
Sedar: Obtaining High-Quality Seeds for DBMS Fuzzing via Cross-DBMS SQL Transfer
Sedar: Obtaining High-Quality Seeds for DBMS Fuzzing via Cross-DBMS SQL Transfer
ABSTRACT
有效的数据库管理系统(DBMS)模糊测试依赖于高质量的初始种子,这些种子作为变异的起点。这些初始种子应该包含各种DBMS功能,以全面探索状态空间。尽管内置的测试用例通常用作初始种子,但许多DBMS缺乏全面的测试用例,这使得难以直接应用最先进的模糊测试技术。
为了解决这个问题,我们提出了Sedar,Sedar通过从其他DBMS转移测试用例,为目标DBMS生成初始种子。其基本原理是,许多DBMS共享类似的功能特性,允许覆盖一个DBMS中深度执行路径的种子可以适用于其他DBMS。挑战在于将这些种子转换为目标数据库所支持的语法格式。Sedar生成种子的过程分为三个步骤。首先,它在种子最初设计的DBMS中执行现有的SQL测试用例,并在执行期间捕获架构信息。其次,它利用大语言模型(LLM)以及捕获的架构信息,基于LLM的响应指导新测试用例的生成。最后,为了确保测试用例能够被模糊测试器正确解析和变异,Sedar暂时注释掉模糊测试器无法解析的部分,并在变异后取消注释。
我们将Sedar集成到DBMS模糊测试器Squirrel和Griffin中,目标DBMS包括Virtuoso、MonetDB、DuckDB和ClickHouse。评估结果表明,这两个模糊测试器的性能有了显著提高。具体而言,与未转移种子的Squirrel和Griffin相比,Sedar分别提高了代码覆盖率72.46%-214.84%和21.40%-194.46%;与这些DBMS的本地测试用例相比,将Sedar生成的转移种子作为初始种子,代码覆盖率提高了4.90%-16.20%和9.73%-28.41%。此外,Sedar发现了70个新漏洞,其中60个是通过转移种子由Sedar唯一发现的,并且19个漏洞已分配了CVE编号。
INTRODUCTION
背景
数据库管理系统(DBMS)在现代软件应用中发挥着关键作用,因为它们存储数据并处理各种领域的查询。然而,DBMS也会存在漏洞,这些漏洞可能导致严重后果,如服务拒绝、数据泄漏、数据丢失甚至系统完全崩溃。因此,主动识别和解决DBMS中的安全问题,以确保系统安全和数据完整性,变得至关重要。
基于变异的模糊测试被广泛认为是一种有效的技术,用于发现软件程序中的漏洞。使用基于变异方法的模糊测试工具会维护一个初始种子的池,并通过变异这些种子迭代生成新的测试用例。这些变异后的输入会在目标程序上执行,探索新的代码区域并可能暴露出漏洞。
然而,当对主要依赖结构化查询语言(SQL)作为输入的DBMS进行模糊测试时,SQL语法的复杂性和DBMS可执行二进制文件的复杂性带来了独特的挑战。传统的基于变异的模糊测试工具通常难以有效地测试DBMS,因为它们生成的输入往往会导致语法错误或语义错误,使得测试底层逻辑和检测DBMS中的漏洞变得困难。因此,许多研究工作提出,确保为DBMS模糊测试生成的输入符合预期的输入格式,从而能够全面测试深层逻辑并发现潜在的漏洞。
模糊测试技术在DBMS中的有效性很大程度上依赖于初始种子的质量。初始种子作为变异的起点,能够全面探索程序的状态空间。为了实现有效的DBMS模糊测试,初始种子必须涵盖DBMS的多种功能,从而全面覆盖目标DBMS的功能和潜在漏洞。
讨论的对象是基于变异的模糊测试方法,确保语法和语义正确是Fuzzing的前提;
初始种子的质量是能不能探索状态空间和有效变异的前提。
Motivation
通常,现有的基于变异的DBMS模糊测试方法依赖于从内置单元测试用例和回归测试套件中收集SQL种子。通过利用这些现有的测试用例,模糊测试技术获得了已经设计用于覆盖特定功能和测试场景的初始种子。这种方法确保初始种子是有效输入的代表,并能有效地指导变异过程。
