
34-侵入 Python 虚拟机,动态修改底层数据结构和运行时
34-侵入 Python 虚拟机,动态修改底层数据结构和运行时
楔子
之前分析了那么久的虚拟机,多少会有点无聊,那么本次我们来介绍一个好玩的,看看如何修改 Python 解释器的底层数据结构和运行时。了解虚拟机除了可以让我们写出更好的代码之外,还可以对 Python 进行改造。举个栗子:

是不是很有趣呢?通过 Python 内置的 ctypes 模块即可做到,而具体实现方式我们一会儿说。所以本次我们的工具就是 ctypes 模块(Python 版本为 3.8),需要你对它已经或多或少有一些了解,哪怕只有一点点也是没关系的。
注意:本次介绍的内容绝不能用于生产环境,仅仅只是为了更好地理解 Python 虚拟机、或者做测试的时候使用,用于生产环境是绝对的大忌。
不可用于生产环境!!!
不可用于生产环境!!!
不可用于生产环境!!!
那么废话不多说,下面就开始吧。
使用 Python 表示 C 的数据结构
Python 是用 C 实现的,如果想在 Python 的层面修改底层逻辑,那么我们肯定要能够将 C 的数据结构用 Python 表示出来。而 ctypes 提供了大量的类,专门负责做这件事情,下面按照类型属性分别介绍。
数值类型
C 语言的数值类型分为如下:
int:整型unsigned int:无符号整型short:短整型unsigned short:无符号短整型long:长整形unsigned long:无符号长整形long long:64 位机器上等同于 longunsigned long long:64 位机器上等同于 unsigned longfloat:单精度浮点型double:双精度浮点型long double:看成是 double 即可_Bool:布尔类型ssize_t:等同于 long 或者 long longsize_t:等同于 unsigned long 或者 unsigned long long
和 Python 以及 ctypes 之间的对应关系如下:

下面来演示一下:
1 | import ctypes |
而 C 的数据转成 Python 的数据也非常容易,只需要在此基础上调用一下 value 即可。
1 | import ctypes |
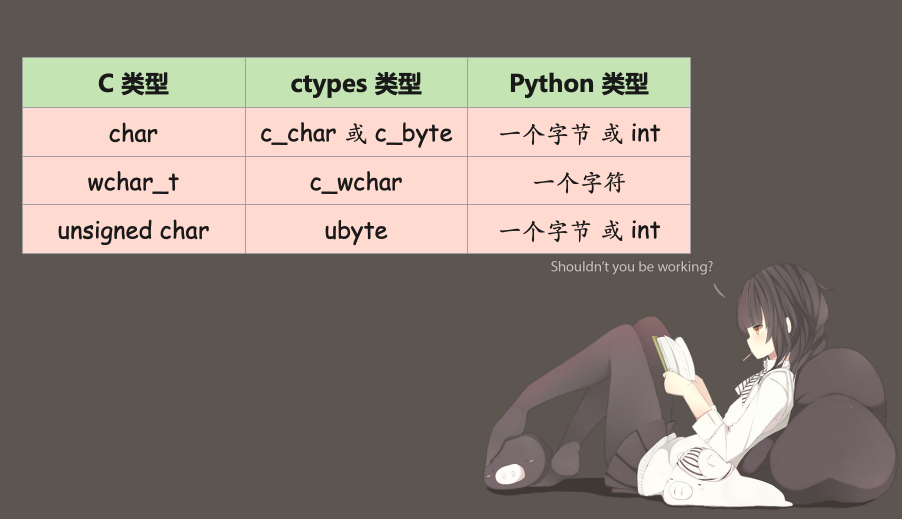
字符类型
C 语言的字符类型分为如下:
char:一个 ascii 字符或者 -128~127 的整型wchar:一个 unicode 字符unsigned char:一个 ascii 字符或者 0~255 的一个整型
和 Python 以及 ctypes 之间的对应关系如下:
举个栗子:
1 | import ctypes |
数组
下面看看如何构造一个 C 中的数组:
1 | import ctypes |
我们看一下数组在 Python 里面的类型,因为数组存储的元素类型为 c_int、数组长度为 5,所以这个数组在 Python 里面的类型就是 c_int_Array_5,而打印的时候则显示为 c_int_Array_5 的实例对象。我们可以调用 len 方法获取长度,也可以通过索引的方式去指定的元素,并且由于内部实现了迭代器协议,我们还可以使用 for 循环去遍历,或者使用 list 直接转成列表等等,都是可以的。
结构体
结构体应该是 C 里面最重要的结构之一了,假设 C 里面有这样一个结构体:
1 | typedef struct { |
要如何在 Python 里面表示它呢?
