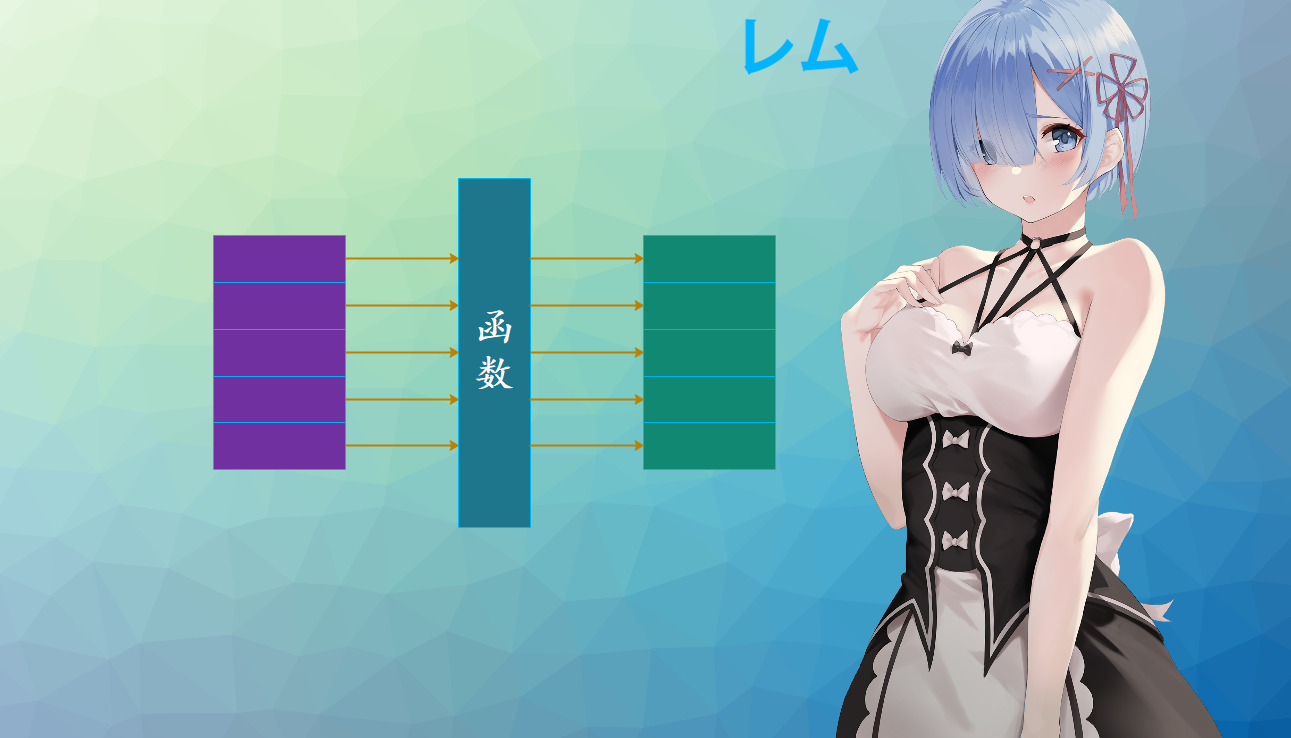
29-源码解密 map、filter、zip 底层实现,对比列表解析式 楔子 Python 现在如此流行,拥有众多开源、高质量的第三方库是一个重要原因,不过 Python 的简单、灵巧、容易上手也是功不可没的,而其背后的内置函数(类)则起到了很大的作用。举个栗子:
1 2 3 4 5 6 7 8 9 10 11 12 numbers = [1 , 2 , 3 , 4 , 5 ] print (list (map (lambda x: x + 1 , numbers))) strings = ["abc" , "d" , "def" , "kf" , "ghtc" ] print (list (filter (lambda x: len (x) >= 3 , strings))) keys = ["name" , "age" , "gender" ] values = ["夏色祭" , 17 , "female" ] print (dict (zip (keys, values)))
我们看到一行代码就搞定了,那么问题来了,这些内置函数(类)在底层是怎么实现的呢?下面我们就来通过源码来分析一下,这里我们介绍 map、filter、zip。
首先这些类(map、filter、zip都是类)都位于 builtin 名字空间中,而我们之前在介绍源码的时候提到过一个文件:Python/bltinmodule.c,我们说该文件是和内置函数(类)相关的,那么显然 map、filter、zip 也藏身于此。
map底层实现 我们知道map是将一个序列中的每个元素都作用于同一个函数(当然类、方法也可以):
当然,我们知道调用map的时候并没有马上执行上面的操作,而是返回一个map对象。既然是对象,那么底层必有相关的定义。
1 2 3 4 5 typedef struct { PyObject_HEAD PyObject *iters; PyObject *func; } mapobject;
PyObject_HEAD:见过很多次了,它是Python中任何对象都会有的头部信息。包含一个引用计数ob_refcnt、和一个类型对象的指针ob_type;
iters:一个指针,这里实际上是一个PyTupleObject *,以 map(lambda x: x + 1, [1, 2, 3]) 为例,那么这里的 iters 就相当于是 ([1, 2, 3, 4, 5].__iter__(),)。至于为什么,分析源码的时候就知道了;
func:显然就是函数指针了,PyFunctionObject *;
通过底层结构体定义,我们也可以得知在调用map时并没有真正的执行;对于函数和可迭代对象,只是维护了两个指针去指向它。
而一个PyObject占用16字节,再加上两个8字节的指针总共32字节。因此在64位机器上,任何一个map对象所占大小都是32字节。
1 2 3 4 5 6 numbers = list (range (100000 )) strings = ["abc" , "def" ] print (map (lambda x: x * 3 , numbers).__sizeof__()) print (map (lambda x: x * 3 , strings).__sizeof__())
再来看看map的用法,Python中的 map 不仅可以作用于一个序列,还可以作用于任意多个序列。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 m1 = map (lambda x: x[0 ] + x[1 ] + x[2 ], [(1 , 2 , 3 ), (2 , 3 , 4 ), (3 , 4 , 5 )]) print (list (m1)) m2 = map (lambda x, y, z: x + y + z, [1 , 2 , 3 ], [2 , 3 , 4 ], [3 , 4 , 5 ]) print (list (m2)) m3 = map (lambda x, y, z: str (x) + y + z, [1 , 2 , 3 ], ["a" , "b" , "c" ], "abc" ) print (list (m3)) m4 = map (lambda x, y, z: x + y + z, [1 , 2 , 3 ], [2 , 3 ], [3 , 4 , 5 ]) print (list (m4)) m5 = map (lambda x, y: x[0 ] + x[1 ] + y, [(1 , 2 ), (2 , 3 )], [3 , 4 ]) print (list (m5))