然而,当许多DBMS缺乏全面的测试用例时,就出现了一个重大障碍,使模糊测试工具无法可靠地收集SQL语句作为初始种子。虽然有一些研究提出了初始种子生成方法,但由于SQL语法的独特复杂性和SQL语句中固有的依赖性,这些技术可能不适用于生成高质量的SQL种子。SQL语法具有复杂的结构和语义规则,与通用标记语言有显著差异,这使得传统的种子生成方法难以直接应用于SQL语句。此外,SQL语句通常涉及依赖关系,如表关系和查询约束,这进一步增加了生成有意义和具有代表性的SQL种子的难度。
现有工作从单元测试用例或回归测试套件搜集测试样例,也有一些SQL生成的方法可以生成种子。生成高质量的种子还是具有挑战性的。
Key insight
为了解决DBMS模糊测试中缺乏高质量初始种子的问题,一种潜在解决方案是从已有的DBMS中收集测试用例,并将其转化为目标DBMS的适当初始种子。然而,跨DBMS转移SQL测试用例存在显著挑战。首先,不同DBMS的语法差异使得直接利用这些测试用例作为初始种子变得不切实际,这会在目标DBMS中导致大量语法和语义错误。为了有效触发目标DBMS中的深层代码区域,必须确保转移种子的SQL语句符合目标DBMS的语法要求。此外,兼容性问题也会在使用现有DBMS模糊测试工具时出现。这些模糊测试工具的变异器设计用于处理符合特定支持语法的SQL测试用例,因此可能无法解析或变异转移的种子,从而限制了这些模糊测试工具在目标DBMS上的有效测试。
从其他DBMS搜集测试样例进行转换,转化正确性和兼容性(变异)是挑战
为克服这些挑战,我们提出了一种名为Sedar的解决方案。Sedar通过三步过程确保与目标DBMS的兼容性:
- 首先,在原始DBMS环境中执行现有SQL测试用例,收集执行过程中必要的模式信息。这些模式信息提供了有关数据库结构和特性的宝贵见解。
- 其次,将SQL测试用例及收集到的模式信息输入到大型语言模型(LLMs)进行进一步处理。LLMs利用提供的模式信息,引导生成符合目标DBMS预期输入格式和行为的新测试用例。这些新生成的测试用例受益于LLMs的广泛知识,确保与目标DBMS的兼容性。
- 最后,为确保DBMS模糊测试工具的变异性,采取特定措施。当生成的测试用例的某些部分无法被模糊测试工具的变异器解析时,这些部分会在SQL语句中标记为注释。这种标记指示变异器忽略这些部分,而专注于变异SQL语句的其余部分。变异完成后,将先前标记的部分取消注释,生成既兼容又可变异的测试用例,准备供DBMS模糊测试工具使用。
C1: 搜集原始SQL语句的模式信息(结构、特性等等)
C2:注释掉不符合模式的部分(解析失败,类似于我们的adaptive parser),继续变异其他部分
Evaluation and contributions
我们将Sedar应用于生成四种DBMS(MonetDB、Virtuoso、DuckDB和ClickHouse)的初始种子,并使用两种最先进的基于变异的DBMS模糊测试工具(Sqirrel和Griffin)来评估生成种子的质量。使用Sedar提供的初始种子,这些模糊测试工具在目标DBMS中的覆盖范围显著提高。具体来说,在MonetDB、Virtuoso、DuckDB和ClickHouse中,模糊测试工具覆盖的分支数量相比使用非转移种子分别增加了40.58%-195.45%、90.82%-126.87%、62.05%-136.20%和72.46%-214.84%。当使用这些转移种子来增强这些DBMS的本地种子进行模糊测试时,模糊测试工具在MonetDB、DuckDB和ClickHouse中的代码覆盖率分别提高了10.77%-28.41%、12.53%-16.20%和4.90%-9.73%。此外,这些模糊测试工具在评估的DBMS中共发现了70个之前未知的漏洞,其中60个漏洞是通过Sedar使用转移种子独特发现的,有19个漏洞由于其严重性被分配了CVE编号。
- 我们识别了模糊测试技术对从内置测试用例中获取高质量初始种子的关键依赖性。然而,许多DBMS缺乏此类测试用例,从而阻碍了有效的DBMS模糊测试。
- 我们提出了Sedar,这是一种创新方法,通过跨DBMS的SQL转移生成目标DBMS模糊测试的种子输入,克服了缺乏初始测试用例的限制。这些种子还可以用于增强本地种子,从而增加代码覆盖率并促进未知漏洞的检测。
- Sedar成功发现了现实世界DBMS中的70个漏洞,其中19个漏洞被分配了CVE标识符。
BACKGROUND AND MOTIVATION
Background
DBMS和SQL
