
Testing Graph Database Systems via Equivalent Query Rewriting
Testing Graph Database Systems via Equivalent Query Rewriting
ABSTRACT
图数据库管理系统(GDBMS)利用图模型进行数据存储,并通过图遍历执行查询,在推荐系统、知识图谱和社交网络等实际场景中被广泛使用。与关系数据库管理系统(RDBMS)类似,GDBMS也不免于出现错误。这些错误通常表现为逻辑错误导致的结果不正确(例如,漏掉应包含的节点)、性能错误(例如,由冗余图扫描导致的长执行时间)和异常问题(例如,意外或缺失的异常)。
本文将等价查询重写(EQR)技术应用于GDBMS测试。EQR将GDBMS查询重写为触发不同查询计划的等价查询,并检查它们是否在系统行为上存在差异。为了实现EQR,我们提出了一个称为抽象语法图(ASG)的通用概念。其核心思想是将基本查询的语义嵌入到图的路径中,这些路径可以用于生成具有自定义属性(例如等价性)的新查询。给定一个基本查询,构建一个ASG,然后通过找到集体携带基本查询完整语义的路径生成等价查询。为此,我们进一步设计了随机游走覆盖(RWC)算法,这是一个简单而有效的路径覆盖算法。作为这些想法的实际实现,我们开发了一个名为GRev的工具,成功检测到了5个流行的GDBMS中的22个先前未知的错误,其中15个得到了确认。特别是,其中14个检测到的错误与GDBMS中图数据检索的不当实现有关,这对于现有技术来说是很难识别的。
INTRODUCTION
Background:
- **图数据库管理系统(GDBMS)**:GDBMS是为了存储和执行图结构化数据查询而设计的系统。与关系数据库管理系统(RDBMS)不同,后者将数据存储在表和列中,而GDBMS使用节点和边的图模型来维护数据,表示实体及其关系。
- 功能与用途:GDBMS提供强大的图遍历和模式匹配功能,允许对相互关联的数据进行灵活高效的查询。这些特性使得GDBMS在推荐系统、知识图谱和社交网络等数据驱动应用中非常有用和高效。
- 示例和普及程度:例如,Facebook使用自己的GDBMS TAO来存储和管理社交网络中数十亿用户及其关系。根据DB-Engines Ranking,有51种广泛使用的GDBMS,如Neo4j、TinkerGraph、MemGraph和NebulaGraph等。
- Bug的存在:与其他软件一样,GDBMS也存在各种类型的错误,包括逻辑错误导致查询结果不正确、性能错误导致查询执行时间不佳或甚至长时间挂起,以及异常问题(例如,意外和缺失异常)。
- 错误类型:这些错误可能出现在GDBMS的各种功能中,包括与图数据检索相关的错误(例如,图模式匹配)和与RDBMS类似的功能相关的常见错误(例如,谓词)。
- 示例:文章列举了一个在RedisGraph中检测到的图相关逻辑错误的例子,表明了GDBMS中可能存在的错误。
Challenges:
不同的查询语言:与RDBMS统一使用SQL访问数据不同,不同的GDBMS采用不同的查询语言,如Neo4j的Cypher、TinkerGraph的Gremlin和NebulaGraph的nGQL。这使得现有的差异测试工具只能测试采用相同查询语言的GDBMS的共享功能,如Neo4j的标签表达式功能。而且,采用不同的查询语言可能导致工程化工作量巨大,当开发人员试图将现有工具推广到更多的查询语言时。因此,现有研究主要关注Cypher和Gremlin这两种查询语言。

RDBMS测试方法的转化:将RDBMS的测试方法应用于GDBMS是非常困难的,因为它需要在不同的数据库模型和查询语言下重新实现。此外,这种适应性只能测试RDBMS和GDBMS之间的共享功能(如表达式和谓词),而未能充分探索图相关的错误。现有的元测试方法,如GDBMeter,尽管发现了与谓词处理相关的常见错误,但报告的错误都与图相关。

同年 ICSE24也有一篇:https://linli1724647576.github.io/2024/03/01/Detecting-Logic-Bugs-in-Graph-Database-Management-Systems-via-Injective-and-Surjective-Graph-Query-Transformation/ 将RDBMS的蜕变测试运用到GDBMS的
