
Mallet: SQL Dialect Translation with LLM Rule Generation
Mallet: SQL Dialect Translation with LLM Rule Generation
ABSTRACT
在不同系统的SQL方言之间进行翻译对于迁移和联合查询处理非常重要。现有的方法依赖于手工制定的翻译规则,这些规则往往不完整且难以维护,尤其是在需要翻译的方言数量增加的情况下。因此,方言翻译仍然是一个未解决的问题。
为了解决这个问题,我们引入了Mallet系统,该系统利用大型语言模型(LLMs)来自动生成SQL-to-SQL翻译规则,即模式转换、自动UDF生成、扩展选择和表达式组合。一旦生成这些规则,它们在新的工作负载上可以无限次重复使用,而无需将LLM置于查询执行的关键路径上。Mallet通过以下方式提高LLM的准确性:(1)在系统文档和人工专业知识的基础上执行检索增强生成(RAG),(2)使用实际SQL系统进行经验验证,以检测幻觉,(3)自动创建准确的少量学习实例。贡献者在不了解系统代码的情况下,通过提供自然语言专业知识来改进Mallet的RAG。
INTRODUCTION
Background
数据库管理领域在过去几十年里变得越来越复杂。这种复杂性不仅源于大量专门处理不同工作负载的数据库管理系统(DBMS),还源于大量不兼容的SQL方言。这种不兼容严重阻碍了迁移和联邦化的便捷性,使用户被绑定在初始的DBMS上,无论其在成本和性能上多么不理想或缺乏特定功能。方言之间的翻译不仅可以促进迁移,还可以实现智能联邦系统,将工作负载的一部分路由到能够以更好成本或性能处理它们的系统上。因此,这将极大地促进DBMS领域的发展。
方言翻译是一个困难的问题。举例来说,考虑图1所示的翻译过程。我们尝试将MySQL工作负载(图1a)迁移到PostgreSQL(图1b)。首先,我们必须检测到某些功能(例如空间功能)在没有扩展(例如PostGIS)的情况下不被PostgreSQL支持。其次,必须将MySQL类型匹配到PostgreSQL类型,这些类型可能具有不同的名称或表示(例如,mediumblob到bytea)。第三,我们必须为每种类型找到一个通用的中间表示来转储和加载数据(例如,空间类型的well-known text (WKT))。第四,一些MySQL函数可能需要生成模仿它们的PostgreSQL用户定义函数(UDFs)。第五,其他MySQL函数可能需要组合PostgreSQL函数(例如,一些日期/时间函数)。最后(未显示),用MySQL编写的用户定义逻辑(例如UDF或存储过程)必须翻译为PostgreSQL。

- 模式转换
- 在MySQL中,
