
32-Python 和 Go 联合编程
32-Python 和 Go 联合编程
楔子
Python 可以和 C 无缝结合,通过 C 来为 Python 编写扩展可以极大地提升 Python 的效率,但是使用 C 来编程显然不是很方便,于是本人想到了 Go。对比 C 和 Go 会发现两者非常相似,没错,Go 语言具有强烈的 C 语言背景,其设计者以及语言的设计目标都和 C 有着千丝万缕的联系。因为 Go 语言的诞生就是因为 Google 中的一些开发者觉得 C++ 太复杂了,所以才决定开发一门简单易用的语言,而 Google 的工程师大部分都有 C 的背景,因此在设计 Go 语言的时候保持了 C 语言的风格。
而在 Go 和 C 的交互方面,Go 语言也是提供了非常大的支持(CGO),可以直接通过注释的方式将 C 源代码嵌入在 Go 文件中,这是其它语言所无法比拟的。最初 CGO 是为了能复用 C 资源这一目的而出现的,而现在它已经变成 Go 和 C 之间进行双向通讯的桥梁,也就是 Go 不仅能调用 C 的函数,还能将自己的函数导出给 C 调用。也正因为如此,Python 和 Go 之间才有了交互的可能。因为 Python 和 Go 本身其实是无法交互的,但是它们都可以和 C 勾搭上,所以需要通过 C 充当媒介,来为 Python 和 Go 牵线搭桥。
我们知道 Python 和 C 之间是双向的,也就是可以互相调用,而 Go 和 C 之间也是双向的,那么 Python 和 Go 之间自然仍是双向的。我们可以在 Python 为主导的项目中引入 Go,也可以在 Go 为主导的项目中引入 Python,而对于我本人来说,Python 是我的主语言、或者说老本行,因此这里我只介绍如何在 Python 为主导的项目中引入 Go。
而在 Python 为主导的项目中引入 Go 有以下几种方式:
将 Go 源文件编译成动态库,然后直接通过 Python 的 ctypes 模块调用将 Go 源文件编译成动态库或者静态库,再结合 Cython 生成对应的 Python 扩展模块,然后直接 import 即可将 Go 源文件直接编译成 Python 扩展模块,当然这要求在使用 CGO 的时候需要遵循 Python 提供的 C API
对于第一种方式,使用哪种操作系统无关紧要,操作都是一样的。但是对于第二种和第三种,我只在 Linux 上成功过,当然 Windows 肯定也是可以的,只不过操作方式会复杂一些(个人不是很熟悉)。因此这里我统一使用 Linux 进行演示,下面介绍一下我的相关环境:
Python 版本:3.6.8,系统自带的 Python,当然 3.7、3.8、3.9 同样是没有问题的(个人最喜欢 3.8)Go 版本:1.16.4,一个比较新的版本了,至于其它版本也同样可以gcc 版本:4.8.5,系统自带(Windows 系统的话,需要去下载 MingGW)

下面我们来介绍一下上面这几种方式。
Go 源文件编译成动态库
首先如果 Go 想要编译成动态库给 Python 调用,那么必须启用 CGO 特性,并将想要被 Python 调用的函数导出。而启用 CGO 则需要保证环境变量 CGO_ENABLE 的值设置为 1,在本地构建的时候默认是开启的,但是交叉编译(比如在 Windows 上编译 Linux 动态库)的时候,则是禁止的。
下面来看看一个最简单的 CGO 程序是什么样子的。
1 | // 文件名:file.go |
相较于普通的 Go 只是多了一句 import “C”,除此之外没有任何和 CGO 相关的代码,也没有调用 CGO 的相关函数。但是由于这个 import,会使得 go build 命令在编译和链接阶段启动 gcc 编译器,所以这已经是一个完整的 CGO 程序了。
1 | [root@satori go_py]# go run file.go |
直接运行,打印输出。当然我们也可以基于 C 标准库函数来输出字符串:
1 | // 文件名:file.go |
可能有人好奇 import “C” 上面那段代码是做什么的,答案是导入 C 中的标准库。我们说 Go 里面是可以直接编写 C 代码的,而 C 代码要通过注释的形式写在 import “C” 这行语句上方(中间不可以有空格,这是规定)。而一旦导入,就可以通过 C 这个名字空间进行调用,比如这里的 C.puts、C.CString 等等。
1 | [root@satori go_py]# go run file.go |
至于这里的 import “C”,它不是导入一个名为 C 的包,我们可以将其理解为一个名字空间,C 语言的所有类型、函数等等都可以通过这个名字空间去调用。
最后注意里面的 C.CString,我们说这是将 Go 的字符串转成 C 的字符串,但是当我们不用了的时候它依旧会停留在内存里,所以我们要将其释放掉,具体做法后面会说。但是对于当前这个小程序来说,这样是没有问题的,因为程序退出后操作系统会回收所有的资源。
我们也可以自己定义一个函数:
1 | // 文件名:file.go |
同样是可以执行成功的。
1 | [root@satori go_py]# go run file.go |
除此之外我们还可以将 C 的代码放到单独的文件中,比如:
1 | // 文件名:1.c |
然后 Go 源文件如下:
1 | // 文件名:file.go |
直接执行即可打印出结果,当然我们会更愿意把 C 函数的声明写在头文件当中,具体实现写在C源文件中。
1 | // 1.h |
然后在 Go 只需要导入头文件即可使用,比如:
1 | // 文件名:file.go |
然后重点来了,这个时候如果执行 go run file.go 是会报错的:
1 | [root@satori go_py]# go run file.go |
