
When Fuzzing Meets LLMs: Challenges and Opportunities
When Fuzzing Meets LLMs: Challenges and Opportunities
ABSTRACT
这篇论文的摘要介绍了模糊测试(Fuzzing)和大型语言模型(LLMs)的结合。模糊测试是一种广泛使用的发现软件缺陷的技术,通过结合大型语言模型,这种技术得到了发展。尽管有潜力,但在模糊测试中应用大型语言模型还面临特定的挑战。本文确定了LLM辅助模糊测试的五大主要挑战,并通过回顾顶级会议的最新论文来支持我们的发现,确认这些挑战是普遍存在的。作为解决方案,我们提出了一些可行的建议,以帮助改进LLM在模糊测试中的应用,并对数据库管理系统的模糊测试进行了初步评估。结果表明,我们的建议有效地解决了这些已识别的挑战。
INTRODUCTION
这个章节介绍了模糊测试和大型语言模型(LLM)的结合如何被用于提高软件缺陷检测的有效性。具体内容概括如下:
模糊测试与LLM的结合: 描述了模糊测试作为软件缺陷检测的有前途的技术,以及LLM因其多功能性和能力在各种应用中迅速流行的情况。LLM在从自然语言处理到代码生成等多个领域的广泛应用,使其成为一个突出且受欢迎的解决方案。
LLM在模糊测试中的应用: LLM已经成为支持模糊测试核心过程的关键技术之一,包括驱动程序合成、输入生成和缺陷检测。
驱动程序合成
[28] Yunlong Lyu, Yuxuan Xie, Peng Chen, and Hao Chen. 2023. Prompt Fuzzing for Fuzz Driver Generation. arXiv preprint arXiv:2312.17677 (2023).
[39] Cen Zhang, Mingqiang Bai, Yaowen Zheng, Yeting Li, Xiaofei Xie, Yuekang Li, Wei Ma, Limin Sun, and Yang Liu. 2023. Understanding large language model based fuzz driver generation. arXiv preprint arXiv:2307.12469 (2023).
输入生成
[9] Arghavan Moradi Dakhel, Amin Nikanjam, Vahid Majdinasab, Foutse Khomh, and Michel C Desmarais. 2023. Effective test generation using pre-trained large language models and mutation testing. arXiv preprint arXiv:2308.16557 (2023).
[10] Victor Dantas. 2023. Large Language Model Powered Test Case Generation for Software Applications. (2023).
缺陷检测
[11] Yinlin Deng, Chunqiu Steven Xia, Haoran Peng, Chenyuan Yang, and Lingming Zhang. 2023. Large language models are zero-shot fuzzers: Fuzzing deep-learning libraries via large language models. In Proceedings of the 32nd ACM SIGSOFT international symposium on software testing and analysis. 423–435.
[17] Ali Reza Ibrahimzada, Yang Chen, Ryan Rong, and Reyhaneh Jabbarvand. 2023. Automated Bug Generation in the era of Large Language Models. arXiv preprint arXiv:2310.02407 (2023).
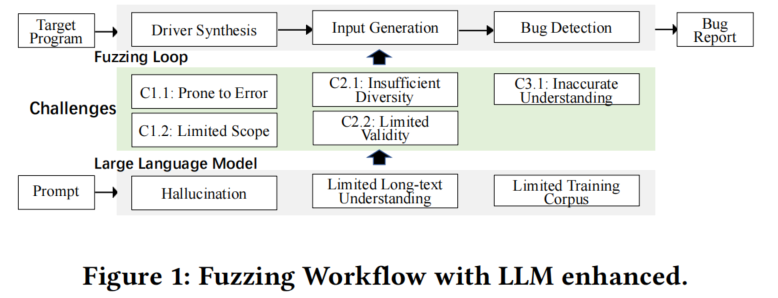
LLM面临的挑战: 尽管LLM在自然语言分析方面表现出色,但在复杂程序分析中显示出一些常见的缺点,如有限的上下文长度和幻觉问题,这些问题影响了模糊测试的有效性,导致测试性能下降,表现为高假阳性、低测试覆盖率和有限的可扩展性。
使用LLM进行模糊测试的五个常见挑战:
- 输出质量低下,缺乏有效缺陷检测所需的精确度。
- 模型在理解和处理能力上的局限性。
- 在模糊测试过程中生成足够多样化输入的困难。
- 维持生成输入的有效性的挑战。
- LLM对缺陷检测机制的理解不准确,限制了它们在识别和解决复杂软件漏洞方面的有效性。
