
LPR: Large Language Models-Aided Program Reduction
LPR: Large Language Models-Aided Program Reduction
程序简化是一种广泛使用的技术,用于通过自动最小化触发编译器错误的程序来促进调试编译器。现有的程序简化技术要么是通用的,可以适用于多种编程语言(如Perses和Vulcan),要么是专门为某一特定语言优化的,通过利用特定语言的知识(例如,C-Reduce)。然而,如何在程序简化中将跨语言的通用性与针对特定语言的最佳性有机结合,仍然是未被探索的领域。
本文提出了LPR,这是一种首次利用大语言模型(LLMs)进行多语言特定程序简化的技术。关键思想在于利用像Perses这样的通用程序简化器的语言通用性,以及LLMs所学到的特定语言语义。具体而言,通用程序简化器可以将程序有效地简化为LLMs能够处理的小尺寸程序;LLMs可以通过学到的语义有效地转换程序,创建新的简化机会,以便通用程序简化器进一步简化程序。
我们在三种编程语言(即C、Rust和JavaScript)上的50个基准测试的详细评估表明,LPR在实用性和优越性上超过了Vulcan,这是当前最先进的通用程序简化工具。在有效性方面,LPR在C、Rust和JavaScript基准上分别比Vulcan生成了24.93%、4.47%和11.71%更小的程序。此外,LPR和Vulcan有潜力互为补充。对于C-Reduce所优化的C语言,通过结合Vulcan和LPR的输出,我们可以达到与C-Reduce相当的程序尺寸。在处理大型复杂程序时,LPR比Vulcan更加高效,在C、Rust和JavaScript基准测试中分别节省了10.77%、34.88%和36.96%的时间。
INTRODUCTION
Background
程序简化技术的目的:
- 程序简化旨在通过最小化触发错误的程序来促进编译器调试,强调效果和效率。
- 给定一个程序 P 和其保持的属性 ψ,程序简化器会生成一个仍能保持 ψ 的最小化程序 Pmin。
程序简化的应用:
- 广泛应用于软件工程任务中,尤其在编译器测试和调试中。
Related work
程序简化中的挑战:
- 核心挑战在于通用性与特定语言的平衡:如何在跨语言的通用性和针对某种语言的最佳性之间做出取舍。
现有程序简化技术的分类:
- 语言特定简化:利用特定语言的语义对程序进行简化,通常效果更好,但需要对语言特性有深刻理解,耗时费力。适用于少数语言(如C、Java、SMT-LIBv2)。
- 语言通用简化:适用于多种语言,但缺乏对语言特性和语义的深刻理解,因此无法执行语言特定的转换(如函数内联),也无法利用语言的特殊特性生成最优简化程序。
当前的问题:
- 语言通用简化器虽然适用范围广,但由于缺乏特定语言的语义知识,无法完成特定的简化任务,从而无法生成最优的简化程序。
Motivation
研究目标:
- 研究旨在找到一种平衡点,结合通用性与针对特定语言的最佳性,通过融合两类程序简化技术的优势,提升程序简化的效果。
通用简化器的局限:
- 通用简化器(如Perses)的主要局限在于无法执行语言特定的转换,缺乏对特定语义信息的理解,限制了进一步的简化效果。
Potential solution
大语言模型(LLMs)的潜力:
- 研究指出,LLMs能够作为强大的助手,帮助执行语言特定的转换。LLMs已经展示出分析和转换主流语言程序的能力,这为程序简化提供了新的可能性。
LLMs的应用前景:
- 通过利用LLMs的能力,可以使通用简化器更好地理解不同语言的语义,简化器的定制和扩展也会变得更加高效,减少手动实现语言特定简化器或添加额外功能的时间和成本。
Challenges of Using LLM
LLMs的局限性:
- LLMs 并不是解决程序简化的万能工具。
- 由于LLMs的固有限制,LLMs可能无法理解代码中的细微差异,并且容易被不相关的上下文干扰。
- 程序简化任务中的输入代码通常包含数万行,这超出了LLMs的输入限制。
缺乏明确指导:
- 在没有有效指导的情况下,LLMs不清楚需要执行哪些转换操作。
Approach
**LLMs辅助的程序简化 (LPR)**:
- LPR 是首个将大语言模型(LLMs)引入程序简化任务的方法。该方法结合了语言通用简化器和LLMs的优势。
- 不是为了用LLM而用LLM,overclaim
- LPR通过交替调用通用简化器(实验中使用了Perses)和LLM来简化程序。
- 首先,Perses将大型程序简化到适合LLM处理的大小,随后LLM根据用户定义的提示进一步转换程序。
- 之后,Perses再次被调用,因为LLM的转换通常会带来新的简化机会,直到程序无法再被最小化。
五种简化转换技术:
- LPR使用了五种通用转换技术来进一步减少程序:函数内联、循环展开、数据类型消除、数据类型简化、变量消除。
多层次提示方法:
- 为了应对LLMs的挑战,LPR设计了多层次提示的方法,首先让LLM确定可转换的目标,之后逐步应用转换。
- 这种方法有助于集中指导LLM,排除不相关的上下文和可能分散LLM注意力的其他目标。
- Prompt engineering, 上下文干扰
Evaluation
LPR的评估结果:
- 进行了广泛的评估,显示LPR优于当前最先进的通用算法Vulcan。
- 在三个基准测试集(C、Rust、JavaScript)上,LPR生成的程序比Vulcan小得多,分别减少了24.93%、4.47%和11.71%。
LPR与Vulcan的互补性:
- LPR和Vulcan可以互相补充,特别是在针对C-Reduce优化的C语言上,通过结合Vulcan和LPR的输出,达到与C-Reduce相同的程序尺寸。
效率与性能:
- 在程序简化效率上,LPR与Vulcan相当;在用户感知的执行时间上,LPR在简化复杂程序时比Vulcan更高效。
- 每种简化转换在程序简化过程中都起着至关重要的作用。
多层次提示方法的效果:
- 评估还表明,LPR的多层次提示方法比不使用提示时表现更优,展示了该方法的有效性。
Contributions
引入LPR:
- 首次尝试使用大语言模型(LLMs)进行程序简化,通过结合语言通用简化器和LLMs的能力,LPR展示了跨语言的通用性和对特定语言语义的理解。LPR还具有通过设计新提示轻松扩展新转换的灵活性。
提出多层次提示方法:
- 提出了一种多层次提示方法来引导LLMs执行程序转换,展示了其实践中的有效性。我们提出了五种通用转换,为LLMs简化程序或创造更多简化机会提供了支持。
全面评估LPR:
- 在C、Rust和JavaScript三种常用语言的50个基准上对LPR进行了全面评估,结果展示了LPR的高效性和通用性。
