
Recommending Analogical APIs via Knowledge Graph Embedding
Recommending Analogical APIs via Knowledge Graph Embedding
ABSTRACT
在软件发展过程中,库迁移是一种常见的操作,目的是替换当前使用的库以保持相同的软件行为。这其中一个关键部分是找到与所需功能相对应的类似API。然而,由于库/API的数量众多,手动寻找这样的API既耗时又容易出错。研究者们创建了自动化的类比API推荐技术,尤其是基于文档的方法。尽管这些方法具有潜力,但也存在局限性,例如文档中的语义理解不完整以及可扩展性问题。在这项研究中,我们提出了一种新的基于文档的方法KGE4AR,通过知识图(KG)嵌入技术来推荐类比API,用于库迁移。KGE4AR引入了一个统一的API知识图,以全面表示文档知识,捕捉高级语义。它进一步将这个统一的API知识图转化为向量,以实现高效、可扩展的相似度计算。我们在两种情况下评估了KGE4AR,即有目标库和无目标库的情况,使用了35,773个Java库。KGE4AR显著优于现有最先进的技术(例如,在MRR上提高了47.1%-143.0%和11.7%-80.6%),展示了随着库数量增加的可扩展性。
INTRODUCTION
Background:
- 第三方库的重要性:第三方库在现代软件开发中至关重要,显著提高了质量和生产效率。
- 当前库的挑战:由于软件和库的快速发展,当前的库可能由于各种因素(如可持续性失败、许可限制、功能缺失以及安全或性能问题)而变得不适用。
- 库迁移的需求:这些挑战需要进行库迁移,开发者需替换当前的库,以保持相同的软件行为。
- 库迁移的普遍性:库迁移在软件演化中很常见。例如,何等人的研究显示,在17,426个开源项目中,有8.98%至28.72%的项目至少经历了一次库迁移。
Challenges of library migration:
- 库迁移的挑战:库迁移是一个耗时、劳动密集且容易出错的任务。有研究表明,一些开发者在库迁移上可能花费长达42天的时间。
- 库迁移的关键步骤:库迁移的一个重要部分是找到一个提供相同功能的类似库(目标库)和类似API(目标API)。
- 手动寻找类似API的困难:手动寻找类似API对开发者来说是一个重大负担,因为他们需要阅读大量的API文档和代码片段,而第三方库和API的数量极大且变化快速,例如截至2020年1月,仅Libraries.io上就有35,773个常用Java库,包含15,441,057个API。
Related work and limitations:
类比API推荐技术:为了减少手动搜索和阅读API文档与代码片段的努力,研究者们提出了多种技术来推荐合适的目标库或类似的目标API。这些推荐技术利用了包括演化历史 [58, 65]、在线问答互动 [34]和API文档 [28, 30, 34, 54, 59,60, 79]等多样化资源。文档基于的API推荐尤为突出,因为API文档易于获取且成本较低。
[34] Chunyang Chen, Zhenchang Xing, Yang Liu, and Kent Ong Long Xiong. 2021.Mining Likely Analogical APIs Across Third-Party Libraries via Large-Scale Unsupervised API Semantics Embedding. IEEE Trans. Software Eng. 47, 3 (2021), 432–447. https://doi.org/10.1109/TSE.2019.2896123
现有技术的局限性:
- 语义捕捉不足:现有的文档基础技术在计算文本相似度时,无法充分捕捉API文档中的语义级联系。这些技术主要基于重叠的词汇计算文本相似度,或在没有上下文考虑的情况下测量词汇相似度,可能导致在API描述中识别类似的名词短语但动词不同的情况(例如,“设置S3对象内容”与“获取S3对象内容长度”)。
