时,直接访问 *interp->builtins* 就可以了,不需要再到 *interp->modules* 里面去找了。因为对于内置函数、属性的使用在Python中会比较频繁,所以这种加速机制是很有效的。
创建sys module
Python在创建并设置了__builtins__之后,会照猫画虎,用同样的流程来设置sys module,并像设置 *interp->builtins* 一样设置 *interp->sysdict* 。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
static PyStatus
new_interpreter(PyThreadState **tstate_p)
{
PyObject *sysmod = _PyImport_FindBuiltin("sys", modules);
if (sysmod != NULL) {
interp->sysdict = PyModule_GetDict(sysmod);
if (interp->sysdict == NULL) {
goto handle_error;
}
Py_INCREF(interp->sysdict);
PyDict_SetItemString(interp->sysdict, "modules", modules);
if (_PySys_InitMain(runtime, interp) < 0) {
return _PyStatus_ERR("can't finish initializing sys");
}
}
}
|
Python在创建了sys module之后,会在此module中设置一个Python搜索module时的默认路径集合。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
static PyStatus
new_interpreter(PyThreadState **tstate_p)
{
status = add_main_module(interp);
}
static PyStatus
add_main_module(PyInterpreterState *interp)
{
PyObject *m, *d, *loader, *ann_dict;
m = PyImport_AddModule("__main__");
if (m == NULL)
return _PyStatus_ERR("can't create __main__ module");
d = PyModule_GetDict(m);
ann_dict = PyDict_New();
if ((ann_dict == NULL) ||
(PyDict_SetItemString(d, "__annotations__", ann_dict) < 0)) {
return _PyStatus_ERR("Failed to initialize __main__.__annotations__");
}
Py_DECREF(ann_dict);
if (PyDict_GetItemString(d, "__builtins__") == NULL) {
PyObject *bimod = PyImport_ImportModule("builtins");
if (bimod == NULL) {
return _PyStatus_ERR("Failed to retrieve builtins module");
}
if (PyDict_SetItemString(d, "__builtins__", bimod) < 0) {
return _PyStatus_ERR("Failed to initialize __main__.__builtins__");
}
Py_DECREF(bimod);
}
loader = PyDict_GetItemString(d, "__loader__");
if (loader == NULL || loader == Py_None) {
PyObject *loader = PyObject_GetAttrString(interp->importlib,
"BuiltinImporter");
if (loader == NULL) {
return _PyStatus_ERR("Failed to retrieve BuiltinImporter");
}
if (PyDict_SetItemString(d, "__loader__", loader) < 0) {
return _PyStatus_ERR("Failed to initialize __main__.__loader__");
}
Py_DECREF(loader);
}
return _PyStatus_OK();
}
|
根据我们使用Python的经验,我们知道最终Python肯定会创建一个PyListObject对象,也就是Python中的sys.path,里面包含了一组PyUnicodeObject,每一个PyUnicodeObject的内容就代表了一个搜索路径。但是这一步不是在这里完成的,至于是在哪里完成的,我们后面会说。
另外,我们需要注意的是:在上面的逻辑中,解释器将__main__这个模块添加进去了,这个__main__估计不用我多说了。之前在 *PyModule_New* 中,创建一个PyModuleObject对象之后,会在其属性字典(md_dict获取)中插入一个名为”name“的key,value就是 “main“。但是对于当然模块来说,这个模块也可以叫做__main__。
1
2
3
4
5
6
| name = "神楽七奈"
import __main__
print(__main__.name)
import sys
print(sys.modules["__main__"] is __main__)
|
我们发现这样也是可以导入的,因为这个__main__就是这个模块本身。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| static PyStatus
add_main_module(PyInterpreterState *interp)
{
PyObject *m, *d, *loader, *ann_dict;
m = PyImport_AddModule("__main__");
if (m == NULL)
return _PyStatus_ERR("can't create __main__ module");
d = PyModule_GetDict(m);
if (PyDict_GetItemString(d, "__builtins__") == NULL) {
PyObject *bimod = PyImport_ImportModule("builtins");
if (bimod == NULL) {
return _PyStatus_ERR("Failed to retrieve builtins module");
}
if (PyDict_SetItemString(d, "__builtins__", bimod) < 0) {
return _PyStatus_ERR("Failed to initialize __main__.__builtins__");
}
