
SQLaser: Detecting DBMS Logic Bugs with Clause-Guided Fuzzing
SQLaser: Detecting DBMS Logic Bugs with Clause-Guided Fuzzing
这篇文章是arXiv 24上的,存在许多问题,不值得学习。。。
ABSTRACT
数据库管理系统(DBMS)是现代数据驱动系统中的重要组成部分。由于其复杂性,这些系统中往往会出现逻辑错误,这些错误是DBMS内部的实现错误,可能导致错误的查询结果、数据泄露、未经授权的访问等问题,而这些错误并不一定会引起系统的明显故障。现有的检测方法主要采用两种策略:基于规则的错误检测和基于覆盖率的模糊测试。然而,规则的指定本身就是一个挑战,因此基于规则的检测通常仅限于特定和简单的规则。基于覆盖率的模糊测试则是盲目地探索代码路径或代码块,其中许多路径不太可能包含逻辑错误,因此这种策略的成本效益较低。
在本文中,我们设计了SQLaser,一种基于SQL子句引导的模糊测试工具,用于检测DBMS中的逻辑错误。通过对现有大多数逻辑错误的全面研究(不包括导致系统崩溃的错误),我们识别了35种逻辑错误模式。这些模式表现为某些常见的SQL子句组合,而这些子句组合背后是一系列函数的组合。因此,我们将逻辑错误模式建模为容易出错的函数链(即一系列函数的组合)。我们进一步开发了一种新的路径到路径距离计算机制,以有效地测试这些链条并发现其他逻辑错误。该机制使SQLaser能够迅速导航到目标站点并揭示从这些路径中出现的潜在错误。
我们的评估是在SQLite、MySQL、PostgreSQL和TiDB上进行的,结果表明,与其他模糊测试方法相比,SQLaser显著加快了错误发现的速度,将检测时间减少了约60%。作为一个独立的测试工具,SQLaser在相同的测试期间(即60天)内发现了22个错误,涵盖了35种逻辑错误模式中的18种,而像SQLRight这样的模糊测试工具在相同的测试期间内只发现了2个错误。此外,SQLaser发现的4个错误是零日漏洞,所有这些错误已向厂商报告并得到确认。
关键词:数据库管理系统、逻辑错误检测、定向模糊测试。
子句组合背后是一系列函数的组合,验证了我们的motivation
Introduction
related work:
数据库管理系统(DBMS)作为现代数据驱动应用的核心组件,广泛用于数据的集中存储和管理。例如,SQLite在全球约35亿部智能手机上被使用。由于DBMS在现代应用中扮演着至关重要的角色,其内部的逻辑错误可能会导致严重后果。这些逻辑错误通常是由DBMS代码实现中的错误引起的,可能导致一系列问题,如错误的查询结果、敏感数据泄露、未经授权的访问和数据损坏。
逻辑错误的检测挑战:
- 大多数逻辑错误不会导致系统崩溃,因此很难被检测到。
- 研究人员提出了多种Oracle机制来检测SQL查询结果的错误,例如:
- NoREC Oracle:将原始SQL查询转换为一个等效形式,如果两者结果有差异,则可能存在逻辑错误。
- TLP Oracle:通过组合多个子查询来实现原始查询的语义,如果结果不同,则表明可能存在错误。
现有工具的局限性:
- SQLancer:实现了多种Oracle机制,但由于其基于特定规则生成SQL查询,可能限制了代码路径的探索。
- SQLRight:为了解决SQLancer的局限性,引入了基于覆盖率引导的模糊测试,通过有效性导向的变异生成高质量查询语句,增加代码覆盖率,从而更高效地发现更多的逻辑错误
总结来说,现有的研究针对DBMS中的逻辑错误提出了多种检测方法,包括差分测试和基于覆盖率的模糊测试,但这些方法在探索范围和效率上各有优劣
总结的不太对,差分测试的思想是变换不同组件,SQLancer等应该是蜕变测试。而且SQLRight也实现几种test oracle?侧重的点不同而已
limitations
- motivation example未考虑多种SQL子句组合的效果:
- 尽管已有很多工作致力于检测DBMS中的逻辑错误,但现有研究往往忽视了逻辑错误模式背后多种SQL子句组合的综合影响。文章中提到的示例显示,在SQLite中,由于错误地应用了NOCASE操作,导致条件表达式的错误结果,这表明逻辑错误的产生往往是多种子句和函数交互的结果。

- SQLRight的不足:
- SQLRight在选择测试用例(种子)时,假设每个种子触发逻辑错误的可能性相同。这种覆盖率引导的模糊测试方法未能有效地优先测试更可能触发逻辑错误的代码路径,导致探索的代码路径中很多部分是无效的,从而降低了检测效率。 我不太赞同这个说法,覆盖率就是Fuzzing的最终目的
- 针对性不足:
- 基于覆盖率的模糊测试方法主要关注尽可能多地覆盖代码路径,而不是有针对性地快速到达和测试预定义的目标站点(即可能存在逻辑错误的地方)。这种策略在发现逻辑错误方面效率较低,因为它忽略了特定SQL子句组合所对应的易出错的代码目标。
- 三大关键问题:
- 如何识别SQL层面的错误模式?
- 如何将这些SQL层面的错误模式作为定向模糊测试的目标站点?