性能错误的忽视:现有方法没有充分考虑GDBMS中的性能错误。差异测试方法,如GDsmith和Grand,无法检测性能错误,因为不同GDBMS的不同底层架构很容易导致性能差异。而基于元测试的方法,如GDBMeter,基于原始查询和三个子查询之间的关系,这些子查询并不显示清晰的性能关系。因此,现有方法很难发现性能错误。

Key ideas:
- 等价查询重写(EQR):本文将等价查询重写技术应用于GDBMS测试中。通过将查询重写为等价形式,如果返回的结果不同或查询时间差异较大,则可能发现潜在的错误。这种方法可以帮助发现不同GDBMS中的潜在错误,而无需对不同的查询语言进行硬编码的规则重写。
- 抽象语法图(ASG):为了实现在GDBMS中的等价查询重写,提出了一个新颖且广泛适用的概念,即抽象语法图(ASG)。ASG将基本查询的完整语义嵌入到图的路径中,从而可以自动地覆盖图中的不同路径集合,生成具有自定义属性(例如等价性)的查询。ASG为查询提供了一个抽象,可以映射到不同GDBMS和它们的查询语言所采用的各种具体图模型中。
- 随机游走覆盖(RWC):为了找到ASG中嵌入的完整语义的等价查询,提出了一个简单而有效的算法,即随机游走覆盖(RWC)。RWC可以生成大量的等价查询,触发多样化的查询计划,有效地对GDBMS进行压力测试。与传统的查询重写技术不同,这种方法不需要依赖多个硬编码的规则,也不需要领域专家对查询语言进行额外的工程资源开发。
- 易于适应不同的查询语言:ASG和RWC可以轻松地适应不同的查询语言,只需要进行轻量级的解析器开发,而传统的查询重写方法需要重新识别变异规则以符合不同的查询语言语法。
实现、评估和贡献:
- 实现工具GRev:作者将提出的想法实现为一个名为GRev的工具。这个工具被用来测试了五种流行的GDBMS,包括Neo4j、RedisGraph、MemGraph、TinkerGraph和NebulaGraph。这些系统共同采用了三种不同的查询语言:Cypher、Gremlin和nGQL。
- 测试结果:在测试过程中,GRev发现了这些GDBMS中的22个先前未知的错误,其中包括14个与图相关的错误,其中15个得到了确认。这些错误包括逻辑错误、性能错误、缺失异常和意外异常等。
- 贡献:
- 将等价查询重写(EQR)技术应用于GDBMS测试。
- 提出了抽象语法图(ASG)的概念,将查询的完整语义编码到图中。
- 设计了一个简单而有效的算法随机游走覆盖(RWC),用于从ASG生成等价查询。
- 实现了这些想法并开发了GRev工具,成功地用于测试了5种广泛使用的GDBMS,并成功检测到22个先前未知的错误,其中15个得到了确认,14个与图相关。
BACKGROUND
2.1 Labeled Property Graph in GDBMS
大多数图数据库管理系统(GDBMS)采用带标签属性图(LPG)来存储和查询数据。LPG包含节点(例如n1、n2和n3)、关系(例如r1和r2)、对应的标签(例如n1:person和r1:read)以及每个节点和关系的属性(例如name:Alice)。这种灵活的图结构可以有效地捕捉关于实体、关系和属性的相互连接的信息,而关系数据库管理系统(RDBMS)则使用多个表来存储此信息。由于其灵活性和有效性,LPG模型已成为GDBMS的重要组成部分。
2.2 Query Languages in GDBMS
与关系数据库管理系统(RDBMS)利用SQL来创建、修改和检索数据不同,图数据库没有标准化的查询语言。相反,为了满足不同应用需求,为不同的GDBMS开发了多种查询语言。例如,Cypher是一种流行的类SQL查询语言,使用类SQL的子句(如MATCH、WHERE和RETURN)来检索数据。另一方面,Gremlin是一种广泛使用的函数式查询语言,以数据流的方式表达查询。根据DB-Engine排名,前10名的GDBMS中有6个支持Gremlin或Cypher作为其查询语言。因此,我们主要实现了针对Cypher和Gremlin为主的GDBMS的EQR。此外,我们还测试了使用其自己语言nGQL的NebulaGraph,以进一步验证我们方法的有效性和通用性。
同年 ICSE24也有一篇:https://linli1724647576.github.io/2024/03/01/Detecting-Logic-Bugs-in-Graph-Database-Management-Systems-via-Injective-and-Surjective-Graph-Query-Transformation/ 也支持了Cypher 和 Gremlin,看看这篇工作是如何支持的,解决他的第一个挑战?