所以我们看到 map 会将后面所有可迭代对象中的每一个元素按照顺序依次取出,然后传递到函数中,因此函数的参数个数 和 可迭代对象的个数 一定要相等。
那么map对象在底层是如何创建的呢?很简单,因为map是一个类,那么调用的时候一定会执行里面的 new 方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 static PyObject *map_new (PyTypeObject *type, PyObject *args, PyObject *kwds) { PyObject *it, *iters, *func; mapobject *lz; Py_ssize_t numargs, i; if (type == &PyMap_Type && !_PyArg_NoKeywords("map" , kwds)) return NULL ; numargs = PyTuple_Size(args); if (numargs < 2 ) { PyErr_SetString(PyExc_TypeError, "map() must have at least two arguments." ); return NULL ; } iters = PyTuple_New(numargs-1 ); if (iters == NULL ) return NULL ; for (i=1 ; i<numargs ; i++) { it = PyObject_GetIter(PyTuple_GET_ITEM(args, i)); if (it == NULL ) { Py_DECREF(iters); return NULL ; } PyTuple_SET_ITEM(iters, i-1 , it); } lz = (mapobject *)type->tp_alloc(type, 0 ); if (lz == NULL ) { Py_DECREF(iters); return NULL ; } lz->iters = iters; func = PyTuple_GET_ITEM(args, 0 ); Py_INCREF(func); lz->func = func; return (PyObject *)lz; }
所以我们看到map_new做的工作很简单,就是实例化一个map对象,然后对内部的成员进行赋值。我们用Python来模拟一下上述过程:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 class MyMap : def __new__ (cls, *args, **kwargs ): if kwargs: raise TypeError("MyMap不接受关键字参数" ) numargs = len (args) if numargs < 2 : raise TypeError("MyMap至少接收两个参数" ) iters = [None ] * (numargs - 1 ) i = 1 while i < numargs: it = iter (args[i]) iters[i - 1 ] = it i += 1 instance = object .__new__(cls) instance.iters = iters instance.func = args[0 ] return instance m = MyMap(lambda x, y: x + y, [1 , 2 , 3 ], [11 , 22 , 33 ]) print (m) print (m.func) print (m.func(2 , 3 )) print (m.iters) print ([list (it) for it in m.iters])
我们看到非常简单,这里我们没有设置构造函数__init__,这是因为 map 内部没有 __init__,它的成员都是在__new__里面设置的。
1 2 3 print (map .__init__ is object .__init__) print (map .__init__)
事实上,你会发现map对象非常类似迭代器,而事实上它们也正是迭代器。
1 2 3 4 5 from typing import Iterable, Iteratorm = map (str , [1 , 2 , 3 ]) print (isinstance (m, Iterable)) print (isinstance (m, Iterator))
为了能更方便地理解后续内容,这里我们来提一下Python中的迭代器,可能有人觉得Python的迭代器很神奇,但如果你看了底层实现的话,你肯定会觉得:”就这?”
