Fuzz4All Universal Fuzzing with Large Language Models
Fuzz4All: Universal Fuzzing with Large Language Models
Abstract
Fuzzing技术在发现各种软件系统中的漏洞和缺陷方面取得了巨大的成功。作为软件开发的基础构件,接受编程语言或形式语言输入的测试系统(SUTs),如编译器、运行时引擎、约束求解器和具有可访问API的软件库,尤为重要。然而,现有的针对这些系统的fuzzers通常针对特定语言,因此无法轻易应用于其他语言甚至同一语言的不同版本。此外,现有fuzzers生成的输入通常局限于输入语言的特定特性,难以发现与其他或新特性相关的漏洞。本文提出了Fuzz4All,这是首个在多个不同输入语言和这些语言的多个特性方面通用的fuzzer。Fuzz4All的核心思想是利用大型语言模型(LLMs)作为输入生成和变异引擎,从而使该方法能够为任何实际相关的语言生成多样且逼真的输入。为了实现这一潜力,我们提出了一种新颖的自动提示技术,该技术创建了适合fuzzing的LLM提示,并提出了一种新颖的LLM驱动的fuzzing循环,该循环迭代更新提示以创建新的fuzzing输入。我们在九个接受六种不同语言(C、C++、Go、SMT2、Java和Python)作为输入的测试系统上评估了Fuzz4All。评估结果显示,在所有六种语言中,通用fuzzing均比现有的特定语言fuzzers实现了更高的覆盖率。此外,Fuzz4All在广泛使用的系统中发现了98个漏洞,如GCC、Clang、Z3、CVC5、OpenJDK和Qiskit量子计算平台,其中64个漏洞已被开发者确认是以前未知的。
INTRODUCTION
背景
Fuzz测试(又称fuzzing)是一种自动化测试方法,旨在生成输入以暴露系统在测试中的意外行为,例如崩溃。研究人员和从业者已经成功构建了实用的fuzzing工具,并在发现真实世界系统中的大量漏洞和缺陷方面取得了巨大成功。特别重要的一类测试系统(SUTs)是那些接受编程语言或形式语言输入的系统,如编译器、运行时引擎和约束求解器。由于这些系统是软件开发的基础构件,许多针对这些系统的fuzzers被提议。例如,找到编译器和运行时引擎中的漏洞至关重要,因为这些漏洞可能影响所有相关的下游应用程序。
传统Fuzzing的局限性
传统fuzzing方法分为生成式和变异式两类。生成式fuzzers通过预定义的语言语法直接合成完整的代码片段,而变异式fuzzers则对一组高质量的fuzzing种子应用变异操作或转换规则。然而,这两种传统方法都面临以下挑战:
- 与目标系统和语言紧密耦合:传统fuzzers通常针对特定语言或特定系统设计和实现,这非常耗时且难以在其他语言或系统中重复使用。例如,Csmith和Syzcaller分别用于C/C++编译器和Linux系统调用,需要大量手工编写的规则。不同语言的实现难以复用,一个系统有效的fuzzing策略可能对另一个系统无效。
- 缺乏对系统演变的支持:实际系统不断演变,加入新特性。传统fuzzers设计用于特定版本的语言或系统,可能在新版本上失效,无法测试新特性。例如,Csmith仅支持C++11的一些特性,无法发现最新编译器版本中的新漏洞。
- 生成能力受限:即使在特定语言范围内,生成式和变异式fuzzing也难以覆盖大部分输入空间。生成式fuzzers依赖输入语法生成有效代码,通常使用简化语法,限制了测试语言特性的范围。变异式fuzzers受限于变异操作,需要高质量的种子,且这些种子难以获得。
Our work
我们提出了Fuzz4All,这是首个通用fuzzer,能够针对多种不同输入语言及其特性。与现有的一般用途fuzzers(如AFL和libFuzzer)不同,这些fuzzers使用极其简单的变异方式,对目标语言不了解,因此难以生成有意义的编程语言fuzzing输入。我们的核心思路是利用大型语言模型(LLM)作为输入生成和变异引擎。由于LLMs在各种编程语言和其他形式语言上预训练,具备这些语言的语法和语义的隐式理解。Fuzz4All利用这一能力,使用LLM作为通用输入生成和变异引擎。
Fuzz4All的输入是用户提供的描述SUT的文档,以及可选的SUT特定特性的描述(如文档、示例代码或正式规范)。这些用户输入可能过于冗长,无法直接用作LLM的提示。我们提出了自动提示步骤,将用户提供的所有输入提炼成简洁有效的fuzzing提示。这一提示是LLM生成fuzzing输入的初始输入。由于持续使用相同提示会生成许多相似的fuzzing输入,我们提出了LLM驱动的fuzzing循环,迭代更新提示以生成多样化的fuzzing输入。Fuzz4All结合前几次迭代生成的fuzzing输入和自然语言指令,例如请求变异这些输入。生成的fuzzing输入传递给SUT,并根据用户提供的测试Oracle(如检查系统崩溃)进行验证。