虽然文件中出现了 #include “1.h”,但是和 1.h 相关的源文件 1.c 则没有任何体现,除非你在go的注释里面再加上 #include “1.c”,但这样头文件就没有意义了。因此在编译的时候,我们不能对这个具体的 file.go 源文件进行编译;也就是说不要执行 go build file.go,而是要在这个 Go 文件所在的目录直接执行 go build,会对整个包进行编译,此时就可以找到当前目录中对应的 C 源文件了。
1 | [root@satori go_py]# go build -o a.out |
但是需要注意的是:我当前目录为 /root/go_py,里面的 Go 文件只有一个 file.go,但如果内部有多个 Go文件的话,那么对整个包进行编译的时候,要确保只能有一个文件有 main 函数。
另外对于 go1.16 而言,需要先通过 go mod init 来初始化项目,否则编译包的时候会失败。
Go 导出函数给 Python 调用
上面算是简单介绍了一下 CGO 以及 Go 如何调用 C 函数,但是 Go 调用 C 函数并不是我们的重点,我们的重点是 Go 导出函数给 Python 使用。
1 | // 文件名:file.go |
我们看到函数上面有一行注释://export SayWhat,这一行注释必须要有,即 //export 函数名。并且该注释要和函数紧挨着,之间不能有空行,而它的作用就是将 SayWhat 函数导出,然后 Python 才可以调用,如果不导出的话,Python 会调用不到的。而且导出的时候是 C 函数的形式导出的,因为 Python 和 Go 交互需要 C 作为媒介,因此导出函数的参数和返回值都必须是 C 的类型。
导出函数的名称不要求首字母大写,小写的话依旧可以导出。
最后是 main 函数,这个 main 函数也是必须要有的,尽管里面可以什么都不写,但是必须要有,否则编译不通过。然后我们来将这个文件编译成动态库:
1 | go build -buildmode=c-shared -o 动态库 [go源文件 go源文件 go源文件 ...] |
以当前的 file.go 为例:gcc build -buildmode=c-shared -o libgo.so file.go,如果是对整个包编译,那么不指定 go源文件即可。
1 | [root@satori go_py]# go build -buildmode=c-shared -o libgo.so file.go |
这里我们将 file.go 编译成动态库 libgo.so,然后 Python 来调用一下试试。
在 Linux 上,动态库的后缀名为 .so;在 Windows 上,动态库的后缀名为 .dll。而 Python 的扩展模块在 Linux 上的后缀名也为 .so,在 Windows 上的的后缀名则是 .pyd(pyd 也可以看做是 dll)。因此我们发现所谓 Python 扩展模块实际上就是对应系统上的一个动态库,如果是遵循标准 Python/C API 的 C 源文件生成的动态库,Python 解释器是可以直接识别的,我们可以通过 import 导入;但如果不是,比如我们上面刚生成的 libgo.so,或者 Linux 自带的大量动态库,那么我们就需要通过 ctypes 的方式加载了。
1 | from ctypes import * |
我们看到成功打印了,那么打印是哪里来的呢?显然是 Go 里面的 fmt.Println。
以上就实现了 Go 导出 Python 函数给 Python 调用,但是很明显这还不够,我们还需要能够传递参数、以及获取返回值。而想要实现这一点,我们必须要了解一下不同语言之间类型的对应关系。
数值类型
在 Go 语言中访问 C 语言的符号时,一般是通过虚拟的 “C” 包访问,比如 C.int 对应 C 语言的 int 类型。但有些 C 语言的类型是由多个关键字组成,而通过虚拟的 “C” 包访问 C 语言类型时名称部分不能有空格字符,比如 unsigned int 不能直接通过 C.unsigned int 访问,这是不合法的。因此 CGO 为 C 语言的基础数值类型都提供了相应转换规则,比如 C.uint 对应 C 语言的 unsigned int。
Go 语言中数值类型和 C 语言数据类型基本上是相似的,以下是它们的对应关系表。
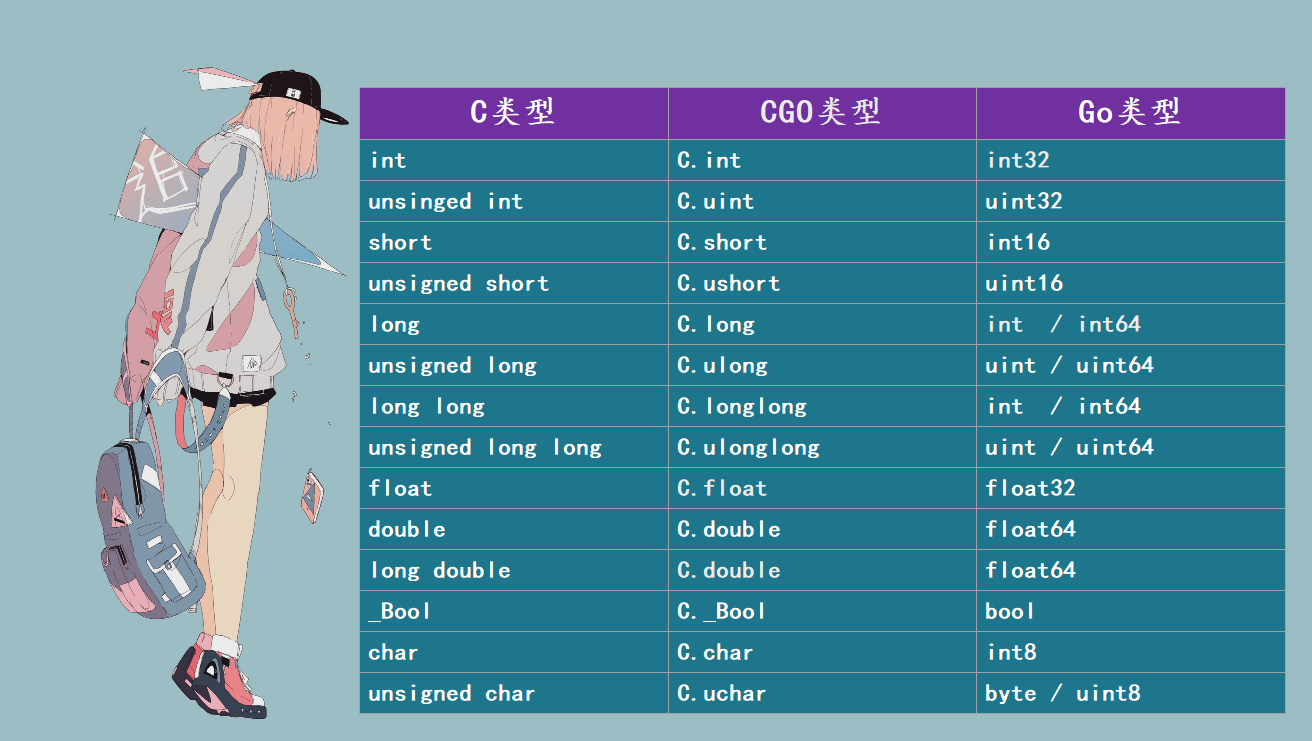
数值类型虽然有很多,但是整型我们直接使用 long、浮点型使用 double 即可,另外我们在 Go 中定义的函数名不可以和 C 中的关键字冲突。
下面我们举个栗子演示一下:
1 | // 文件名:file.go |
然后重新编译生成动态库,交给 Python 调用。
1 | from ctypes import * |
怎么样,是不是很简单呢?
我们在生成 libgo.so 的同时,还会自动帮我们生成一个 libgo.h,在里面会为 Go 语言的字符串、切片、字典、接口和管道等特有的数据类型生成对应的 C 语言类型:
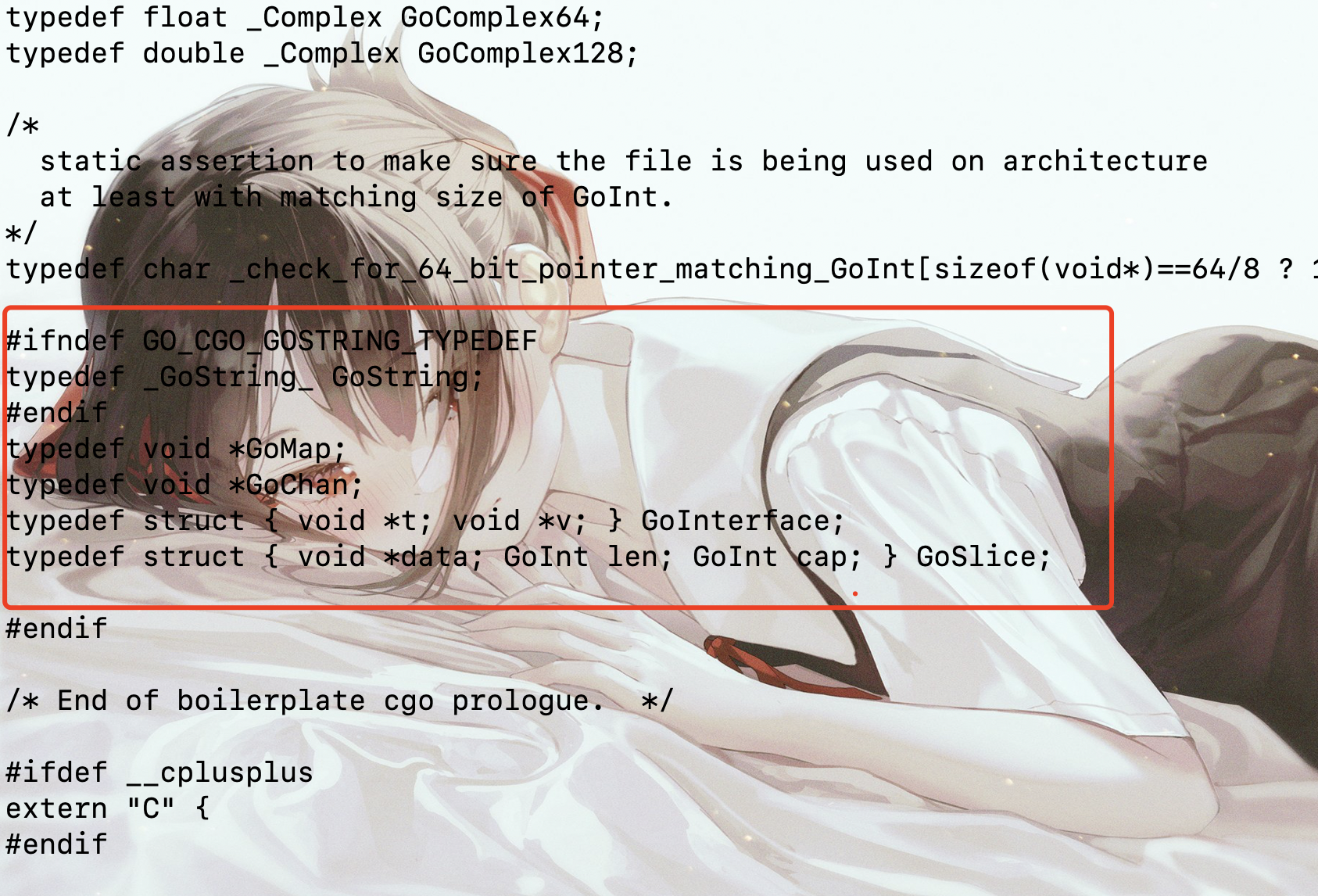
不过需要注意的是,其中只有字符串和切片在 CGO 中有一定的使用价值,因为二者可以直接被 C 和 Python 调用。但是 CGO 并未针对其它的类型提供相关的辅助函数,且 Go 语言特有的内存模型导致我们无法保持这些由 Go 语言管理的内存指针,所以它们在编写动态库给 Python 调用这一场景中并无使用价值,比如 channel,这东西在 Python 里面根本没法用,还有 Map 也是同样道理。
字符串
字符串可以说是用的最为频繁了,而且使用字符串还需要考虑内存泄漏的问题,至于为什么会有内存泄漏以及如何解决它后面会说,目前先来看看如何操作字符串。
1 | // 文件名:file.go |
还是调用 go build -buildmode=c-shared -o libgo.so file.go 将其编译成动态库,然后 Python 进行调用。
