Testing Database Engines via Query Plan Guidance
Testing Database Engines via Query Plan Guidance
ABSTRACT
摘要——数据库系统被广泛用于存储和查询数据。测试预言机(test oracles)已被提议用于发现这些系统中的逻辑错误,即导致数据库系统计算出错误结果的错误。为了实现完全自动化的测试方法,这些测试预言机与测试用例生成技术相结合;测试用例指的是数据库状态和可应用测试预言机的查询。在这项工作中,我们提出了查询计划引导(QPG)的概念,用于引导自动化测试朝向“有趣”的测试用例。SQL和其他查询语言是声明式的。因此,为了执行查询,数据库系统将源语言中的每个操作符翻译为一个或多个可以执行的所谓物理操作符;物理操作符的树被称为查询计划。我们的直觉是,通过引导测试去探索各种独特的查询计划,我们也会探索更多有趣的行为——其中一些可能是错误的。为此,我们提出了一种变异技术,逐步将有希望的变异应用于数据库状态,从而导致数据库管理系统(DBMS)为后续查询创建潜在的未见过的查询计划。我们将我们的方法应用于三个成熟的、广泛使用且经过广泛测试的数据库系统——SQLite、TiDB和CockroachDB——并发现了53个独特的、以前未知的错误。我们的方法比简单的随机生成方法多行使了4.85至408.48倍的独特查询计划,比代码覆盖引导方法多行使了7.46倍的独特查询计划。由于大多数数据库系统(包括商业数据库)都向用户公开查询计划,我们认为QPG是一种普遍适用的黑箱方法,并相信这一核心理念也可以应用于其他情境(例如,衡量测试套件的质量)。 关键词——自动化测试,测试用例生成
INTRODUCTION
背景
数据库管理系统的重要性:数据库管理系统(DBMSs)广泛用于存储、检索和运行数据查询,几乎在每一个计算设备中都能找到它们的身影。
逻辑错误的挑战:逻辑错误是指数据库系统返回错误结果的情况,这类错误特别难以发现,因为它们会悄无声息地计算出错误结果。
测试预言机的作用:找到逻辑错误需要测试预言机(test oracle),用来验证数据库管理系统的结果。近年来,已经提出了一些有效的测试预言机,使得验证此类查询结果成为可能。
测试用例生成方法的需求:自动发现逻辑错误需要测试用例生成方法,测试用例指的是一个数据库状态和一个可以应用测试预言机的查询。
测试用例生成面临的挑战:
- 生成“有趣的”测试用例,以增加发现错误的机会。
- 测试用例在语法和语义上都应当是有效的,同时要符合测试预言机施加的结构约束。
相关工作
- 基于生成的方法:
- SQLancer:采用基于生成的方法,生成的测试用例遵循各自SQL方言的语法以及测试预言机施加的约束。有效查询率约为90%。
- 缺点:没有引导生成有趣的测试用例。
- 基于变异的方法:
- SQLRight:通过变异测试用例,旨在最大化DBMS的代码覆盖率。改进了SQLancer的多个指标,但有效查询率仅为40%。
- 缺点:仅凭代码覆盖率作为代理指标对于DBMS和有状态系统来说是不完美的。
- 其他测试用例生成方法:一些方法旨在发现崩溃错误,忽略了测试预言机的约束,包括:
- 基于变异的方法:如Squirrel和DynSQL。
- 基于生成的方法:如SQLsmith和RAGS。
Motivation Example:
- 查询计划是描述DBMS如何执行SQL语句的操作树,通常通过EXPLAIN语句获得。查询计划提供了查询执行的高层次概述,覆盖更多独特的查询计划可以增加发现逻辑错误的可能性。

Key insight:
- 提出了一种利用查询计划引导测试用例生成过程的技术,称为查询计划引导(QPG)。通过改变数据库状态而非查询来生成有效的查询,从而满足测试预言机的约束。
- 使用SQLancer的随机语法生成方法生成查询,并记录所有查询计划。当观察不到新的查询计划时,通过变异数据库状态来生成新的查询计划。