Fuzz4All解决了传统fuzzers的限制和挑战。通过使用LLM作为生成引擎,Fuzz4All可以应用于广泛的SUTs和输入语言,避免了设计单一用途fuzzer的复杂性(C1)。与针对特定版本SUT或输入语言的fuzzers相比,Fuzz4All可以轻松随目标演进(C2),例如用户可以提供与新特性相关的文档或示例代码。为了应对传统fuzzers的生成能力限制(C3),Fuzz4All利用LLMs在数十亿代码片段上的预训练,生成遵循输入语言语法和语义约束的多种示例。最后,Fuzz4All不需要对SUT进行任何仪器化,使其易于在实践中应用。
实验:
我们在六种输入语言(C、C++、SMT、Go、Java和Python)和九个测试系统(SUTs)上进行了广泛评估。对于每个SUT,我们将Fuzz4All与最先进的生成式和变异式fuzzers进行了比较。结果显示,Fuzz4All在所有语言中都实现了最高的代码覆盖率,平均提高了36.8%。此外,我们证明了Fuzz4All支持一般fuzzing和针对特定特性的fuzzing,这取决于用户提供的输入文档。最后,Fuzz4All在所研究的SUTs中检测到了98个漏洞,其中64个已被开发者确认是以前未知的。
贡献:
- 通用fuzzing:我们引入了一种新的fuzzing维度,直接利用LLMs的多语言能力,对许多SUTs进行fuzz测试,并生成各种有意义的输入。
- 自动提示fuzzing:我们提出了一种新颖的自动提示阶段,通过自动提炼用户输入生成有效的SUT输入提示,支持一般和针对特定特性的fuzzing。
- LLM驱动的fuzzing循环:我们提出了一种算法,通过选择示例和生成策略迭代修改提示,持续生成新的fuzzing输入。
- 真实世界有效性的证据:我们展示了在六种流行语言和九个真实世界SUTs(如GCC、CVC5、Go、javac和Qiskit)中的实验结果,显示我们的方法相比最先进的fuzzers显著提高了覆盖率(平均36.8%),并检测到98个漏洞,其中64个已被确认是以前未知的。
BACKGROUND AND RELATED WORK
2.1 Large Language Models
这段话讨论了大型语言模型(LLMs)在自然语言处理(NLP)和代码任务中的广泛应用。LLMs主要基于transformer架构,可以分为仅解码器模型(如GPT-3和StarCoder)、仅编码器模型(如BERT和CodeBERT)和编码器-解码器模型(如BART和CodeT5)。最近,基于指令的LLMs(如ChatGPT和GPT-4)和使用人类反馈强化学习(RLHF)微调的LLMs被证明能够理解和执行复杂指令。
LLMs通常通过微调或提示来执行特定任务。微调需要在特定任务数据集上进一步训练模型权重,但数据集可能不可用,且随着LLMs规模的增长,微调变得昂贵。提示则无需更新模型权重,通过提供任务描述和示例来指导模型执行任务。选择输入提示的过程称为提示工程,最近研究者提出了自动提示,这是一种利用LLM梯度选择软提示或硬提示的自动化过程。
本文利用LLMs解决模糊测试(fuzzing)问题,与传统自动提示和基于代理的方法不同,本文的方法直接使用GPT-4合成提示,并根据模糊测试的特定目标评分。
2.2 Fuzzing and Testing
这段文字介绍了模糊测试(fuzzing)及其相关技术。模糊测试旨在生成引发被测系统(SUT)异常行为的输入。传统模糊测试工具分为生成式和变异式。生成式模糊测试工具使用预定义的语法和内置的语言语义知识生成完整的代码片段,而变异式模糊测试工具通过对种子进行变换生成新的模糊测试输入。为利用这两种方法的优点,许多模糊测试工具结合了两者的方法。
此外,还有通用模糊测试工具,如AFL和libFuzzer,它们使用遗传算法来优先考虑进一步变异的新覆盖输入。这些变异不关心SUT,仅关注字节级变换,因此在处理编程语言输入时很难生成有效输入。最近的研究添加了基于正则表达式的变异操作符来匹配常见的编程语句,但其简单性限制了覆盖新代码的能力。
为了补充传统模糊测试技术并应用于新兴领域,提出了基于学习的模糊测试工具,这些工具主要训练神经网络生成模糊测试输入。最近,研究人员直接利用大型语言模型(LLMs)进行模糊测试,如TitanFuzz使用Codex生成种子程序,并使用InCoder进行模板化变异。
与以往的基于学习和LLM的模糊测试工具不同,Fuzz4All能够适用于多种编程语言。以往的工具需要特定语言的模型或解析,而Fuzz4All不需要特定语言的解析,且支持针对特定特征的模糊测试。此外,Fuzz4All还应用于单元测试生成问题,通过自动提示阶段,可以接受任意格式的输入进行模糊测试。相比之下,以往的单元测试生成器通常需要手动检查或完成测试,而Fuzz4All则完全自动化,利用广泛使用的模糊测试判据(如崩溃)进行测试。仅能处理崩溃错误!