1 | from ctypes import * |
同理我们也可以修改传递的字符串,当然与其说修改,倒不如说仍是重新创建一份。
1 | // 文件名:file.go |
编译之后给 Python 调用:
1 | from ctypes import * |
字符串操作基本上使用 C.GoString 和 C.CString 就足够了,但是正如我们之前说的,C.CString 存在着内存泄漏问题,后面会解决它。
结构体
结构体应该算是 Go 中最重要的成员了吧,但是 Go 的结构体是不能作为导出函数的参数或返回值的,我们需要使用C中的结构体。
如果尝试导出一个参数或返回值为 Go 的结构体的函数,那么会报错:
Go type not supported in export: struct
1 | // 文件名:file.go |
对于 Python 而言,我们看看如何在 Python 中创建一个结构体:
1 | from ctypes import * |
还是比较简单的,只不过定义变量的时候最好不要和关键字冲突。但是 Go 给我们提供了一个隐形的转化方式,即便我们在 C 中定义的变量和 Go 关键字冲突了,也可以通过在变量前面加上一个下划线的方式访问。那么问题来了,如果有两个成员:一个成员以 Go 语言关键字命名,另一个成员以下划线加上相同的关键字命名,那么以关键字命名的成员将无法访问(被屏蔽)。
1 | /* |
我们看到参数只能是 C 的结构体,那么 Go 的结构体就无法使用了吗?答案不是的,只要 Go 的结构体不作为导出函数的参数或者返回值就可以。
1 | // 文件名:file.go |
然后交给 Python 来访问:
1 | from ctypes import * |
我们看到 Python 依旧可以正常调用,两个结构体成员的类型可以是 Go 的类型、也可以是 C 的类型,区别就是需要类型转化的地方不同罢了。Go 中的结构体,它没有作为参数和返回的话是可以正常使用的,但是一旦作为参数或者返回值就不可以了,因为 Go 不允许我们这么做,所以我们只能使用 C 中的结构体。
返回一个结构体
下面来看看如何返回一个结构体:
1 | // 文件名:file.go |
Python 调用的话依旧很简单:
1 | from ctypes import * |
传入结构体指针
结构体指针我们也是可以传递的,举个栗子:
1 | // 文件名:file.go |
在 Python 中创建一个结构体传进去,然后值会被修改:
1 | from ctypes import * |
注意:传递一个指针可以,但是返回一个指针不行。因为 Go 语言是类型安全的,比如一个变量究竟该分配在堆上、还是分配在栈上,Go 编译器会进行逃逸分析,是否返回指针便是决定一个变量究竟分配在什么地方的一个主要因素。而一旦返回指针给其他语言,那么 Go 就无法决定这块内存究竟何时该被回收,所以 Go 中不允许返回指针。而且对于 Python 来讲,Go 返回一个值还是指针,对于 Python 而言几乎没什么区别,无非是获取的方式不一样。所以我们不会在 Go 中返回一个指针,但是传递一个指针是可以的。
函数调用
函数是 C 语言编程的核心,通过 CGO 技术我们不仅仅可以在 Go 语言中调用 C 语言函数,也可以将 Go 语言函数导出为 C 语言函数。对于一个启用 CGO 特性的程序,CGO 会构造一个虚拟的 C 包,通过这个虚拟的 C 包可以调用 C 语言函数。
1 | // 文件名:file.go |
这一点我们之前就见过了,但是 Go 文件里面的 C 函数不仅可以让 Go 自身调用,还可以交给 Python 调用。Go 文件里面的 C 函数和使用 export 导出的 Go 函数(导出之后就变成了 C 函数)是等价的,都是可以被 Python 调用的,我们还是对该文件进行编译得到动态库。
1 | from ctypes import * |
Python 向 C 传递函数
Python 不能直接向 Go 的导出函数中传递函数,我们需要在里面定义一个 C 的函数,Python 只能向 C 的函数中传递函数。
1 | // 文件名:file.go |
里面的 add 接收两个整型和一个函数指针,这个函数指针指向的函数接收两个 int *,我们依旧实现两个数相加。
1 | from ctypes import * |
当然如果函数比较复杂的话,或者内容比较多的话,我们还可以分成多个源文件来写。
1 | // 1.h |
此时 Go 源文件的代码就变得简单了;
1 | // 文件名:file.go |
然后编译成动态库就不要加上文件名了,直接 go build -buildmode=c-shared -o libgo.so 对整个目录进行编译。那么 Python 可不可以调用呢?我们试一下:
1 | from ctypes import * |
不仅如此,我们还可以直接使用 Go 中的导出函数作为 C 函数中的一个参数,我们的 .h 和 .c 文件都不变,只修改一下 Go 源文件:
1 | // 文件名:file.go |
我们在 Go 文件中定义相应的函数,不在 Python 中定义了,然后 Python 直接调用:
1 | from ctypes import * |
数组
再来看看如何操作数组,这里操作的数组只能是 C 中的数组,因为在 Go 里面不允许导出一个参数或返回值是数组的函数。最关键的是,Go 数组的表达能力没有 C 数组那么丰富。
在 Go 里面数组的长度也是类型的一部分,这一点完全限制了数组的表达能力。而 C 中的数组类型与长度无关,比如在 C 的结构体中声明一个长度为 1 的数组,但是我们可以把它当成长度为 n 的数组来用。
1 | // 文件名:file.go |
然后我们来在 Python 中构建一个数组:
1 | from ctypes import * |
