
No More Manual Tests Evaluating and Improving ChatGPT for Unit Test Generation
No More Manual Tests? Evaluating and Improving ChatGPT for Unit Test Generation
ABSTRACT
摘要—单元测试在检测功能独立的程序单元(例如,方法)中的错误中发挥着重要作用。手工编写高质量的单元测试既耗时又劳累。尽管传统技术能够生成覆盖率合理的测试,但它们显示出低可读性,实际上还不能被开发者直接采用。最近的研究显示,大型语言模型(LLMs)在单元测试生成中具有很大潜力。通过预训练在大量开发者编写的代码库上,这些模型能够生成更加人性化和有意义的测试代码。ChatGPT,作为最新的LLM,进一步融合了指令调优和强化学习,已在各种领域表现出卓越的性能。迄今为止,ChatGPT在单元测试生成中的有效性仍不明确。
在这项工作中,我们进行了第一次实证研究来评估ChatGPT生成单元测试的能力。特别是,我们进行了量化分析和用户研究,系统地调查了其生成测试的质量,包括正确性、充分性、可读性和可用性。我们发现ChatGPT生成的测试仍存在正确性问题,包括各种编译错误和执行失败(主要由不正确的断言引起);但是,通过ChatGPT生成的通过测试几乎与手工编写的测试相似,实现了可比的覆盖率、可读性,甚至有时候开发者的偏好。我们的发现表明,如果能进一步提高其生成测试的正确性,使用ChatGPT生成单元测试可能非常有前途。
受我们上述发现的启发,我们进一步提出了一种新的基于ChatGPT的单元测试生成方法CHATTESTER,该方法利用ChatGPT本身来提高其生成测试的质量。CHATTESTER包括一个初始测试生成器和一个迭代测试优化器。我们的评估显示,CHATTESTER通过生成的编译测试比默认的ChatGPT多出34.3%,正确断言的测试多出18.7%。
索引术语—单元测试生成,ChatGPT
INTRODUCTION
Background and related work:
这段文本讨论了软件开发中单元测试的重要性和机制,以及现有自动化测试生成方法的局限性。以下是概要:
单元测试的重要性:
- 单元测试验证功能独立的程序单元(如方法)的正确性,确保它们的行为符合预期。
- 它是软件开发流程中的一个关键部分,对于早期检测和诊断错误起着关键作用,从而防止错误在开发周期中的进一步传播。
单元测试的机制:
- 一个方法的单元测试包括测试前缀(一系列方法调用或赋值语句,使方法达到可测试状态)和测试预言(指定期望的行为并检查方法的实际行为)。
- 断言通常用作测试预言。
手动单元测试的挑战:
- 手动编写和维护高质量的单元测试既耗时又劳累。
自动化单元测试生成的传统方法(Fuzzing):
开发了各种技术,如基于搜索的 [7,8,9]、基于约束 [10,11,12] 的和基于随机的策略 [13,14],以自动化单元测试的生成,目的是最大化覆盖范围。
Reference from https://blog.csdn.net/qq_67479387/article/details/136856795
Search-based approach:更高效的方法是 Greybox Fuzz Testing。Greybox Fuzz Testing 的核心思想是,现实世界中,程序的输入数据大部分是存在某种特定语义的,基于一组有效语义的 seed 数据以及各种 Fuzzing Strategy 所生成的测试数据,更容易覆盖更多有效的代码路径。例如我们在为一个图片浏览器程序生成数据时,如果是纯粹随机的数据,那么大部分的测试数据都是无效的,会因文件不符合某种格式而走入相同的代码路径。这显然极其低效。而基于有效的图片文件进行比特翻转,或文件大小调整,则更容易避免这种情况,从而尽可能高效的生成有效测试数据。
LLVM 社区的 LibFuzzer 和 AFL 具有类似的思想。Google 的 ClusterFuzz 就是基于 LibFuzzer 的。和 Monkey Testing 相比,Greybox Fuzz Testing 生成有效测试数据的效果提升非常明显,并且在具体应用过程中也有着非常好的效果。然而尽管如此,从本质上讲,Greybox Fuzz Testing 还是一种基于暴力的方式,他不保证能够准确的覆盖到全部代码路径。
Constraint-based approach:基于约束的测试生成方法依赖于从程序中提取约束(如条件表达式)并求解这些约束来生成测试输入,这些输入能够满足特定的测试目标,如执行特定的代码路径。通过符号执行(Symbolic Execution)技术,分析所有分支路径的符号约束(Symbolic Constrains),来指导如何生成新的测试数据(Guided Test Generation),以保证每一个代码路径尽可能的只执行一次,这样就可以大大的提高分支覆盖的效率,避免生成的测试数据重复的走入同一个代码路径。这种方式也被称作为 Whitebox Fuzz Testing。符号执行 (Symbolic Execution)是一种程序分析技术。其可以通过分析程序来得到让特定代码区域执行的输入。
Whitebox Fuzz Testing 虽然非常高效,但实际上 Symbolic Execution 技术非常复杂,也存在一定的限制,同时 Constrains Solving 也非常耗时。所以在实际应用场景中,Whitebox Fuzz Testing 通常与 Greybox Fuzz Testing 结合使用。Greybox Fuzz Testing 执行速度非常快,通过先运行 Greybox Fuzz Testing,完成初次的路径覆盖。对于无法达到的路径,通过 Symbolic Execution 的方式找到 Symbolic Constains,然后指导生成特定的测试数据,用于进入更深层次的代码路径。然后,再继续使用 Greybox Fuzz Testing 进行覆盖,如此循环迭代。
Random-based approach:基于随机的测试生成方法随机产生输入数据,以尝试覆盖尽可能多的代码路径。这种方法不需要复杂的分析,实现简单,但可能效率不高,需要较多的测试用例来达到较高的覆盖率。
- 【7】Harman, M., & McMinn, P. (2009). A theoretical and empirical study of search-based testing: Local, global, and hybrid search. IEEE Transactions on Software Engineering, 36(2), 226-247.
- 【8】Blasi, A., Gorla, A., Ernst, M. D., & Pezzè, M. (2022). Call me maybe: Using NLP to automatically generate unit test cases respecting temporal constraints. In 37th IEEE/ACM International Conference on Automated Software Engineering (pp. 1-11).
