
Squirrel Testing Database Management Systems withLanguage Validity and Coverage Feedback--对于DBMS的模糊测试技术介绍
Squirrel Testing Database Management Systems withLanguage Validity and Coverage Feedback——对于DBMS的模糊测试技术介绍
数据库管理系统(DataBase Management System)与其他的大型复杂系统一样,存在着许多漏洞。 其 中的内存错误漏洞往往可能导致远程代码执行、数据泄露、拒绝服务攻击等。 由于数据库管理系统的重要性,这些攻击的影响往往十分重大。 本文将基于 Squirrel [1] 这篇文章,来介绍对于 DBMS 的模糊测试技术。 简单来说,对于 DBMS 的模糊测试的目标是找到一些 SQL 语句,将其输入到 DBMS 后会触发 DBMS 的异常行为(一般是崩溃)。
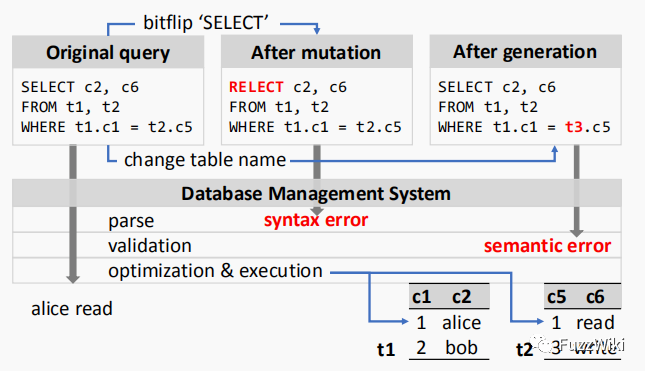
DBMS 在接收到一条 SQL 查询语句的时候,会依次进行词法分析、语法分析(上图中的 parse)、语义检查(validation)、语句优化和执行(optimization & execution)等流程。在词法分析阶段,DBMS 会识别 SQL 语句中的关键字、标识符等记号(token),然后在语法分析阶段则会识别这些记号的关联信息。如果这些关联信息不符合语法规则,DBMS 将立即终止本次查询并向客户端返回错误信息。例如上图,假设在 AFL 中的一次位翻转(bitflip)变异,将一个查询语句中的 “SELECT” 变异为 “RELECT”。在新的语句进行词法分析的时候,“RELECT” 将不会被识别为关键字(或是一个别的什么关键字)。在接下来的语法分析中,由于这个 “RELECT…FROM…WHERE” 的记号组合不在 DBMS 的语法规则中,因此通不过语法分析阶段。在语义检查阶段,DBMS 将验证语句的语义正确性,例如进行查询的表名、列名是否存在等。在上图中,假设在语句中变异出一个不存在的表 t3,则将通不过语义检查。在语义正确的情况下,DBMS 将构建多个查询计划并且选择最有效的一个来对当前的查询语句进行优化。最后 DBMS 会在数据库中执行选定的查询计划并将结果发送给客户端。因此,如果变异出来的 SQL 查询通不过语法分析和语义检查阶段,则输入进去的 SQL 语句将不会执行 DBMS 的优化和执行处的代码,对于程序的状态空间提升就极其有限。
目前主要有两种对于 DBMS 的模糊测试方法,基于生成(model-based generation)的方法与基于变异(random mutation)的方法。SQLSmith [2] 是目前使用较广的基于生成的 DBMS 模糊测试工具。它基于抽象语法树(Abstract Syntax Tree)来生成语法正确的查询语句。与其他的黑盒模糊测试工具一样,因为没有反馈信息,SQLSmith 会依次遍历 SQL 语句的输入空间。由于许多的 SQL 语句在 DBMS 中是由一套代码流程来处理,因此在探索程序状态空间上,这种方法是十分低效的。此外,这种方法也较难产生符合语义正确的输入。而基于变异的方法在近年来飞速发展,以 AFL 为代表的工具以代码覆盖率作为反馈,可以有效的探索程序的状态空间。但是 AFL 的变异策略对于结构化的输入效果并不好,很难变异出合法的 SQL 语句。文章中的实验显示,AFL 在 24 小时变异生成的两千万条 SQL 查询语句中,只有 30% 通过了语法检查,并且最终只有 4% 是语义正确的。