1 2 3 4 5 6 typedef struct { PyObject_HEAD Py_ssize_t it_index; PyObject *it_seq; } seqiterobject;
这就是Python的迭代器,非常简单,我们直接用Python来模拟一下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 class MyIterator : def __new__ (cls, it_seq ): instance = object .__new__(cls) instance.it_index = 0 instance.it_seq = it_seq return instance def __iter__ (self ): return self def __next__ (self ): if self.it_seq is None : raise StopIteration try : val = self.it_seq[self.it_index] self.it_index += 1 return val except IndexError: raise StopIteration for _ in MyIterator([1 , 2 , 3 ]): print (_, end=" " ) print ()my_it = MyIterator([2 , 3 , 4 ]) print (list (my_it)) print (list (my_it))
Python的迭代器底层就是这么做的,可能有人觉得这不就是把 可迭代对象 和 索引 进行了一层封装嘛。每迭代一次,索引自增1,当出现索引越界时,证明迭代完了,直接将 it_seq 设置为 NULL 即可(这也侧面说明了为什么迭代器从开始到结束只能迭代一次)。
是的,迭代器就是这么简单,没有一点神秘。当然不仅是迭代器,再比如关键字 in,在C的层面其实就是一层 for 循环罢了。而迭代器除了通过 iter 实现之外,我们还可以通过 getitem__,__iter 我们下一章分析,下面看看 getitem 在源码中是如何体现的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 PyObject * PySeqIter_New (PyObject *seq) { seqiterobject *it; if (!PySequence_Check(seq)) { PyErr_BadInternalCall(); return NULL ; } it = PyObject_GC_New(seqiterobject, &PySeqIter_Type); if (it == NULL ) return NULL ; it->it_index = 0 ; Py_INCREF(seq); it->it_seq = seq; _PyObject_GC_TRACK(it); return (PyObject *)it; } static PyObject *iter_iternext (PyObject *iterator) { seqiterobject *it; PyObject *seq; PyObject *result; assert(PySeqIter_Check(iterator)); it = (seqiterobject *)iterator; seq = it->it_seq; if (seq == NULL ) return NULL ; if (it->it_index == PY_SSIZE_T_MAX) { PyErr_SetString(PyExc_OverflowError, "iter index too large" ); return NULL ; } result = PySequence_GetItem(seq, it->it_index); if (result != NULL ) { it->it_index++; return result; } if (PyErr_ExceptionMatches(PyExc_IndexError) || PyErr_ExceptionMatches(PyExc_StopIteration)) { PyErr_Clear(); it->it_seq = NULL ; Py_DECREF(seq); } return NULL ; }
所以这就是迭代器,真的一点都不神秘。
在迭代器上面多扯皮了一会儿,但这肯定是值得的,那么回到主题。我们说调用map只是得到一个map对象,从上面的分析我们也可以得出,在整个过程并没有进行任何的计算。如果要计算的话,我们可以调用__next__、或者使用for循环等等。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 m = map (lambda x: x + 1 , [1 , 2 , 3 , 4 , 5 ]) print ([i for i in m]) m = map (lambda x: int (x) + 1 , "12345" ) while True : try : print (m.__next__()) except StopIteration: break """ 2 3 4 5 6 """
所以下面我们来看看map底层是怎么做的?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 static PyObject *map_next (mapobject *lz) { PyObject *small_stack[_PY_FASTCALL_SMALL_STACK]; PyObject **stack ; PyObject *result = NULL ; PyThreadState *tstate = _PyThreadState_GET(); const Py_ssize_t niters = PyTuple_GET_SIZE(lz->iters); if (niters <= (Py_ssize_t)Py_ARRAY_LENGTH(small_stack)) { stack = small_stack; } else { stack = PyMem_Malloc(niters * sizeof (stack [0 ])); if (stack == NULL ) { _PyErr_NoMemory(tstate); return NULL ; } } Py_ssize_t nargs = 0 ; for (Py_ssize_t i=0 ; i < niters; i++) { PyObject *it = PyTuple_GET_ITEM(lz->iters, i); PyObject *val = Py_TYPE(it)->tp_iternext(it); if (val == NULL ) { goto exit ; } stack [i] = val; nargs++; } result = _PyObject_VectorcallTstate(tstate, lz->func, stack , nargs, NULL ); exit : for (Py_ssize_t i=0 ; i < nargs; i++) { Py_DECREF(stack [i]); } if (stack != small_stack) { PyMem_Free(stack ); } return result; }
然后突然发现map对象还有一个鲜为人知的一个方法,也是一个没有什么卵用的方法。说来惭愧,要不是看源码,我还真没注意过。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 static PyObject *map_reduce (mapobject *lz, PyObject *Py_UNUSED(ignored)) { Py_ssize_t numargs = PyTuple_GET_SIZE(lz->iters); PyObject *args = PyTuple_New(numargs+1 ); Py_ssize_t i; if (args == NULL ) return NULL ; Py_INCREF(lz->func); PyTuple_SET_ITEM(args, 0 , lz->func); for (i = 0 ; i<numargs; i++){ PyObject *it = PyTuple_GET_ITEM(lz->iters, i); Py_INCREF(it); PyTuple_SET_ITEM(args, i+1 , it); } return Py_BuildValue("ON" , Py_TYPE(lz), args); } static PyMethodDef map_methods[] = { {"__reduce__" , (PyCFunction)map_reduce, METH_NOARGS, reduce_doc}, {NULL , NULL } };