FUZZ4ALL APPROACH
我们提出了Fuzz4All,一个通用模糊测试工具,利用大型语言模型(LLMs)支持对任何接受编程语言输入的被测系统(SUT)进行通用和针对性的模糊测试。Fuzz4All首先接受描述模糊测试输入的用户输入,并将其提炼为简洁但信息丰富的提示。这个过程中,Fuzz4All进行自动提示步骤,使用大规模的蒸馏LLM生成多个候选提示,并选择生成最高质量模糊测试输入的提示。
Fuzz4All结合蒸馏LLM和生成LLM,以平衡不同LLMs提供的成本和收益。使用高端的基础模型(如GPT-4)进行蒸馏,用较小的模型(如StarCoder)进行输入生成,以提高效率。选定最佳提示后,Fuzz4All进入模糊测试循环,不断生成模糊测试输入。在每次迭代中,Fuzz4All更新输入提示,选择之前生成的输入作为示例,并附加生成指令,引导模型生成新的模糊测试输入。生成的模糊测试输入不断传递到SUT,并根据用户定义的判据(如崩溃)检查其行为。
User inputs是一次性输入
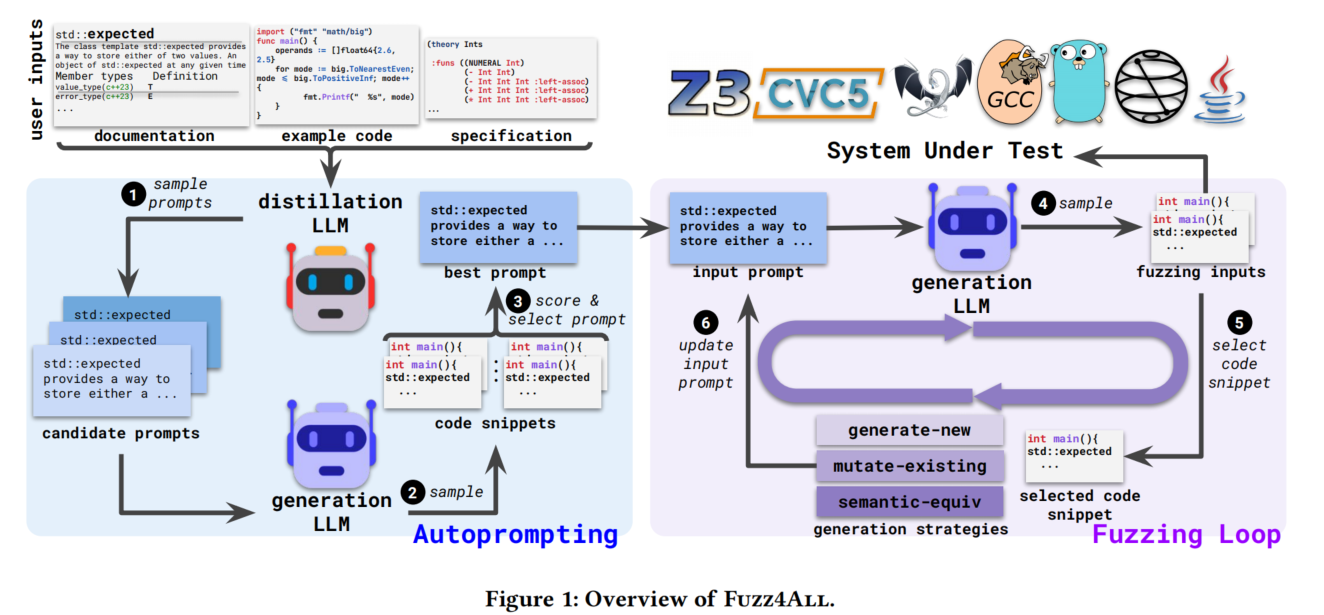
3.1 Autoprompting
这部分详细介绍了Fuzz4All的第一个主要步骤,即通过自动提示将给定的用户输入提炼为适合模糊测试的提示。用户输入可能是对SUT的整体描述,或需要测试的特定功能。这些输入可以是技术文档、示例代码、规范,甚至是不同形式的组合。与传统模糊测试工具需要特定格式的输入不同,Fuzz4All能够直接理解用户输入中的自然语言描述或代码示例。然而,用户输入中可能包含冗余或不相关的信息,因此直接将这些输入用作生成LLM的提示可能效果不佳。因此,自动提示的目标是生成一个提炼后的输入提示,从而实现有效的基于LLM的模糊测试。