- 大多数DBMS使用结构化查询语言(SQL)来管理数据。
- 用户通过执行相应的SQL语句来利用DBMS的各种功能。
- 通常,DBMS遵循ANSI SQL标准的基本特性,同时通过独特的SQL方言支持更高级的功能。
- 不同DBMS的SQL方言在语法上不兼容,因为相似的功能在不同DBMS中可能会采用不同的语法实现。
DBMS模糊测试的初始种子
- 初始种子通常指包含一系列SQL语句的测试用例。
- 基于变异的DBMS模糊测试通过不断变异现有种子来生成新的测试用例。
- 初始种子的质量对模糊测试的有效性至关重要。
- 初始种子作为模糊测试的起点,形成了后续测试迭代的基础。
- 初始种子的功能丰富性影响了在后续变异中可以探索的DBMS功能的多样性。
- 高质量的初始种子有助于增加测试覆盖率并提高漏洞检测的效果。
- 由于不同DBMS的独特语法和行为,重要的是要针对目标DBMS的特定特性调整初始种子,以确保模糊测试能够有效地探索该系统。
流行DBMS的测试方法
- 测试工程师使用基于变异的模糊测试工具对许多广泛使用的DBMS(如SQLite、MySQL、MariaDB和PostgreSQL)进行广泛测试。
- 这些DBMS的初始种子通常从其内置测试用例中获取。
- 这些DBMS维护了大量的测试套件,包含数千个用于单元测试、回归测试、性能测试等目的的内置测试用例。
- 通过访问这些测试套件,测试工程师可以有效收集初始种子并对这些流行的DBMS进行高效的模糊测试。
缺乏高质量初始种子对DBMS模糊测试的影响
- 并非所有DBMS都提供如此大且高质量的测试套件。
- 一些DBMS缺乏全面的内置测试用例,这对模糊测试工具构成了挑战,因为无法直接收集适合这些DBMS的初始种子。
- 由于缺乏高质量的初始种子,这一限制可能会对DBMS模糊测试的性能产生不利影响。

Challenges
图1展示了一个由于缺乏适当的初始种子而无法被当前DBMS模糊测试工具检测到的崩溃漏洞。该漏洞由一个TRACE语句触发。TRACE语句是MonetDB中的一种专用功能,用于分析语句执行,类似于其他DBMS中的EXPLAIN语句。然而,MonetDB官方没有提供包含TRACE语句的测试用例。因此,目前的DBMS模糊测试工具无法发现这个漏洞,因为没有任何初始种子包含TRACE语句,导致难以生成触发漏洞的后续变异。
一种测试MonetDB中TRACE功能的方法是从使用EXPLAIN功能的其他DBMS中转移测试用例,因为它们的语法相似。例如,可以简单地将关键词EXPLAIN替换为TRACE以测试MonetDB。但是,这种转移面临两个挑战:
- DBMS之间的语法差异显著:
- TRACE和EXPLAIN语句的例子中仅关键词不同,但其他功能如存储引擎、数据类型和函数名称等语法差异显著。
- 例如,MonetDB有225个函数,而SQLite有165个函数,只有59个函数在两个DBMS中共享相同的名称。
- 这些显著的差异使得转移变得困难且繁琐。
- DBMS模糊测试工具的语法支持有限:
- 许多DBMS模糊测试工具是为测试特定流行DBMS而实现的,这意味着它们支持的语法也针对这些特定系统进行了定制。
- 即使成功将其他DBMS的测试用例转移以匹配MonetDB的语法,模糊测试工具可能仍会由于缺乏对某些语法的支持而难以解析或变异这些转移的测试用例。
Basic ideas
- 为了应对第一个挑战,Sedar利用大型语言模型(LLMs)来简化转移过程。LLMs在自然语言任务和编程语言任务中表现出色,特别是在SQL相关任务中,LLMs已成功用于从文本生成SQL语句,展示了出色的效果。Sedar利用LLMs来转移SQL语句,通过生成包含单个SQL语句及其相应描述的提示,辅助LLMs完成转移过程。
- 为了克服第二个挑战,Sedar采取措施确保转移的测试用例能够被模糊测试工具变异。具体做法是将任何不可解析的关键词和子句隐藏起来,通过将其注释掉来实现。这一策略使模糊测试工具仅专注于剩余的可解析部分,从而有效地变异测试用例。通过结合SQL转移和变异性优化,Sedar成功生成了与DBMS和模糊测试工具兼容的高质量初始种子。
DESIGN
3.1 Schema Capture
