
Towards Generic Database Management System Fuzzing
Towards Generic Database Management System Fuzzing
USENIX Security 24 投稿中
ABSTRACT
数据库管理系统在现代网络空间中发挥着不可或缺的作用。近年来,已经提出了多种模糊测试框架来测试关系型(SQL)数据库管理系统以提高其安全性,而非关系型(NoSQL)数据库管理系统尚未得到同样的关注,且总体上缺乏有效的测试解决方案。在本研究中,我们识别了现有方法在扩展到有效模糊测试数据库管理系统时的三个局限性:非通用性、使用静态约束和生成松散的数据依赖性。随后,我们提出了有效的解决方案来应对这些局限性。我们将这些解决方案实现到一个端到端的模糊测试框架BUZZBEE中,该框架可以有效地模糊测试关系型和非关系型数据库管理系统。BUZZBEE在四种不同数据模型的八个数据库管理系统中成功发现了40个漏洞,其中25个已被修复,并分配了4个新的CVE。在我们的评估中,BUZZBEE在代码覆盖率方面比最先进的通用模糊测试工具高出最多177%,并在非关系型数据库管理系统中发现的错误数量比第二佳模糊测试工具多出30倍,同时在关系型数据库管理系统方面与专业的SQL模糊测试工具取得了可比的结果。
Introduction
Background and Related work:
- 数据库管理系统(DBMSs)在现代网络空间中扮演着不可或缺的角色,负责有效和高效地存储、检索和管理数据。
- 随着时间的推移,DBMSs的景观发生了显著变化,关系型(SQL)和非关系型(NoSQL)数据库相继出现,以满足各种应用领域的不同需求。
- 虽然关系型DBMSs已经被广泛研究和应用了几十年,但非关系型DBMSs如键值对DBMS、文档DBMS和图形DBMS由于其在处理大规模非结构化数据方面的灵活性和性能优势而近年来得到了广泛应用。
- 鉴于这些系统的普及和关键性,加强各种DBMSs的安全性和健壮性至关重要。
- 模糊测试是一种自动化的软件测试方法,通过向软件注入随机数据作为输入来发现其中的故障,在发现DBMSs中的错误方面已被证明是有效的。
- 然而,在针对非关系型DBMSs和关系型DBMSs的模糊测试工作方面存在差距。过去几年里,与关系型DBMSs相关的模糊测试框架和研究得到了广泛发展,有助于建立更安全可靠的关系型DBMSs系统。相比之下,非关系型DBMSs没有受到同样程度的关注。
- 最先进的通用模糊测试框架在应用于非关系型DBMSs时表现不佳,因为它们无法有效地生成触发DBMSs行为的测试用例。
- 因此,有必要开发一种能够测试关系型和非关系型DBMSs的有效解决方案。
第一篇测试非关系型数据库的文章!!! 也不太对啊,Graph DBMS不是被广泛讨论了吗
Challenges:
- 难以泛化:非关系型DBMSs的接口多样化,接受各种不同类型的输入,从键值对命令序列到JSON文档再到ASCII艺术形式表示的图案。这种接口的多样性在设计能够有效处理各种类型DBMS接口的通用框架时带来了独特的挑战,因为不同DBMS类别的接口语义可能差异巨大,使我们陷入了在促进测试用例质量和保持模糊测试器通用性之间的两难境地。
- 语义随上下文变化:语义可以根据上下文而改变。例如,在许多图形DBMSs中使用的图查询语言Cypher中,一个语法结构可以根据语法上下文要么定义一些数据,要么使用一些数据。同样,在键值对DBMS redis中,某些键的类型取决于上下文中指定的值。许多非关系型DBMSs的失败在于无法建模这种语义,导致产生语义不正确的测试用例,并且很难达到深入逻辑。
- 随机变异导致松散的数据依赖性:一些模糊测试器采用覆盖率作为反馈,但变异过程仍然是随机的,可能会浪费时间生成触发不太有效行为的测试用例,导致发现新覆盖率需要更长的时间。数据依赖性在有效的DBMS模糊测试中起着重要作用。没有数据依赖性,即使是语义正确的测试用例也可能表现出不太有效的行为。例如,一个测试用例连续创建相同的数据100次并不会触发DBMS更多的行为,而一个首先创建数据然后读取数据的测试用例,尽管它们都是语义正确的,却能触发更多的行为。
语义随上下文变化:
在许多图形数据库管理系统(DBMS)中使用的查询语言Cypher中,一个语法结构可以根据其上下文含义而变化。例如,考虑以下Cypher查询:
2
3
WHERE a.name = 'Alice'
RETURN b.name;在这个查询中,
:FRIEND表示两个人之间的友谊关系。然而,当我们改变查询的语义上下文时,:FRIEND的含义也可能会改变。例如,如果我们改变查询,要求返回“有共同朋友”的人:
2
3
WHERE a.name = 'Alice'
RETURN b.name;
Key insight:
- 对挑战进行系统分析:作者系统地分析了模糊测试非关系型DBMSs所面临的挑战,包括泛化困难、语义随上下文变化和数据依赖性等问题。
- 提出三种解决方案:作者提出了三种解决方案,分别是语义抽象、上下文敏感约束解决和依赖引导变异。
- 实现了端到端的模糊测试框架:作者将这些解决方案实现到了一个名为BUZZBEE的端到端模糊测试框架中,该框架能够有效地模糊测试关系型和非关系型DBMSs。
- 关键见解:该工作的关键见解在于通过对DBMSs语义的抽象和上下文敏感约束的处理,以及利用数据依赖性引导变异,有效地解决了模糊测试非关系型DBMSs时所面临的挑战,从而提高了测试用例的有效性和效率。
Evaluation and contributions:
作者通过在C++和Python中实现了一个名为BUZZBEE的模糊测试框架,总共约有9130行代码,并将其应用于8个DBMSs,包括关系型DBMSs和三种主流非关系型DBMSs:键值对DBMS、图形DBMS和文档DBMS。在对这些DBMSs进行评估后,发现了40个漏洞,其中25个已被修复,并分配了4个新的CVE。此外,作者将BUZZBEE与六种最先进的模糊测试框架进行了比较,发现BUZZBEE在发现新程序状态方面的性能提升高达177%,在与第二优秀的通用模糊测试工具相比,发现的漏洞数量高出30倍。
总的来说,作者的贡献包括:
- 系统地分析了模糊测试各种DBMS接口所面临的挑战,包括关系型和非关系型接口,提出了有效解决方案。
- 将解决方案原型实现为一个端到端的模糊测试框架BUZZBEE,使其能够有效地模糊测试关系型和非关系型DBMSs。
- 在四种数据模型的八个主流DBMS上进行了广泛的评估,BUZZBEE在测试的DBMSs中发现了40个漏洞。
https://github.com/OMH4ck/BuzzBee
Problem
2.1 Diverse DBMS Interfaces
- DBMSs暴露不同类型的接口来处理用户请求,其中包括:
- 关系型DBMSs通常接受SQL格式的输入,通过结构化查询语言进行数据操作。
- 非关系型DBMSs拥有更多样化的接口,与各种非关系型数据模型相关联,接受多种输入格式,包括命令序列、JSON文档和ASCII艺术形式。
- 根据用户输入如何进行处理,接口分为两大类别:
- 基于查询的接口:接受以查询语言形式的用户输入,例如SQL和Cypher,经过解析器和查询规划器处理后再进入查询执行阶段。
- 基于命令的接口:接受用户的一系列命令,并按顺序评估它们,尽管这些命令通常是独立执行的,但具有语义错误或不足的语义依赖性的命令序列仍可能触发较少的有效行为。
基于查询的接口:
- 示例:SQL查询语句
2
SELECT * FROM Users WHERE Age > 18;在这个例子中,SQL查询语句是一种基于查询的接口。用户通过使用SQL语句来查询数据库中年龄大于18岁的所有用户。这个查询会被DBMS解析器解析并进行语法和语义检查,然后由查询规划器生成一个优化的执行计划,最终执行查询并返回结果。
基于命令的接口:
- 示例:命令序列
2
3
4
SET Name = 'John';
SET Age = 25;
INSERT INTO Users (Name, Age) VALUES ('John', 25);在这个例子中,一系列命令被用来修改或插入数据库中的数据。每个命令独立执行,没有直接的查询语言参与。尽管这些命令通常是独立执行的,但它们的语义错误或不足的语义依赖性可能会导致触发较少的有效行为。
2.2 Existing Challenges and Limitations
Non-generic 非通用性: SQLsmith [44] 根据某些SQL DBMS的预定义模式信息生成随机SQL查询。SQUIRREL [56] 及其后续工作 [27, 28] 通过引入一种中间表示(IR),有效地结合了SQL的语法和语义,使其能够适应多个SQL数据库。然而,这些框架仍然需要非凡的采用努力才能支持一个新的关系型DBMS,如 [49] 中所提到的。此外,它们要么没有支持非关系型DBMS,要么由于模型设计的原因,根本无法支持它们。考虑到非关系型DBMS的广泛使用,我们缺乏一种通用的解决方案,能够高效地测试各种DBMS接口。
Static Constraint 静态约束:DBMS模糊测试中,变异很容易破坏测试用例的语义正确性。本文使用约束来表示测试用例应遵循的语义规则,以避免DBMS执行错误。这些约束包括范围约束和类型约束。范围约束限制了变量的可用范围,通常通过定义、使用和无效化等数据操作来执行。类型约束进一步限制了数据操作中变量的合法类型。

