
Translating between SQL Dialects for Cloud Migration
Translating between SQL Dialects for Cloud Migration
ABSTRACT
将系统从现场迁移到云端是许多工业机构的基本任务。此类云迁移的一个关键组成部分是将数据库转移到在线托管。在这项工作中,我们考虑了SQL数据库迁移的困难。尽管SQL是存储数据库程序的主要方法之一,但存在大量不同的SQL方言(例如,MySQL,Postgres等),当本地SQL方言与云端托管的方言不同时,这些方言会使迁移变得复杂。AWS和Azure等常见云服务提供商提供了一些工具来帮助方言之间的翻译,以缓解大部分困难。然而,这些工具无法成功翻译100%的代码。因此,软件工程师必须手动转换其余未翻译的数据库。对于大型组织来说,这项任务很快就变得难以处理,因此需要更创新的解决方案。
我们认为这个挑战是任何考虑云迁移的大型公司面临的新颖但重要的工业研究问题。此外,我们介绍了一些应对这一挑战的潜在研究途径,这些途径已经产生了有前景的初步结果。
INTRODUCTION
在过去的十年里,向云迁移的兴趣和需求一直在加速增长。确实,越来越多的公司选择将现场功能迁移到云端,以支持在云上托管应用程序和资源。SQL数据库迁移到云端是这些努力的一个重要组成部分。当现场和云端基础设施一致时(例如,本地SQL方言与云SQL方言匹配),这通常是一个简单的任务。然而,当情况不一致时,公司可能需要大量投资于工具、框架和开发人员的时间来解决这个问题。
大型云服务提供商通常不支持所有基于SQL的方言,因此需要在SQL方言之间进行翻译。模式转换工具在很大程度上可以自动化这项任务。然而,这些工具并不能总是100%地转换代码,开发人员需要手动转换工具无法处理的代码片段。虽然这对于较小的迁移来说可能并不太过于繁重,但较大的迁移可能涉及数十万行SQL代码,即使只有1%的代码不能转换,也需要大量的工作。因此,工业界必须寻找更自动化的方法来有效地将数据库迁移到云端。
在本文中,我们向研究界介绍了数据迁移的一个关键工业挑战:如何自动化转换现有数据库转换工具无法处理的SQL片段。由于缺乏可用的公共和私人数据,许多基于机器学习的方法并不适用。因此,我们提出了三条值得探索的途径来解决这个挑战:手动规则创建、模仿学习(IL)和大型语言模型(LLMs)。
PROBLEM DEFINITION
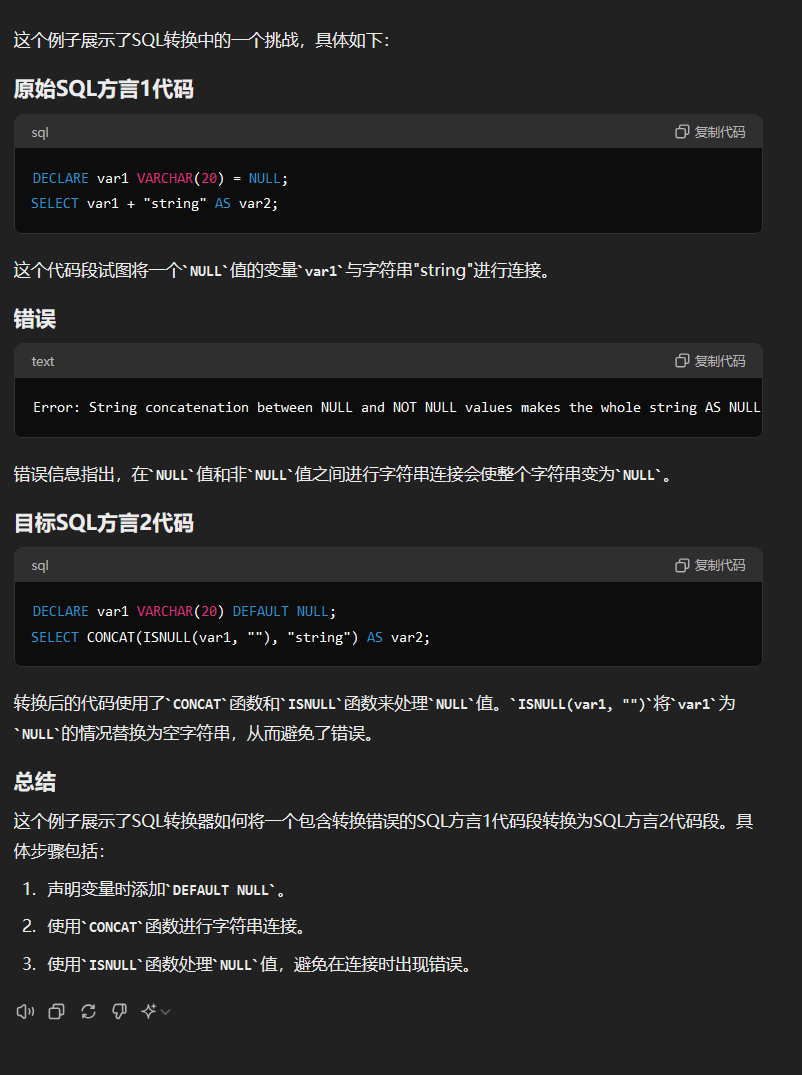
本研究引入的挑战比SQL-to-SQL翻译更复杂,最好结合图1进行解释。考虑将使用SQL方言1的数据库迁移到使用SQL方言2的数据库。第一步,我们利用常见工具转换大部分数据库。然而,这些工具通常无法转换整个代码库,未转换的部分需要手动处理;未转换的部分通常伴随着转换错误,并且往往比成功转换的代码段更复杂。因此,任务是自动将SQL方言1的代码段及其相应的错误转换为SQL方言2的代码段,以完成迁移。对于工业界来说,这个问题至关重要,因为大量的手动工作会对云迁移造成严重瓶颈。这些工作会带来巨大的财务影响,例如在本地和云上同时托管应用程序和数据库,以及执行手动转换的开发人员成本。