需要注意的是,数组的类型一定要正确,我们之前说对于整数而言,long 和 int 实际上没有太大差别。如果一个函数接收的是 long,那么我们传递一个 int 也是可以的,反之亦然(只要都存的下,不会溢出即可)。但是对于数组而言就不行了,函数中接收的数组里面的元素是 int,我们也必须要传递 int,否则指针在移动的时候会出问题。
我们往 C 里面传递一个数组是没有问题的,因为内存是在 Python 中申请的,C 拿到的只是一个指针罢了。但是我们不能在 C 中构建一个数组然后返回,因为如果 C 中返回了一个数组,那么它要么是静态数组、要么是堆上申请的数组。但是问题来了,这些数组的内存最终由谁来释放?Python 显然是无能为力的,更何况这些 C 代码还嵌套在 Go 里面。
尽管 C 无法返回一个数组,但是可以对我们传递的数组进行修改。或者说先创建一个普通数组,然后把内容再拷贝到我们传递的数组中,函数结束后 C 中的数组再被释放掉。
1 | // 文件名:file.go |
我们将传递过来的数组里面的元素都加上 100:
1 | from ctypes import * |
以上就是 Python 向 C 传递数组,例子比较简单。
但是问题来了,此时貌似压根就没有 Go 什么事情,因为里面根本就没有涉及到 Go。原因就是 Go 无法导出一个参数或者返回值为 Go 数组的函数(由于数组的长度也是类型的一部分,导致灵活性也大大降低),并且我们也不能像 C 一样声明一个 arr *C.int、然后把 arr 当成数组使用,这是不允许的,在 Go 里面该 arr 只能是一个指向整型的指针。于是可能有人想到了切片,在 Go 里面切片可以作为导出函数的参数或返回值,但是 Go 里面的切片比较特殊、它本质上是一个结构体:
1 | // runtime/slice.go |
Python 传递一个数组过来的话,我们在操作的时候可能会出问题。我们先举个栗子看看 Go 自身访问是什么情况:
1 | // 文件名:file.go |
我们看到对于 Go 的 int 而言,结果是正常的,但是对于 C.int 却得到了一个乱七八糟的脏数据。Go 自身访问会得到错误数据,如果是作为导出函数让 Python 访问,那么首先会报错,并且解释器还会异常退出。
那么我们能不能直接通过下标的方式来访问呢?答案是:在 Go 里面是可以的,因为 Go 的导出函数接收的是一个切片,只要我们也传递切片即可。
1 | // 文件名:file.go |
但如果这个函数给 Python 调用的话,会产生如下后果:

我们看到会出现段错误,此时解释器会直接异常退出,不是使用异常捕获能解决的了的问题。原因就在于操作了一个无效的内存地址,Go 不会出问题是因为它接收的是切片、传递的也是切片,而 Python 传递的是一个数组,对于 Go 而言切片和数组是不同的。
结论:我们可以传递一个数组,但只能向 C 的函数传递,因为 Go 的导出函数的参数或返回值不能是 Go 数组。也不要试图使用切片,很容易造成段错误。
内存模型
我们目前的做法是将 Go 的函数导出给 Python 使用,因此就会受到很多限制,比如不能返回指针等等。原因就是我们之前说的,Go 是一个类型安全的语言,一旦返回指针之后给 Python 使用,那么 Go 编译器就无法把控该指针指向的变量的声明周期了。举个栗子:
1 | // 文件名:file.go |
我们看到 return_pointer 返回了一个指针,但是在 Go 里面使用是没有任何问题的,原因就是 Go 编译器会进行逃逸分析,或者说此时对函数的调用仍然是发生在 Go 里面。只要是在 Go 里面,那么编译器就能牢牢地把控,可一旦交给 Python 使用,就意味着它要独立于 Go 了。
1 | from ctypes import * |
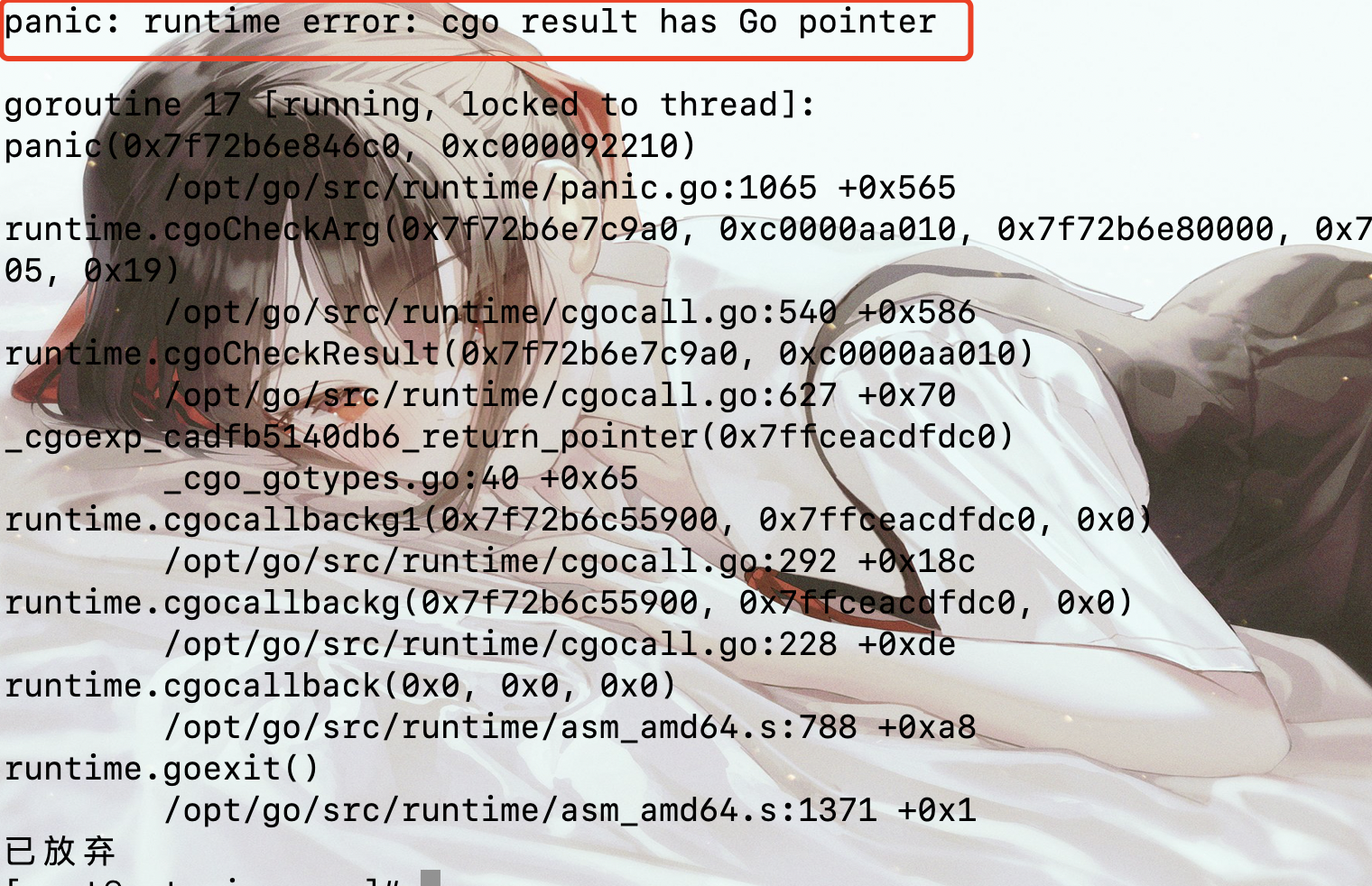
Python 在调用导出函数的时候直接就异常了,告诉我们 Go 的导出函数中返回了一个指针,所以 Python 在和 Go 交互的时候是会受到很多限制的。但是 C 和 Go 交互的时候是没有限制的,不仅可以返回指针,而且还可以通过 C 来为 Go 创建一个超过 2GB 的切片。因为 Go 的切片是有大小限制的,不能超过 2 GB,但是我们可以通过 C 的 malloc 申请超过 2 GB 的内存,然后再转成 Go 的切片。
Go 和 C 之间的访问是很自由的,主要是 Go 编译器能够把握全局,然而一旦导出函数给别的语言使用,Go 编译器就鞭长莫及了。所以 Python 在访问 Go 的时候才会有这么多限制,毕竟两门语言的内存模型不同,当同一段内存被跨语言操作时肯定会非常危险,因此对于 Go 这种类型安全的语言压根就不允许访问一个返回指针的导出函数。
但我们之前返回一个 *C.char 为什么可以呢?原因就是我们调用了 C.CString,此时返回的字符串是在 C 中申请的,所以它可以返回。而像 var a C.int 这种,此时 a 的内存是在 Go 里面被申请的,因此我们不能返回 &a。举个栗子,如果我们返回字符串不是调用 C.CString 的话,看看会有什么后果:
1 | // 文件名:file.go |
假设我们有一个切片,那么我们可以直接将底层数组的地址返回转成 * C.char 返回,注意:此时 C 字符串和 Go 的底层数组之间是共享内存的,因此省去了开销。
但是这个 return_string 不可以给 Python 调用,因为我们将切片对应的底层数组的地址返回了。换句话说内存依旧是在 Go 里面申请的,而我们返回了指向该内存的指针,所以 Python 调用的话依旧会出现 panic: runtime error: cgo result has Go pointer。
不要试图返回一个指向 Go 申请的内存的指针给 Python。
问题来了,我们之前就说 C.CString 存在一个巨大的缺陷, 那就是返回的字符串是 C 在堆区申请的,那么这个字符串最后要由谁来释放?
