Detecting Metadata-Related Logical Bugs in Database Systems via Raw Database Construction
Detecting Metadata-Related Logical Bugs in Database Systems via Raw Database Construction
ABSTRACT:
数据库管理系统(DBMSs)被广泛用于高效地存储和检索数据。DBMSs通常支持各种元数据,例如用于确保数据完整性的完整性约束和用于定位数据的索引。DBMSs还可以利用这些元数据来优化查询评估。然而,不正确的元数据相关优化可能会引入元数据相关的逻辑错误,这可能导致DBMS对给定查询返回不正确的查询结果。在本文中,我们提出了一种通用且有效的测试方法,原始数据库构建(Radar),以检测DBMS中的元数据相关逻辑错误。给定一个包含一些元数据的数据库DB,Radar首先构建一个原始数据库DB_raw,它清除DB中的元数据并包含与DB相同的数据。由于DB和DB_raw具有相同的数据,它们对给定查询应返回相同的查询结果。任何查询结果的不一致都表明存在元数据相关的逻辑错误。为了有效地检测元数据相关的逻辑错误,我们进一步提出了一种元数据导向的测试优化策略,重点测试以前未见过的元数据,从而快速检测更多的元数据相关逻辑错误。我们在五个广泛使用的DBMS上实现并评估了Radar,检测到42个错误,其中38个被确认是新错误,16个已被DBMS开发人员修复。
INTRODUCTION:
metadata
在DBMS中,数据库元数据描述了数据库中的数据组织,包括数据库结构(如数据类型和完整性约束)、索引和存储配置。DBMS可以利用这些元数据来确保其管理数据库中的数据完整性。例如,一个表中的TINYINT数据类型列只能存储-128到127之间的数值;如果对该列应用了NOT NULL约束,则该列不能存储NULL值;如果应用了UNIQUE约束,则该列不能存储重复的数值。
DBMS还可以利用数据库元数据(如完整性约束和索引)来优化查询评估。例如,如果在一个表的某列上c1应用了NOT NULL约束,在评估SELECT c1 FROM t1 WHERE ISNULL(c1)查询时,DBMS可以直接返回FALSE,而无需对每条记录进行评估;如果在某列上应用了索引,DBMS可以快速找到匹配条件的记录,避免不必要的数据访问。
Motivation example
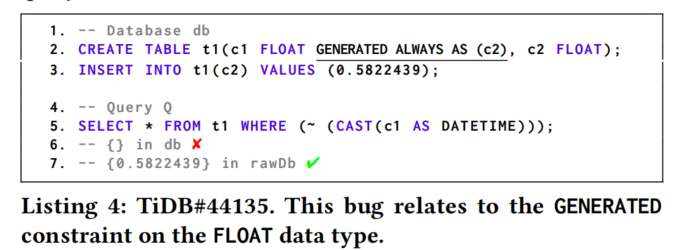
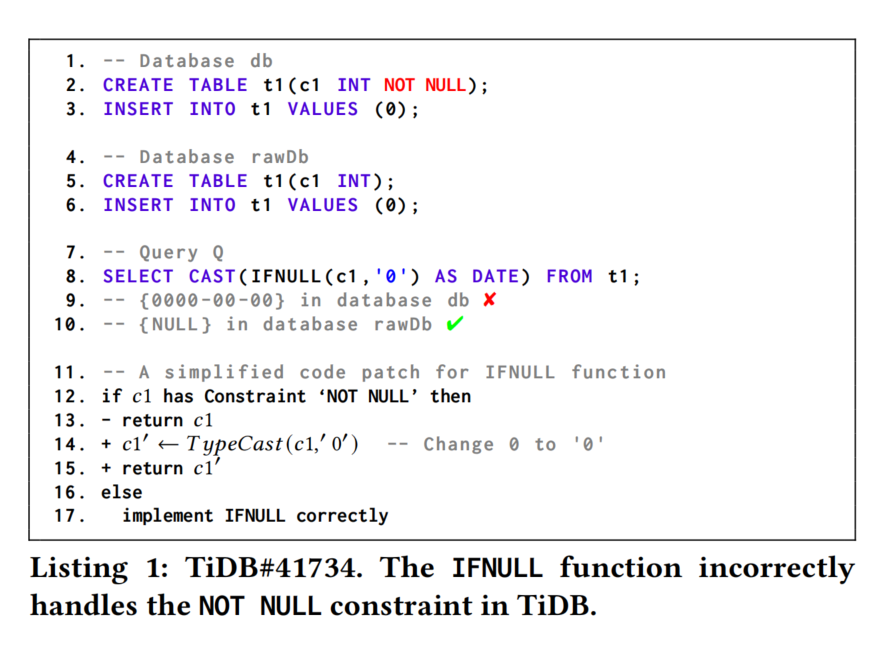
这个例子展示了我们的方法在广泛使用的DBMS TiDB中检测到的一个真实世界的元数据相关逻辑错误(MRL),编号为TiDB#41374。数据库DB包含一个表T1,表中有一个数据类型为INT并带有NOT NULL约束的列C1。由于IFNULL函数中的不正确优化(直接返回列C1的值,即INT值0),导致返回了错误的值“0000-00-00”。在正确的实现中,IFNULL函数需要将INT值0转换为字符串’0’,从而产生正确的查询结果NULL。我们将此错误报告给TiDB开发人员,他们将其分类为重大错误并迅速修复了它。
Related work
最近,研究人员提出了许多方法来检测DBMS中的逻辑错误。RAGS通过在多个DBMS上执行查询并识别查询结果之间的差异。然而,差异测试无法检测到在所有DBMS中都发生的错误,也无法测试单个DBMS的特定功能。DQE、NoREC和TLP通过构造与原始查询等价的查询,并识别其执行结果之间的差异。然而,这些查询转换不能有效地禁用有问题的元数据相关优化,因此会遗漏MRLs。MutaSQL通过向表中添加索引并观察查询结果的变化来检测与索引相关的逻辑错误,但它不支持大多数数据库元数据,如NOT NULL、GENERATED和FOREIGN KEY。因此,现有的方法无法有效地检测DBMS中的MRLs,可能会遗漏许多实际存在的MRLs。