2.3 Query Rewriting
查询重写在关系数据库管理系统(RDBMS)中是查询优化的关键步骤,主要目的是将原始查询转换为等效但更有效的形式,以加速执行。这种转换是通过一组硬编码的重写规则实现的,这些规则通过生产规则引擎进行选择和应用,显著提高了查询执行的效率。虽然受到查询重写的启发,但我们的EQR追求的是不同的目标,即自动生成大量的具有多样化查询计划的等价查询,而无需任何硬编码的规则。此外,在数据库领域探索的现有查询重写规则不能用于GDBMS测试,因为大多数查询重写研究集中在RDBMS上,并且在GDBMS中缺乏类似的技术。与之不同的是,我们提出的EQR是一种验证GDBMS的通用方法,并能够生成大量的等价查询,这些查询不容易优化到相同的查询计划,从而解决了之前的问题。
[21] Xinyu Liu, Qi Zhou, Joy Arulraj, and Alessandro Orso. 2022. Automatic detection of performance bugs in database systems using equivalent queries. In *Proceedings of the 44th International Conference on Software Engineering. 225–236.
APPROACH
为了解决在GDBMS中实现ERQ的挑战,我们引入了一个称为抽象语法图(ASG)的通用概念。核心洞见是将查询的完整语义编码成一组形成图的路径(即ASG)。然后,可以通过找到另一组覆盖ASG中所有关系(即边)和约束(即标签和属性)的路径来生成等价查询。为此,我们还设计了一种简单但有效的路径查找算法,称为随机游走覆盖(RWC)。RWC可以以不同的方式遍历ASG并返回不同的路径集,这些路径集将进一步转换为不同的等价查询。
EQR的过程始于ASG解析器将具体查询转换为相应的ASG表示。然后,将ASG输入RWC算法,生成多个等价查询。接下来,我们将详细介绍ASG、ASG解析和RWC。
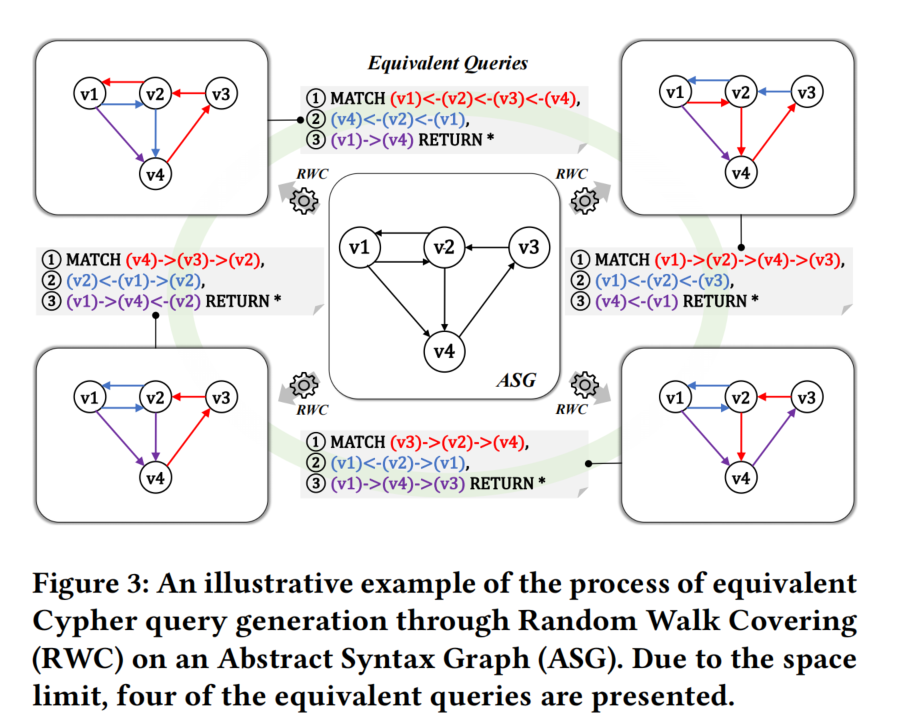
3.1 Abstract Syntax Graph (ASG)
抽象语法图(ASG)是一个通用概念,用于以与语言无关的方式表示查询的语义,即查询所检索的节点之间的关系以及边缘或节点周围的约束。ASG不针对特定的查询语言,因此它是各种查询的灵活和通用表示。给定一个查询𝑄,ASG是一个有向图结构,封装了𝑄所检索的节点之间的关系。具体来说,每个顶点对应于𝑄中定义的一类要检索的节点,每个边描述了这两类节点之间应满足的关系。通过提供将查询语言与ASG之间进行转换的转换器,开发人员只需要扩展我们的工具到新的图查询语言,而不必从头开始编写全栈代码。