然后我们来演示一下:
1 2 3 4 5 6 7 8 9 10 11 from pprint import pprintm = map (lambda x, y, z: x + y + z, [1 , 2 , 3 ], [2 , 3 , 4 ], [3 , 4 , 5 ]) pprint(m.__reduce__()) """ (<class 'map'>, (<function <lambda> at 0x000001D2791451F0>, <list_iterator object at 0x000001D279348640>, <list_iterator object at 0x000001D279238700>, <list_iterator object at 0x000001D27950AF40>)) """
filter底层实现 然后我们filter的实现原理,看完了map之后,再看filter就简单许多了。
1 2 lst = [1 , 2 , 3 , 4 , 5 ] print (list (filter (lambda x: x % 2 !=0 , lst)))
首先filter接收两个元素,第一个参数是一个函数(类、方法),第二个参数是一个可迭代对象。然后当我们迭代的时候会将可迭代对象中每一个元素都传入到函数中,如果返回的结果为真,则保留;为假,则丢弃。
但是,其实第一个参数除了是一个可调用的对象之外,它还可以是None。
1 2 3 lst = ["夏色祭" , "" , [], 123 , 0 , {}, [1 ]] print (list (filter (None , lst)))
至于为什么,一会看源码filter的实现就清楚了。
下面看看底层结构:
1 2 3 4 5 typedef struct { PyObject_HEAD PyObject *func; PyObject *it; } filterobject;
我们看到和map对象是一致的,没有什么区别。因为map、filter都不会立刻调用,而是返回一个相应的对象。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 static PyObject *filter_new (PyTypeObject *type, PyObject *args, PyObject *kwds) { PyObject *func, *seq; PyObject *it; filterobject *lz; if (type == &PyFilter_Type && !_PyArg_NoKeywords("filter" , kwds)) return NULL ; if (!PyArg_UnpackTuple(args, "filter" , 2 , 2 , &func, &seq)) return NULL ; it = PyObject_GetIter(seq); if (it == NULL ) return NULL ; lz = (filterobject *)type->tp_alloc(type, 0 ); if (lz == NULL ) { Py_DECREF(it); return NULL ; } Py_INCREF(func); lz->func = func; lz->it = it; return (PyObject *)lz; }
和map是类似的,因为本质上它们做的事情都是差不多的,下面看看迭代过程。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 static PyObject *filter_next (filterobject *lz) { PyObject *item; PyObject *it = lz->it; long ok; PyObject *(*iternext)(PyObject *); int checktrue = lz->func == Py_None || lz->func == (PyObject *)&PyBool_Type; iternext = *Py_TYPE(it)->tp_iternext; for (;;) { item = iternext(it); if (item == NULL ) return NULL ; if (checktrue) { ok = PyObject_IsTrue(item); } else { PyObject *good; good = PyObject_CallFunctionObjArgs(lz->func, item, NULL ); if (good == NULL ) { Py_DECREF(item); return NULL ; } ok = PyObject_IsTrue(good); Py_DECREF(good); } if (ok > 0 ) return item; Py_DECREF(item); if (ok < 0 ) return NULL ; } }
所以看到这里你还觉得Python神秘吗,从源代码层面我们看的非常流畅,只要你有一定的C语言基础即可。还是那句话,尽管我们不可能写一个解释器,因为背后涉及的东西太多了,但至少我们在看的过程中,很清楚底层到底在做什么。而且这背后的实现,如果让你设计一个方案的话,那么相信你也一样可以做到。
还是拿关键字 in 举例子,像"b" in ["a", "b", "c"]我们知道结果为真。那如果让你设计关键字 in 的实现,你会怎么做呢?反正基本上都会想到,遍历 in 后面的可迭代对象呗,将里面的元素 依次和 in前面的元素进行比较,如果出现相等的,返回真;遍历完了也没发现相等的,那么返回假。如果你是这么想的,那么恭喜你,Python解释器内部也是这么做的,我们以列表为例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 static int list_contains (PyListObject *a, PyObject *el) { PyObject *item; Py_ssize_t i; int cmp; for (i = 0 , cmp = 0 ; cmp == 0 && i < Py_SIZE(a); ++i) { item = PyList_GET_ITEM(a, i); Py_INCREF(item); cmp = PyObject_RichCompareBool(el, item, Py_EQ); Py_DECREF(item); } return cmp; }
以上便是关键字 in,是不是很简单呢?所以个人推荐没事的话可以多读一读Python解释器,如果你不使用Python / C API进行编程的话,那么不需要你有太高的C语言水平(况且现在还有Cython)。如果你想写出高质量、并且精简利落的Python代码,那么就势必要懂得背后的实现原理。比如:我们看几道思考题,自己乱编的。
1. 为什么 方法一 要比 方法二 更高效?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 lst = [1 , 2 , 3 , 4 , 5 ] def f1 (): return [f"item: {item} " for item in lst] def f2 (): res = [] for item in lst: res.append(f"item: {item} " ) return res
所以这道题考察的实际上是列表解析为什么更快?首先Python中的变量在底层本质上都是一个泛型指针PyObject *,调用res.append的时候实际上会进行一次属性查找。会调用 PyObject_GetAttr(res, "append") ,去寻找该对象是否有 append 函数,如果有的话,那么进行获取然后调用;而列表解析,Python在编译的时候看到左右的两个中括号就知道这是一个列表解析式,所以它会立刻知道自己该干什么,会直接调用C一级函数 PyList_Append,因为Python对这些内置对象非常熟悉。所以列表解析少了一层属性查找的过程,因此它的效率会更高。
2. 假设有三个变量a、b、c,三个常量 “xxx”、123、3.14,我们要判断这三个变量对应的值 和 这三个常量是否相等,该怎么做呢?注意:顺序没有要求,可以是 a == “xxx”、也可以是 b == “xxx”,只要这个三个变量对应的值正好也是 “xxx”、123、3.14 就行。
显然最方便的是使用集合:
1 2 a, b, c = 3.14 , "xxx" , 123 print (not {a, b, c} - {"xxx" , 3.14 , 123 })
3. 令人困惑的生成器解析式,请问下面哪段代码会报错?