[34] Xinyue Chen, Chenglong Wang, and Alvin Cheung. 2020. Testing Query Execution Engines with Mutations. In Proceedings of the Workshop on Testing Database Systems. Article 6, 5 pages.
Key insight有点小,和MutaSQL相比,仅仅是支持了大多数metadata?
和Testing_Database_Engines_via_Query_Plan_Guidance的本质区别是? 都是涉及一些优化选项,本质相同,表现形式不同而已,和Mozi也差不多。
approach
给定一个包含一些元数据(如完整性约束和索引)的数据库DB,DBMS可以利用这些元数据以优化的方式评估查询Q。如果我们从数据库DB中移除这些元数据,DBMS必须以相应的非优化方式评估相同的查询Q。我们观察到,这两种查询评估方式应该返回相同的查询结果。例子中展示了这种情况:如果在表T1的列C1上应用NOT NULL约束,TiDB以优化方式评估查询Q;如果我们移除NOT NULL约束,TiDB则以非优化方式评估查询Q。如果在优化和非优化查询评估之间出现任何不一致,就揭示了一个MRL。
基于上述观察,我们提出了一种通用的测试方法——原始数据库构建(Radar),用于检测DBMS中的元数据相关逻辑错误(MRLs)。具体来说,我们首先随机生成一个包含一些元数据的数据库DB,然后构建一个与DB具有相同数据但不包含元数据的原始数据库DB_raw。给定一个查询Q,我们分别在DB和DB_raw上执行,并比较它们返回的查询结果。任何返回查询结果的不一致都表明目标DBMS中存在一个MRL。为了提高测试效率并避免测试具有相似元数据的数据库,我们进一步提出了一种元数据导向的测试优化策略,从而可以继续测试以前未见过元数据的数据库,并快速检测到更多独特的MRLs。
Evaluation and contributions
为了评估Radar的有效性,我们在五个广泛使用的DBMS上实现并评估了它,分别是MySQL、SQLite、MariaDB、CockroachDB和TiDB。我们总共检测到了42个错误,其中38个被确认是独特的且以前未知的错误,16个错误已被DBMS开发人员修复。实验结果还表明,元数据导向的测试优化策略可以帮助更快地测试具有多样元数据的数据库,并发现更多独特的错误。我们进一步将Radar与四种最先进的DBMS测试方法(DQE、NoREC、TLP和MutaSQL)在错误检测能力上进行了比较。最多只有13个已确认的MRL可以被这些方法检测到。DBMS开发人员对我们的方法非常认可,例如,TiDB开发人员希望将Radar集成到他们的内部测试过程中。我们相信,Radar的普遍性可以大大提高DBMS的可靠性。
总结来说,我们的贡献如下:
- 我们提出了Radar,一种通用且有效的测试方法,用于检测DBMS中的元数据相关逻辑错误。我们通过比较包含相同数据但元数据不同的数据库上的查询结果,解决了测试判定问题。
- 我们提出了一种元数据导向的测试优化策略,以提高Radar的测试效率,能够快速测试具有多样元数据的数据库并发现独特的错误。
- 我们在五个广泛使用的DBMS上实现并评估了Radar,发现了42个错误,其中38个被确认是独特且新发现的错误。