- 【9】Delgado-Pérez, P., Ramírez, A., Valle-Gómez, K. J., Medina-Bulo, I., & Romero, J. R. (2022). Interevo-TR: Interactive evolutionary test generation with readability assessment. IEEE Transactions on Software Engineering.
- 【10】Ernst, M. D., Perkins, J. H., Guo, P. J., McCamant, S., Pacheco, C., Tschantz, M. S., & Xiao, C. (2007). The Daikon system for dynamic detection of likely invariants. Science of Computer Programming, 69(1-3), 35-45.
- 【11】Csallner, C., Tillmann, N., & Smaragdakis, Y. (2008). DySy: Dynamic symbolic execution for invariant inference. In Proceedings of the 30th International Conference on Software Engineering (pp. 281-290).
- 【12】Xiao, X., Li, S., Xie, T., & Tillmann, N. (2013). Characteristic studies of loop problems for structural test generation via symbolic execution. In 2013 28th IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, pp. 246-256.
- 【13】Zeller, A., Gopinath, R., Böhme, M., Fraser, G., & Holler, C. (2019). The Fuzzing Book.
- 【14】Pacheco, C., Lahiri, S. K., Ernst, M. D., & Ball, T. (2007). Feedback-directed random test generation. In Proceedings of the 29th International Conference on Software Engineering (ICSE’07) (pp. 75-84). IEEE.
虽然这些自动化测试实现了合理的覆盖率,但与手工编写的测试相比,它们在可读性和意义性方面往往存在差距。
这种质量的不足导致开发者大多不愿在实践中直接采用这些自动生成的测试。
总的来说,虽然存在自动化单元测试生成方法,并且在覆盖范围方面有效,但由于可读性和意义性的问题,这些方法仍无法替代手动测试,影响了开发者的采纳率。
什么是test prefix 和 test oracle?
我们来用一个简单的Java例子来说明单元测试中的测试前缀(test prefix)和测试预言(test oracle)的含义。假设我们有一个名为
Calculator的类,其中有一个方法add用于添加两个整数。以下是如何使用JUnit(一个流行的Java测试框架)为这个方法编写单元测试的示例:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
public int add(int a, int b) {
return a + b;
}
}
public class CalculatorTest {
public void testAdd() {
// 测试前缀
Calculator calculator = new Calculator();
int x = 5;
int y = 3;
// 测试预言
assertEquals(8, calculator.add(x, y));
}
}
- 测试前缀:这部分测试设置了执行测试所需的环境。它包括:
- 实例化被测试类的对象(
Calculator calculator = new Calculator();)。- 设置测试所需的输入或状态(
int x = 5; int y = 3;)。这些行准备了Calculator对象和输入,使得add方法可以被有效地测试。- 测试预言:这部分单元测试检查方法是否按预期行为。它包括:
assertEquals语句(assertEquals(8, calculator.add(x, y));),这是一个断言。这行代码检查add方法的输出是否等于预期值(在这个例子中是8),当输入是5和3时。断言作为预言,验证方法的当前行为是否符合预期行为。总结来说,测试前缀通过设置必要的条件和状态来准备测试,而测试预言则实际进行验证,查看方法是否如预期那样工作。
LLM based unit test generation:
这段文本讨论了最近利用高级深度学习技术,尤其是大型语言模型(LLMs),来生成单元测试的研究进展。以下是对这段内容的概括:
- 技术背景:最近的研究采用了深度学习技术,特别是大型语言模型(LLMs),以改进单元测试生成。
- 问题转换:这些技术通常将单元测试生成视为一个神经机器翻译问题,即将给定的焦点方法翻译成相应的测试前缀和测试断言。
- 模型训练方法:通过在测试生成任务上微调预训练的模型,整合了LLMs的强大功能。这些模型首先在庞大的开发者编写的代码库上进行广泛的预训练,然后针对测试生成任务进行特定的微调。
- 潜在优势:由于这种训练方法,这些模型能够生成更接近人类编写的、有意义的测试代码,显示出LLMs在单元测试生成中的巨大潜力。
总的来说,通过将单元测试生成视为一种翻译任务,并利用预训练后微调的大型语言模型,这些研究表明了使用深度学习技术在单元测试自动生成方面的先进性和潜力。
ChatGPT and motivation:
ChatGPT是由OpenAI开发的,基于生成预训练变换器架构(GPT)的最新大型语言模型,已在多种任务中显示出卓越的能力。与现有基于学习的测试生成技术中使用的其他LLMs(如BART、BERT和T5)不同,ChatGPT进一步整合了人类反馈的强化学习(RLHF)和更大的模型规模。这些特点使得ChatGPT在不同领域表现出更好的泛化能力和更高的与人类意图的一致性。尽管ChatGPT展示了诸多优势,其在单元测试生成方面的实际效果仍不清楚,需要进一步的评估和研究。
Empirical Study and results:
本文进行了第一次实证研究,以评估ChatGPT在单元测试生成方面的能力。以下是研究的概括以及所采用的方法:
实证研究设计:
- 数据集构建:研究团队构建了一个包含1000个Java焦点方法的数据集,每个方法都配有完整且可执行的项目环境。
- 基本提示设计:基于以往测试生成工作的常见做法和广泛认可的ChatGPT相关经验,设计了一个包括自然语言描述任务和代码上下文的基本提示。
- 使用ChatGPT API:通过向ChatGPT API提交基本提示,并分析返回的测试质量,以回答四个研究问题:
- RQ1(正确性):ChatGPT生成的单元测试的正确性如何?错误测试中常见的错误是什么?
- RQ2(充分性):ChatGPT生成的单元测试的充分性如何?
- RQ3(可读性):ChatGPT生成的单元测试的可读性如何?
- RQ4(可用性):开发者能否直接采用ChatGPT生成的测试?
