
MVP: Detecting Vulnerabilities using Patch-Enhanced Vulnerability Signatures
MVP: Detecting Vulnerabilities using Patch-Enhanced Vulnerability Signatures
ABSTRACT
复现漏洞在现实世界的系统中广泛存在并且通常未被检测到,这通常是由于重用代码库或共享代码逻辑所导致的。然而,脆弱函数与其修补函数之间潜在的小差异以及脆弱函数与目标检测函数之间可能存在的大差异,给基于克隆和函数匹配的检测方法带来了挑战,导致高误报率和漏报率。
在本文中,我们提出了一种新颖的方法来检测复现漏洞,具有低误报率和低漏报率。我们首先使用我们新颖的程序切片技术,从脆弱函数及其修补函数中提取漏洞和补丁签名,在语法和语义层面上进行分析。然后,如果目标函数匹配漏洞签名但不匹配补丁签名,则将其识别为潜在的脆弱函数。我们将该方法实现于一个名为MVP的工具中。我们在十个开源系统上的评估结果表明,i) MVP显著优于当前最先进的基于克隆和函数匹配的复现漏洞检测方法;ii) MVP检测到了一般漏洞检测方法无法检测到的复现漏洞,即两个基于学习的方法和两款商业工具;iii) MVP检测到97个新的漏洞,并已分配了23个CVE标识符。
INTRODUCTION
background
漏洞可以被利用来攻击软件系统,威胁系统安全。因此,尽早检测和修补软件系统中的漏洞非常重要。为了检测漏洞,已经开发了多种技术,如静态分析、模糊测试、符号执行和人工审计等。此外,还出现了一些技术用于自动修补漏洞,以减少补丁部署的延迟。
由于重用代码库或共享代码逻辑,具有相似特征的复现漏洞在软件系统中广泛存在,但在现实世界的程序中往往未被检测到。因此,复现漏洞的检测得到了广泛关注,尤其是在漏洞数量不断增加的情况下。本文的目标是检测复现漏洞,即在一个程序中表现出特定行为的漏洞,是否会在其他程序中也表现出这种特定行为。与此不同的是,通用漏洞检测技术倾向于利用大量漏洞的总体行为来发现这些行为的特定实例。
related work
总体思路:
- 通过匹配目标系统的源代码与已知漏洞的源代码来检测复现漏洞。
- 现有方法可以分为基于克隆和基于函数匹配的两类。
基于克隆的方法:
- 将复现漏洞检测问题视为代码克隆检测问题。
- 提取已知漏洞的标记或语法级别签名,识别与这些签名匹配的代码克隆并标记为潜在漏洞。
基于函数匹配的方法:
- 使用已知漏洞中的脆弱函数作为签名,检测与这些脆弱函数匹配的代码克隆。
- 不考虑漏洞特性,因为这些方法并非特别为复现漏洞检测设计的。
局限性:
- 由于克隆检测的性质,未考虑漏洞修复的方式,导致无法区分脆弱函数和修补函数之间的微小差异,造成高误报率。
- 对于与已知漏洞代码差异较大的复现漏洞,这些方法无法检测,导致高漏报率。
challenges
检测复现漏洞的主要挑战概括如下:
- 区分已修补的漏洞:如何区分已经修补过的漏洞以减少误报率。
- 生成精确的漏洞签名:如何精确生成已知漏洞的签名,以同时减少误报率和漏报率。
这两个挑战都涉及如何在复现漏洞检测中实现低误报率和低漏报率。
approach
