
How Effective Are They? Exploring Large Language Model Based Fuzz Driver Generation
How Effective Are They? Exploring Large Language Model Based Fuzz Driver Generation
Abstract
Fuzz驱动程序对于库API的模糊测试至关重要。然而,自动生成Fuzz驱动程序是一项复杂的任务,因为这需要编写高质量、正确且健壮的API使用代码。基于大语言模型(LLM,Large Language Model)的Fuzz驱动程序生成方法是一个颇具前景的研究领域。与传统基于程序分析的生成器不同,这种基于文本的方法更加通用,能够利用多样的API使用信息,从而生成更易于人类阅读的代码。然而,目前在这一方向上对其有效性和潜在挑战等基本问题的理解仍然不足。
为弥补这一空白,我们首次针对使用LLM生成高效Fuzz驱动程序的关键问题进行了深入研究。本研究整理了一个包含86个Fuzz驱动生成问题的数据集,涉及30个广泛使用的C项目。我们设计并测试了六种提示策略,并在五种最先进的LLM上使用五种不同的温度设置进行了评估。总共生成了736,430个Fuzz驱动程序,耗费了8.5亿个token(费用超过8000美元)。此外,我们还将LLM生成的驱动程序与工业中实际使用的驱动程序进行了对比,并进行了广泛的模糊测试实验(相当于3.75年的CPU时间)。我们的研究发现如下:
1)尽管基于LLM的Fuzz驱动程序生成是一个有前途的方向,但在实际应用中仍面临诸多障碍;
2)LLM在生成具有复杂特定要求的API的有效Fuzz驱动程序时存在困难。三种设计突出的提示策略可以带来帮助:重复查询、通过示例查询和采用迭代查询过程;
3)LLM生成的驱动程序可以实现与工业中实际使用驱动程序相当的模糊测试效果,但在改进方面仍有很大的空间,例如扩展包含的API使用范围,或集成语义Oracle以促进逻辑错误检测。我们将研究洞见应用于OSS-Fuzz-Gen项目,从而促进工业界Fuzz驱动程序生成的实用化。
Before this: Fuzz Driver相关工作: https://zhuanlan.zhihu.com/p/629837208
Fuzzing是目前应用最广泛的程序漏洞挖掘技术,根据待测程序类型大体上可分为
1)Application fuzzer:测试整个程序(如AFL [1])
2)Library fuzzer:测试程序接口或API(如LibFuzzer [2])
本文主要关注近些年第二类fuzzer的研究进展。在fuzz之前,这类fuzzer通常需要为待测library提供fuzz driver/harness,来调用待测library的程序接口或API序列。由于fuzz driver的设计大体上决定了对library的主要测试路径,fuzz driver的编写是非常重要的
Introduction
模糊测试及Fuzz驱动程序的重要性:
- 模糊测试是发现零日漏洞的标准方法。
- Fuzz驱动程序是模糊测试库API的核心组件,需高质量、正确且健壮。
- 手工编写驱动程序耗时且劳动密集,例如OSS-Fuzz维护了数千个驱动程序。
Motivation
基于大语言模型(LLM)的Fuzz驱动生成的优势:
- LLM通过文本生成代码,无需复杂的程序分析。
- LLM能够从文档、错误信息和代码片段等多种来源学习API用法。
- 生成的代码通用性强,适合大规模真实项目,并且更加易读。
现有方法的局限性:
- 传统方法需要从示例中学习API用法,依赖程序分析,局限性较大。
- 现有研究对LLM生成驱动程序的有效性及挑战缺乏深入理解。
基于LLM方法的潜力:
- 提供轻量化、通用的代码生成平台。
- 有助于整合多种学习输入,提升生成效率。
- 开辟了新的研究方向,但仍需进一步探索其基本问题。
Empirical study
To address this gap, we conducted an empirical study for understanding the effectiveness of zero-shot fuzz driver generation using LLMs.
研究目标:
- 探讨基于大语言模型(LLM)的零样本Fuzz驱动生成的有效性。
- 主要关注如何生成“更多”有效的Fuzz驱动,而非仅提高现有驱动的效果。
研究问题:
- RQ1: 当前LLM能在多大程度上生成有效的Fuzz驱动用于软件测试?
- RQ2: 使用LLM生成高效Fuzz驱动面临的主要挑战是什么?
- RQ3: 不同提示策略的有效性和特征如何?
- RQ4: LLM生成的驱动与工业实践中的驱动相比如何?