3.2 ASG Parsing
ASG解析的目标是将查询语言中表达的数据关系转换为ASG中的图表示。这一步骤需要轻量级的工程化工作,因此我们的方法可以轻松地适应其他查询语言。我们使用大约260行Python代码来实现Cypher ASG解析器。这些解析器将不同查询语言的多样化语法和语义转换为统一的ASG表示。具体地,在GDBMS查询同时搜索多个图组件(例如,在社交网络中同时查找Alice的朋友和Bob的朋友)时,这种转换还允许将复杂查询划分为多个ASG,其中每个ASG表示查询的一个不同部分。在我们的实现中,对于Cypher查询,查询中的每个模式都被提取并转换为一个单独的ASG;对于Gremlin查询,起始步骤、结束步骤和每个as()步骤都被转换为ASG顶点,而内部遍历步骤被转换为ASG边。
3.3 Random Walk Covering
随机游走覆盖(RWC)是一个简单而有效的算法,用于将ASG转换为一系列不重叠的路径序列,这些路径覆盖了ASG中的所有关系和约束。每条路径都匹配ASG描述的一部分关系和约束。这些路径序列随后被翻译成GDBMS查询,生成了从ASG生成的等价查询。RWC算法从空的GDBMS查询开始,并从ASG中选择路径,直到整个ASG被覆盖为止。该算法的主要目标是生成具有多样化查询计划的等价查询,这样可以全面有效地测试GDBMS。

IMPLEMENTATION
本研究开发了名为GRev的工具,用于测试GDBMS,包括三个组件:图生成器、基础查询生成器和等价查询重写器。
GRev首先使用图生成器在目标图数据库中随机创建图模式,包括标签、属性、节点和关系。然后使用基础查询生成器生成基础查询,标记为𝑄𝑏𝑎𝑠𝑒。随后,利用等价查询重写器,采用前文提到的EQR方法,重写𝑄𝑏𝑎𝑠𝑒,生成多个等价查询,标记为𝑄1,𝑄2,…,𝑄𝑘,每个查询都保持了与𝑄𝑏𝑎𝑠𝑒的等价性。通过在目标图数据库上执行这些查询,如果它们导致不一致的系统行为,则可能发现潜在的错误。
- 图生成:通过多个步骤创建随机的标签、属性、节点和关系,形成图模式。
- 基础查询生成:根据GDBMS查询语言的语法,生成语法正确的基础查询。
- 等价查询重写和验证规则:使用EQR方法生成多个等价查询,然后根据不同的验证规则检测逻辑错误和性能错误。
- 逻辑错误检测:比较两个等价查询的结果,如果结果不同且没有抛出异常,则表示存在逻辑错误。
- 性能错误检测:比较两个等价查询的执行时间,如果执行时间存在显著差异,则表示存在性能错误。
EVALUATION
在本节中,我们针对以下研究问题来评估GRev的各个重要方面:
- RQ1:检测先前未知的错误。GRev在检测成熟的GDBMS中先前未知的错误方面有多有效?