preview_img使用MEDIUMBLOB类型,而在PostgreSQL中,转换为BYTEA类型。 last_login_fail从MySQL的DATETIME转换为PostgreSQL的TIMESTAMP。location从MySQL的POINT转换为PostgreSQL的GEOMETRY(POINT, 4326)。
- 在MySQL中,
- 查询转换
- MySQL使用
HEX函数来处理preview_img,PostgreSQL使用DECODE。 - JSON查询从
JSON_EXTRACT转换为EXTRACT_UDF,需要自定义UDF函数来处理JSONPath。 - 计算时间差的查询从
TIMESTAMPDIFF转换为EXTRACT EPOCH并使用FLOOR计算分钟数。 - 位置查询的
ST_ASTEXT函数在两者中保持一致,但PostgreSQL需要加载postgis扩展。
- MySQL使用
Limitations
问题在于上述步骤必须针对多个系统对进行重复翻译(即直接在两种方言之间或通过中间方言)。尽管已有多个工具可以简化迁移过程,但它们都依赖于精心手写的规则,这种方法繁琐且只能适用于特定系统集。这些工具在支持更多系统时表现不佳,导致一些系统对在基本查询上失败。
Challenges
作为手写规则的替代方案,我们考虑使用大型语言模型(LLMs),这些模型在数据管理任务中表现出潜力。尽管可以尝试直接使用LLMs进行逐查询翻译(例如,提示“将
Approach
在这篇论文中,我们提出了一种比手工编写系统更具扩展性、更准确、快速、可验证且廉价的解决方案,以实现逐查询翻译。我们的核心理念是自动生成这些翻译规则,而不是手工编写。
我们引入了名为Mallet的实验原型系统,该系统利用大型语言模型(LLMs)生成数据库管理系统(DBMS)中每个功能的细粒度转换规则。每条规则比整个查询更简单,这使得这种方法比逐查询LLM翻译更准确。此外,因为这些规则一旦生成、测试和验证后,可以在查询之间无限次重复使用,Mallet比粗粒度翻译更快速、经济和可验证,同时不会遭受手工编写系统的扩展性问题。
为了提高准确性,Mallet进一步使用检索增强生成(RAG)技术,不仅覆盖系统文档,还包括自然语言的人工专业知识,允许贡献者无需编写代码就能改进系统。此外,由于LLM可以自动生成示例数据,Mallet可以使用SQL系统自动测试规则、捕捉幻觉,并生成任何给定功能的准确少量学习示例。我们的初步评估证实了Mallet在方言翻译中的实用性。
总结而言,我们的贡献如下:
- 我们引入了规则生成技术,利用LLMs生成细粒度的方言翻译规则。它比手工编写规则更具扩展性、更准确、快速且廉价。
- 我们在系统文档和贡献者的专业知识上执行RAG,允许他们无需编写代码就能改进系统。
- 我们通过使用LLMs与DBMS结合,自动测试规则和捕捉幻觉,并实现少量学习,从而进一步增强规则生成过程。