研究方法:
构建了包含86个Fuzz驱动生成问题的数据集,来源于30个广泛使用的C项目。
设计了六种提示策略,考虑提示内容、交互特性以及查询重复过程。
测试了五种最先进的LLM,包括闭源(如GPT-4和GPT-3.5)和开源模型(如CodeLlama和WizardCoder)。
评估了736,430个Fuzz驱动程序,消耗了0.85亿tokens(费用超过8000美元)。
使用自动评估框架验证驱动程序的编译和模糊测试结果,并手动检查API使用的语义正确性。
对比实验:
- 与工业中手动编写的驱动程序进行对比。
- 进行24小时模糊测试(总计3.75 CPU年)以获取实际见解。
研究意义:
- 通过系统性实验探索LLM生成Fuzz驱动的潜力及改进方向。
Results
- LLM生成Fuzz驱动的潜力:
- 在最佳配置下,LLM可以解决91%的问题。
- 前20种配置中,每种都至少能解决一半的问题。
- 生成驱动的三大挑战:
- 成本控制:71%的问题需重复5次查询,45%需重复10次,需提高查询精度以降低成本。
- 语义正确性:34%的API需语义验证,否则可能导致虚假结果。
- 复杂需求:6%的问题无法通过LLM配置解决,需依赖额外环境或服务。
- 有效提示策略:
- 重复查询:有助于提升性能,但效果在5次后趋于平缓。
- 示例扩展:结合API文档和示例代码能显著提高生成结果。
- 迭代查询:通过循环优化改进LLM的逐步解决能力。
- 性能优化:
- 较低的温度设置(低于1.0)性能更稳定,最佳温度为0.5。
- GPT-4和WizardCoder在开放/闭源模型中表现最佳。
Contributions
- 首次深入研究LLM在Fuzz驱动生成中的有效性,揭示其潜力与挑战。
- 设计并实现六种生成策略,系统分析其优劣。
- 将生成结果与工业实践中的驱动对比,总结改进方向。
- 优化OSS-Fuzz-Gen框架,推动开源项目Fuzz测试的自动化。
Preliminaries
1. Fuzz 驱动程序的基本组成:
一个典型的 Fuzz 驱动程序包含以下三个必要部分:
- 预备步骤初始化(Line 3):初始化输入、设置必要的环境。
- 执行部分(Line 4):调用目标 API 并进行模糊测试。
- 清理部分(Line 7):释放资源,确保不会产生副作用。
此外,有以下三个可选部分可提升驱动程序的有效性:
- 输入调整(Line 2):通过拒绝过短或过长的输入,或者解析多种输入格式,确保输入质量。
- 扩展调用(Line 5):调用更多的 API,以触发更多的程序行为。
- 语义 Oracle(Line 6):类似于单元测试中的
assert,用于检测逻辑错误。
2. 有效 Fuzz 驱动程序的最低要求:
- 核心需求集中在正确初始化参数和满足必要的控制流依赖性。
- 参数初始化的几种情况(按简单性排序):
- C1:如果参数可以是任意值,则使用简单值(如
0或NULL)。 - C2:如果参数是项目中常见变量或宏,则直接使用这些变量。
- C3:如果参数需要用其他库 API 创建(如文件读写),则按惯例调用这些库。
- C4:如果参数的初始化依赖其他 API 的输出,则需先初始化相关 API。
- C1:如果参数可以是任意值,则使用简单值(如
3. Fuzz 驱动程序的正确性要求:
- 高正确性和健壮性:驱动程序必须确保输入被正确传递给目标 API。
- 不正确的初始化或使用可能导致:
- 假阳性(虚假的错误)。
- 假阴性(未能发现实际问题)。
假设我们有一个图形库,提供了一个
Rectangle类及其方法calculate_area(),用来计算矩形的面积。我们需要确保它的逻辑正确。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
def __init__(self, width, height):
self.width = width
self.height = height
def calculate_area(self):
return self.width * self.height
# 测试代码
def test_rectangle_area():
rect = Rectangle(5, 10)
assert rect.calculate_area() == 50, "Area calculation failed for 5x10 rectangle"
rect = Rectangle(0, 10)
assert rect.calculate_area() == 0, "Area calculation failed for 0x10 rectangle"
rect = Rectangle(-5, 10)
assert rect.calculate_area() == 0, "Area should be 0 for negative dimensions"逻辑错误的检测:
- 如果代码中有 bug,例如
calculate_area()忘记考虑负数输入或宽度为零的情况,assert会捕获这些问题。- 在
test_rectangle_area中,负数或宽度为零的情况是明确的逻辑错误。
assert的作用:
- 如果条件为
false,例如面积计算为-50或其他不期望的值,assert会抛出一个异常,提示开发者逻辑错误。扩展:在 Fuzz 测试中的应用
在 Fuzz 驱动中,
assert可以用于验证输入对 API 的逻辑影响。例如:
- 测试输入是否超出预期范围。
- 验证返回值是否满足 API 的使用规范。
- 检查状态变化是否符合预期。
2
3
4
5
6
7
8
9
10
11
12
try:
width, height = data["width"], data["height"]
rect = Rectangle(width, height)
area = rect.calculate_area()
# 使用 assert 验证逻辑
assert area >= 0, "Area should not be negative"
assert area == width * height, "Area calculation mismatch"
except Exception as e:
print(f"Test failed for input: {data}, Error: {e}")自动生成不同输入(例如负数或超大数值)进行测试。
检测代码是否在异常输入下表现出不正确的逻辑行为。
Methodology
3.1 Design of Prompt Strategies
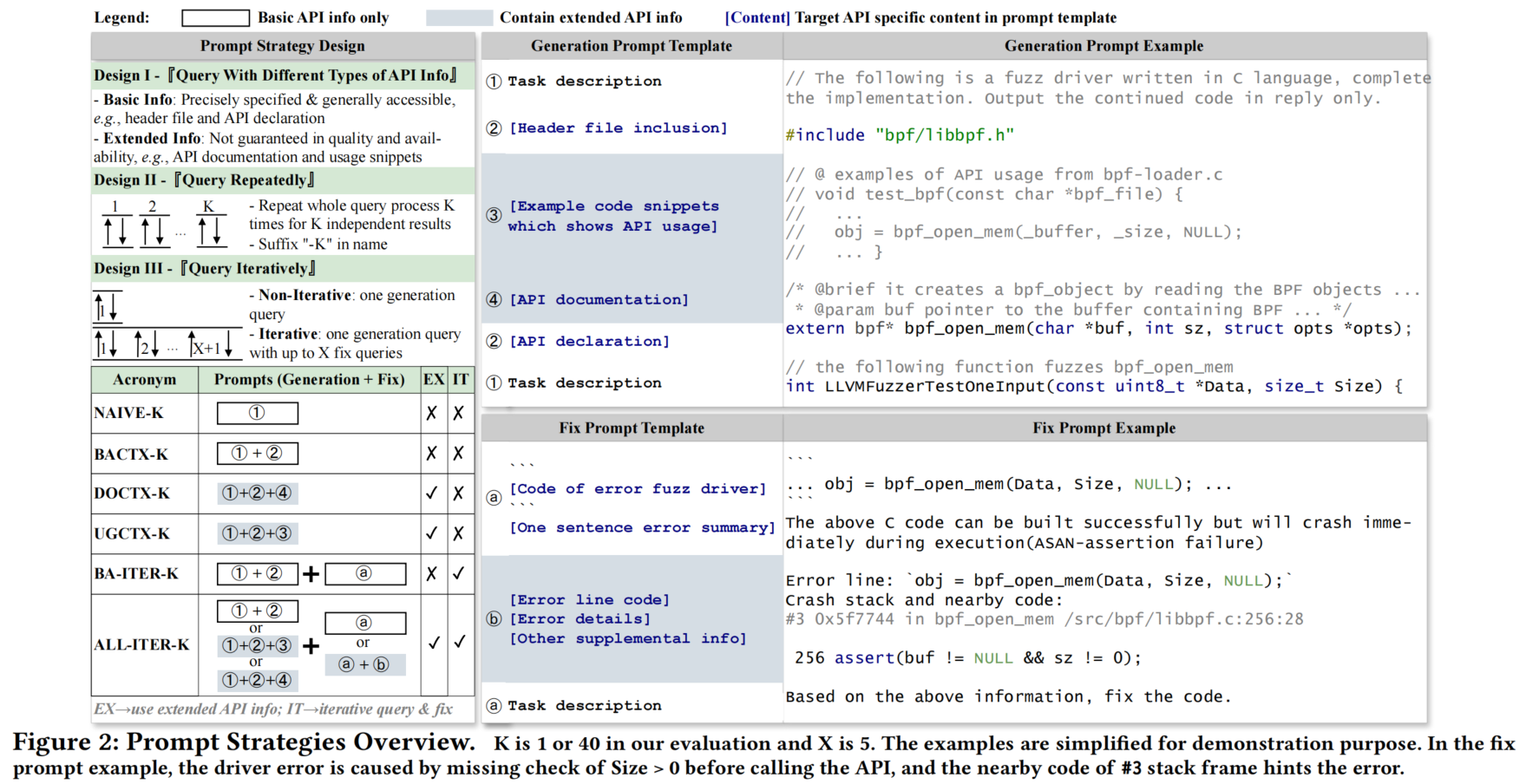
1. Prompt Strategies 的设计关键点
- 三种设计维度:
- API 信息查询:包括基本信息(如 API 声明、参数名称)和扩展信息(如文档、示例代码)。
- 重复查询:评估多次查询的效果(最多重复 40 次)。
- 迭代查询:通过“生成-修复”循环改进驱动程序的有效性。
- 命名规则:
- 如果策略名称中有 “K”,表示使用重复查询。
- 如果名称中包含 “ITER”,表示使用迭代查询。
2. Prompt Strategies 的具体方法
- NAIVE-K & BACTX-K:
- NAIVE-K:仅使用基础 API 信息,不包含上下文。
- BACTX-K:扩展到包含函数名、API 声明等基础上下文信息。
- DOCTX-K & UGCTX-K:
- DOCTX-K:从文档和项目中提取 API 文档信息,扩展 BACTX-K。
- UGCTX-K:从公共代码库(如 GitHub)提取实际代码片段,扩展 BACTX-K。
- BA-ITER-K & ALL-ITER-K:
- BA-ITER-K:基于基本 API 信息,使用迭代查询策略逐步改进驱动程序。
- ALL-ITER-K:结合所有可用信息(包括文档和代码片段),通过迭代策略生成更高质量的驱动程序。
3. 错误分类与修复提示
- 错误类型:
- 编译错误(1/7)。
- 链接错误(1/7)。
- Fuzzing 运行时错误(5/7),进一步分为内存泄漏、超时、崩溃、非有效模糊测试等。
- 修复提示生成:
- 根据错误信息提取根因 API 并提供相关文档或代码片段。
- 修复过程通过迭代改进完成。
4. 主要结论
- 迭代策略的区别:
- BA-ITER-K 仅使用基本 API 信息。
- ALL-ITER-K 利用所有可用资源,性能最优。
- 效果评估:
- 自动检查工具确保生成驱动程序的有效性。
- 提供多种策略以适应不同的需求场景。
3.2 Evaluation Framework
1. Evaluation Question Collection
- 收集有效评估问题的过程:
- 并非所有 API 都适合作为评估目标,某些 API(如无输入的初始化函数)会生成无意义的驱动程序。
- 确保所选 API 具有代表性,优先选择核心 API,而非辅助功能 API。
- 示例:
- 调用
free_object(object *obj)意义不大,除非配合parse_from_str(char *input)一起使用。 - 重点测试目标是输入解析和资源分配逻辑,而非单独释放资源的功能。
- 调用
- 数据来源:
- 从 OSS-Fuzz 的项目中随机选取 30 个 C 项目,手动提取了 86 个核心 API 作为评估问题。
2. Effectiveness Validation Criteria
- 评估有效性的 4 个步骤:
- 使用编译器检查驱动程序的语法错误。
- 在一无初始输入的情况下观察模糊测试会话是否能找到错误或进行进展。
- 无进展或无错误即视为无效。
- 对检测到的错误进行过滤,确保是目标 API 导致的错误。
- 手动撰写 API 特定语义测试,以检测生成驱动程序中常见的无效模式。
- 特殊场景处理:
- 对于需要依赖其他 API 的情况(如客户端 API 测试需要服务端上下文),通过注入 hook 实现模拟环境。
3. Evaluation Configuration
- 配置内容:
- 包括 LLM 模型、提示策略、温度参数等。
- 测试中使用 5 个不同的 LLM 和 5 种温度设置,共评估 6 种提示策略。