1 | // 文件名:file.go |
然后我们给 Python 来调用:
1 | from ctypes import * |
这种做法看似没有问题,虽然结果也是正确的,但是却有一个重大的隐患。因为在返回 C 的字符串之后,Python 会拷贝得到一份 bytes 对象,但问题是这个 C 字符串它是不会主动释放的。假设我们的字符串比较长,而且是在一个不间断的服务中调用 Go 编写的动态库,那么后果是很严重的。我们将 Python 的代码改一下:
1 | from ctypes import * |
你会发现,内存没一会就被占满了,执行的时候可以通过 top 命令看到内存使用率蹭蹭的网上长。
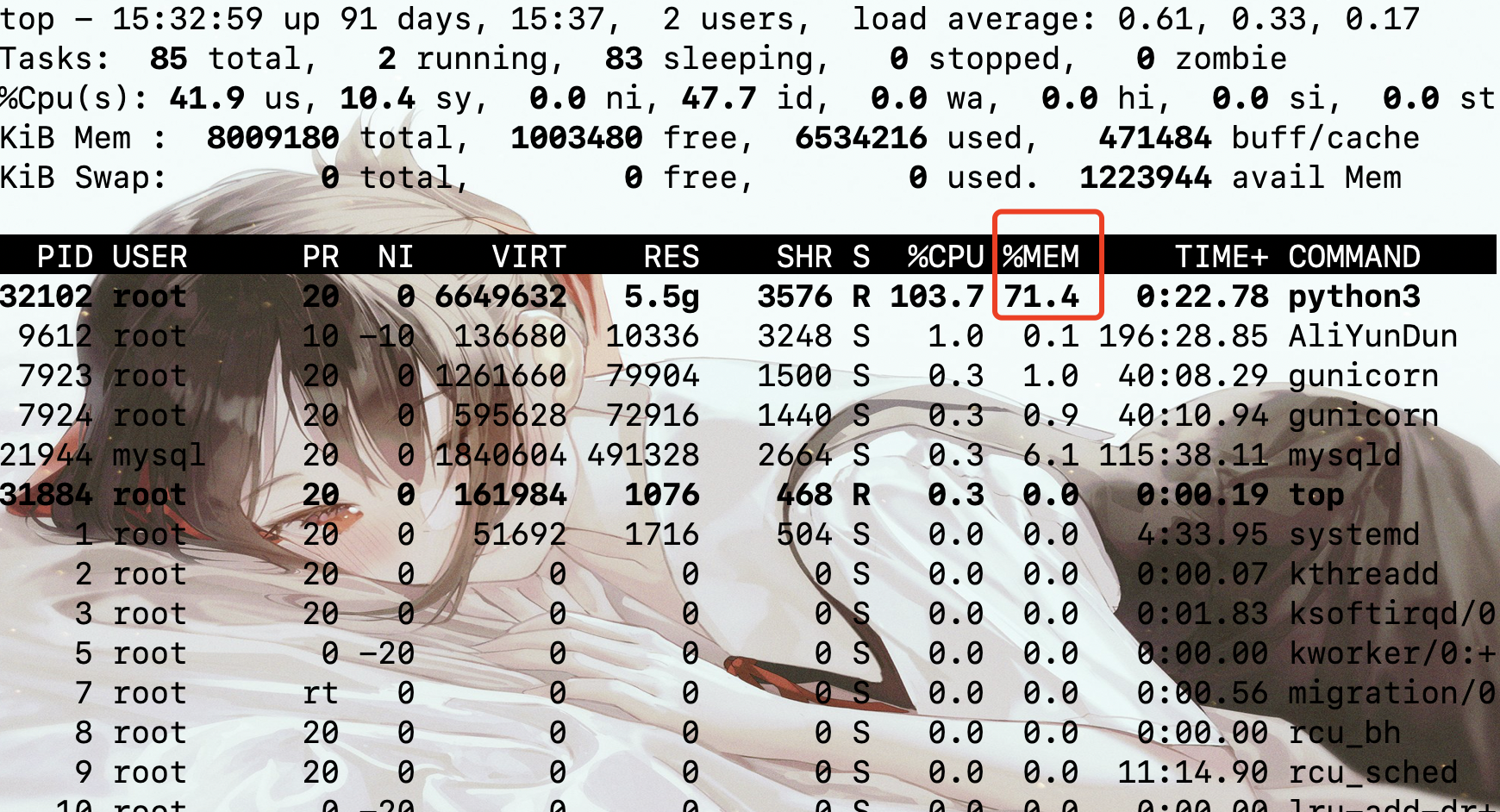
而导致这一点的原因就是返回的 C 字符串没有被释放,每一次执行都会创建这么一个字符串。因此我们一定要将其释放掉,释放的方式是使用 free,但问题是这个 free 要如何使用?下面这种做法可以吗?
1 | // 文件名:file.go |
如果你编译成动态库之后让 Python 调用的话,你会发现解释器得不到正确结果,而且有可能会异常退出,原因就是我们在将字符串返回给 Python 之前,就已经将其回收了,那么 Python 拿到的就是一块非法的内存。
因此正确的做法是:先正常返回,Python 在获取到值之后 Go 再将其释放掉,不过这样就又产生了一个问题:那就是地址要如何保存。因为必须要确保 Python 能够获取字符串(意味着 Go 中导出的执行函数的 return 语句结束,显然此时该函数也已经结束),然后再将 C 字符串销毁,所以我们肯定还需要一个函数,这个函数接收一个地址、然后专门用来对 C 字符串进行释放。
那么又回到了开始的问题,地址怎么办?由谁来保存,思考一下不难发现应该由 Go 负责保存。因为 Python 获取结果的时候,实际上也是将 C 的字符串拷贝一份得到 Python 的 bytes 对象,因此在 Python 中你是拿不到相应的地址的,使用 id 查看得到也是 Python 对象的地址。所以解决办法是我们可以在 Go 中使用一个全局变量专门负责保存地址,举个栗子:
1 | // 文件名:file.go |
然后我们使用 Python 来进行测试,看看是否有效:
1 | from ctypes import * |
此时不管持续多长时间,内存都不会有太大变化,证明该方法是有效的。
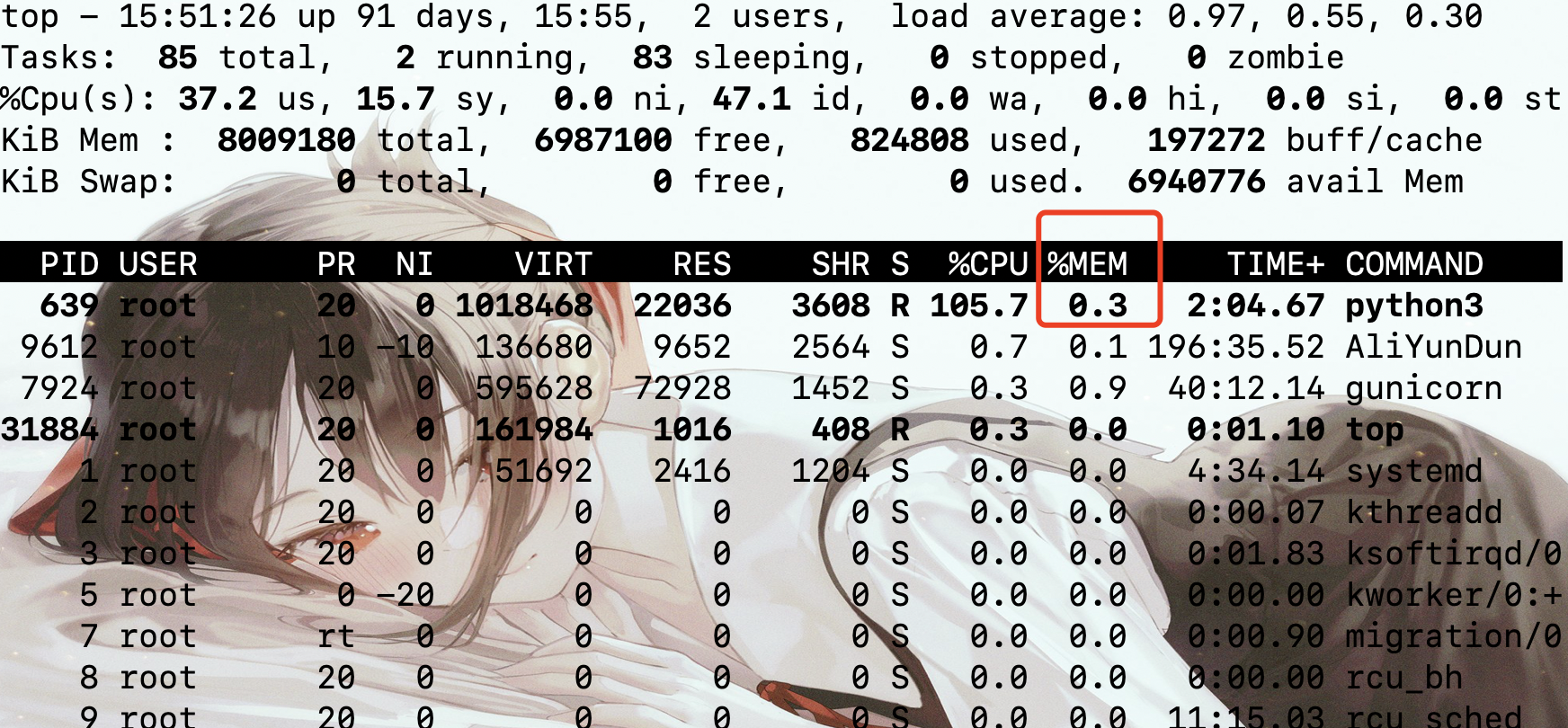
如果我们将 libgo.release_memory() 给注释掉的话,那么会发现内存使用率再度蹭蹭往上涨。所以对于那些需要回收的数据,我们就可以通过这种方式来释放,每调用一次就释放一次即可。对于数值类型我们无需担心,我们只需要关注字符串即可,至于结构体,如果里面包含 char *,那么同样需要考虑字符串的释放问题,但是不建议返回这种复杂的数据结构。
因此我们更关心字符串,因为它非常容易造成内存泄漏,那么什么时候应该进行回收呢?答案是:如果是使用 C.CString 返回的字符串,我们是一定要进行回收的;如果看一下上面的 Go 代码的话,你会发现参数是一个 char * 类型的变量 s,那么这个变量 s 不需要回收吗?其实是不需要的,还是那句话我们只需要对 C.CString 返回的字符串进行回收即可。
如果 C.CString 返回的字符串作为了返回值,那么显然不能在执行函数的过程中删除,使用 defer 也不可以,因为要确保 Python 能够拿到返回值,就不能在函数执行过程中回收;而解决办法就是我们上面说的定义一个专门用来释放的函数,但是程序中未必只有一个 C.CString 啊。是的,如果不止一个,那么就把不被 Python 接收的C字符串在函数执行过程中释放掉。比如:
1 | //export return_string |