3.1.1 Autoprompting Algorithm.
算法1详细介绍了Fuzz4All的自动提示步骤。输入为用户输入和需要生成的候选提示数量,最终输出为用于模糊测试的输入提示。自动提示的目标是使用蒸馏LLM生成提炼用户信息的提示。我们给蒸馏LLM的自动提示指令是:“请简要总结上述信息,以描述目标的用法和功能。” “Please summarize the above information in a concise manner to describe the usage and functionality of the target”.具体步骤如下:
- 使用蒸馏LLM(MD)和用户输入(userInput),通过贪婪采样(温度为0)生成第一个候选提示。这种低温度采样方法能以较高置信度生成一个合理的初始提示。
- 然后,算法通过高温度采样生成更多样化的候选提示,增加提示的多样性。
- 每个生成的提示被加入候选提示列表,直到达到所需数量。
- 为选择最佳输入提示,算法通过小规模模糊测试实验评估每个候选提示。具体方法是使用生成LLM(MG)将每个提示生成多个代码片段。
- 根据评分函数对每个提示生成的代码片段进行评分。评分函数可以基于覆盖率、发现bug的能力或生成模糊测试输入的复杂性。为简化和通用性,默认评分函数是生成的有效代码片段数量。
- 选择得分最高的输入提示作为用于模糊测试的初始输入提示。
总结来说,自动提示步骤结合了提示生成和评分,使Fuzz4All能够自动生成并选择适合模糊测试目标的提示。
3.1.2 Example: Autoprompting.
图2展示了自动提示算法生成的输入提示示例。该示例针对C++编译器的模糊测试,特别关注C++23引入的新特性std::expected。我们将cppreference文档作为用户输入传递给Fuzz4All,原始文档包含498个单词和3262个字符,内容繁杂且冗长。而自动提示算法生成的提炼后的输入提示则提供了更简洁的自然语言描述,包含214个单词和1410个字符。
提炼后的输入提示包括std::expected的高层次使用描述。例如,其中包含一句简洁的句子(用橙色突出显示)总结了该特性适用的情况。此外,输入提示还描述了该特性的输入以及不同用法(如成员函数)。在原始文档中,函数and_then、transform、or_else和transform_error的描述非常相似,并为每个函数重复。而在提炼后的输入提示中,这些函数被简洁地组合在一起,仍能展示其用法。
通过使用提炼后的输入提示,Fuzz4All能够生成有效针对C++编译器std::expected特性的模糊测试输入。

3.1.3 Comparison with Existing Autoprompting Techniques.
据我们所知,我们是首个使用黑箱自动提示技术从任意用户输入中提炼知识用于软件工程任务的。与之前在NLP和软件工程领域的自动提示工作相比,这些工作通过访问模型梯度优化提示,而我们的自动提示仅需对蒸馏LLM进行黑箱采样访问。尽管使用评分函数评估每个提示的方式与最近的NLP工作相似,我们的评分函数直接在生成有效代码片段的下游任务上评估提示,而不是使用近似的代理评分函数。
3.2 Fuzzing Loop
在Fuzz4All的第一步创建了输入提示后,模糊测试循环的目标是使用生成LLM生成多样化的模糊测试输入。然而,由于LLMs的概率性特征,使用相同输入多次采样会产生相同或相似的代码片段。为了模糊测试的目的,我们希望避免重复的输入,生成覆盖新代码并发现新漏洞的多样化输入。
模糊测试循环的核心思路是通过选择前几次迭代的示例输入并指定生成策略,持续扩展原始输入提示。使用示例的目的是展示我们希望生成LLM生成的代码片段类型。生成策略则作为指导如何处理所提供代码示例的指令。这些策略受到传统模糊测试工具的启发,模仿其生成新模糊测试输入(如生成式模糊测试工具)和生成已有输入变体(如变异式模糊测试工具)的能力。在每次新的模糊测试循环迭代之前,Fuzz4All将示例和生成策略附加到输入提示中,使生成LLM能够持续创建新的模糊测试输入。