Py_DECREF(bimod);
}
}
|
因此我们算是知道了,为什么python xxx.py执行的时候,__name__是__main__了,因为我们这里设置了。而Python沿着名字空间寻找的时候,最终会在__main__的local空间中发现__name__,且值为字符串”main“。但如果是以import的方式加载的,那么__name__则不是”main“,而是模块名,后面我们会继续说。

其实这个__main__我们是再熟悉不过的了,当输入dir()的时候,就会显示__main__的内容。dir是可以不加参数的,如果不加参数,那么默认访问当前的py文件,也就是__main__。
1
2
3
4
5
6
7
8
9
10
| >>> __name__
'__main__'
>>>
>>> __builtins__.__name__
'builtins'
>>>
>>> import numpy as np
>>> np.__name__
'numpy'
>>>
|
所以说,访问模块就类似访问变量一样。modules里面存放了所有的(module name, PyModuleObject),当我们调用np的时候,是会找到name为”numpy”的值,然后这个值里面也维护了一个字典,其中就有一个key为__name__的entry。
设置site-specific的module的搜索路径
Python是一个非常开放的体系,它的强大来源于丰富的第三方库,这些库由外部的py文件来提供,当使用这些第三方库的时候,只需要简单的进行import即可。一般来说,这些第三方库都放在/lib/site-packages中,如果程序想使用这些库,直接把库放在这里面即可。
但是到目前为止,我们好像也没看到python将site-packages路径设置到搜索路径里面去啊。其实在完成了__main__的创建之后,Python才腾出手来,收拾这个site-package。这个关键的动作在于Python的一个标准库:site.py。
我们先来将Lib目录下的site.py删掉,然后导入一个第三方模块,看看会有什么后果。
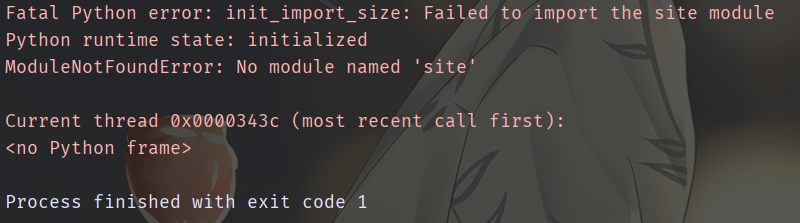
因此我们发现,Python在初始化的过程中确实导入了site.py,所以才有了如下的输出。而这个site.py也正是Python能正确加载位于site-packages目录下第三方包的关键所在。我们可以猜测,应该就是这个site.py将site-packages目录加入到了前面的sys.path中,而这个动作是由 *init_import_size* 完成的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| static PyStatus
new_interpreter(PyThreadState **tstate_p)
{
if (config->site_import) {
status = init_import_size();
if (_PyStatus_EXCEPTION(status)) {
return status;
}
}
}
static PyStatus
init_import_size(void)
{
PyObject *m;
m = PyImport_ImportModule("site");
if (m == NULL) {
return _PyStatus_ERR("Failed to import the site module");
}
Py_DECREF(m);
return _PyStatus_OK();
}
|
在 *init_import_size* 中,只调用了 *PyImport_ImportModule* 函数,这个函数是Python中import机制的核心所在。PyImport_ImportModule(“numpy”)等价于python中的 import numpy 即可。
激活python虚拟机
Python运行方式有两种,一种是在命令行中运行的交互式环境;另一种则是以python xxx.py方式运行脚本文件。尽管方式不同,但是却殊途同归,进入同一个字节码虚拟机。
Python在 *Py_Initialize* 完成之后,最终会通过 *pymain_run_file* 调用 *PyRun_AnyFileExFlags*。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
|
static int
pymain_run_file(PyConfig *config, PyCompilerFlags *cf)
{
const wchar_t *filename = config->run_filename;
if (PySys_Audit("cpython.run_file", "u", filename) < 0) {
return pymain_exit_err_print();
}
FILE *fp = _Py_wfopen(filename, L"rb");
if (fp == NULL) {
char *cfilename_buffer;
const char *cfilename;
int err = errno;
cfilename_buffer = _Py_EncodeLocaleRaw(filename, NULL);
if (cfilename_buffer != NULL)
cfilename = cfilename_buffer;
else
cfilename = "<unprintable file name>";
fprintf(stderr, "%ls: can't open file '%s': [Errno %d] %s\n",
config->program_name, cfilename, err, strerror(err));
PyMem_RawFree(cfilename_buffer);
return 2;
}
int run = PyRun_AnyFileExFlags(fp, filename_str, 1, cf);
Py_XDECREF(bytes);
return (run != 0);
}
int
PyRun_AnyFileExFlags(FILE *fp, const char *filename, int closeit,
PyCompilerFlags *flags)
{
if (filename == NULL)
filename = "???";
if (Py_FdIsInteractive(fp, filename)) {
int err = PyRun_InteractiveLoopFlags(fp, filename, flags);
if (closeit)
fclose(fp);
return err;
}
else
return PyRun_SimpleFileExFlags(fp, filename, closeit, flags);
}
|
我们看到交互式和py脚本式走的两条不同的路径,但是别着急,最终你会看到它们又会分久必合、走向同一条路径。
交互式运行
先来看看交互式运行时候的情形,不过在此之前先来看一下提示符。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| >>> a = 1
>>> if a == 1:
... pass
...