具体实现:
- 将选择最有希望的变异操作(修改数据库状态的SQL语句)的决策过程建模为多臂赌博机问题(multi-armed bandit problem),优先选择能生成最多新查询计划的SQL语句。
- 在SQLancer中实现QPG,并在SQLite、TiDB和CockroachDB上进行了评估。
研究结果:
- 发现了53个独特的、以前未知的错误,其中35个已被修复。
- 其中三个错误在SQLite中隐藏了超过六年,尽管SQLancer和SQLRight已经进行了广泛的测试。
- 触发许多错误需要复杂的查询计划,新发现错误的平均查询计划长度是之前错误的2.47倍。
- QPG方法在24小时内覆盖的独特查询计划比SQLancer和SQLRight多4.85至408.48倍。
贡献:
- 研究了之前发现错误的查询计划,以评估该思想的潜力。
- 提出了一种利用查询计划进行测试的普遍方法。
- 提出了一种变异数据库状态而非查询的具体测试方法,以兼容现有的测试预言机。
- 实现并评估了该方法,发现了53个独特的、以前未知的错误。
BACKGROUND
数据库管理系统:
- 数据库管理系统(DBMSs)在应用程序和后台数据之间充当接口,帮助用户存储、操作和查询数据。
- 关系数据模型是最常见的模型,本文重点测试此类关系型数据库管理系统。
结构化查询语言(SQL):
- SQL是与关系型数据库管理系统交互的最常用语言,已被ISO/IEC 9075标准化。
- SQL包含多种类型的语句,可分为三个主要子语言:
- 数据查询语言(DQL):提供SELECT语句用于查询数据。
- 数据定义语言(DDL):用于创建和修改数据对象的模式,例如CREATE、DROP和ALTER语句。
- 数据操作语言(DML):用于修改数据对象的内容,例如INSERT和UPDATE语句。
- 虽然DDL和DML语句会影响数据库状态,但查询(即DQL语句)通常不会。本文的测试用例包括DQL、DDL和DML语句。
查询计划:
- 查询计划是一棵描述SQL语句如何由特定DBMS执行的操作树。
- 大多数成熟的关系型DBMSs(包括DB-Engines排名前10的数据库)允许用户通过在查询前添加EXPLAIN来查询查询计划的文本表示。
- 查询计划可能包括额外信息,如估计成本或WHERE子句中使用的谓词表达式。
- 数据库文献区分了逻辑查询计划和物理查询计划。逻辑查询计划与原始声明性查询紧密对应,而物理查询计划则将每个逻辑操作符映射到DBMS可以执行的物理操作符。
逻辑错误:
- 逻辑错误是指导致系统计算错误结果的错误。
- 最近,有效的测试预言机被提出,用于发现广泛使用的DBMSs中的大量独特错误。
- 本文使用了最新的测试预言机,包括三值逻辑分区(TLP)和非最优参考引擎构建(NoREC)。
研究方法:
- 使用查询计划以黑箱方式引导测试,而不考虑操作符的语义。
- TLP通过将查询分成多个更复杂的查询来检查其结果是否相同。
- NoREC检查DBMS可能优化的查询中使用的谓词的结果是否一致。
QUERY PLAN STUDY
调查使用查询计划作为测试引导的潜力,研究之前发现的错误中查询的独特性和复杂性。
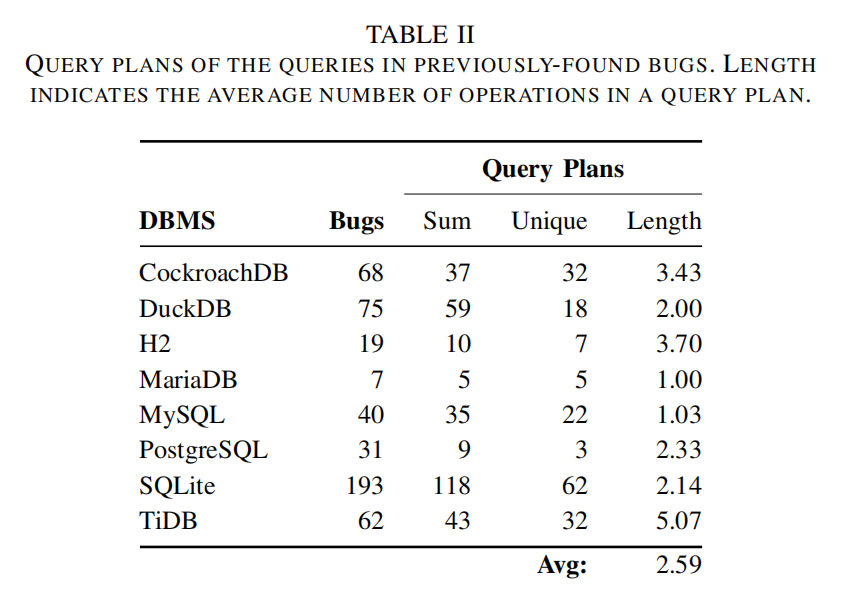
研究方法:
- 使用SQLancer提供的公开错误报告,对这些报告中的499个错误进行分析。
- 从这些报告中排除了4个未公开查询计划的DBMS(如TDEngine)。
- 获取查询计划:为所有495个引发错误的测试用例,使用EXPLAIN语句获取查询计划。不同的DBMS可能包括各种附加辅助信息(如估计成本、WHERE子句中的表达式、随机标识符等),这些信息在处理时被排除。
独特性分析:
- 获得316个查询计划,其中57.28%是独特的。
- 不同DBMS中的独特查询计划比例不同,最小为DuckDB(30.51%),最大为MariaDB(100.00%)。