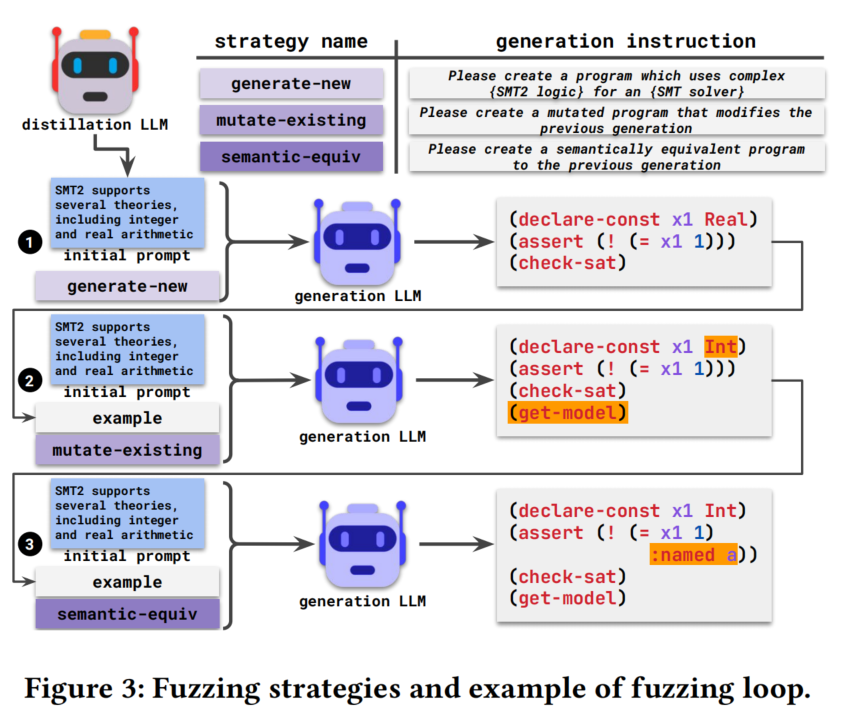
3.2.1 Fuzzing Loop Algorithm.

循环算法的步骤如下:
- 初始化:设置初始输入提示和模糊测试预算。初始化生成策略(生成新输入、变异已有输入和语义等价)。
- 第一次调用生成LLM:
- 在没有示例的情况下,在输入提示中添加“生成新输入”的指令。
- 使用该提示生成第一批模糊测试输入。
- 进入主模糊测试循环:
- 选择示例:从前一批生成的有效模糊测试输入中随机选择一个作为示例。
- 选择生成策略:随机选择一个生成策略(生成新输入、变异已有输入或语义等价)。
- 构建新提示:将初始输入提示、选定的示例和生成策略连接成一个新提示。
- 生成新输入:使用新提示查询生成LLM,以生成新一批模糊测试输入。
- 检查行为:将每个创建的模糊测试输入传递给SUT,如果用户定义的判据识别出异常行为(如崩溃),则记录检测到的漏洞。
- 重复循环:重复主模糊测试循环,直到耗尽模糊测试预算。
- 输出结果:输出用户定义的判据识别出的漏洞集合。
3.2.2 Example: Fuzzing Loop.
图3展示了模糊测试循环如何使用输入示例和生成策略创建不同的模糊测试输入。示例中,我们对一个SMT求解器进行模糊测试,输入为SMT2语言编写的逻辑公式。
- 初始阶段:没有示例,算法使用“生成新输入”策略合成新的模糊测试输入。
- 第二阶段:选取一个生成的有效模糊测试输入作为示例,算法使用“变异已有输入”策略创建新输入,观察到新输入通过交换变量类型和添加一些计算对之前的输入进行细微修改。
- 第三阶段:选取之前生成的模糊测试输入作为示例,使用“语义等价”策略创建新输入,这次新输入仅添加了一个语法标签。
通过组合这些生成策略,Fuzz4All生成了导致SMT求解器意外崩溃的模糊测试输入,暴露了一个真实存在的漏洞,该漏洞在评估期间被Fuzz4All检测到,并已被开发人员确认和修复。
3.2.3 Oracle.
Fuzz4All在模糊测试循环中生成的输入可用于检查SUT的行为,以检测漏洞。判据是针对每个SUT自定义的,可以由用户完全定义和定制。例如,在对C编译器进行模糊测试时,用户可以定义一个差分测试判据,比较编译器在不同优化级别下的行为。本文重点讨论简单且易于定义的判据,如因分段错误和内部断言失败引起的崩溃。更多细节在第4.2节中讨论。
EXPERIMENTAL DESIGN
我们通过以下研究问题评估Fuzz4All:
- RQ1:Fuzz4All与现有模糊测试工具相比如何?
- RQ2:Fuzz4All在执行针对性模糊测试方面的效果如何?
- RQ3:不同组件对Fuzz4All的有效性有何贡献?
- RQ4:Fuzz4All发现了哪些现实中的漏洞?
4.1 Implementation
Fuzz4All主要用Python实现。其自动提示和模糊测试循环组件仅包含872行代码(LoC)。相比于需要大量手动工作实现生成器的传统模糊测试工具(如Csmith,超过80K LoC),Fuzz4All的实现非常轻量。Fuzz4All使用GPT-4作为蒸馏LLM进行自动提示,因为该模型在广泛的基于NLP的推理任务中表现出色。具体来说,我们使用OpenAI API提供的gpt-4-0613检查点,最大token数为500,以确保提示始终适合生成LLM的上下文窗口。