- RQ2:生成重要测试用例的有效性。GRev生成的测试用例在生成不同查询计划时的有效性如何,以及其中有多少触发了错误?
- RQ3:与现有技术的比较。GRev在GDBMS测试中的有效性和通用性与当今先进技术相比如何?
5.1 Experimental Setting
实验设置如下:
- 选取了五种广泛使用且具有代表性的GDBMS进行评估,包括Neo4j、RedisGraph、MemGraph、TinkerGraph和NebulaGraph。
- 表格列出了所选GDBMS的基本信息,包括DB-Engines排名、GitHub星数以及它们的初始发布日期。
- Neo4j、RedisGraph和MemGraph是最受欢迎的开源GDBMS,采用Cypher作为查询语言。
- TinkerGraph是由Gremlin的创建者开发的,是Gremlin-based GDBMS(如JanusGraph和OrientDB)的基础库。
- 我们测试了该工作时各个GDBMS的最新版本,包括Neo4j 5.6.0、RedisGraph 6.2.6-v7、MemGraph 2.8.0、TinkerGraph 3.6.0和NebulaGraph 3.5.0。
- 所有实验在一台配备13代Intel(R) Core(TM) i5-13400和128 GB内存的Linux(Ubuntu 22.04 LTS)工作站上进行。
5.2 Detecting Previously Unknown Bugs
我们检测到了五种GDBMS中的22个先前未知的漏洞,其中有15个得到了开发人员的确认。除了这些漏洞外,Neo4j中报告的3个问题已经被开发人员知晓,但尚未公开披露。这些问题已在最新的Neo4j版本中得到修复,因此不被视为检测到的漏洞。此外,有一个已识别的Neo4j问题涉及开发人员有意对新功能隐藏异常。虽然这个异常在先前和未来的版本中都是意外的,但我们不将其分类为已确认的漏洞。总体漏洞统计如下表所示。在报告的22个漏洞中,有12个是逻辑错误,3个是性能问题,4个是缺失异常,3个是意外异常。其中,有15个已被开发人员修复或确认,而其余11个漏洞的状态仍然未定。经过对这些漏洞表现形式的详细调查,我们进一步确定了其中14个与图相关。这些漏洞源于GDBMS中图数据检索的不当实现(例如,Cypher中的MATCH子句),而不是与RDBMS共享的常见功能(例如,谓词)。值得注意的是,这些漏洞很少被现有技术检测到,特别是对于GDBMeter [15],它重新使用了针对RDBMS设计的测试神谕(即TLP [32])。

5.3 Test Cases Analysis
在测试案例分析中,我们通过进行实验来回答以下问题,以研究GRev生成高质量等效查询并产生多样化查询计划的能力:
- RQ2 (a):GRev为每个基本查询生成的等效查询有多种多样?
- RQ2 (b):GRev为每个基本查询生成的查询计划有多种多样?
- RQ2 (c):由GRev生成的测试案例中有多少比例会触发错误?
