
MR-Adopt: Automatic Deduction of Input Transformation Function for Metamorphic Testing
MR-Adopt: Automatic Deduction of Input Transformation Function for Metamorphic Testing
ABSTRACT
尽管最近的研究揭示,许多开发者编写的测试用例可以编码为可重用的变形关系(MR),但其中超过70%直接对源输入和后续输入进行了硬编码。这些编码的MR不包含将源输入转换为相应后续输入的显式输入转换,因此无法通过新的源输入重用来增强测试充分性。
在本文中,我们提出了MR-Adopt(自动推导输入转换),以自动从硬编码的源和后续输入中推导输入转换,旨在使编码的MR能够与新的源输入一起重用。以一个通常只包含一对源输入和后续输入的MR编码测试用例为例,我们利用LLM(大语言模型)理解测试用例的意图并生成额外的源-后续输入对。这有助于引导生成可推广至多个源输入的输入转换。此外,为了缓解LLM生成错误代码的问题,我们通过数据流分析移除与MR无关的代码元素,进一步优化LLM生成的转换。最后,我们基于编码的输出关系评估候选转换并选择最佳转换作为结果。
评估结果表明,MR-Adopt能够生成适用于72.00%编码MR的所有实验源输入的输入转换,这比使用普通GPT-3.5提高了33.33%。通过结合MR-Adopt生成的输入转换,基于MR编码的测试用例可以有效提升测试充分性,分别将代码覆盖率和变异得分提高10.62%和18.91%。
INTRODUCTION
Background
变形测试(MT):
- 用于解决测试用例生成和判定问题。
- 验证的是待测对象(SUT)与定义的变形关系(MRs)的行为,而非单个输入的输出。
- 每个MR定义:
- 一组相关输入之间的输入关系。
- 这些输入的预期输出之间的输出关系。
- 识别出MR后,MT可以通过自动生成的输入(源输入)测试多样的程序行为。
- 无需为每个输入单独准备判定标准。
- 已在编译器、数据库等软件的测试中表现出色。
识别合适的MRs的重要性:
- 识别适合SUT的MR是应用MT的关键。
- 早期方法存在问题:
- 劳动密集,特定于某些领域或预定义的MR模式。
- 产生过于通用且对测试无效的MR。
- 最近的研究进展:
- 开发者经常在测试用例中编码领域知识。
- 这些编码的MR可以通过自动输入生成技术应用于更多新输入。
- 提供了更全面的程序测试判定标准。
问题描述:
- 超过70%的MR编码测试用例没有明确的输入关系,而是直接硬编码了源输入和后续输入。
- 没有明确的输入转换程序,自动生成的源输入无法直接生成相应的后续输入,这限制了这些编码MR的重用,影响了自动化MT和测试充分性的提升。
解决方案:
- 该论文旨在通过从硬编码输入对中推导出明确的输入关系来克服这一障碍。
- 目标是构建一个输入转换函数,将源输入转换为相应的后续输入,从而使编码的MR能够应用于更多源输入,进行更全面的测试。
Challenges
技术挑战与方法:
- 该任务可以看作是一个通过示例编程(PBE)的问题,目标是合成一个转换函数,将给定的源输入转换为相应的后续输入。
- 挑战在于正确解读上下文信息,包括硬编码输入对之间的关系、输出关系以及SUT的属性。
- 只有一对源输入和后续输入作为示例时,存在程序过拟合于该示例的风险,而无法实现真正的意图。
- 有效利用上下文信息引导PBE,并生成符合MR语义的通用输入转换函数,以确保其适用于所有潜在的源输入。
Approach
提出MR-Adopt方法:
- MR-Adopt 利用大语言模型(LLMs)自动生成MR编码测试用例的输入转换函数。
- LLMs具备理解代码和生成代码的能力,能有效挖掘MR的意图和输入关系,生成高质量的输入转换代码。
三项设计:
- 设计1:通过两阶段实现:
- 阶段1:LLMs根据硬编码的源-后续输入对进行类比推理,推导出服从相同输入关系的新输入对。
- 阶段2:LLMs生成基于硬编码输入对和第一阶段生成的额外输入对的输入转换函数。