数据访问是克服此挑战的最大障碍之一。由于保密问题,大型组织通常无法公开数据进行研究,因此必须依赖公共数据来完成这项任务。不幸的是,目前没有公共数据集用于解决此问题。虽然可能通过网络抓取整理一个数据集,但这种尝试不太可能准确捕捉任务的实质。这是因为我们专门处理的是那些常见工具无法处理并且有错误指示的问题转换。此外,公开可用的代码通常不能代表工业代码的复杂性,也不太可能使用现有工具进行转换。因此,我们必须考虑在数据较少(甚至没有数据)的环境中解决这个问题,而不是依赖常见的翻译解决方案,这些解决方案利用机器学习。
这个例子好像不能说明什么问题。。。

POSSIBLE APPROACHES
3.1 Manual Rule Creation
大多数SQL解析器都是基于规则的。这是因为SQL方言具有有限的语法和确定的语法规则。尽管广泛使用的转换工具的细节没有公开,但通过分析它们的输出(特别是转换错误),我们认为这些流行的转换工具也是基于规则的。因此,针对我们问题的最简单方法可能是为重复出现的错误示例制定规则。这些规则可以集成到转换工具之上,以执行完整的数据库迁移。然而,这种方法有一个明显的局限性:我们必须手动构建规则。这不仅耗时,还需要了解相关SQL方言以及转换机制(即规则是如何实现的)。因此,虽然应用规则一直是SQL解析器和转换器的主要方法,但我们认为它不是解决当前任务的可持续解决方案。
我们进一步指出,如果范围仅限于非常简单的情况,我们可以将SQL迁移问题简化为编程语言抽象问题。
3.2 Imitation Learning
模仿学习是强化学习的一个分支,是一种人工智能技术,用于训练系统遵循特定的“策略”,并已在多种不同的背景下被采用。在我们的案例中,这个策略涉及如何在给定错误的情况下将SQL片段从一种方言转换为另一种方言。模仿学习具体要求“专家”(在我们的案例中,是熟悉必要手动转换的开发人员)向学习系统提供应如何操作的示例,系统随后学习模仿这种行为。
与规则创建相似,这种方法要求我们知道如何执行初始工具无法完成的手动转换。然而,模仿学习不要求我们自己开发规则。此外,仅需要少量示例(有时甚至是一个示例)来创建规则,这意味着对于高频转换错误,所需的工作量很少。因此,无论是技能障碍还是使用模仿学习工具的努力都比手动规则创建所需的要低得多。实际上,我们开发了一个模仿学习工具,该工具将SQL片段视为树,因此转换规则是树转换。该工具成功学习了处理初始测试集中超过80%的内容,并且正在进一步开发和测试以处理更复杂的错误。
3.3 Large Language Models
大型语言模型(LLMs),例如GPT-4、Bard等,已经展示了令人印象深刻的代码编写能力,因此成为解决这一挑战的有趣且有前途的方案。使用LLMs进行这些翻译的最吸引人的特点之一是无需进行手动转换。然而,LLM生成的解决方案并不能保证是正确的。研究表明,LLMs容易出现幻觉,这意味着生成的任何SQL片段中可能存在语法或语义错误。
通过对GPT-3.5的初步实验,我们发现尽管有正确的转换,但某些复杂的错误仍然导致不正确的转换。因此,任何应用LLMs的解决方案都必须包含强有力的验证,以确保返回的片段在语法上与目标SQL方言一致,并且保留了原始SQL片段的语义。
CONCLUSION
在这篇论文中,我们介绍了一个在工业界普遍存在的大规模SQL迁移中的独特问题。目前,各公司必须为那些广泛使用的工具无法处理的SQL片段规划不可持续的大规模手动转换工作。因此,组织面临着一个紧迫且艰难的研究挑战,即实现过程自动化。我们概述了三种应对这一挑战的途径:手动规则创建、模仿学习(IL)和大型语言模型(LLMs)。每种解决方案都能提高自动化水平,其中IL和LLMs显示出有前途的结果。我们希望这篇论文能够激发进一步研究所提出的解决方案,并可能鼓励提出全新的解决方案来应对这一挑战。