模式捕获旨在从其他DBMS的测试用例中收集模式信息。模式指的是数据库的结构或蓝图,描述了数据库对象的组织,包括表、列、索引、函数、约束等。模式提供了SQL语句的全面概览,可用于描述这些语句并作为后续通过LLMs进行SQL转移过程的提示。模式信息为语句提供了上下文,增强了转移的准确性。缺乏模式信息可能导致LLMs输出的SQL语句由于单个SQL语句的模糊性而出现不准确。例如,在一个简单的SELECT语句“SELECT… WHERE a=b”中,如果没有模式信息,“a”和“b”列的数据类型是模糊的。如果该语句需要转移到需要显式类型转换的DBMS(如PostgreSQL),表达式“a=b”需要进行类型转换重写。
过程如下:
- 重要性:提供模式信息可以让LLMs根据数据类型生成正确的表达式,避免由于数据类型模糊性导致的转移错误。
- 信息检索:模式信息可以通过执行特定查询来检索。DBMS通常支持对系统表的查询,这些表可以列出所有数据库对象及其对应的名称和类型,有效地代表整个模式。
- 必要性:收集整个模式对于描述SQL语句来说是多余的。数据库可能包含数百个对象,但单个SQL语句可能只引用几个数据库对象。因此,仅需检索测试用例中SQL语句引用的数据库对象的模式。
Sedar的步骤
- 执行测试用例:在各自的DBMS中执行测试用例,记录每个执行的语句并将其分割成标记。
- 标识符查询:枚举语句中的标识符标记,并查询当前系统表以定位与这些标识符匹配的数据库对象。
- 构建子模式:根据查询到的数据库对象的信息,构建引用的子模式。
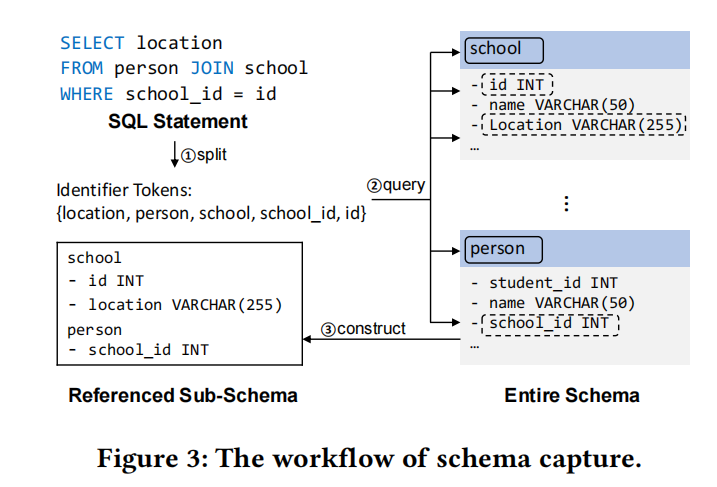
图3展示了模式捕获的工作流程示例。以下是步骤:
- 分割语句:
- 执行SQL语句后,Sedar首先将语句分割成标识符标记,如“location”、“person”、“school”、“school_id”和“id”。
- 查询系统表:
- Sedar查询系统表以定位相应的数据库对象。查询结果显示“school”和“person”是表名,而“id”、“location”和“school_id”是列名。
- 构建子模式:
- Sedar根据查询结果构建由语句引用的子模式。最终构建的子模式包含表“school”和“person”的结构信息。
通过上述步骤,我们获得了与各自子模式配对的测试用例中的SQL语句。每个语句的模式信息将用于描述该语句,这是Sedar的下一组件中介绍的内容。
3.2 SQL Transfer with LLM

SQL转移旨在通过LLMs将流行DBMS中的SQL语句转化为与目标DBMS语法匹配的语句。Sedar首先根据SQL语句及其对应的模式信息生成供LLMs使用的提示。然后,它查询LLMs并将响应处理成与目标DBMS兼容的测试用例。
提示生成
提示:输入给LLMs的提示决定了它们的输出。为了使LLMs处理转移任务,需要设计合适的提示(即提示工程)。
单语句处理:由于LLMs在处理大输入和生成大量输出时存在限制,Sedar为每个测试用例中的每条语句生成单独的提示,确保处理效率和兼容性。
示例提示
:图4展示了单条语句转移的示例提示,包含以下部分:
- 语句描述:包括引用子模式的介绍,提供语句上下文,使LLMs能够生成准确的输出。
- 语句内容:用markdown代码块包围,带有’sql’提示。
- 命令部分:指示LLMs将给定语句转移为目标DBMS的等效语句。
描述部分通过将子模式中的每个项目转换为“{item_name} is a {item_type}”格式的句子并连接这些句子生成。
LLM查询
- 生成提示后,Sedar枚举提示并查询LLMs。由于每个提示已经包含语句的上下文,查询顺序不影响过程,因此Sedar可以并行查询多个提示以加速处理。
- LLMS生成包含转移后SQL语句的响应。如果LLMs预训练数据包含目标DBMS的知识,可以直接提供转移结果,否则需要使用目标DBMS的文档和教程进行微调。
- 接收LLMs响应后,Sedar提取转移后的语句并按原始顺序组合,创建新的测试用例,称为兼容种子。
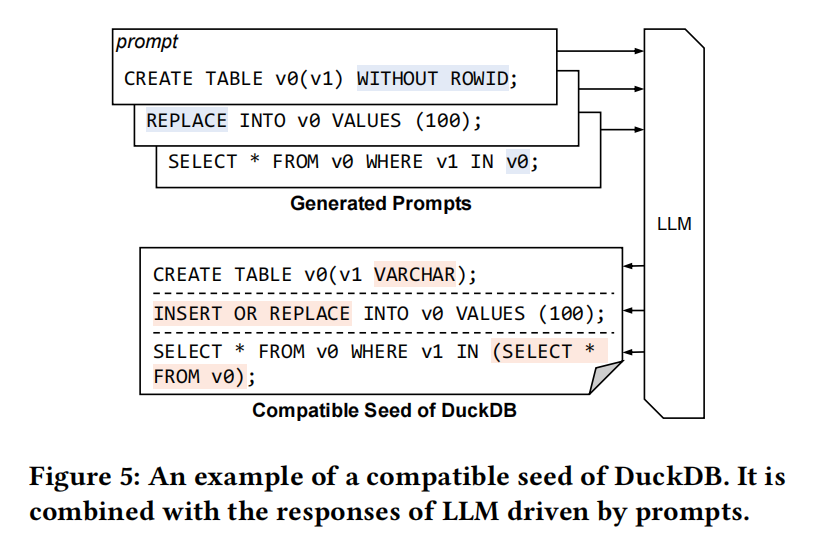
图5展示了将SQLite测试用例转移为DuckDB兼容种子的过程。Sedar为测试用例的三条语句生成三个提示并并行查询LLMs。LLMs的响应对语句进行了以下修改:
- 删除表创建语句中的WITHOUT ROWID子句,因为DuckDB不支持该功能。
- 添加数据类型定义,因为DuckDB的表创建需要显式定义列类型。
- 将REPLACE关键字和IN子句替换为DuckDB的等效语法。
最终,Sedar将这些语句连接形成DuckDB的兼容种子。
3.3 Mutability Refinement

尽管兼容种子适合目标DBMS的语法,但当前无法用于基于变异的DBMS模糊测试工具。在变异过程中,模糊测试工具的变异器需要解析种子的SQL语句,分析其语法结构,修改结构,并将修改后的结构转换回SQL语句以形成新的测试用例。如果种子包含目标DBMS支持但变异器解析器不支持的语法,变异器将无法解析这些语句,从而阻碍进一步的变异。
例如,Sqirrel无法变异包含ClickHouse的CREATE TABLE语句的种子,因为ClickHouse的CREATE TABLE语句总是指定存储引擎(如MergeTree和Memory),而Sqirrel不支持引擎声明子句的语法。如果将这些语句输入Sqirrel进行变异,变异器将无法解析这些语句并跳过整个种子,限制了Sqirrel在ClickHouse上的性能。
Sedar的解决方案
为了使变异器能够解析和变异种子,Sedar使用算法提取种子的可解析部分。具体步骤如下:
- 将种子的内容分解为标记列表,然后将这些标记依次输入变异器的解析器。
- 当标记导致解析器错误时,Sedar将该标记标记为不可解析部分,恢复解析器的错误状态,并继续处理下一个标记。
- 处理完所有标记后,Sedar将不可解析部分注释掉,指示解析器忽略它们。
- 注释掉不可解析部分后,种子被称为可变种子,因为它现在可以解析以进行进一步变异。
- 可变种子交给DBMS模糊测试工具的变异器进行变异,引入各种变异结构。
- 最后,Sedar取消注释不可解析部分,以恢复不支持的语法。生成的种子包含变异后的可解析部分和取消注释的不可解析部分,可以触发目标DBMS中的新行为。
示例展示
图6展示了Sedar如何优化ClickHouse兼容种子的可变性。Sedar使用Sqirrel的变异器解析种子中的语句,并识别两个不可解析部分:Int32数据类型和引擎子句。然后,Sedar将这些不可解析部分注释掉,形成仅包含CREATE TABLE关键字和列名“v1”的可变种子。接着,Sqirrel将可变种子变异为包含NOT NULL和PRIMARY KEY关键字的语句。最后,Sedar取消注释不可解析部分,得到最终种子。变异后的种子对于ClickHouse仍然有效,并包含由变异引入的新关键字,能够触发新行为。
IMPLEMENTATION
如图2所示,Sedar包含三个组件,对应三个步骤:模式捕获、SQL转移和可变性优化。我们用3213行C++代码和1072行Java代码实现了这三个组件。
- 模式捕获组件:我们修改了DBMS客户端的源代码,以在执行语句时捕获引用的子模式。一旦完成了一个DBMS测试用例的语句及其模式信息的收集,这些结果在转移到多个DBMS时可以重复使用。
- SQL转移组件:我们使用gpt-3.5-turbo-0301模型作为LLM来转移SQL语句。提示生成由Java实现,与gpt-3.5-turbo-0301的交互通过其在线API运行。
- 可变性优化组件:其实现依赖于DBMS模糊测试工具的解析器。例如,Sqirrel的解析器用Lex和Yacc编写。我们通过向Sqirrel的解析器添加错误恢复规则实现了可变性的优化,使其能够自动记录并跳过不可解析的标记。
这些组件的组合确保了Sedar能够有效地捕获模式、转移SQL语句并优化测试用例的可变性,从而提高DBMS模糊测试的效果。
EVALUATION
我们通过评估Sedar对现有DBMS模糊测试工具的代码覆盖率和漏洞检测的改进,以及Sedar生成的种子在DBMS模糊测试中的效率,来评估Sedar的效果。我们的评估旨在回答以下研究问题:
- RQ1:使用Sedar后,DBMS模糊测试工具能否在现实世界的DBMS中发现新的漏洞?
- RQ2:Sedar对新DBMS的基于变异的模糊测试工具的性能改进如何?
- RQ3:SQL转移对模糊测试初始种子的贡献是什么?
- RQ4:优化可变性对DBMS模糊测试工具的有效性如何?
