Finding Bugs in Gremlin-Based Graph Database Systems via Randomized Differential Testing
Finding Bugs in Gremlin-Based Graph Database Systems via Randomized Differential Testing
Basic Information:
- Title: Finding Bugs in Gremlin-Based Graph Database Systems via Randomized Differential Testing (通过随机差异测试在基于Gremlin的图数据库系统中发现错误)
- Authors: Yingying Zheng, Wensheng Dou, Yicheng Wang, Zheng Qin, Lei Tang, Yu Gao, Dong Wang, Wei Wang, and Jun Wei
- Affiliation: State Key Lab of Computer Science at ISCAS, University of CAS, China (中国科学院计算技术研究所)
- Keywords: Graph database systems, differential testing, Gremlin
- URLs: Paper, [GitHub: None]
论文简要 :
- 本研究提出了Grand,一种用于自动发现采用Gremlin检索图数据的图数据库系统中逻辑错误的随机差异测试方法,并在六种广泛使用的图数据库系统中发现了21个先前未知的逻辑错误。
背景信息:
- 论文背景: 图数据库系统在许多应用中发挥着重要作用,但逻辑错误在这些系统中却受到较少关注。
- 过去方案: 与关系数据库系统不同,图数据库系统的逻辑错误难以自动检测,因为它们通常使用自己的查询语言,语法和查询模式与SQL完全不同。
- 论文的Motivation: 本研究的动机在于解决图数据库系统中逻辑错误难以自动检测的问题,通过提出Grand方法,利用随机差异测试发现逻辑错误,并在六种广泛使用的图数据库系统中取得了显著成果。
方法:
- a. 理论背景:
- Grand旨在通过比较多个基于Gremlin的图数据库系统(GDBs)上的Gremlin查询结果,自动发现逻辑错误。该方法包括基于模型的查询生成和数据映射方法,以创建有效的Gremlin查询并统一查询结果格式。
- b. 技术路线:
- 为多个GDBs构建语义等价数据库。
- 使用基于模型的查询生成方法生成有效的Gremlin查询。
- 使用数据映射方法统一不同GDBs的查询结果格式。
结果:
- a. 详细的实验设置:
- Grand在六个广泛使用的GDBs上进行了评估,检测到了21个先前未知的错误。
- b. 详细的实验结果:
- Grand总共发现了21个逻辑错误,其中18个已确认,7个已被开发人员修复。
ABSTRACT:
这篇文章介绍了一种名为Grand的方法,旨在自动发现采用Gremlin查询语言的图数据库系统(GDBs)中的逻辑错误。Grand的核心思想是为多个GDB构建语义等价的数据库,然后比较在这些数据库上执行相同Gremlin查询的结果。如果在多个GDB上的查询结果不一致,很可能是这些GDBs中存在逻辑错误。为了有效测试GDBs,文章提出了一种基于模型的查询生成方法来生成可能返回非空结果的有效Gremlin查询,以及一种数据映射方法来统一不同GDBs的查询结果格式。通过在六个广泛使用的GDBs(例如Neo4j和HugeGraph)上评估Grand,共发现了21个之前未知的逻辑错误。其中18个错误已被开发者确认,且已修复7个错误。这项工作强调了GDBs在正确操作中的重要性,并针对在复杂的图和查询中可能被开发者忽视的逻辑错误,提供了一种有效的自动发现方法。
INTRODUCTION:
背景:
图数据库系统(GDBs)基于标签属性图模型或资源描述框架(RDF)图模型构建,支持高效的图数据存储和查询,图数据由顶点和边组成。近年来,GDBs的普及度显著增加,在许多应用中发挥了重要作用,例如知识图谱、社交网络和欺诈检测等。一些最受欢迎的GDBs包括Neo4j、OrientDB、JanusGraph(从Titan扩展而来)、Nebula、HugeGraph、TinkerGraph、ArcadeDB等。这些系统的流行和应用强调了GDBs在处理复杂关系和网络分析中的关键作用。
Logical bugs in graph db and a Motivation Example:
在图数据库系统(GDBs)中,逻辑错误是指查询返回意外结果的情况,这种结果可能是错误的查询结果(例如,在图中遗漏一个顶点),或者是意外的错误,而不会导致GDBs崩溃。举一个例子,如果在HugeGraph中发现了一个逻辑错误的测试案例,首先创建一个带有顶点标签和属性的图模式,并在该属性上创建索引。然后,基于这个图模式,创建三个具有不同属性值的顶点并将它们添加到图中。当计算属性值在某个范围内的顶点数量时,应该返回满足条件的顶点数。然而,由于HugeGraph在执行OR操作时忘记了去重重叠值,因此返回了错误的结果。这说明逻辑错误可以导致查询结果不准确,例如返回额外的不应该出现的结果。

Related work:
- RAGS
- 使用差异测试来检测关系数据库系统中的错误。
- SQLancer
- 提供三种方法来发现逻辑错误:
- Pivoted Query Synthesis (PQS)
- 通过生成和执行查询来检测数据不一致性。
- Ternary Logic Partitioning (TLP)
- 利用三元逻辑分割来发现错误。
- Non-Optimizing Reference Engine Construction (NoREC)
- 通过构建非优化引擎来比较查询结果,以发现错误。
- Pivoted Query Synthesis (PQS)
- 提供三种方法来发现逻辑错误:
当前没有可用的工具能够直接应用于图数据库系统(GDBs)来检测逻辑错误,突显了在GDBs逻辑错误检测方面的研究和工具开发需求。
Challenges:
自动检测图数据库系统(GDBs)中的逻辑错误面临的挑战主要包括:
- 缺乏标准化查询方式:与关系数据库系统不同,图数据库没有统一的查询数据方式。大多数GDBs通常使用它们自己的查询语言,如Neo4j的Cypher和TigerGraph的GSQL。尽管大约66%的GDBs支持一个通用查询语言Gremlin,这为统一查询提供了一线希望,但语言的多样性仍旧是一个挑战。
- 与SQL语法和查询模式的巨大差异:例如,Gremlin是一种功能性语言,它通过一系列的遍历步骤来遍历图,这些步骤可以组合来表达复杂的查询。这种差异意味着不能直接将关系数据库系统的现有测试方法应用于GDBs。