- 结果表明,覆盖更多不同查询计划可能增加发现错误的可能性。
复杂性分析:
- 复杂查询计划通常对应复杂的数据库状态或查询。例如,在SQLite中,从两个表中检索数据的查询计划至少需要三个操作(SCAN、MERGE)。
- 表II中的数据显示,平均每个查询计划的操作数为2.59,表明大多数错误相关的查询计划是紧凑的。
- 发现跨八个DBMS最频繁的查询计划是SCAN table t0,表示在单个表上进行顺序扫描,不使用索引。
研究结论:
- 之前发现的错误中的查询计划通常是紧凑和简单的,平均操作数为2.59。
- 虽然这可能表明简单的查询计划足以触发这些错误,但也可能是现有方法集中在简单查询和数据库状态上的结果。
- 推测覆盖更复杂的查询计划可能增加发现错误的可能性。
APPROACH
提出使用查询计划引导(QPG)来变异数据库,生成更多独特且复杂的数据库状态,以高效检测数据库管理系统(DBMSs)中的逻辑错误。
方法原理:
- 查询计划反映了DBMS对给定查询的内部执行逻辑。
- 覆盖更多独特的查询计划可以增加发现逻辑错误的可能性。
- 与简单的随机生成方法相比,QPG逐步变异数据库状态,使后续查询能够覆盖更多独特且复杂的查询计划。
选择变异数据库状态的原因:
- 测试预言机对查询有各种约束,使用变异方法难以满足这些约束。
- QPG变异数据库状态,而不是直接变异查询。
方法优势:
- 与其他基于覆盖率的灰盒测试工具(如Squirrel和SQLRight)相比,QPG是黑盒测试方法,不需要访问DBMS的源代码。
- 使用成熟DBMSs提供的信息,可以应用于商业闭源DBMSs。
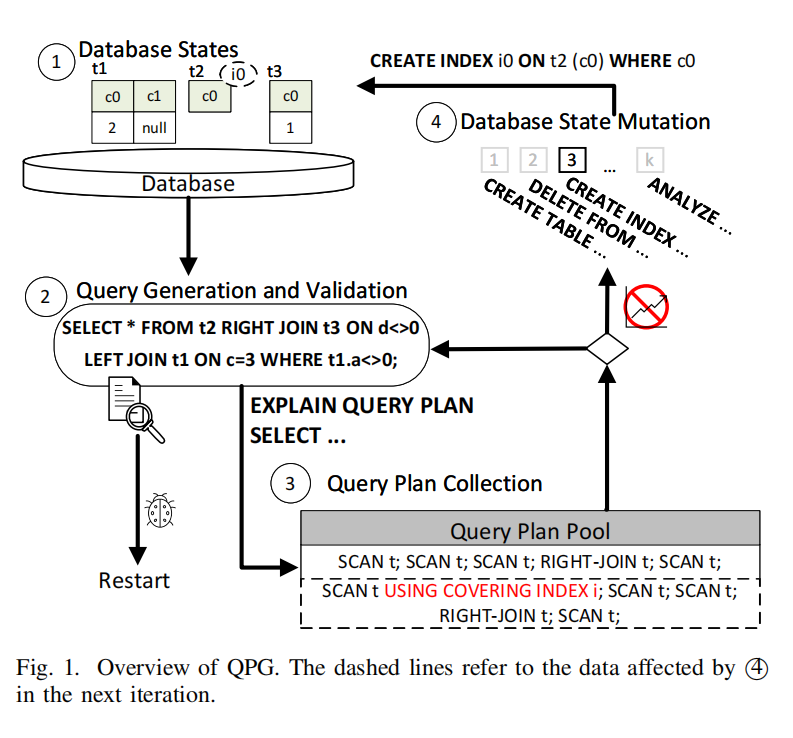
Overview
图1展示了基于列表1的QPG实现概述。在给定初始数据库状态(标记为1)的情况下,QPG在步骤2生成一个随机SQL查询,并在数据库上执行,以使用测试预言机验证查询的结果。如果预言机指示存在错误,QPG输出错误报告并重新启动测试过程。否则,它记录查询计划并将其添加到查询计划池中(标记为3)。通常情况下,执行会在相同的数据库状态下继续进行。然而,如果在固定次数的迭代后没有观察到新的独特查询计划,QPG将在步骤4通过对当前数据库状态应用变异操作符来变异数据库状态以创建新的数据库状态,假设这个新的状态将随后导致探索新的独特查询计划。
A. Database States.
初始数据库状态生成:
- 初始数据库状态可以随机生成或手动给定。
- 在实现中,通过随机执行DDL和DML语句生成初始数据库状态。
避免空数据库状态:
- 为了避免生成空的数据库状态,首先执行CREATE TABLE语句。
- 例如,为了创建图1中的初始数据库状态,执行List 1中的第1至5行。
不直接操作数据库文件:
- 由于数据库文件结构高度复杂,不直接操作数据库文件。
- 任何意外字节可能导致错误,从而妨碍测试过程。
B. Query Generation and Validation.
查询生成:
- 生成的查询用于自动验证结果以发现错误。
- 生成的查询必须符合两个主要约束:
- 语义有效性:查询必须在语义上对数据库状态有效,例如,只能引用存在的表和视图。
- 预言机约束:必须符合测试预言机施加的约束,例如NoREC预言机要求查询包含WHERE子句,但禁止HAVING或GROUP BY等其他子句。
- 为了满足这些约束,采用SQLancer的基于规则的随机生成方法,根据SQL方言的语法生成查询。
验证:
- 使用最先进的逻辑错误预言机NoREC和TLP来验证查询结果。
- 这些预言机使用变形测试方法,根据给定查询导出另一个查询,并用其结果集来验证原始查询的结果。
- 例如,在图1中,给定三个表和测试预言机,生成查询并验证返回的结果是否正确。如果预言机表明结果正确,执行继续;如果预言机表明存在错误,输出错误报告并重新启动测试过程。