5.1 Evaluation Setup
测试的DBMS
我们选择了四个流行的DBMS进行评估,包括MonetDB、Virtuoso、DuckDB和ClickHouse。这些DBMS都是广泛使用的开源DBMS,根据DB-Engine排名。它们支持类似的DBMS特性(如关系数据模型),但使用不同的SQL方言。评估中使用的版本包括MonetDB v11.46.0、Virtuoso-opensource v7.2.9、DuckDB v0.7.1和ClickHouse v23.5.3.24。
DBMS模糊测试工具
为了评估Sedar生成种子的质量,我们使用了两个基于变异的DBMS模糊测试工具,Griffin(清华的)和Sqirrel。具体来说,Griffin通过重排语句和元数据指导的替换进行变异,而Sqirrel在SQL测试用例上执行语法保留的变异和语义指导的插入。两者都依赖于DBMS模糊测试的初始种子,并旨在检测崩溃漏洞。
收集的测试用例
为了为目标DBMS生成高质量的初始种子,Sedar通过从其他DBMS转移测试用例,收集了SQLite、MySQL和PostgreSQL的内置测试用例。这些测试用例的详细信息如表1所示。此外,我们还从MonetDB、DuckDB和ClickHouse的代码库中收集了本地开源测试用例进行比较。Virtuoso不提供开源测试用例。
基本设置
我们在一台配备128核AMD EPYC 7742处理器(2.25 GHz)和504 GiB内存的机器上进行评估,运行64位Ubuntu 20.04。测试的DBMS通过AFL++编译以提供覆盖反馈。我们在默认配置和不同初始种子集下运行DBMS模糊测试工具,并使用ptrace监控DBMS在模糊测试期间是否崩溃。每个模糊测试实例运行24小时,每个DBMS使用2个CPU进行测试。
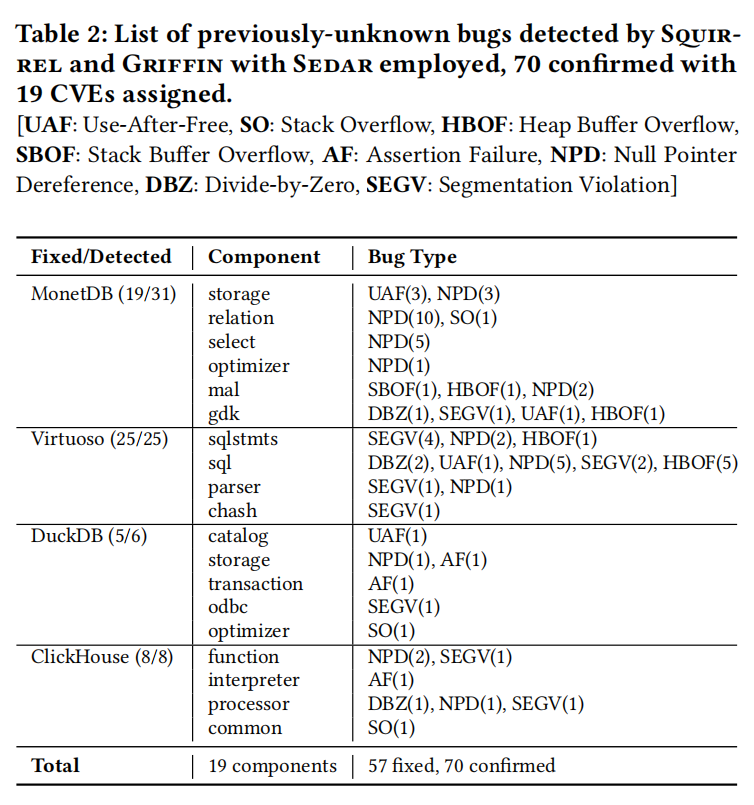
5.2 DBMS Vulnerabilities
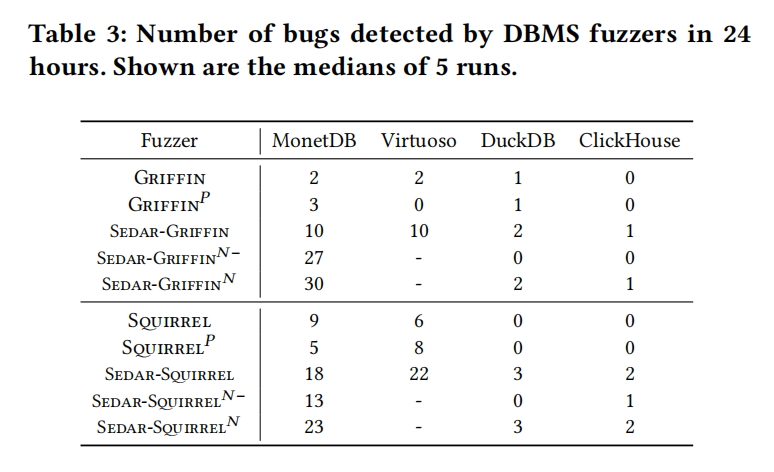
Sedar 是一个用于发现数据库管理系统(DBMS)漏洞的工具。在三天内,Sedar 帮助 Sqirrel 和 Griffin 发现了 70 个未知漏洞,其中 60 个漏洞是通过转移种子首次被发现的。这些漏洞分布在不同的数据库系统中,包括 MonetDB、Virtuoso、DuckDB 和 ClickHouse,具体数量分别是 31、25、6 和 8 个。
这些新发现的漏洞类型多样,包括:
- 33个空指针解引用错误
- 6个使用后释放错误
- 3个栈溢出
- 8个堆缓冲区溢出
- 1个栈缓冲区溢出
- 4个零除错误
- 12个段违规
- 3个断言失败
所有这些漏洞都已经被相关的供应商确认,其中 57 个已经被修复,并且有 19 个被分配了 CVE 标识。