- 如何设计一个定向模糊测试工具,能够快速到达和测试预定义的目标站点?这些问题在现有的方法中尚未得到有效解决。
总结:现有方法在覆盖率引导模糊测试中往往缺乏针对性和效率,难以识别和优先测试特定的SQL逻辑错误模式。因此,本文提出了基于SQL子句组合引导的定向模糊测试,以更高效地检测数据库管理系统中的逻辑错误。
approaches
问题 1:系统性研究现有逻辑错误:
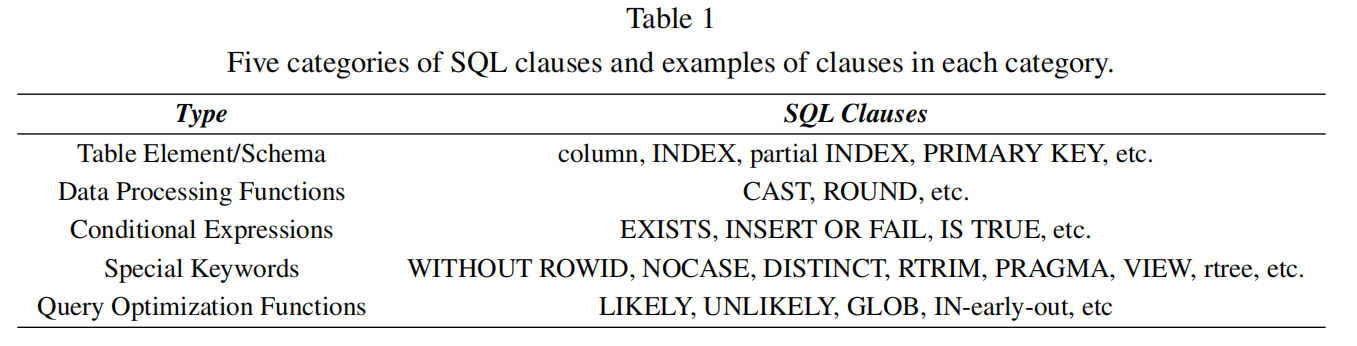
- 文章首次系统性地研究了四个不同DBMS(SQLite、MySQL、PostgreSQL和TiDB)中大部分已知的逻辑错误(不包括导致系统崩溃的错误)。研究发现某些SQL子句或子句组合(如表元素/模式、数据处理函数、条件表达式、特殊关键字、查询优化函数等)容易导致逻辑错误。作者总结了35种与现有逻辑错误相关的SQL子句组合模式。
问题 2:动态追踪和分析代码路径:
- 通过动态分析,作者发现执行SQL语句导致逻辑错误时,通常涉及一系列函数调用链。为了在定向模糊测试中使用这些函数调用链作为目标站点,作者提出了一种方法来“修剪”函数调用链,去除与SQL逻辑错误模式无关的函数。这样可以有效聚焦在真正的错误点上,避免由于调用链过长而导致的检测效率低下。 SQL精简?
问题 3:提出SQLaser工具:
- 为了解决上述问题,作者提出了SQLaser,这是一种基于子句引导的模型,用于检测DBMS中的逻辑错误。SQLaser引入了一种新的方法来计算种子和目标站点之间的距离,并利用基于区分度的策略来优先选择更接近目标调用链的种子。最终,SQLaser利用SQLRight的测试Oracle,通过生成原始查询的变体并评估其执行结果来有效地检测逻辑错误,同时确保查询功能的完整性。
Evaluation
- 覆盖DBMS范围广泛:
- SQLaser在四个主流DBMS系统(SQLite、MySQL、PostgreSQL和TiDB)上进行了评估。结果显示,SQLaser可以重现所有35种已知的逻辑错误模式(即SQL子句组合),这些错误模式是从现有工具的集体发现中总结出来的。
- 发现新的逻辑错误:
- SQLaser成功发现了35种错误模式中的22个逻辑错误。其中,4个是其他模糊测试工具无法检测到的新型错误,这些错误已经全部报告给供应商并得到确认。
- 效率显著提升:
- 相比SQLRight和传统的定向模糊测试方法,SQLaser的检测效率提高了约60%。它能够更快地到达目标站点,并有效地验证是否存在逻辑错误。
contributions
- 系统性研究:
- 首次系统性地研究了DBMS中的大多数逻辑错误,揭示了这些错误源自于特定SQL子句组合,以及背后的一系列关键函数。基于此发现,提出了子句引导的模糊测试(clause-guided fuzzing),能够聚焦于容易出错的函数链,从而高效地发现逻辑错误。
- 新的模糊测试反馈机制:
- 提出了一种新的模糊测试反馈机制,可以计算种子调用链与目标调用链之间的距离。这种路径到路径的距离计算不同于传统的单点距离计算,支持基于路径的定向模糊测试,使得SQLaser能够优先选择更接近目标路径的种子。
- 开发SQLaser工具:
- 提出了SQLaser工具,利用定向模糊测试高效地导航到目标站点,并自动生成输入查询以验证是否能触发逻辑错误。通过实验验证了SQLaser的有效性和性能。相比于基于覆盖率引导的模糊测试和传统的定向模糊测试方法,SQLaser在效率上提升了约60%。
总结:SQLaser不仅能够重现现有的已知逻辑错误模式,还能够发现新的逻辑错误,并显著提高了逻辑错误检测的效率。
Background
2.1. Logic Bugs and Threat Model
一个logical bug 的 example。 SQLaser工具发现了一些新的逻辑错误,例如MySQL中的ANY逻辑错误和LIKE逻辑错误,这些错误可能会导致DBMS泄露不应暴露给用户的数据。对于DBMS安全或特权信息而言,这些逻辑错误会带来显著的安全风险。
2.2. Logic Bug Testing Oracles and Differential Testing
差分测试和各种Oracle机制提供了检测DBMS逻辑错误的有效手段,但构建覆盖所有逻辑错误的Oracle具有挑战性。每种Oracle方法都有其适用场景和局限性,需要针对特定DBMS功能特点进行设计。
2.3. Coverage-guided Fuzzing and Directed Fuzzing
基于覆盖率的模糊测试(Coverage-guided Fuzzing):
- 这是一种软件测试技术,涉及向程序提供无效、意外或随机的数据输入,并观察程序如何响应这些输入,以发现漏洞或错误。
- 其核心思想是测量当前输入集所实现的代码覆盖率,并利用这些信息生成新的测试输入,从而探索新的或未覆盖的代码路径。此方法旨在最大化程序代码的探索,增加发现隐藏漏洞的机会。
- 基于覆盖率的模糊测试已被应用于多种程序测试,包括操作系统、编译器、网页浏览器、文档阅读器和智能合约等。最近的研究也将其用于测试DBMS系统,如SQLRight通过这种方法在SQLite和MySQL中发现逻辑错误。
定向模糊测试(Directed Fuzzing):
- 定向模糊测试则是提供有针对性的特定输入,以探索特定的代码路径或功能。与依赖随机或变异输入的基于覆盖率的模糊测试不同,定向模糊测试更加集中和有目的性。
- 这种方法通常用于已经知道潜在漏洞位置或测试特定程序功能时。例如,在本文中,定向模糊测试被用于故意检测逻辑错误,而不是随机测试代码路径。研究人员将大部分时间分配给这些高度可能触发逻辑错误的路径,以提高发现错误的效率。
总结:基于覆盖率的模糊测试侧重于代码路径的广泛覆盖,通过随机或变异输入来发现潜在的漏洞;而定向模糊测试则更关注已知问题区域或特定代码路径,以更加精确、高效地检测逻辑错误。两者在不同场景中各有优势,并可以互补使用。
Analysis of Existing Logic Bug Patterns
研究范围:
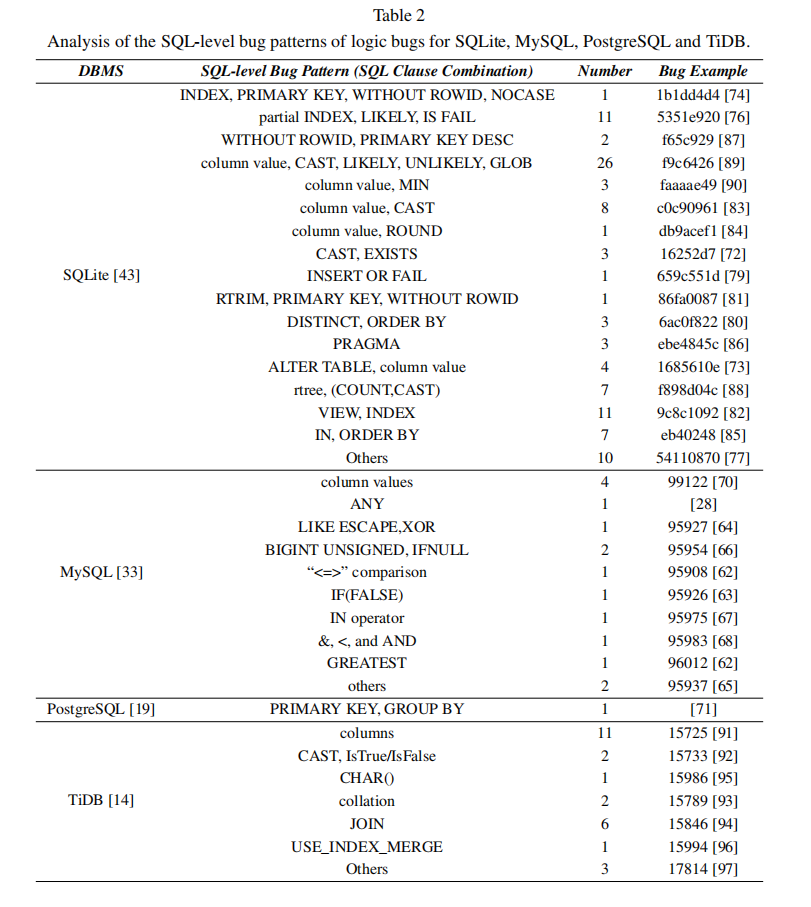
- 本研究对四个不同数据库管理系统(DBMS)中的144个现有逻辑错误进行了系统性研究,包括SQLite(102个错误)、MySQL(15个错误)、PostgreSQL(1个错误)和TiDB(26个错误)。研究排除了导致系统崩溃的错误,主要关注那些不会导致可观测系统故障(如崩溃)的逻辑错误。
144个太少了,分类的意义在哪里?
