
METAL Metamorphic Testing Framework for Analyzing Large-Language Model Qualities
METAL: Metamorphic Testing Framework for Analyzing Large-Language Model Qualities
Abstract
大型语言模型(LLMs)已经改变了自然语言数据处理的范式。然而,其黑箱性和概率特性可能导致多种LLM应用中输出质量的潜在风险。最近的研究通过生成对抗输入文本,测试了LLMs的质量属性(QAs),例如稳健性或公平性。然而,现有研究在覆盖LLMs的QAs和任务方面存在局限性,并且难以扩展。此外,这些研究通常仅使用一个评估指标——攻击成功率(ASR)来评估其方法的有效性。为了解决这些问题,我们提出了一种用于分析LLMs的变形测试(METAL)框架,通过应用变形测试(MT)技术来系统化地测试LLMs的质量。
这种方法通过定义变形关系(MRs),为评估提供模块化的指标,从而促进LLMs质量的系统测试。METAL框架可以从覆盖各种QAs和任务的模板中自动生成数百个MRs。此外,我们引入了结合ASR方法的新颖指标,将其整合到文本的语义质量中,以准确评估MRs的有效性。通过对三个主流LLMs的实验,我们证实了METAL框架能够有效评估LLMs在主要任务上的重要QAs,并揭示LLMs的质量风险。此外,提出的新指标能够指导每项任务的最优MRs生成方式,并为生成MRs的最有效方法提供建议。
关键词:大型语言模型,变形测试,质量属性,文本扰动
INTRODUCTDION
Background
大型语言模型(LLMs)改变了自然语言数据检索和分析的格局。
工业界已推出多个LLMs,如Google PaLM、ChatGPT、Llama2等。
LLMs被广泛应用于多种领域,需关注其潜在风险对输出质量的影响。
高扩展性、黑箱特性、概率性导致无法保证意外场景下的高质量输出(如稳健性、公平性)。
近期研究通过生成对抗性输入和提示测试LLMs的质量属性(如稳健性)。
对抗性输入可能导致LLMs输出结果的显著差异。
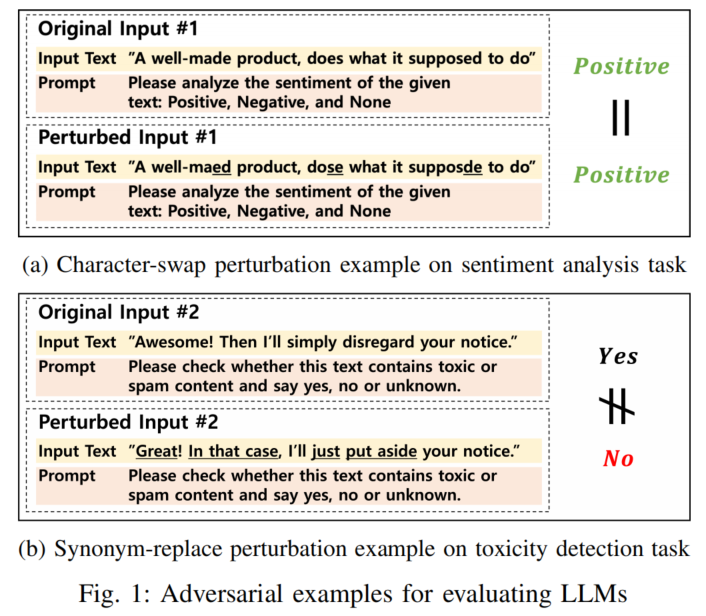
Motivation and limitations
对抗性输入测试的分析:
- 提供了两种对抗性输入来评估LLMs的稳健性:
- 示例1(Fig. 1(a)):通过字符交换的输入,情感分析任务中LLMs输出稳定。
- 示例2(Fig. 1(b)):通过同义词替换的输入,毒性检测任务中LLMs的稳健性受到影响。
**现有测试方法的局限性 [4-13] **:
- 仅覆盖少量关键质量属性(QAs)。
- 测试范围局限于特定任务,难以扩展至多样化的应用场景。
- 主要依赖攻击成功率(ASR)作为评估指标。
[5] B. Liu, B. Xiao, X. Jiang, S. Cen, X. He, W. Dou et al., “Adversarial attacks on large language model-based system and mitigating strategies: A case study on chatgpt,” Security and Communication Networks, vol. 2023, 2023.
[9] F. Perez and I. Ribeiro, “Ignore previous prompt: Attack techniques for language models,” arXiv preprint arXiv:2211.09527, 2022.