1 | import ctypes |
就像实例化一个普通的类一样,然后也可以像获取实例属性一样获取结构体成员。这里获取之后会自动转成 Python 中的数据,比如 c_int 类型会自动转成 int,c_float 会自动转成 float,而数组由于 Python 没有内置,所以直接打印为 “c_long_Array_5 的实例对象”。
指针
指针是 C 语言灵魂,而且绝大部分的 Bug 也都是指针所引起的,那么指针类型在 Python 里面如何表示呢?非常简单,通过 ctypes.POINTER 即可表示 C 的指针类型,比如:
C 中的 int *,在 Python 里面就是 ctypes.POINTER(c_int)C 中的 float *,在 Python 里面就是 ctypes.POINTER(c_float)
1 | from ctypes import * |
所以通过 POINTER(类型) 即可表示对应类型的指针,而获取指针则是通过 pointer 函数。
1 | # 在 C 里面就相当于,long a = 1024; long *p = &a; |
同理,我们也可以通过指针获取指向的值,也就是对指针进行解引用。
1 | from ctypes import * |
总的来说,还是比较好理解的。但我们知道,在 C 中数组等于数组首元素的地址,我们除了传一个指针过去之外,传数组也是可以的。
1 | from ctypes import * |
数组在作为参数传递的时候会退化为指针,所以此时数组的长度信息就丢失了,使用 sizeof 计算出来的结果就是一个指针的大小。因此将数组作为参数传递的时候,应该将当前数组的长度信息也传递过去,否则可能会访问非法的内存。
然后在 C 里面还有 char *、wchar_t *、void *,这些指针在 ctypes 里面专门提供了几个类与之对应。
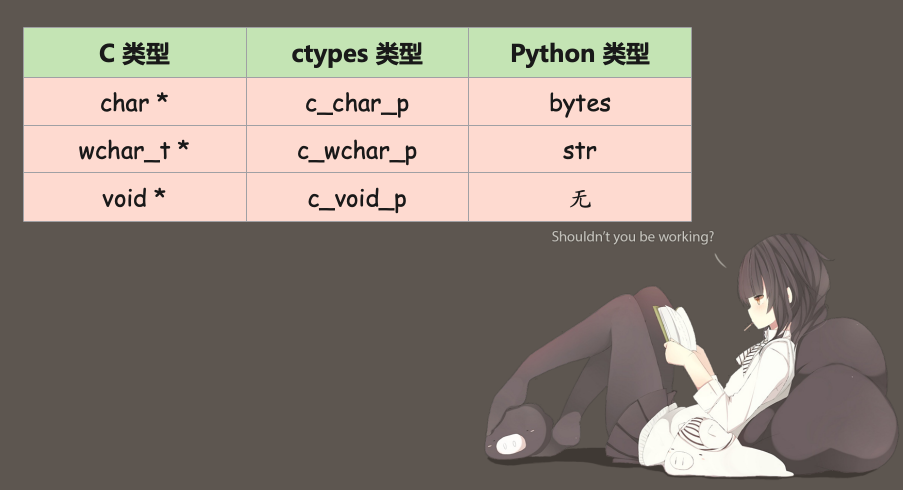
1 | from ctypes import * |
函数
最后看一下如何在 Python 中表示 C 的函数,首先 C 的函数可以有多个参数,但只有一个返回值。举个栗子:
1 | long add(long *a, long *b) { |
这个函数接收两个 long *、返回一个 long,那么这种函数类型要如何表示呢?答案是通过 ctypes.CFUNCTYPE。
1 | from ctypes import * |
类型转换
以上就是 C 中常见的数据结构,然后再说一下类型转化,ctypes 提供了一个 cast 函数,可以将指针的类型进行转化。
1 | from ctypes import * |
指针在转换之后,还是引用相同的内存块,所以整型指针转成浮点型指针之后,打印的结果乱七八糟。当然数组也可以转化,我们举个栗子:
1 | from ctypes import * |
原来数组元素是 int 类型(4 字节),现在转成了 long(8 字节),但是内存块并没有变。因此 t2 获取元素时会一次性获取 8 字节,所以 t1[0] 和 t1[1] 组合起来等价于 t2[0]。
1 | from ctypes import * |
模拟底层数据结构,观察运行时表现
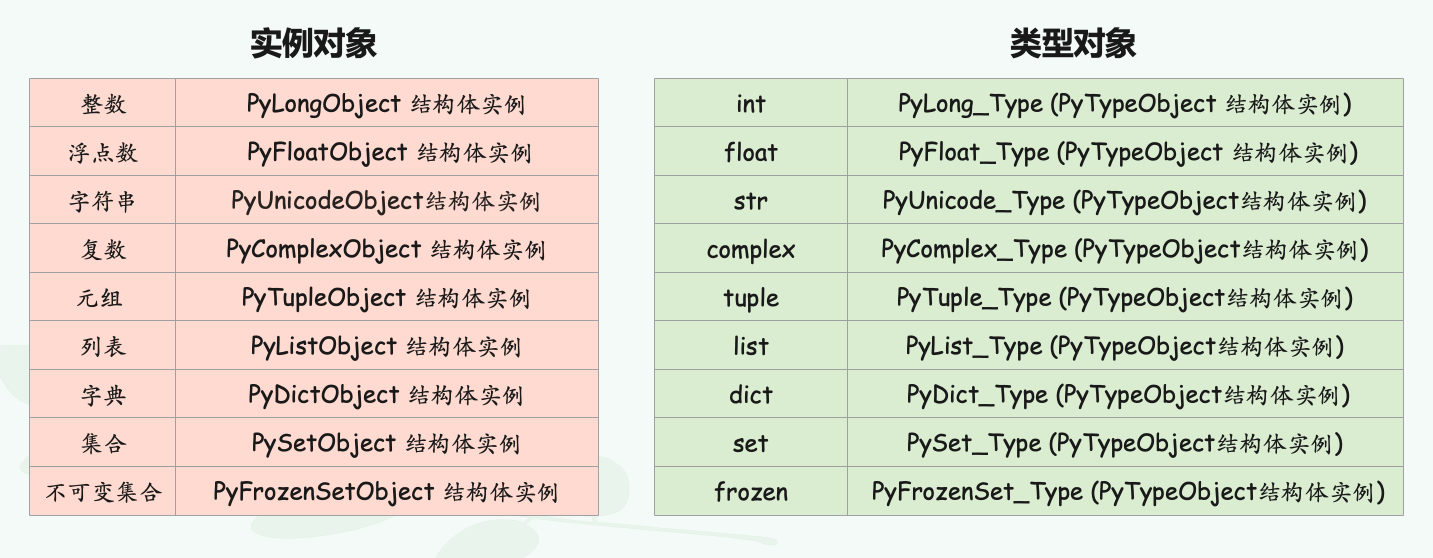
我们说 Python 的对象本质上就是 C 的 malloc 函数为结构体实例在堆区申请的一块内存,比如整数是 PyLongObject、浮点数是 PyFloatObject、列表是 PyListObject,以及所有的类型都是 PyTypeObject 等等。那么在介绍完 ctypes 的基本用法之后,下面就来构造这些数据结构来观察 Python 对象在运行时的表现。