研究发现:
- 不足之处:只有24.8%的由ChatGPT生成的测试能够通过执行测试,其余测试存在多种正确性问题。其中57.9%的测试出现编译错误,17.3%的测试虽然能编译通过但执行失败,这通常是由于ChatGPT生成的断言错误。
- 优势:通过的测试在覆盖率、可读性方面与手工编写的测试相似,有时甚至更受开发者偏好。
方法提议:
- CHATTESTER方法:受上述发现的启发,提出了一种新的基于ChatGPT的单元测试生成方法CHATTESTER,该方法利用ChatGPT本身来提高生成测试的正确性。CHATTESTER包括一个初始测试生成器和一个迭代测试优化器,通过分解测试生成任务和迭代修正编译错误来提高测试质量。
- 初始测试生成器:
- 分解测试生成任务为两个子任务:
- 首先,利用ChatGPT通过意图提示(intention prompt)理解焦点方法。
- 然后,利用ChatGPT根据生成的意图通过生成提示(generation prompt)为焦点方法生成测试。
- 分解测试生成任务为两个子任务:
- 迭代测试优化器:
- 迭代修复初始测试生成器生成的测试中的编译错误。
- 采用验证和修复的模式,根据编译错误信息和额外的代码上下文提示ChatGPT进行修复。
- 初始测试生成器:
整体而言,这项研究表明,如果能进一步解决生成测试中的正确性问题,基于ChatGPT的测试生成可能非常有前途。研究还提出了两条潜在指导方针:为ChatGPT提供关于代码的深入知识,并帮助ChatGPT更好地理解焦点方法的意图,以减少编译错误和断言错误。
Evaluation:
这段文本描述了如何评估CHATTESTER这一单元测试生成方法的有效性。以下是评估过程的概要:
- 评估数据集:
- 使用了包含100个额外焦点方法的评估数据集,避免使用之前研究部分已经广泛分析的数据集。
- 研究问题:
- RQ5(改进):与默认的ChatGPT相比,CHATTESTER在生成正确测试方面的效果如何?CHATTESTER中的每个组件效果如何?
- 比较方法:
- 比较了由CHATTESTER生成的测试与默认ChatGPT生成的测试之间的编译错误数量和执行失败率。
- 进一步调查了CHATTESTER中每个组件的贡献。
- 研究结果:
- CHATTESTER显著提高了ChatGPT生成测试的正确性,编译成功率提高了34.3%,执行通过率提高了18.7%。
- 结果还进一步确认了CHATTESTER中两个组件的贡献:初始测试生成器能够生成更多带有正确断言的测试,而迭代测试优化器能够迭代修复编译错误。
Contributions:
本文主要做出了以下几方面的贡献:
- 实证研究:这是首次通过量化分析和用户研究,全面调查了ChatGPT生成的单元测试的正确性、充分性、可读性和可用性。
- 研究发现与实践意义:指出了基于ChatGPT的单元测试生成的局限性和前景,为未来的研究和实践提供了方向。
- 新技术—CHATTESTER:提出了首个包括初始测试生成器和迭代测试优化器的技术,该技术利用ChatGPT本身来提高生成测试的正确性。
- 广泛评估:通过实际评估展示了CHATTESTER的有效性,特别是在显著减少ChatGPT生成的测试中的编译错误和错误断言方面。
BACKGROUND
A. Large Language Models
这段文本详细介绍了大型语言模型(LLMs)的特点、分类、应用及其与人类意图对齐的最新进展,并探讨了ChatGPT在软件工程特定任务中的应用潜力。以下是该段内容的概括:
- 大型语言模型(LLMs)的定义和训练:LLMs是在大规模文本语料库上预训练的大型模型,采用自监督学习目标,如掩码语言建模、掩码跨度预测和因果语言建模。
- 技术架构:大多数LLMs基于变压器架构,具有用于输入表示的编码器和用于输出生成的解码器。LLMs可以分为仅编码器、仅解码器和编解码器三种模型。
- 应用领域和成就:LLMs已广泛应用于多个领域,并取得了巨大的成功。
- ChatGPT的开发和应用:ChatGPT是基于生成预训练变压器架构的新型LLM,通过监督学习和人类反馈的强化学习进行优化,已在多个任务中显示出卓越能力。它在软件工程任务中的潜力,如程序修复和代码生成,也开始被探索。
- 研究动机和方法:尽管ChatGPT的潜力得到认可,其在单元测试生成方面的效果仍不明确。为了填补这一知识空白,本研究首次探讨了ChatGPT在单元测试生成方面的能力,并提出了CHATTESTER,这是一种基于ChatGPT的新方法,旨在提高ChatGPT生成测试的质量。