为了解决两个主要挑战,提出了一种新颖的复现漏洞检测方法,名为MVP(Matching Vulnerabilities with Patches)。具体包括:
- 生成漏洞和补丁签名:不仅生成漏洞签名,还生成补丁签名,以捕捉漏洞的产生和修复过程。这有助于区分潜在脆弱函数是否已被修补。
- 使用新颖的切片方法:提出了一种新的切片方法,仅提取与漏洞和补丁相关的语句,在语法和语义层面生成签名。
- 应用语句抽象和基于熵的语句选择:进一步提高MVP的检测精度。
这些方法共同解决了区分已修补漏洞和生成精确漏洞签名的挑战。
evaluation and contributions
评估:
- MVP在包含25,377个安全补丁的十个开源系统上进行了评估。
- 与两个最先进的基于克隆的方法(ReDeBug和VUUDY)相比,MVP提高了74.5%和75.6%的精度,以及42.4%和65.8%的召回率。
- MVP检测出97个新漏洞,并分配了23个CVE标识符。
- 与基于函数匹配的方法(SourcererCC和CCAligner)相比,MVP提高了83.1%和83.3%的精度,以及22.5%和30.6%的召回率。
- 与基于学习的方法(VulDeePecker和Devign)和商业工具(Coverity和Checkmarx)相比,MVP展示了其在检测复现漏洞方面的优势。
贡献:
- 提出了利用漏洞和补丁签名的新颖切片技术,开发并实现了一种新的复现漏洞检测方法。
- 进行了深入的评估,将MVP与四类最先进的方法进行了比较,MVP在精度上显著优于它们。
- 在十个开源系统中发现了97个新漏洞,并分配了23个CVE标识符。
Motivation
Problems
- 漏洞函数与修补函数的相似性问题:
- 大部分漏洞函数和修补函数之间的代码差异较小。由于此相似性,基于克隆的方法可能会错误地将修补函数识别为漏洞函数,从而引发高误报率。
- 漏洞函数与目标函数的相似性问题:
- 如果漏洞函数和目标函数的相似性较低,现有方法可能无法检测到目标函数中的漏洞。在评估中,35.1%的实际漏洞函数与目标函数的相似性低于70%,导致现有方法无法检测到这些漏洞函数,从而引发高漏报率。
总结来说,现有方法在处理漏洞函数与修补函数或目标函数的相似性时容易产生误报和漏报的问题。
A Motivating Example
为说明现有方法的局限性并引出MVP的概念,本文使用Qcacld-2.0中的一个漏洞作为示例。Qcacld-2.0是Qualcomm WLAN的开源驱动程序,广泛用于Android手机中。示例展示了一个越界访问漏洞,以及相应的补丁修复措施。
- 基于克隆的方法(如ReDeBug):通过纯语法级匹配来检测复现漏洞。ReDeBug在漏洞补丁前后提取几行代码生成漏洞签名。然而,由于修补函数中的语法与漏洞签名相同,ReDeBug错误地将修补函数识别为漏洞函数,导致误报。
- MVP方法:MVP识别漏洞的根本原因,即缺少对局部变量
vdev_id的检查,该变量在后续用作数组访问的索引。MVP通过构建vdev_id的语义数据流签名来检测语义等效的漏洞,即使这些漏洞的语法有所变化。
这一概念说明了MVP在处理语法略有变化的语义等效漏洞时的优势。

这个motivation example展示了在Qcacld-2.0中修复的一个越界访问漏洞,并用来说明现有方法的局限性及MVP方法的优势。