C. Query Plan Collection.
查询计划的获取:
- 通过使用EXPLAIN语句对查询进行检测来收集查询计划。
- 示例中,使用
EXPLAIN QUERY PLAN SELECT * FROM t2 RIGHT JOIN t3 ON d<>0 LEFT JOIN t1 ON c=3 WHERE t1.a<>0获取查询计划,并移除表和索引的名称。
查询计划池:
- 查询计划池存储独特的查询计划,使用哈希表实现,键是查询计划,值是对应的查询字符串。
- 给定一个查询计划,检查其是否已存在于池中,如果不存在则插入。
操作逻辑:
- 初始时,查询计划池为空,首次获取的查询计划会被插入池中。
- 如果在固定数量的查询后没有新的查询计划插入池中,则对数据库状态进行变异,以促使DBMS探索更多独特的查询计划。
- 否则,继续使用相同的数据库状态测试DBMS。
- 默认情况下,这个固定数量设定为1000,这是基于经验确定的。
D. Database State Mutation.
变异触发条件:
- 如果在固定数量的查询后没有新的查询计划插入池中,则触发数据库状态变异。
- 目的是通过操纵数据库状态,使DBMS探索更多独特的查询计划。
变异操作符:
- 采用与生成初始数据库状态相同的DDL和DML语句,如CREATE TABLE、CREATE INDEX和ANALYZE。
- 关键挑战是应用有希望的变异,以触发新的查询计划。
决策建模:
- 变异操作符的选择被建模为多臂赌博机(MAB)问题,目标是最大化覆盖的独特查询计划数。
- 使用已知增益(exploitation)和探索增益(exploration)来优化决策。
- 采用经典的贪婪算法,选择预期增益最高的操作符,并以一定概率随机选择其他操作符。
增益计算:
- 已知增益:基于每个操作符在所有迭代中的加权平均增益计算。
- 即时增益:测量最新数据库状态下查询探索新查询计划的比例。
过程示例:
- 例如,应用变异操作符CREATE INDEX t0 ON t2(c)。
- 生成新的查询并观察到新的查询计划,然后将其插入查询计划池并进行验证。
- 如果发现错误,则输出错误报告;否则,继续测试或变异。
数据库状态清理:
- 在测试了一定数量的查询后,清理数据库状态并重启测试过程,以探索更多独特的查询计划。
通过这些步骤,QPG通过变异数据库状态有效地引导DBMS探索和验证更多复杂和独特的查询计划,从而提高发现逻辑错误的可能性。
变异数据库状态的过程举例:
假设我们有一个初始数据库状态,其中包含两个表
t1和t2,表结构如下:
2
3
4
5
CREATE TABLE t2 (c INT, d INT);
// 初始数据库状态已经填充了一些数据:
INSERT INTO t1 VALUES (1, 2), (3, 4);
INSERT INTO t2 VALUES (5, 6), (7, 8);QPG生成一个查询:
执行这个查询并验证结果。如果没有发现错误,QPG记录查询计划,并将其添加到查询计划池中。
经过多次查询后,如果没有新的查询计划被发现,QPG决定变异数据库状态。假设变异操作符是
CREATE INDEX,那么可以执行以下变异操作:
这个操作创建了一个索引,可以改变DBMS执行查询的方式,从而生成新的查询计划。
在变异操作后,QPG重新生成一个查询:
由于索引的存在,DBMS可能使用新的查询计划来执行这个查询,例如,利用索引来加速连接操作。QPG再次验证查询结果。如果没有发现错误,则记录新的查询计划并将其添加到查询计划池中。如果发现错误,则输出错误报告。
如果再次触发变异操作,QPG可能会选择其他DDL或DML语句。例如,添加新列:
或是插入新的数据:
通过这些变异操作,QPG不断改变数据库状态,生成新的查询计划,从而提高发现逻辑错误的机会。
查询计划池的作用是?
唯一性检测:查询计划池存储所有已生成的查询计划,并用于检测新生成的查询计划是否独特。通过检查新查询计划是否已存在于池中,确保测试过程探索新的数据库行为。
变异触发:如果在一定数量的查询后,查询计划池中没有新增的独特查询计划,QPG会触发数据库状态的变异操作。这样可以促使DBMS生成新的查询计划,从而提高发现错误的可能性。
如何选择变异操作符?