scope constraint
图1a: PostgreSQL例子
- 部分语法规则:
createtbl_stmt是定义”CREATE TABLE”语句的语法规则。tbl_name代表表名,并且其语法结构被定义在括号中。
- 测试用例:
CREATE TABLE t1(c1 date);这是一个创建名为t1的表的SQL语句。
- 约束绑定:
- 将”TABLE define”约束绑定到AST节点
tbl_name上。 - 在遍历AST时,当我们到达
tbl_name节点时,我们知道表t1已经被定义。
- 将”TABLE define”约束绑定到AST节点
图1b: Cypher例子
部分语法规则:
match_clause定义了Cypher中MATCH子句的语法规则。pattern_part和where_part是匹配部分和条件部分的语法规则。node_pattern定义了节点模式,其中包括标识符。
测试用例:
- ```
MATCH (n:L) WHERE (n)->[]->() RETURN n.x;1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
这是一个Cypher查询语句。
- `(n:L)` 定义了一个变量`n`,表示标签为`L`的节点。
- `WHERE (n)->[]->()` 表示匹配以`n`为起点的路径模式。
- `RETURN n.x` 返回节点`n`的属性`x`。
3. **约束绑定**:
- 如果将"variable define"约束绑定到标识符`identifier`的AST节点上,由于两次出现的`n`都是标识符类型,结果会将两个`n`都视为"variable define"。
- 实际上,当标识符在`pattern_part`节点的子树中时,它意味着"variable define"。当标识符在`where_part`节点的子树中时,它意味着"variable use"。
- 因此,静态范围约束无法正确地建模这种语义。
<font color='red'>type constraint</font>
**图1c: Redis命令**
这个例子展示了静态类型约束的问题。我们来看Redis命令:
1. **Redis命令解释**:
- `HSET k1 k1_field1 "Hello"`:将ASCII字符串“Hello”存储在键`k1`的字段`k1_field1`中。
- `HSET k2 k2_field1 "123"`:将数字字符串“123”存储在键`k2`的字段`k2_field1`中。
- `HINCRBY k1 k1_field1 1`:尝试将键`k1`的字段`k1_field1`的值增加1,但由于`k1_field1`存储的是ASCII字符串,因此操作失败,产生错误(值不是整数)。
- `DEL k2`:删除键`k2`。
- `HINCRBY k2 k2_field1 1`:尝试将键`k2`的字段`k2_field1`的值增加1,操作成功,返回值为124(数字字符串“123”加上1的结果)。
2. **问题说明**:
- Redis中,用户可以使用`HINCRBY`命令来增加由`HSET`创建的集合中的字段的值。然而,如果字段不包含数值,`HINCRBY`命令将会失败。
- 例如,第4行的`HINCRBY`命令尝试对`k1_field1`操作,但由于该字段预先定义的值是ASCII字符串而不是数字字符串,所以命令失败,没有触发值增加的逻辑。
3. **静态类型约束的问题**:
- 采用现有的方法,我们只能让`k1`的AST节点生成类型“HSET key”,让`k1_field1`的节点生成类型“HSET field”,这会丢失隐含的值信息,即`k1_field1`是一个ASCII字符串而不是数字字符串。
- 在不查看值(即字面量“Hello”和“123”)的情况下使用静态类型约束,会丢失建模语义所需的重要信息,导致无法正确处理语义
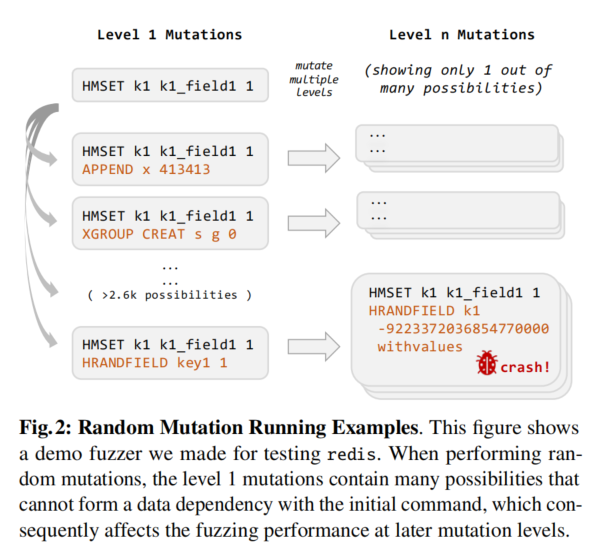
**Loose Data Dependencies 松散的数据依赖性**:现有的基于变异的DBMS模糊测试工具进行随机变异,并依赖代码覆盖率来探索更多程序行为。然而,随机变异在模糊测试非关系型DBMSs时可能浪费大量精力,因为它们倾向于生成松散的数据依赖性,触发稀薄且不太有效的行为。这一问题在接口包含许多非依赖性操作的情况下尤为明显,这在非关系型DBMSs(如Redis)中很常见。
图1c展示了一个实际的Redis命令例子,用于说明依赖性问题:
1. **Redis命令解释**:
- `HSET k1 k1_field1 "Hello"`:将ASCII字符串“Hello”存储在键`k1`的字段`k1_field1`中。
- `HSET k2 k2_field1 "123"`:将数字字符串“123”存储在键`k2`的字段`k2_field1`中。
- `HINCRBY k1 k1_field1 1`:尝试将键`k1`的字段`k1_field1`的值增加1,但由于`k1_field1`存储的是ASCII字符串,因此操作失败,产生错误(值不是整数)。
- `DEL k2`:删除键`k2`。
- `HINCRBY k2 k2_field1 1`:尝试将键`k2`的字段`k2_field1`的值增加1,操作成功,返回值为124(数字字符串“123”加上1的结果)。
2. **依赖性说明**:
- 第二个`HSET`命令与第一个`HSET`命令没有依赖关系,因为它们不能形成任何数据依赖性。
- 相反,第5行的`HINCRBY`命令与前两个`HSET`命令有依赖关系,因为它可以使用它们定义的数据,即`k1`、`k1_field1`、`k2`和`k2_field1`。
3. **随机变异的低效性**:
- 为了演示随机变异的低效性,我们实现了一个对Redis命令进行随机变异的模糊测试器,通过插入新命令或随机变异现有命令的参数来生成测试用例。
- 图2展示了变异过程。我们从Redis的官方测试套件中随机抽取了2643条命令作为变异源,每种命令类型最多抽取30条。命令在相同时会被去重(即共享相同类型和参数)。
4. **变异过程**:
- 模糊测试器从初始测试用例`"HMSET k1 k1_field1 1"`开始。
- 在第一轮变异(level 1)中,模糊测试器在`HMSET`命令下面插入一个新命令。在这一层,有2643个候选命令可供插入。然而,只有大约5.86%(155 / 2643)的命令与`HMSET`有依赖关系,可以使用`HMSET`定义的变量`k1`。其他变异(约占总数的94.14%)则较低效,因为它们不能利用现有数据(即它们要么操作不同的数据类型,要么根本不包含任何数据操作),因此将它们插入测试用例对探索更深层次的逻辑贡献不大。
5. **实际漏洞发现**:
- BUZZBEE发现的一个CVE(如图2所示)在处理`HRANDFIELD`命令的代码中,该命令需要数据依赖性来触发。随机模糊测试器更难找到这样的漏洞。
### **2.3 Our Insights and Solutions**
1. **语义抽象(Semantics Abstraction)**:
- 为了支持模糊测试多样化的DBMS接口,我们提出抽象语义,将大多数语义差异中和。
- 通过描述常见DBMS操作为三种基本数据操作:定义(Define)、使用(Use)和无效化(Invalidate),分别定义、使用或更新符号,并删除符号。
- 使用约束来限制高度抽象的语义,例如何时定义或使用、定义的符号类型或使用可以接受的类型等。
- 设计一个中间表示(IR)来结合输入的语法结构和抽象语义,并设计注释系统供用户指定语义约束,从而中和不同DBMS接口的语义差异,保持通用性。
2. **上下文敏感的约束解析(Context-sensitive Constraint Resolution)**:
- 为避免静态约束问题,启用基于上下文的动态约束。
- 为注释系统设计两个额外功能,让用户基于上下文指定约束。
- 设计了一个轻量级的领域特定语言(DSL),用户可以轻松查询常见的上下文信息,并提供接口让用户基于上下文编写复杂的语义规则,从而简便且有效地定制上下文敏感的规则。
3. **依赖引导变异(Dependency-guided Mutation)**:
- 为避免生成松散数据依赖性的测试用例,提出依赖引导变异。
- 变异器优先选择能够形成新数据依赖性的变异操作,偏向于与上下文中的现有数据相关联的操作。
- 例如,在变异创建了某些数据的测试用例时,变异器优先插入读取已创建数据的操作,而不是再次创建数据或与已创建数据无关的操作。
- 通过依赖引导变异,可以减少冗余工作和模糊测试器浪费的时间,提高模糊测试效率。
## Overview of BUZZBEE
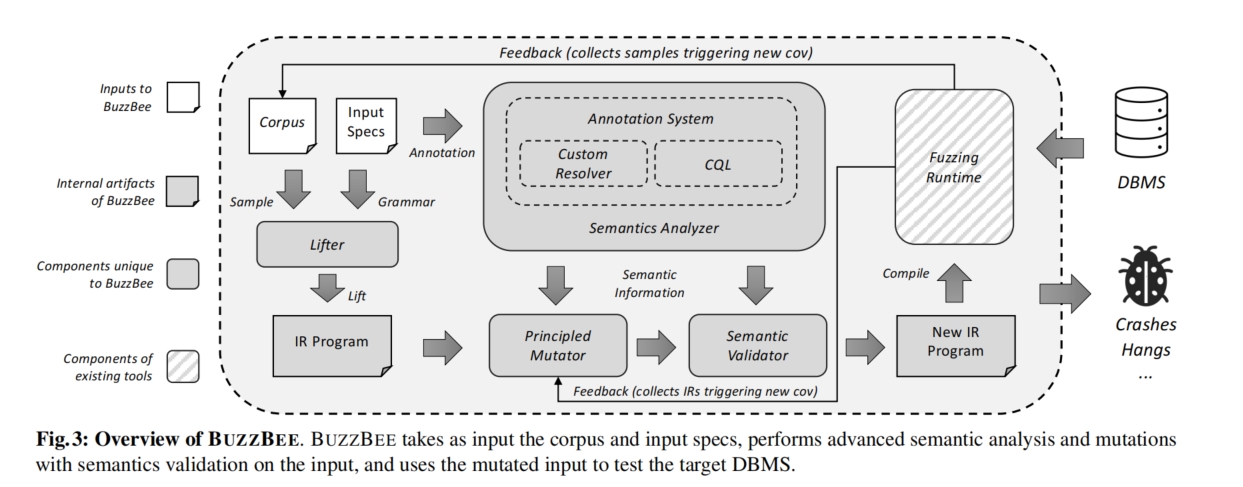
- **BUZZBEE框架简介**:
- BUZZBEE是一个端到端的模糊测试框架,旨在解决DBMS接口模糊测试的挑战。
- 输入包括目标DBMS接口的初始测试用例和输入规范(注释文件和语法文件)。
- 框架对测试用例进行变异,并使用变异后的测试用例测试目标DBMS。通过覆盖反馈,BUZZBEE持续尝试发现覆盖新程序状态的测试用例,并输出触发漏洞的测试用例。