实证调查与初步评估: 通过回顾依赖LLM处理模糊测试问题的最新工作,发现这些工作中每一个都至少遇到了上述挑战之一。此外,还进行了一些初步评估,通过在模糊测试数据库管理系统中应用LLM,展示了合理实施这些建议能够克服在LLM辅助的DBMS模糊测试中的挑战。
整体来看,这部分强调了LLM在模糊测试中的潜力和挑战,并提出了一些改善建议和初步的成功应用案例。
CHALLENGES AND OPPORTUNITIES
尽管LLM取得了巨大的成功,但LLM在模糊化中的应用往往容易出现几个问题,从演绎精度到适应可伸缩性。忽略这些问题可能会导致种子质量差或忽略关键的缺陷,从而导致有限的模糊性能。在本节中,我们总结了在模糊过程中应用LLM时通常发生的五个挑战。虽然这些挑战一开始可能看起来很简单,但它们通常源于模糊过程中常见的小缺点。
Driver Synthesis
这个章节讨论了使用大型语言模型(LLM)来增强驱动程序合成的方法、面临的挑战和建议的解决策略。以下是详细概括:
- 驱动程序合成的描述:
- 利用LLM使用API文档作为上下文提示,生成API调用序列,用作模糊测试的驱动程序。
- 提到了一些特定的工具,如TitanFuzz和PromptFuzz,它们设计了定制的提示模板来引导LLM生成符合编程语法和语义的代码。
- 面临的挑战:
- 直接使用LLM进行驱动合成可能会导致效率不高,因为LLM容易产生幻觉并且在未包括在其训练语料库中的程序上表现不佳。
- 这些限制导致两个主要挑战:合成的驱动程序易出错,导致模糊测试期间的假阳性数量显著;LLM对未见过的程序知识有限,有时会生成错误的API调用序列。
- 建议:
- REC 1.1: 对于已包含在训练语料库中的目标代码或用例,使用LLM自动合成模糊驱动程序,并通过错误引导的纠正措施来补充,这是一种实用的方法。例如,对于libpng库,可以直接让GPT-4根据给定的提示生成模糊测试驱动程序,但可能还需要通过提交错误消息进行多次迭代查询来纠正错误。
- REC 1.2: 对于没有专门语料库的目标,可以收集如函数原型、示例程序或函数间的连接规则等宝贵资料。通过嵌入这些资料进行提示工程,可以提高生成函数调用逻辑序列的准确性。
- REC 1.3: 即使有足够的文档和示例,LLM有时也可能在生成有效驱动程序方面遇到挑战,特别是对于如Linux内核这样极其复杂的目标。对于这些目标,建议不依赖LLM,而是探索传统方法。例如,KSG通过动态推断内核的系统调用参数类型和值约束,与基于内核手册页和源代码的静态推断方法相比,生成的Syzlang数量显著多于KernelGPT。
SQL语法较为简单,大模型应该不会遇到这些问题
Input Generation
这个章节讨论了利用大型语言模型(LLM)增强输入生成的方法、面临的挑战和提出的解决策略。以下是详细概括:
- 输入生成的描述:
- 介绍了使用LLM根据输入规范和示例来生成新输入的先导工作,例如LLMFuzzer使用输入规范让LLM生成变异型模糊器的初始种子。
- 面临的挑战:
- 直接使用LLM进行输入生成可能会导致效率低下,因为LLM严重依赖训练语料库并且对长文本理解有限。这导致生成的输入缺乏多样性和有效性。
- LLM通常不能生成足够多样化的输入,难以充分探索输入空间,举例说明了在RTPS协议模糊测试中的限制。
- 生成的输入往往有效性有限,可能导致目标程序在执行这些输入时提前终止,如在处理复杂的Border Gateway Protocol(BGP)时的限制。
- 建议:
- REC 2.1: 对于在网络上有大量示例并且已包含在LLM训练语料库中的测试输入,可以直接使用LLM生成测试用例,并结合多样化方法。这些方法包括精心设计的提示和覆盖引导的遗传算法等,以增加输入的多样性。例如,在测试常见的文本协议如HTTP和FTP时,可以使用多种HTTP方法、不同的头部、查询参数和URL结构来增加多样性。
- REC 2.2: 在很多情况下,LLM没有针对测试对象专门训练的语料库。建议使用LLM将已知的知识转换为输入规范或构建初步的测试用例。例如,对于缺乏机器可读语法的协议实现,利用LLM已经训练过的协议,转移这些协议的语法来增强生成测试用例的有效性,并可以使用传统的基于语法的模糊器来生成更多测试用例。还可以将流行数据库系统的SQL查询转换为测试数据库系统的初步种子,增强生成测试用例的多样性。

Bug Detection
这个章节探讨了使用大型语言模型(LLM)增强缺陷检测的方法、面临的挑战和提出的解决策略。以下是详细概括:
- 缺陷检测的描述:
- 描述了一种通过使用目标程序的功能描述作为提示上下文,请求LLM生成与目标程序实现相同功能的代码的方法。通过比较两个功能等效程序的执行结果,可以检测目标程序中的逻辑错误。
- 例如,Differential Prompting通过询问LLM提供的代码的意图,然后使用获取的意图作为新的提示上下文,让LLM生成具有相同意图的代码。
- [21] Siva Kesava Reddy Kakarla and Ryan Beckett. 2023. Oracle-based Protocol Testing with Eywa. arXiv preprint arXiv:2312.06875 (2023).