总的来说,这段文本强调了LLMs在处理各种复杂任务中的能力,特别是ChatGPT如何被用于改善软件开发过程中的特定任务,如单元测试生成。
B. Unit Test Generation
这段文本讨论了单元测试生成的传统技术和基于学习的技术,以及ChatGPT在此领域的潜在优势和实际表现。以下是对该段内容的概括:
- 传统技术:
- 传统单元测试生成方法包括基于搜索的(如Evosuite)、基于随机的和基于约束的策略。
- 这些方法虽能实现合理的代码覆盖率,但生成的测试通常在可读性和意义性上不足,难以被开发者直接采用。
- 基于学习的技术:
- 最近的研究利用先进的深度学习技术,尤其是大型语言模型(LLMs),来生成单元测试,将测试生成视为神经机器翻译问题。
- 例如,AthenaTest和Teco等工作通过在特定的测试生成数据集上微调LLMs,生成完整的测试用例或补全测试用例的下一条语句。
- 基于学习的方法能生成更类似人类编写的、有意义的测试代码。
- ChatGPT的应用与评估:
- ChatGPT作为一种新发布的LLM,通过结合人类反馈的强化学习(RLHF)和更大的模型规模,显示出与人类意图更好的一致性和在各种任务中的杰出性能。
- 本研究评估了ChatGPT在单元测试生成方面的能力,发现它在生成正确性和覆盖率方面显著优于现有的最先进的基于学习的单元测试生成技术。
这段描述强调了在单元测试生成方面,从传统方法到基于深度学习的技术的演进,以及ChatGPT如何可能改变这一领域的现状,提供更高质量的测试生成解决方案。
STUDY SETUP
A. Benchmark
这段文本描述了为了全面评估ChatGPT生成的单元测试的质量,研究团队如何建立一个新的基准测试。以下是对这一过程的概括:
- 项目收集:
- 使用CodeSearchNet基准中的4,685个Java项目作为初始项目列表。
- 按照持续维护、至少100星级、使用Maven框架并能在本地环境成功编译的标准筛选,最终获得185个Java项目。
- 数据对收集:
- 从这185个项目中提取数据对,每对包括一个焦点方法和其对应的测试方法。
- 对每个Java项目进行分析,找到所有包含至少一个标记有@Test注解的方法的类,将这些类视为测试类。在确定为测试类的类中,收集所有的测试方法。对每个测试方法,通过文件路径和类名匹配来寻找相应的焦点方法。例如,若测试方法“testFunction()”位于“src/test/java/FooTest.java”,则会将位于“src/main/java/Foo.java”的“Function()”方法视为其焦点方法。如果在同一类中存在多个同名的焦点方法,进一步通过参数的数量和类型进行筛选,以确保找到唯一匹配的方法。
- 基准测试建立:
- 从这些项目中严格提取了1,748个数据对。
- 考虑到使用ChatGPT API的成本和用户研究的人工努力,最终抽样1,000个数据对作为实证研究的最终基准。
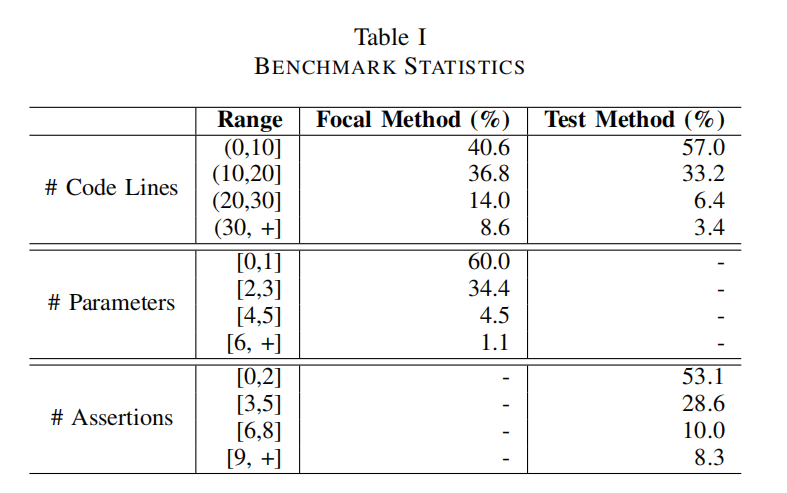
- 基准测试的统计数据包括每个焦点方法和测试方法的代码行数、焦点方法的参数数量和测试方法的断言数量,展示了测试方法和焦点方法的多样化规模和结构。
总的来说,这段描述强调了研究团队为确保评估质量而建立的详尽和精确的基准测试框架,旨在通过这一基准更好地理解和评估ChatGPT在单元测试生成领域的表现。
B. Basic Prompt Design
这段文本描述了为评估ChatGPT在单元测试生成中的能力而设计的基本提示(basic prompt)的构成和理念。以下是对该过程的概括:
- 提示设计目的:
- 设计基本提示是为了避免使用过于简单的提示,这可能会低估ChatGPT的能力,同时也避免使用在实际中不常见的复杂提示。
- 基本提示的组成:
- 基本提示包含两部分:
- 自然语言描述部分(NL部分):向ChatGPT解释任务的内容。
- 代码上下文部分(CC部分):包括焦点方法和其他相关的代码上下文。
- 基本提示包含两部分:
- 代码上下文(CC部分):
- 包括完整的焦点方法(方法签名和方法体)、焦点类的名称、焦点类中的字段、以及在焦点类中定义的所有方法的签名。
- 自然语言描述(NL部分):
- 包括角色扮演指令(例如,“你是一名编写Java测试方法的专业人士。”)以激发ChatGPT生成测试的能力,这是一种常见的提示优化策略。