我们 return 了 res3,那么 res1 和 res2 在用完之后就直接释放掉即可,而 res3 是需要被 Python 接收的,所以它需要使用另一个函数单独释放。还是那句话:只需要释放 C.CString 返回的字符串,如果把上面代码改一下:
1 | //export return_string |
那么你会发现 Python 解释器在调用的时候直接就异常退出了,原因是上面 res1、res2、res3 都是指向同一个字符串,而 C.free 对其释放了两次。所以当调用这个执行函数的时候就直接崩溃了,解决办法就是将那两个 C.free 注释掉即可,因为 res3 被返回了,所以它应该由专门的函数进行一次释放即可。当两个 C.free 被注释掉之后,会发现 Python 又调用正常了。
总结:
1. 关于字符串,我们需要对其进行释放,否则会一直停留在堆区,如果字符串比较大、或者是长时间运行的服务,很容易造成内存溢出;
2. 一旦字符串作为返回值返回,那么不可以在执行函数内部释放它,而是保存它的地址,然后由专门的函数去释放;
3. 我们只需要对 C.CString 返回的字符串进行释放,所以应该使用变量进行接收,如果一旦使用完毕就直接释放掉;
4. 因为 C 字符串是由一个指针指向,所以如果是变量之间的传递的话,那么不管有多少个变量,字符串在内存中只有一份;因此最直观的做法就是:有多少个 C.CString 就释放多少次,所以使用变量作为左值,然后只对那些出现 C.CString 的赋值语句中的左值进行 free 即可。
这里多提一句,关于 Go 给 Python 提供动态库,需要遵循一个原则:Go 中导出的执行函数的内部逻辑可以很复杂,但是参数和返回值一定要简单。因为这两者之间是需要通过 C 来作为媒介,参数和返回值必须能用 C 准确表达,所以建议只选择整型、浮点型、字符串这三种。
最关键的是内存方面,对于 Go 中的数据结构我们完全不需要关心,因为 Go 的垃圾回收机制会解决它,我们只需要关注 C 中的字符串即可,而原则就是我们上面说的那样。另外在 Go 中不允许返回指针,原因我们也说过了,因为 Go 中的指针是类型安全的,只要在 Go 里面,那么 Go 的编译器便可以牢牢地把控它们。但是一旦将指针返回了,不好意思,即使你能编译成功,当 Python 调用时也会报错,会提示你 panic: runtime error: cgo result has Go pointer。所以只要返回值带有”取址符”,Python 在调用时都是不允许的,当然返回切片也是不允许的,甚至(*C.char)(unsafe.Pointer(&s))也不允许,因为它也是一个指针,C 的字符串只能通过 C.CString 的方式。
因此我们只建议返回整型、浮点型或者字符串,像数组、map 我们可以转成 json,然后再让 Python 对其进行解析即可。
我们举个栗子:
1 | // 文件名:file.go |
将 json 变成 C 字符串,然后返回,这里为了简便就不写释放逻辑了:
1 | from ctypes import * |
我们看到导出函数中可以编写更加复杂的逻辑,可以做很多的操作,但是参数和返回值一定要简单。因为内部逻辑再复杂,那也是在 Go 的内部,不需要 Python 关心。但参数和返回值就不一样了,它们是需要 Python 和 Go 同时理解的,因此我们要秉承着最保守的原则,使用那些 Python 和 Go 都能准确理解、并且不会产生歧义的数据结构。
Go 源文件编译成静态库、动态库并结合 Cython
对于使用 ctypes 调用而言,Go 的动态库叫什么名字其实无关紧要,但是在 Linux 中静态库和动态库的命名是有规范的,我们在使用 gcc 进行链接的时候需要遵循这种规范。首先静态库以 .a 为后缀、动态库以 .so 为后缀,并且它们的名字都必须以 lib 开头。比如我们上面指定的 libgo.so,然后在链接的时候把开头的 lib 和结尾的 .so 去掉、也就是只需要指定 “go” 即可,会自动寻找 libgo.so 这个动态库,如果没有 libgo.so,那么会去寻找静态库 libgo.a。