- 我们开发了一个名为Mallet的初始规则生成原型,并证明它优于现有的手工编写系统和逐查询LLM翻译。
MALLET
2.1 Overview
图 2 提供了 Mallet 系统的概览。图 2a 展示了系统的架构。Mallet 的目标是利用通过 RAG、小样本学习和自动化测试增强的大型语言模型(LLM)来生成一个细致的翻译规则数据库。这些规则确定如何将工作负载从一个数据库管理系统(DBMS)翻译到另一个(即源和目标)。Mallet 的贡献者可以通过提供英语专业知识或在自动化方法失败时编辑规则数据库来改进系统。一旦生成,这些规则可以在不再涉及 LLM 的情况下适用。图 2b 展示了如何仅使用翻译规则数据库将 MySQL 查询翻译成 PostgreSQL,这使得过程比将 LLM 放在关键路径上要快得多。我们现在将深入探讨图 2a 所示的组件。
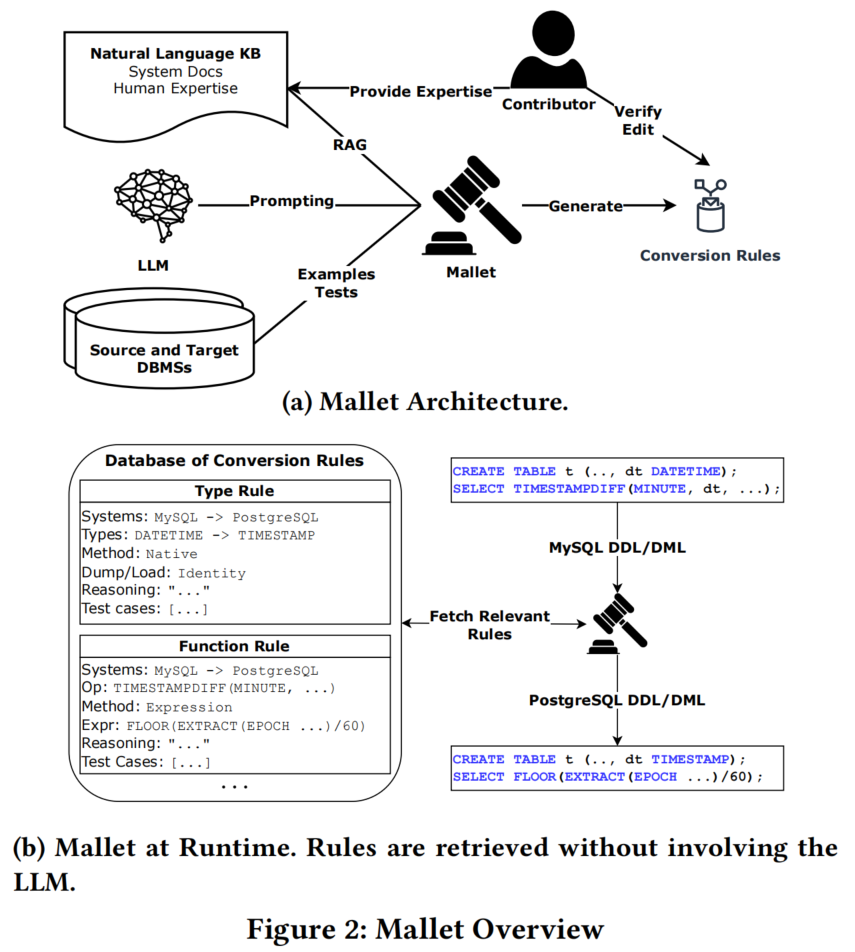
2.2 RAG
RAG I: 系统文档
即便LLM已经通过DBMS的文档进行了训练,某些功能可能只有在其上下文中被包括时LLM才会注意到。因此,我们包括了相关文档片段以避免过分依赖专业知识去理解这些细微之处。由于文档结构高度规范化,我们主要依赖关键词搜索,这通常能返回所需的片段。当此类搜索失败时,我们使用向量嵌入相似性搜索作为后备方案。
RAG II: 贡献者专业知识
当文档和常识不足以支持,或者当LLM系统性地出现错误时,就需要提供专业知识来帮助翻译过程。这使得贡献者能够在不了解系统代码的情况下改进系统,这是基于LLM的编程的一个重要好处。通常,这种专业知识是普遍适用于许多系统的(例如,“使用WKT转储空间数据类型”),但有时它必须是具体的(例如,“使用<特定功能>转换<特定Oracle功能>”)。因为专业知识片段对于正确性至关重要,我们依靠精确搜索来包括它们在提示中,否则它们可能会被近似搜索浪费。当前,贡献者必须提供一个正则表达式来匹配他们的目标规则(例如,.*mysql_postgres.*用于MySQL和PostgreSQL之间的转换)。
2.3 Using the DBMSs
幻觉检测
由于我们拥有源系统中任何功能的正确实现,且可以生成样本数据(或者使用应用数据进行抽样),因此可以为源系统中的任何功能生成正确的输入/输出值。然后,通过应用规则,我们可以在目标系统中获得结果值。每当这些值不等价时,就意味着规则不正确;这表明LLM产生了幻觉。每当检测到这样的幻觉时,我们通过两种方式迭代地重新提示LLM:(a) 在提示中包含之前的错误以便修正它们;或者(b) 从头开始重新提示。选择(b)是必要的,因为有些情况下LLM只是对根本错误的规则进行微小调整。在这些情况下,从头开始通常是更好的选择。
少数示例学习