SQL子句分类:
- 根据SQL子句的语义,将与这些逻辑错误相关的子句分为五类:
- 表元素/模式(Table Element/Schema):涉及已创建表中的元素或模式,例如列索引、列值和主键。
- 数据处理函数(Data Processing Functions):涉及数据处理函数,例如将数据类型转换为兼容的另一种数据类型的
CAST函数,或将数值进行四舍五入的ROUND函数。 - 条件表达式(Conditional Expressions):用于条件检查的表达式,例如
EXISTS、INSERT OR FAIL等,确保数据完整性,防止插入无效或重复的记录。 - 特殊关键字(Special Keywords):用于设置约束或定义虚拟表等特定结构的特殊关键字,例如
WITHOUT ROWID、NOCASE、DISTINCT等。 - 查询优化函数(Query Optimization Functions):用于进一步优化和控制查询执行的函数,例如LIKELY 函数表示某个条件可能发生,函数表示某个条件可能发生,而
UNLIKELY表示某个条件不太可能发生
错误模式分类:
- 基于这些SQL子句的分类,研究将现有逻辑错误划分为35种错误模式。其中,SQLite中有17种模式,MySQL中有10种,PostgreSQL中有1种,TiDB中有7种。
SQLaser
overview
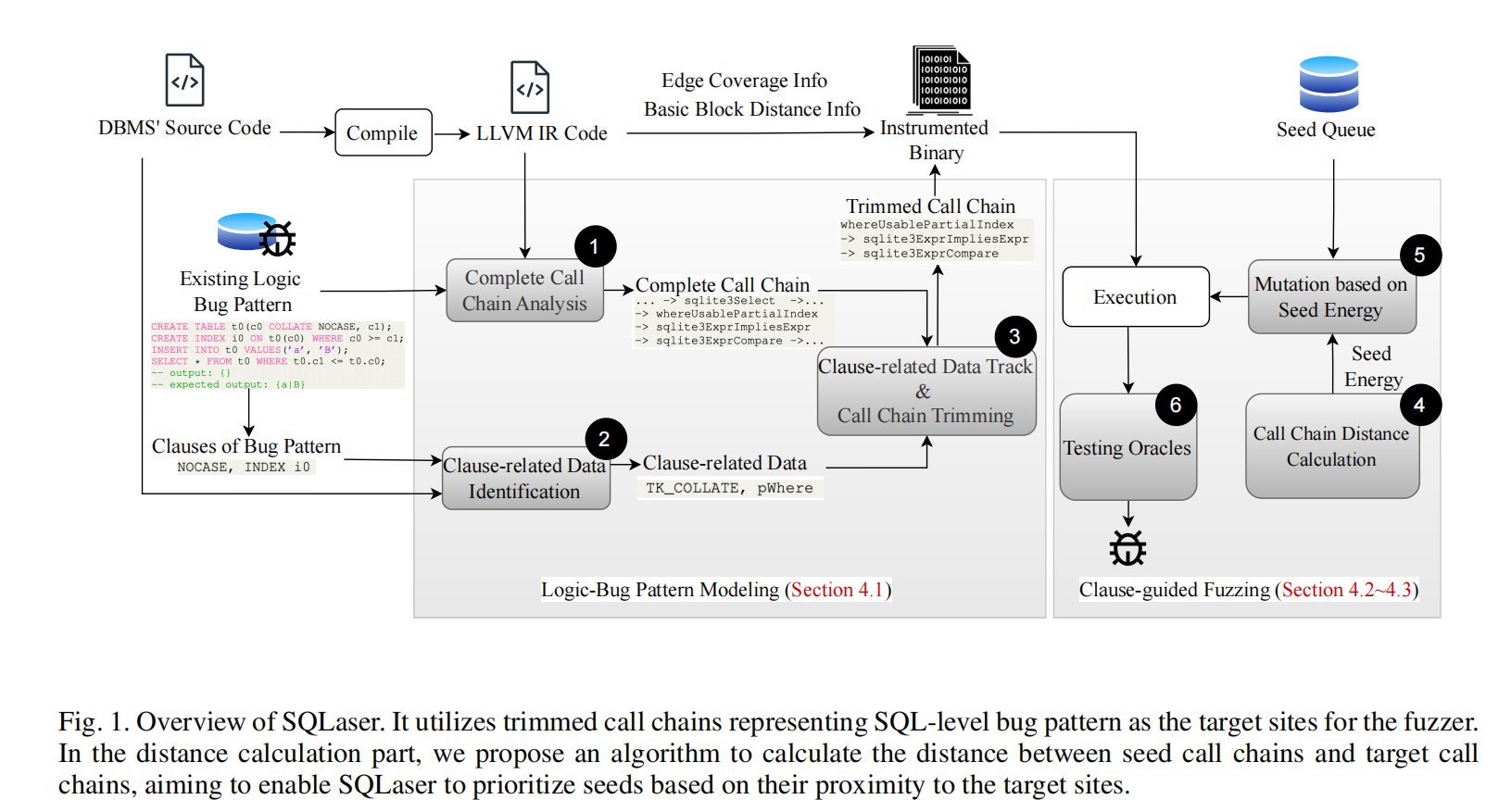
SQLaser工具的概览由两个主要部分组成:逻辑错误模式建模和子句引导模糊测试。
- 逻辑错误模式建模(Logic-bug Pattern Modeling):
- 在这一阶段,SQLaser的目标是将逻辑错误模式的信息作为调用链(call chains)插入到二进制代码中。这些调用链在模糊测试阶段表现为目标调用链。
- 首先,通过动态分析(Step ❶),SQLaser获取在错误发生时执行的完整调用链。然而,完整的调用链中包含许多与错误无关的函数,过多的函数会限制模糊测试的探索能力。
- 为了解决这个问题,SQLaser通过手动分析确定代表错误模式属性的数据对象(称为子句相关数据,Step ❷),然后利用自动静态分析工具,跟踪子句相关数据,从完整调用链中提取出部分调用链(Step ❸)。这些修剪后的调用链将作为目标调用链被插入到二进制代码中,用于后续模糊测试。
- 子句引导模糊测试(Clause-guided Fuzzing):
- 在这一阶段,SQLaser通过计算种子调用链与目标调用链之间的距离(Step ❹)来确定种子的“能量值”(energy),根据该距离优先选择需要变异的种子(Step ❺)。
- 变异种子后,SQLaser执行这些种子并通过测试Oracle分析结果,以确定是否触发了任何逻辑错误(Step ❻)。最终,触发错误的变异种子会被保留并加入到种子队列中,供后续执行。
整个过程包括:
- 步骤 1-3:通过动态和静态分析获取并修剪调用链,将其插入到二进制代码中。
- 步骤 4-6:计算种子和目标调用链之间的距离,基于距离优先选择种子进行变异,并利用测试Oracle分析结果。
该过程中的各个步骤将在后续章节中详细说明,包括4.1节中关于调用链距离计算,4.2节中关于种子能量的计算和基于测试Oracle的分析
在设计SQLaser时,主要面临两个技术挑战:
- 逻辑错误模式建模阶段的挑战:
- 在逻辑错误模式建模阶段,主要的挑战是如何识别执行SQL子句组合(即SQL级别错误模式)的调用链,并将其作为模糊测试的目标站点。由于SQL子句组合的复杂性和调用链的多样性,如何从庞大的调用链中提取出与错误模式直接相关的部分,并准确地标注为目标站点,是一个复杂且关键的问题。
- 子句引导模糊测试阶段的挑战:
- 在子句引导模糊测试阶段,由于目标站点是函数调用链,因此路径到路径的距离计算与传统的单点距离计算不同。需要设计一种新的距离计算机制,以便根据该机制来确定变异和测试Oracle所需的调整。该机制的设计需要能够准确地反映种子调用链与目标调用链之间的距离,从而指导模糊测试过程中种子的优先级分配和变异策略的选择。