PRELIMINARIES
2.1 Database Management Systems and SQL
数据库管理系统(DBMSs)为许多关键业务应用提供高效的数据存储和检索。特别是关系型数据库管理系统(如MySQL、PostgreSQL和SQLite)基于关系数据模型,将数据组织成由列和行组成的表。关系型DBMSs是最广泛使用的数据库管理系统之一。
关系型DBMSs通常支持SQL作为其标准查询语言。根据SQL语句的功能,大致可以分为四类:(1)用于创建和修改数据库元数据的语句,如CREATE TABLE、ALTER TABLE和CREATE INDEX;(2)用于检索数据库元数据的语句,如SHOW CREATE TABLE;(3)用于修改数据的语句,如INSERT、UPDATE、DELETE和TRUNCATE;(4)用于检索数据的语句,如SELECT。
在这项工作中,我们选择了五个流行的关系型DBMS(见表1),包括两个传统的DBMS(MySQL和MariaDB),一个嵌入式DBMS(SQLite)和两个NewSQL DBMS(CockroachDB和TiDB)。根据DB-Engines排名,MySQL、MariaDB和SQLite是最受欢迎的DBMS之一。根据GitHub数据库主题的排名,CockroachDB和TiDB是最受欢迎的DBMS之一。
2.2 Database Metadata
数据库管理系统(DBMSs)使用元数据来描述其管理的数据库中的数据组织和结构。数据库由一个或多个表组成,每个表包括表名、一个或多个列、一些可选的表约束和表配置。每列包括列名、数据类型和一些可选的列约束。这些数据库元数据都是用户可配置的,不包括系统级元数据如预写日志(WAL)和Manifest文件。
数据类型定义了列中可以存储的值的类型,常见的数据类型有INT、VARCHAR、BLOB和BOOLEAN。除了SQLite之外,所有目标DBMSs中的每列都需要有一个数据类型。
列约束是直接附加到特定列上的完整性约束,用于限制存储在列中的值。目标DBMSs支持三种列约束:NOT NULL、DEFAULT和GENERATED。NOT NULL约束强制列不能存储NULL值。DEFAULT约束指定列的默认值。GENERATED约束通过指定的表达式定义如何自动生成列的值。
表约束是可以应用于一个或多个列的完整性约束,本文重点讨论四种表约束:
- PRIMARY KEY约束唯一标识表中的每条记录,必须包含唯一值,通常不能包含NULL值。
- UNIQUE约束确保所有值唯一,可以应用于一个或多个列,这些列可以包含NULL值。
- CHECK约束通过表达式限制存储在表中的值。
- FOREIGN KEY约束定义两个表中列之间的关系。
索引是辅助数据结构,用于优化表中的数据查询。索引可以使用一个或多个列创建,可以声明为唯一索引(UNIQUE INDEX),这同时创建索引并在指定列上应用UNIQUE约束。
表配置(即,tConfig)用于定制表的性能和存储特性。例如,我们可以使用MySQL中的ENGINE配置来指定表使用的存储引擎。我们可以通过CHARACTER SET和COLLATE配置分别指定字符集和字符集排序规则。我们可以使用TiDB中的PARTITIONING配置在表中物理分配数据。

2.3 Metadata-Related Query Optimization
根据数据库元数据如何影响查询Q在数据库上的执行结果,我们将数据库元数据分为两类:强制性数据库元数据和可选数据库元数据。强制性数据库元数据是指执行查询Q所必需的元数据,包括表名、列名、数据类型和部分表配置(如ENGINE和CHARACTER SET)。可选数据库元数据不能影响查询Q的执行结果,包括列约束、表约束、索引和部分表配置(如PARTITIONING)。