BACKGROUND
2.1 Program Reduction
程序简化的目标:
- 给定一个程序 P 和某种属性(如触发编译器错误),程序简化的目标是找到一个最小化的程序 Pmin ,它仍然保留该属性。
- 程序简化通过去除与错误无关的代码,极大地提高了调试的效率。
语言通用简化器:
一些简化器可以适用于多种语言,如HDD和Perses。这些算法通过解析语法树来删除不必要的节点,生成更小的程序变体。
Vulcan进一步扩展了Perses,引入新的方法来寻找更小的变体,例如替换标识符或子树,删除局部组合。
通用简化器虽然有效,但不能利用特定语言的语义来进一步简化程序,缺乏进行函数内联等转换的能力,无法利用特定程序的特征来进行更深层次的优化。
语言特定简化器:
- 语言特定简化器针对某些特定语言进行定制,如C-Reduce是C语言最有效的简化工具。它通过多次转换,根据语言特性进行简化。
- 开发语言特定简化器是复杂的过程,涉及大量的时间和人力成本。设计新的简化器或对现有简化器添加新功能,通常都很耗时耗力。
2.2 Large Language Models
大语言模型的定义与能力:
- 大语言模型(LLMs)是基于大规模数据集进行训练的深度学习模型,适用于多种任务。
- LLMs不仅擅长处理自然语言,还在理解和处理编程语言方面展现出显著的能力,预示了其在软件工程领域中的广阔前景。
LLMs的应用:
- LLMs最近被应用于多项软件工程任务,如自动程序修复和程序生成,展示了其在这些领域中的潜力。
LLMs的局限性:
- 尽管LLMs用途广泛,但一些研究表明,当前的LLMs在区分程序中的细微差异上存在不足。
- 随着输入规模的增加,LLMs的记忆和处理能力会下降,因此无法期望LLMs自动完成复杂任务,必须有针对性地进行引导。
- 在程序简化过程中,直接让LLMs处理成千上万行代码是不切实际的。
APPROACH
3.1 Motivation
这个例子展示了LPR(利用大语言模型的程序简化)的优势。具体步骤如下:
- 原始代码的复杂性:
- 原始代码包含高度嵌套的循环结构,如图1a所示。嵌套循环通常难以进行有效的简化。
- 循环展开:
- 通过LLM的语义转换,嵌套的循环在图1b至1c中被完全展开,形成了数百行代码。这一过程称为循环展开(Loop Unrolling)。
- 进一步简化:
- 尽管在展开循环时代码暂时变得更长,但Perses接下来有效地消除了除了与错误相关的行之外的所有其他行。最终结果就是图1d所示的LPR简化后的代码。
- 对比其他简化器:
- Vulcan:图1e显示,Vulcan通过替换标识符和树节点来尝试简化,但无法避免陷入局部最小值,效果不如LPR。
- C-Reduce:虽然C-Reduce也能简化代码,但它无法完全展开循环结构,因为它没有与循环展开技术集成。
- 对比手动实现:
- 尽管可以在未来版本的C-Reduce中加入循环展开技术,但实现这种特定转换的代价非常高,相比之下,通过自然语言提示定义转换的方式更加省时省力。

3.2 Workflow
工作流程概述:
- LPR接收一个触发错误的程序作为输入,通过交替调用语言通用简化器和LLM,直到程序无法进一步简化为止。