- 不同的存储和查询结果格式:GDBs在顶点和边的查询结果上可能因为不同的ID生成策略而有所不同。自动构建有效的图查询及其对应的预言机(oracles)以适应不同GDBs的这一需求构成了一个关键挑战。
Approach:
本文提出了一种名为Grand的随机差异测试方法,用于自动发现采用Gremlin查询语言检索图数据的图数据库系统(GDBs)中的逻辑错误。具体来说,通过生成随机Gremlin查询,该方法寻找不同Gremlin-based GDBs返回结果之间的差异,并将这些差异识别为潜在的逻辑错误。为了有效地在基于Gremlin的GDBs中发现逻辑错误,本方法解决了两个特定的挑战:
- 生成语法正确且有效的Gremlin查询:采用基于模型的查询生成方法,总结Gremlin遍历API到不同的遍历类型,然后提出一个Gremlin遍历模型,表达不同遍历API之间的转换,以生成正确和有效的Gremlin查询。这样做可以高概率地返回非空的查询结果。
- 获取不同GDBs中格式统一的查询结果:利用数据映射方法,在不同GDBs中获取统一的查询结果。这使得该方法能够比较不同GDBs返回的不同格式的查询结果。
总体而言,Grand通过这两个策略有效地发现了基于Gremlin的GDBs中的逻辑错误,提高了在复杂图数据库环境中自动化测试的能力。
Evaluation and contributions:
本文提出了Grand,这是一种自动化的差异测试方法,专门用于检测基于Gremlin的图数据库系统(GDBs)中的逻辑错误。Grand通过随机生成Gremlin查询来探索不同GDBs返回结果之间的差异,以此识别潜在的逻辑错误。为了评估Grand的有效性,作者将其应用于六个广泛使用的GDBs:Neo4j、OrientDB、JanusGraph、HugeGraph、TinkerGraph和ArcadeDB。实验结果显示,Grand在检测GDBs中的逻辑错误方面非常有效,到目前为止已经检测到21个之前未知的逻辑错误,其中18个已被确认,7个已被修复。
本文的贡献包括:
- 提出了Grand,一个自动化的差异测试方法,用于发现Gremlin-based GDBs中的逻辑错误,并引入了基于模型的查询生成方法来有效生成语法正确且有效的Gremlin查询。
- 在六个广泛使用的GDBs上实施并评估Grand,发现了21个先前未知的错误。
PRELIMINARIES
2.1 Graph Models in Graph Database Systems
图数据库系统(GDBs)采用图数据结构来存储和查询数据,主要使用两种图模型:标签属性图模型和资源描述框架(RDF)图模型。
标签属性图模型通过顶点、边、标签(顶点或边的分组)和属性(特性)来描述实体间的关系。每个顶点或边都关联有一组属性,并可以通过其标签划分为不同的组。边在这个模型中是有方向的,用来表示顶点之间的关系,例如表示人与书之间的“写”和“读”关系。
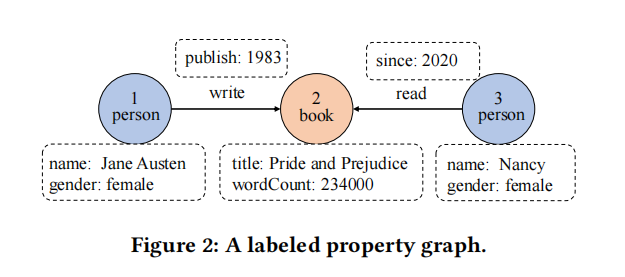
RDF图模型是一种W3C标准,使用三元组(主体、宾语和谓词)来表示网络中的资源。与标签属性图模型不同,RDF模型中的顶点和边具有相同的角色,三元组结构中的主体可以是顶点或边,宾语可以是另一个顶点、边或文字值,谓词描述它们之间的关系。