DBMSs利用可选数据库元数据来优化查询评估。例如,对于一个具有NOT NULL约束的列,DBMS可以直接返回一些函数和操作符的评估结果(如IFNULL函数和IS NULL操作符),而不需要在表的每条记录上评估这些函数或操作符。此外,DBMS可以利用索引快速查找满足谓词的记录。例如,哈希索引可以帮助MySQL在这些列上进行高效的相等比较查找。
APPROACH
3.1 Architecture
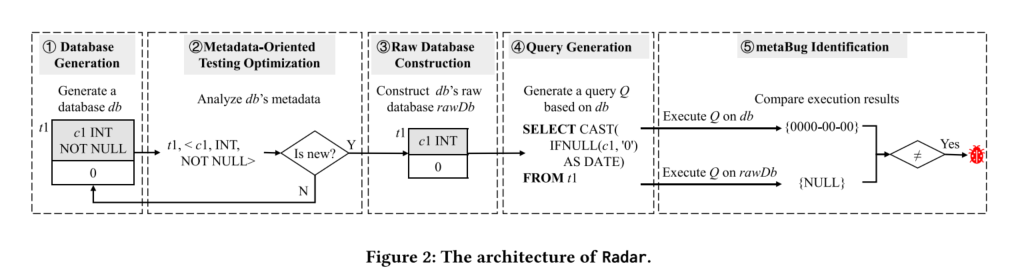
Radar的架构由五个组件组成:
- 数据库生成组件(①):生成有效的数据库。
- 查询生成组件(④):利用生成的数据库生成有效的查询。
- 原始数据库构建组件(③):合成SQL语句以为给定数据库生成原始数据库rawDb。
- 元数据优化组件(②):过滤掉具有相似元数据的数据库,以提高测试效率。
- 错误识别组件(⑤):使用rawDb作为交叉参考,验证查询执行结果以识别元数据错误(metaBugs)。
Radar的工作流程如下:
- 随机生成一个包含表t1的数据库db,表t1中有一个带有INT数据类型和NOT NULL约束的列c1。
- 分析db的元数据,以确定是否需要测试db。如果db的元数据是新的(即以前未测试过),则测试db;否则,重新生成一个新数据库。
- 对于具有新元数据的有趣数据库db,构建其对应的原始数据库rawDb,去除db中的可选元数据(例如,列c1中的NOT NULL约束)。
- 生成基于db的随机查询Q。
- 分别在db和rawDb上执行查询Q,并比较返回的查询结果。
- 报告任何不一致作为metaBug。
- 重复测试过程,直到生成可配置数量的查询或耗尽固定时间预算。
这个架构确保通过对比优化和非优化查询结果来有效检测DBMS中的元数据错误。
3.2 Database and Query Generation
Database Generation

算法2描述了构建CREATE TABLE语句的过程:
- 生成一个随机名称的表(第3行)和随机数量(最多
maxColumns个)的列(第5-15行)。 - 每列具有随机名称(第6行)、随机数据类型(如INT和DOUBLE)(第7行)和一些随机列约束(如NOT NULL、DEFAULT和GENERATED)(第8-13行)。
- 随机在一些列上添加表约束(如CHECK、PRIMARY KEY和UNIQUE)(第16行),例如
PRIMARY KEY (c1)。 - 如果目标DBMS支持表配置(如MySQL和TiDB),则随机添加一些表配置及其适当的值(第18行),例如
ENGINE=InnoDB。 - 在表生成过程中,记录生成的列和表约束以避免在
CREATE TABLE语句中违反语义约束。例如,如果已经生成了一个PRIMARY KEY,则不再生成另一个PRIMARY KEY,因为一个表最多只能有一个PRIMARY KEY。
对于生成的表,随机通过执行最多maxIndexes个CREATE INDEX语句来构建一些索引。当生成的数据库包含多个表时,通过执行最多maxForeignKeys个ALTER TABLE语句随机添加外键约束。最后,通过执行最多maxInserts个INSERT语句向每个表填充随机数据。
Radar支持生成包含各种元数据的数据库,包括各种数据类型、列约束、表约束、索引和表配置。用于生成数据库的SQL特性可以是标准的或方言的。