>>>
>>> import sys
>>> sys.ps1 = "matsuri:"
matsuri:a = 1
matsuri:a
1
matsuri:
matsuri:sys.ps2 = "fubuki:"
matsuri:if a == 1:
fubuki: pass
fubuki:
matsuri:
|
我们每输入一行,开头都是>>> ,这个是sys.ps1,而输入语句块的时候,没输入完的时候,那么显示...,这个是sys.ps2。如果修改了,那么就是我们自己定义的了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
| int
PyRun_InteractiveLoopFlags(FILE *fp, const char *filename_str, PyCompilerFlags *flags)
{
v = _PySys_GetObjectId(&PyId_ps1);
if (v == NULL) {
_PySys_SetObjectId(&PyId_ps1, v = PyUnicode_FromString(">>> "));
Py_XDECREF(v);
}
v = _PySys_GetObjectId(&PyId_ps2);
if (v == NULL) {
_PySys_SetObjectId(&PyId_ps2, v = PyUnicode_FromString("... "));
Py_XDECREF(v);
}
err = 0;
do {
ret = PyRun_InteractiveOneObjectEx(fp, filename, flags);
if (ret == -1 && PyErr_Occurred()) {
if (PyErr_ExceptionMatches(PyExc_MemoryError)) {
if (++nomem_count > 16) {
PyErr_Clear();
err = -1;
break;
}
} else {
nomem_count = 0;
}
PyErr_Print();
flush_io();
} else {
nomem_count = 0;
}
} while (ret != E_EOF);
Py_DECREF(filename);
return err;
}
static int
PyRun_InteractiveOneObjectEx(FILE *fp, PyObject *filename,
PyCompilerFlags *flags)
{
PyObject *m, *d, *v, *w, *oenc = NULL, *mod_name;
mod_ty mod;
PyArena *arena;
const char *ps1 = "", *ps2 = "", *enc = NULL;
int errcode = 0;
_Py_IDENTIFIER(encoding);
_Py_IDENTIFIER(__main__);
mod_name = _PyUnicode_FromId(&PyId___main__);
if (mod_name == NULL) {
return -1;
}
if (fp == stdin) {
}
v = _PySys_GetObjectId(&PyId_ps1);
if (v != NULL) {
}
w = _PySys_GetObjectId(&PyId_ps2);
if (w != NULL) {
}
arena = PyArena_New();
if (arena == NULL) {
Py_XDECREF(v);
Py_XDECREF(w);
Py_XDECREF(oenc);
return -1;
}
mod = PyParser_ASTFromFileObject(fp, filename, enc,
Py_single_input, ps1, ps2,
flags, &errcode, arena);
Py_XDECREF(v);
Py_XDECREF(w);
Py_XDECREF(oenc);
if (mod == NULL) {
PyArena_Free(arena);
if (errcode == E_EOF) {
PyErr_Clear();
return E_EOF;
}
return -1;
}
m = PyImport_AddModuleObject(mod_name);
if (m == NULL) {
PyArena_Free(arena);
return -1;
}
d = PyModule_GetDict(m);