这两种图模型以不同的方式描述连接的数据,并可以根据它们各自的优势在不同的应用中使用。例如,在知识图谱中广泛使用RDF模型,因为它具有高度结构化的信息。然而,在图数据库系统中,标签属性图模型更受欢迎。几乎所有GDBs都支持标签属性图模型(如Neo4j、JanusGraph和TigerGraph),而支持RDF图模型的GDBs不到一半(如Virtuoso)。因此,本研究聚焦于标签属性图模型。
01
属性图(Property Graphs)
虽然属性图的实现中有一些核心的共性,但是没有真正标准的属性图数据模型,因此属性图的每个实现都有些不同。在下面,我们将重点讨论任何属性图数据库都常见的特征。
- 节点(Nodes):是图中的实体,用表示其类型的0到多个文本标签进行标记,相当于实体。
- 边(Edges):是节点之间的定向链接,也称为关系。其中对应的“from node”称为源节点,“to node”称为目标节点。边是定向的且每条边都有一个类型,它们可以在任何方向上导航和查询。相当于实体之间的关系。
- 属性(Properties):是一个键值对,顶点和边都具有属性。
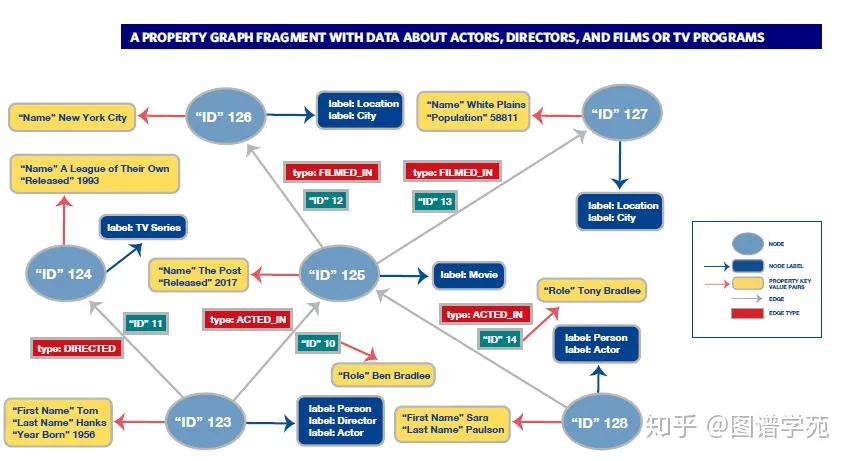
图1显示了一个属性图的部分,其中包含有关演员、导演和他们参与的电影或电视节目的数据。其中节点用椭圆表示。例如,ID为123的节点(从其属性中看出)表示Tom Hanks。节点标签以深蓝色显示。节点123的标签是人物、演员和导演。关系用灰色箭头表示,从一个节点指向另一个节点,每个关系都有一个红色显示的类型。属性显示在带有金色的圆角矩形中,并使用红色箭头连接到它们所属的节点和关系。
02
资源描述框架图(RDF Graphs)
RDF图使用标准的图数据模型,其技术栈的标准是由万维网联盟(W3C)管理的,这个组织也同时管理HTML、XML和许多其他网络标准。因此每个支持RDF的数据库都应该以同样的方式支持该模型。除此之外,RDF有一个标准的查询语言称为SPARQL。它既是一种功能齐全的查询语言,又是一种HTTP协议,可以通过HTTP将查询请求发送到端点。RDF图数据模型主要是由以下两个部分组成的:
- 节点(Nodes):对应图中的顶点,可以是具有唯一标识符的资源,也可以是字符串、整数等有值的内容。
- 边(Edges):是节点之间的定向链接,也称为谓词或属性。边的入节点称为主语,出节点称为宾语,由一条边连接的两个节点形成一个主语-谓词-宾语的陈述,也称为三元组。边是定向的,它们可以在任何方向上导航和查询。
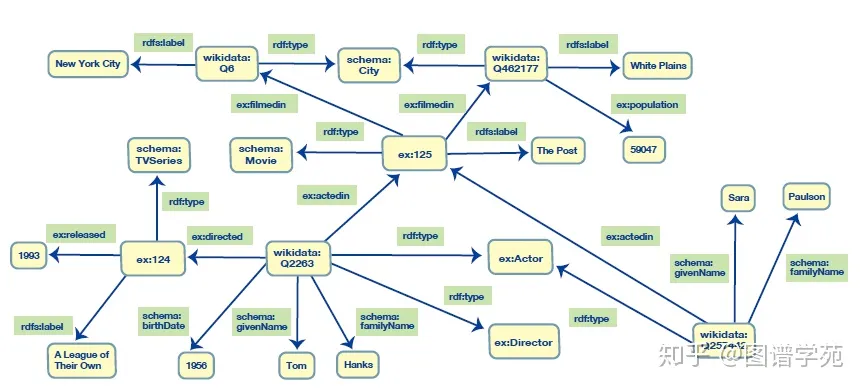
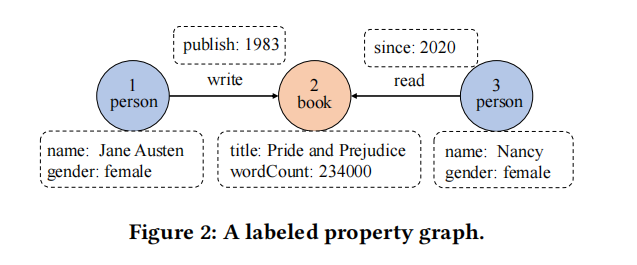
RDF的英文全称为Resource Description Framework,因为在RDF图中,一切都称为源。边和节点只是给定语句中资源所扮演的角色。基本上在RDF中,扮演边角色的资源和扮演节点角色的资源没有区别,因此一条语句中的边也可以是另一条语句中的节点。RDF数据模型相较于属性图更加丰富,也在语义上保持一致性。图2展示了如何将上面的图1由属性图表示为RDF:
图2中的图看起来比图1中的属性图大,因为图中的所有文字都被描述为节点。而在可视化RDF图数据时,通常不会这样做,以便使图看起来更干净和更简单。所有节点都用带有浅黄色背景的圆角矩形表示。也就是说,从数据结构的角度来看,它们是图形的一部分,就像任何其他节点一样,唯一的区别是它们不能作为源节点,只能是目标节点或宾语。RDF图中的文字值可以有数据类型,数据类型取自XML模式(如xsd:string、xsd:integer等),文本值也可以有语言标记来支持数据国际化。例如,对于纽约市的rdfs:label,我们可以有多个值,例如:“New York City” xsd:string @en 或 “NuevaYork” xsd:string @sp。标识符也是RDF图的一个非常重要的概念。每个非文字节点都被分配一个标识符——通常是一个URI(Uniform Resource Identifier,统一资源标识符)或IRI(Internationalized Resource Identifiers,国际化资源标识符)。本地非URI标识符因为不能互操作而很少使用。而全局唯一标识符为图数据模型带来了许多好处,同时基于RDFbased的解决方案可以根据选定的URI构造规则自动生成URI。另外,在添加数据(例如加载序列化的文件)时,用户也可以提供他们想要使用的URI。标识节点的URI使用限定名(通常称为Qname表示法)显示在图中,如图2中的 rdf 就表示着:http://w3.org/1999/02/22-rdf-syntax-ns#,而对应的也可以使用命名空间中的内置资源定义的语义,如rdf:type. 而使用URI最大的好处之一便是可以如果不同的节点具有同样的URI,就会自动地合并,这也就使得RDF图更加简洁清晰。
reference from : https://zhuanlan.zhihu.com/p/260430189
2.2 Graph Query Languages
图数据库系统(GDBs)与使用SQL作为标准查询方式的关系数据库系统不同,没有统一的标准方法来查询标签属性图。为了高效且方便地访问标签属性图中的数据,开发了一些图查询语言。根据它们的设计原则,这些查询语言可以分为两大类:
SQL-like图查询语言:为不同的GDBs开发了不同的SQL-like图查询语言,这些语言关注于各自GDBs的特定需求。例如:
- Cypher是为Neo4j设计的,使用MATCH、WHERE和RETURN作为其查询语法。
- Nebula使用nGQL进行查询。
- TigerGraph提出了GSQL,使用SELECT、FROM和WHERE来获取数据。
这些SQL-like声明式查询语言通常为特定GDBs实现,不能被其他GDBs支持。
函数式图查询语言:Gremlin是一个函数式、数据流查询语言,用于遍历标签属性图,使用户能够通过组合一系列Gremlin步骤(即Gremlin API调用)来表达复杂的遍历。Gremlin由Apache TinkerPop框架引入,已在大多数流行的GDBs中被广泛使用,例如Neo4j、JanusGraph、TinkerGraph和HugeGraph。
Gremlin不仅提供查询API,还提供了一组更新API来构建图数据库,例如添加顶点(addV())、添加边(addE())和移除元素或属性(drop())。
SQL-like声明式图查询语言通常为特定GDBs设计,而Gremlin查询语言在大多数流行的GDBs中得到了广泛使用。在Graph DBMSs的DB-Engine排名中,66%的GDBs支持Gremlin API。因此,本文主要关注Gremlin查询语言及使用Gremlin检索图数据的GDBs(也称为基于Gremlin的GDBs),并将在文中讨论如何将Grand扩展到其他图查询语言。
APPROACH
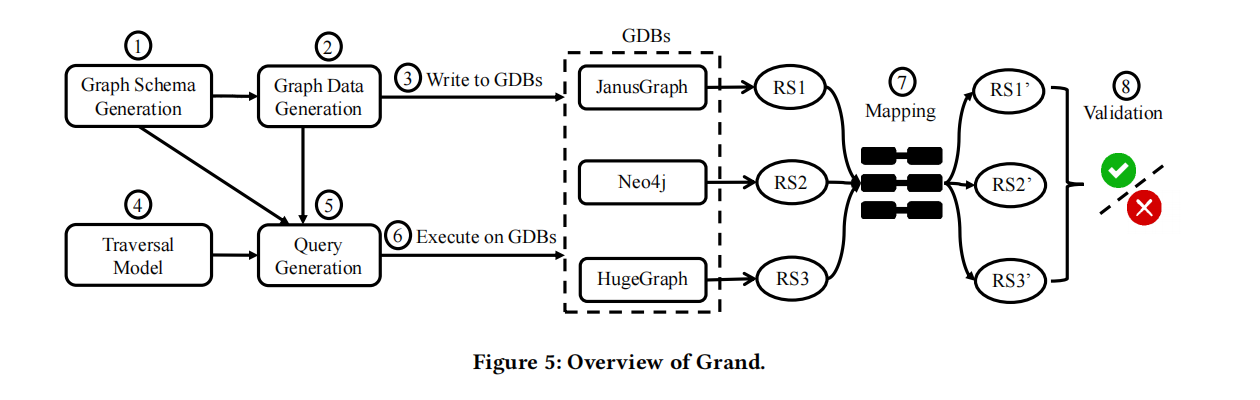