- 包括任务描述指令(例如,“请基于给定信息为{焦点方法名称}编写测试方法,使用{JUnit版本}。”)来明确任务要求。
本文通过这样详细的说明,阐述了如何通过精心设计的提示来有效地利用ChatGPT生成单元测试,以期获得更准确和实用的测试输出。

C. Baselines
这段文本描述了在进行单元测试生成评估时采用的两种基准测试方法:传统技术和基于学习的技术。以下是对这些基线设置的概括:
- 传统技术基线 - Evosuite:
- 使用Evosuite生成每个数据对中焦点类的测试,采用默认设置。
- 从生成的多个测试中,只保留第一个调用焦点方法的测试,以便与其他技术(如AthenaTest和ChatGPT)进行公平比较。
- 基于学习的技术基线 - AthenaTest:
- 由于AthenaTest没有发布其基于BART的预训练模型或微调模型,研究团队根据其论文内容,使用广泛使用的LLM CodeT5在AthenaTest使用的相同微调数据集上进行重现和微调。
- 选择CodeT5是因为它已经在文本和代码语料库上进行了预训练,这也是AthenaTest论文中显示的最佳预训练设置。
此外,为避免潜在的数据泄露,从微调数据集中移除了与基准测试数据集重复的数据。这样的措施确保评估的准确性和公正性。
D. Experimental Procedure
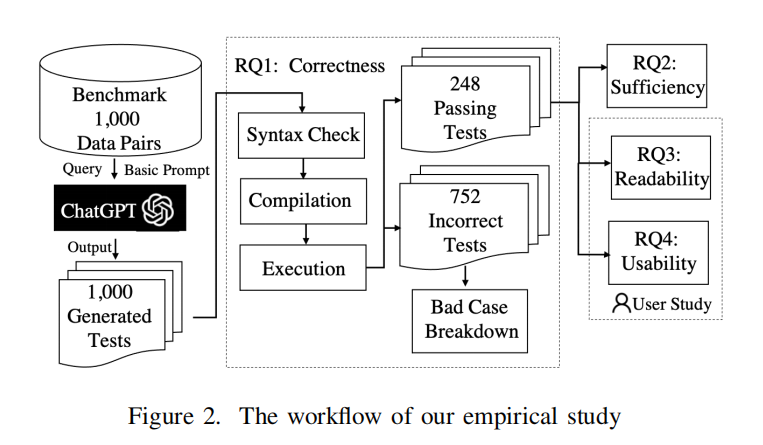
这段文本描述了一个关于ChatGPT生成的单元测试的实验过程和评估方法,涉及三个研究问题(RQ1, RQ2, RQ3 & RQ4)。以下是对实验过程的概括:
- 实验设置:
- 使用在之前部分设计的基本提示,通过官方的ChatGPT API查询每个数据对,获取生成的测试,并将其放置在相应的焦点类目录中进行编译和执行。
- RQ1(正确性):
- 评估生成测试的正确性,包括语法正确性、编译正确性和执行正确性。
- 语法正确性:检查测试是否能通过语法检查器。此处使用AST解析器(例如JavaParser)作为语法检查工具。
- 编译正确性:评估测试是否能成功编译。
- 执行正确性:验证测试是否能成功执行。
- 评估生成测试的正确性,包括语法正确性、编译正确性和执行正确性。
- RQ2(充分性):
- 评估生成测试的充分性,包括对焦点方法的语句覆盖、分支覆盖和测试用例中断言的数量。
- 使用Jacoco工具收集覆盖数据。
- RQ3 & RQ4(可读性和可用性的用户研究):
- 对248个通过编译和执行的测试进行用户研究,评估其可读性和可用性。
- 邀请有4到5年Java开发经验的参与者,比较ChatGPT生成的测试和项目中手写的测试,通过问题调查参与者对测试的可读性评分和使用偏好。
STUDY RESULTS
A. RQ1: Correctness
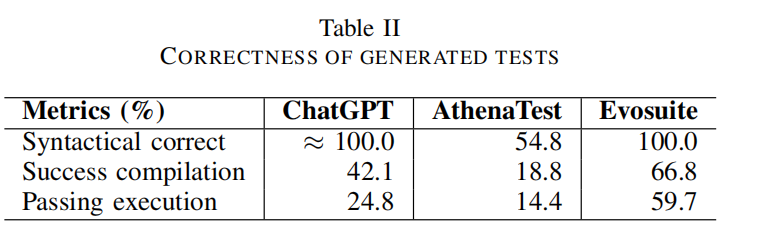
- ChatGPT生成的测试的正确性:
- 42.1%的由ChatGPT生成的测试能够成功编译,而只有24.8%的测试能成功执行且无执行错误。
- 失败的测试在人工检查后发现,问题主要是由不恰当的测试代码本身引起的,而非揭示被测试焦点方法中的错误。
- 与基于学习的基线(AthenaTest)的比较:
- ChatGPT在语法正确性、编译正确性和可执行正确性方面相较于AthenaTest有显著的改进。
- ChatGPT生成的测试在语法上几乎都是正确的(除了一个括号错误的例外),而AthenaTest生成的测试中近一半存在语法错误。
- ChatGPT较大的模型规模可能帮助它更好地捕捉到大量预训练代码库中的语法规则。
- 与传统基于搜索的基线(Evosuite)的比较:
- Evosuite生成的测试显示出更高的编译率和通过率。
- Evosuite在搜索过程中会剪枝无效的测试代码,并且基于动态执行值精确生成断言,而基于学习的技术(如ChatGPT和AthenaTest)则是直接逐个令牌生成测试,没有后生成验证或过滤。
- 总结:
- 尽管Evosuite在生成更正确的测试方面表现更好,但如果基于学习的技术也能加入类似的后生成验证来过滤不正确的测试,则其测试的正确性有进一步提升的潜力。
Finding1: ChatGPT在语法、编译和执行正确性方面大大优于现有的基于学习的技术。但是,只有一部分其生成的测试可以通过执行,而其生成的测试仍然有很大比例的编译错误和执行错误。
Bad Case Breakdown.