- 该设计不仅能减少LLMs过拟合问题,还能提高生成代码的通用性。
- 设计2:发现LLMs有时会生成与任务无关的代码片段。MR-Adopt通过数据流分析对LLMs生成的代码进行优化,移除无关片段,并生成正确的输入转换代码。
- 设计3:为减轻LLMs生成的相关代码中的错误,MR-Adopt使用开发者编写的输出关系(如断言)作为判定标准验证生成的测试对,并使用额外输入选择最通用的输入转换。
结果:
- 在100个MR编码的测试用例中,MR-Adopt生成了95个可编译的输入转换,其中72个可以推广到所有源输入。
- 与GPT-3.5相比,MR-Adopt生成了17.28%的更多编译成功的输入转换,并提升了输入对生成的准确性。
- 整体测试结果表明,MR-Adopt的输入转换大幅提升了测试充分性,提高了代码覆盖率和变异得分。
Evaluation
总体表现:
- 使用100个开发者编写的MR测试用例对MR-Adopt进行了评估,结果显示其能够为95个MR生成可编译的输入转换,其中72个可以推广到所有源输入。
相较于GPT-3.5的提升:
- MR-Adopt生成了17.28%更多的可编译转换,生成了33.33%更多的可推广转换。
- 生成的后续输入覆盖了91.21%的源输入,相较于GPT-3.5提高了122.10%。
设计贡献:
- 消融实验表明,所有三个设计(额外输入对、基于数据流分析的优化和基于输出关系的验证)均对MR-Adopt的整体表现有贡献,其中验证和额外输入对的影响最大。
测试充分性提升:
- 结合输入转换和新源输入,MR-Adopt使代码覆盖率提高了10.62%,变异得分提高了18.91%,验证了其在提高测试充分性方面的实际效果。
Contribution.
创新贡献:
- 首次为测试用例中的MR编码生成输入转换函数,使得更多编码的MR可以被重用,从而提高SUT的测试充分性。
提出MR-Adopt方法:
- 基于大语言模型(LLMs)的方法,通过生成多个示例输入对来减少过拟合并生成可推广的输入转换。
- 该方法结合了基于数据流分析的代码优化策略以及验证策略,能够减少LLMs生成的无关错误代码。
评估结果:
- 广泛评估了MR-Adopt在生成输入转换方面的有效性,结果显示72%的输入转换可以推广到所有准备的源输入。
- 结合这些转换,编码的MR提高了10.62%的代码覆盖率和18.91%的变异得分。
数据集构建:
- 构建了包含100个编码MR的数据集,并在2023年4月1日后发布,连同复制包一起在网站上公开。
PRELIMINARIES
2.1 Metamorphic Testing
定义:
- 变形测试(MT)通过验证程序是否满足特定的变形关系(MR)来验证程序。MR可以表示为从输入关系到输出关系的逻辑蕴涵。
输入和输出关系:
- 输入关系(Ri)定义了从源输入生成后续输入的规则。
- 输出关系(Ro)定义了源输入和后续输入对应的预期输出之间的关系。
示例:
- 对于实现正弦函数的程序,可以定义输入关系为后续输入等于负源输入,输出关系为后续输出等于负源输出,基于正弦函数的性质P(x)=−P(−x)。
变形测试的五个步骤:
- 构造源输入xs。
- 执行程序并获取源输出ys。
- 构造满足输入关系Ri的后续输入xf。
- 执行程序并获取后续输出yf。
- 验证两个输出ys和yf是否满足输出关系Ro。
输入转换:
- 输入转换是实现输入关系的函数,负责生成后续输入,可以由开发者编写或通过自动生成的方式(如随机测试)生成。
2.2 MR-Encoded Test Cases
MR编码测试用例(MTCs):
- MR编码测试用例(MTCs)由Xu等人提出,包含领域特定知识并建议了有用的变形关系(MRs)。
- MTCs数量庞大,研究中在701个开源项目中发现了超过11,000个MTCs。
MTC的特点:
- MTC可看作是已实现的MR实例,通常包含特定的源输入、后续输入、方法调用和断言。
- 这些MR被很好地编码,并作为判定标准,可应用于新测试输入。
例子:
- 例如,如果一个日期格式的输入应该在另一日期的基础上增加一天,那么编码的MR会验证日期转换函数是否正确处理这种输入关系。