变异操作符的选择被建模为一个多臂赌博机(Multi-Armed Bandit,MAB)问题。在这个模型中,每个变异操作符被视为一个臂,选择一个操作符的过程类似于选择一个臂进行赌博。目的是通过选择适当的操作符,使得探索到更多独特的查询计划,从而最大化测试覆盖率和错误发现的概率。
增益选择:选择变异操作符时,使用一种贪婪算法来平衡已知增益和即时增益。
已知增益(Exploitation):这是基于历史数据计算的每个操作符的加权平均增益,反映了过去该操作符的效果。
即时增益(Exploration):这是当前选择操作符后立即观察到的新查询计划数目,用于衡量当前操作符的即时效果。
一个例子:
假设有三个变异操作符:
CREATE INDEXINSERT INTOALTER TABLE初始状态:
- 已知增益初始值:
- μ^1(0)=0.0\hat{\mu}_1(0) = 0.0μ^1(0)=0.0
- μ^2(0)=0.0\hat{\mu}_2(0) = 0.0μ^2(0)=0.0
- μ^3(0)=0.0\hat{\mu}_3(0) = 0.0μ^3(0)=0.0
- 探索概率 eee = 0.1
执行步骤:
- 选择操作符:
- 使用决策函数选择操作符,初始选择是随机的,因为已知增益都为0。
- 假设随机选择了操作符
CREATE INDEX。- 应用操作符:
- 执行变异操作:
CREATE INDEX idx_t1_a ON t1(a)- 生成新查询并记录即时增益 QQQ,假设发现2个新查询计划。
- 更新已知增益:
- 使用即时增益更新已知增益,公式为:μ^i(t+1)=μ^i(t)+(Q−μ^i(t))⋅w\hat{\mu}_i(t+1) = \hat{\mu}_i(t) + (Q - \hat{\mu}_i(t)) \cdot wμ^i(t+1)=μ^i(t)+(Q−μ^i(t))⋅w
- 假设权重 w=0.1w = 0.1w=0.1,则更新后的已知增益为: μ^1(1)=0.0+(2−0.0)⋅0.1=0.2\hat{\mu}_1(1) = 0.0 + (2 - 0.0) \cdot 0.1 = 0.2μ^1(1)=0.0+(2−0.0)⋅0.1=0.2
- 继续选择操作符:
- 在下一轮中,使用决策函数选择操作符,这次选择可能会偏向于
CREATE INDEX,因为其已知增益较高。- 再次执行变异操作,记录即时增益并更新已知增益。
E. Implementation
实现平台:
- 在SQLancer中实现了描述的QPG方法,并将其原型称为SQLancer+QPG。
- 更新了SQLancer以支持SQLite的最新版本,该版本具有三个新特性:RIGHT JOIN、FULL OUTER JOIN和STRICT。
代码实现:
- 实现方法使用大约1000行Java代码。
- 针对每个DBMS的特定组件进行了额外100行Java代码的适配,例如定义收集查询计划的具体语句。
兼容性设计:
- 设计该方法以兼容现有测试工具。
- 对于数据库状态生成和查询生成与验证步骤,重用了SQLancer的实现。
- 在数据库状态变异步骤中,作为一个独立模块实现了算法,可在不同DBMS中重用。
变异操作符:
- 使用SQLancer支持的DDL和DML语句作为变异操作符。
- SQLite使用了23种变异操作,TiDB使用了13种,CockroachDB使用了17种。
- 这些变异操作有助于覆盖更多独特的查询计划。
限制和优化:
- 为避免大量表和索引导致的测试吞吐量下降,限制了表和索引的最大数量:最多10个表和20个索引。