1 2 3 4 5 x = ("xxx" for _ in dasdasdad) x = (dasdasdad for _ in "xxx" )
首先生成器解析式,只有在执行的时候才会真正的产出值。但是关键字 in 后面的变量是会提前确定的,所以代码一会报错,抛出 NameError;但代码二不会,因为只有在产出值的时候才会去寻找变量 dasdasdad 指向的值。
再留个两个思考题,为什么会出现这种结果呢?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class A : x = 123 print (x) lst = [x for _ in range (3 )] """ 123 NameError: name 'x' is not defined """ def f (): a = 123 print (eval ("a" )) print ([eval ("a" ) for _ in range (3 )]) f() """ 123 NameError: name 'a' is not defined """
像这样类似的问题还有很多很多,当然最关键的还是理解底层的数据结构 以及 解释器背后的执行原理,只有这样才能写出更加高效的代码。
回到正题,filter 也有 reduce 方法,和 map 类似。
1 2 3 f = filter (None , [1 , 2 , 3 , 0 , "" , [], "xx" ]) print (f.__reduce__()) print (list (f.__reduce__()[1 ][1 ]))
zip底层实现 最后看看 zip,其实 zip 和 map 也是有着高度相似之处的,首先它们都可以接受任意个可迭代对象。而且 zip,我们完全可以使用 map 来进行模拟。
1 2 3 4 5 6 7 8 9 10 11 12 13 print ( list (zip ([1 , 2 , 3 ], [11 , 22 , 33 ], [111 , 222 , 333 ])) ) print ( list (map (lambda x, y, z: (x, y, z), [1 , 2 , 3 ], [11 , 22 , 33 ], [111 , 222 , 333 ])) ) print ( list (map (lambda *args: args, [1 , 2 , 3 ], [11 , 22 , 33 ], [111 , 222 , 333 ])) )
所以 zip 的底层实现同样很简单,我们来看一下:
1 2 3 4 5 6 7 typedef struct { PyObject_HEAD Py_ssize_t tuplesize; PyObject *ittuple; PyObject *result; } zipobject;
目前我们根据结构体里面的成员,可以得到一个 zipobject 显然是占 40 字节的,16 + 8 + 8 + 8,那么结果是不是这样呢?我们来试一下就知道了。
1 2 3 4 5 6 7 z1 = zip ([1 , 2 , 3 ], [11 , 22 , 33 ]) z2 = zip ([1 , 2 , 3 , 4 ], [11 , 22 , 33 , 44 ]) z3 = zip ([1 , 2 , 3 ], [11 , 22 , 33 ], [111 , 222 , 333 ]) print (z1.__sizeof__()) print (z2.__sizeof__()) print (z3.__sizeof__())