Squirrel 的工作就是将上述的两种方法的优势进行结合,即将基于 AST 的变异方法引入到具有反馈驱动的 AFL 中,并且提出了基于依赖图的查询实例化(instantiation)方法,尽可能的使变异出来的语句通过语义检查。总的来看,Squirrel 的每次执行都从一个空的数据库开始,一次输入一组 SQL 语句(通常会包含创建表、插入数据、查询等语句)。在变异前,Squirrel 会剥离这些 SQL 语句中语义信息(例如列名、表名、整型数值)。变异后,Squirrel 会经过一个被称为 “实例化” 的阶段,再来填充这些新的 SQL 语句中的语义信息。最后,输入到 DBMS 中执行,并监控执行结果,执行完毕后会清空数据库。

对于每组输入的 SQL 语句,Squirrel 会首先将其转换为 AST,然后将 AST 转换为文中所谓的中间表示(Intermediate Representation)。但本质上来说,这个 IR 就是二叉树形式的 AST。其中每个 IR 是这个二叉树上的一个节点,保存着这个节点的左子节点和右子节点,以及该节点的类型。由于 AST 中的节点可能有超过两个子节点,因此转化为二叉树后,需要创建一些 “虚空节点” 来进行连接,这些虚空节点的类型即为 Unknown。
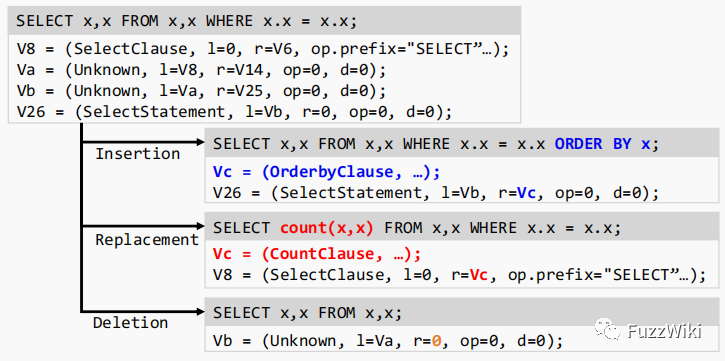
在变异阶段,所有 AFL 自带的变异策略均被舍弃。Squirrel 重新定义了三种变异操作,分别是插入、替换和删除。变异的对象是 IR,每次变异输入的这组 SQL 语句中的一个 IR。对于这个 IR 的左子节点和右子节点,分别有几率将其替换成一个同类型的节点或是删除(如果非空的话),或是插入一个同类型的节点(如果为空的话)。这些插入或替换进去的新的节点来自于一个被称为 IR library 的素材库。在刚开始进入模糊测试的准备阶段,Squirrel 会读取一些预定义的素材 SQL 语句,并将其转换成 IR 存到这个素材库中。
整体看下来,这个 IR 其实并不是类似于 LLVM 或是编译原理里面的那种 “中间表示”,本质上就是二叉树形式的 AST。但由于文章这么叫了,这里也继续沿用这个 IR 的称谓。至于为什么不直接对于 AST 进行操作,而是对于 IR 来进行变异。我个人认为可能是二叉树操作起来更简单一些,例如遍历二叉树就比遍历一颗不知道每个节点有几个子节点的树要来的方便一些。并且变异操作也可以写的比较简单直观,因为只需要对于确定的两个子节点进行变异即可。
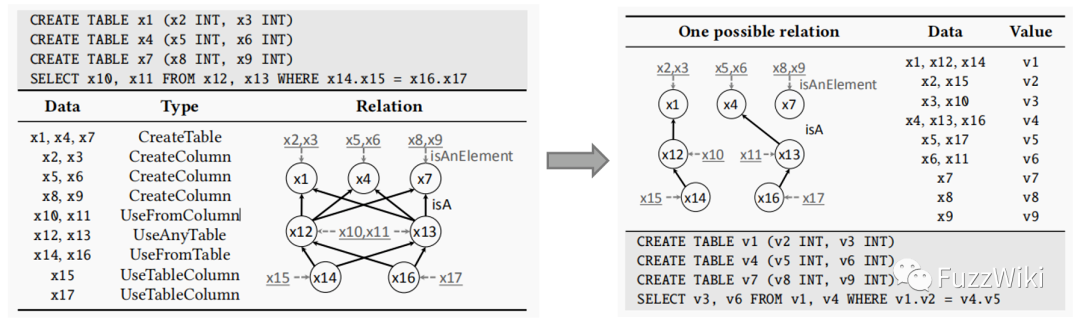