EVALUATION
为了评估QPG在发现DBMS错误方面的有效性和效率,我们提出并回答以下问题:
- 新错误:QPG是否能帮助发现新错误?发现这些错误是否需要复杂的查询计划?
- 覆盖独特查询计划:QPG能否比简单随机生成和代码覆盖引导方法覆盖更多独特的查询计划?
- 错误发现效率:QPG能否比简单随机生成和代码覆盖引导方法更高效地发现错误?
- 敏感性分析:QPG的每个组成部分对结果的贡献是什么?在不同配置下,QPG的表现如何?
Test DBMS:
- SQLite:最流行的嵌入式DBMS,用于所有iOS和Android智能手机。
- TiDB和CockroachDB:流行的企业级DBMS,在GitHub上有较多的关注和使用。
Baselines:
- SQLancer:使用简单随机生成方法,是SQLancer+QPG的基准。
- SQLRight:使用代码覆盖引导方法的最先进工具。
DBMS Version
- 最新开发版本:用于Q1、Q2和Q4。
- SQLite:3.39.0
- TiDB:6.3.0
- CockroachDB:23.1
- 历史版本:用于Q3,确保所有工具都已测试并能发现错误的版本。
- SQLite:3.36.0
- TiDB:4.0.15
- CockroachDB:21.2.2
Q.1 New Bugs
总体结果
- 使用SQLancer+QPG共发现了53个新错误,其中35个已被修复。
- 错误分布:
- SQLite:28个逻辑错误,5个崩溃错误。
- TiDB:9个逻辑错误,4个崩溃错误。
- CockroachDB:16个逻辑错误,2个崩溃错误。
查询计划分析
- 查询计划数量:
- SQLite:51个查询计划,其中29个是独特的,平均长度为5.55。
- TiDB:12个查询计划,其中9个是独特的,平均长度为5.67。
- CockroachDB:6个查询计划,全部是独特的,平均长度为7.83。
- 平均查询计划长度为6.35。
发现的复杂性
- QPG成功生成了更复杂的查询计划,暴露了之前隐藏的错误。
- 与表II中查询计划的平均操作数2.59相比,新的错误查询计划的平均长度为6.35,显示了更高的复杂性。

RIGHT JOIN example
- 查询语句的SELECT部分因RIGHT JOIN功能中的不正确优化而返回错误结果。
- 执行逻辑:
- 该查询语句首先执行LEFT OUTER JOIN,将
t4和t3连接,条件为TRUE,这意味着每个t4中的行都会与t3中的所有行连接。 - 然后,结果与
t1进行INNER JOIN,连接条件是t3.c=t。 - 最后,通过WHERE子句过滤结果,条件是
t3.c ISNULL。
- 该查询语句首先执行LEFT OUTER JOIN,将
- 错误根源:
- 错误出现在RIGHT JOIN的优化中,特别是对
ISNULL操作的处理。 - RIGHT JOIN操作应正确处理
t3.c ISNULL的情况,但由于优化问题,返回了不正确的结果。
- 错误出现在RIGHT JOIN的优化中,特别是对
- 影响:
- 由于优化错误,查询返回了包含意外记录的结果集,而正确的结果应当是空的。
JSON example
- 问题:由于对JSON功能中的
json_quote函数的不正确优化,SELECT语句返回空结果。 - 执行逻辑:
- 该查询从视图
v1和表t1中选择数据,并通过WHERE子句过滤结果。 json_quote(b)是一个JSON函数,返回字符串b的JSON表示。- WHERE子句中,条件为