v = run_mod(mod, filename, d, d, flags, arena);
PyArena_Free(arena);
if (v == NULL) {
return -1;
}
Py_DECREF(v);
flush_io();
return 0;
}
|
我们发现在run_mod之前,python会将__main__中维护的PyDictObject对象取出,作为参数传递给run_mod,这个参数关系极为重要,实际上这里的参数d就将作为Python虚拟机开始执行时当前活动的frame对象的local名字空间和global名字空间。
脚本文件运行方式
接下来,我们看一看直接运行脚本文件的方式。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
|
#define Py_file_input 257
int
PyRun_SimpleFileExFlags(FILE *fp, const char *filename, int closeit,
PyCompilerFlags *flags)
{
PyObject *m, *d, *v;
const char *ext;
int set_file_name = 0, ret = -1;
size_t len;
m = PyImport_AddModule("__main__");
if (m == NULL)
return -1;
Py_INCREF(m);
d = PyModule_GetDict(m);
if (PyDict_GetItemString(d, "__file__") == NULL) {
PyObject *f;
f = PyUnicode_DecodeFSDefault(filename);
if (f == NULL)
goto done;
if (PyDict_SetItemString(d, "__file__", f) < 0) {
Py_DECREF(f);
goto done;
}
if (PyDict_SetItemString(d, "__cached__", Py_None) < 0) {
Py_DECREF(f);
goto done;
}
set_file_name = 1;
Py_DECREF(f);
}
len = strlen(filename);
ext = filename + len - (len > 4 ? 4 : 0);
if (maybe_pyc_file(fp, filename, ext, closeit)) {
FILE *pyc_fp;
if (closeit)
fclose(fp);
if ((pyc_fp = _Py_fopen(filename, "rb")) == NULL) {
fprintf(stderr, "python: Can't reopen .pyc file\n");
goto done;
}
if (set_main_loader(d, filename, "SourcelessFileLoader") < 0) {
fprintf(stderr, "python: failed to set __main__.__loader__\n");
ret = -1;
fclose(pyc_fp);
goto done;
}
v = run_pyc_file(pyc_fp, filename, d, d, flags);
} else {
if (strcmp(filename, "<stdin>") != 0 &&
set_main_loader(d, filename, "SourceFileLoader") < 0) {
fprintf(stderr, "python: failed to set __main__.__loader__\n");
ret = -1;
goto done;
}
v = PyRun_FileExFlags(fp, filename, Py_file_input, d, d,
closeit, flags);
}
}
PyObject *
PyRun_FileExFlags(FILE *fp, const char *filename_str, int start, PyObject *globals,
PyObject *locals, int closeit, PyCompilerFlags *flags)
{
PyObject *ret = NULL;
mod = PyParser_ASTFromFileObject(fp, filename, NULL, start, 0, 0,
flags, NULL, arena);
if (closeit)
fclose(fp);