[12] X. Huang, W. Ruan, W. Huang, G. Jin, Y. Dong, C. Wu, S. Bensalem, R. Mu, Y. Qi, X. Zhao et al., “A survey of safety and trustworthiness of large language models through the lens of verification and validation,” arXiv preprint arXiv:2305.11391, 2023.
[13] J. Wang, Z. Liu, K. H. Park, M. Chen, and C. Xiao, “Adversarial demonstration attacks on large language models,” arXiv preprint arXiv:2305.14950, 2023.
Initution
变形测试(MT)的引入:
- 通过定义变形关系(MRs),对LLMs的QAs进行系统化测试。
- 变形关系的示例包括:
- MR1:原始输入与字符交换输入的输出应一致。
- MR2:原始输入与同义词替换输入的输出应一致。
变形关系的定义与优势:
- 定义由目标模型、输入文本、提示、关系运算符(如=、≠)和扰动函数(如字符交换)组成。
- 优势:
- 无需依赖有限的测试数据库,也无需标注数据。
- 高扩展性,可适用于LLMs的多种任务。
- 作为模块化工具,评估LLMs的QAs和任务表现。
Approach
构建用于分析LLMs的变形测试框架(METAL),以解决现有测试方法的局限性。
框架设计:
- 定义覆盖主要质量属性(如稳健性、公平性、非确定性和效率)的变形关系(MR)模板。
- 基于模板开发自动化MR生成流程,并引入多种文本扰动类型。
- 利用LLMs及框架功能,从自检和交叉检查角度优化MR生成流程。
- 提出结合ASR方法的新指标,整合文本语义与结构相似性,用于精确评估MR的有效性。
研究问题:
- RQ1:框架能否评估LLMs并揭示实现多样QAs的质量风险?
- RQ2:哪些MR最适合评估LLMs的特定任务?
- RQ2-1:哪个MR最有效?
- RQ2-2:哪个MR对特定任务最优化?
- RQ3:哪种MR生成方法在LLMs的自检/交叉检查中表现最佳?
实验结果:
- 在GooglePaLM、ChatGPT和Llama2上应用框架。
- 结果显示:
- GooglePaLM在大多数QAs和任务上表现优于其他模型。
- 新提出的MR有效性指标能引导最优MR的选择。
- 验证了LLMs自检/交叉检查的可行性,其中ChatGPT在MR生成中表现出高效性。
RELATED WORKS
Adversarial test datasets.
AdvGLUE [16]:
- 用于评估NLP模型在多个任务上的准确性(Accuracy)和稳健性(Robustness),包括情感分析和自然语言推理(NLI)。
- 数据集包含人为设计的对抗性样本(如拼写错误或关键字压力测试)。
AdversarialSQuAD [17]:
- 从SQuAD扩展而来,通过在上下文段落末尾添加干扰句子设计的对抗性数据集。
- 专注于问答(Q&A)任务的攻击性能评估。
ANLI [18]:
- 提供人工精心设计的复杂句子,用于评估NLI任务的对抗性性能。
SQuAD 2.0 [20]:
- 包含不可回答的问题,这些问题与SQuAD 1.0中的可回答问题相似。
- 适用于问答任务的对抗性评估。
SNLI [19] 和 HELLASWAG [21]:
- 提供用于NLI和Q&A任务的准确性测试数据。
发现和局限性:
- 数据集仅覆盖LLMs应用场景中的有限任务。
- 大多数数据集只关注特定功能需求(如准确性),仅AdvGLUE评估了稳健性。
- 数据集的测试案例数量有限,主要由于分析和标注成本高,难以适应LLMs在不同领域中的广泛使用需求。
Adversarial attack generators.
对抗攻击生成器的研究:
- 为解决有限测试数据集的多样性和可迁移性问题,提出了基于预训练NLP模型的对抗攻击生成器 [4-13]。
- 攻击生成器将原始文本转换为扰动文本,用于验证LLMs任务的稳健性(Robustness)。
具体研究工作:
- Liu et al. [6]:提出一个预训练模型,通过追加嵌入空间生成扰动文本。
- Jin et al. [7] 和 Chiang et al. [11]:提出同义词替换攻击模型,生成语义相同但句法不同的句子。
- Wang et al. [8]:为情感分析任务提供了语义扰动功能。
生成修改提示的研究:
- Guo et al. [22]:提出数据完整性和隐私攻击方法,贯穿预训练NLP模型的构建和微调流程。
- Perez et al. [9] 和 Zhou et al. [25]:提出了目标劫持和提示泄露攻击方法,通过添加特定命令和后缀进行攻击。
- Li et al. [23] 和 Shen et al. [24]:提出越狱攻击方法,诱导隐私和安全泄露。
现有攻击模型的局限性:
- 仅生成特定类型的文本扰动,扩展性较低,难以覆盖各种质量属性(QAs)和任务。
- 提示攻击需要分析整个ML流水线,以缓解安全和隐私问题。
- 研究仅基于攻击成功率(ASR)评估方法,未考虑扰动的质量。
QA analysis on NLP models.