注意:maxTables、maxColumns、maxIndexes、maxInserts和maxForeignKeys都是可配置的。在我们的实验中,分别将它们设置为3、3、30、5和3。图2展示了我们可以生成一个包含表t1、列c1和一个值为0的行的数据库db。列c1具有INT数据类型和NOT NULL约束。
Query Generation

我们基于SELECT语句的语法和数据库db中的元数据生成查询。生成的查询应能够在生成的数据库db和原始数据库rawDb(第3.3节)上执行,并在这两个数据库上产生确定性的查询结果。
具体步骤如下:
- 随机生成一个select-from-where查询,然后随机生成其他可选子句。
- 根据生成的数据库元数据,随机生成一个表源。表源可能包含一个表或多个通过连接操作符连接的表,例如
t1 JOIN t2(步骤1)。 - 随机生成基于表源的一些列作为选择字段,例如
t1.c1, t2.c2(步骤2)。 - 随机生成一个基于表源列的表达式以形成谓词,例如
t1.c1 > 1 AND t2.c2 < 3(步骤3)。
类似地,我们可以生成其他可选子句,例如GROUP BY、ORDER BY和LIMIT,并将这些可选子句附加到生成的select-from-where查询中。
Radar中的查询生成支持SQL标准中几乎所有的关键特性(例如连接、子查询和复杂谓词),以及目标DBMS采用的定制特性(例如MySQL中的high_priority和straight_join)。然而,Radar不能支持一些可能使其无效的功能:
- Radar不支持包含DEFAULT函数和索引提示的查询。例如,
DEFAULT(c1)函数要求列c1具有DEFAULT约束,索引提示@{index_hint = i0}要求存在索引i0。但rawDb不包含DEFAULT约束和索引,因此上述查询不能在rawDb上执行。 - Radar不支持返回数据库特定信息的查询,例如返回当前数据库名称的CURRENT_DATABASE函数,在db和rawDb上会返回不同的名称。
- Radar不支持包含非确定性函数的查询,例如RAND函数在不同的执行中返回不同的值。
3.3 Raw Database Construction
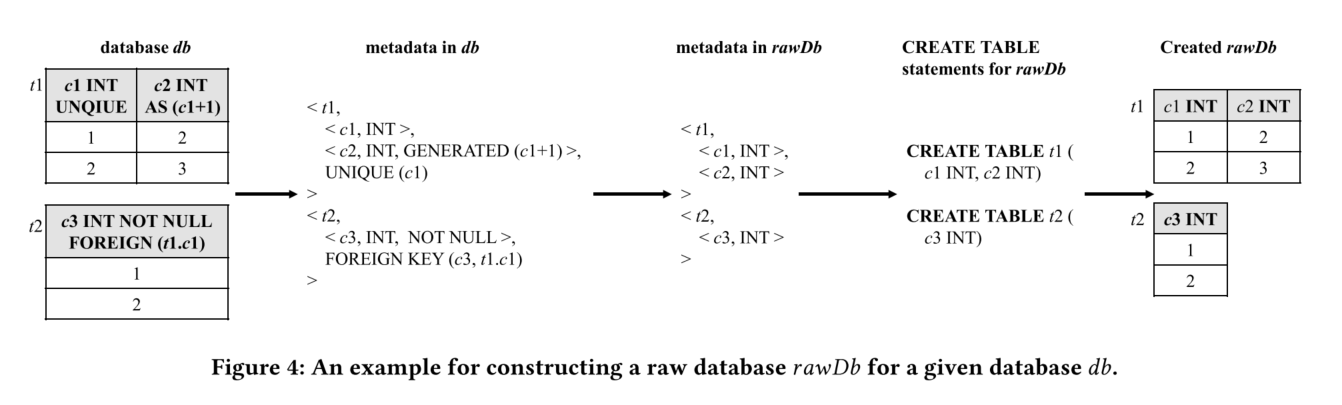
在生成数据库db之后,我们通过清除db中的可选数据库元数据来构建其对应的原始数据库rawDb。本节首先介绍目标DBMS中原始数据库的数据库元数据的正式描述(第3.3.1节),然后解释如何构建给定数据库db的原始数据库rawDb(第3.3.2节)。
3.3.1 Database Metadata in Raw Database
原始数据库只能包含强制性数据库元数据,不能包含任何可选的数据库元数据。图5展示了目标DBMS中原始数据库的元数据的正式描述。原始数据库由一个或多个表组成,每个表包括表名(tName)、一个或多个列,每列包含列名(cName)和数据类型(type)。原始数据库可能包含一些表配置(如MySQL和TiDB中的ENGINE配置),但这些表配置在这些DBMS中是强制性的。

3.3.2 Constructing Raw Databases
对于给定数据库db,我们首先通过执行CREATE DATABASE语句创建一个空数据库作为其对应的原始数据库rawDb。然后,我们从db中获取元数据,并根据图5的描述构建rawDb的元数据,最后创建对应的表并将数据从db复制到rawDb中。
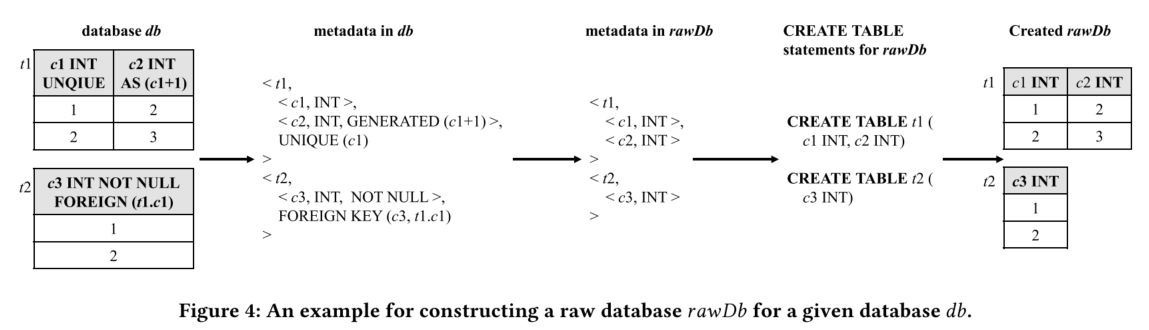
步骤如下(都是具体实现):
提取并复制数据到rawDb:
- 根据rawDb中的元数据,首先构建对应的