所以我们分析的没有错,任何一个 zip 对象所占的大小都是 40 字节。所以在计算内存大小的时候,有人会好奇这到底是怎么计算的,其实就是根据底层的结构体进行计算的。
注意:如果你使用 sys.getsizeof 函数计算的话,可能会多出 16 个字节,这是因为对于可变对象,它们是会被 GC 跟踪的。在创建的时候,它们会被挂到零代链表中,所以它们额外还会有一个 前继指针 和 一个 后继指针,而 sys.getsizeof 将这两个指针的大小也算在内了。
下面看看 zip 对象是如何被实例化的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 static PyObject *zip_new (PyTypeObject *type, PyObject *args, PyObject *kwds) { zipobject *lz; Py_ssize_t i; PyObject *ittuple; PyObject *result; Py_ssize_t tuplesize; if (type == &PyZip_Type && !_PyArg_NoKeywords("zip" , kwds)) return NULL ; assert(PyTuple_Check(args)); tuplesize = PyTuple_GET_SIZE(args); ittuple = PyTuple_New(tuplesize); if (ittuple == NULL ) return NULL ; for (i=0 ; i < tuplesize; ++i) { PyObject *item = PyTuple_GET_ITEM(args, i); PyObject *it = PyObject_GetIter(item); if (it == NULL ) { Py_DECREF(ittuple); return NULL ; } PyTuple_SET_ITEM(ittuple, i, it); } result = PyTuple_New(tuplesize); if (result == NULL ) { Py_DECREF(ittuple); return NULL ; } for (i=0 ; i < tuplesize ; i++) { Py_INCREF(Py_None); PyTuple_SET_ITEM(result, i, Py_None); } lz = (zipobject *)type->tp_alloc(type, 0 ); if (lz == NULL ) { Py_DECREF(ittuple); Py_DECREF(result); return NULL ; } lz->ittuple = ittuple; lz->tuplesize = tuplesize; lz->result = result; return (PyObject *)lz; }
再来看看,zip对象的定义:
1 2 3 4 5 6 typedef struct { PyObject_HEAD Py_ssize_t tuplesize; PyObject *ittuple; PyObject *result; } zipobject;
如果以:zip([1, 2, 3], [11, 22, 33], [111, 222, 333])为例的话,那么:
tuplesize: 3ittuple: ([1, 2, 3].__iter__(), [11, 22, 33].__iter__(), [111, 222, 333].__iter__())result: (None, None, None)
所以目前来说,其它的很好理解,唯独这个result让人有点懵,搞不懂它是干什么的。不过既然有这个成员,那就说明它肯定有用武之地,而派上用场的地方不用想,肯定是在迭代的时候使用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 static PyObject *zip_next (zipobject *lz) { Py_ssize_t i; Py_ssize_t tuplesize = lz->tuplesize; PyObject *result = lz->result; PyObject *it; PyObject *item; PyObject *olditem; if (tuplesize == 0 ) return NULL ; if (Py_REFCNT(result) == 1 ) { Py_INCREF(result); for (i=0 ; i < tuplesize ; i++) { it = PyTuple_GET_ITEM(lz->ittuple, i); item = (*Py_TYPE(it)->tp_iternext)(it); if (item == NULL ) { Py_DECREF(result); return NULL ; } olditem = PyTuple_GET_ITEM(result, i); PyTuple_SET_ITEM(result, i, item); Py_DECREF(olditem); } } else { result = PyTuple_New(tuplesize); if (result == NULL ) return NULL ; for (i=0 ; i < tuplesize ; i++) { it = PyTuple_GET_ITEM(lz->ittuple, i); item = (*Py_TYPE(it)->tp_iternext)(it); if (item == NULL ) { Py_DECREF(result); return NULL ; } PyTuple_SET_ITEM(result, i, item); } } return result; }
所以当我们进行迭代的时候,迭代出来的是一个元组。
1 2 3 4 5 6 7 8 9 10 z = zip ([1 , 2 , 3 ], [11 , 22 , 33 ]) print (z.__next__()) z = zip ([1 , 2 , 3 ]) print (z.__next__()) z = zip ([[1 , 2 , 3 ], [11 , 22 , 33 ]]) print (z.__next__())
最后,zip 也有一个__reduce__ 方法:
1 2 3 4 5 z = zip ([1 , 2 , 3 ], [11 , 22 , 33 ]) print (z.__reduce__()) print ([tuple (_) for _ in z.__reduce__()[1 ]])
map、filter 和 列表解析之间的区别 其实在使用 map、filter 的时候,我们完全可以使用列表解析来实现。比如:
1 2 3 4 lst = [1 , 2 , 3 , 4 ] print ([str (_) for _ in lst]) print (list (map (str , lst)))
这两者之间实际上是没有什么太大区别的,都是将 lst 中的元素一个一个迭代出来、然后调用 str 、返回结果。如果非要找出区别话,就是列表解析使用的是 Python 的for循环,而调用list的时候使用的是C中的for循环。从这个角度来说,使用 map 的效率会更高一些。
所以后者的效率稍微更高一些,因为列表解析用的是 Python 的for循环,list(map(func, iter)) 用的是C的for循环。但是注意:如果是下面这种做法的话,会得到相反的结果。
我们看到 map 貌似变慢了,其实原因很简单,后者多了一层匿名函数的调用,所以速度变慢了。
如果列表解析也是函数调用的话:
会发现速度更慢了,当然这种做法完全是吃饱了撑的。之所以说这些,是想说明在同等条件下,list(map) 这种形式是要比列表解析快的。当然在工作中,这两者都是可以使用的,这点效率上的差别其实不用太在意,如果真的到了需要在乎这点差别的时候,那么你应该考虑的是换一门更有效率的静态语言。
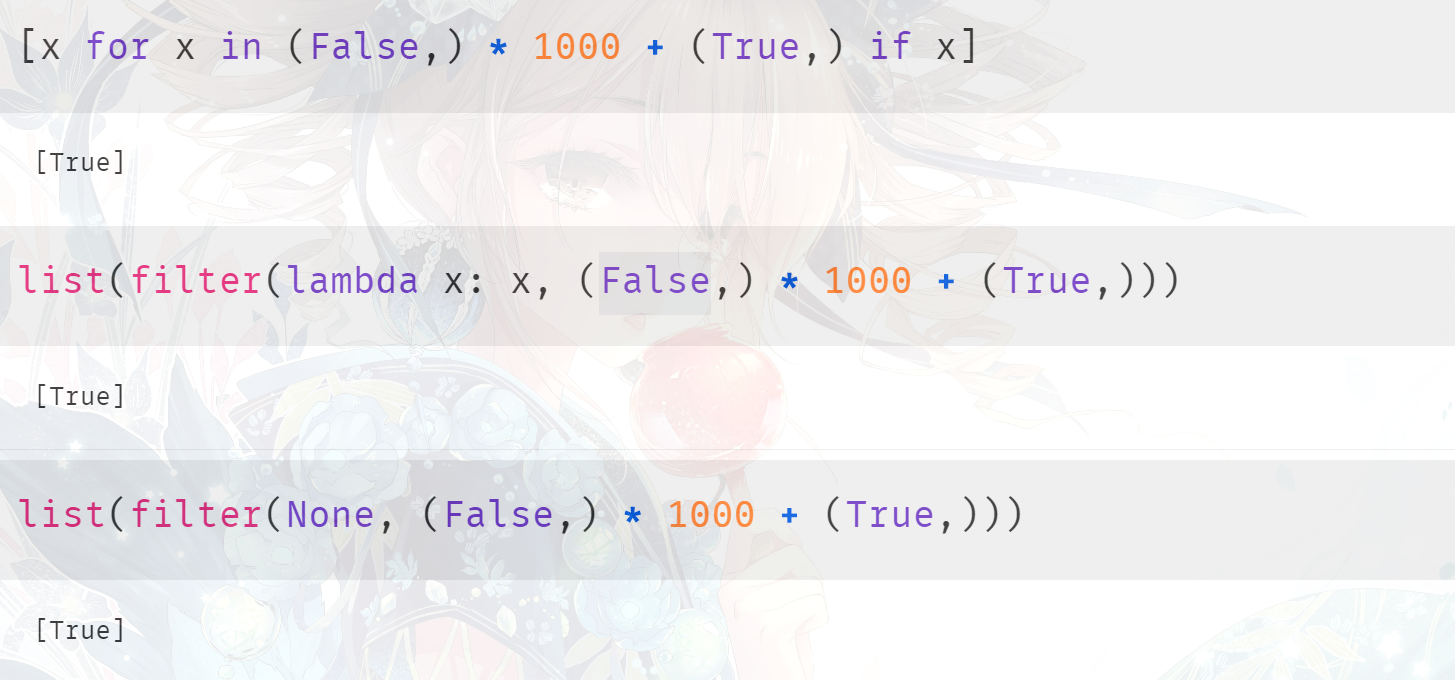
filter 和 列表解析之间的差别,也是如此。
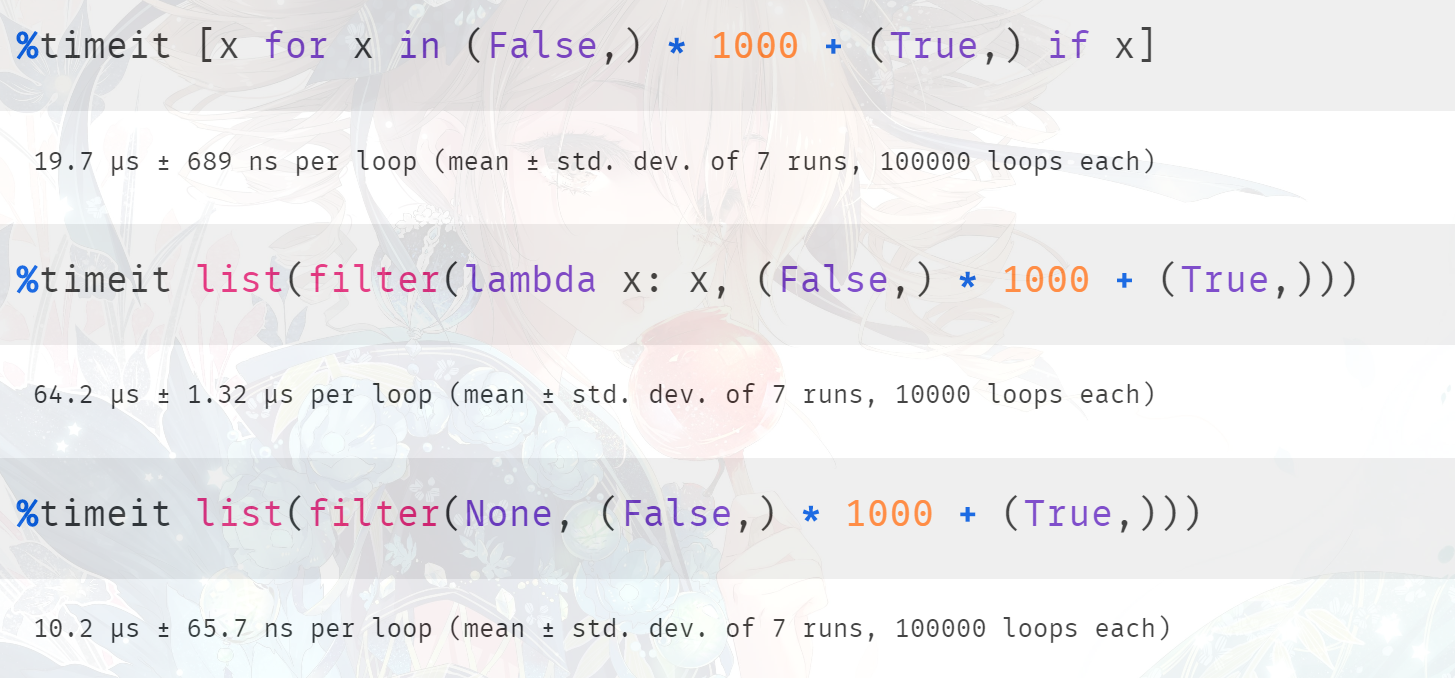
对于过滤含有 1000个 False 和 1个True 的元组,它们的结果都是一样的,但是谁的效率更高呢?首先第一种方式 肯定比 第二种方式快,因为第二种方式涉及到函数的调用;但是第三种方式,我们知道它在底层会走单独的分支,所以再加上之前的结论,我们认为第三种方式是最快的。
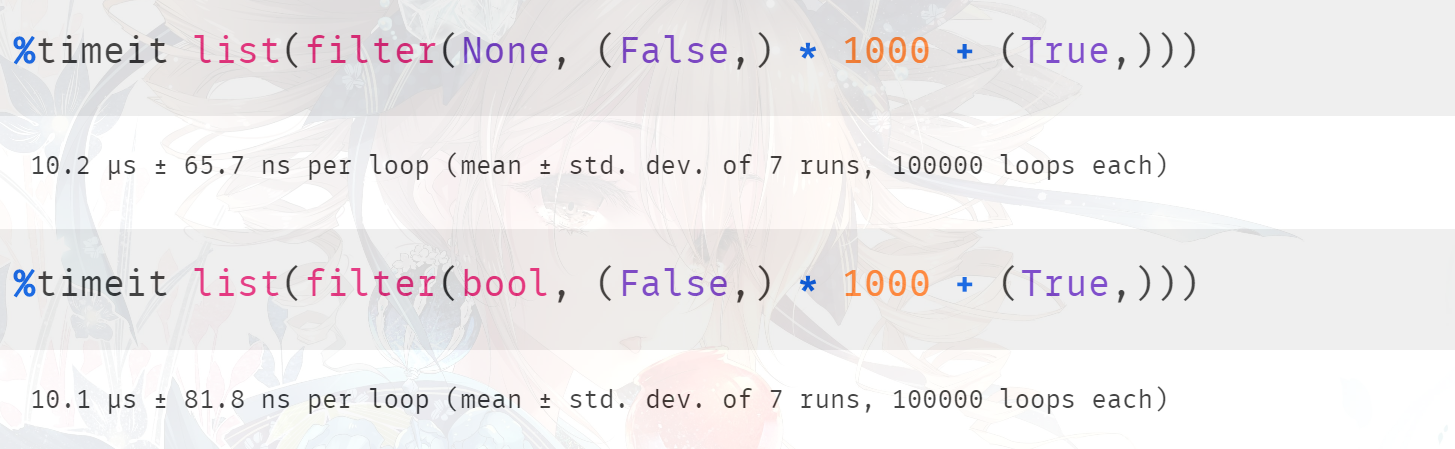
结果也确实是我们分析的这样,当然我们说在底层 None 和 bool 都会走相同的分支,所以这里将 None 换成 bool 也是可以的。虽然 bool 是一个类,但是通过 filter_new 函数我们知道,底层不会进行调用,也是直接使用 PyObject_IsTrue,可以将 None 换成 bool 看看结果如何,应该是差不多的。
总结 所以 map、filter 完全可以使用列表解析替代,如果执行的逻辑比较复杂的话,那么对于 map、filter 而言就要写匿名函数了。但逻辑简单的话,比如:获取为真的元素,完全可以通过list(filter(None, lst))实现,效率更高,因为它走的是相当于是C的循环;但如果获取大于3的元素,那么就需要使用list(filter(lambda x: x > 3, lst))这种形式了,而我们说它的效率是不如列表解析[x for x in lst if x > 3]的,因为前者多了一层函数调用。
但是在工作中,这两种方式都是可以的,使用哪一种就看个人喜好。到此我们发现,如果排除那一点点效率上的差异,那么确实有列表解析式就完全足够了,因为列表解析式可以同时实现 map、filter 的功能,而且表达上也更加地直观。只不过是 map、filter 先出现,然后才有的列表解析式,但是前者依旧被保留了下来。
当然 map、filter 返回的是一个可迭代对象,它不会立即计算,可以节省资源;当然这个功能,我们也可以通过生成器表达式来实现。
map、filter、zip 的底层实现我们就看完了,是不是很简单呢?
另外,如果你得到的结论和我这里的不一致,那么不妨把可迭代对象的元素个数设置的稍微大一些,最终结论和我这里一定是一样的。