if (mod == NULL) {
goto exit;
}
ret = run_mod(mod, filename, globals, locals, flags, arena);
exit:
Py_XDECREF(filename);
if (arena != NULL)
PyArena_Free(arena);
return ret;
}
|
很显然,脚本文件和交互式之间的执行流程是不同的,但是最终都进入了run_mod,而且同样也将与__main__中维护的PyDictObject对象作为local名字空间和global名字空间传入了run_mod。
启动虚拟机
是的你没有看错,下面才是启动虚拟机,之前做了那么工作都是前戏。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| static PyObject *
run_mod(mod_ty mod, PyObject *filename, PyObject *globals, PyObject *locals,
PyCompilerFlags *flags, PyArena *arena)
{
PyCodeObject *co;
PyObject *v;
co = PyAST_CompileObject(mod, filename, flags, -1, arena);
if (co == NULL)
return NULL;
if (PySys_Audit("exec", "O", co) < 0) {
Py_DECREF(co);
return NULL;
}
v = run_eval_code_obj(co, globals, locals);
Py_DECREF(co);
return v;
}
|
run_mod接手传来的ast,然后传到 *PyAST_CompileObject* 中,创建了一个我们已经非常熟悉的PyCodeObject对象。关于这个完整的编译过程,就又是另一个话题了,总之先是scanner进行词法分析、将源代码切分成一个个的token,然后parser在词法分析之后的结果之上进行语法分析、通过切分好的token生成抽象语法树(AST,abstract syntax tree),然后将AST编译PyCodeObject对象,最后再由虚拟机执行。知道这么一个大致的流程即可,至于到底是怎么分词、怎么建立语法树的,这就又是一个难点了,个人觉得甚至比研究Python虚拟机还难。有兴趣的话可以去看Python源码中Parser目录,如果能把Python的分词、语法树的建立给了解清楚,那我觉得你完全可以手写一个正则表达式的引擎、以及各种模板语言。
而接下来,Python已经做好一切工作,开始通过 *run_eval_code_obj* 着手唤醒字节码虚拟机。
1
2
3
4
5
6
7
8
9
10
11
| static PyObject *
run_eval_code_obj(PyCodeObject *co, PyObject *globals, PyObject *locals)
{
PyObject *v;
v = PyEval_EvalCode((PyObject*)co, globals, locals);
if (!v && PyErr_Occurred() == PyExc_KeyboardInterrupt) {
_Py_UnhandledKeyboardInterrupt = 1;
}
return v;
}
|
函数中调用了 *PyEval_EvalCode*,根据前面介绍函数的时候,我们知道最终一定会走到 *PyEval_EvalFrameEx*。
从操作系统创建进程,进程创建线程,线程设置builtins(包括设置__name__、内建对象、内置函数方法等等)、设置缓存池,然后各种初始化,设置搜索路径。最后分词、编译、激活虚拟机执行。而执行的这个过程就是曾经与我们朝夕相处的 *PyEval_EvalFrameEx* ,掌控Python世界中无数对象的生生灭灭。参数f就是PyFrameObject对象,我们曾经探索了很久,现在一下子就回到了当初。有种梦回栈帧对象的感觉。目前的话,Python的骨架我们已经看清了,虽然还有很多细节隐藏在幕后。至少神秘的面纱已经被撤掉了。
名字空间
现在我们来看一下有趣的东西,看看在激活字节码虚拟机、创建 *PyFrameObject* 对象时,所设置的3个名字空间:local、global、builtin。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
|
PyFrameObject*