- 每次迭代中,语言通用简化器首先将程序简化到最小,而LLM基于语言的语义知识,进一步对简化后的程序进行转换。这个过程由用户定义的提示引导,以暴露更多简化的机会。
预定义提示的组成:
- 预定义的提示包括 primaryQuestion 和 followupQuestion :
primaryQuestion让LLM确定要转换的目标。followupQuestion引导LLM对每个目标逐一进行转换。
示例:
- 比如在循环展开的例子中,LLM被要求识别要展开的循环,并生成目标列表,随后进行展开并简化代码。
过程细节:
- 在每个转换过程中,LLM可以生成多个经过转换的程序,LPR会保留最小的那个,同时仍然通过了属性测试的程序,其他则被丢弃。
- 如果没有合适的转换程序,LPR会保留之前的版本。
- 最后,LPR通过语言通用简化器(如Perses)进一步简化,直到程序无法再简化。
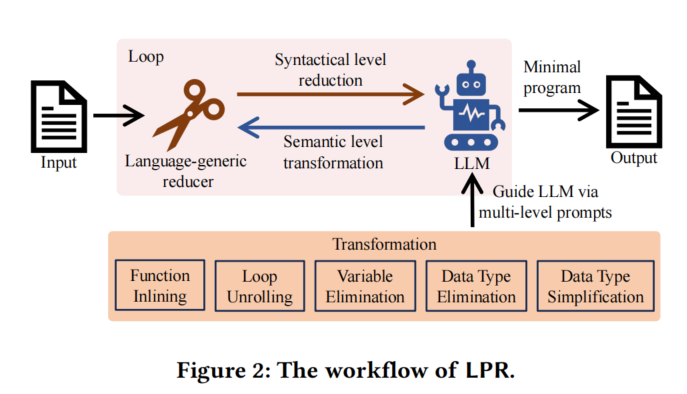
3.3 Transformations
提出的五种通用转换:
- 为了通过LLM进一步简化程序,本文提出了五种通用转换方法:
- 函数内联(Function Inlining):将函数的所有调用点替换为相应的函数体,消除多余的函数调用。
- 循环展开(Loop Unrolling):识别并展开循环,将循环变成重复的代码片段,减少复杂性。
- 数据类型消除(Data Type Elimination):消除与错误无关的数据类型,如C中的
typedef或Rust中的type别名。 - 数据类型简化(Data Type Simplification):将复杂的数据类型转换为更简单的原始数据类型。
- 变量消除(Variable Elimination):优化程序中的中间变量和未使用的变量,简化代码。
- 类似于SQLess中的精简策略
转换应用范围广泛:
- 这些转换可以广泛应用于多种编程语言,减少了设计和实现针对特定语言简化器的工作量。
- 通过LLM进行这些转换,简化了过程,同时扩展了这些方法在不同编程语言中的应用。
对比现有简化器:
- 某些语言特定简化器(如C-Reduce)已经包含了一些转换技术(如函数内联和变量消除),但创建新的转换仍然是一项复杂的任务。本文的方法简化了这个过程,并扩展了其跨多种编程语言的适用性。
3.4 Multi-level Prompts
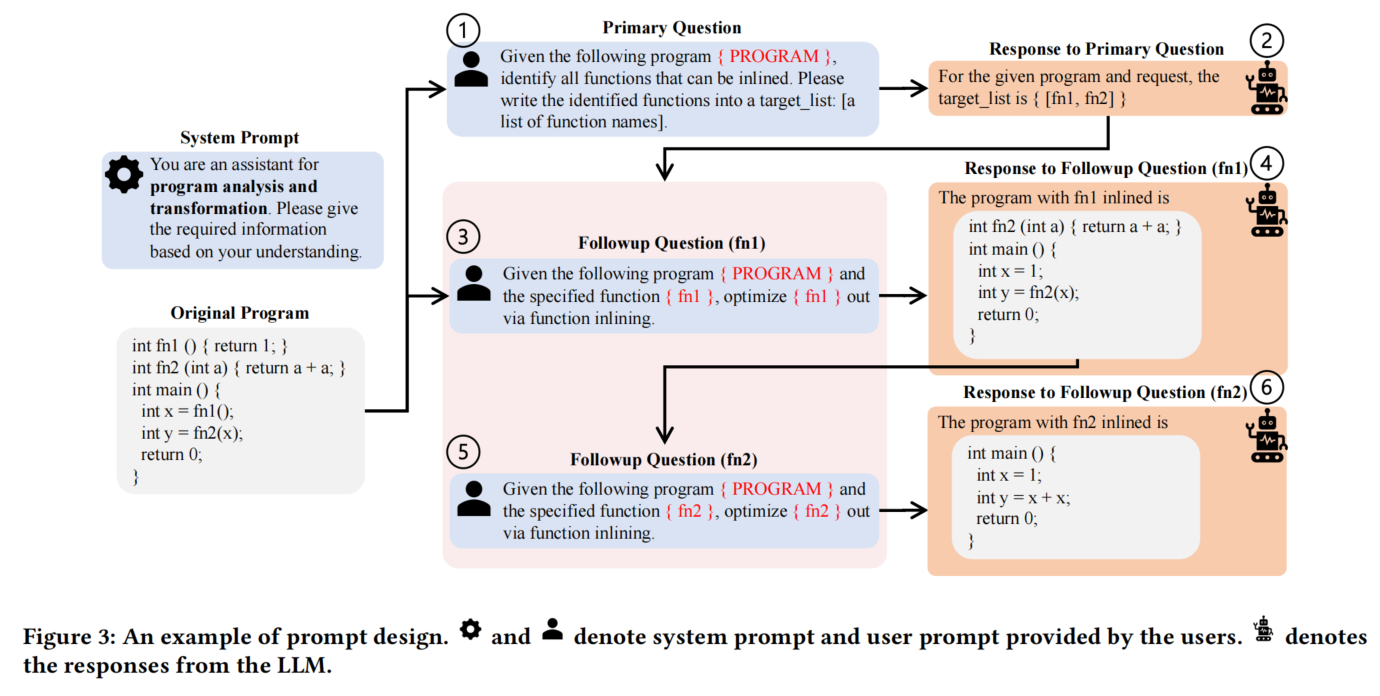
多层次提示的作用:
- 多层次提示使LLMs能够逐步应用前述的转换方法,如函数内联,而不是让LLMs一次性执行所有的转换,这样可以避免过载处理能力。
函数内联示例:
- 以函数内联为例,首先提出一个初步问题:给定程序,识别所有可以内联的函数(第1步)。
- 基于LLM返回的函数列表,接着提出后续问题,如“给定指定函数,进行内联优化”(第3步和第5步)。
- LLM根据提示执行相应的转换(第4步和第6步)。
提示的效果:
- 这种策略能够排除无关上下文,使查询更加精准,从而提高LLM生成高质量结果的可能性。
- 其他转换也可以遵循类似的模板,先让LLM识别目标,再引导它优化每个目标。
EVALUATION
RQ1:LPR在程序简化中的有效性如何?
RQ2:LPR在程序简化中的效率在用户看来达到何种程度?
RQ3:LPR中每种转换的有效性如何?