- 系统角色设置:
- 模拟用户身份为“负责库 API Fuzz 驱动程序的安全审计员”。
总结
该框架通过精心挑选 API、严格的错误验证和配置策略,系统性地评估了生成的 Fuzz 驱动程序的有效性及其潜在问题,确保评估结果的可靠性和代表性。
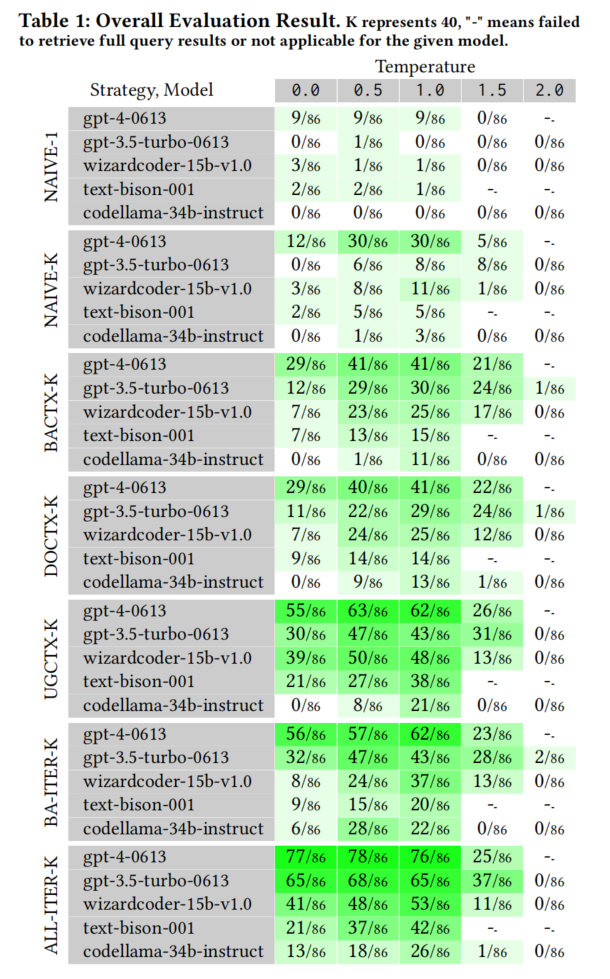
Overall Eectiveness (RQ1)
1. 研究结果概述
- 成功率:
- 在最优配置(如 GPT-4-0613,ALL-ITER-K,温度 0.5)下,生成的 Fuzz 驱动程序成功解决了 91% 的问题(78/86)。
- 五个评估的 LLM 中,三个模型(包括一个开源选项)和一半的提示策略能解决超过一半的问题。
- 数据缺失的处理:
- 由于某些温度设置(如 2.0)下的性能较差或超时,部分数据不完整,但对整体评估影响较小。
2. 主要发现
- 语言模型生成 Fuzz 驱动程序的可行性:
- 研究结果提供了有力证据,证明基于大语言模型的 Fuzz 驱动生成在实践中具有巨大潜力。
- 成功率的显著差异:
- 成功率在不同配置间存在显著波动,表明温度、模型和提示策略的组合对性能影响重大。
- 例如:
- 使用
gpt-3.5-turbo-0613和NAIVE-1, 0.0配置时,无法解决任何问题。 - 同一模型在
ALL-ITER-K, 0.0配置下,成功解决了 76% 的问题(65/86)。
- 使用
- 最佳配置的表现:
- 表现最好的配置集中在优化得当的“绿色区域”,即温度、模型和策略的合理组合。
3. 结论
- 成功率依赖于适当的配置调整。
- 为实现高成功率,避免使用次优组合至关重要。
- 结果表明,在生成 Fuzz 驱动程序方面,LLM 的能力与提示策略和配置密切相关,正确的优化策略能够显著提升性能。
4.1 Analysis of Eectiveness Factors
1. Prompt Strategies 的影响
- 总体发现:
- 提示策略设计对整体效果有显著影响,从 NAIVE-1 提高到 ALL-ITER-K,问题解决率从 10% 提升到 90%。
- 综合利用可用信息的提示策略效果更好:
- 如 UGCTX-K 因包含目标 API 的代码示例,显著优于 BACTX-K。
- BA-ITER-K 在初始信息相同的情况下,通过迭代收集调试信息,比 BACTX-K 表现更优。
- ALL-ITER-K 整合了扩展 API 信息并采用递归问题解决方法,在所有策略中表现最佳。
2. 温度对性能的影响
- 最佳温度:
- 温度设置为 0.5 的配置普遍实现最高成功率。
- 较低温度(<1.0)在一致性和可预测性方面表现更优,而高温度增加的随机性对任务没有明显优势。
- 特例:
- 在 0.0 温度下,ALL-ITER-K 和 BA-ITER-K 依然表现良好,成为次优配置。这可能是因为:
- 提示策略已经内置了随机性。
- 评估标准主要关注驱动程序的有效性,而非 API 多样性。
- 在 0.0 温度下,ALL-ITER-K 和 BA-ITER-K 依然表现良好,成为次优配置。这可能是因为:
3. 开源 LLM 与闭源 LLM 的比较
- 闭源模型的表现:
- 闭源模型(如 GPT-4-0613)总体优于开源模型,性能最佳。
- GPT-3.5-turbo-0613 提供了性能和成本的良好平衡。
- 开源模型的进步:
- WizardCoder-15b-v1.0 在开源模型中表现突出,超过部分闭源模型(如 Text-Bison-001)。
- 尽管与 GPT-3.5-turbo-0613 存在性能差距,但其表现已达到开源领域的可观水平。
总结
- 提示策略是决定生成驱动程序性能的核心因素,ALL-ITER-K 因全面整合信息和递归方法而表现最佳。
- 温度的选择对一致性和结果质量至关重要,温度 0.5 为最优。
- 闭源 LLM 在生成能力上仍有优势,但开源模型正逐步缩小差距。
4.2 How Far Are We to Total Practicality?
1. 总体评价
- 在最优配置(GPT-4-0613,ALL-ITER-K,温度 0.5)下,LLM 能解决 86 个 API 中 78 个问题(91% 的成功率)。
- 然而,这并不意味着 LLM 已经完全适用于生产环境。
2. 三大主要挑战
C1: Fuzz 驱动生成中的高 Token 成本
- 约 50% 的解决问题需要超过 10 次查询,31% 的问题需超过 20 次,甚至 18% 的问题需超过 40 次。
- 高查询成本不仅增加了经济负担,还影响了实际应用的效率。
- 需要开发成本优化技术以提升驱动生成效率。
C2: 确保 API 使用的语义正确性
- 在 34% 的 API 中(29/86),生成的驱动程序存在语义错误,如:
- 传递错误类型的参数(例如文件名参数应为已创建的文件,而不是变异后的字符串)。
- 未检查某些条件或缺失状态验证。
- 当前需要手动验证语义正确性,而自动化验证仍然是一个重大技术挑战。
C3: 满足复杂 API 使用依赖
- 有 5 个 API 无法通过任何配置解决,原因是:
- 驱动程序需要深度理解 API 的上下文关系(如 tmux 的窗口、面板等关系)。
- 某些网络相关 API 需要创建特定的服务端或客户端环境才能调用目标 API。
- 有效驱动程序的生成需要满足这些上下文要求,但目前 LLM 在这些场景中表现有限。
3. 总结
虽然基于 LLM 的生成技术展示了很大的潜力,但在以下方面仍存在重大挑战:
- 控制生成成本。
- 实现语义正确性的自动验证。
- 处理复杂的上下文依赖问题。 这些问题需要进一步的技术改进,才能使该技术在生产环境中可靠应用。
Fundamental Challenge (RQ2)
5.1 Links Between Question and Performance
1. 研究目标
- 通过 BACTX-K 策略分析 Fuzz 驱动生成中核心困难。
- 目标是探索问题解决率与 API 使用复杂性之间的关系。
2. 主要发现
- 成功率与问题复杂性呈反比:
- 问题越复杂,LLM 的成功率越低。
- API 使用复杂性由以下指标综合量化:
- 独特项目 API。
- 独特 API 使用模式。
- 独特标识符(如项目中的全局变量)。
- 分支和循环。
- API 使用的特定控制流依赖性。
- LLM 的性能受限于 API 使用复杂性:
- 对于复杂 API 使用,生成驱动程序需要准确预测:
- API 参数的正确使用。
- 控制流的依赖性。
- 然而,LLM 无法像人类一样通过文档或实现代码验证其预测。
- 对于复杂 API 使用,生成驱动程序需要准确预测:
3. 性能下降的原因
- LLM 的训练主要基于语言基础和编程惯例,对于复杂场景(如少见的 API 使用模式或具有特殊语义约束的情况)缺乏支持。
- 在处理 C 项目中复杂的低级别、特定于项目的 API 时,LLM 容易丢失重要细节,导致错误预测。
4. 结论
- 关键挑战:
- 当目标 API 使用模式更加复杂时,LLM 的性能显著下降。
- 改进方向:
- 提升对复杂 API 的理解和处理能力是实现生成驱动程序高效性的关键。
总结:API 使用复杂性是限制 LLM 性能的重要因素,需要开发更精准的机制应对复杂 API 的生成需求。
5.2 Failure Analysis
1. 分析目标
- 对 BACTX-K 策略下生成失败的 Fuzz 驱动程序进行分析,以揭示生成过程中的主要阻碍。
- 总共分析了 52,824 个无效的驱动程序,其中包含 11,095 个运行时错误。
2. 失败分类(Failure Taxonomies)
将失败原因分为 两类:
- 语法错误(编译和链接阶段发现):
- G1 - Corrupted Code:由于 token 限制或括号未匹配,生成的代码缺乏完整功能。
- G2 - Language Basics Violation:违反语言基础规则(如变量重定义、括号不匹配、不完整表达式等)。
- G3 - Non-Existing Identifier:引用了不存在的标识符(如头文件、宏、全局变量等)。
- G4 - Type Error:函数参数类型不匹配或类型转换错误(如将 void 转换为变量)。
- 语义错误(运行时模糊测试中发现):
- S1 - Incorrect Input Arrangement:输入格式不正确,未满足 API 的要求。