- **框架组成部分**:
- **语法文件**:用户提供语法文件以描述目标DBMS接口的语法。
- **注释文件**:用户提供注释文件以限制目标DBMS接口的抽象语义。
- **语义分析**:BUZZBEE进行语义分析,并使用数据依赖性指导进行原则性变异。
- **语义验证**:BUZZBEE通过修复变异引入的错误来验证语义,并生成新的测试用例进行DBMS测试。
- **详细讨论**:
- 后续章节详细讨论了BUZZBEE组件的设计及其协作方式,分别解决通用性(第4节)、上下文敏感约束(第5节)和原则性变异(第6节)等三个挑战。
## **Generalization**
- **挑战**:变异容易破坏测试用例的语义正确性。BUZZBEE使用抽象语义模型来检查变异测试用例的语义正确性,并尝试在发送到模糊测试运行时之前修复语义错误。
- **语义抽象**:BUZZBEE通过三个基本数据操作(定义、使用和无效化)来抽象DBMS接口的语义,每个操作都与数据类型和名称相关联。
- **定义(Define)**:表示数据创建。例如,在Redis命令中,`HSET`命令定义了数据`k1`(类型为"HSET key")和`k1_field1`(类型为"HSET field of k1")。
- **使用(Use)**:表示对已定义数据的访问和更新。例如,`HINCRBY`命令使用了由`HSET`命令定义的数据`k1`和`k1_field1`。使用未定义数据被视为语义错误。
- **无效化(Invalidate)**:表示对已定义数据的删除操作。一旦数据被无效化,就不能再次使用。例如,如果删除了`k2`,其从属数据`k2_field1`也应被删除。
- **中间表示(IR)**:BUZZBEE设计了一个中间表示(IR)来承载用户指定的语法和语义信息。IR是一个树结构,与原始测试用例的抽象语法树一一对应,并捕捉用户指定的抽象语义。这样,BUZZBEE可以方便地将原始测试用例提升到IR中,进行语义分析、变异和验证,然后将IR编译回新的测试用例进行模糊测试。
- **IR结构**:IR结构的详细信息如图8所示,结合语法和语义信息,支持统一的语义分析和变异操作。
> 为了说明作者是如何通过抽象语义模型解决通用性问题,我们可以看以下简单的例子:
>
> #### 1. 定义(Define)操作:
>
> 假设我们有两个DBMS接口,一个是Redis,另一个是PostgreSQL。
>
> - 在Redis中,我们有以下命令:
>
- ```
HSET k1 k1_field1 “Hello”
2
3
4
5
6
7
这条命令定义了一个键`k1`及其字段`k1_field1`,值为ASCII字符串“Hello”。
在PostgreSQL中,我们有以下SQL查询:
- ```
CREATE TABLE t1 (c1 INT)这条查询创建了一个名为
t1的表,并定义了一个列c1,类型为整数。在BUZZBEE中,这两个操作都会被抽象为
Define操作。2. 使用(Use)操作:
接下来,我们对已定义的数据进行操作:
- 在Redis中,我们有以下命令:
这条命令尝试将键
k1的字段k1_field1的值增加1。在PostgreSQL中,我们有以下SQL查询:
- ```
INSERT INTO t1 (c1) VALUES (1)DEL k1
2
3
4
5
6
7
8
9
10
11
这条查询向表`t1`插入一行,列`c1`的值为1。
在BUZZBEE中,这两个操作都会被抽象为`Use`操作。
#### 3. 无效化(Invalidate)操作:
最后,我们对已定义的数据进行删除操作:
- 在Redis中,我们有以下命令:这条查询删除表
2
3
4
5
6
7
这条命令删除键`k1`及其所有字段。
在PostgreSQL中,我们有以下SQL查询:
- ```
DROP TABLE t1t1及其所有列。在BUZZBEE中,这两个操作都会被抽象为
Invalidate操作。中间表示(IR):
通过上述抽象,BUZZBEE可以创建一个通用的中间表示(IR),不论具体的DBMS接口如何,所有的操作都可以映射到
Define、Use和Invalidate这三种基本操作上。这样一来,BUZZBEE可以在不同的DBMS接口之间保持通用性。
Semantics Constraining
在对DBMS接口进行高层次建模之后,BUZZBEE使用约束来表达更丰富的语义。本文介绍了BUZZBEE如何为不同的DBMS接口实施灵活且轻量的上下文敏感语义约束。
- 注释系统(Annotation System):