- 漏洞类型:越界访问漏洞。
- 漏洞位置:函数
WDA_TxPacket中。- 修复措施:补丁在第18-22行添加了对局部变量
vdev_id的检查,确保其值不超过wma_handle->max_bssid。这个检查防止了在第28行中使用vdev_id作为数组wma_handle->interfaces的索引时发生越界访问。现有方法的局限性:
- ReDeBug方法:ReDeBug通过语法级别的匹配来检测漏洞,它从补丁前后的几行代码生成漏洞签名,并在目标函数中寻找匹配的签名。
- 问题:由于修补函数中的某些代码行(如第20-22行和第23-25行)与漏洞签名语法相同,ReDeBug误将修补函数识别为漏洞函数,导致误报。
MVP方法的优势:
- 识别漏洞根源:MVP识别出漏洞的根本原因是缺少对局部变量
vdev_id的检查,该变量用于后续的数组访问。- 语义检测:MVP通过构建
vdev_id的语义数据流签名,可以检测出语法稍有不同但语义等效的漏洞,避免了ReDeBug中的误报问题。这个例子展示了MVP如何通过更深入的语义分析克服现有方法在处理语法相似但语义不同的修补函数时的局限性。
Methodology
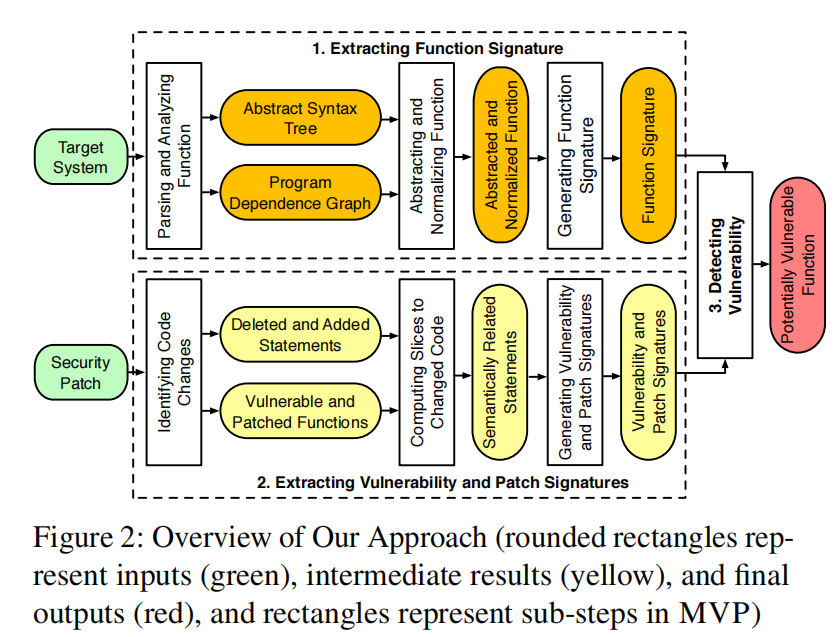
图2展示了MVP的概览,包含三个步骤。
- 提取函数签名步骤(§ 3.2)接收一个目标系统作为输入,并为目标系统中的每个函数生成一个签名。
- 提取漏洞和补丁签名步骤(§ 3.3)接收一个安全补丁作为输入,并生成一个漏洞签名和一个补丁签名,以反映漏洞是如何产生和修复的。
- 最后一步检测漏洞步骤(§ 3.4)通过将目标系统中每个函数的签名与漏洞和补丁签名进行匹配,来确定该函数是否可能存在漏洞。
3.1 Definition
1. 函数签名定义:
函数签名由语法签名(
fsynf_{syn}fsyn
)和语义签名(
fsemf_{sem}fsem
)组成。
- fsynf_{syn}fsyn:函数中所有语句的哈希值集合,表示目标函数的语法特征。
- fsemf_{sem}fsem:包含数据和控制依赖关系的三元组集合,描述语句之间的依赖关系,表示函数的语义特征。
这些签名提供了函数的互补信息,有助于提高匹配精度。
2. 函数补丁定义:
- 函数补丁由一个或多个hunk组成,hunk包括上下文行、删除行和添加行。
- 删除行:在脆弱函数中存在但在修补函数中缺失的行。
- 添加行:在修补函数中存在但在脆弱函数中缺失的行。
- 进一步定义了:
- Sdel:脆弱函数中存在但在修补函数中缺失的语句集合。
- **Sadd:修补函数中存在但在脆弱函数中缺失的语句集合。
- Svul:脆弱函数中的所有语句。
- Spat:修补函数中的所有语句。
这些定义为后续分析漏洞和修补函数之间的关系奠定了基础。
3.2 Extracting Function Signature
3.2节描述了提取函数签名的过程,分为三个步骤:
- 解析和分析函数(3.2.1):
- 使用解析工具解析目标系统的源代码,生成抽象语法树(AST)和程序依赖图(PDG)。
- 通过这些图提取出目标系统中每个函数的语句及其依赖关系。
- 抽象和规范化函数(3.2.2):
- 识别并替换函数中的形式参数、本地变量和字符串字面量,使用标准化符号(如