浮点数
这里先说浮点数,因为浮点数比整数要简单,先来看看底层的定义。
1 | typedef struct { |
除了 PyObject 这个公共的头部信息之外,只有一个额外的 ob_fval,用于存储具体的值,而且直接使用的 C 中的 double。
1 | from ctypes import * |
我们修改 float_obj.ob_fval 也会影响 f,并且修改前后 f 的地址没有发生改变。同时我们也可以观察一个对象的引用计数,举个栗子:
1 | f = 3.14 |
所以这就是引用计数机制,当对象被引用,引用计数加 1;当引用该对象的变量被删除,引用计数减 1;当对象的引用计数为 0 时,对象被销毁。
整数
再来看看整数,我们知道 Python 中的整数是不会溢出的,换句话说,它可以计算无穷大的数。那么问题来了,它是怎么办到的呢?想要知道答案,只需看底层的结构体定义即可。
1 | typedef struct { |
明白了,原来 Python 的整数在底层是用数组存储的,通过串联多个无符号 32 位整数来表示更大的数。
1 | from ctypes import * |
当然我们也可以修改值:
1 | num = 1024 |
digit 是 32 位无符号整型,不过虽然占 32 个位,但是只用 30 个位,这也意味着一个 digit 能存储的最大整数就是 2 的 30 次方减 1。如果数值再大一些,那么就需要两个 digit 来存储,第二个 digit 的最低位从 31 开始。
1 | # 此时一个 digit 能够存储的下,所以 ob_size 为 1 |
当然了,用整数数组实现大整数的思路其实平白无奇,但难点在于大整数 数学运算 的实现,它们才是重点,也是也比较考验编程功底的地方。
字节串
字节串也就是 Python 中的 bytes 对象,在存储或网络通讯时,传输的都是字节串。bytes 对象在底层的结构体为 PyBytesObject,看一下相关定义。
1 | typedef struct { |
我们解释一下里面的成员对象:
PyObject_VAR_HEAD:变长对象的公共头部ob_shash:保存该字节序列的哈希值,之所以选择保存是因为在很多场景都需要 bytes 对象的哈希值。而 Python 在计算字节序列的哈希值的时候,需要遍历每一个字节,因此开销比较大。所以会提前计算一次并保存起来,这样以后就不需要算了,可以直接拿来用,并且 bytes 对象是不可变的,所以哈希值是不变的ob_sval:这个和 PyLongObject 中的 ob_digit 的声明方式是类似的,虽然声明的时候长度是 1, 但具体是多少则取决于 bytes 对象的字节数量。这是 C 语言中定义"变长数组"的技巧, 虽然写的长度是 1, 但是你可以当成 n 来用, n 可取任意值。显然这个 ob_sval 存储的是所有的字节,因此 Python 中的 bytes 对象在底层是通过字符数组存储的。而且数组会多申请一个空间,用于存储 \0,因为 C 中是通过 \0 来表示一个字符数组的结束,但是计算 ob_size 的时候不包括 \0
1 | from ctypes import * |
除了 bytes 对象之外,Python 中还有一个 bytearray 对象,它和 bytes 对象类似,只不过 bytes 对象是不可变的,而 bytearray 对象是可变的。
列表