这两个挑战分别涉及如何有效地建模逻辑错误模式,以及如何在模糊测试过程中准确地计算和应用调用链之间的距离,以提高错误检测的效率和精确性。
4.1. Logic-Bug Pattern Modeling
完整调用链分析:
- 在这一阶段,SQLaser通过动态分析来获取执行错误时的完整调用链。具体来说,使用LLVM Pass在函数入口处设置钩子,记录函数调用信息,从而获取包含所有相关函数的完整调用链(Step ❶)。然而,完整的调用链中包含了许多与逻辑错误无关的函数,这可能会限制模糊测试的探索能力,因此需要对调用链进行“修剪”。
手动识别子句相关的数据对象:
- 为了修剪调用链,研究人员手动分析错误模式中各子句的属性(如表元素、数据处理函数、条件表达式、特殊关键字等),并将其与程序中的变量进行关联(Step ❷)。例如,对于 NOCASE 和 INDEX i0 的组合错误,可以确定与其相关的变量为 TK_COLLATE 和 pWhere 。通过分析这些数据对象,可以定位处理这些对象的特定函数。
自动提取部分调用链:
- 使用静态分析工具(LLVM Pass),跟踪这些子句相关的数据对象在代码中的数据流动,提取与这些对象处理相关的部分调用链。这样做可以过滤掉不相关的函数,只保留那些直接操作子句相关数据对象的函数,形成“修剪”后的调用链(Step ❸)。这些精简后的调用链将作为模糊测试的目标调用链。
子句相关数据对象的识别规则:
识别子句相关的数据对象时,依据以下规则:
表元素/模式(Table Element/Schema):识别引用这些元素或模式的变量,如
pWhere表示索引,pPk表示主键。数据处理函数(Data Processing Functions):识别函数的参数或返回值,如
CAST函数中的TK_CAST、ppVal等。条件表达式(Conditional Expressions):识别表示条件检查的标志或变量,如
EXISTS表达式中的pExpr->op变量。特殊关键字(Special Keywords):识别用于实现某些功能的标志,如
TK_COLLATE、TF_WithoutRowid等。查询优化函数(Query Optimization Functions) :识别与优化功能相关的标志或变量,如 LIKELY 函数中的
EP_Unlikely标志。
实例说明:
通过示例展示了如何应用这些规则。例如,在 NOCASE 和 INDEX i0 的错误模式中,定位子句相关的数据对象 TK_COLLATE
和 pWhere 后,提取相关的函数 whereUsablePartialIndex 和 sqlite3ExprCompare ,最终形成修剪后的调用链。
总结:在4.1节中,SQLaser通过动态分析获取完整调用链,并通过手动分析和静态分析相结合的方法提取与子句相关的数据对象,修剪出与错误模式密切相关的部分调用链。这些调用链将在模糊测试阶段用于优先探索可能存在逻辑错误的代码路径。

该例子描述了如何从一个具体的逻辑错误出发,提取与错误相关的目标调用链。
- 确定错误子句组合:
- 首先,分析示例中的逻辑错误,确定该错误与“NOCASE”和“INDEX i0”这两个SQL子句组合有关。
- 获取完整调用链:
- 然后,使用动态分析方法获取执行
SELECT语句时的完整调用链。通过使用LLVM Pass在函数入口处设置钩子,记录程序执行期间的函数调用信息,从而获得了一个完整的调用链,包括诸如sqlite3Select、sqlite3WhereBegin、whereLoopAddAll等函数。- 分析调用链:
- 完整调用链展示了SQL子句组合的内部工作原理,例如
whereUsablePartialIndex处理部分索引的操作,而sqlite3ExprImpliesExpr则定义了在“NOCASE”场景下如何比较两个值。- 精简调用链:
- 由于完整的调用链中包含了许多与逻辑错误无关的函数,会限制模糊测试的探索能力,因此仅使用完整调用链作为模糊测试目标是不合适的。
- 为了解决这个问题,作者确定了与“NOCASE”和“INDEX i0”相关的数据对象变量,即
TK_COLLATE和pWhere。- 如何确定相关的数据变量对象?手动识别?