NOT json_quote(b),意味着过滤条件为json_quote(b)返回false的记录。
- 该查询从视图
- 错误根源:
- 错误出现在
json_quote函数的优化过程中。 - 优化器未能正确处理
json_quote函数的结果,导致返回空结果集。
- 错误出现在
- 影响:
- 本应返回符合条件的记录,但由于优化错误,查询结果为空。

Q.2 Covering Unique Query Plans
研究目标
- 评估SQLancer+QPG是否能比简单随机生成和代码覆盖引导方法覆盖更多的独特查询计划。
方法
- 使用TLP预言机,它是唯一支持所有DBMS的测试预言机。
- 每15分钟记录一次查询计划,移除表、视图和索引名称以确保唯一性。
- 对TiDB和CockroachDB,由于系统崩溃,只能运行SQLancer+QPG最多6小时。
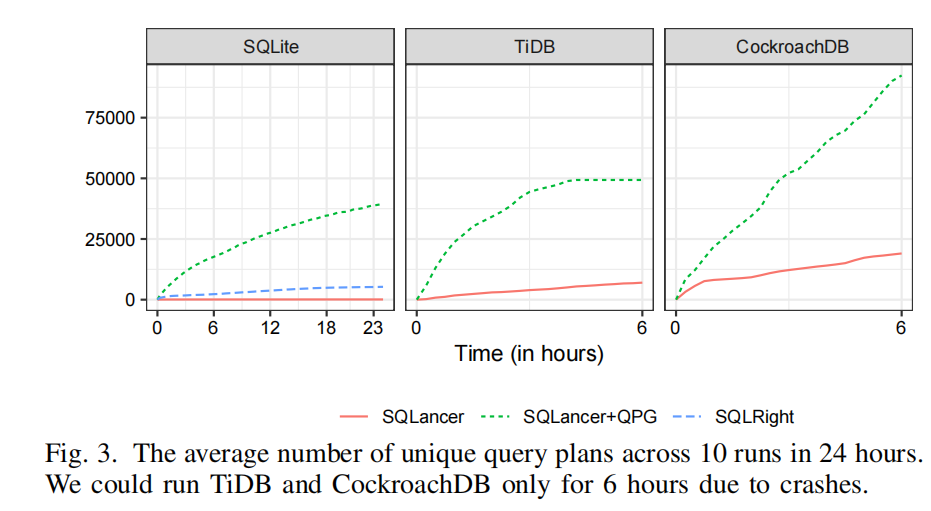
结果
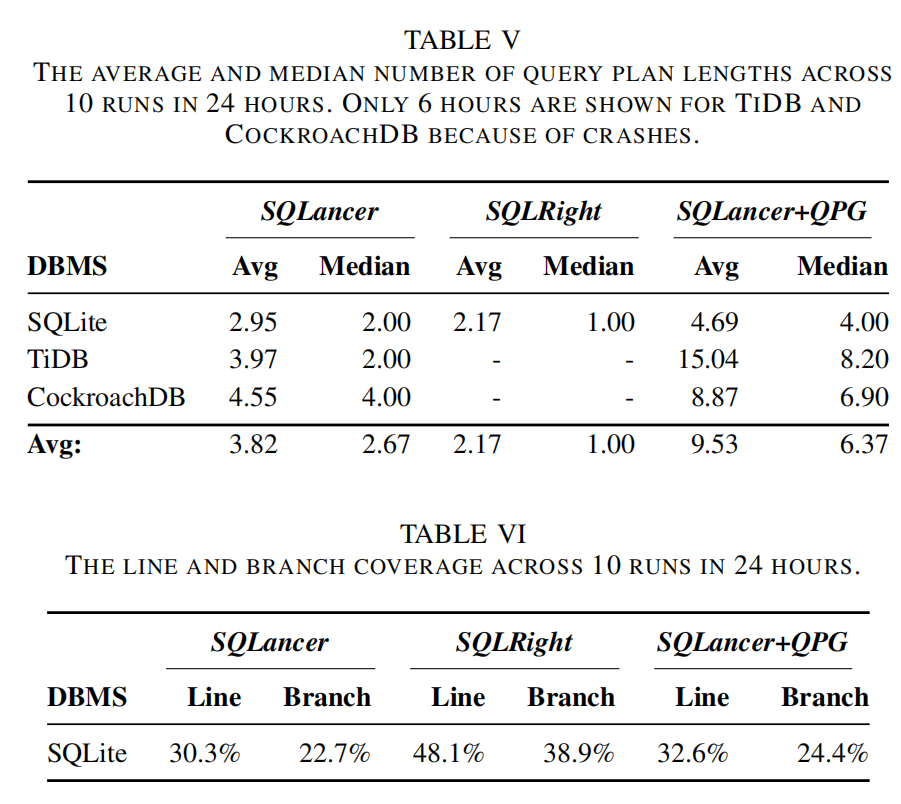
- 图3显示了10次运行中每24小时内所有工具覆盖的独特查询计划的平均数量。
- SQLancer+QPG明显优于SQLancer和SQLRight。
- SQLancer+QPG的独特查询计划覆盖率是SQLancer的4.85到408.48倍,是SQLRight的7.46倍。
- 表IV显示了新发现错误的查询计划的平均长度:
- SQLite:5.55
- TiDB:5.67
- CockroachDB:7.83
- 平均:6.35
统计分析
使用Vargha-Delaney
和Wilcoxon秩和检验比较SQLancer+QPG与SQLancer的随机测试结果。
- 对于两种度量,A^12=1\hat{A}_{12} = 1A^12=1且 U<0.05U < 0.05U<0.05 表明SQLancer+QPG显著优于SQLancer。
- 结果表明SQLancer+QPG在所有DBMS中连续生成显著更多的独特查询计划和复杂数据库状态。
结论
- SQLancer+QPG能够有效覆盖更多独特和复杂的查询计划,显著提高了发现数据库管理系统中逻辑错误的可能性和效率。
- 尽管SQLancer+QPG不以最大化代码覆盖率为目标,但由于覆盖了更多独特查询计划,仍在代码覆盖率上优于SQLancer。
Q.3 Bug Finding Efficiency
研究目标
评估SQLancer+QPG在发现错误方面是否比SQLancer和SQLRight更高效。
实验方法
- 使用TLP预言机运行SQLancer+QPG、SQLancer和SQLRight各24小时。
- 使用基于堆栈跟踪的工具区分唯一错误:
- 崩溃错误:堆栈跟踪相同的认为是重复的崩溃错误。
- 错误消息:错误消息相同的认为是重复的错误。
- SQL结构:仅包含RIGHT JOIN和GROUP BY子句的SQL结构相同的认为是重复的错误。
- 未重新启动测试过程,以避免不公平地影响SQLancer+QPG的数据库状态变异策略。
结果
- 表VII显示了10次运行中发现的所有错误和唯一错误的总数。
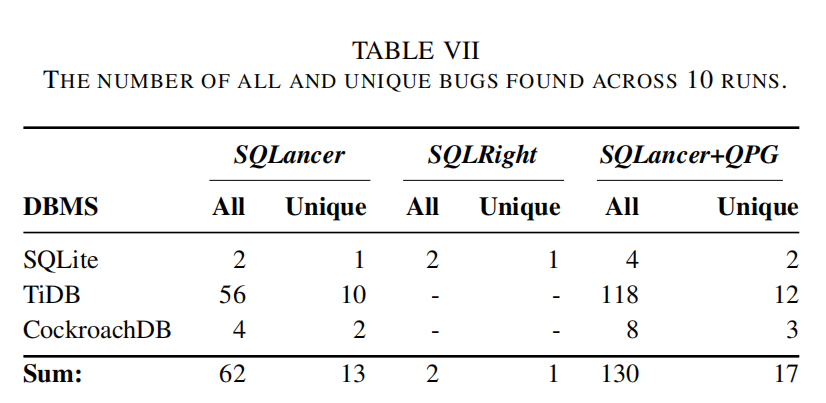 - **SQLancer**:发现了62个错误,其中13个是唯一的。
- **SQLRight**:发现了13个错误,其中2个是唯一的。