PyFrame_New(PyThreadState *tstate, PyCodeObject *code,
PyObject *globals, PyObject *locals)
{
PyFrameObject *f = _PyFrame_New_NoTrack(tstate, code, globals, locals);
if (f)
_PyObject_GC_TRACK(f);
return f;
}
PyFrameObject* _Py_HOT_FUNCTION
_PyFrame_New_NoTrack(PyThreadState *tstate, PyCodeObject *code,
PyObject *globals, PyObject *locals)
{
PyFrameObject *back = tstate->frame;
PyFrameObject *f;
PyObject *builtins;
Py_ssize_t i;
if (back == NULL || back->f_globals != globals) {
builtins = _PyDict_GetItemIdWithError(globals, &PyId___builtins__);
}
else {
builtins = back->f_builtins;
assert(builtins != NULL);
Py_INCREF(builtins);
}
f->f_builtins = builtins;
f->f_globals = globals;
if ((code->co_flags & (CO_NEWLOCALS | CO_OPTIMIZED)) ==
(CO_NEWLOCALS | CO_OPTIMIZED))
;
else if (code->co_flags & CO_NEWLOCALS) {
locals = PyDict_New();
if (locals == NULL) {
Py_DECREF(f);
return NULL;
}
f->f_locals = locals;
}
else {
if (locals == NULL)
locals = globals;
Py_INCREF(locals);
f->f_locals = locals;
}
f->f_lasti = -1;
f->f_lineno = code->co_firstlineno;
f->f_iblock = 0;
f->f_executing = 0;
f->f_gen = NULL;
f->f_trace_opcodes = 0;
f->f_trace_lines = 1;
return f;
}
|
我们说内置名字空间是从global名字空间里面获取的,我们用Python来演示一下。
1
2
3
4
5
6
7
8
9
10
11
12
|
print(globals()["__builtins__"])
print(globals()["__builtins__"].int("123"))
print(globals()["__builtins__"].globals)
print(globals()["__builtins__"].globals()["__builtins__"].list("abcd"))
|
所以不管套娃多少次,都是可以的,因为它们都是指针。
可以看到builtin和global空间里面都存储一个能够获取对方空间的一个函数指针, 所以这两者是并不冲突的。当然除此之外,还有一个__name__,注意我们之前说设置__name__只是builtins的__name__,并不是当前模块的。
1
2
3
4
5
6
7
8
9
10
11
12
13
|
print(globals()["__builtins__"].__name__)
print(globals()["__name__"])
globals().pop("__name__")
print(__name__)
|
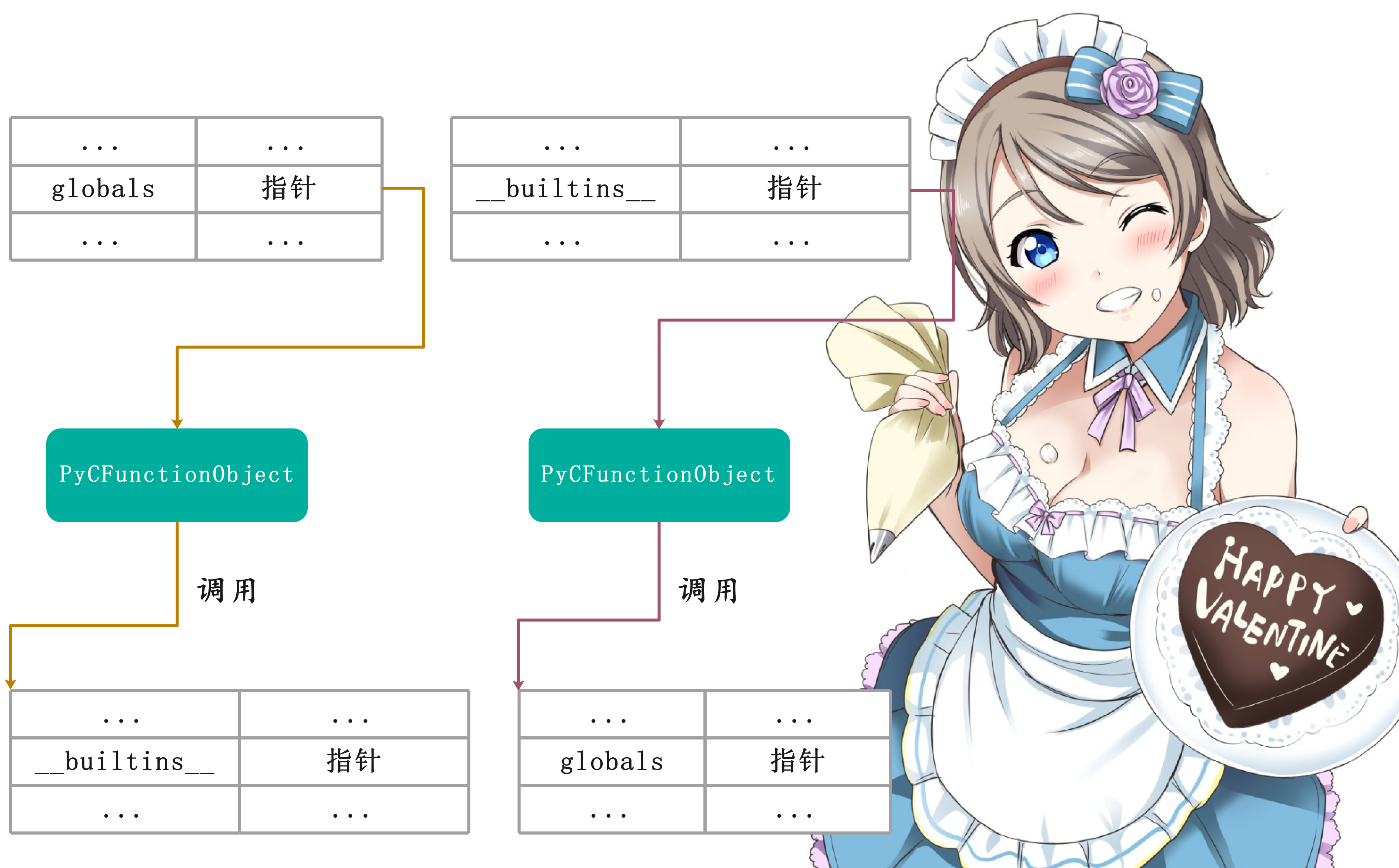
所以我们看到__name__这个属性是在启动之后动态设置的,如果执行的文件和该文件是同一个文件,那么__name__就会是__main__;如果不是同一个文件,证明这个文件是作为模块被导入进来的,那么此时它的__name__就是文件名。
更多细节可以前往源码中查看,Python运行环境初始化还是比较复杂的。
小结
这一次我们说了Python运行环境的初始化,或者说当Python启动的时候都做了哪些事情。可以看到,做的事情不是一般的多,真的准备了大量的工作。因为Python是动态语言,这就意味很多操作都要发生在运行时。