PARAM、VARIABLE、STRING)替换变量和字符串,以减少命名不同带来的干扰。 - 对格式字符串相关漏洞进行了特殊处理,将格式字符串抽象为通用的符号,以避免格式字符串引发的漏洞检测问题。
- 通过规范化,去除了函数体中的注释、括号和空格,提升对代码格式的容忍度。
- 识别并替换函数中的形式参数、本地变量和字符串字面量,使用标准化符号(如
- 生成函数签名(3.2.3):
- 通过对抽象后的语句进行哈希运算,生成语法签名(fsyn),并提取数据和控制依赖关系生成语义签名(fsem)。
- 语法签名表示函数的语句特征,而语义签名则表示函数内部语句间的依赖关系,两者共同构成函数签名。
通过这些步骤,MVP能够更准确地匹配和检测潜在的漏洞。
3.3 Extracting Vulnerability and Patch Signatures
3.3节描述了提取漏洞和补丁签名的过程,分为三个主要步骤:
- 识别代码更改(3.3.1):
- 通过解析安全补丁的头文件,确定代码中已删除和已添加的语句。
- 使用这些信息提取脆弱函数和修补函数中的更改语句集(Sdel 和 Sadd)以及所有相关语句集(Svul 和 Spat)。
- 计算代码切片(3.3.2):
- 利用切片技术提取与更改语句相关的数据和控制依赖语句,通过正向和逆向切片方法减少噪声。
- 对不同类型的语句(如赋值语句、条件语句、返回语句等)采用特定的切片策略,确保涵盖与漏洞相关的所有关键语句。
- 生成漏洞和补丁签名(3.3.3):
- 生成漏洞签名(Vsyn 和 Vsem)和补丁签名(Psyn 和 Psem),分别表示在语法和语义层面的漏洞特征和补丁特征。
- 通过信息熵的方式对提取的语句集进行优化,以减少噪声和错误匹配。
这一节详细阐述了如何通过解析补丁和利用代码切片技术生成准确的漏洞和补丁签名,以提高检测的精度并减少误报和漏报。
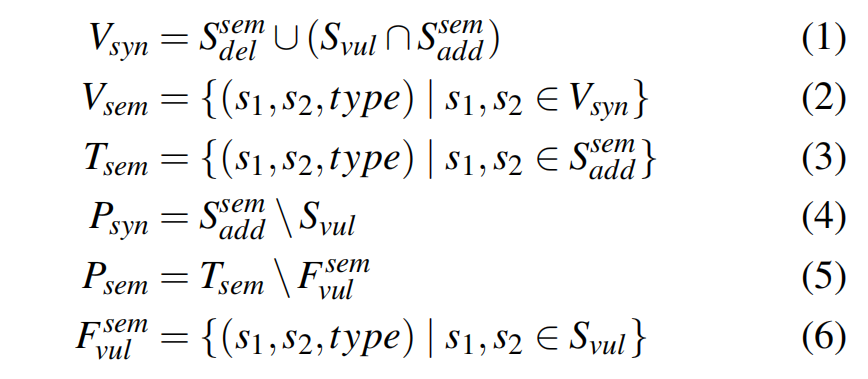
3.4 Detecting Vulnerability through Matching
3.4节描述了通过匹配检测漏洞的方法,提出了确定目标函数是否可能存在漏洞的五个条件(C1到C5):
- C1:目标函数必须包含所有已删除的语句,确保这些与漏洞相关的语句被保留。
- C2:目标函数的语法签名与漏洞签名匹配的程度必须超过阈值 t1。
- C3:目标函数的语法签名与补丁签名的匹配程度不能超过阈值 t2,以确保修补后的特征不会被错误匹配。
- C4:目标函数的语义签名与漏洞签名匹配的程度必须超过阈值 t3。
- C5:目标函数的语义签名与补丁签名的匹配程度不能超过阈值 t4,以避免误报修补后的特征。
这些条件通过比较目标函数与漏洞函数和修补函数的签名,在语法和语义层面检测潜在的漏洞。根据敏感性分析,推荐的阈值为 t1和 t3 为0.8,t2 和 t4 为0.2,但用户可以根据需要进行配置。
总结来说,这部分定义了匹配规则,以减少误报和漏报,并提供了可调节的阈值设置以优化检测效果。
Evaluation
4.1 Evaluation Setup
4.1节描述了评估MVP方法的设置,包括以下几个方面:
- 研究问题:
- RQ1: MVP在检测复现漏洞方面的准确性如何?