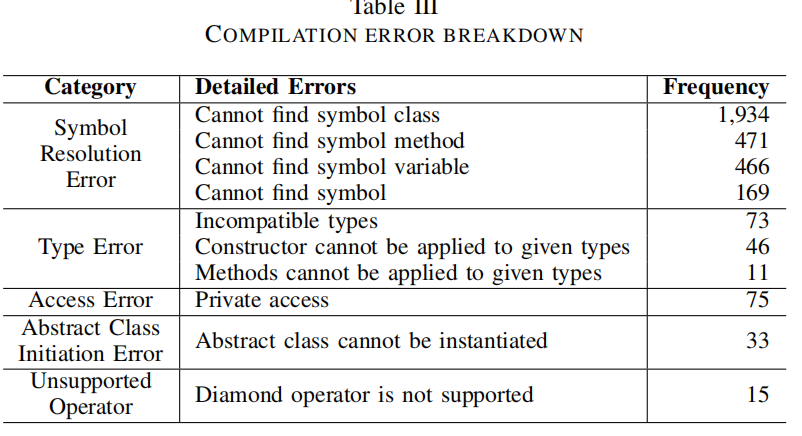
- 编译失败:
- 在表III中,统计了579个无法编译的测试中各类编译错误的频率。由于一个测试中可能出现多个编译错误,总数超过579。
- 常见的编译错误包括无法解析的符号(如未定义的类、方法或变量)、类型错误(如方法调用中的参数类型与方法声明不一致),以及非法访问私有变量或方法的访问错误。
- 还有一些测试因非法实例化抽象类或使用不支持的操作符而出现编译错误。
- 执行失败:
- 在表IV中,因空间限制,出现频率低于三次的错误归类为“其他”。
- 绝大多数执行失败(85.5%)由断言错误引起,即ChatGPT生成的断言认为程序行为违反了规范。
- 通过手动检查这些断言错误,发现它们都是由ChatGPT生成的不正确断言引起的,表明ChatGPT可能未能准确理解焦点方法,其生成的断言质量需要大幅提升。
- 其他执行错误包括各种运行时异常,例如,测试中抛出的NullPointerException因为尝试访问不存在的外部资源(如“/test.jar”)。
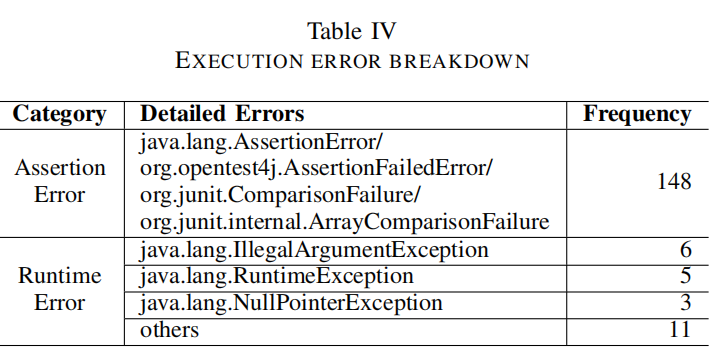
Finding2:chatgpt生成的测试会遇到不同的编译错误,如符号解析错误、类型错误和访问错误;大多数失败的执行都是由错误生成的断言引起的。
B. RQ2: Sufficiency
这段文本探讨了研究问题二(RQ2:充分性),聚焦于由ChatGPT及其他技术生成的单元测试在语句覆盖率和分支覆盖率上的表现,并比较了这些测试与手写测试的断言数量。以下是对这部分内容的概括:
- 覆盖率比较:
- 表V显示了能通过执行的生成测试的语句和分支覆盖率,并将其与手写测试(项目中针对焦点方法的原始测试)的覆盖率进行了比较。
- ChatGPT生成的测试在覆盖率上不仅超过了现有的基于学习和基于搜索的技术,而且与手写测试相当。
- 断言数量分布:
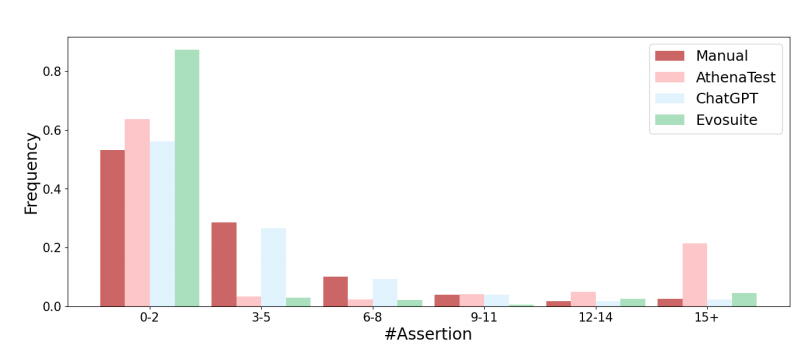
- 图4展示了不同技术生成的每个测试中断言数量的分布图。
- ChatGPT生成的测试在断言数量上与手写测试的分布最为相似。具体来说,Evosuite倾向于生成断言较少的测试,而基于学习的技术AthenaTest则可能生成断言异常多的测试(即每个测试超过15个断言)。
- ChatGPT生成更类似人类编写的测试代码可能得益于人类反馈的强化学习(RLHF)的帮助。
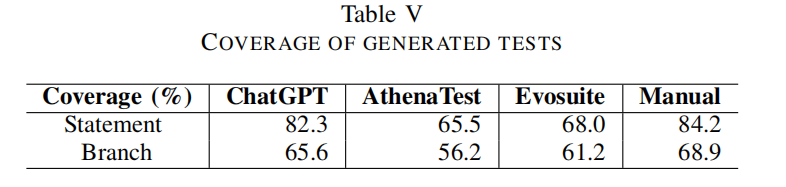
Finding3:chatgpt生成的测试在测试充分性方面与手工编写的测试相似。ChatGPT实现了与手工测试相当的覆盖率,而且与现有技术相比也具有最高的覆盖率;ChatGPT还生成更多类似人类的测试,每个测试的断言数量与手工编写的测试相似。
C. RQ3: Readability
这段文本讨论了研究问题三(RQ3:可读性),通过用户调查问卷的第一个问题(关于可读性的评价)的结果进行分析。以下是对这部分内容的概括:
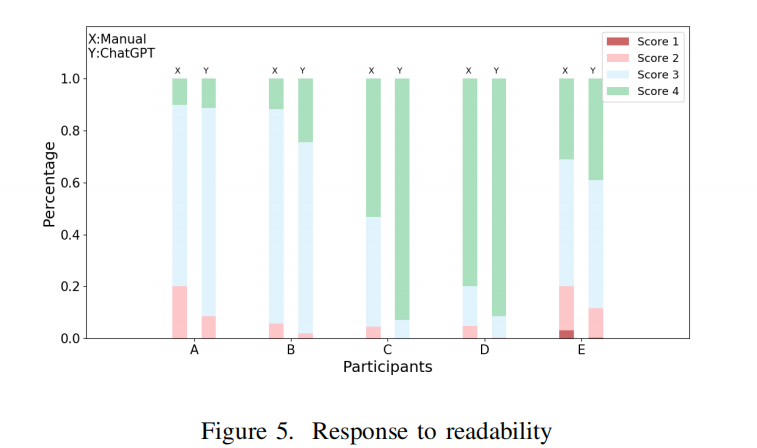
- 可读性调查结果:图5以堆叠柱状图的形式展示了各参与者(从A到E)对测试可读性的评分结果,其中x轴代表参与者,y轴表示不同评分的比例。
- 评价总结:大多数由ChatGPT生成的测试在可读性上获得了较好的评价。与手写测试相比,这些生成的测试在可读性上不仅相当,有时甚至更优。
Finding4:ChatGPT生成的测试与手工编写的测试具有良好和相当的可读性。
D. RQ4: Usability
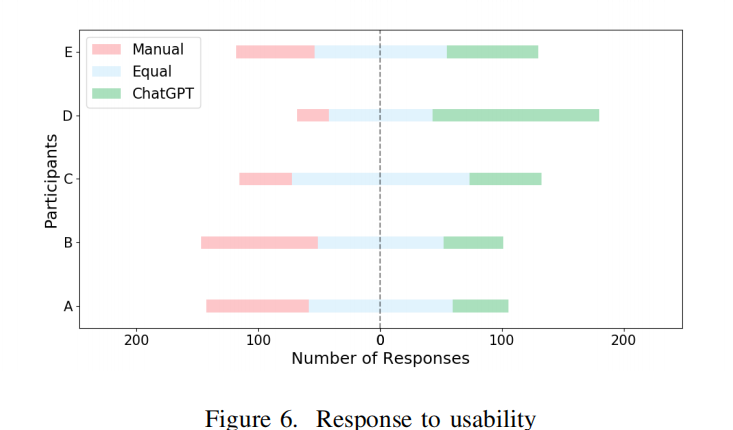
这段文本讨论了研究问题四(RQ4:可用性),通过用户调查问卷的第二个问题(关于测试的可用性)的结果进行分析。以下是对这部分内容的概括:
- 可用性调查结果:图6展示了参与者对于手写测试、ChatGPT生成的测试以及无偏好选择的响应数量。结果显示,ChatGPT生成的测试在可用性方面非常有竞争力,有时甚至有相当一部分情况下,参与者更倾向于选择ChatGPT生成的测试。
- 决策因素:参与者的选择通常基于多种因素的综合考虑,如代码格式、注释、调用焦点方法的方式以及断言的合理性。这些因素反映了参与者对于测试代码的综合评价。
- 总结:参与者的偏好表明,ChatGPT能够按照良好的手动编码实践生成测试,这使得参与者愿意直接使用这些生成的测试。