- S2 - Misinitialized Function Args:初始化参数的值或状态不满足函数要求。
- S3 - Inexact Ctrl-Flow Deps:函数的控制流依赖未正确实现(如忽略指针非 NULL 检查、遗漏上下文初始化等)。
- S4 - Improper Resource Cleaning:资源清理 API 使用错误或遗漏(如未关闭文件)。
- S5 - Failure on Common Practices:未正确实现常见库函数(如缓冲区溢出、使用只读缓冲区等)。
3. 核心发现
- 问题来源:
- 目标 API 的使用方式过于复杂,难以在单个提示中完全覆盖,可能导致 token 限制或模型注意力分散。
- 单个驱动程序的生成依赖于多种实现路径,无法完全预测。
- 模型局限性:
- 语言模型具有黑箱和概率性,难以全面保证输出的准确性。
- API 的实现方式多样化,增加了生成正确驱动程序的难度。
4. 结论
- LLM 在处理复杂 API 场景时仍存在显著挑战,主要包括:
- 语法错误导致代码无法编译。
- 语义错误导致运行时行为不符合预期。
- 提升对 API 使用规则的理解、优化提示策略,将是提高成功率的关键。
Characteristics of Key Design (RQ3)
6.1 Repeatedly Query
1. 重复查询的重要性
- 重复查询是提示策略的关键部分,可显著提高生成 Fuzz 驱动程序的成功率。
- 在最优配置(GPT-4-0613, ALL-ITER-K, 温度 0.5)下,47.44% 的问题通过重复查询解决(37/78)。
- 对于前 20 种配置,重复查询的平均贡献率高达 **67.50%**。
2. 效果分析
- 配置与重复查询收益的关系:
- 配置越有效,重复查询带来的收益越大。
- 表明重复查询与整体配置效率存在强相关性。
- 重复查询的边际收益递减:
- 在初始几轮查询后,重复查询的收益显著下降。
- 具体分析显示,超过 6 次查询 后收益变小,仅解决初始查询外 20% 的问题。
3. 推荐
- 建议将重复查询的次数限制在 6 次以内,以平衡收益与成本。
总结
- 重复查询是提升 Fuzz 驱动程序生成成功率的重要策略,特别是在复杂问题上效果显著。
- 然而,其收益在初期几轮后快速下降,需要控制重复次数以优化效率和资源利用。
6.2 Query With Extended Information
1. 使用 API 文档的查询
- 效果对比:
- DOCTX-K 和 BACTX-K 的结果在解决问题的数量上没有显著差异。
- 原因在于:
- 评估中的 43% 的 API(37/86)没有文档支持,这使得 DOCTX-K 和 BACTX-K 查询相同。
- API 文档通常只有高层次描述,缺乏低级细节(如参数初始化要求),无法有效解决关键问题。
2. 使用代码示例的查询
- 效果对比:
- UGCTX-K 比 BACTX-K 表现显著提升,平均在 22 个配置中解决问题的数量提高了 **104%**。
- 示例代码提供了直接的 API 用法细节,大幅增强模型的性能。
- 代价分析:
- 包含代码示例的查询显著增加了 token 成本,平均增长 10 倍:
- Token 成本从 4.20 增加到 39.71,UGCTX-K 单次正确解决问题的平均成本为 32,367 tokens。
- 包含代码示例的查询显著增加了 token 成本,平均增长 10 倍:
- 示例来源影响:
- 内部项目的代码(Internal)和测试相关代码(Test & Example)提供的示例质量显著高于其他来源。
- 内部示例能直接展示目标项目 API 的用法,而测试代码包含更具体的功能示例。
3. 案例分析
- wc_Str_conv_with_detect:
- 该 API 的用法不直观(将一种字符编码转换为另一种),需要复杂的参数初始化(如特定 API 生成的结构)。
- 大多数策略因初始化错误而失败,而包含正确示例的 UGCTX-K 能直接提供准确用法,从而解决问题。
4. 总结
- 结论:
- 示例代码对提升模型性能至关重要,能有效弥补文档描述的不足。
- 然而,使用代码示例的成本显著增加,需要在效率和精度之间权衡。
6.3 Iterative Query
1. Iterative Query 的重要性
- 迭代查询策略是一种能够显著提升性能的关键设计:
- BA-ITER-K 相较于 BACTX-K,解决的问题多了 **159%**。
- ALL-ITER-K 比 UGCTX-K 多解决了 23% 的问题。
- 代价:
- 迭代查询会显著增加 token 成本:
- 对于 BACTX-K,每次成功驱动生成的 token 成本增加了 **57%**。
- 对于 UGCTX-K,增加了 **17%**。
- 迭代查询会显著增加 token 成本:
2. 成效来源
- 信息利用:
- 迭代查询充分利用了更广泛的信息,如先前生成的驱动程序验证过程中产生的错误数据。
- 问题逐步分解:
- 采用逐步处理和分而治之的方法,简化生成任务的复杂性。