Python 中的列表可以说使用的非常广泛了,在初学列表的时候,有人会告诉你列表就是一个大仓库,什么都可以存放。但我们知道,列表中存放的元素其实都是泛型指针 PyObject *。
下面来看看列表的底层结构:
1 | typedef struct { |
我们看到里面有如下成员:
PyObject_VAR_HEAD: 变长对象的公共头部信息ob_item:一个二级指针,指向一个 PyObject * 类型的指针数组,这个指针数组保存的便是对象的指针,而操作底层数组都是通过 ob_item 来进行操作的。allocated:容量, 我们知道列表底层是使用了 C 的数组, 而底层数组的长度就是列表的容量
1 | from ctypes import * |
元组
下面来看看元组,我们可以把元素看成不支持元素添加、修改、删除等操作的列表。元组的实现机制非常简单,可以看做是在列表的基础上丢弃了增删改等操作。既然如此,那要元组有什么用呢?毕竟元组的功能只是列表的子集。元组存在的最大一个特点就是,它可以作为字典的 key、以及可以作为集合的元素。因为字典和集合存储数据的原理是哈希表,对于列表这样的可变对象来说是可以动态改变的,而哈希值是一开始就计算好的,显然如果支持动态修改的话,那么哈希值肯定会变,这是不允许的。所以如果我们希望字典的 key 是一个序列,显然元组再适合不过了。
1 | typedef struct { |
可以看到,对于不可变对象来说,它底层结构体定义也非常简单。一个引用计数、一个类型、一个指针数组。这里的 1 可以想象成 n,我们上面说过它的含义。并且我们发现不像列表,元组没有 allocated,这是因为它是不可变的,不支持扩容操作。
这里再对比一下元组和列表的 ob_item 成员,PyTupleObject 的 ob_item 是一个指针数组,数组里面是泛型指针 PyObject *;而 PyListObject 的 ob_item 是一个二级指针,该指针指向了一个存放 PyObject * 的指针数组的首元素。
所以 Python 中的 “列表本身” 和 “列表里面的值” 在底层是分开存储的,因为 PyListObject 结构体实例并没有存储相应的指针数组,而是存储了指向这个指针数组首元素的二级指针。显然我们添加、删除、修改元素等操作,都是通过这个二级指针来间接操作这个指针数组。这么做的原因就在于对象一旦被创建,那么它在内存中的大小就不可以变了,因此这就意味着那些可以容纳可变长度数据的可变对象,要在内部维护一个指向可变大小的内存区域的指针,遵循这样的规则可以使维护对象的工作变得非常简单。
试想一下这样一个场景:一旦允许对象的大小可在运行期改变,那么假设在内存中有对象 A,并且其后面紧跟着对象 B。如果运行的某个时候,A 的大小增大了,这就意味着必须将 A 整个移动到内存中的其他位置,否则 A 增大的部分会覆盖掉原本属于 B 的数据。只要将 A 移动到内存的其他位置,那么所有指向 A 的指针就必须立即得到更新。可想而知这样的工作是多么的繁琐,而通过一个指针去操作就变得简单多了。
可以看到 PyListObject 实例本身和指针数组之间是分离的,两者通过二级指针(ob_item)建立联系;但元组不同,它的大小不允许改变,因此 PyTupleObject 直接存储了指针数组本身(ob_item)。
1 | from ctypes import * |
此时我们就成功修改了元组里面的元素,并且修改前后元组的地址没有改变。
要是以后谁跟你说 Python 元组里的元素不能修改,就拿这个例子堵他嘴。好吧,元组就是不可变的,举这个例子有点不太合适。