在变异过后,对于每组新的 SQL 语句,需要进行实例化,填充其中的语义信息。Squirrel 提出了一种基于依赖图的实例化算法。以上图左边的这组 SQL 语句为例,这里一共有两类依赖,一种是表名与表名之间的依赖,即某个表名是由另一个表名决定的;另一种是列名与表名之间的依赖,即某个列名是由一个表名决定的。例如 x14 这个表名就依赖于 x12 或 x13,而表名 x12 和 x13 又依赖于 x1、x4 或 x7。由于依赖图中的某个节点可能有多个依赖的目标,Squirrel 会随机为这个节点指定一个目标进行依赖,例如上图右边。在确定所有的依赖关系以后,我们就可以为那些不依赖于其他节点的节点(一般处在依赖图的末端)分配一个新的值,然后根据依赖关系依次填充值即可。当然这里面会充斥着一些细枝末节和奇技淫巧,例如依赖关系是在构建 AST 的时候根据一些人为规则指定的,依赖图在实现中并不是跨 SQL 语句的等等,这些内容本文就不展开讲解了。

实现上,Squirrel 使用了 Flex 和 Bison 实现了词法分析和语法分析的部分(将 SQL 语句转化为 AST),插桩反馈用的是 AFL 的基本框架,并在 AFL 中添加了基于 AST 的变异方法。多说一句,Squirrel 看起来是有很多代码,但实际上核心的变异和实例化算法可能也就 500 到 1000 行左右的代码,每个数据库的文法定义也就是大概是 3000 行左右的 Bison 代码。如果对于其基础实现感兴趣的同学可以放心阅读。
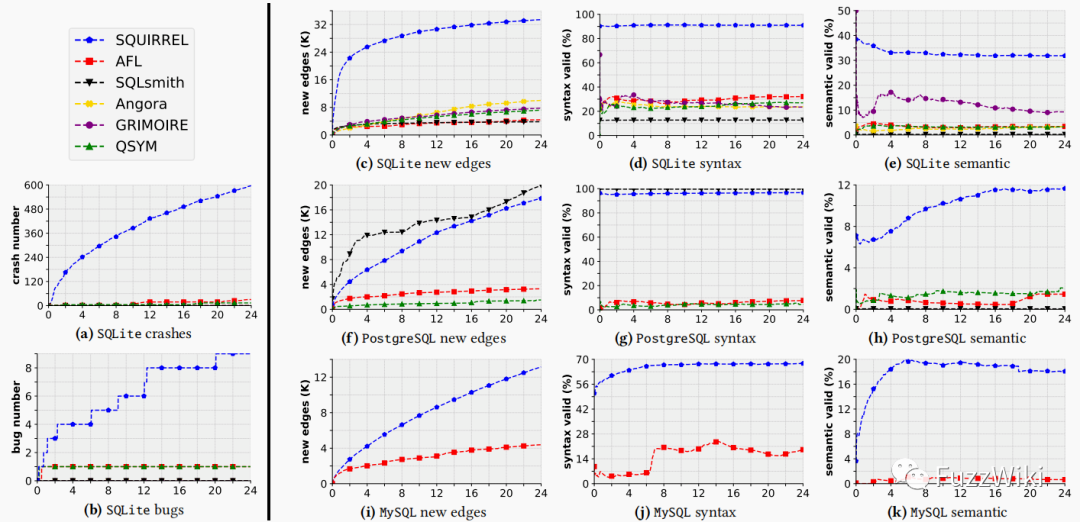
实验方面,Squirrel 对于几个时下流行的数据库用多个模糊测试工具进行了测试。可以看到,在语法正确和语义正确的百分比上,Squirrel 相较其他的工具都有绝对的优势。在 SQLite、MySQL 和 MariaDB 中分别找到了 51 个、7 个和 5 个漏洞。由于 AFL 插桩中的碰撞问题的限制,以及 Squirrel 对于 SQLite 的文法支撑较好等原因,Squirrel 仅在代码量较少的 SQLite 上挖掘出了较多的漏洞。未来如果希望使用 Squirrel 在 PG、MYSQL 等数据库中挖掘更多漏洞的话,需要解决一下碰撞问题,以及在文法上要支持这些数据库的语法 “方言”。
[1] Zhong,R., Chen, Y., Hu, H., Zhang, H., Lee, W., & Wu, D. (2020). SQUIRREL:Testing Database Management Systems with Language Validity and CoverageFeedback. In CCS 2020 - Proceedings of the 2020 ACM SIGSAC Conference onComputer and Communications Security (pp. 955-970). (Proceedings of the ACMConference on Computer and Communications Security). Association for ComputingMachinery. https://doi.org/10.1145/3372297.3417260
[2]SQLSmith. https://github.com/anse1/sqlsmith, 2016.
[3] copy from https://www.wangan.com/p/7fygf36463e85a21
test test test