- 每次迭代基于错误反馈修正生成结果,逐步完善驱动程序。
3. 案例分析
- pj_stun_msg_decode:
- 该函数的第一个参数需要多层 API 依赖初始化:
- 依赖链:
pj_pool_create→pj_caching_pool_init。
- 依赖链:
- 非迭代策略的问题:
- 无法准备所有正确的间接依赖使用细节,导致失败。
- 迭代策略的解决方法:
- 根据错误反馈逐步解决问题:
- 修复错误的 API 使用。
- 修正类型不匹配错误。
- 解决运行时崩溃,利用崩溃堆栈中断言代码定位问题。
- 根据错误反馈逐步解决问题:
- 该函数的第一个参数需要多层 API 依赖初始化:
4. 总结
- 优势:
- 迭代查询通过利用多样化的信息和分步解决复杂依赖问题的能力,显著提高了生成效率和质量。
- 劣势:
- 增加了 token 成本和生成过程的复杂性。
OSS-Fuzz Driver Comparison (RQ4)
1. 对比概述
- 比较了 LLM 生成的驱动程序与 OSS-Fuzz 的驱动程序,以获得实际应用的洞见。
- 测试了两个 LLM 配置:GPT-4-0613 和 WizardCoder-15b-v1.0,均采用迭代查询策略,温度设为 0.5。
- 数据来源:
- 共评估了 53 个问题,使用合并后的驱动程序进行对比。
- 使用
wrapper代码片段链接输入种子与驱动逻辑,并通过 switch 结构决定每次迭代使用的逻辑。
2. 实验设置
- 使用了
libfuzzer和AFL++作为模糊测试工具,进行了 5 次重复测试,每次运行 24 小时。 - 总实验时间为 3.75 CPU 年。
- 测量指标包括:
- 覆盖率。
- 崩溃次数。
- 使用的 API 数量。
- 语义 Oracle 的使用情况。
3. 对比结果
(1) API 使用情况
- LLM 的 API 使用倾向:
- LLM 通常保守地使用 API,如果提示中没有明确指导,往往仅调用必要的 API。
- LLM 生成的驱动中,14%(5/35)的 API 使用比 OSS-Fuzz 更少;WizardCoder 中这一比例为 39%。
- 示例代码可以帮助扩展 API 使用范围。
- OSS-Fuzz 的 API 多样性:
- OSS-Fuzz 的驱动程序由不同贡献者创建,API 使用多样化。
- 一些驱动程序基于现有测试文件修改生成,类似于通过 LLM 查询示例的过程。
(2) Oracle 的使用情况
- OSS-Fuzz 驱动中:
- 15 个问题至少使用了一个语义 Oracle(如检查返回值或输出是否符合期望)。
- LLM 驱动中:
- 没有驱动包含语义 Oracle,这成为 LLM 生成驱动的主要不足。
(3) 覆盖率与崩溃检测
- 大多数情况下,LLM 生成的驱动程序在覆盖率和唯一发现崩溃数量上表现与 OSS-Fuzz 相当甚至更好。
- 注意事项:
- LLM 驱动未使用 Oracle,因此避免了误报;但在大型项目中,缺乏 Oracle 可能导致遗漏关键语义错误。
4. 总结
- 优势:
- LLM 驱动程序在模糊测试性能上与 OSS-Fuzz 相当,具有实用性。
- 劣势:
- LLM 生成的驱动程序缺乏语义 Oracle,无法检测逻辑错误。
- 在扩展 API 使用和增加语义检测能力方面仍有改进空间。
LLM 的驱动生成技术在性能上已接近工业标准,但在语义分析与大规模应用中仍面临挑战。
Discussion
1.与 OSS-Fuzz-Gen 的关系
- 项目背景:
- Google 的 OSS-Fuzz-Gen 项目专注于基于 LLM 的 Fuzz 驱动生成,旨在帮助发现零日漏洞并扩大测试覆盖范围。
- 该项目主要集中于工程实现(如 LLM 接口与 OSS-Fuzz 项目的集成),而对提示策略设计、模型参数影响、以及挑战与改进方向的讨论较少。
- 研究互补性:
- 本研究深入探讨了提示策略和生成技术的基础问题,设计了多种提示策略,评估了不同模型和温度设置下的效果,并总结了发现。
- 改进贡献:
- 为 OSS-Fuzz-Gen 平台引入了新的功能:
- 运行时错误自动验证。
- 错误分类与迭代修复流程。
- 目前改进已并入主分支,并应用于 282 个支持的项目。
- 为 OSS-Fuzz-Gen 平台引入了新的功能:
2. 潜在改进方向
- 领域知识建模:
- 将特定领域的知识(如通信协议状态机)进行建模和利用,以指导驱动生成。
- 混合解决方案:
- 探索结合传统程序分析与提示策略、基于代理的方法。
- 模型微调:
- 使用细化的训练数据,提升模型生成效率与效果。
3. 有效性威胁
- OSS-Fuzz 数据依赖性:
- 某些 OSS-Fuzz 驱动可能已包含在 LLM 的训练数据中,可能影响生成验证的独立性。
- 解决方案:
- 手动验证生成的驱动是否满足语义约束。
- 生成驱动具有独特的编码风格,与 OSS-Fuzz 的驱动差异明显,显示其未直接复制。
- 局限性:
- 本研究专注于 C 项目,可能无法完全泛化到其他语言或领域。