在自动提示过程中,我们采样四个候选提示,每个提示生成30个模糊测试输入,并使用基于有效率的评分函数进行评估。在模糊测试循环中,我们使用Hugging Face实现的StarCoder模型作为生成LLM,该模型在超过80种语言的一万亿代码tokens上进行了训练。默认设置下,生成模糊测试输入时使用的温度为1,批量大小为30,最大输出长度为1024,采用核采样(top-p为1)。
4.2 Systems Under Test and Baselines
4.3 Experimental Setup and Metrics
模糊测试活动:针对RQ1,我们使用24小时的模糊测试预算(包括自动提示),这在以往工作中常用。为了考虑变化性,我们对Fuzz4All和基线进行五次实验。由于实验成本较高,后续研究问题使用10,000个生成的模糊测试输入的预算,并进行四次消融研究实验。
环境:实验在一台运行Ubuntu 20.04.5 LTS的64核工作站上进行,配备256 GB RAM和4个NVIDIA RTX A6000 GPU(每次模糊测试运行仅使用一个GPU)。
指标:我们使用广泛采用的代码覆盖率作为评估模糊测试工具的标准。为了统一,我们报告评估中每个目标的行覆盖率。根据以往工作,我们使用Mann-Whitney U检验计算统计显著性,并在适用的表格中标注显著结果(p < 0.05)。此外,我们测量输入的有效率,即生成的模糊测试输入中有效且唯一的百分比。为了评估针对性模糊测试的效果,我们报告命中率,即使用特定目标特征的模糊测试输入的百分比(通过简单的正则表达式检查)。最后,我们报告模糊测试的最重要指标和目标:Fuzz4All在每个九个SUT中检测到的漏洞数量。
RESULTS
5.1 RQ1: Comparison against Existing Fuzzers
5.1.1 Coverage over Time
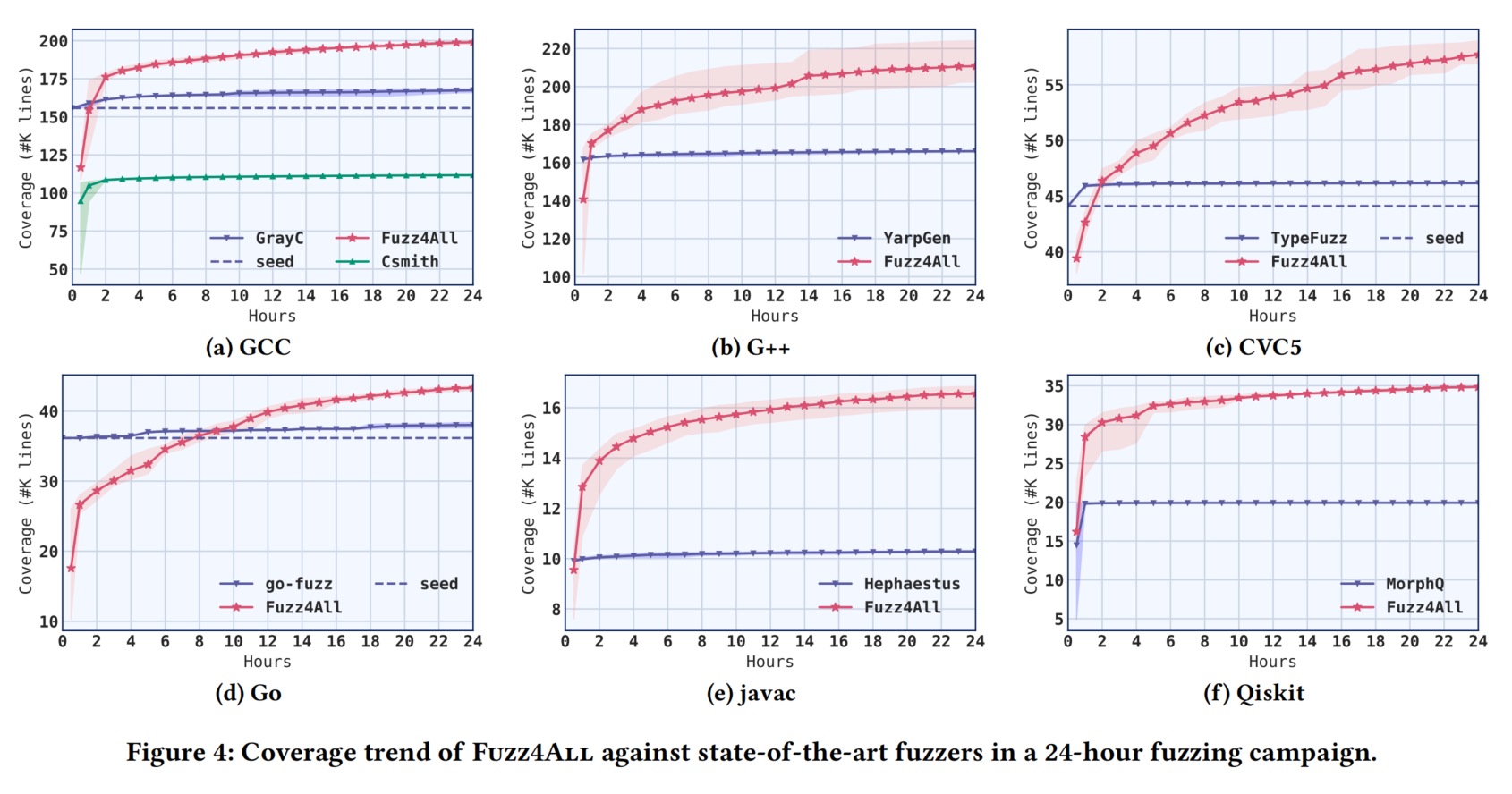
图4展示了Fuzz4All与基线工具在24小时内的覆盖率趋势,实线表示平均覆盖率,阴影区域表示五次运行的最小值和最大值。我们观察到,在所有目标上,Fuzz4All在模糊测试活动结束时实现了最高的覆盖率,平均比表现最好的基线工具提高了36.8%。与基于生成的模糊测试工具(如YARPGen和MorphQ)相比,Fuzz4All几乎立即实现更高的覆盖率,展示了LLMs在生成多样化代码片段方面的强大能力。虽然基于变异的模糊测试工具(如go-fuzz和GrayC)在开始时由于高质量的种子能够实现较高的覆盖率,但其通过变异获得的覆盖率迅速下降,而Fuzz4All则能够逐渐覆盖更多代码。
值得注意的是,为了公平比较,我们将自动提示时间包含在模糊测试预算内,但其开销可忽略不计(每次模糊测试活动平均为2.3分钟)。与基线工具在24小时内覆盖率达到平台期不同,Fuzz4All即使在模糊测试活动接近尾声时仍能找到覆盖新代码的输入。我们认为,这是因为在Fuzz4All的每次模糊测试循环迭代中,原始输入提示都会更新新的示例和生成策略,从而引导LLM生成新的模糊测试输入。这使得Fuzz4All即使在长时间的模糊测试后,仍能有效生成新的多样化输入,持续增加覆盖率。