Finding5:Chatgpt生成的测试在实际可用性方面具有很大的潜力;在相当大的情况下,参与者愿意直接采用Chatgpt生成的测试。
E. Enlightenment
这段文本讨论了基于ChatGPT的单元测试生成的优势和局限性,基于之前的研究结果进行了深入分析。
局限性:
- 编译错误:大量的编译错误可能由于ChatGPT对代码中“深层知识”的不了解,例如,ChatGPT可能不会意识到只有公共字段可以在类外访问,抽象类不能实例化等规则。
- 执行错误:大多数执行错误(尤其是断言错误)源于ChatGPT对焦点方法意图的理解不足,这导致它难以为被测试的焦点方法编写恰当的断言作为规范。
优势:
- 尽管许多测试在编译或执行阶段失败,但通过的测试通常在充分性、可读性和实际可用性方面具有高质量,这些测试可以直接用于减轻手动编写测试的工作量。
- 如果能进一步解决生成测试中的正确性问题,利用ChatGPT生成单元测试是一个有前途的方向。
总的来说,这段文本强调了通过改进和优化ChatGPT的测试生成过程,可以克服现有的限制并发挥其在自动化测试编写中的潜力。
启示:基于chatgpt的单元测试生成是很有前途的,因为它能够生成许多高质量的测试,具有相当的可用性、可读性和可用性。但是,还需要进一步的努力来解决chatgpt生成的测试中的正确性问题。为此目的的两个方向是(i)为ChatGPT提供关于代码的深入知识,(ii)帮助ChatGPT更好地理解焦点方法的意图,从而分别减少其编译错误和断言错误。
APPROACH OF CHATTESTER
Overview: CHATTESTER,这是一种改进的基于ChatGPT的单元测试生成方法,旨在提高ChatGPT生成的测试的正确性。CHATTESTER由两个主要组件组成:
- 初始测试生成器:
- 这个组件不是直接要求ChatGPT为给定的焦点方法生成测试,而是将测试生成任务分解为两个子任务:首先理解焦点方法的意图,然后基于这一意图生成单元测试。这个过程旨在生成具有更高质量断言的测试,通过意图生成的中间步骤来帮助提高断言的质量。
- 迭代测试优化器:
- 这个组件迭代地修复初始测试生成器生成的测试中的编译错误。如前所述,消除大部分不可编译测试的关键是在测试生成过程中向ChatGPT提供“深层知识”。由于无法事先在提示中包含所有这些潜在规则,因此采用验证和修复的范式,通过向ChatGPT提供编译错误消息和额外相关的代码上下文来迭代优化不可编译的测试。迭代测试优化器实际上利用编译器的错误消息作为“深层知识”的违规实例来修正生成的测试中的编译错误。
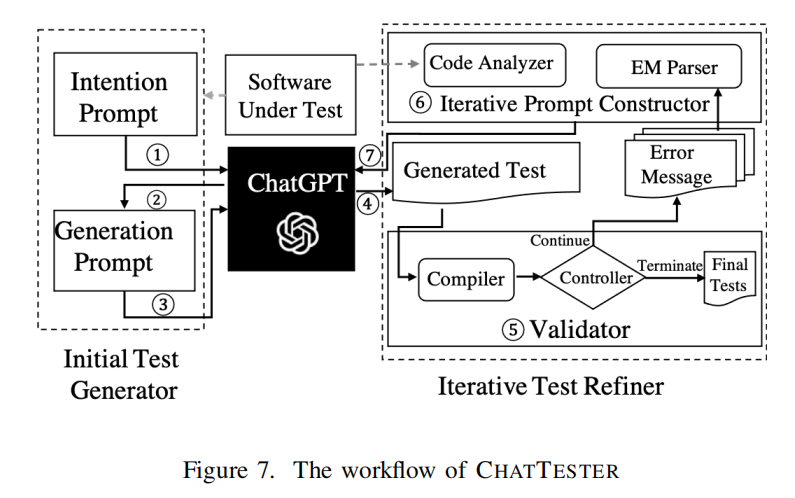
A. Initial Test Generator
这段文本描述了初始测试生成器的工作原理,它是CHATTESTER方法中的一个关键组件,用于改进测试的生成过程。初始测试生成器将测试生成分为两个步骤:
- 意图提示:
- 首先,利用ChatGPT通过意图提示来理解焦点方法的预期功能。意图提示要求ChatGPT返回焦点方法的功能意图的自然语言描述。这包括类声明、构造函数签名、相关字段以及焦点方法本身,类似于基本提示中的代码上下文部分。此外,自然语言指令要求ChatGPT推断焦点方法的意图。
- 生成提示:
- 然后,基于生成的意图,利用生成提示让ChatGPT为焦点方法生成测试。生成提示将包含生成的意图,并要求ChatGPT生成对应的单元测试。
文本中还通过图示比较了基本提示和初始测试生成器如何为同一个给定的焦点方法“setCharAt()”生成测试。例如,在没有意图推断的基本提示下,ChatGPT生成了一个包含错误断言的测试。而在使用意图提示后,ChatGPT首先正确地生成了焦点方法的意图,随后通过生成提示生成了一个包含正确断言的测试。这种额外的意图推断旨在增强ChatGPT对焦点方法的理解,从而导致更准确的断言生成。

B. Iterative Test Refiner
这段文本描述了CHATTESTER方法中的迭代测试优化器的工作流程,它主要致力于修复初始测试生成中产生的编译错误。以下是该过程的详细概括:
- 迭代修正流程:
- 过程开始于在验证环境中编译生成的测试,以验证其编译状态。
- 如果编译出错,根据编译错误消息和相关的代码上下文构建新的提示。
- 使用新提示查询ChatGPT,以获取修正后的测试。
- 这个过程会重复进行,直到测试能成功编译或达到最大迭代次数。
- 验证器:
- 直接在焦点类的同一目录下创建测试文件,并尝试用Java编译器编译。