- 领域知识忽视:这些技术在计算文本相似度时很少考虑领域知识,如JSON数组、对象、键和值等常见于JSON处理的API中的概念。
- 计算成本高:这些技术通常需要成对计算相似度,当候选API数量庞大时,计算成本极高。例如,像TestNG这样的库可能包含超过4,000个候选API,需要进行超过4,000次成对比较,这种计算不仅耗时而且成本高昂,特别是当涉及多个目标库时。
Key insights:
为了解决上述挑战,作者提出了一种名为KGE4AR的新方法,这是一种基于文档的方法,有效且可扩展地利用知识图嵌入来推荐类比API。KGE4AR的解决方案包括以下两个技术创新:
- 统一API知识图(KG)的构建:KGE4AR构建了一个统一的API知识图,这个知识图汇总了三种类型的文档知识,覆盖了不同的库。这种统一的表示方式能够更好地捕捉API文档中的总体语义。
- 知识图的嵌入表示:KGE4AR通过将统一的API知识图嵌入为数值向量,增强了效率和可扩展性。这种嵌入允许通过向量索引来简化类比API向量的检索过程,从而提高了检索的效率和可扩展性。
Implements, evaluation and contributions:
这段文本详细描述了KGE4AR的实现、评估和贡献:
- 实现KGE4AR:作者构建了一个包含59,155,631个API元素的统一API知识图(KG),这些元素来自35,773个Java库。这个知识图包括72,242,099个实体和289,122,265个连接这些实体的关系。
- 评估KGE4AR:
- 有目标库的情况:KGE4AR在MRR(最大回归率)和Hit@10两个指标上比基线模型分别提高了47.1%-143.0%和41.4%-95.4%。
- 无目标库的情况:KGE4AR在MRR、精度和召回率方面分别实现了11.7%-80.6%、26.2%-72.0%和33.2%-116.5%的提升,显著优于现有的类比API推荐技术。
- 可扩展性评估:研究还评估了KGE4AR随着库数量增加的可扩展性表现。
- 设计选择的影响:进一步深入研究了KGE4AR不同设计选择的影响。
- 贡献:
- 新颖方法:介绍了KGE4AR,这是一种基于文档的类比API推荐方法,通过为众多库构建统一的API知识图,提供了可扩展的推荐。
- 全面评估:通过在两种API推荐场景下的效果比较、不同库数量的可扩展性评估以及设计选择影响的分析,全面评估了KGE4AR。
- 公共基准测试:发布了一个用于广泛评估类比API的公共基准测试。
BACKGROUND AND RELATED WORK
2.1 Analogical API Recommendation
类比API推荐技术的来源和方法:
- 不同数据来源:类比API推荐技术使用包括演化历史、在线帖子和API文档等多样化的数据源来寻找合适的目标API。
- 基于演化历史的方法:利用代码变更等演化历史来挖掘经常一起出现的API对。
- 基于文档的方法:通过分析API相关文本(例如描述)来计算文本相似度。这种方法由于其普及性、数据收集成本低、以及近期研究的重点而被本文聚焦。
由于基于文档方法的流行,数据收集的低成本和最近的研究重点,我们专注于基于文献的建议。
文档基础的API类比技术的分类:
- 基于监督学习的技术:如Alrubaye等人提出,利用从API文档中提取的特征(如方法描述、返回类型描述、方法名和类名的相似性)来训练机器学习模型(例如提升决策树),并使用此模型预测未见API对的类比概率。
- 基于无监督学习的技术:常通过无监督方式对API进行向量化,然后根据向量相似度推荐类比API。例如,张等人使用Word2Vec模型来向量化API的功能描述、参数和返回值,进而计算这些向量的联合相似度。
现有技术的局限性:
- 文本相似度的计算局限:现有方法基于重叠词汇计算文本相似度或在忽略整体上下文的情况下测量词汇相似度,难以捕捉API文档中的语义级相似性。
- 可扩展性问题:这些技术以穷尽方式计算所有API之间的成对相似性,当API数量庞大时遇到可扩展性问题。
作者的创新方法及评估:
- 新的统一API知识图(KG):作者首次尝试使用一个新的统一API知识图全面且结构化地表示API文档中的知识。
- 知识图嵌入:进一步利用知识图嵌入来实现更有效和可扩展的相似度计算。
- 评估结果:评估结果显示,与现有的文档基础技术相比,作者的方法在有效性和可扩展性方面有所改进。
2.2 Knowledge Graph in Software Engineering
这段文字讨论了在软件工程领域中知识图(Knowledge Graph, KG)的应用,以及作者如何特别地将其应用于类比API推荐:
知识图在软件工程中已被用于多种目的,包括API概念、API注意事项、API比较、API文档、领域术语、编程任务、机器学习/深度学习模型和bug的研究。
与现有工作不同,作者将API知识图应用于类比API推荐任务。这意味着作者的API知识图在设计和关注点上与现有的知识图不同。
例如,现有为API误用检测构建的知识图主要包括API之间的调用顺序和条件检查关系。而作者构建的API知识图专注于API文档中有助于类比API推荐的三种类型的知识:API结构、API功能描述和API概念关系。
作者还提出了一种新颖的知识图嵌入方法,以实现更有效和更可扩展的类比API推荐。
2.3 Knowledge Graph Embedding
知识图嵌入使用低维向量来表示知识图中的实体和关系,能够捕捉实体间的语义关系。这些模型将实体映射到一个向量空间中,使得相似的实体在空间中更接近。
KGE在问答系统、推荐系统和知识图补全等应用中表现出色。
常用的知识图嵌入方法包括TransE、TransR和DistMult。这些方法将知识图中的三元组(头实体、关系、尾实体)编码成连续的向量表示。例如,TransE将实体和关系视为向量,并定义关系作为从头实体到尾实体的转换。
作者使用KGE技术来嵌入一个统一的API知识图,用于类比API推荐。
APPROACH
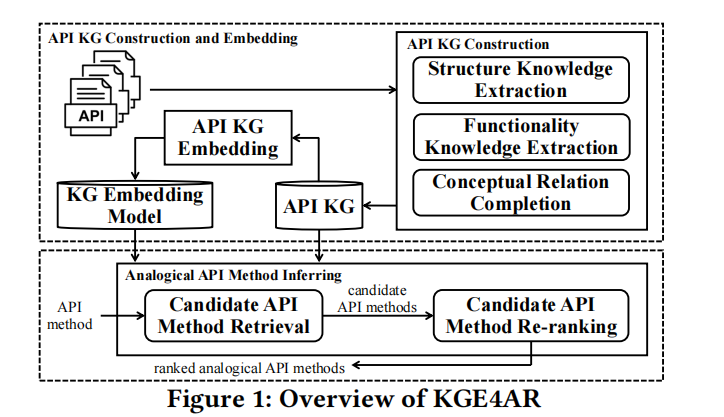
KGE4AR是一种基于知识图嵌入的类比API推荐系统,包含三个主要阶段:
- API知识图构建:
- KGE4AR首先根据大量库的API文档构建一个统一的API知识图。这个知识图包含了文档中发现的三种类型的知识:API结构(如包结构、类定义、方法声明)、API功能描述(例如,“获取JSONArray中元素的数量”)、以及API概念关系(例如,“属于”关系)。
- API知识图嵌入:
- 然后,KGE4AR训练一个嵌入模型来将构建的知识图嵌入到一个向量空间中。这一步骤通过将每个API表示为向量,实现了结构和语义数据的有效保存,并加快了知识图中API之间的相似度计算。
- 类比API方法推断:
- 对于给定的源API,KGE4AR基于嵌入的知识图返回其类比API。这一过程通过向量索引快速检索相似的API向量,提高了检索效率。
技术创新:
- 创新1:提出构建一个包含大量库的统一API知识图,不仅包括API结构和功能描述,还新增了API概念关系这一以往未探索的类别。
- 创新2:采用基于知识图嵌入的相似度计算方法,与传统方法相比,这种方法无需对所有API对进行穷尽的相似度计算,从而实现了更高效且有效的相似度计算方法。
KGE4AR的设计允许一次构建和嵌入后,可以高效地为给定API推荐类比API,显著提高了推荐过程的效率和效果。
3.1 API Knowledge Graph Construction
在这个阶段,KGE4AR根据大量库的API文档构建了一个统一的API知识图(KG)。构建过程主要包括三个步骤:
- 结构知识提取:
- KGE4AR首先从文档中提取所有API元素(如包、类/接口、方法、字段、参数)及其关系,形成API知识图的基本骨架。
- 功能知识提取:
- 接着,KGE4AR提取API库的功能知识,即方法的标准化功能表达(包括功能动词、功能类别和短语模式)以及涉及的概念,这些都是从方法的名称和文本描述中得到的。
- 概念关系完成:
- 最后,KGE4AR通过分析API元素和概念的名称及文本描述,完成API元素与概念之间的概念关系。这样,不同库的API元素可以基于共享的类型引用(例如方法参数和返回值的类型)、功能表达和概念相互关联。
3.1.1 Schema of the Unified API Knowledge Graph.
这段文字详细介绍了统一API知识图(KG)的架构,包括关键实体和关系的定义:
- API元素:
- API元素包括库、包、类/接口、字段、方法、返回值、参数和抽象参数等组件,这些是构成API基本构建块的元素。
- 结构关系:
- 结构关系描述了API元素之间的关系,如“extend”(继承)、“implement”(接口实现)、“has field”(类/接口中的字段)、“has method”(类/接口中的方法)、和“has parameter”(方法所需的参数),这些关系构成了API知识图的基础。
- 功能表达元素:
- 功能表达元素涉及到API功能描述的结构表达,包括功能表达、功能动词、功能类别和短语模式。这些元素帮助标准化API功能的表示。
- 功能表达:
- 功能表达为方法的功能描述提供了一个标准化的结构表达,从方法的描述句中提取。
- 功能动词:
- 功能动词代表表达功能主要动作的动词,例如“return”、“get”和“obtain”。
- 功能类别:
- 功能类别基于语义含义对功能表达进行分类,从一组具有相似含义的功能动词中抽象出来,例如“return”、“get”和“obtain”可以归类为同一类别。
- 短语模式:
- 短语模式捕捉功能表达中使用的特定句法模式或模板,例如“V {patient}”和“V {patient} in {location}”,其中占位符“patient”和“location”代表充当语义角色的名词短语。
- 概念:
- API知识图中的概念是捕捉特定领域知识或API文档中常见主题的语义单位,通常由名词短语表示。例如,在处理JSON相关的API中,常见概念如JSON数组、JSON对象、键和值。概念可以在功能表达中扮演某些语义角色(例如,patient, location)。
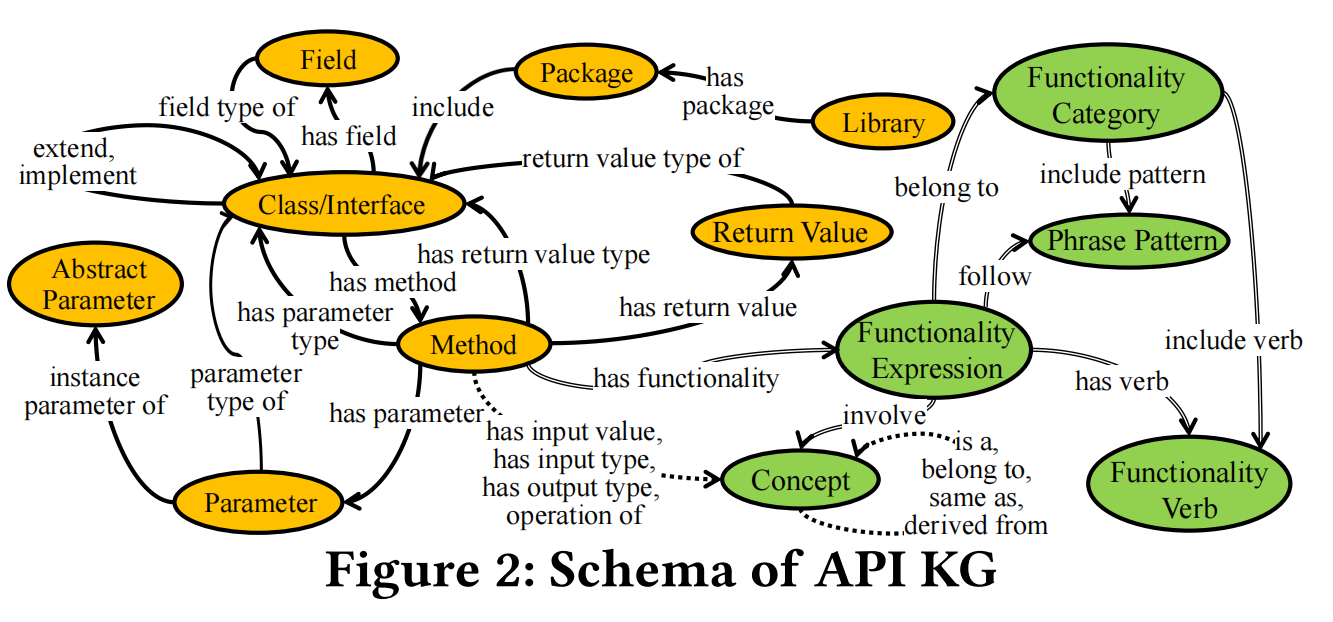
图2展示了API知识图(KG)的结构,描绘了其中涉及的不同类型的实体和它们之间的关系。这些实体和关系如下所述:
- API元素(橙色椭圆):
- 包括包、库、类/接口、方法、字段、返回值、参数和抽象参数等。
- 这些元素通过结构关系连接,如“extend, implement”(扩展、实现)、“has field”(包含字段)、“has method”(包含方法)和“has parameter”(包含参数)。
- 功能表达元素(绿色椭圆):
- 包括功能表达、功能动词、功能类别和短语模式。
- 这些元素通过功能相关的关系连接,如“include verb”(包含动词)、“follow”(跟随)、“involve”(涉及)。
- 概念(绿色椭圆):
- 与功能表达元素相关,通过双线表示的关系连接,显示它们之间的语义联系,如“is a”(是一个)、“belong to”(属于)。
此结构不仅展示了API元素之间的直接结构关系,还揭示了功能和概念之间的更深层次的语义联系。例如,一个方法的功能表达可以通过功能动词、功能类别和特定的短语模式详细描述,而这些功能表达又与特定的概念相关联。这样的知识图结构有助于精确地描绘出API功能的细节和它们的语义网络,为功能相关的查询和类比API推荐提供了强大的支持基础。
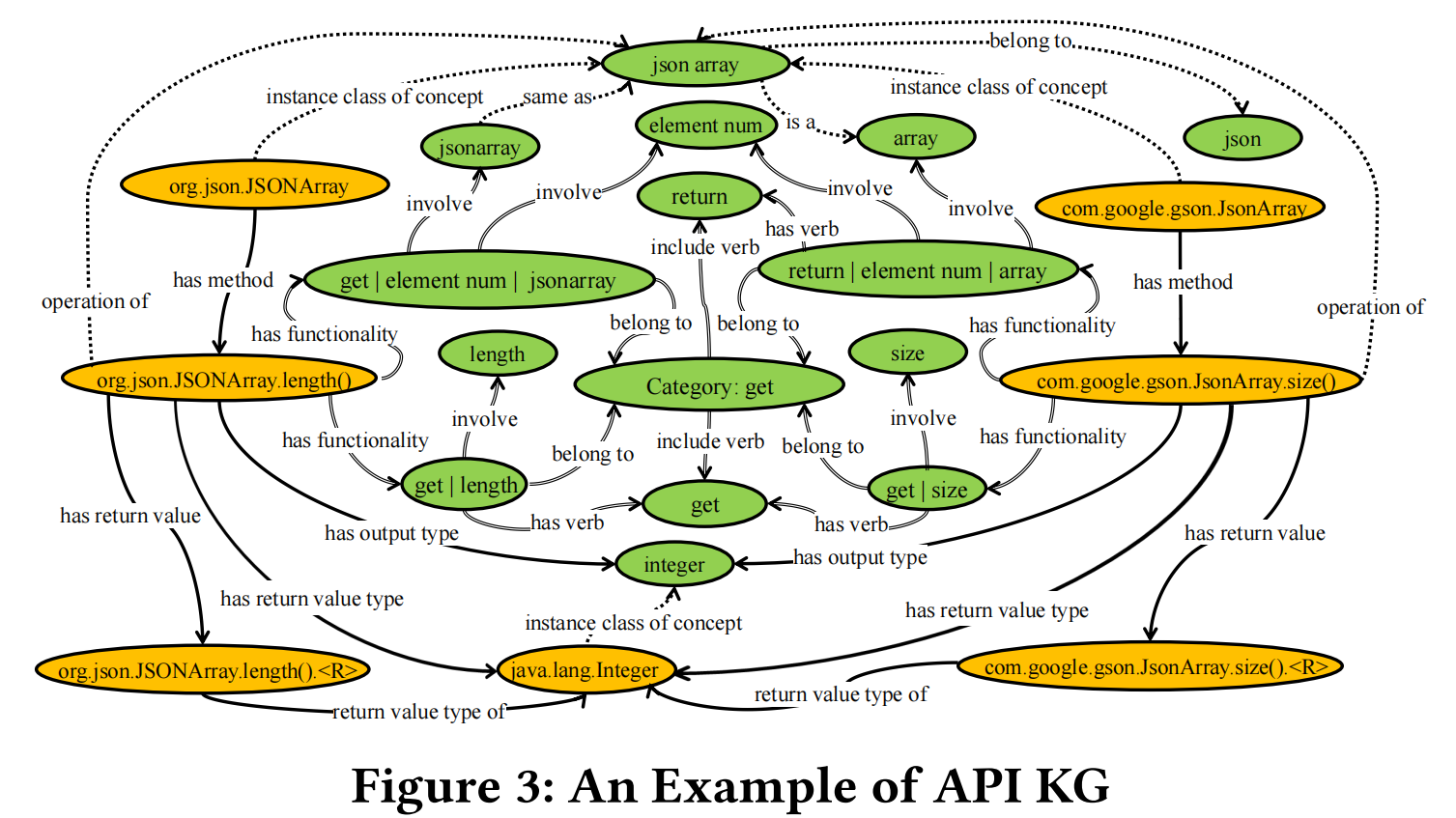