- 跟踪相关变量:
- 通过在IR级别跟踪这些变量,发现只有
whereUsablePartialIndex、sqlite3ExprImpliesExpr和sqlite3ExprCompare这三个函数直接操作这些变量,而其他函数则没有。- 生成精简后的调用链:
- 因此,最终精简后的目标调用链仅包括:
whereUsablePartialIndex → sqlite3ExprImpliesExpr → sqlite3ExprCompare。总结:该例子通过动态分析获取完整调用链,手动识别与错误子句组合相关的数据对象,并通过静态分析精简调用链,提取出最相关的目标调用链,用于后续模糊测试。
4.2. Call Chain Distance Calculation
目标调用链表示:
SQLaser的目标是到达目标站点,即函数调用链。与传统的单点距离计算不同,这里需要定义一种支持路径到路径距离计算的新机制。精简后的目标调用链用一个m元组模型表示,形式为 targetCallChain = trimCallChain = (f1, f2, …, fm) ,其中每个
fi 代表调用链中的一个函数。
控制关系模型:
- 调用链中的每个函数调用关系用 ctl_{fi→fj} 表示,包含两部分信息: fi 和 BB_{fi→fj}。BB_{fi→fj} 是函数 fi 在LLVM IR代码中调用 fj 的基本块。
计算种子调用链与目标调用链的距离:
- SQLaser首先自动获取种子调用链的控制关系
seedCtl,并将种子调用链和目标调用链分别表示为基本块集合SBB和TBB。 - 然后,计算 SBB 中每个基本块与 TBB 中基本块之间的距离 d_{BB},作为种子调用链与目标调用链之间的距离 d_{CallChain}。
- SQLaser首先自动获取种子调用链的控制关系
基本块间距离计算:
- 基本块 b 和 tb 之间的距离 d(b, tb) 的计算使用调和平均值。如果两个基本块在同一个函数内,则距离定义为 undefined;否则,距离等于两个基本块所在函数之间的距离 df(d, tb)。
- df(d, tb) 表示基本块 b 和 tb 所在函数间的最短路径距离,等于两函数间最短路径上的边数。
多目标调用链选择:
- SQLaser为不同逻辑错误引入了多个目标调用链。在选择与当前种子调用链最匹配的目标调用链时,先计算文本相似度,再用最短距离作为选择标准。当多个目标调用链的文本相似度相同时,选择距离最短的目标调用链。
应用场景:
- 以上距离计算方法用于确定种子与目标调用链之间的距离。根据该距离计算出的种子“能量”值用于指导种子的变异策略,更接近目标调用链的种子将获得更多的变异机会。
总结:4.2节提出了一种路径到路径的距离计算方法,用于量化种子调用链与目标调用链之间的距离,从而优化模糊测试中的种子选择和变异策略。
4.3. Mutation based on Seed Energy and Testing Oracles
4.3.1 基于种子能量的变异(Mutation based on Seed Energy)
- SQLaser使用SQLRight提出的有效性导向的查询生成方法,避免生成语法或语义错误的查询。生成的查询作为模糊测试的种子,SQLaser为每个种子分配“能量值”。能量值越高,意味着种子有更大的机会经历较多的变异操作。
- SQLaser根据种子调用链与目标调用链之间的距离(公式8),分配种子的能量值。距离越短,能量值越高,从而种子被赋予更多的变异机会。能量计算公式为:energy=dCallChain−1energy = d_{CallChain}^{-1}energy=dCallChain−1 这里, d_{CallChain} 表示种子调用链与目标调用链之间的距离。
4.3.2 测试Oracle(Testing Oracles)
- SQLaser利用五种测试Oracle来分析种子执行的结果,通过差分测试方法将原始查询转换为具有不同语法结构但功能等价的变体,比较原始查询和变体的执行结果,以检测潜在的逻辑错误。这五种Oracle包括:
- NoREC Oracle:将包含
WHERE子句的优化查询重写为不包含WHERE优化的查询。 - TLP Oracle:将原始查询分割成多个等价子查询,子查询的结果可以组合成与原始查询相同的结果。
- INDEX Oracle:向查询集中插入不同的
CREATE INDEX子句,测试索引使用对查询执行的影响。 - ROWID Oracle:检查原始查询中是否包含