问题:
- 尽管这些实现的MR可以重用并推广到更多新输入,但许多后续输入(如dateB)是通过硬编码而非输入转换程序生成的。
- 超过70%的MR编码测试用例没有明确的输入转换,从而限制了它们的推广应用。
论文中的解决方案:
- 该论文通过从给定的测试用例及其硬编码输入对中推导出明确的输入关系,解决了这一限制。
- 目标是构建一个输入转换函数,将源输入转换为后续输入,促进MR的推广应用,增强测试充分性。
MR-ADOPT
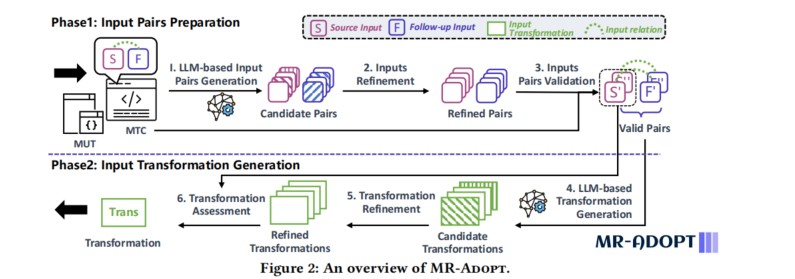
概述:
- MR-Adopt使用源输入和后续输入对,以及上下文(如MR编码的测试用例和被测试的方法),生成输入转换函数。
- MR-Adopt采用两阶段流水线实现输入转换生成。
阶段1:
- 在第一阶段,MR-Adopt通过类比推理生成额外的源-后续输入对,用作输入关系的示例,从而指导输入转换的生成。
- 生成候选测试输入对后,通过数据流分析移除无关代码,基于输出关系断言筛选有效输入对。
阶段2:
- 第二阶段,MR-Adopt基于第一阶段的示例对,利用LLM生成输入转换函数。
- 然后通过进一步移除无关代码和依赖,并将转换函数应用于额外的源输入,最终输出最具通用性的输入转换函数。
总结:
- MR-Adopt通过生成、优化和验证候选转换函数,确保其生成的输入转换在多种源输入中具有通用性,提升测试的充分性。
3.1 Phase 1: Input Pair Preparation
输入对生成:
- MR-Adopt利用大语言模型(LLM)生成新的源输入和后续输入对。通过模仿给定的输入对并结合现有MTC(测试用例)的上下文,LLM生成这些新的输入对。
- 生成源输入后,再生成相应的后续输入。该方法采用了“链式思维”(Chain of Thought)策略,逐步生成源输入和后续输入对。
输入对的优化:
- 为了移除无关代码,MR-Adopt执行数据流分析,识别构造后续输入所需的相关代码,并移除不必要的部分。
- 图4显示了LLM生成的输入对示例,并指出某些输入对无效(如违反MR的输入关系),需要过滤掉这些无效对以避免生成不正确的转换。
输入对验证:
- MR-Adopt通过MR编码的输出关系验证LLM生成的输入对。具体来说,它根据MTC中的开发者编写的断言检查输出,确保输入对的输出与预期的输出关系一致。
- 通过这种方式,MR-Adopt筛选出符合输入关系的有效输入对,过滤掉无效或与输出关系不匹配的输入对。
3.2 Phase2:Transformation Generation
输入转换生成:
- MR-Adopt通过向LLM提供源-后续输入对示例生成候选输入转换函数,这些示例包括硬编码的输入对和第一阶段生成的额外输入对。
- 提供给LLM的提示中包括系统消息、测试方法代码、输入对、测试用例代码以及输出格式。生成的函数包括函数名、参数列表和返回类型等。
输入转换优化:
- 类似于之前的优化过程,LLM生成的输入转换函数可能包含无关代码,MR-Adopt通过构建依赖图去除无关部分。它跟踪定义输入的语句并递归追踪依赖关系,保留相关的语句,移除不必要的部分。
- 通过分析生成函数的依赖项,MR-Adopt确保导入的类和包匹配实际需求,解决不准确命名或缺少导入库的问题。
输入转换评估:
- 经过优化后,MR-Adopt进一步通过测试新源输入评估候选转换的通用性。它通过开发者编写的断言(输出关系断言)作为测试判据。
- 转换函数若能成功生成后续输入并且通过断言,即被视为适用于该源输入。MR-Adopt从所有候选转换中选择适用于最多输入的通用转换。
- 在多个候选转换适用性相同时,MR-Adopt返回生成的第一个转换作为结果。
Evaluation
4.1 Research Questions
RQ1:MR-Adopt 在生成输入转换方面的效果如何?
- 评估 MR-Adopt 与基准方法在生成通用输入转换函数方面的效果,以确定其生成的输入转换是否适用于多个编码测试用例中的MR。
RQ2:与LLM直接生成输入相比,MR-Adopt 生成的输入转换在构建后续输入时效果如何?