我们还是编写 Go 源文件:
1 | // 文件名:go_fib.go |
然后我们来使用 go build 根据 go 源文件生成静态库:
1 | go build -buildmode=c-archive -o 静态库文件 [go源文件1, go源文件2, go源文件3, ...] |
然后我们还需要一个头文件,这里定义为 go_fib.h:
1 | double go_fib(int); |
里面只需要放入一个函数声明即可,具体实现在 libfib.a 中,然后编写 Cython 源文件:
1 | # 文件名:fib.pyx |
然后我们来进行编译:
1 | # 文件名:setup.py |
然后我们执行 python3 setup.py build,执行成功之后,会生成一个 build 目录,我们将里面的扩展模块移动到当前目录,然后进入交互式 Python 中导入它,看看会有什么结果。
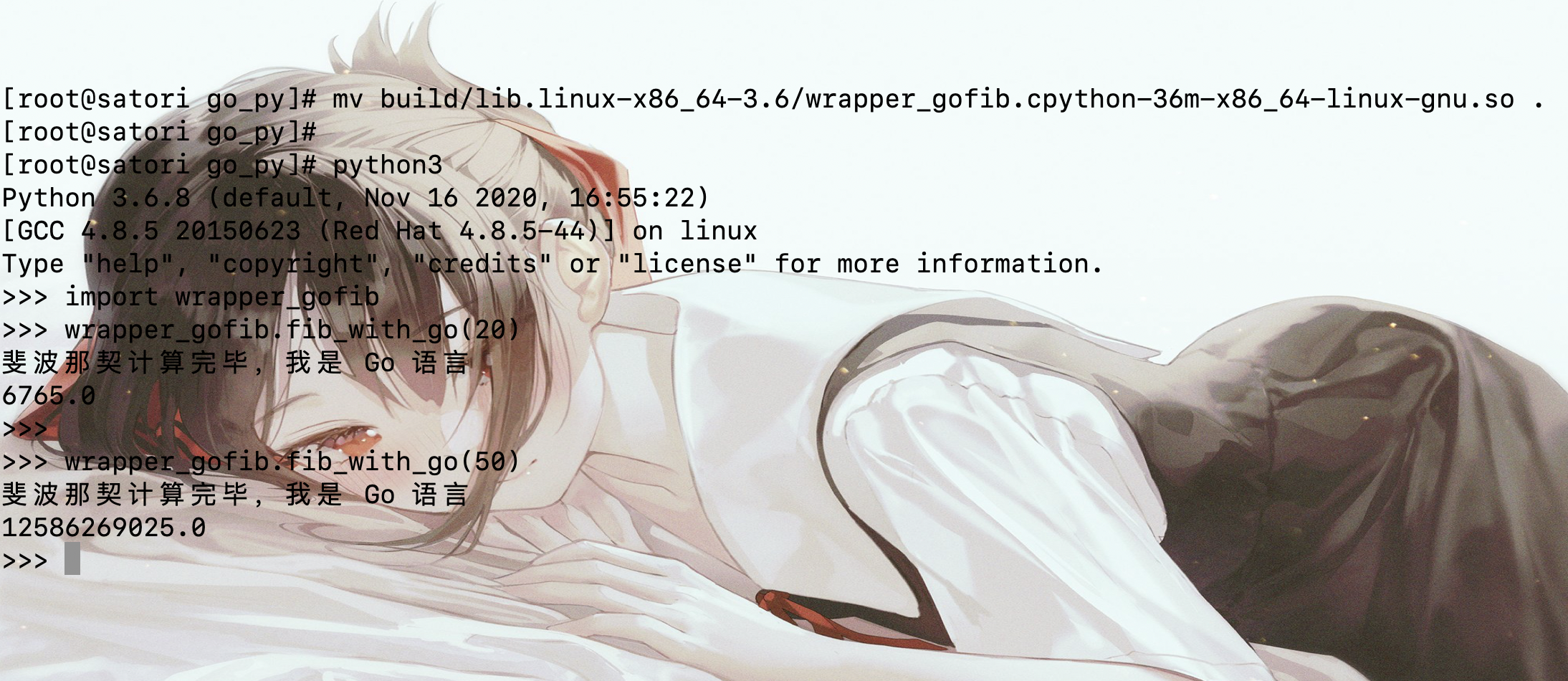
除了静态库之外,Cython 还可以包装动态库,我们只需要生成 libfib.so 即可,其它不需要有任何改动。因为 gcc 在链接的时候,如果指定的是 fib、那么优先链接 libfib.so,当 libfib.so 不存在的时候才会去链接 libfib.a。只不过在生成扩展模块之后,对应的动态库不可以丢,它是在运行的时候被动态加载的,不仅不能丢、还要将所在路径配置到 /etc/ld.so.conf 中,否则找不到;而对于静态库而言,在链接的时候会把静态库的内容都包含进去,所以编译之后是可以独立于相应的静态库的。
因此这就是 Cython 的强大之处,它将 C 的性能引入了 Python 中,Cython 同时理解 C 和 Python,可以直接包装 C、C++ 源文件、静态库、动态库。关于 Cython,它是一门单独的技术,值得去学习。
关于 Cython,可以看 https://www.cnblogs.com/traditional/tag/Cython/ 。
由 Cython 释放内存
本来这一部分之前是没有的,然而在 B 站上有一个小伙伴问了我一个问题:
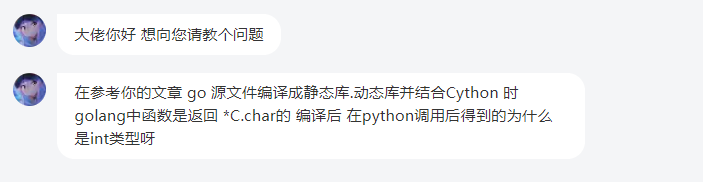
这个问题很简单,我们看一下怎么做。首先编写 Go 源文件:
1 | // 文件名:return_string.go |
编译成静态库:
1 | go build -buildmode=c-archive -o libreturn_string.a return_string.go |
然后编写头文件:
1 | // 文件名 return_string.h |
注意:Go 编译器在生成 libreturn_string.a 的同时,也会自动生成一个 libreturn_string.h,我们直接用自动生成的头文件也是可以的。
最后是 Cython 源文件:
1 | # 文件名:return_string.pyx |
以上就完事了,然后编译成 Python 扩展模块:
1 | from distutils.core import setup, Extension |
然后我们来测试一下:
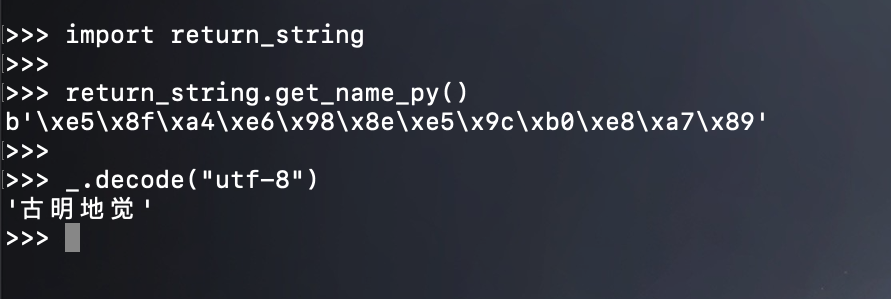
结果上是没有问题的,上面的小伙伴调用之后得到的整型,估计是函数声明的时候返回值类型写错了。当然我这里之所以单独拿出来说一下,并不是为了这个,而是为了引出内存释放这一话题。我们在 Go 里面返回了字符串,这个字符串是 C 在堆区创建的,Python 在调用之后,这个字符串依旧会停在堆区,不会被释放。
1 | import return_string |
调用这个死循环,会发现内存占用瞬间飙升,原因就是每调用一次就会在堆区创建一个字符串,并且字符串还不会被回收。所以问题来了,我们要如何将 C 在堆区申请的字符串给释放掉呢?