- RQ2: MVP在检测复现漏洞方面的可扩展性如何?
- RQ3: MVP中可配置的阈值在匹配组件中的敏感性如何?
- RQ4: 抽象语句和语句选择方法的采用如何提高MVP的准确性?
- RQ5: 通用漏洞检测方法在检测复现漏洞方面的表现如何?
- 数据集:
- 选择了十个开源项目作为评估数据集,这些项目包含大量的C/C++代码,并涵盖了广泛的应用领域,如操作系统内核、图像处理、压缩、通信工具包和WLAN驱动程序。
- 收集了这些项目的安全补丁及其在国家漏洞数据库(NVD)中的漏洞标识符,并记录了与漏洞相关的代码更改。
- 比较方法:
- 评估了与MVP相比的四种最先进的方法,包括基于克隆的ReDeBug和VUUDY,基于函数匹配的SourcererCC和CCAligner,以及基于学习的VulDeePecker和Devign。
- 还包括两个广泛使用的商业静态分析工具Coverity和Checkmarx,尽管它们主要用于通用漏洞检测,但用于展示MVP的优势。
- 评估配置:
- MVP在6500个文件和500万行代码中进行了实现和评估,所有比较的方法在实验中都使用了其原始论文中报告的设置。
这一节为后续的评估实验奠定了基础,通过提出研究问题和选择合适的数据集与比较方法,旨在全面评估MVP在检测复现漏洞方面的性能。
4.2 Accuracy Evaluation (RQ1)
4.2节主要探讨了MVP的准确性评估(RQ1),通过与现有的先进方法进行比较,展示了MVP在检测复现漏洞方面的表现。以下是主要内容的概括:
- 准确性评估:
- 使用精度(Precision)和召回率(Recall)作为衡量指标,比较了MVP与ReDeBug、VUUDY这两种基于克隆的方法的表现。
- MVP在检测潜在漏洞函数时,达到了83.6%的精度和81.4%的召回率,而ReDeBug和VUUDY的精度和召回率分别较低。
- MVP的误报率(False Positive)显著低于ReDeBug和VUUDY,尤其在两个项目中没有出现误报。
- 误报分析:
- 通过对MVP的误报进行分析,发现主要原因包括缺少过程间分析和语义等效性的问题,这导致了9次误报。
- 另外,ReDeBug和VUUDY的误报也进行了详细分析,揭示了它们在处理补丁时引入的误报问题。
- 与SourcererCC和CCAligner的比较:
- 比较表明MVP显著提高了精度,分别达到83.1%和83.3%,召回率也提升了22.5%和30.6%。
- 漏洞函数与目标函数的相似性分析:
- 对于不同方法,MVP能够更好地检测与漏洞函数相似性低的目标函数。
4.3 Scalability Evaluation (RQ2)
4.3节讨论了MVP的可扩展性评估(RQ2),并与基于克隆的漏洞检测方法ReDeBug和VUUDY进行了比较。以下是主要内容的概括:
- 基本组件:MVP、ReDeBug和VUUDY都包含三个基本组件:
- 系统分析:提取目标系统中每个目标函数的信息。
- 补丁分析:生成漏洞的签名。
- 匹配:搜索目标函数中的漏洞。
- 性能开销:
- 系统分析:MVP由于进行语义分析,花费了比VUUDY多3.2倍的时间,但仍能扩展到大型系统。例如,MVP在Linux内核上的分析时间为10.4小时。
- 补丁分析:MVP花费的时间是VUUDY的3.3倍,平均耗时17,272.82毫秒从安全补丁中提取签名。
- 匹配过程:所有三个方法在匹配上的表现都很快。
- 总结:虽然MVP在分析时间上比ReDeBug和VUUDY慢,但它具有更高的精度,这显著减少了手动验证潜在漏洞函数所需的时间。MVP仍然能够扩展到大型系统,并且由于减少了误报,它可能会节省更多的时间。
这个部分强调了MVP的可扩展性,即使在处理大型项目时,MVP的时间开销仍在可接受范围内,特别是考虑到其更高的精度。
4.4 Threshold Sensitivity Analysis (RQ3)