- 通过比较MR-Adopt生成的输入转换函数与LLM直接生成的后续输入,评估使用输入转换函数生成后续输入的好处。
RQ3:MR-Adopt 各个组件的贡献是什么?
- 通过消融研究(Ablation Study),分析MR-Adopt各个组件在生成输入转换中的具体贡献。
RQ4:生成的输入转换如何增强测试充分性?
- 探讨编码MR在结合生成的输入转换后,如何通过新输入重用MR,从而提高对SUT的测试覆盖范围,增强测试充分性。
4.2 Dataset
MR编码测试用例(MTCs)收集:
- 通过Xu等人的方法,从高质量的Java项目中收集了2007个MTCs,这些项目至少包含200个GitHub stars。
- 为了确保实验LLM没有在训练期间学习到相关代码,收集的项目均在2023年4月1日之前创建。
- 选取可以成功编译和执行、并且包含两次方法调用(一个用于源输入,一个用于后续输入)的MTC进行分析,排除了更复杂的包含多个输入组的MR。
数据集构建:
- 最终获得了180个MTC,其中54个有显式的开发者编写的输入转换,126个没有输入转换。
- 准备了包含两个部分的数据集:(i) 没有输入转换的100个MTC作为任务,(ii) 对应的输入转换函数作为标准答案。
输入转换任务构建:
- 试图利用所有54个有标准答案的MTC,将开发者编写的输入转换应用于硬编码的源输入来生成后续输入。
- 构建了36个任务,使用开发者的转换函数替换硬编码的后续输入。
- 对于没有开发者编写的输入转换的MTC,手动构建了转换函数,并在两个作者间协作评审解决分歧,最终花费了约200小时完成任务构建。
4.3 Environment and Large Language Models
硬件环境:
- 实验使用的机器配置包括三张RTX 4090显卡、双Intel Xeon E5-2683 v4 CPU和256 GB内存。
使用的大语言模型(LLMs):
- 评估中使用的LLMs包括:
- GPT-3.5(来自OpenAI)
- Llama3-8B(来自Meta)
- Deepseek-coder-7b(来自DeepSeek)
- CodeQwen1.5-7B-Chat(来自阿里巴巴)
- 选择这些模型是因为它们属于知名的LLM系列且可在实验环境中部署。
4.4 Source Input Preparation
挑战:
- 为了评估生成的输入转换,需要有效的源输入作为“测试集”。然而,自动化测试输入生成工具(如Evosuite和Randoop)对于超过50%的MR难以生成有效输入,因为这些输入通常是用户定义的复杂对象,具有复杂的前提条件和环境。
使用LLM生成源输入:
- 最近的研究表明,大语言模型(LLMs)是很好的测试输入生成器。因此,研究中使用了Qwen LLM生成新的源输入用于评估转换。
- 为避免循环评价,使用不同的LLM分别生成“测试集”以及用于MR-Adopt中的输入对和转换函数。
过程:
- Qwen每次生成5个源输入,并重复了10次,使用0.2的温度设置生成更多的源输入。
- Qwen共生成了5,535个源输入,经过去重后得到2,477个输入。随后,通过执行对应的输入转换来验证这些输入是否有效。
- 源输入被认为有效的标准是:它能成功生成后续输入,并通过开发者编写的断言。
- Qwen在一些复杂且具有严格领域限制的对象上无法生成新的有效输入,最终共收集到1,366个有效源输入,平均每个MR有14.37个。
4.5 RQ1: Effectiveness of MR-Adopt
RQ1:MR-Adopt的有效性的概括:
- 实验设置:
- 该研究问题旨在检查MR-Adopt生成输入转换函数的效果,重点在于它们的可编译性和通用性。
- 采用了GPT-3.5、Llama3-8B、Deepseek-coder-7b作为基线模型,直接提示这些模型生成输入转换,并将结果与MR-Adopt进行比较。
- 度量指标包括生成的可编译转换函数数量和生成的通用转换函数数量(即至少适用于75%的源输入)。
- 结果:
- MR-Adopt与GPT-3.5结合时效果最佳,生成了95个可编译的转换函数,其中72个通用于所有源输入。
- 与Llama3和Deepseek结合时,MR-Adopt分别生成了68个和71个通用转换。
- 相比之下,直接提示LLMs生成的转换函数在处理常见案例时效果较好,但在处理边界案例时遇到困难,生成的转换往往依赖于错误的方法或受限的API。