- 根据编译状态决定后续步骤:成功编译则终止迭代;如果当前迭代比上一次有更少的编译错误,则继续迭代;如果错误没有减少或增加,则根据累计的无效迭代次数决定是否终止。
- 迭代提示构造器:
- 基于错误消息解析器(EM parser)和代码分析器来构建迭代提示。
- 错误消息解析器识别错误类型、触发编译错误的测试代码行和出错的元素(如变量或对象)。
- 代码分析器从项目中提取额外的代码上下文,如错误元素所在的类的声明和公共方法签名,并将这些信息加入到提示中。
- 高效生成测试:
- 这种方法通过逐步添加必要的代码上下文和基于编译错误消息的反馈,有助于生成高质量的测试代码。
- 这种迭代方式能够确保生成的测试不仅解决了编译错误,还能适应复杂的项目结构,提高测试的质量和实用性。

EVALUATION OF CHATTESTER
A. Evaluation Setup
这段文本描述了用于评估CHATTESTER方法的实验设置,包括评估数据集的构建和研究的技术方法。以下是该部分的详细概括:
- 评估数据集:
- 为了避免使用先前研究中已经广泛分析的基准数据集,从而消除潜在的过拟合问题,构建了一个新的评估数据集。
- 在之前的研究中共收集了1,748个数据对,用于实证研究的基准数据集中包括了1,000个数据对;在本节中,从剩余的748个数据对中重新抽样了100个数据对,用作评估CHATTESTER的有效性。
- 研究的技术:
- 为了评估CHATTESTER的总体有效性以及其各个组件(初始测试生成器和迭代测试优化器)的单独贡献,研究了三种技术:
- ChatGPT:使用基本提示的默认ChatGPT,即在实证研究中使用的版本。
- **CHATTESTER-**:CHATTESTER的一个变体,没有迭代测试优化器,仅增强了默认ChatGPT的初始测试生成器。
- CHATTESTER:完整的CHATTESTER,包括初始测试生成器和迭代测试优化器。
- 为了评估CHATTESTER的总体有效性以及其各个组件(初始测试生成器和迭代测试优化器)的单独贡献,研究了三种技术:
- 实验重复性:
- 为了减少ChatGPT的随机性影响,所有实验都重复进行了三次,并展示了平均结果。
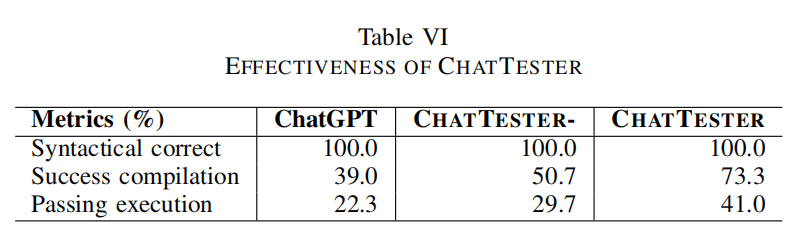
B. Evaluation Results
这段文本详述了CHATTESTER方法及其变体在生成单元测试中的评估结果。以下是关键点的概括:
- CHATTESTER的性能提升:
- 与默认的ChatGPT相比,CHATTESTER在编译率和通过率上显示出显著的改善。例如,额外有34.3%的测试能够成功编译,另外18.7%的测试能够成功执行。
- CHATTESTER- 的表现:
- CHATTESTER-(没有迭代测试优化器的版本)在编译率和通过率上也比默认的ChatGPT有所提高,分别提高了11.7%和7.4%。
- 在ChatGPT生成的带有错误断言的测试中,有12.5%的断言在CHATTESTER-中被修正为正确的断言,显示出初始测试生成器的有效性。
- 进一步的改进:
- 从CHATTESTER-到CHATTESTER,可以看到进一步的提升,即迭代测试优化器将额外22.6%的测试修正为可编译的测试,并将11.3%的测试修正为通过的测试。
- 实际示例:
- 文中提供了如何通过意图提示和迭代测试优化器分别改进断言正确性和修复编译错误的具体例子(图8和图9)。
评估摘要:聊天测试人员通过大大减少生成的测试中的编译错误和错误的断言,有效地提高了chatgpt生成的测试的正确性。特别是,初始测试生成器和迭代测试细化器对聊天测试者的有效性都有积极的贡献。
CONCLUSION
在这项工作中,我们进行了第一项实证研究,以评估ChatGPT在单元测试生成方面的能力,通过系统地调查其生成的测试的正确性、充分性、可读性和可用性。我们发现,由ChatGPT生成的测试仍存在正确性问题,包括多样的编译错误和执行失败(主要是由于不正确的断言引起的);但通过的测试与手写测试相似,实现了可比的覆盖率、可读性,甚至有时候开发者的偏好。我们的发现表明,如果可以进一步提高其生成测试的正确性,基于ChatGPT的单元测试生成非常有前景。受我们上述发现的启发,我们进一步提出了CHATTESTER,利用ChatGPT本身来提高其生成测试的质量。我们的评估显示,CHATTESTER通过生成比默认ChatGPT多34.3%的可编译测试和多18.7%的正确断言的测试,证明了其有效性。