给类对象增加属性
我们知道类对象(或者说类型对象)是有自己的属性字典的,但这个字典不允许修改,因为准确来说它不是字典,而是一个 mappingproxy 对象。
1 | print(str.__dict__.__class__) # <class 'mappingproxy'> |
我们无法通过修改 mappingproxy 对象来给类增加属性,因为它不支持增加、修改以及删除操作。当然对于自定义的类可以通过 setattr 方法实现,但是内置的类是行不通的,内置的类无法通过 setattr 进行属性添加。因此如果想给内置的类增加属性,只能通过 mappingproxy 入手,我们看一下它的底层结构。
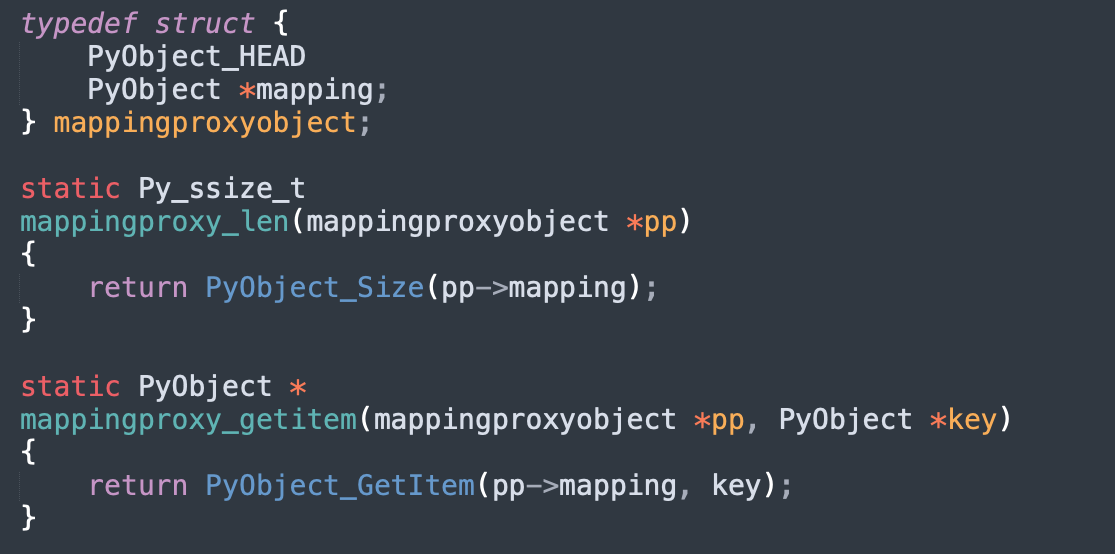
所谓的 mappingproxy 就是对字典包了一层,并只提供了查询功能。而且从函数 mappingproxy_len、mappingproxy_getitem 可以看出,mappingproxy 对象的长度就是内部字典的长度,获取 mappingproxy 对象的元素实际上就是获取内部字典的元素,因此操作 mappingproxy 对象就等价于操作其内部的字典。
所以我们只要能拿到 mappingproxy 对象内部的字典,那么可以直接操作字典来修改类属性。而 Python 有一个模块叫 gc,它可以帮我们实现这一点,举个栗子:
1 | import gc |
那么问题来了,你觉得 mappingproxy 对象引用了谁呢?显然就是内部的字典。
1 | import gc |
但是需要注意的是,我们上面添加的是之前没有的新属性,如果是覆盖一个已经存在的属性或者函数,那么还缺一步。
1 | from ctypes import * |
不过上面的代码还有一个缺点,那就是函数的名字没有修改:
1 | from ctypes import * |
我们看到函数在修改之后名字就变了,匿名函数的名字就叫
1 | from ctypes import * |
很明显,我们不仅可以修改 str,任意的内置的类都是可以修改的。
1 | lst = [1, 2, 3] |
我们还可以添加一个类方法或静态方法:
1 | patch_builtin_class( |
还是很有趣的,但需要注意的是,我们目前的 patch_builtin_class 只能为类添加属性或函数,但其 “实例对象” 使用操作符时的表现是无法操控的。什么意思呢?我们举个栗子:
1 | a, b = 3, 4 |
我们看到重写了 add 之后,直接调用魔法方法的话是没有问题的,打印的是重写之后的结果。而使用操作符的话(a + b),却没有走我们重写之后的 __add__,所以 a + b 的结果还是 7。
1 | s1, s2 = "hello", "world" |
我们重写了 sub 之后,直接调用魔法方法的话也是没有问题的,但是用操作符(s1 - s2)就会报错,告诉我们字符串不支持减法操作,但我们明明实现了 sub 方法啊。想要知道原因并改变它,我们就要先知道类对象在底层是怎么实现的。
类对象的底层结构 PyTypeObject
首先思考两个问题:
1. 当在内存中创建对象、分配空间的时候,解释器要给该对象分配多大的空间?显然不能随便分配,那么该对象的内存信息在什么地方?2. 一个对象是支持相应的操作的,解释器怎么判断该对象支持哪些操作呢?再比如一个整型可以和一个整型相乘,但是一个列表也可以和一个整型相乘,即使是相同的操作,但不同类型的对象执行也会有不同的结果,那么此时解释器又是如何进行区分的?