5.1.2 Generation Validity, Number, and Coverage.
我们检查了生成的模糊测试输入数量及其在不同SUT上的有效率。表2中,“# programs”表示生成的唯一输入数量,“% valid”表示有效模糊测试输入的百分比,“Coverage”显示每个模糊测试工具获得的最终覆盖率及相对于最佳基线工具的相对改进。
首先观察到,除Hephaestus外,几乎所有传统模糊测试工具都能实现很高的有效率。Hephaestus故意生成无效代码以检查错误编译漏洞。相比之下,Fuzz4All生成的有效模糊测试输入百分比较低,平均比基线工具减少56.0%。此外,基线工具生成的模糊测试输入数量也更高。由于使用LLM作为生成引擎,Fuzz4All受到GPU推理的限制,生成的模糊测试输入比传统模糊测试工具少43.0%。
尽管有效率和输入数量较低,Fuzz4All生成的程序更加多样化,获得的覆盖率更高(平均提高36.8%)。即使是接近有效的无效代码片段也对模糊测试有用,因为它们有助于发现SUT的验证逻辑中的漏洞。第5.4节进一步描述了Fuzz4All通过有效和无效代码片段检测到的各种类型的漏洞,展示了生成多样化模糊测试输入的好处。
Fuzz4All在不同SUT上的有效率和输入数量差异较大。不同目标的模糊测试输入数量因每次模糊测试迭代后调用SUT进行漏洞检测的成本不同而异。关于有效率,通用编程语言(如C)的有效率相对较低,而领域特定语言(如用于SMT求解器的SMT2语言)有效率较高。严格的语言(如不允许任何声明但未使用变量的Go语言)有效率更低。量子计算平台的模糊测试也表现出较低的有效率。由于量子计算是一个新兴领域,生成LLM在训练过程中可能没有看到过多的量子程序示例。尽管如此,Fuzz4All仍能够利用用户提供的文档生成有趣的模糊测试输入,使用量子库API,并相比最先进的模糊测试工具实现显著的覆盖率提升(+75.6%)。
5.2 RQ2: Effectiveness of Targeted Fuzzing
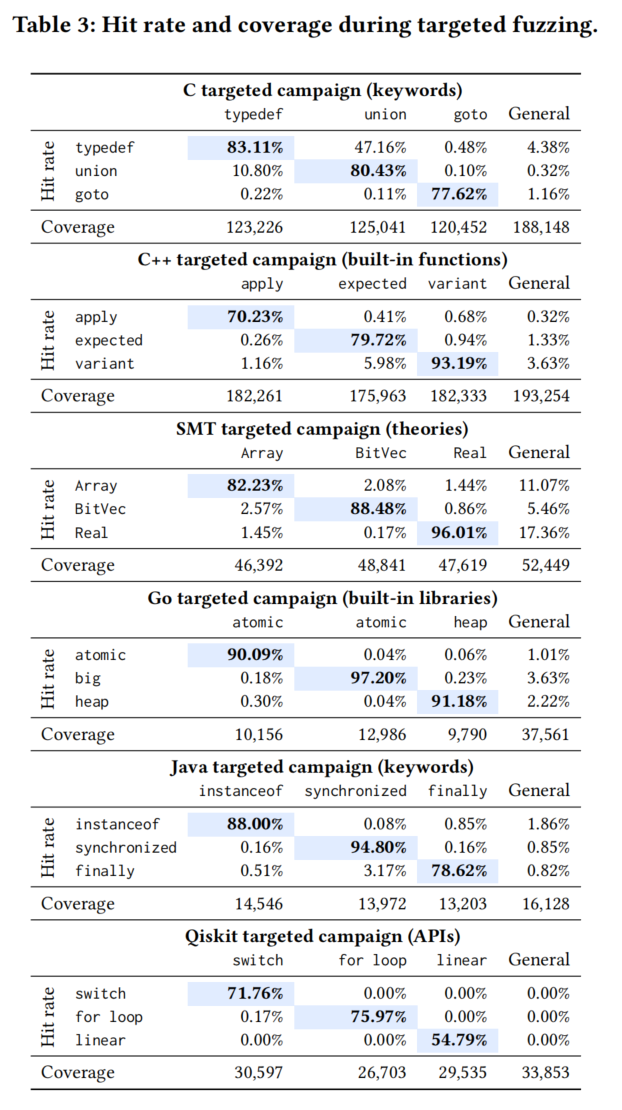
我们现在评估Fuzz4All执行针对性模糊测试的能力,即生成聚焦于特定特性的模糊测试输入。对于每个目标SUT和语言,我们针对三个不同的特性进行测试,并将其与RQ1中使用的一般用户输入进行比较。目标特性包括内置库或函数/API(Go、C++和Qiskit)、语言关键词(C和Java)以及理论(SMT)。针对性模糊测试的用户输入是我们关注的特性的文档。
表3显示了针对性模糊测试和RQ1中默认的一般模糊测试的结果。每列表示一次针对性模糊测试,聚焦于一个特性。每个单元格的值表示该特性的命中率,以及获得的覆盖率。