具体案例研究指出,在 ClickHouse 中,一个名为“interval”的操作符引发了一个空指针解引用的漏洞。该漏洞由一个包含 INTERVAL 操作符的插入语句触发。ClickHouse 支持非标准的 INTERVAL 语法,但这种特性在处理插入语句时可能导致崩溃。问题的根源是 ClickHouse 缺少对在插入语句中非标准间隔表达式的测试,而其他数据库系统如 MySQL 已经测试了类似功能。Sedar 通过将 MySQL 中的表达式转换成 ClickHouse 的语法,有效地揭示了这个漏洞。
5.3 Overall Experiments
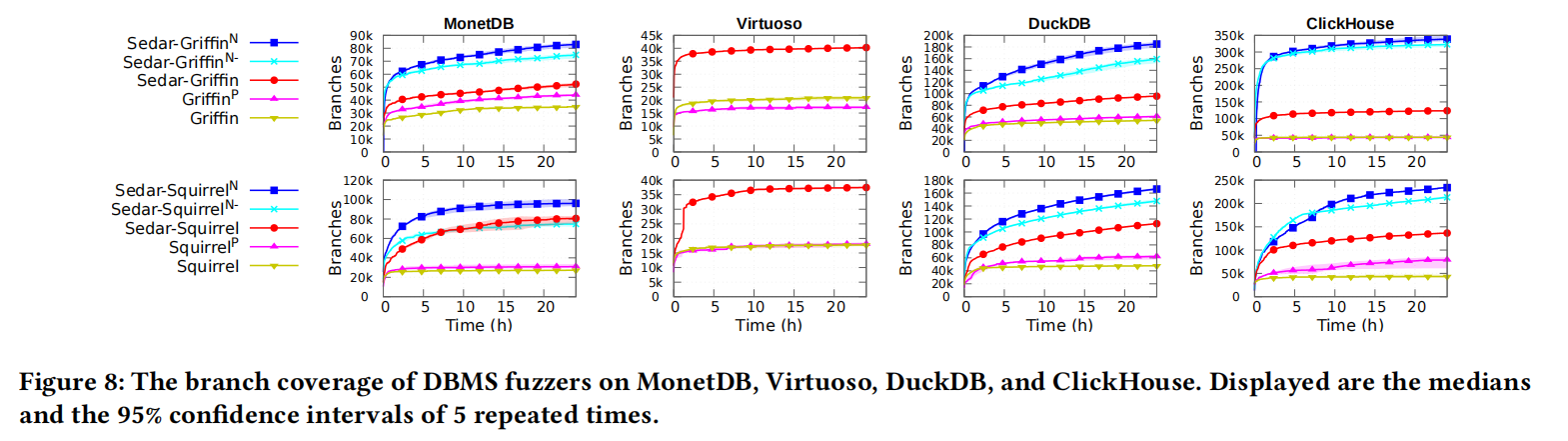
本节描述了使用 Sedar 工具来评估数据库管理系统(DBMS)模糊测试工具(fuzzers)的改进。通过在不同的数据库系统上部署不同种类的初始种子,研究者们比较了这些模糊测试工具在代码覆盖率和漏洞检测能力方面的表现。
实验设置包括五种不同的初始种子配置:
- 默认配置的内置种子,标记为 Griffin 和 Sqirrel。
- 从其他流行的 DBMS 收集的测试用例,未进行转换,标记为 Griffin𝑃 和 Sqirrel𝑃。
- 由 Sedar 生成的种子,标记为 Sedar-Griffin 和 Sedar-Sqirrel。
- DBMS 的本地测试用例,应用了 Sedar 的可变性细化(mutability refinement),标记为 Sedar-Griffin𝑁- 和 Sedar-Sqirrel𝑁-。
- 结合 Sedar 生成的种子和本地测试用例的组合,标记为 Sedar-Griffin𝑁 和 Sedar-Sqirrel𝑁。
结果表明,应用了 Sedar 的模糊测试工具在代码覆盖率和漏洞检测上表现更佳。特别是 Sedar 处理的种子使得模糊测试工具可以更有效地覆盖更多代码分支,并检测到更多漏洞。这些改善主要归功于两个原因:
- Sedar 提供的种子更符合目标 DBMS 的语法,有助于提高代码覆盖率。
- Sedar 的可变性细化功能增强了 SQL 语句的正确性,使得模糊测试工具能够更深入地测试 DBMS。
此外,实验还反复进行了五次,通过计算 𝑝 值来进行统计测试,显示 Sedar 系列的显著性高于其他设置。
总之,Sedar 工具通过提供兼容的初始种子和增强 SQL 语句的准确性,显著提高了模糊测试工具的效果,使其能够更有效地发现和修复 DBMS 中的漏洞。
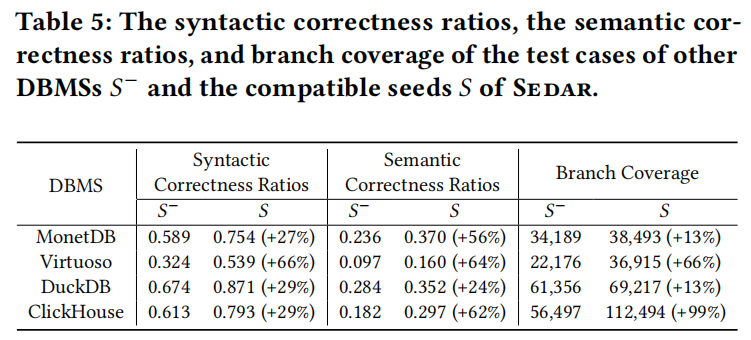
5.4 Contribution of SQL Transfer
以下是关于 Sedar 通过 SQL 转换功能提升测试种子的有效性的研究结果,以列表形式简要总结:
- 测试种子对比:
- 原始测试种子(标记为 𝑆−)
- 通过 Sedar 的 SQL 转换生成的兼容种子(标记为 𝑆)