图3展示了API知识图中与两个类比API方法相关的实体和关系,这两个方法分别是来自不同库的org.json.JSONArray.length()和com.google.gson.JsonArray.size()。这两种方法虽然名称(分别是length()和size())和功能描述(分别是“获取JSONArray中的元素数量,包括空值”和“返回数组中的元素数量”)不同,但在API知识图中通过不同类型的关系间接相关联。
在API知识图中,这两个方法通过以下几种方式表现出相似性:
- 返回值类型:两个方法都返回相同类型的数据,这在图中通过将两个方法连接到相同的返回值类型
java.lang.Integer来表示。 - 功能类别:两者都属于“get”类别,这在知识图中通过连接到功能类别“get”的节点来表示。
- 概念关联:两个方法都与“json array”和“element num”等概念相关联,这些概念在图中通过与方法相关的节点表示。
3.1.2 Structure Knowledge Extraction.
在本工作中,结构知识提取是构建API知识图(KG)基本框架的首要步骤。以下是此步骤的关键点:
- 数据源与工具:
- 选择了Java库作为重点,利用其流行性和标准化的Javadoc API文档(存放于JAR文件中)进行分析。
- 使用JavaParser工具分析JAR文件中的Java源文件,这是因为Java的结构化文档格式和广泛的应用。
- 结构知识的提取过程:
- 利用静态分析和抽象语法树(AST)技术,从Java源代码中提取所有API元素及其结构关系和文本描述。
- 不仅限于Java,KGE4AR也可以适用于其他来源的API文档,例如在线官方文档。
- 功能实现:
- 从API定义中提取所有API元素和它们的结构关系,如图2所示的架构。
- 进一步从每个API元素的Javadoc注释中提取文本描述,这些描述用于后续的功能知识提取和概念知识提取。
3.1.3 Functionality Knowledge Extraction.
这段文字详细描述了如何从API方法的名称和文本描述中提取功能知识,这是构建API知识图的关键部分。以下是主要步骤和方法:
- 功能知识的数据源:
- 使用Xie等人提供的标准化功能描述数据集,包含10,016个功能动词,89个功能类别和523个短语模式。
- 功能表达的解析工具:
- 利用FuncVerbNet工具,这是一个能够将功能描述解析为标准化功能表达的文本分类器。该工具通过依存树解析,将功能描述分类到一个功能类别,并识别相应的短语模式、功能动词和概念。
- 功能表达的具体示例:
- 例如,从描述“returns the number of elements in the array”中提取出的功能表达包括:功能类别是“get”,功能动词是“return”,短语模式是“V {patient} in {location}”,概念是[element number, array]。
- 功能知识的提取过程:
- 对于每个API方法,首先取其文本描述的第一句作为功能描述,使用FuncVerbNet提取关联的功能表达。
- 提取的功能表达中涉及的概念(对应于短语模式中的名词短语)通过去除停用词和词形还原技术进行精炼。
- 如果提取的功能表达和相关概念在API知识图中尚不存在,将它们作为实体添加进来,并建立它们之间的“involve”关系。
- 还会建立提取的功能表达与其他现有元素(如功能动词、短语模式和功能类别)之间的关系。
- 处理无文本描述的方法:
- 如果方法没有文本描述,从其名称中提取功能表达,通过按驼峰命名和下划线分割名称为一系列令牌,然后将这些令牌序列用作方法的功能描述。
- 根据方法名称的词性(使用WordNet确定),添加默认的功能动词,如名词短语前加“get”,名称以“to”开头加“convert”,形容词前加“check”。