- **SQLancer+QPG**:发现了130个错误,其中17个是唯一的。
- **SQLancer**:发现了62个错误,其中13个是唯一的。
- **SQLRight**:发现了13个错误,其中2个是唯一的。
- **SQLancer+QPG**:发现了130个错误,其中17个是唯一的。- 对比分析:
- SQLancer+QPG发现错误的效率比SQLancer高1.4倍,比SQLRight高17倍。
- SQLancer+QPG发现的唯一错误数是SQLancer的1.3倍,是SQLRight的8.5倍。
分析
- SQLancer:使用随机生成方法,发现错误的效率较低。
- SQLRight:使用代码覆盖引导方法,尽管其覆盖率高,但在发现逻辑错误方面不如SQLancer+QPG有效。
- SQLancer+QPG:
- 通过生成更多独特的查询计划和变异数据库状态,提高了错误发现的概率和效率。
- 能够发现更复杂和隐藏更深的错误。
Q.4 Sensitivity Analysis
目标
评估SQLancer+QPG各组件的贡献,通过敏感性分析确定其对整体效果的影响。
算法组件的贡献
- 主要组件:查询计划收集(③)和数据库状态变异(④)。
- 配置:为评估各组件的贡献,设计了新配置SQLancer + QPG_r,只启用查询计划收集(③),并随机应用变异(④)。
结果
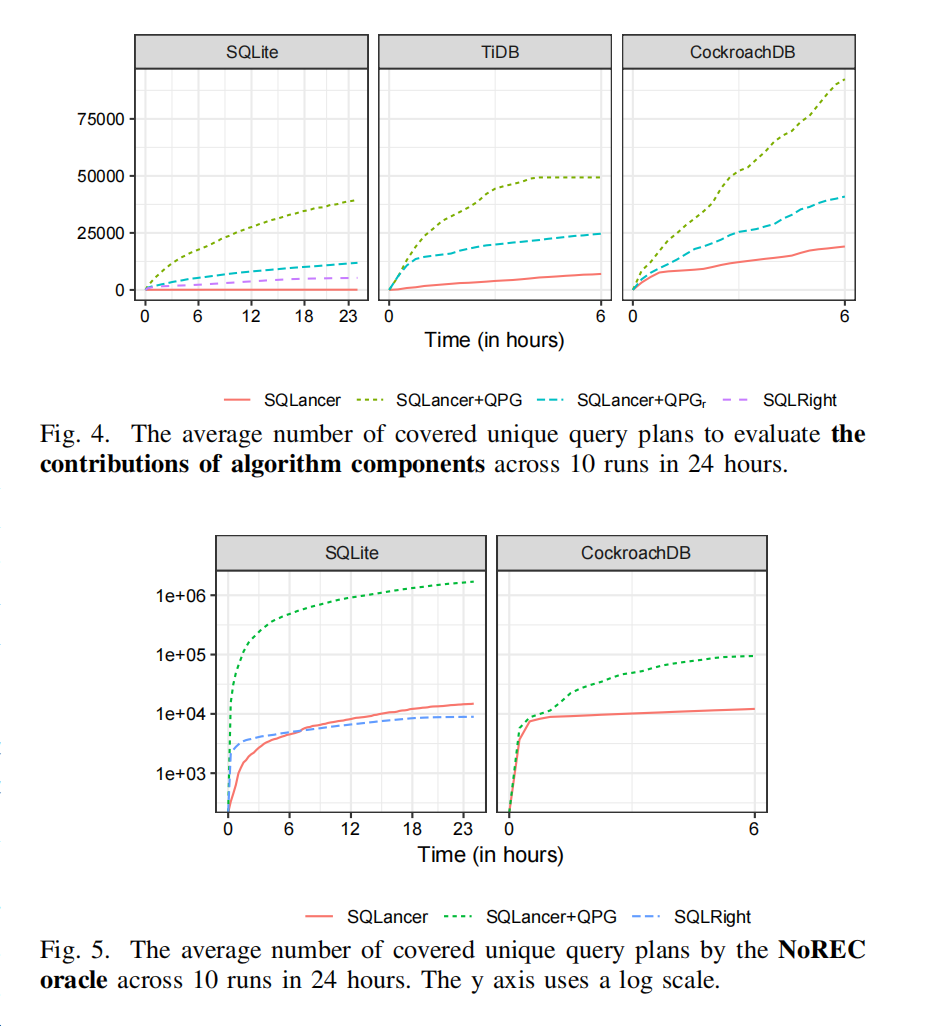
- 图4:显示了10次运行中24小时内TLP预言机覆盖的独特查询计划数量的平均值。
- SQLancer + QPG:优于SQLancer + QPG_r,证明了数据库状态变异(④)的贡献。
- SQLancer + QPG_r:优于SQLancer,证明了查询计划收集(③)的贡献。
- SQLancer + QPG:比SQLancer + QPG_r增长率更高,因为④逐渐学习哪些变异操作符是有效的。
预言机敏感性
- NoREC预言机:评估了SQLancer+QPG与NoREC预言机的组合效果。
- 图5显示了10次运行中24小时内覆盖的独特查询计划数量的平均值。
- 与TLP预言机类似,SQLancer+QPG在NoREC预言机下显著优于SQLancer和SQLRight。
每个数据库状态的最大查询数
- 配置:调整了每个数据库状态的最大查询数,评估SQLancer+QPG在不同配置下的表现。
- 图6显示了在不同最大查询数下覆盖的独特查询计划数量的平均值。
- 结果表明,无论最大查询数设置如何,SQLancer+QPG均显著优于SQLancer。
变异的敏感性
- 变异频率:评估每种变异(SQL语句)在10次运行中24小时内的执行频率。
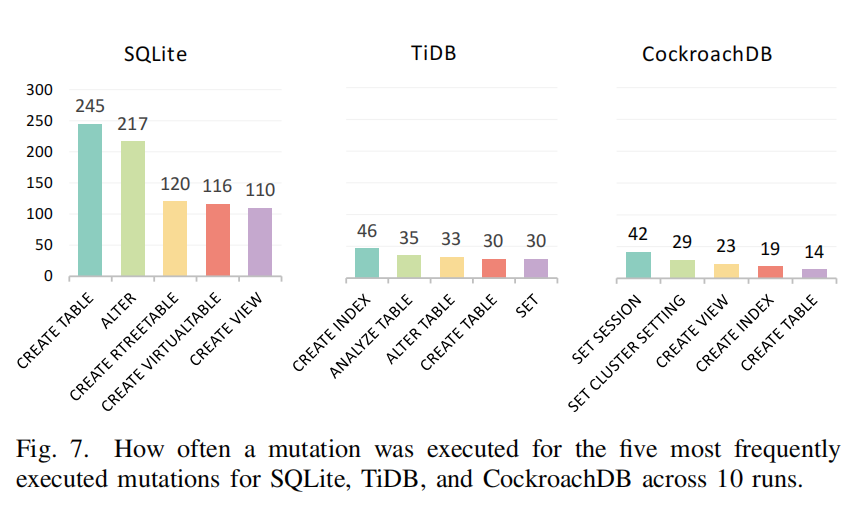 - 图7显示了SQLite、TiDB和CockroachDB中执行频率最高的五种变异的频率。
- **SQLite**:最频繁的变异是`CREATE TABLE`。
- **TiDB**:最频繁的变异是`CREATE INDEX`。
- **CockroachDB**:最频繁的变异是`SET SESSION`。
- 图7显示了SQLite、TiDB和CockroachDB中执行频率最高的五种变异的频率。
- **SQLite**:最频繁的变异是`CREATE TABLE`。
- **TiDB**:最频繁的变异是`CREATE INDEX`。
- **CockroachDB**:最频繁的变异是`SET SESSION`。