CREATE TABLE语句并在rawDb上执行这些语句。 - 将db中的表数据复制到rawDb的对应表中。不同DBMS对跨数据库引用的支持不同,我们采用两种解决方案:
- 对于支持跨数据库引用的DBMS(如MySQL、MariaDB、CockroachDB和TiDB),直接使用
INSERT INTO SELECT语句将数据从db中的表复制到rawDb中的表。 - 对于不支持跨数据库引用的DBMS(如SQLite),首先将db中的表克隆到rawDb(例如,将表t1克隆为t1new),然后将这些克隆表重命名为rawDb中的对应表。接着,使用
INSERT INTO SELECT语句将数据从t1new复制到rawDb中的t1,最后删除克隆表(如t1new)。
- 对于支持跨数据库引用的DBMS(如MySQL、MariaDB、CockroachDB和TiDB),直接使用
3.4 metaBug Identification
对于在3.2.2节生成的查询Q,在数据库db及其对应的原始数据库rawDb上执行Q应返回相同的查询结果。
我们应用算法3来识别metaBugs。首先在数据库db和rawDb上执行查询Q,以获取它们的返回结果,包括查询结果Rdb和RrawDb,以及错误消息Edb和ErawDb(第2-3行)。然后分别比较查询结果和错误消息以识别metaBugs。如果db和rawDb返回不同的查询结果或不同的错误消息,则在目标DBMS中揭示出潜在的metaBug(第4-5行)。注意,我们在比较查询结果时忽略结果集中项目的顺序。
3.5 Metadata-Oriented Testing Optimization
随机数据库生成(第3.2.1节)可以生成许多具有相同或相似元数据的数据库。在这些相似数据库上进行测试通常会触发重复的metaBugs,难以发现新的metaBugs。为了提高测试效率,避免测试具有相似元数据的数据库,我们识别这些数据库并提高测试效率,快速发现更多的metaBugs。 (类似于去重)
3.5.1 Extracting Abstract Database Metadata
对于给定的数据库db,我们移除表名和列名等具体信息。从db的元数据中提取列名和列约束(如数据类型、约束类型)。然后,构建抽象元数据。这样可以生成一个没有具体表名和列名的抽象数据库元数据。如果db的抽象元数据没有被测试过,则继续在db上测试。否则,丢弃db并重新生成新数据库。
3.5.2 Choosing Interesting Databases
我们维护一个已测试的抽象元数据集。通过比较db的抽象元数据与已记录的抽象元数据,判断是否需要测试。如果抽象元数据没有被测试过,则继续测试db并将其抽象元数据加入已测试集。我们只比较抽象元数据中的相同元素,忽略顺序,因为顺序通常与元数据相关的查询优化无关。
Evaluation
我们在五个DBMS上实现了Radar,即MySQL、SQLite、MariaDB、CockroachDB和TiDB。Radar主要包括三个部分,即数据库和查询生成、原始数据库构建和元数据导向的测试优化。数据库和查询生成基于SQLancer在Java中实现。我们用179行代码实现了原始数据库构建和元数据导向测试优化的通用逻辑。为了测试目标DBMS,我们分别用261、192、161、243和431行代码实现了MySQL、SQLite、MariaDB、CockroachDB和TiDB的特定测试逻辑。
我们通过回答以下三个研究问题来评估Radar的有效性:
- RQ1. Radar可以在现实世界的DBMS中检测到哪些metaBugs?
- RQ2. Radar中元数据导向的测试优化的效果如何?
- RQ3. Radar检测到的错误有多少可以被现有方法发现?