我们观察到,**针对特定特性生成的模糊测试输入的命中率很高,平均命中率为83.0%**。这一结果表明,通过使用描述特定特性的输入提示,Fuzz4All确实能够执行针对性模糊测试。此外,相关特性的模糊测试也会导致较高的交叉特性命中率。例如,C语言中的typedef和union都与类型操作相关,因此它们的交叉特性命中率较高,而与goto等不相关特性相比则较低。
表3显示,一般模糊测试方法虽然在总体代码覆盖率上最高,但在针对特定特性时效率极低,命中率平均减少了96.0%。例如,在Qiskit中,一般模糊测试对三个目标特性的命中率为0%。这可以解释为这些特性是最近添加到Qiskit中的,在LLM训练数据中出现频率极低。然而,通过在针对性模糊测试活动中提供合适的用户输入,Fuzz4All能够成功生成使用这些新特性的模糊测试输入。Fuzz4All这种能力对于开发者测试新特性或SUT组件非常有价值。
5.3 RQ3: Ablation Study
5.3.1 Autoprompting.
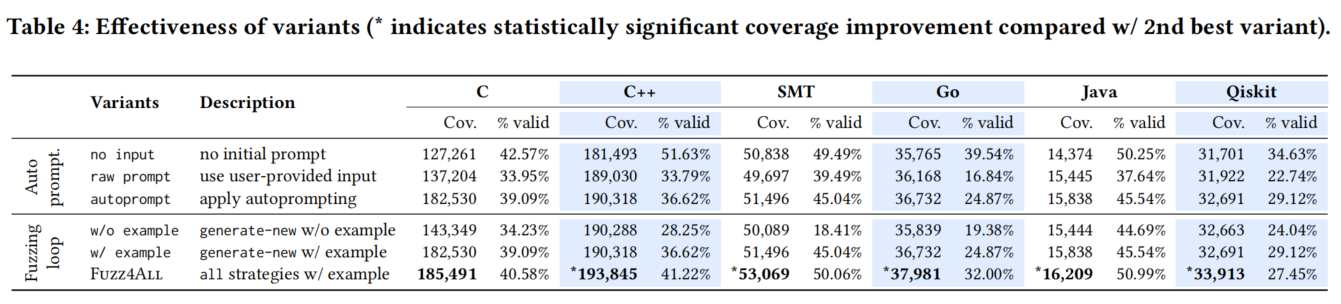
首先,我们研究了提供给生成LLM的不同初始输入的效果。为减少其他因素的影响,我们将生成策略固定为只使用“生成新输入”,并研究三种变体:1) 无输入(no input),即不使用任何初始提示,2) 原始提示(raw prompt),直接使用原始用户输入作为初始提示,3) 自动提示(autoprompt),通过自动提示生成初始提示。
在所有研究的语言中,无输入变体的覆盖率最低。无输入情况下,我们没有提供任何初始提示,这使得LLM只能生成简单的代码片段,虽然有效率高,但在覆盖SUT方面效果较差。使用原始提示变体时,我们提供原始文档作为初始提示,覆盖率有所提升。
然而,通过使用自动提示阶段将用户输入提炼成简洁但信息丰富的提示(autoprompt),我们可以进一步提高代码覆盖率和有效率。直接使用用户提供的输入可能包含与模糊测试无关的信息,导致较低的有效率(因为生成LLM可能难以理解原始文档)和较低的覆盖率(因为原始文档并非为LLM生成而设计)。
5.3.2 Fuzzing loop.
接下来,我们研究了不同变体的模糊测试循环设置,同时保持初始提示相同(使用默认自动提示):
- 无示例(w/o example):在模糊测试循环中不选择示例,即不断从相同的初始提示中采样。
- 有示例(w/ example):选择一个示例,但仅使用“生成新输入”的指令。
- Fuzz4All:使用全部生成策略的完整方法。
首先观察到,仅从相同输入中采样(无示例)时,LLM往往会重复生成相同或相似的模糊测试输入。平均而言,无示例情况下生成的模糊测试输入有8.0%是重复的,而使用完整的Fuzz4All方法时仅为4.7%。在输入提示中添加示例(有示例)可以避免从相同分布中采样,改善覆盖率和有效率。最终,完整的Fuzz4All方法在所有SUT中实现了最高覆盖率。与有示例变体(第二好的变体)相比,完整的Fuzz4All增加了“语义等价”和“变异已有输入”生成策略,为生成LLM提供了有用的指令。
5.4 RQ4: Bug Finding