- 评估指标:
- 语法正确性
- 语义正确性
- 代码覆盖率
- 性能提升:
- 语法正确性提升:
- MonetDB: +27%
- Virtuoso: +66%
- DuckDB: +29%
- ClickHouse: +29%
- 语义正确性提升:
- MonetDB: +56%
- Virtuoso: +64%
- DuckDB: +24%
- ClickHouse: +62%
- 代码覆盖率提升:
- MonetDB: +13%
- Virtuoso: +66%
- DuckDB: +13%
- ClickHouse: +99%
- 语法正确性提升:
- 具体案例分析:
- Virtuoso:对 SQL 语法的基础支持限制导致原始种子语法正确性低,通过 SQL 转换,部分语句被转换成 Virtuoso 支持的表达式,显著提高代码覆盖率。
- ClickHouse:处理 CREATE TABLE 语句中的存储引擎声明问题,使得表创建语句和相关的 INSERT 和 SELECT 语句在 ClickHouse 中有效,提高代码覆盖率。
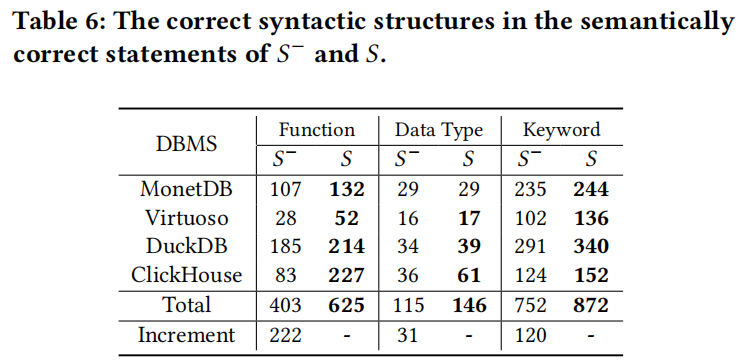
- 函数、数据类型和关键字的增加:
- 相较于 𝑆−,𝑆 在四个 DBMS 中包含更多的函数(+222)、数据类型(+31)和关键字(+120),增强了测试种子的正确性和代码覆盖能力。
这些结果表明,Sedar 的 SQL 转换功能显著增强了种子的兼容性和有效性,提高了 DBMS 测试过程中的语法和语义正确性以及代码覆盖率。
5.5 Effectiveness of Mutability Refinement
本部分研究了 Sedar 的可变性细化(mutability refinement)功能的有效性,通过在四个不同的数据库管理系统(DBMS)上运行 Sqirrel 模糊测试工具来评估。研究中使用了两组种子:一组是仅由 Sedar 的 SQL 转换组件生成的兼容种子(标记为 𝑆),另一组是由 SQL 转换和可变性细化生成的可变种子(标记为 𝑆+)。
主要发现和结果包括:
- 种子的解析和变异能力提升:
- 与 𝑆 相比,𝑆+ 在四个 DBMS 上的可解析语句数量分别增加了 44%、89%、61% 和 54%(MonetDB, Virtuoso, DuckDB, ClickHouse)。
- 这一提升主要归因于可变性细化功能,该功能帮助模糊测试工具变异与语法不兼容的 SQL 语句。
- 代码覆盖率的提高:
- 运行 Sqirrel 的结果显示,与 𝑆 相比,𝑆+ 在四个数据库上的代码覆盖率分别提高了 25%、55%、21% 和 64%。
- 这表明,通过可变性细化,Sqirrel 能够解析和变异包含独特语法的测试用例,从而生成更多语义上正确的 SQL 语句,并覆盖更多的代码分支。