4.1 Experiment Setup
目标DBMS
我们在五个广泛使用的DBMS上评估Radar。这些DBMS的具体版本如下:
- MySQL 8.0.32
- SQLite 3.41.0
- MariaDB 11.0.3
- CockroachDB 22.2.5
- TiDB 6.6.0
当目标DBMS发布新版本时,我们会更新到最新版本并进行测试。
实验基础设施
我们在一台配备8个CPU核心和32GB RAM的机器上执行实验。我们通过Docker容器部署MySQL和MariaDB,通过官方命令行工具tiup playground以分布式方式部署TiDB,嵌入SQLite,并使用CockroachDB的三节点集群。
实验过程
我们在每个目标DBMS上运行Radar 24小时,然后将生成的错误报告提交给DBMS开发人员。在生成错误报告后,我们开始新一轮测试。
对于每个生成的错误报告,我们首先使用SQLancer的语句级别和语法级别减少技术自动简化错误报告。具体步骤如下:
- 简化数据库db和rawDb:通过移除某些语句或替换常量等方法减少语句或表达式。
- 如果错误仍然存在,则恢复更改并尝试另一种简化方法,直到无法进一步简化。
然后,我们根据抽象数据库元数据和SQL特性自动聚类错误报告。如果两个简化错误报告包含相同的抽象数据库元数据和SQL特性,我们认为它们是重复的。最后,我们手动分析聚类后的错误报告并识别独特的错误。
4.2 Bug Detection Capability of Radar

为了评估Radar的有效性并回答RQ1,我们在目标DBMS上运行Radar,调查其是否能在这些DBMS中检测到真实世界的元数据相关逻辑错误(metaBugs)。我们分别在每个目标DBMS上运行Radar,总共运行了24小时。
错误检测结果
- Radar总共生成了1,663份错误报告。我们按照4.1节中提到的步骤来简化和删除重复的错误报告。筛选出42个独特的错误花费了大约三周时间。
- 我们将这42个独特错误提交给相应的DBMS开发社区。提交的错误中有4个在MySQL,8个在SQLite,1个在MariaDB,2个在CockroachDB和1个在TiDB。
- 错误状态:提交的42个错误中,38个已被确认是新错误,16个已被DBMS开发人员修复。剩余的4个metaBugs中,有3个被认为是重复报告,1个被认为是误报。
- 错误严重性:在确认的38个错误中,有34个被分类为严重(critical),例如MySQL中的2个错误被分类为严重。MariaDB开发人员将1个错误分类为严重。TiDB开发人员将4个错误分类为严重,12个分类为重大,18个分类为中等。
metaBug分析
- 30个确认的38个错误是metaBugs:包括MySQL中的3个、SQLite中的12个、MariaDB中的1个、TiDB中的2个。剩余的8个不是metaBugs,因为它们在db和rawDb上的查询结果一致。
- 23个metaBugs发生在包含可选数据库元数据(如完整性约束和索引)的生成数据库中,这些元数据在rawDb中被禁用。7个metaBugs发生在不包含任何可选元数据的生成数据库中。
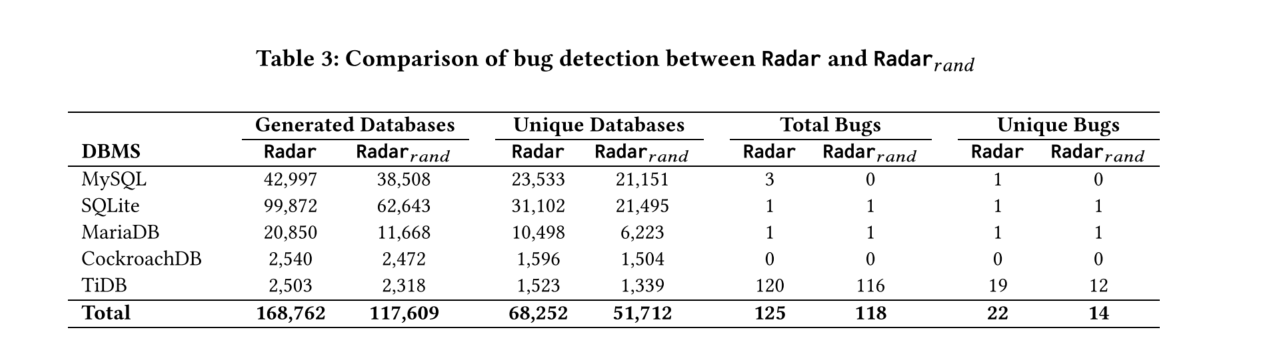
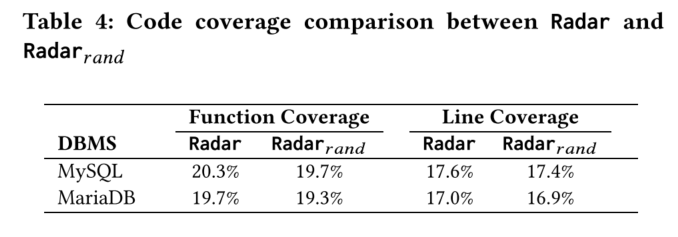
图表分析
- 表3比较了Radar和Radar_rnd在错误检测方面的表现。Radar在生成数据库、独特数据库和检测到的独特错误方面都表现出色。
- 表4比较了两者的代码覆盖率。Radar在测试中覆盖了更多的代码路径。
这些结果显示了Radar在检测元数据相关逻辑错误方面的高效性和有效性。
4.3 Effectiveness of Metadata-Oriented Testing Optimization
为了回答RQ2,我们在实现Radar之后,移除了元数据导向的测试优化,进行对比实验。
错误检测