- [25] Tsz-On Li, Wenxi Zong, Yibo Wang, Haoye Tian, Ying Wang, Shing-Chi Cheung, and Jeff Kramer. 2023. Nuances are the Key: Unlocking ChatGPT to Find Failure Inducing Tests with Differential Prompting. In 2023 38th IEEE/ACM International Conference on Automated Software Engineering (ASE)*. IEEE, 14–26.
- 面临的挑战:
- 直接使用LLM进行缺陷检测可能会因为LLM对长文本理解有限而导致效果不佳,可能会误解目标程序的语义。例如,研究发现LLM可能会将寻找最长公共子串的代码误解为寻找最长公共子序列,这种误解会导致生成的代码功能与目标程序偏离,从而导致测试标准不准确。
- Differential Prompting在生成编程比赛网站Codeforces程序的参考实现时,成功率为66.7%,但误报率为33.3%,这对实际使用来说还不够。
- 建议:
- REC 3.1: 对于复杂的目标,建议避免直接用LLM分析结果。相反,可以考虑使用LLM提取与特定错误类型相关的特征或模式,并利用领域知识。然后,使用这些模式监控系统,帮助解决理解不准确的挑战。例如,在分析时间序列数据库(如IoTDB)的日志时,可以利用LLM识别错误模式,进而检测逻辑错误。
- REC 3.2: 对于文档定义明确、预期行为清晰描述的目标或项目,建议利用LLM的自然语言理解能力从文档中提取预期行为来定义测试标准。这有助于LLM理解目标程序的意图和设计,从而解决理解不准确的问题。例如,使用Telnet协议的RFC 854作为测试标准,可以进一步用来揭示CVE-2021-40523等问题。
POTENTIAL SOLUTIONS
为了证明我们的建议的实用性,我们使用数据库管理系统(DBMS)作为llm辅助模糊化的目标。为了解决驱动程序合成、输入生成和bug检测方面的挑战,我们提出了三种潜在的解决方案:状态感知的驱动程序合成、跨dbms SQL传输和基于日志的Oracle定义。这些解决方案被实现,并与直接使用LLM的基本使用进行了比较。实验是在一台256核(AMD EPYC 7742处理器@ 2.25 GHz)和512 GiB的机器上进行的,证明了我们推荐的方法在增强基于llm的模糊处理,如DBMSs等复杂系统方面的有效性。
LLM-Enhanced Connector Synthesis
这个章节探讨了如何使用大型语言模型(LLM)来增强数据库连接器的驱动程序合成,其面临的挑战以及提出的解决方案。以下是详细概括:
- 挑战:
- 使用LLM直接生成数据库连接器的驱动程序会面临两个主要挑战:容易出错和范围有限。API序列包含嵌入在数据库连接器状态中的语义信息,直接生成序列可能会引入错误。此外,由于缺乏相关的训练语料库,LLM缺乏连接器的状态转换知识。
- 解决方案:
- 根据建议REC 1.2,提出了一种LLM增强的状态感知数据库连接器合成方法。首先收集JDBC函数原型和使用JDBC的示例程序,然后建模JDBC函数之间的连接关系作为状态转换规则。接着,将函数原型、示例程序和连接规则作为LLM的输入。给定的提示是:“基于状态转换规则和函数的状态描述,请生成一个长度为15的API序列,要求覆盖以前不同的状态转换组合。”
- 结果:
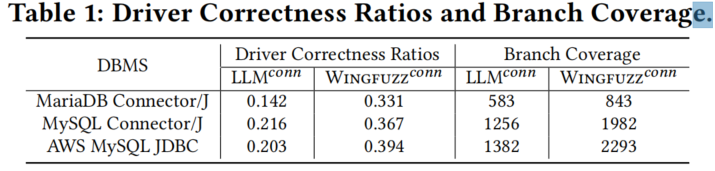