WITHOUT ROWID子句,如果没有,则插入该子句,观察其对查询执行的影响。 - LIKELY Oracle:检查原始查询中是否包含 LIKELY 子句,如果没有,则添加 LIKELY 子句,查看其对查询执行的影响。
- NoREC Oracle:将包含
Implementation
- 插桩阶段(Instrumentation Phase):
- 在编译时,SQLaser插入四种类型的代码片段:
- 边覆盖信息:收集模糊测试器执行过程中代码覆盖率的信息。
- 基本块距离信息:用于计算种子调用链与目标调用链之间的距离。
- 函数入口钩子:在每个函数入口处设置钩子,以在执行期间获取种子调用链。
- 逻辑错误模式信息:在相关函数入口处插入唯一标识符,以区分不同的调用链,并在运行时收集这些标识符,以确定执行的调用链是否构建了目标调用链。
- 这些插桩方法类似于WindRanger的方法,通过收集覆盖率信息、基本块距离信息及逻辑错误模式信息来进行模糊测试和距离计算。
- 模糊测试阶段(Fuzzing Phase):
- 在模糊测试阶段,SQLaser修改了WindRanger的代码,以适应其设计,包括距离计算和变异方法。
- 总共修改了约10,000行代码,并通过更改WindRanger的执行分析部分实现了测试Oracle。
- 这部分修改的代码大约有3,000行,用于实现与SQLaser模糊测试目标相符的逻辑错误检测策略。
Evaluation
以下是这三个研究问题的翻译:
- SQLaser在实际程序中发现错误的效果如何?它是否能发现新的独特错误?(对应第6.1节)
- 这一问题旨在评估SQLaser在真实环境中检测逻辑错误的有效性,特别是是否能够识别出以往未被发现的新的逻辑错误。
- 在相关指标(如性能、代码覆盖率和种子距离分布)方面,SQLaser与现有最先进的模糊测试方法相比如何?(对应第6.2节)
- 该问题探讨SQLaser在各种性能指标上的表现,包括与其他顶尖模糊测试方法相比时的效率、代码覆盖范围以及种子与目标调用链之间的距离分布情况。
- 修剪的效果如何?当目标设定为完整调用链或修剪后的调用链时,SQLaser生成的误报和漏报数量分别是多少?(对应第6.3节)
- 这个问题关注调用链修剪策略的影响,通过比较目标为完整调用链和修剪后的调用链时的误报(false positives)和漏报(false negatives)数量来评估修剪策略的有效性。
Test DBMS : 为了与SQLRight进行对比,SQLaser选择测试了与SQLRight相同版本和类型的数据库管理系统(DBMS)。具体测试如下:
- 相同版本的DBMS:
- SQLite:版本3.28
- MySQL:版本8.0.27
- PostgreSQL:版本13.0
- 额外测试的DBMS:
- TiDB:版本3.0.12
- SQLite:版本3.41
测试的不是最新版本,说明很多bug SQLRight已经发现了被修复了,只是重复发现而已
6.1. Finding Bugs in DBMSs
SQLaser在四个测试的DBMS(SQLite、MySQL、PostgreSQL和TiDB)中,共总结了35种错误模式,其中包括SQLite的17种、MySQL的10种、PostgreSQL的1种和TiDB的7种。SQLaser作为一个独立的模糊测试工具,成功复现了所有35种错误模式,并在其中18种模式中发现了22个错误。具体来说,SQLite检测到10种错误模式,MySQL和TiDB各检测到4种。在22个发现的错误中,18个是已知错误,4个是新的零日漏洞(Zero-day bugs),其中包括SQLite的2个新错误和MySQL的2个新错误。
仅仅提交了4个bug report.
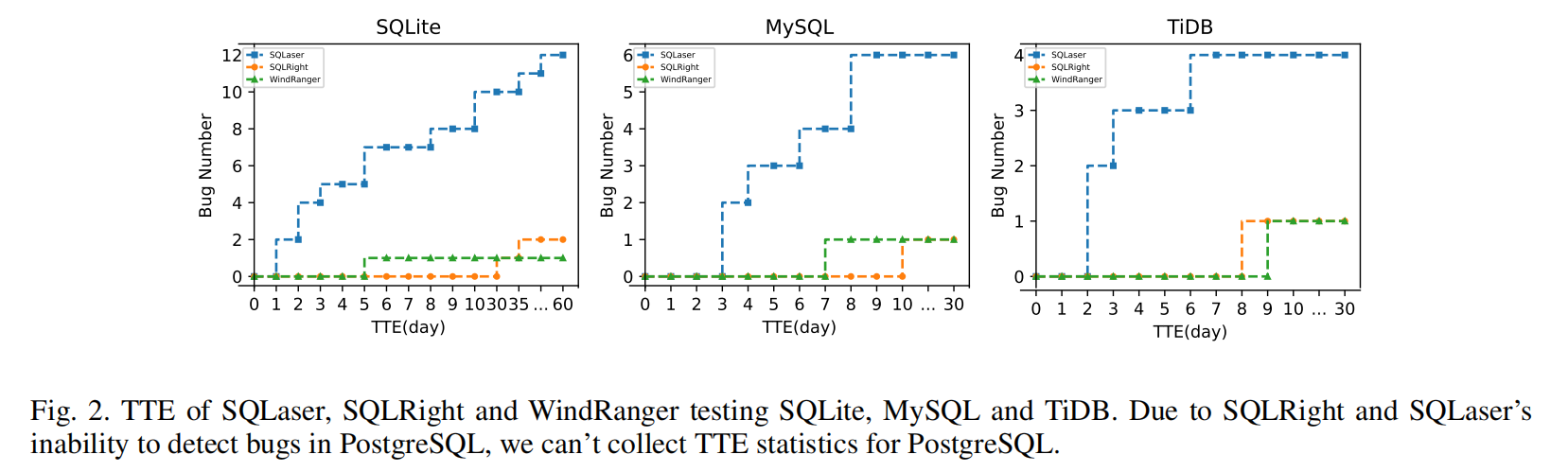
6.2. Comparison with Existing Tools
在评估SQLaser时,研究人员还运行了SQLRight和WindRanger进行对比。SQLRight是基于覆盖率引导的模糊测试工具,WindRanger则是单函数目标的定向模糊测试工具。在本部分中,研究者深入比较了这三个模糊测试工具在以下几个方面的表现:
- 性能:比较三个工具在逻辑错误检测过程中的效率,包括发现错误的速度和数量。 (更快)
- 代码覆盖率:评估每个工具在测试过程中覆盖的代码路径,分析它们在探索代码上的能力。 (更低) 在低覆盖率的情况下找到同样的bug?