先前的工作表明,通过为任务提供示例解决方案,可以提高LLM的性能,然后再将其推广到新的环境中。这被称为少数示例学习。用于测试的同一方法可以生成提示的输入/输出对。唯一的额外复杂性是,提示是文本的,而某些类型则具有不透明的(例如,二进制)表示。在这种情况下,我们通过要求LLM为每种类型生成一个标准表示(例如,用于blob的十六进制,用于空间类型的WKT)来衍生标准表示。
2.4 Conversion Rules
架构规则
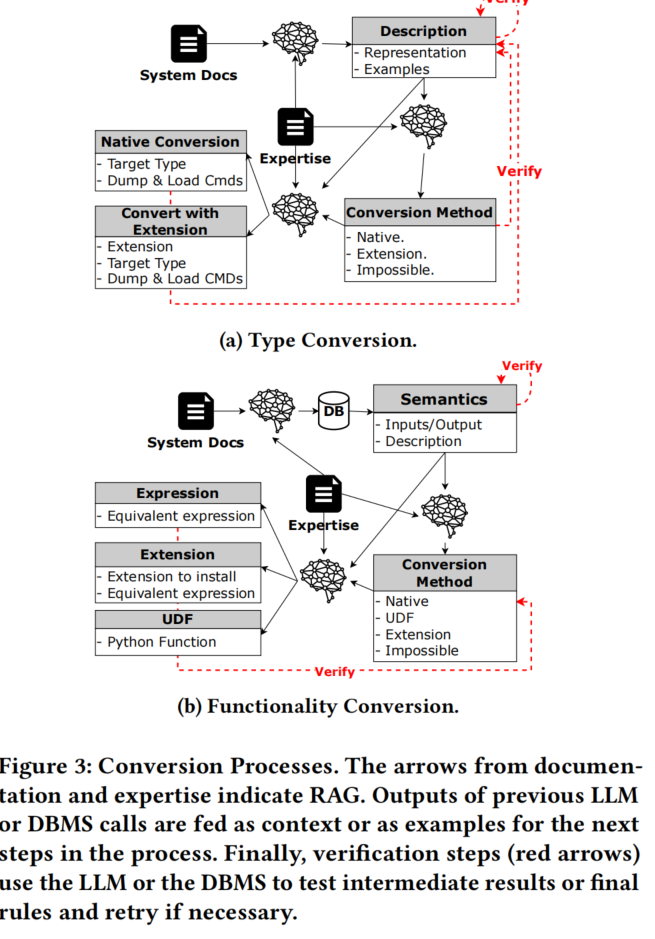
图 3a 展示了类型转换规则生成过程。该过程从通过文档进行 RAG 并获取相关信息开始。第一个提示让LLM生成类型的描述和表示,并给出多个示例值。这些值将根据系统的格式化和类型正确性进行检查。这些输出(连同RAG的结果)被传递到另一个提示中,询问LLM对于给定类型的最佳转换方法。我们要求LLM选择三种方法之一:(1) 原生:使用原生类型进行转换;(2) 扩展(名称):使用LLM还指定的扩展进行转换;(3) 不可能:转换该类型是不可能的。最后一个选项只与非常不寻常的类型相关,当目标系统无法扩展以支持这些类型时。例如,将 Redshift 的 HLLSKETCH 类型转换为 MySQL 目前是不可能的。当转换不可能时,我们仍可以使用联邦(见第1节)来适应性地移动可转换的工作负载部分。
功能规则
图 3b 展示了功能转换规则生成过程。Mallet 通过使用 RAG、LLM 和底层 DBMS 产生输入/输出对开始,同时附带强调必须显式处理的角落案例和细节的文档。然后,它要求LLM提供一个转换方法,如下:(1) 原生:组合现有表达式;(2) UDF:生成一个新的用户定义函数;(3) 扩展(名称):安装一个扩展;(4) 不可能:转换是不可能的。基于方法,我们给LLM具体指令来生成规则,然后运行我们的幻觉检测机制并在检测到幻觉时重试。如果经过足够多的重试后仍未产生有效规则,我们返回“不可能”,这表明要么缺乏专业知识,要么LLM无法实现翻译。
请注意,我们目前仅生成 Python 的用户定义函数,因为我们更关注可行性而不是性能。具体的替代方法和性能讨论请见第4节。
PRELIMINARY RESULTS
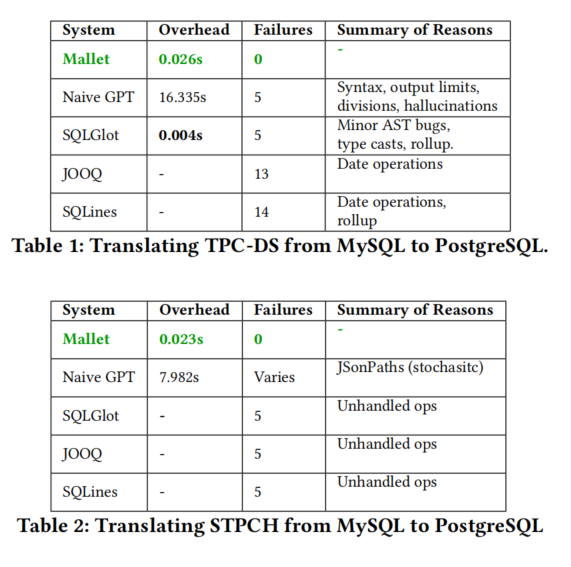
本节介绍了 Mallet 的初步效果展示。该原型结合了两种数据库管理系统(DBMS)、一个架构和一组查询,并执行迁移。它建立在 SQLglot 上,并且还在手写规则不完整的情况下使用了 GPT-4 生成规则。对于文档信息获取,使用了 ChromaDB 和 OpenAI 的 text-embedding-ada-002。我们比较了四种方法:第一种方法是简单地提示 GPT-4,给出架构作为上下文;第二种是没有 Mallet 额外变换的 SQLglot;第三种和第四种是商业迁移工具 JOOQ 和 SQLines。