- 实现了LLM增强的连接器合成在Wingfuzz𝑐𝑜𝑛𝑛中,并与直接使用LLM生成驱动程序的LLM𝑐𝑜𝑛𝑛进行比较,比较对象包括MySQL Connector/J、MariaDB Connector/J和AWS JDBC Driver for MySQL。在对ClickHouse进行模糊测试后,结果显示Wingfuzz𝑐𝑜𝑛𝑛在驱动程序正确率和分支覆盖率方面均优于LLM𝑐𝑜𝑛𝑛。具体来说,Wingfuzz𝑐𝑜𝑛𝑛在驱动合成的正确率提高了94%,生成的驱动程序平均覆盖了更多56%的分支。这主要是因为状态转换规则嵌入了语义信息,帮助LLM生成考虑到数据库连接器多样状态的API序列。
Cross-DBMS SQL Transfer
这个章节探讨了使用大型语言模型(LLM)进行跨数据库管理系统(DBMS)的SQL传递的方法、面临的挑战以及提出的解决策略。以下是详细概括:
- 挑战:
- 使用LLM直接生成SQL查询会面临两个主要挑战:确保语义正确性和提升查询多样性。语义正确的SQL查询对于触发复杂的DBMS行为至关重要,而SQL的复杂语法对LLM实现语义正确性构成挑战。此外,由于缺乏DBMS反馈,LLM在探索多样化查询结构方面受到限制。
- 解决方案:
- 为了克服这些挑战,介绍了一种与建议REC 2.2相符的跨DBMS SQL传递方法。与直接生成SQL查询相比,该方法使用LLM将其他DBMS的测试用例转移作为目标DBMS模糊测试的初始种子。这些初始种子在模糊测试循环期间用于突变新的SQL测试用例。此过程包括三个关键步骤:首先,在其原生DBMS中执行现有的SQL测试用例以捕获执行期间的模式信息;其次,利用LLM和捕获的模式信息引导新测试用例的生成;最后,为了确保适当的解析,临时注释掉无法解析的部分,并在突变后取消注释。
- 结果:
- 实施了名为Wingfuzz𝑖𝑛𝑝𝑢𝑡的解决方案,并与直接使用LLM生成SQL查询的LLM𝑖𝑛𝑝𝑢𝑡进行比较。在三个DBMS(MonetDB、DuckDB和ClickHouse)上运行这两个工具。结果显示,Wingfuzz𝑖𝑛𝑝𝑢𝑡在DBMS模糊测试方面的表现优于LLM𝑖𝑛𝑝𝑢𝑡。具体来说,Wingfuzz𝑖𝑛𝑝𝑢𝑡生成的测试用例包含更多的语义正确的SQL语句,并覆盖了更多的代码分支。这表明LLM不能直接生成高质量的SQL查询作为DBMS模糊测试的输入,转移种子提高了突变测试用例的多样性,并且模糊器的突变器保证了SQL查询的语义正确性。
Monitor-Based DBMS Bug Detection
这个章节探讨了使用基于运行时监控的DBMS缺陷检测方法、面临的挑战以及提出的解决策略。以下是详细概括:
- 挑战:
- DBMS缺陷检测中最关键的步骤是构建测试标准(test oracle)来识别DBMS中的逻辑或性能缺陷。直接使用LLM构建测试标准面临挑战,因为LLM缺乏关于DBMS复杂工作和行为的具体知识,并且无法访问内部逻辑,难以准确预测或模拟DBMS行为。
- 解决方案:
- 为了应对这些挑战,提出了基于运行时监控的DBMS缺陷检测方法,该方法通过实时分析DBMS的运行时信息来检测异常。该方法不是直接使用LLM通过检查SQL查询的执行结果来构建测试标准,而是收集DBMS的运行时信息,并使用LLM分析这些信息以检测缺陷。该过程包含两个主要步骤:首先,部署一个代理来提取DBMS的运行时信息;然后,收集这些信息并使用LLM预定义一些错误模式来检测异常。
- 结果:
- 为了评估我们的建议的有效性,实施了名为Wingfuzz𝑏𝑢𝑔的解决方案,并将其与直接使用LLM在模糊测试循环中判断SQL查询执行是否正确的LLM𝑏𝑢𝑔进行比较。结果显示,Wingfuzz𝑏𝑢𝑔可以检测到更多异常,并且比LLM𝑏𝑢𝑔有更少的误报。具体来说,LLM𝑏𝑢𝑔共报告了182个缺陷,但只有1个是真实的缺陷。相比之下,Wingfuzz𝑏𝑢𝑔报告了14个缺陷,其中9个被确认为真实的缺陷。主要原因是收集到的运行时信息包含了DBMS的错误消息,这有助于LLM分析和检测缺陷。