- BUZZBEE首先通过CQL(Context Query Language)和自定义解析器(Custom Resolvers)驱动的注释系统接受用户针对不同DBMS接口的自定义语义信息。
- 语义分析器(Semantics Analyzer):
- BUZZBEE的语义分析器根据用户指定的语义信息分析(变异后的)测试用例,获取测试用例的语义。
- 语义验证器(Semantics Validator):
- 在将测试用例发送到模糊测试运行时之前,语义验证器会强制执行测试用例的指定语义约束。
5.1 Annotation System
为了处理不同DBMS接口之间的语义差异,BUZZBEE设计了注释系统,让用户在抽象语义模型中注释目标DBMS的语义。注释系统有两个目标:简洁性和表达力。
主要功能:
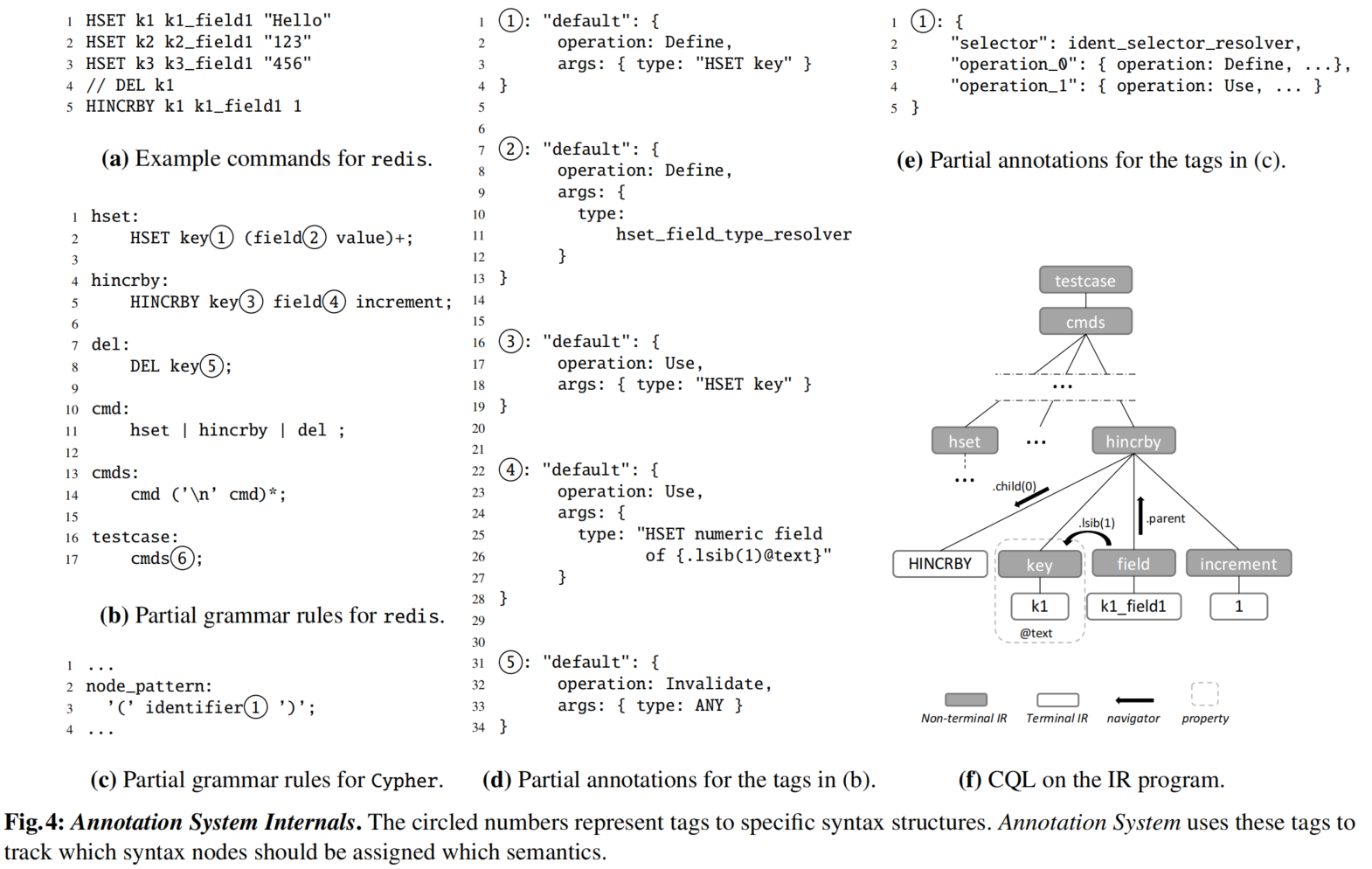
- 语法标签:
- BUZZBEE使用语法标签将语法结构和语义信息相关联。用户可以通过标记语法规则中的元素直接为AST节点分配语义。
- 示例:Redis的语法规则中,
key被标记为1,然后用户在注释文件中为该标记指定具体语义。
- 注释:
- 注释由多个条目组成,每个条目描述特定标记语法节点的语义,并包含操作和参数字段。
- 操作:指定要执行的抽象操作(定义、使用或无效化)。
- 参数:提供操作的具体参数,如数据类型。
- 上下文查询语言(CQL):
- BUZZBEE开发了一种轻量级查询语言CQL,用于在操作参数中直接查询上下文信息。CQL通过导航器和属性来指定要查询的上下文部分和信息。
- 示例:解析
HSET命令中k1_field1的数据类型时,CQL查询其左侧节点的文本(k1),从而确定其类型为HSET numeric field of k1。
- 自定义解析器(Custom Resolvers):
- 为支持更复杂的语义,BUZZBEE提供接口,让用户以高层次编程语言(如C++)编写自定义解析器。自定义解析器可以访问BUZZBEE的所有上下文信息,定制解析规则。
- 示例:解析
HSET命令中字段的类型时,自定义解析器hset_field_type_resolver首先检查字段值是否为数字字符串,然后获取关联的键的文本,并返回合适的类型。
主要步骤:
- 用户通过注释系统标注AST节点的基本语义属性(定义、使用或无效化),以及这些语义与输入上下文的关系。
- 语义分析器根据用户指定的语义信息分析(变异后的)测试用例,获取测试用例的语义。
- 语义验证器在将测试用例发送到模糊测试运行时之前,强制执行测试用例的指定语义约束。
5.2 Semantic Analysis and Validation
语义分析器
语义分析器负责在抽象语义模型中根据用户指定的约束检查语义正确性。它通过在IR程序上执行模拟执行来检查语义正确性,按照正确的顺序执行抽象语义操作。
分析阶段
- 依赖分析:
- BUZZBEE首先在执行任何操作之前对IR程序进行依赖分析。
- 它遍历每个操作,收集每个操作依赖的上下文,并据此构建依赖图。
- 然后对依赖图进行拓扑排序,给IR程序中的所有IR节点排序。
- 当两个IR节点没有任何依赖关系时,BUZZBEE根据IR程序的先序遍历顺序对它们进行排序。
- 通过这种方式,依赖分析可以输出IR程序中IR节点的安全且正确的执行顺序。
- 执行模拟:
- 一旦确定了正确的执行顺序,BUZZBEE就会通过执行语义操作来进行执行模拟。
- 对于
Define操作,BUZZBEE尝试在当前作用域中定义指定类型和名称的符号。 - 对于
Use操作,它尝试在作用域树中找到匹配指定类型和名称的符号,然后使用它。 - 对于
Invalidate操作,它执行与Use相同的操作,并使符号失效,以便不能再次使用。 - 在此过程中,语义分析器评估操作参数中使用的CQL查询,并在需要时调用自定义解析器以解析特定值。
- 期间,重新定义符号、定义前使用或失效后使用都会被视为语义错误。
- 如果操作依赖的上下文包含语义错误,该操作也将被视为语义错误。
- BUZZBEE维护符号表和作用域树以跟踪成功执行的操作(即没有语义错误的操作)。
语义验证器
语义验证器在BUZZBEE将测试用例发送到DBMS之前尝试修复测试用例中的语义错误:
- 对于定义前使用和失效后使用错误,它会找到另一个可用的数据进行使用。
- 对于重新定义错误,它尝试使用未定义的名称来定义数据。
- 当验证器无法修复错误时,BUZZBEE会丢弃该测试用例。
Principled Mutation
原则性变异
通过依赖引导变异,BUZZBEE减少了冗余工作并最小化了模糊测试器浪费的时间,从而提高了模糊测试效率。
变异过程
- 输入:
- 原则性变异器接收一个提升的IR程序作为输入。
- 查询语义分析器获取IR程序的依赖信息。
- 语义分析:
- 语义分析器对IR程序进行语义分析,检索符号和作用域信息,即哪些符号在何处和哪些作用域中定义。
- 语法正确的变异:
- 节点替换:将IR程序中的节点A替换为IR池中的另一个相同类型的节点B。
- 节点插入:将IR池中的节点B插入到IR程序中。
- 节点删除:删除IR程序中的一个节点(目前没有设计针对节点删除的引导)。
- 引导变异:
- 对于节点替换,首先获取在A处可用的符号集合S,然后在从IR池中随机选择B时,优先选择包含
Use或Invalidate动作且类型匹配的B。 - 节点插入遵循相同逻辑,寻找合适的B进行插入。
- 对于节点替换,首先获取在A处可用的符号集合S,然后在从IR池中随机选择B时,优先选择包含
- 优先级分配:
- BUZZBEE根据候选B在当前测试用例中是否已存在来优先选择。例如,在图4a中,如果
HINCRBY和DEL是仅有的包含Use和Invalidate动作的命令,那么BUZZBEE在第4行优先插入DEL而不是另一个HINCRBY,因为第5行已经有一个HINCRBY。 - 通过为语义动作分配权重来实现这一点,出现次数越多的动作被分配的权重越低。BUZZBEE根据权重随机选择一个动作,并从IR池中搜索包含该动作的B。
- BUZZBEE根据候选B在当前测试用例中是否已存在来优先选择。例如,在图4a中,如果
Evaluation
我们对BUZZBEE进行了评估,以回答以下问题:
- BUZZBEE能否适用于各种不同的DBMS接口(通用性和可移植性)?
- BUZZBEE能否发现实际存在的漏洞和安全隐患(有效性)?
- 每个提出的解决方案对BUZZBEE的性能有何贡献?
- BUZZBEE与最先进的工具相比表现如何?
8.1 Environment Setup
硬件
所有评估在运行Ubuntu 22.04.2 LTS的机器上进行,配置有两块AMD EPYC 7452 32核处理器和1,024GB RAM。
基准测试
我们在三种主流的非关系型DBMS(键值、图形、文档DBMS)和关系型DBMS(SQL DBMS)上评估BUZZBEE。选择基于它们的流行度和当前模糊测试运行时(AFL++)对C/C++目标的最佳支持。表5显示了评估中使用的DBMS,包括:
- 键值类:redis和KeyDB
- 图形类:RedisGraph和AgensGraph
- 文档类:MongoDB和ArangoDB
- 关系类:PostgreSQL和MySQL
实际漏洞检测评估
我们在选择目标的最新版本或开发分支上评估BUZZBEE,综合评估语义正确性、代码覆盖率和漏洞检测能力,选择了redis、ArangoDB、RedisGraph和PostgreSQL作为重点评估对象,因为它们表现出更高的模糊测试稳定性并覆盖所有四个类别。
工具比较
我们将BUZZBEE与支持所有四种DBMS类别的通用模糊测试工具(AFL++、REDQUEEN、POLYGLOT和Grammarinator)进行比较,以了解其通用性和有效性。还将BUZZBEE与成熟的SQL模糊测试工具(SQUIRREL和SQLANCER)进行比较,以进一步了解其处理关系型目标的能力。部分模糊测试工具不支持某些DBMS,详见表6。
评估设置
对所有评估的模糊测试工具提供相同的输入(如果需要),计算资源限制为一个CPU核心。对于漏洞检测评估,将DBMS回滚到所有漏洞未修复的版本。每次实验运行24小时,重复五次,并报告平均结果。
8.2 Generalizability and Portability
我们将BUZZBEE应用于八个真实世界的DBMS,以了解其在采用工作量方面的通用性和可移植性。具体操作如下:
- 语法和输入语料库收集:
- 从公开可用的资源(如官方文档页面、GitHub仓库或其他模糊测试工具的开源成果)中收集每个DBMS接口的语法和输入语料库。
- 注释添加:
- 手动为每个DBMS接口添加注释。
- 表2显示了为BUZZBEE收集的工件详细信息。注释工件的平均行数为123行。
- 注释编写:
- 由于BUZZBEE的高度抽象语义建模,大部分注释是简单的语义,如“语法中的节点A定义符号s”和“节点B可以使用符号s”,这些注释简单直观,由人工分析员编写。
- 对于熟悉每个DBMS的普通用户来说,平均不到一个小时就能为一个目标编写100行注释。
- 评估结果:
- 后续评估显示,这么少的采用工作量足以使BUZZBEE取得优异的模糊测试性能。
8.3 Real-world Bug Hunting