4.1 Experimental Setup
实验工具和环境:
- 实验中使用了Perses作为语言无关的简化器,并与OpenAI的GPT-3.5-turbo结合。实验还设计了LPR+Vulcan的变体,进一步简化LPR的输出。
- 实验在Ubuntu 22服务器上运行,配置为Intel Xeon CPU(2.60GHz,512GB RAM),所有算法都在单线程、单进程的环境下执行。
基准测试:
- 使用了三个基准测试集:Benchmark-C、Benchmark-Rust和Benchmark-JS,分别测试C语言、Rust语言和JavaScript的程序。
- Benchmark-C包含20个复杂的真实世界错误,Benchmark-Rust包含20个Rust程序错误,Benchmark-JS通过FuzzJIT生成10个导致JIT编译器错误的JavaScript程序。
基线比较:
- 实验采用了Perses和Vulcan作为基线,Vulcan基于Perses,并进一步减少了程序的token数量,但运行时间有所增加。还包含C-Reduce(v2.9.0)作为对比,它在C语言中表现最优,也可应用于其他语言。
配置和设置:
- 默认使用OpenAI API进行实验,LLM的
temperature设置为1.0,以鼓励生成更多样的结果。每个查询生成5个结果,选择符合条件的最小程序。
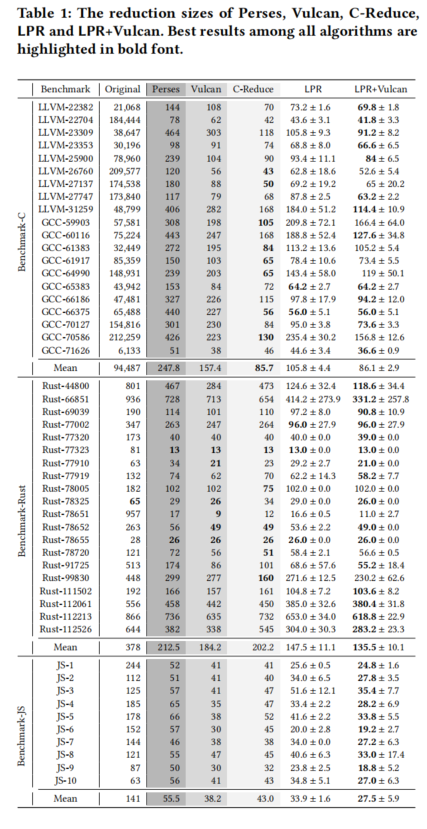
4.2 RQ1: Reduction Effectiveness
- 评估方法:
- 通过最终程序的token数量来衡量LPR、LPR+Vulcan以及基线算法的简化效果。程序越小,表示移除了更多无关的错误代码,从而减少开发人员的手动工作。
- Benchmark-C:
- Perses将程序简化到平均247.8个token,Vulcan进一步压缩到157.4个token,LPR将程序缩小到105.8个token,减少了24.93%。
- C-Reduce表现最优,生成了85.7个token的最小程序。然而,LPR+Vulcan的表现仍然出色,在20个基准测试中,LPR+Vulcan在13个中超过了C-Reduce。
- Benchmark-Rust:
- Perses和Vulcan分别将程序简化到212.5和184.2个token,LPR和LPR+Vulcan进一步缩小到147.5和135.5个token。
- C-Reduce再次表现最优,但LPR和Vulcan在对较大的程序执行语义转换和局部穷举搜索时表现突出。
- Benchmark-JS:
- JavaScript程序相对较小,Perses将程序简化到55.5个token,LPR和LPR+Vulcan分别缩小到38.2和27.5个token。
- C-Reduce在JavaScript中的表现不如其他算法,因为它没有使用JavaScript的特定优化。
总结:LPR在不同基准测试中的表现证明了其在程序简化中的有效性,尤其是在与Vulcan配合使用时,能够在多个基准上产生最佳结果。
4.3 RQ2: Reduction Efficiency
- 评估方法:
- 通过程序简化所需的时间来衡量LPR、Vulcan和C-Reduce的效率。较短的时间表示更高的效率。
- Benchmark-C:
- LPR的平均运行时间为1小时54分钟54秒,比Vulcan的2小时8分钟46秒短10.77%。但是,与Vulcan相比,LPR在Benchmark-C中总共需要多出45.83%的时间。LPR在处理大且复杂的程序时效率更高,而Vulcan在简化较小且简单的程序时更快。
- Benchmark-Rust:
- 类似的趋势表明,LPR在处理复杂程序时更有效率,而Vulcan在处理较小且简单的程序时表现更好。对于超过一小时的基准,LPR比Vulcan节省了4.15%和21.69%的时间。
- Benchmark-JS:
- 在Benchmark-JS中,LPR的平均执行时间为1.915小时、1.839小时和0.174小时。LPR消耗的时间大部分用于等待LLM响应,分别占32.26%、28.11%和72.99%。
- 效率成本:
- 以Benchmark-C为例,每个基准的平均成本为0.42美元,每个基准测试平均需要41次查询,每次查询大约耗时39秒。
结论:尽管LPR的效率较高,但受限于LLM的响应时间。然而,随着LLM技术的进步,未来LPR的效率有望显著提高。
4.4 RQ3: Effectiveness of Each Transformation
- 评估方法:
- 研究分析了每种转换对程序大小的影响,并探讨了它们逃避局部最小化并解锁新简化机会的潜力。主要通过Benchmark-C来进行评估。
- 转换的效果:
- 每次转换后,程序大小的变化通过箱线图和点图进行展示。
- 部分转换能够立即减少程序大小:
- 函数内联:平均减少132个token。
- 数据类型消除:减少4.7个token。
- 变量消除:减少4.3个token。
- 循环展开和数据类型简化在初次应用时通常会增加程序的大小,但随后通过Perses执行的后续简化步骤能够减少最终程序大小。
- 对整体影响的分析:
- 计算每个转换在所有基准测试中的平均贡献。函数内联是影响最大的转换,平均减少88.2个token,占总减少量的62.12%。循环展开的贡献较小,仅减少了4.8个token,占总减少量的3.35%。
- 不同转换的普及率:
- 数据类型消除影响了所有基准,原因是
typedef在所有基准中广泛存在。 - 循环展开是最少应用的转换,仅影响了20个基准中的6个。
- 数据类型消除影响了所有基准,原因是
总结:每种转换在程序简化中的贡献程度各不相同,函数内联和数据类型消除的影响最大,而循环展开的效果较小。部分转换在实际应用中遇到了挑战,尤其是复杂结构的转换。
DISCUSSION
5.1 The Effectiveness of Multi-level Prompt
- 目的:
- 为验证多层次提示的有效性,设计了单层次提示作为对比,并评估其与多层次提示的效果差异。
- 单层次提示将
primaryQuestion和followupQuestion合并为一个问题,例如“给定程序,识别并内联一个可以内联的函数”。
- 实验结果:
- 在Benchmark-C上进行的5次实验中,单层次提示的平均结果是155.0 ± 8.7个token,远高于多层次提示的105.8 ± 4.4个token,表明单层次提示效果较差。
- 原因可能是单层次提示虽然更简洁,但使得LLM在目标上的集中度下降,从而可能遗漏一些简化机会。
结论:多层次提示在引导LLMs进行转换时更加有效,因为它能够使LLM更加专注于特定目标。
5.2 The Impact of Temperature
- 实验设置:
- 实验中,LLM的温度参数通常设置为1.0。为了衡量该参数对性能的影响,进行了多次实验,测试了温度值为1.0、0.75、0.5、0.25和0的情况。
- 高温度会指示LLM生成更多创造性和多样化的结果。
- 实验结果:
- 表3展示了不同温度下的简化结果,温度为0的效果最差,生成的程序比其他温度更大。
- 其余温度下,性能相似,但较高的温度(如1.0和0.75)能生成更多样化的结果,帮助LPR更好地探索简化机会。
- 温度的影响分析:
- 较低的温度(如0)限制了输出的多样性,阻碍了LPR探索局部最小值,从而影响了程序简化的效果。
- 随机性有利于帮助LPR在一些基准测试中生成比C-Reduce更小的程序,但也会引入不确定性,使得结果可能有较大的波动,特别是在复杂的程序中。
总结:较高的温度参数能够更有效地帮助LPR探索不同的简化路径,提高简化效果,而较低的温度限制了输出的多样性,表现较差。
5.3 Failures in LPR
失败的常见性:
- 在LPR中,生成无法通过属性测试的变体是常见且可以接受的现象。主要有两种场景导致LPR未能生成通过测试的变体:
- 非确定性:LLM通常是非确定性的,可能无法在复杂程序中执行正确的转换。因此,为了减少潜在的失败,每次LLM查询都会请求多个响应。
- 属性测试失败:有时转换消除了触发错误的模式(例如,编译器在函数调用处崩溃,但内联了该函数),即使语义正确,属性测试仍然可能失败。
失败的处理:
- 当转换后的程序无法通过测试时,LPR会继续使用原始程序进行下一步尝试。失败虽然增加了测试次数,但这是程序简化中的一种不可避免的“试错”过程。
- 即使在没有LLM的情况下,像Perses和Vulcan这样的简化器也会有大约90%的失败率。
结论:
- LPR通过多个响应来减轻失败的影响,表现依然高效和有效,如表1和表2所示。
5.4 Threats to Validity
- 内部有效性威胁:
- 主要威胁来自数据泄露问题,即LLMs是否通过逐步分析提供了合理的转换,还是简单地记忆了公开可用的最小化程序。
- 该威胁通过多个角度进行缓解:
- 程序简化涉及触发编译器错误的随机生成程序,通常规模大且无特定用途,因此LLMs不太可能记住这些无序内容,降低了数据泄露的风险。
- Benchmark-JS基准测试集由作者通过JIT模糊测试工具创建,且不公开,这确保了LLMs无法通过记忆解决问题。
- 外部有效性威胁:
- 主要威胁在于LPR跨语言的泛化能力。虽然LPR方法是语言无关的,但LLMs可能对某些语言的知识有限,影响其表现。对此,研究通过在C、Rust和JavaScript上评估LPR,证明了其在多种流行编程语言上的泛化能力。
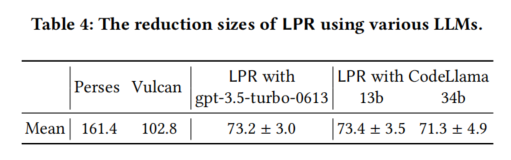
- 另一威胁是LPR在不同LLMs上的适用性。实验也在CodeLlama上进行了评估,结果与ChatGPT相似,表明了不同LLMs的适用性。
总结:通过多方面的缓解策略,数据泄露和泛化能力的威胁得以减少,确保了LPR的有效性。
RELATED WORK
6.1 Program Reduction
程序简化的历史背景:
- DDMIN引入了程序简化研究,通过递归分割输入列表,逐步减少其规模。随后,HDD(层次化的增量调试)通过将输入解析为语法树并在每一层执行DDMIN进一步提升了简化效果。
- Perses通过形式语法转换避免生成语法无效的程序变体,而Vulcan则进一步通过替换标识符/子树和局部穷举搜索来推动简化。
- RCC采用缓存刷新机制加快简化进程,但这些工具不针对特定语言进行优化,缺乏语言语义知识。
语言特定工具:
- C-Reduce是针对C语言的最有效简化工具,结合了多种转换方法。
- J-Reduce则是用于Java字节码的简化工具,ddSMT针对SMT-LIBv2格式的程序进行简化,这些工具都利用了语言特定特性来进行有效的简化。
LPR的独特性:
- LPR将LLMs与语言通用简化工具结合起来,充分利用了两者的优势。语言通用简化工具因其在多语言间的广泛适用性而突出,而LLMs利用了从大规模训练集学习的语言领域知识,进一步简化程序。
- 与需要大量手动设计和实现的语言特定工具相比,LPR通过自然语言提示大幅降低了简化过程中的人力成本。
6.2 LLMs for Software Engineering
- LLMs在软件工程中的应用:
- 大语言模型(LLMs)展示了在处理文本相关任务中的显著能力,包括源代码相关的任务。近期的研究着重于应用LLMs来支持软件工程任务,评估LLMs在软件开发和维护中的有效性、潜力和局限性。
- 自动程序修复(APR):
- 许多研究集中于通过实验证明LLMs在自动程序修复中的作用,这些研究展示了LLMs在软件开发任务中的广泛应用。
- LPR方法的独特性:
- 与传统研究不同,LPR方法利用LLMs对随机、无特定目标的程序进行简化,而其他研究通常关注逻辑明确、有特定目标的程序。因此,LPR提供了对LLMs处理无明显目标程序表现的新见解。
总结来说,LLMs在软件工程领域展现了广泛的应用潜力,尤其是在代码生成、修复和简化方面,相关研究也在持续拓展LLMs的使用场景。