4.4节讨论了MVP方法中阈值的敏感性分析(RQ3)。以下是主要内容的概括:
- 默认配置:在MVP的匹配步骤中,四个可配置的阈值(t1,t2,t3,t4t_1, t_2, t_3, t_4t1,t2,t3,t4)的默认配置为0.8、0.2、0.8和0.2。通过调整这些阈值,评估了它们对MVP准确性的影响。
- 调整阈值:
- t1t_1t1 和 t3t_3t3 控制函数签名是否与漏洞签名匹配的阈值,分别从0.1到1.0进行调整。
- t2t_2t2 和 t4t_4t4 控制函数签名是否不与补丁签名匹配的阈值,分别从0.0到0.9进行调整。
- 共执行了35种不同的配置,并分析了检测结果,发现了8个在默认配置下未检测到的漏洞。
- 结果分析:
- 当 t3t_3t3 增加到0.7之前,精度和召回率在大多数系统中保持稳定;当 t3t_3t3 进一步增加到1.0时,精度增加而召回率下降。
- t1t_1t1 从0.1增加到0.8时,精度显著提高。较严格的匹配条件导致了更少的误报,但召回率有所下降。
- 对于 t2t_2t2 和 t4t_4t4,将其从0.0到0.2时,精度略有提高,因此0.2被认为是这些阈值的最佳值。
- 总结:表5显示了不同阈值配置对精度和召回率的影响,最佳配置为 t1t_1t1 和 t3t_3t3 为0.8,t2t_2t2 和 t4t_4t4 为0.2。通过适当配置阈值,MVP在精度和召回率之间取得了良好的平衡。
这一部分的分析帮助优化了MVP的匹配参数,使得在保持较高检测精度的同时减少漏报和误报。
4.5 Contribution of Statement Abstraction and Statement Information (RQ4)
4.5节讨论了语句抽象和语句信息对MVP的贡献(RQ4)。
- 语句抽象的贡献:
- MVP在生成函数签名时使用了语句抽象。通过去除语句抽象来运行MVP,并分析潜在的漏洞函数,发现仅有11个更多的漏报(即Linux内核中的3个,ImageMagick中的5个,以及Qcacld-2.0中的3个)。
- 结果表明,语句抽象能够提高MVP的表现,使其多检测到12.8%的漏洞。
- 语句信息的贡献:
- MVP在提取漏洞签名时采用了语句信息。为了评估这一点,配置MVP在禁用和启用语句信息的情况下运行,调整了阈值 tImaxt_{I}^{max}tImax 从4到8。
- 通过对比分析,表5的结果表明,采用语句信息显著提高了MVP的准确性,并且阈值5被验证为tImaxt_{I}^{max}tImax的最佳值。
总结来说,语句抽象和语句信息的应用分别提高了MVP的漏洞检测能力和准确性。
4.6 Performance of General-Purpose Vulnerability Detection (RQ5)
4.6节讨论了通用漏洞检测工具的性能评估(RQ5)。
- VulDeePecker和Devign的表现:
- VulDeePecker只检测到111个复现漏洞中的8个,召回率为7.2%;Devign检测到40个,召回率为36.0%。
- VulDeePecker的高漏报率主要是因为它只能处理调用特定库函数或API的函数,而Devign只能处理节点少于500的函数。
- 特别是在Linux内核中,VulDeePecker未能检测到任何复现漏洞,而Devign检测到了其中的19个,召回率为59.3%。
- 结果表明,基于学习的方法可能不适合发现复现漏洞,而MVP在这方面具有优势。
- 与Coverity和Checkmarx的比较:
- Coverity在十个项目中只检测到4个复现漏洞,而Checkmarx未能检测到任何复现漏洞。
- 这些结果表明,静态扫描工具在发现复现漏洞方面效果不佳,MVP是一个值得考虑的方法。
总结来说,通用漏洞检测工具在处理复现漏洞方面表现不理想,进一步强调了MVP方法的有效性和价值。