Overview
Grand是一个提出的随机差异测试方法,用于自动发现基于Gremlin的图数据库系统(GDBs)中的逻辑错误。Grand的过程包括三个主要阶段:
- 图数据库生成:Grand首先随机生成图模式,定义顶点和边的类型、标签和属性(步骤1)。接着,根据生成的图模式随机生成详细的顶点和边(步骤2)。然后,生成的数据库将被写入目标GDBs(步骤3)。
- Gremlin查询生成:使用基于模型的查询生成方法来生成语法正确且有效的Gremlin查询。具体来说,首先为Gremlin API构建一个遍历模型(步骤4),然后基于构建的遍历模型和生成的图数据库生成Gremlin查询(步骤5)。
- GDBs的差异测试:执行生成的Gremlin查询(步骤6),通过差异测试验证查询结果。具体而言,对于每个目标GDB,记录每个查询的结果,并借助映射信息将其转换为统一的查询结果(步骤7)。然后,Grand检查这些统一结果以识别是否存在差异(步骤8)。如果某些GDBs显示不同的输出,则发现潜在的错误。
Grand通过这三个阶段的综合应用,有效地自动化检测基于Gremlin的图数据库系统中的逻辑错误,提高了在复杂图数据库环境中自动化测试的能力和准确性。
3.1 Graph Database Generation
在图数据库生成阶段,Grand采用了以下步骤来为目标GDBs随机生成数据库状态,包括图模式和图数据,用于构建Gremlin查询:
图模式生成:
- 顶点类型:定义为一对标签名和一组属性类型,每个顶点包含一个标签和一组属性。
- 边类型:定义为一个输入顶点类型、一个输出顶点类型、一个标签名和一组属性类型,每条边包含一个输入顶点、一个输出顶点、一个标签和一组属性。
- 属性:每个属性包含一个属性名和其数据类型。数据类型可以是Integer、String、Double、Boolean、Float和Long等。
通过算法随机生成顶点类型和边类型的集合,确保每种类型具有唯一的标签名,并且同一类型内的所有属性具有不同的属性名。不同的顶点类型可以包含相同的属性类型。
图数据生成:
- 根据生成的图模式,Grand随机生成符合图模式的顶点和边,并将这些生成的顶点和边写入GDBs。
- 顶点生成过程中,随机选择一个顶点类型并生成一个顶点,随机选择该顶点类型的一部分属性类型并为其生成属性值。
- 边生成过程中,随机选择一个边类型并生成一条边,为边生成属性值,并随机选择符合边类型要求的输入/输出顶点。
Grand允许GDB测试者指定图数据库中顶点类型、边类型、属性类型、顶点和边的最大数量。在实验中,最多生成10种顶点类型、20种边类型、20种属性类型、100个顶点和200条边,以构建图数据库。
3.2 Model-Based Query Generation
文章通过构建一个遍历模型来生成语法正确且有意义的Gremlin查询。这个遍历模型精确地理解了Gremlin API及其语义,使得Grand能够正确地链接Gremlin API,并生成语法正确且具有实际意义的查询。具体方法包括以下几个步骤:
- 遍历模型的构建:首先定义了一个遍历模型,它包括三种类型的实体(顶点、边、值)、三种类型的操作(过滤、谓词、聚合)以及常量。这个模型代表了Gremlin API之间合法转换的规则,确保了查询的语法正确性和逻辑连贯性。