想都不用想,这些信息肯定都在对象所对应的类型对象中。而且占用的空间大小实际上是对象的一个元信息,这样的元信息和其所属类型是密切相关的,因此它一定会出现在与之对应的类型对象当中。至于支持的操作就更不用说了,我们平时自定义类的时候,方法都写在什么地方,显然都是写在类里面,因此一个对象支持的操作显然定义在类型对象当中。
而将一个对象和其类型对象关联起来的,毫无疑问正是该对象内部的 PyObject 中的 ob_type,也就是类型的指针。我们通过对象的 ob_type 成员即可获取指向的类型对象的指针,通过该指针可以获取存储在类型对象中的某些元信息。
下面我们来看看类型对象在底层是怎么定义的:
1 | typedef struct _typeobject { |
而 Python 中的类对象(类型对象)在底层就是一个 PyTypeObject 实例,它保存了实例对象的元信息,描述对象的类型。所以 Python 中的实例对象在底层对应不同的结构体实例,而类对象则是对应同一个结构体实例,换句话说无论是 int、str、dict,还是其它的类对象,它们在 C 的层面都是由 PyTypeObject 这个结构体实例化得到的,只不过成员的值不同,PyTypeObject 这个结构体在实例化之后得到的类型对象也不同。
这里我们重点看一下里面的 tp_as_number、tp_as_sequence、tp_as_mapping 三个成员,它们表示实例对象为数值、序列、映射时所支持的操作。它们都是指向结构体的指针,该结构体中的每一个成员都是一个函数指针,指向的函数便是实例对象可执行的操作。
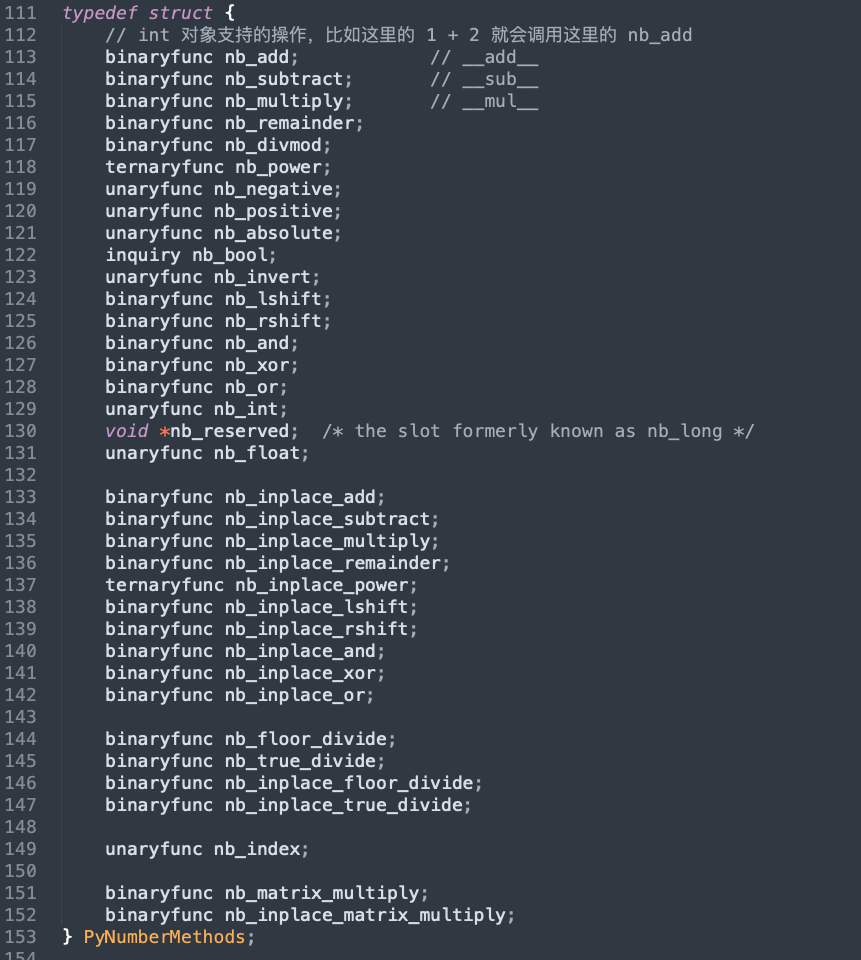
我们再看一下类对象 int 在底层的定义:
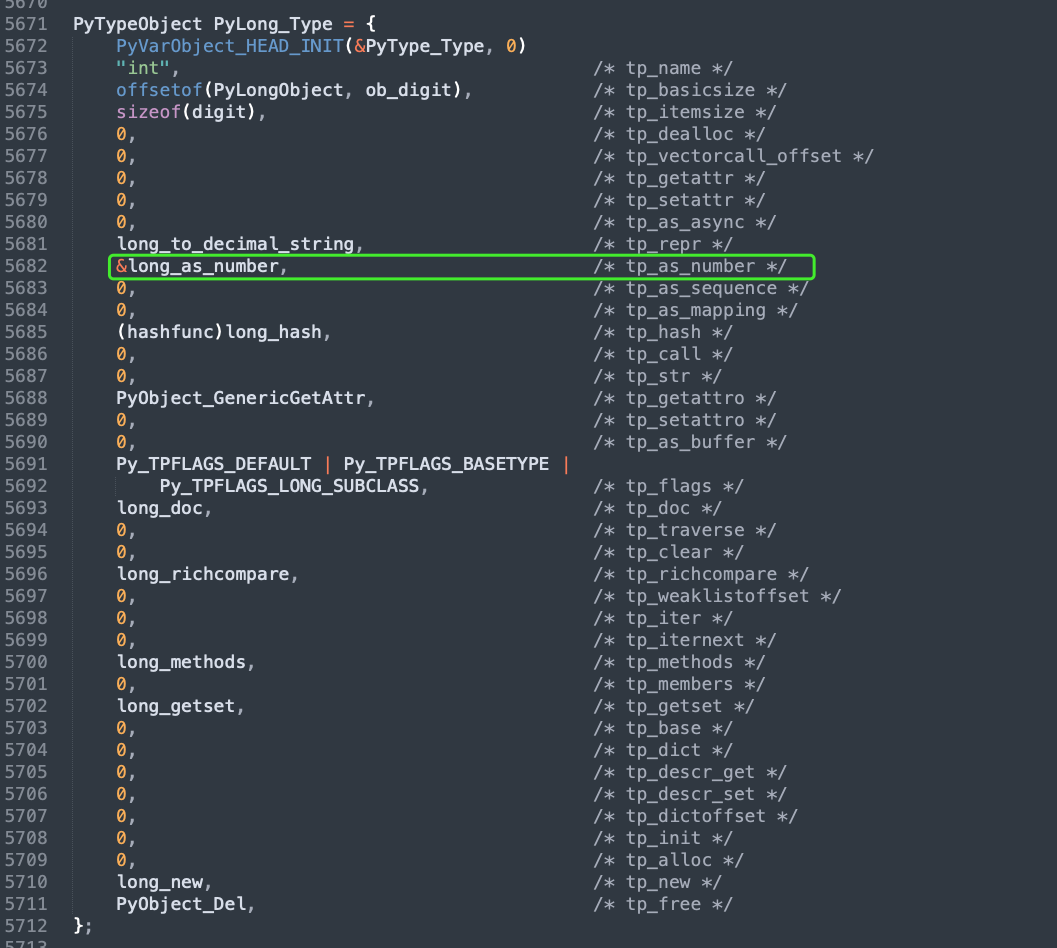
我们注意到它的类型被设置成了 PyType_Type,所以在 Python 里面 int 的类型为 type。然后重点是 tp_as_number 成员,它被初始化为 &long_as_number,而整型对象不支持序列和映射操作,所以 tp_as_sequence、tp_as_mapping 设置为 0。当然这三者都是指向结构体的指针类型,我们看一下 long_as_number。
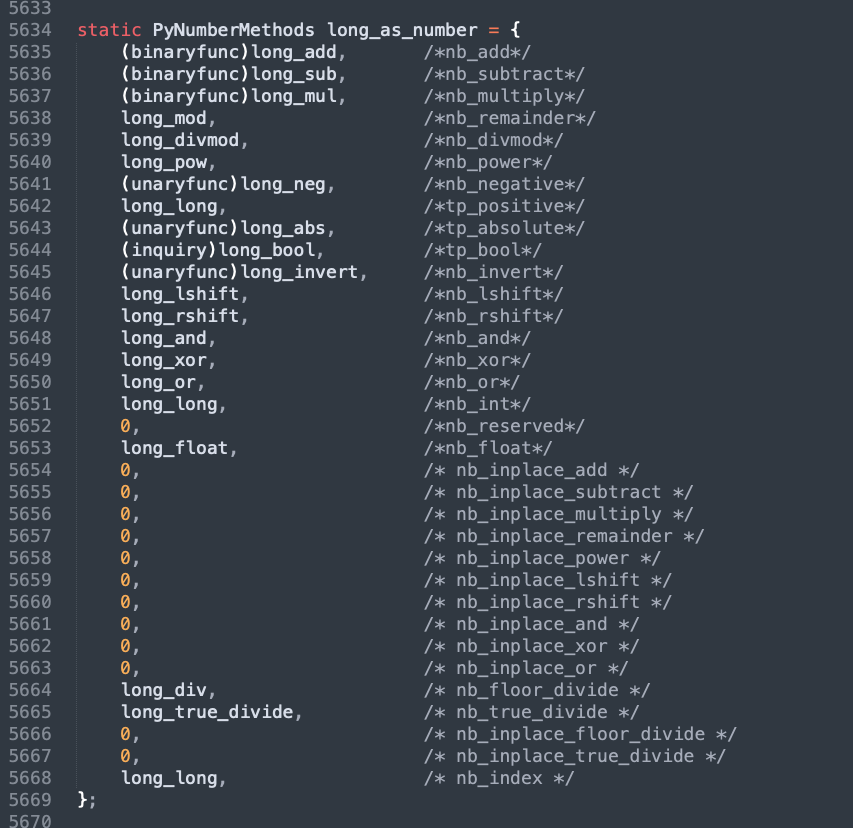
因此 PyNumberMethods 的成员就是整数所有拥有的魔法方法,当然也包括浮点数。
至此,整个结构就很清晰了。
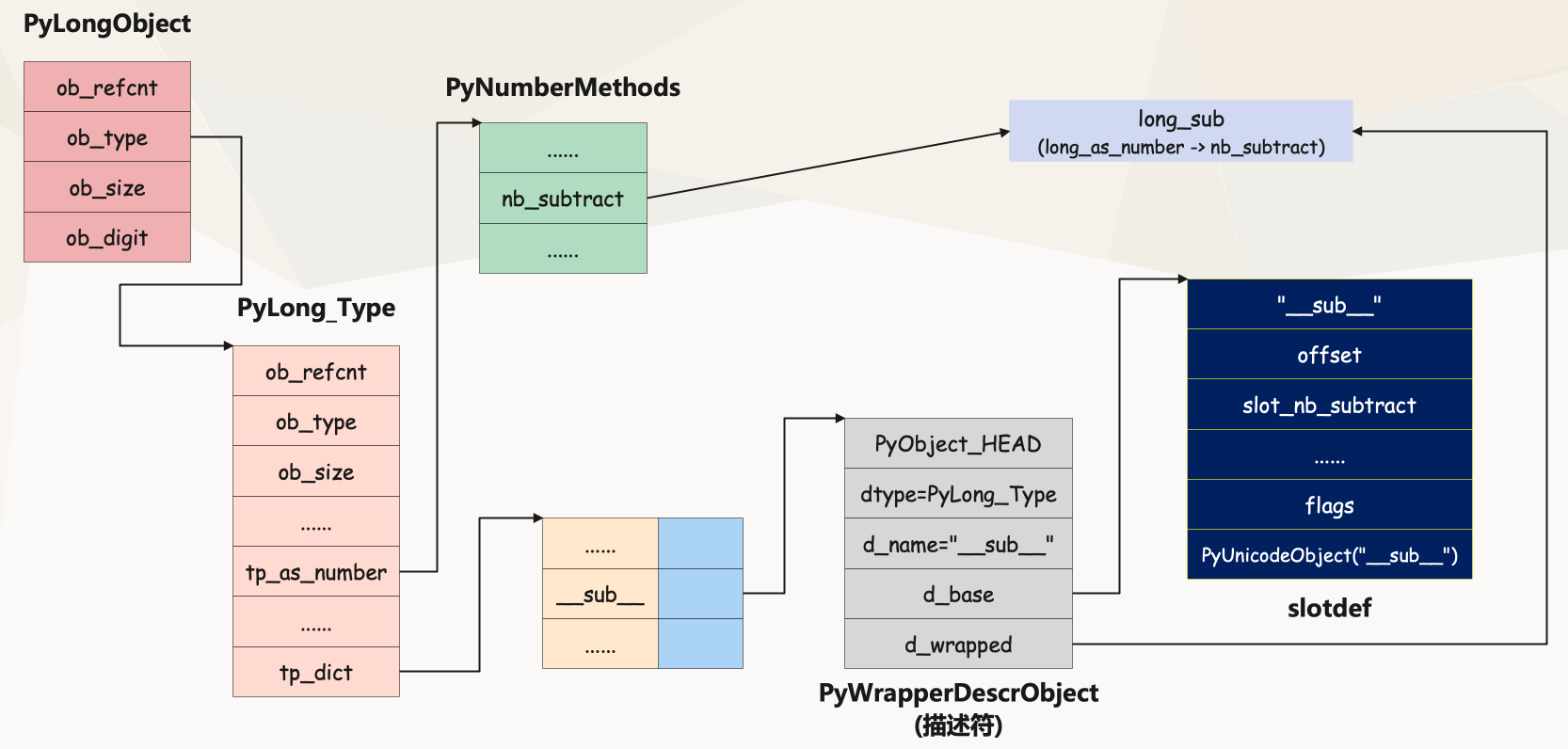
若想改变操作符的表现行为,我们需要修改的是 tp_as_* 里面的成员的值,而不是简单的修改属性字典。比如我们想修改 a + b 的表现行为,那么就将类对象的 tp_as_number 里面的 nb_add 给改掉。如果是整形,那么就覆盖掉 long_add,也就是 “PyLong_Type -> long_as_number -> nb_add”;同理,如果是浮点型,那么就覆盖掉 float_add,也就是 “PyFloat_Type -> float_as_number -> nb_add”。
重写操作符
我们说类对象里面有 4 个方法集,分别是 tp_as_number、tp_as_sequence、tp_as_mapping、tp_as_async,如果我们想改变操作符的表现结果,那么就重写里面对应的函数即可。
1 | from ctypes import * |