我们通过两个工作负载评估,将它们从 MySQL 转换到 PostgreSQL。第一个工作负载是 TPC-DS,它包含少量特殊功能,有助于展示规则生成相比每个查询翻译的显著性能优势。Mallet 是唯一能完全翻译查询的系统,应用规则的时间为 26ms,远快于简单使用 GPT-4 的 16s。第二个工作负载是 STPC-H,它增加了更多类型(如 JSON、二进制、空间类型)和更多特殊操作,每个系统应有其对应的 STPC-H。STPC-H 的详细结果将在第 3 节展示。总的来说,SQLglot 和 JOOQ 在处理特殊功能时存在小的语法错误或翻译错误,而 SQLines 根本无法进行转换。
FUTURE DIRECTIONS
智能联邦
智能联邦是下一步最重要的发展方向,因为即使无法翻译每一个特性,它也允许在成本和性能上获得实际部署的好处。Mallet 可以与 BRAD 结合使用,以优化数据布置和跨多个具有不兼容方言的系统的查询路由。
性能
到目前为止,我们关注的是 LLM 生成规则的可行性和正确性,但它们的性能也同样重要。我们计划生成多种替代的翻译同一功能的方法,使用静态微基准或多臂老虎机(MAB)来挑选表现最佳的方法。
模拟
Hyper-Q 研究表明,即使在某些功能不能被支持时,通过与系统互动的外部代理进行模拟也是可能的。我们将调查 LLM 生成的模拟来扩展我们的能力。
过程翻译
虽然我们关注于迁移数据和查询,许多应用程序使用自定义过程。为了避免依赖联邦,我们必须能够翻译这些过程。这个问题比查询翻译更复杂,因为它涉及到任意的命令式代码。然而,对于只使用简单过程的广泛类别应用,这可能是可解决的。
LLM 微调
我们目前使用的是增强了 RAG 和少数示例学习的通用 LLM。LLM 的微调是解决复杂任务的另一种选择。将要研究的两个问题是:(1) 为编码总体和特别是 SQL 生成进行微调的 LLM 是否更好?(2) 使用现有迁移作为训练数据,我们能否有效地针对 SQL 转换特别微调一个 LLM?
保密性
我们的方法在隐私合规方面表现更好,因为它可以避免发送用户的敏感查询到云端进行 LLM 翻译。然而,为了改善系统(例如,修复错误或完善特定功能),用户当前必须披露他们使用的特定功能。如何以保密的方式分享对个别功能的改进,是一个未解决的问题。
CONCLUSION
我们介绍了 Mallet,这是第一个使用大型语言模型(LLM)进行规则生成的自动 SQL 到 SQL 翻译工具。通过将功能翻译细分为简单步骤,适应性地用系统文档和人类专家知识增强提示,使用 SQL 系统本身自动生成少数示例学习案例,以及在 LLM 生成的测试案例上迭代验证结果,Mallet 旨在生成一套复杂且全面的规则,用于在不同系统之间翻译工作负载,而不将 LLM 置于关键路径上。这使其比手写方法更具可扩展性,同时保持速度和准确性。