
35-Numba是如何解决Python的三大性能瓶颈的
35-Numba是如何解决Python的三大性能瓶颈的
为什么python这么慢
1、动态变量:
在c中我们编写一些功能性代码,需要严格定义变量的类型,比如进行加法计算,需要定义我们的数据是int、float还是其它类型,而python中则不需要,这是我在实践中发现影响python运行速度最大的因素之一,具体的原因在于:
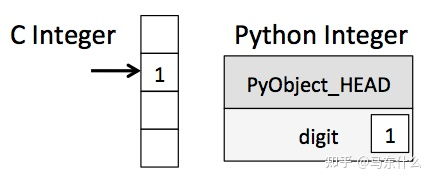
在python中,所有的变量都是对象,例如:
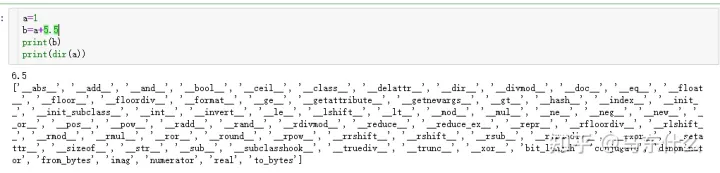
我们可以看到一个简单的a中,有这么多的methods。。。python的变量定义的便利性也给python的效率带来了很大的问题,
Python等动态类型语言之所以慢,就是因为每一个简单的操作都需要大量的指令才能完成。他们的虚拟机拥有很强的优化器,却是为静态语言设计的。对Python几乎没有效果。举一个例子。对于整数加法,C语言很简单,只要一个机器指令ADD就可以了,最多不过再加一些内存读写。但是,对于Python来说,a+b这样的简单二元运算,可就真的很麻烦了。Python是动态语言,变量只是对象的引用,变量a和b本身都没有类型,而它们的值有类型。所以,在相“加”之前,必须先判断类型。
2、大量重复的编译
前面提到过了,编译型语言,可以一次编译,下次使用直接运行,而python这种解释性语言,每次运行的时候都要重新将源代码通过解释器转化为机器码;
3、gil锁
在理解gil锁之前需要理解一下基本概念
GIL:Global Interpreter Lock又称全局解释器锁。简单来说是一个互斥锁,每个线程在执行的过程中都需要先获取GIL,作用就是限制多线程同时执行,使得在同一进程内任何时刻仅有一个线程在执行。
由于GIL的存在,在Python上开启多个线程时,每个单独线程都会在竞争到GIL后才运行,因此在我们的Python语言中多线程其实是假的多线程,它只会在一个CPU上运行。即使在具有多核CPU中,Python的多线程也是串行执行的,并不会同一时间多个线程分布在多个CPU上运行。
GIL的优缺点
优点:线程是非独立的,所以同一进程里线程是数据共享,当各个线程访问数据资源时会出现“竞争”状态,即数据可能会同时被多个线程占用,造成数据混乱,这就是线程的不安全。所以引进了互斥锁,确保某段关键代码、共享数据只能由一个线程从头到尾完整地执行。
缺点: 单个进程下,开启多个线程,无法实现并行,只能实现并发,牺牲执行效率。
由于GIL锁的限制,所以多线程不适合计算密集型任务,更适合IO密集型任务
常见IO密集型任务:网络IO(抓取网页数据)、磁盘操作(读写文件)、键盘输入
面试常见
描述Python GIL的概念, 以及它对Python多线程的影响?
编写一个多线程抓取网页的程序,并阐明多线程抓取程序是否可比单线程性能有提升,并解释原因。
参考答案:
GIL:全局解释器锁。每个线程在执行的过程都需要先获取GIL,保证同一时刻只有一个线程可以执行代码。
Python语言和GIL没有任何关系。仅仅是由于历史原因在Cpython虚拟机(解释器),难以移除GIL。
线程释放GIL锁的情况: 在IO操作等可能会引起阻塞的system call之前,可以暂时释放GIL,但在执行完毕后,必须重新获取GIL
Python使用多进程是可以利用多核的CPU资源的。
多线程爬取比单线程性能有提升,因为遇到IO阻塞会自动释放GIL锁。
numba是如何解决python的三大问题的
1、动态变量问题
使用过numba的用户应该知道,如果在jit装饰的时候,nopython设置为True,则numba几乎不会提速甚至反而会更慢一点,numba在nopython模式下不适用python 定义的动态变量,而是使用静态变量定义,因此有效的避免了python动态变量的一大堆复杂的检查,但是这也意味着nopython模型下,编程的灵活性变低,你额能无法像python环境中一样自由地进行字符的四则运算;
2、 编译问题
这里要写了解什么是jit 编译:
即时编译(英语:Just-in-time compilation),又译及时编译、实时编译[3],动态编译的一种形式,是一种提高程序运行效率的方法。通常,程序有两种运行方式:静态编译与动态编译。静态编译的程序在执行前全部被翻译为机器码,而动态编译执行的则是一句一句边运行边翻译。即时编译器则混合了这二者,一句一句编译源代码,但是会将翻译过的代码缓存起来以降低性能损耗。相对于静态编译代码,即时编译的代码可以处理延迟绑定并增强安全性。