3.1.4 Conceptual Relation Completion.
这段文字描述了在API知识图中完成概念关系的各个步骤,以建立API元素与概念间及概念间的关系:
- API元素名称分析:
- 对于每个API元素(除方法外),视其为相应概念的实例,例如
java.io.File代表file概念的一个实例。 - 根据API元素的类型(包、类、接口、返回值、参数和字段),通过分割其简短名称(完全限定名后的部分)来提取对应的概念,如
org.json.JSONArray的概念是json array。 - 为每个这样获得的概念创建“实例类”关系。
- 对于每个API元素(除方法外),视其为相应概念的实例,例如
- API元素描述分析:
- 从API元素描述中提取名词短语,例如从“返回一个JSONObject,它是值”中提取“A JSONObject”和“the value”。
- 对提取的名词短语进行小写处理和词形还原,并移除短语开始的停用词。
- 将剩余的名词短语视为API元素描述中提到的概念,并在它们之间创建相应的“提及”关系。
- 概念名称分析:
- 分析概念名称,推断概念间的概念关系,如
json array与array之间的“是”关系。 - 根据概念名称间的派生、前缀或后缀关系添加概念间的关系,例如如果一个概念的名称是另一个概念名称的前缀,则添加“facet of”关系。
- 分析概念名称,推断概念间的概念关系,如
- API方法概念关系完成:
- 为了在API知识图嵌入中更好地反映方法间的概念关联,进一步创建方法与通过多跳关系间接连接的概念之间的直接关系。
- 根据方法的不同部分(如对象、输入值、输入类型和输出类型)建立方法和概念之间的直接关系。
3.2 API Knowledge Graph Embedding
在这一阶段,KGE4AR使用基于张量分解的知识图嵌入方法(ComplEx模型)来训练API知识图(KG)。以下是其关键步骤和目标:
- 嵌入模型的选择与训练:
- 使用ComplEx模型,这是一种基于张量分解的KG嵌入方法。该方法将API知识图中的所有实体(例如API元素、功能表达元素、概念)映射到一个高维向量空间中,使得具有相似结构、功能和概念关系的API元素在向量空间中位置接近。
- 模型训练以知识图中的关系三元组为输入,输出所有实体和关系的嵌入表示。训练的目标是让真实的三元组得分高于错误的三元组。
- 模型的技术细节:
- 使用复数空间的向量来支持反对称关系,每个实体和关系的嵌入都有实部和虚部。
- 使用公式 ϕ(h,r,t)=Eh×Er×Etϕ(h,r,t)=Eh×Er×Et 来计算每个关系三元组的得分,其中 h,r,th,r,t 分别代表头实体、关系类型和尾实体,Eh,Er,EtEh,Er,Et 是它们的嵌入。
- 大规模图的处理:
- 由于API知识图的规模较大(包含超过7200万实体和2.89亿关系),使用PyTorch-BigGraph(PBG)和GitHub上的实现来训练ComplEx模型。PBG是Facebook开发的一个分布式系统,专门用于在大规模图上训练知识图嵌入模型。
- 嵌入向量的存储与检索:
- 将所有知识图嵌入存储在向量数据库Milvus中,Milvus是一个开源的向量数据库,支持高效的向量索引和相似性搜索。这样可以高效地获取给定实体的嵌入,或找到给定嵌入的最相似实体。
- 可视化与分析:
- 通过主成分分析(PCA)降维后,展示了一些API方法在向量空间中的分布情况。同一库的API方法或类比库的方法在向量空间中相对靠近,而不同主题库的方法则相距较远。
3.3 Analogical API Method Inferring
在这一阶段,KGE4AR 通过分析给定源API方法与API知识图(KG)及其嵌入模型中的API方法之间的相似性,返回一组排序的类比API方法。这一过程分为两个步骤:候选API方法的检索和重新排序。
- 候选API方法检索:
- 首先通过查询向量数据库Milvus获取给定源API方法的KG嵌入。
- 然后计算给定方法与其他库中方法的KG相似性,选择相似性最高的前k个API方法作为候选。
- 候选API方法重新排序:
- 由于高KG嵌入相似性的两个API方法不一定是类比的,需要考虑给定API方法与候选API方法的邻居之间的相似性进行重新排序。
- 这包括功能相似性、对象相似性、输入类型相似性、输入值相似性、输出类型相似性和平均邻居相似性等多个方面。
- 通过对这些基于邻居的相似性进行加权求和,计算最终的类比得分。
这个过程的目的是缩小候选API的范围,并在较少的候选集中进行精确的相似度计算,从而有效地推荐功能和概念上与给定API方法类似的API。这种方法不仅考虑了API方法之间的直接相似性,还通过分析API方法的邻居来评估它们在更广泛的上下文中的关联性,从而更准确地识别出真正类比的API方法。
EVALUATION
API知识图的构建:
- 从35,773个Java库中收集数据,使用Libraries.io的数据集获取库的元数据,并从Maven Central Repository下载最新版本的JAR文件。
- 使用zipfile和JavaParser工具从JAR文件中提取API相关的文档,包括API定义和功能描述。
- 构建的API KG包含72,242,099个实体,其中包括59,155,631个API元素,5,210,925个功能元素,和5,660,553个概念。
知识图嵌入模型的训练:
- 使用ComplEx模型和逻辑损失函数训练KG嵌入模型。
- 在一个单独的验证设置中基于实验确定各种相似度权重,以避免过拟合,并在第4.3节中研究不同权重的影响。
RQ:
- **RQ1 (带目标库的有效性)**:探讨KGE4AR在有给定目标库的情况下,与现有基于文档的技术相比,推荐类比API方法的效果如何。
- **RQ2 (无目标库的有效性)**:研究在没有给定目标库的情况下,KGE4AR与现有基于文档的技术相比,在推荐类比API方法上的表现如何。
- **RQ3 (影响分析)**:分析KGE4AR中不同组件(如KG嵌入模型、知识类型及相似度类型和权重)如何影响系统的有效性。
- **RQ4 (可扩展性)**:考察随着库数量增加,KGE4AR的可扩展性表现如何。
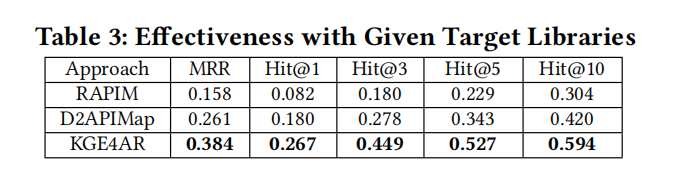
4.1 RQ1: Effectiveness with Target Libraries
这段文字讨论了在有给定目标库的情况下,KGE4AR在类比API推荐的有效性评估。
- 评估协议:
- 基准:合并了两个现有的手动验证的类比API对数据集,构建了一个大型基准,包含16对类比库中的245对API方法。
- 基线:选择了两种最新和最有效的基于文档的类比API推荐技术进行比较,RAPIM(监督学习)和D2APIMap(无监督学习)。
- 评估指标:使用MRR(平均倒数排名)和Hit@k(k=1, 3, 5, 10)作为常见的评估指标。
- 评估结果:
- KGE4AR在所有评估指标上显著超过两个基线方法,包括MRR和不同的Hit@k指标,显示出47.1%-225.6%的改进。
- KGE4AR在处理API功能描述时的分析方式可能是其性能优于基线的原因。例如,KGE4AR通过更细致地分析功能动词和功能类别,在重新排序阶段考虑方法的功能相似性,有效区分了具有相同名词短语但不同动词的API方法。
- 结论:
- KGE4AR在给定目标库的场景下推断类比API方法时,显著优于现有的基于文档的技术,表明其高效的功能描述分析和相似度计算方法在类比API推荐中的实际应用潜力。
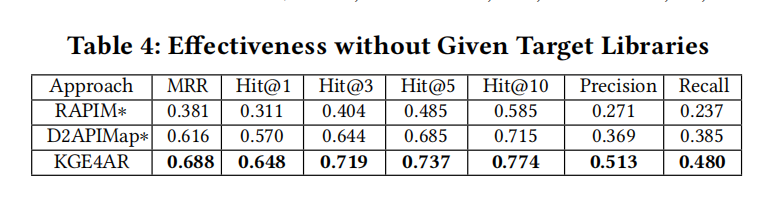
4.2 RQ2: Effectiveness without Target Libraries
在RQ2中,评估了在没有给定目标库的情况下,KGE4AR在类比API推荐上的有效性。此情况更具挑战性,因为正确选择目标库本身就是一个难题,现有自动目标库推荐方法的有效性有限。
协议与基准设置:
- 构建了一个新的基准,涵盖来自广泛库的类比API对,不局限于特定目标库。
- 选择了270个源API进行评估,这些API来自手动选择的9对类比库,包括流行和不那么流行的库。
- 对返回的API对进行了手动标记,以判断它们是否为类比API。