UZZBEE在我们测试的四类DBMS的八个DBMS中都发现了漏洞。除了PostgreSQL外,BUZZBEE在所有最新版本的DBMS中都发现了漏洞。完整的漏洞列表见附录表7。截至撰写本文时,BUZZBEE在最新的DBMS中发现了40个漏洞,其中38个已被供应商确认,25个已修复,4个分配了新的CVE ID。
8.4 Contributions of the Solutions3
为了了解每个解决方案对BUZZBEE的贡献,我们通过逐步关闭解决方案来比较BUZZBEE的三个变体:
- BUZZBEE!g:关闭依赖引导变异,使变异纯粹随机。
- BUZZBEE!gc:关闭BUZZBEE!g的上下文敏感约束解析,使所有CQL和自定义解析器返回静态值。
- BUZZBEE!gcs:完全去除BUZZBEE!gc的语义验证器,关闭整个注释系统。
我们在实际目标上评估这四个模糊测试器,并比较它们在测试用例语义正确性、覆盖率和漏洞发现能力方面的差异。
语义正确性
- 结果:BUZZBEE的语义正确率比其他模糊测试器高0.22到626倍。
- 原因:
- BUZZBEE!gcs的语义正确率最低,因为它不强制执行任何语义。
- BUZZBEE!gc通过强制执行语义(无上下文敏感性)提高了语义正确率。
- BUZZBEE!g引入上下文敏感性后,生成了更多语义正确的测试用例。
- BUZZBEE通过依赖引导变异进一步提高了语义正确率,因为它更倾向于形成数据依赖的变异操作。
覆盖率
- 结果:BUZZBEE在redis、RedisGraph、ArangoDB和PostgreSQL上的平均覆盖率分别比其他模糊测试器高29.2%、8.2%、22.6%和36.8%。
- 原因:
- BUZZBEE在redis上的表现最好,增加了35.5%的覆盖率,因为redis有更多无法形成数据依赖的操作。
- 其他DBMS接口包含更多的依赖关联操作,使得形成数据依赖变得更容易。
漏洞发现
- 结果:BUZZBEE在24小时内发现了12个漏洞,最多。
- 原因:
- BUZZBEE!g发现了8个漏洞,全部被BUZZBEE覆盖。
- BUZZBEE!gc发现了2个漏洞,因为它无法在没有上下文的情况下正确建模语义。
- BUZZBEE!gcs发现了1个其他版本未发现的漏洞,这是一个语义不正确的测试用例触发的漏洞。
分类漏洞
- 数据依赖性:BUZZBEE发现更多依赖数据关系的漏洞。
- 语义正确:BUZZBEE!g找到了一些语义正确但没有数据依赖关系的漏洞,BUZZBEE!gc则无法发现这些漏洞。
- 语法正确但语义不正确:BUZZBEE!gcs找到了一些语法正确但语义不正确的测试用例触发的漏洞。
8.5 Comparison with Existing Tools
在这一部分中,我们将BUZZBEE与现有的最先进的工具在代码覆盖率和漏洞检测能力方面进行比较。
比较工具
我们比较了BUZZBEE与以下模糊测试工具:
- 通用模糊测试器:AFL++ 和 REDQUEEN
- 语法感知模糊测试器:POLYGLOT 和 Grammarinator
- SQL 专用模糊测试器:SQUIRREL 和 SQLANCER
REDQUEEN不支持C/S程序,因此我们跳过了它在ArangoDB和PostgreSQL上的评估。POLYGLOT擅长模糊测试编译器,但由于其对上下文不敏感,无法有效建模DBMS接口的语义。Grammarinator生成随机程序,不进行覆盖率引导。SQLANCER最近增加了对ArangoDB的支持,因此我们也在ArangoDB上评估了它。
代码覆盖率
- 结果:BUZZBEE在所有目标上(除了PostgreSQL)达到了最佳的边缘覆盖率。
- 在redis、RedisGraph和ArangoDB上的覆盖率分别比第二好的模糊测试器POLYGLOT高69.2%、19.8%和76.9%。
- 在PostgreSQL上,BUZZBEE达到了最先进SQL模糊测试器SQUIRREL的92.7%代码覆盖率,表现出相当的能力。
- 在PostgreSQL上的语义正确率为9.8%,接近SQUIRREL的11.7%。
漏洞发现
- 结果:在六个现有模糊测试器中,只有POLYGLOT在redis中发现了一个漏洞(属于语法感知类别)。
- AFL++ 和 REDQUEEN在评估期间未发现任何漏洞。
- BUZZBEE、SQUIRREL和SQLANCER在最新版本的PostgreSQL中未能在24小时内发现漏洞。
- 回滚PostgreSQL到旧版本后,BUZZBEE发现了一个SQUIRREL和SQLANCER错过的已知漏洞。
- BUZZBEE在代码覆盖率上不如SQUIRREL和SQLANCER,但发现了一个涉及未建模语法结构的漏洞,展示了其在发现现有工具无法发现的实际漏洞方面的能力。