- 种子距离分布:分析种子与目标调用链之间的距离分布情况,以评估种子选择和优先级策略的有效性。
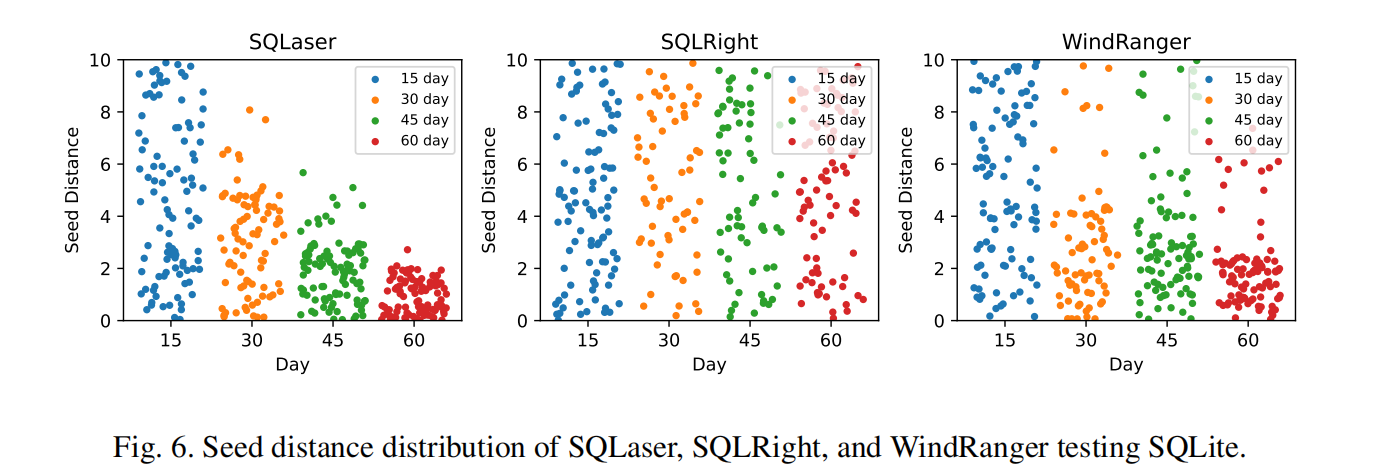
实验设置:
- 研究者对SQLite进行了测试,每隔15天(15天、30天、45天、60天)随机选择100个种子,评估这些种子与目标调用链的距离分布情况。
SQLaser的表现:
- 在第15天时,SQLaser的一些种子距离目标调用链仍然较远,分布较为分散。
- 随着测试时间的增加,种子距离逐渐减少,大多数种子在第60天时集中到0到2的距离范围内。这表明SQLaser的种子生成策略随着时间推移,种子变得越来越接近目标调用链,验证了其距离计算算法的有效性。
SQLRight的表现:
- SQLRight由于缺乏基于种子与目标调用链距离的反馈策略,在60天的测试期间,种子的距离分布始终较为分散。
- 尽管SQLRight专注于单一函数的测试,但依旧有部分种子距离目标调用链较远,无法有效覆盖目标调用链。
WindRanger的表现:
- WindRanger也专注于单一函数的测试,虽然部分种子距离有所收敛,但依旧存在较大距离的种子。
- 这表明WindRanger的种子策略在覆盖目标调用链方面表现不足
6.3. Trimmed Call Chains vs. Complete Call Chains
研究目标:
- 本文将SQLaser的目标设置为修剪后的调用链(Trimmed Call Chain),而非完整的调用链(Complete Call Chain),以增强模糊测试工具发现新错误的能力。研究比较了这两种方法的结果,包括它们分别引入的误报(False Positives)和漏报(False Negatives)。
SQLite上的测试结果:
- 当目标是修剪后的调用链时,SQLaser在SQLite上产生了25个误报。手动验证这些误报并不耗时,研究者用半小时验证了这25个误报。
- 当目标是完整的调用链时,SQLaser报告了18个误报,并发现了8个错误,而修剪后的调用链发现了3个错误。这表明完整调用链可能更容易遗漏(漏报)某些潜在的错误。
结果分析:
- 修剪后的调用链由于覆盖了更广泛的代码路径,可能会在不是实际错误的情况下报告更多的误报。但相对来说,由于覆盖了更广泛的可能性,它也会导致更多错误的发现,即使其中有些是误报。
- 而完整的调用链则减少了误报,因为模糊测试工具对目标的上下文有更好的理解,但也可能因为避免某些路径而导致更多漏报。这是因为完整调用链的目标更具体,可能会限制模糊测试的探索能力。