- 对比结果:
- MR-Adopt显著优于基线LLMs,特别是在生成可编译转换和通用转换方面,改进幅度在16.66%到33.33%之间。
- MR-Adopt通过细化生成过程和评估策略,成功生成了适用于大部分源输入的转换,尤其是在生成75%或以上通用转换时表现出色。
结论: MR-Adopt在所有指标上均显著优于基线LLMs,生成了更多的可编译和通用输入转换函数,提升了33.33%的通用性。
4.6 RQ2: Effectiveness of Input Transformations
实验设置:
- 该研究问题旨在评估MR-Adopt生成的输入转换函数在生成有效后续输入方面的效果,并与直接使用LLMs生成的输入对进行对比。
- 使用1,366个准备好的源输入(从之前步骤生成)作为测试集,测量有效后续输入的数量。
结果:
- MR-Adopt与GPT-3.5结合时,生成了1,246个有效后续输入,覆盖了91.22%的源输入。
- 与直接使用LLMs生成的输入对相比,MR-Adopt的有效后续输入数量分别提升了72.10%到108.71%(与Llama3、Deepseek和GPT-3.5相比)。
比较和分析:
- 增强版的LLMs(结合MR-Adopt的优化过程)生成了更多有效后续输入,分别提升了61.82%(与Llama3相比)、69.06%(与Deepseek相比)、75.99%(与GPT-3.5相比)。
- 这表明MR-Adopt的两阶段管道以及准备-优化-验证流程有效提升了输入转换的质量。
- 相比之下,直接使用LLMs生成的后续输入往往存在错误值或无法捕捉多个输入参数之间的约束问题,而MR-Adopt能够更好地处理这些问题。
总结:
- MR-Adopt的优化步骤有效提升了后续输入的生成质量,与GPT-3.5相比最多提升了18.59%。
- MR-Adopt生成的输入转换函数能够为91.22%的源输入生成有效的后续输入,显著超过基线LLMs。
4.7 RQ3: Ablation Study on MR-Adopt
实验设置:
- 通过消除MR-Adopt中的三个关键组件,创建了三个变体来分析每个设计对生成通用输入转换的帮助:
- v1:不使用额外的输入对。
- v2:不进行优化步骤。
- v3:不进行评估步骤。
结果:
- v1(没有额外输入对)导致100%通用转换的生成减少了19.44%。这表明额外的输入对有助于解决过拟合问题,帮助生成更通用的转换。
- v2(没有优化步骤)导致100%通用转换减少了15.27%。这表明优化步骤能够修正生成中的小问题,移除无关代码,从而生成更有效的转换。
- v3(没有评估步骤)导致100%通用转换减少了22.22%。这表明评估步骤对选择最通用的转换函数至关重要,随机选择可能会错过最优解。
结论:
- 研究表明,MR-Adopt的三个设计(额外输入对、优化步骤和评估步骤)都对生成通用输入转换有重要贡献。
- 评估步骤对MR-Adopt效果的贡献最大,额外输入对和优化步骤贡献相似。
4.8 RQ4: Usefulness of Input Transformations
实验设置:
- 该研究问题旨在评估MR-Adopt生成的输入转换在增强测试充分性方面的效果。
- 通过将生成的输入转换整合到MTCs中构建新测试用例(M),并与两种基线进行比较:(i) 开发者编写的MR测试用例(D)和 (ii) LLM生成的后续输入对(L)。
测试充分性评估:
- 使用代码覆盖率(执行的代码行百分比)和变异分数(被测试用例杀死的变异体百分比)作为测试充分性的指标。
- 测试采用Mutation Testing工具Pitest,针对目标类中由MR涉及的方法计算变异分数。
结果:
- 与开发者编写的测试用例(D)相比,整合了MR-Adopt生成的输入转换的新测试用例(D+M)提升了代码覆盖率10.62%,变异分数提升了18.91%。
- 即使对比经过LLM增强的输入对(D+L),新测试用例(D+L+M)也表现出4.25%的代码覆盖率提升和5.67%的变异分数提升。
结论:
- MR-Adopt生成的输入转换通过生成更多的有效后续输入,扩展了对SUT行为的覆盖,显著增强了测试充分性。
- 生成的新测试用例展示了MR-Adopt在提高测试覆盖范围和识别更多潜在缺陷方面的实际效用。