基线和评估指标:
- 对比了增强后的RAPIM∗和D2APIMap∗两个基线方法。这些方法在没有目标库的广泛候选API中,通过BM25信息检索技术首先缩小候选范围。
- 评估指标包括MRR、Hit@k(k=1, 3, 5, 10)、精度和召回率。
评估结果:
- KGE4AR在所有评估指标上均优于基线方法,显示出11.7%-116.5%的改善。
- 特别是在不太流行的库上,KGE4AR的表现提升更为显著,说明KGE4AR能够更好地通过知识图嵌入结合API的结构信息和功能描述来推断类比API。
结论:
- KGE4AR在没有给定目标库的场景下,有效地推断类比API,展示了其在处理广泛候选API和不同类型库上的优越性和通用性。
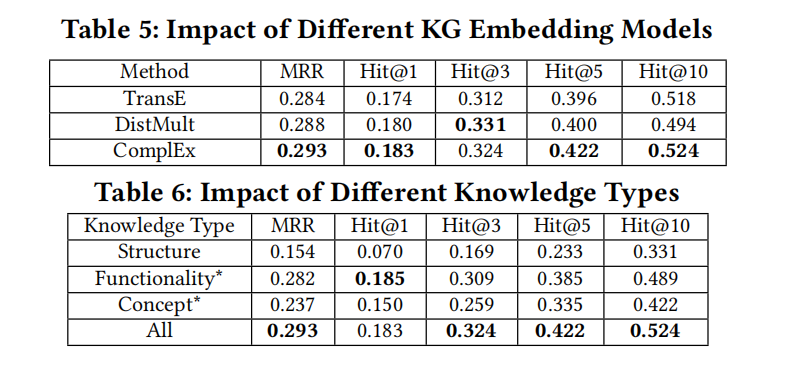
4.3 RQ3: Factor Impact
这段文字详细讨论了KGE4AR中各个组件对系统效果的影响,包括重新排序组件、知识图嵌入模型、知识类型、相似度类型和权重。以下是各个部分的主要内容:
- 重新排序组件的影响(4.3.1):
- 移除KGE4AR的重新排序步骤后,表现出显著下降的结果(如Hit@1下降50.2%),证明了重新排序步骤对于提高KGE4AR的有效性至关重要。
- KG嵌入模型的影响(4.3.2):
- 对比了ComplEx、TransE和DistMult三种嵌入模型。结果显示,ComplEx在所有评估指标上表现最佳,说明其适合用于KGE4AR。
- 知识类型的影响(4.3.3):
- 通过使用仅包含结构关系、排除功能关系、排除概念关系的不同关系三元组子集来训练不同的嵌入模型,评估了不同知识类型的影响。功能和概念知识均对类比API方法推断有积极贡献,其中概念知识的影响大于功能知识。
- 相似度类型和权重的影响(4.3.4):
- 通过使用Beam搜索调整重新排序步骤中相似度的权重,并对每种相似度进行了独立评估。结果表明功能相似度的移除导致了最大的性能下降(MRR下降22.9%),显示功能知识对于推断类比API方法的重要性。
- 而邻域相似度的移除在提高MRR的同时降低了Hit@10,表明邻域相似度虽然引入了一些噪声但提高了召回率。
总结来说,KGE4AR的设计选择(如重新排序步骤、嵌入模型、知识类型、相似度类型和权重)均对系统的有效性产生了积极贡献。同时,这些实验还揭示了进一步优化系统性能的潜在方向。
4.4 RQ4: Scalability
在RQ4中,研究了KGE4AR的可扩展性,分析了在线成本和离线成本。
- 在线成本:
- KGE4AR的在线推断时间对于单个查询少于一秒,主要包括候选API方法检索和重新排序两个步骤。
- 重新排序步骤的时间与候选数目成比例,并在确定候选后保持不变。
- 检索步骤的时间取决于API知识图的大小和所使用的向量数据库。使用了Milvus这一高效的向量索引机制,即使在API知识图规模增大的情况下,也能保持毫秒级的平均延迟,确保了检索步骤的高效执行。
- 离线成本:
- 讨论了不同规模API知识图的KGE4AR的离线成本。
- 数据显示,从小规模API知识图到大规模API知识图,实体数量增加了2,019倍,而收集输入数据、构建知识图和嵌入知识图的时间仅分别增加了386倍、121倍和40倍。
- 知识图的构建和嵌入只需执行一次,且当有新库时,知识图可以增量扩展。
CONCLUSIONS
这项工作提出了KGE4AR,一种新颖的基于文档的方法,利用知识图(KG)嵌入在库迁移过程中推荐类比API。特别地,KGE4AR提出了一个统一的API知识图,以全面且结构化地表示文档中的三种类型知识,这能更好地捕捉高层次的语义。此外,KGE4AR还建议嵌入这个统一的API知识图,使得相似度计算更加有效和可扩展。我们将KGE4AR实现为一种完全自动化的技术,为35,773个Java库构建了一个统一的API知识图。我们进一步在两种API推荐场景中评估了KGE4AR(即有给定目标库和无给定目标库的场景),我们的结果显示,在所有评估指标上,KGE4AR都显著优于现有的基于文档的技术。此外,我们还研究了KGE4AR的可扩展性,并发现KGE4AR能够随着库数量的增加而良好地扩展。