- 理解Gremlin API及其语义:通过深入研究Gremlin API,遍历模型精确地捕捉了API之间的转换规则和参数的语义。例如,API的输入输出类型必须匹配,这样的规则被编码在模型中,确保了生成的查询不仅语法正确,而且逻辑上有意义。
- 查询语句的构建:遵循遍历模型的指导,Grand迭代地、步骤化地生成查询语句。它从图的遍历源
g开始,随机选择下一个符合模型规则的Gremlin步骤,直到达到最大查询长度或满足退出条件。这种方法确保了每一步的选择都是基于对前一步骤输出类型的理解,从而生成连贯且有意义的查询序列。 - 参数值的生成:为了确保查询返回非空结果并具有探测潜在错误的能力,Grand在生成Gremlin API的参数值时,采取了基于图数据库内容选择值以及使用随机函数生成参数值的策略。这样既增加了查询返回有意义结果的概率,也避免了生成大量无效查询。
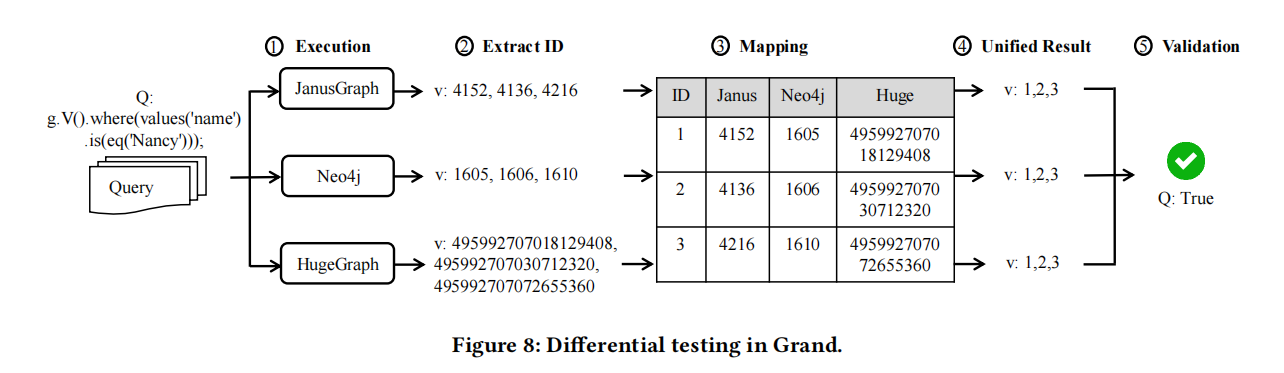
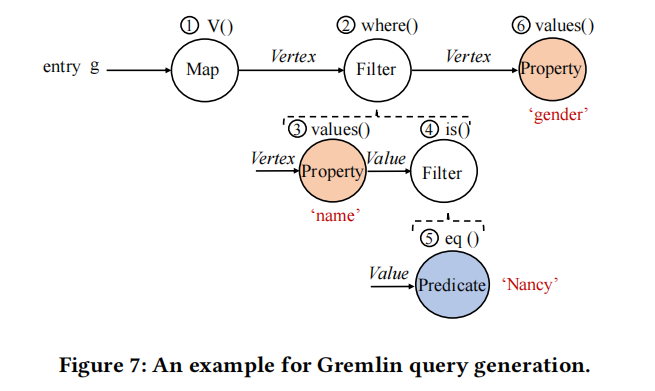
以下是一个Gremlin查询生成的例子,以查询 g.V().where(values('name').is(eq('Nancy'))).values('gender') 为例,对应于图2。如图7所示,通过算法2随机生成了三个遍历步骤,例如一个Map步骤(V() 在步骤1),一个Filter步骤(where() 在步骤2),和一个Property步骤(values() 在步骤6)。特别地,Filter步骤包含了一个嵌套子查询,这个子查询由一个Property API(values() 在步骤3)和一个Filter API(is() 在步骤4)组成。由于Map步骤(步骤1)的输出是Vertex,因此在Filter步骤(步骤2)的嵌套子查询中的属性名(即name)是从生成的顶点属性中随机选择的,或者使用我们的随机函数随机创建的。此外,Predicate API(eq() 在步骤5)的属性值和Property API(values() 在步骤6)的属性名可以以相同的方式生成。
3.3 Differential Testing for GDBs
文章通过差异测试来检测图数据库系统(GDBs)中的逻辑错误。具体步骤包括:
- 数据写入:首先将相同的图数据写入一组目标GDBs中。
- 执行查询:然后在这些GDBs上执行相同的Gremlin查询。
- 比较结果:通过比较不同GDBs返回的查询结果,来识别潜在的逻辑错误。如果返回结果在不同的GDBs之间存在差异,则将这种差异视为这些GDBs中的潜在错误。
- 结果格式的统一:返回结果可能是值、顶点列表、边列表或属性列表。当查询结果为顶点或边的列表时,不同GDBs可能会因为使用不同的ID生成策略而返回不同格式的结果。为了使比较成为可能,需要将它们转换为统一格式。
- 映射表的使用:通过生成每个顶点和边的唯一ID(𝑢𝐼𝐷)并在写入目标GDB后检索其实际ID(𝑎𝑐𝑡𝑢𝑎𝑙𝐼𝐷),使用映射表记录𝑢𝐼𝐷和𝑎𝑐𝑡𝑢𝑎𝑙𝐼𝐷之间的映射关系,从而便于将不同GDBs返回的顶点或边列表转换为统一格式。
- 差异测试的五个步骤:对于生成的Gremlin查询,首先在目标GDBs中执行它并获取查询结果;然后,对于每个GDB,提取查询结果中每个顶点或边的ID以获得实际的顶点ID或边ID列表;接着,根据映射表将实际查询结果转换为统一查询结果;最后,检查目标GDBs的统一查询结果是否相同。如果所有结果都相同,则返回真值(True),表示没有发现潜在错误;否则,返回假值(False),表示存在潜在错误。