在 Python 使用 ctypes 调用动态库的时候,我们说过,在 Go 里面需要有一个全局变量来保存字符串的指针,然后再定义一个函数,在里面调用 C.free 进行释放。但是在 Cython 中我们完全不需要这么做,因为 Cython 同时理解 C 和 Python,我们完全可以在 Cython 里面去释放这个堆区的字符串。
1 | from libc.stdlib cimport free |
此时重新编译,然后再调用的话,会发现不管调用多少次,内存占用都不会往上涨,因为堆区字符串会被回收。而之前内存占用上涨的原因是我们直接 return get_name(),那么在将堆区的字符串拷贝一份得到 bytes 对象之后就直接返回了,但堆区的字符串并没有被回收。
显然此时就方便多了,我们不需要再通过回调的方式在 Go 里面释放了,因为在 Go 里面也是要通过 C 来释放的(调用 C.free)。而我们说 Cython 同时理解 C 和 Python,所以在 Cython 里面释放完全等价。并且此时对导出函数的返回值也没有任何要求,返回数组、结构体、指针统统都是没有问题的,Cython 都是支持的。
这也算是一个比较重要的地方吧,值得说明一下。
Go 源文件直接编译成 Python 扩展模块
直接编写扩展是一件难度比较大的事情,因为这要求你严格遵循 Python/C API,所以才有了 Cython。那么如何用 Go 来给 Python 写扩展呢,首先还是那句话,Python 和 Go 之间是通过 C 进行交互的,所以用 Go 写扩展实际上还是相当于用 C 写扩展。但其实 Go 写扩展并没有 C 写扩展方便,因为 CPython 提供的一些宏在 Go 里面没办法通过 C 这个名字空间进行引用,而且还不能调用具有可变参数的 C 函数。比如 CPython 解析函数参数时会使用一个函数:
1 | int PyArg_ParseTuple(PyObject *args, const char *format, ...); |
这个函数你在 Go 里面没法直接用,因为它包含可变参数 ...,如果我们调用 C.PyArg_ParseTuple,Go 编译器会报错。解决办法是你要在 import "C" 上面的 C 代码中单独定义一个包装器,所以还是比较麻烦的。那么下面我们来简单实现一下 Python 的 binascii 模块里面的两个函数,看看 Go 是如何编写 Python 扩展的。
1 | import binascii |
在 binascii 里面有这两个函数,我们下面就来用 Go 实现它们,先来介绍一下这两个函数吧。binascii.hexlify 是将数据用 16 进制表示,binascii.unhexlify 则是前者的逆运算。
1 | import binascii |
了解完函数原理之后,我们接下来就用 Go 来写扩展实现它们。
1 | package main |
里面涉及到的一些细节就不详细说了,使用 Go 写扩展首先需要了解如何使用 C 写扩展,而且正如之前所说,用 Go 写扩展反而会没有 C 方便。原因就是 CPython 解释器内置了大量的宏,这些宏在 Go 里面没法直接通过 C 这个名字来进行引用,还有上面说的具有可变参数的 C 函数,不能直接调用,必须定义一个包装器才可以(个人觉得这算是最大的硬伤);以及 Python 底层的数据结构、C 的数据结构、Go 的数据结构三者要经常来回转化,还有引用计数的增加、减少,堆区上 C 字符串的释放等等,个人觉得这些东西处理起来不是一件简单的事情。个人觉得最好的做法还是前两种,如果熟悉 Cython 则更推荐第二种,至于这里的第三种:用 Go 直接给 Python 写扩展,个人不是很推荐。
而上面的代码则是简单实现了 hexlify、unhexlify 两个函数,我们来测试一下吧。
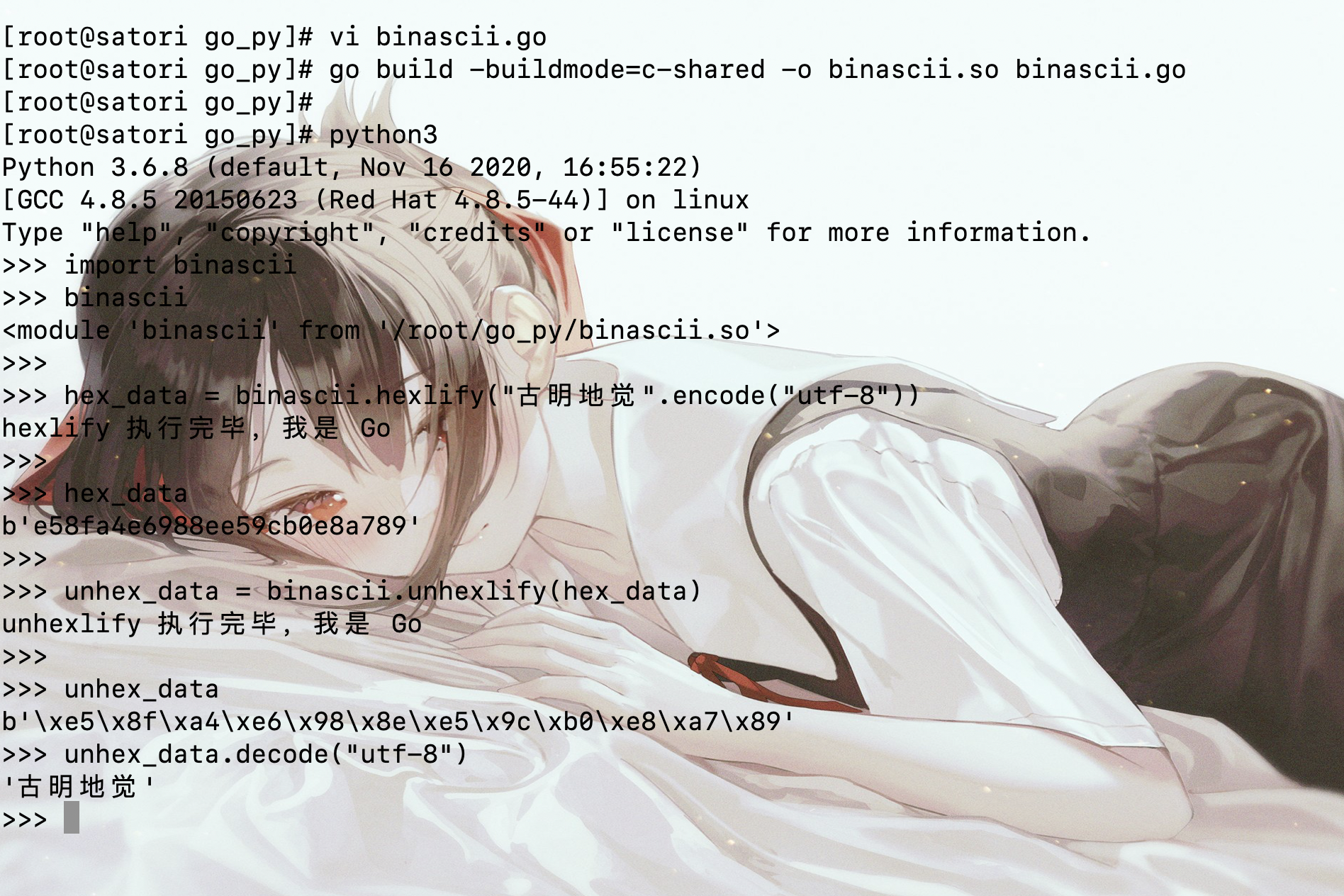
从结果上来看是没有任何问题的,但这是参数类型传递正确的前提下。因为我们这里没有对参数进行检测,假设我们传递了一个整型过去,那么在执行 C.PyBytes_AsString 的时候很明显是会报错的。
当然这里关于扩展的更多细节,这里就不讨论了,个人觉得不管啥语言,直接写扩展都不是一件简单的事情。所以本人特别喜欢 Cython,因为它同时理解 C 和 Python,将 C 的高性能和 Python 的动态特性结合在了一起。
小结
以上就是在 Python 中引入 Go 的几种方式,当然 Go 里面也可以引入 Python,只不过个人是以 Python 作为主语言,所以只关注前者。而 Python 引入 Go 也有三种方式:
1. Go 直接编写动态库给 Python,然后 Python 解释器通过 ctypes 调用2. Go 编写静态库或者动态库,然后再由 Cython 包装成 Python 扩展,Python解释器直接 import3. Go 直接为 Python 提供扩展
第三种个人不推荐,因为受到的限制太多了,可以尝试前两种。