代码量还是稍微有点多的,但是不难理解,我们将这些代码放在一个单独的文件里面,文件名就叫 unsafe_magic.py,然后导入它。
1 | from unsafe_magic import patch_builtin_class |
你觉得之后会发生什么呢?我们测试一下:

怎么样,是不是很好玩呢?
1 | from unsafe_magic import patch_builtin_class |
因此 Python 给开发者赋予的权限是非常高的,你可以玩出很多意想不到的新花样。
另外再多说一句,当对象不支持某个操作符的时候,我们能够让它实现该操作符;但如果对象已经实现了某个操作符,那么其逻辑就改不了了,举个栗子:
1 | from unsafe_magic import patch_builtin_class |
不过上述这个问题在 3.6 版本的时候是没有的,操作符会无条件地执行我们重写的魔法方法。但在 3.8 的时候出现了这个现象,可以自己测试一下。
最后再来说一说 Python/C API,Python 解释器暴露了大量的 C 一级的 API 供我们调用,而调用方式可以通过 ctypes.pythonapi 来实现。我们之前用过一次,就是 pythonapi.PyType_Modified。那么再举个例子来感受一下:
1 | from ctypes import * |
ctypes.pythonapi 用的不是很多,像 Python 提供的 C 级 API 一般在编写扩展的时候有用。
小结
以上我们就用 ctypes 玩了一些骚操作,内容还是有点单调,当然你也可以玩的再嗨一些。但是无论如何,一定不要在生产上使用,线上不要出现这种会改变解释器运行逻辑的代码。如果只是为了调试、或者想从实践的层面更深入的了解虚拟机,那么没事可以玩一玩。