我们在MySQL、SQLite、MariaDB、CockroachDB和TiDB上分别运行Radar和Radar_rnd 12小时。实验中,我们统计生成的数据库、总错误和独特错误的数量。如果数据库包含相同的抽象数据库元数据,我们认为生成的数据库是重复的,并使用4.1节中的方法筛选独特错误。
- Radar能有效消除45.2%、68.8%、49.6%、37.1%和39.1%的重复数据库。
- Radar比Radar_rnd生成更多独特数据库,分别多11.2%、44.6%、40.7%、6.1%和13.7%。
- Radar检测到比Radar_rnd多7个独特错误,分别多8个独特错误。
我们的实验结果表明,元数据导向的测试优化策略有助于在更少的时间内检测到更多的metaBugs。
代码覆盖率
我们分析了MySQL和MariaDB在12小时测试中的代码覆盖率,包括函数覆盖率和行覆盖率。
- Radar在MySQL中的函数覆盖率为20.3%,行覆盖率为17.6%;在MariaDB中的函数覆盖率为19.7%,行覆盖率为17.0%。
- Radar_rnd在MySQL中的函数覆盖率为19.7%,行覆盖率为17.4%;在MariaDB中的函数覆盖率为19.3%,行覆盖率为16.9%。
虽然代码覆盖率略低,但这些覆盖率主要关注验证查询引擎的正确性,特别是元数据相关的查询优化。Radar能够覆盖目标DBMS中更广泛的功能和代码行。
4.4 Comparing with Existing Approaches
为了回答RQ3,我们将Radar与四种最先进的DBMS逻辑错误检测方法(DQE、NoREC、TLP和MutaSQL)进行比较。这些方法都采用随机策略测试DBMS,包括随机数据库生成和查询生成。我们首先调查Radar检测到的30个确认metaBugs是否可以被这些方法检测到,然后在目标DBMS上应用Radar和现有方法,比较其错误检测结果。
现有方法在概念上最多可以检测到我们确认的30个metaBugs中的13个。具体比较如下:
- DQE:通过识别执行结果中的不一致来检测错误。由于构建了UPDATE和DELETE语句,DQE可以检测到8个metaBugs。
- NoREC:将优化后的查询转换为非优化查询,并比较执行结果。NoREC可以检测到13个metaBugs。
- TLP:通过将查询分解为三个子查询并比较结果来检测错误。TLP可以检测到3个metaBugs。
- MutaSQL:通过添加索引并观察查询结果变化来检测错误。MutaSQL可以检测到5个metaBugs。
实验比较
我们应用DQE、NoREC、TLP和Radar在目标DBMS上分别运行12小时,使用相同的方法去重错误报告和识别独特错误。表6显示了实验结果:
- 所有方法共检测到33个错误,其中21个是Radar在4.2节中检测到的metaBugs。
- 剩余的12个错误是其他类型的错误(如UPDATE或DELETE语句中的逻辑错误和错误)。
- Radar检测到了21个metaBugs中的20个,其中15个metaBugs仅被Radar检测到。
- 替代方法检测到21个metaBugs中的6个。
- 唯一一个Radar未检测到的metaBug,是因为Radar未生成相应的测试用例来随机数据库和查询生成。
metaBugs是由于数据库元数据相关的错误优化而引入的。尽管现有方法可以有效检测其他类型的逻辑错误,但不能有效检测metaBugs。
4.5 Other Experimental Statistics
查询测试效率
我们通过在目标DBMS上分别运行Radar 12小时,并统计测试的查询数量来衡量查询测试效率。在此实验中,Radar在MySQL、SQLite、MariaDB、CockroachDB和TiDB上每秒分别测试了118、4、795、948、132和280个查询。
原始数据库构建的开销
我们通过在目标DBMS上分别运行Radar 12小时来衡量原始数据库构建的开销。在此实验中,Radar平均花费95ms、33ms、34ms、2ms、645ms和877ms来构建MySQL、SQLite、MariaDB、CockroachDB和TiDB的原始数据库。
4.6 Representative Bugs