为了解决RQ2 (a)和RQ2 (b),我们使用GDsmith [13]的标准查询生成器生成基本查询以进行高效分析。我们专注于两组基本查询:
- 随机基本查询:从GDsmith生成的5000个查询中随机选择10个基本查询。
- 长基本查询:从相同的5000个查询中选择前10个最长的基本查询。
然后,我们使用我们的EQR方法为每个基本查询生成300个等效查询,并在RedisGraph 6.2.6-v7中导出它们的查询计划。我们的分析涉及跟踪等效查询集合中观察到的不同查询和查询计划的数量。我们进行了50次实验,并取平均结果呈现在图5和图6中。
GRev是否会生成重复的查询?如图5所示,GRev在生成多样化等效查询方面表现出有效性:随机基本查询的(2,394/3,000)独特等效查询,长基本查询的(3,000/3,000)独特等效查询,这意味着GRev可以持续生成多样化的查询。如图6所示,GRev在生成多样化查询计划方面也表现出有效性和效率。具体来说,我们使用10个基本查询(随机或长),要求GRev生成等效查询,并记录等效查询触发的不同查询计划的数量。我们可以观察到,当要求GRev为每个基本查询生成30个等效查询(总共300个)时,我们可以为随机基本查询获得63个不同的查询计划,为长基本查询获得227个不同的查询计划。对于一个基本查询获得的不同查询计划数量会随着生成的等效查询数量的增加而增加。如果我们为10个随机基本查询生成3,000个等效查询(每个300个),我们可以获得178个不同的查询计划(图6中最右边的粉色柱),平均每个基本查询获得17.8个不同的计划。类似地,我们可以获得1253个不同的查询计划(图6中最右边的黄色柱),平均每个基本查询获得125.3个不同的查询计划。因此,我们相信GRev生成的等效查询可以触发不同的查询计划。相比之下,基于特定查询转换的现有技术(如GDBMeter [15])只能触发一个(来自基本查询)+ 3(来自三个子查询)= 4个不同的查询计划。此外,基于差异测试的工具(如GDBMeter和Grand)仅限于在给定基本查询的情况下为每个目标GDBMS触发一个查询计划。因此,同时在三个GDBMS上执行差异测试时,这些工具每个基本查询只能激活三个不同的查询计划。
为了研究RQ2 (c),我们在12小时内在RedisGraph [31]上执行了1,250,000个测试案例,其中每个测试案例包括一个基本查询和一个等效查询。在这些测试案例中,**(945/1,250,000)成功触发了错误,其中936个是逻辑错误,9个是性能错误。**这个结果表明,平均而言,GRev能够识别每1,322个测试案例执行中的一个触发错误的测试案例。在我们的实际测试中,识别一个触发错误的测试案例平均需要一分钟。
5.4 Analytical Comparison with Existing Techniques

- GRev与GDsmith、Grand和GDBMeter是测试GDBMS的最相关的三个工作。
- GDsmith和Grand基于差异测试,而GDBMeter基于查询分区。
- 与RDBMS测试工具(如SQLancer)不同,GRev和这些工具的目标数据库存在根本差异。
- GRev能够检测到与MemGraph和Neo4j等GDBMS有关的逻辑错误,而GDsmith不会测试这些查询以避免误报。
- GDsmith和Grand在检测性能错误方面面临挑战,因为不同的目标GDBMS具有不同的底层架构。
- GDBMeter利用三态逻辑分区(TLP)测试Oracle来检测GDBMS中的错误,但它对查询和查询语言非常敏感。
- GDBMeter在查找遍历错误时面临挑战,因为TLP无法有效地修改遍历过程的查询计划。
- GRev能够生成多样化的等效查询和查询计划,并且在触发错误的测试用例中表现出高效性和有效性。
5.5 Empirical Comparison with Existing Techniques
- GRev进行了与GDBmeter和GDsmith在RedisGraph以及GDsmith在Neo4j上的测试覆盖率比较,结果显示GRev在Neo4j上具有更高的指令覆盖率和分支覆盖率,而在RedisGraph上与GDsmith的覆盖率相同。
- 对于Bug Reproduce比较,GRev发现的13个错误中有9个(69%)能够在早期版本中重现,除了Neo4j。这表明GRev能够发现其他工具可能忽略的错误,尤其是与新功能相关的错误。
- GRev的测试覆盖率和Bug Reproduce能力表明其在发现数据库管理系统中的错误方面具有较高的有效性和效率。