**HELM框架 [27]**:
- 由Liang等人提出,用于综合评估NLP模型的质量属性(QAs)。
- 提供了多样的测试数据集和评估指标,但主要是对现有基准测试的概览,而非可执行的评估框架。
**对抗性攻击的研究 [28]**:
- Qiu等人研究了多种对抗攻击,分类为四个级别,并分析了相应的对抗训练方法和防御策略。
- 重点在于提出对抗攻击的替代防御策略,而非评估LLMs的QAs。
**基于变形测试的垃圾检测评估 [29]**:
- Wang等人提出了一个基于变形测试(MT)的评估框架,专注于文本垃圾检测。
- 分类了11种扰动类型,并定义了变形关系(MRs),通过真实垃圾文本(英文和中文)的分析评估LLMs在垃圾检测任务中的稳健性(Robustness)。
METAL framwork
我们的METAL框架的特点:
- 提供一次性评估,覆盖四个主要QAs和六个任务。
- 支持从无限制来源输入文本,采用MT技术。
- 系统定义了五个MR模板,涵盖主要QAs和任务。
- 开发了自动MR生成流程,支持13种扰动类型的输入文本生成,并执行模块化评估。
- 结合ASR和文本相似度度量,精准评估MR的有效性。
APPROACH: METAL FRAMEWORK
A. Quality Attributes and Tasks in LLMs
变形关系(MRs)的定义:
- MT框架需要定义一组MRs作为目标系统的评估指标和测试Oracle [14]。
- 本研究采用自上而下的方法,确定覆盖关键QAs和任务的MR模板,然后基于模板生成MRs。
关键质量属性(QAs):
- 通过对通用机器学习和生成式AI的评估研究 [15, 22, 27, 30-38],确定以下四个关键QAs:
- 稳健性(Robustness)
- 公平性(Fairness)
- 非确定性(Non-determinism)
- 效率(Efficiency)
- 其他QAs如可解释性(Explainability)、安全性(Security)和隐私性(Privacy)需要外部数据或整条ML管道的分析,未包含在本研究中 [30, 34, 35]。
QAs的具体定义:
- 稳健性:LLMs在扰动输入下的输出应保持一致 [41]。
- 公平性:不同人群生成的相同输入结果应一致 [27, 42-44]。
- 非确定性:相同输入应产生一致的输出 [45-47]。
- 效率:原始与扰动输入的处理时间差应低于阈值。
任务划分与分类:
- 将六个任务分为两类 [27, 28, 48]:
- 分类任务:单标签分类,包括情感分析、毒性检测、新闻分类。
- 生成任务:多标签任务,包括文本摘要、问答和信息检索。
QAs与任务的相关性:
- 稳健性、非确定性、效率:与六种任务高度相关。
- 公平性:主要与情感分析、毒性检测、问答任务相关 [27]。对新闻分类等任务的公平性分析受限于区域和数据集的定义。
研究重点:
- 针对公平性问题,主要分析情感分析、毒性检测和问答任务。
- 通过MR模板,评估这些任务的QAs表现。
B. Metamorphic Relation Templates for LLM Evaluation
变形关系模板(MRTs)的定义:
- MRTs系统性定义了MRs,用于评估LLMs的功能需求或质量属性(QAs)[49, 50]。
- MRT由以下组件组成:
- LLMs:可执行的模型或API。
- Input:输入样本文本。
- Prompt:任务相关的指令文本。
- REL_OP:关系运算符(如=, ≠, >, <)。
- Perturb:对抗性扰动函数。
- Dist:计算文本间距离的函数。
主要MRT类型及公式:
- Equivalence_MRT (公式7):
- 比较原始输入与扰动输入的输出是否相等,用于稳健性(Robustness)评估。
- 适用于短文本任务(如分类任务)。
- Discrepancy_MRT (公式8):
- 检查原始输入和扰动输入的输出是否不同,用于评估对语义改变的稳健性。
- 适用于生成扰动(如反义词替换、代词替换)的场景。
- Set_Equivalence_MRT (公式9):
- 评估公平性(Fairness)和非确定性(Non-determinism),比较原始输入与一组扰动生成的输出集合。
- 可用于验证相同输入是否对不同群体(如性别、地区)输出一致结果。
- Distance_MRT (公式10):
- 通过距离函数量化原始与扰动输入输出的差异,用于稳健性和生成任务的效率(Efficiency)评估。
- Set_Distance_MRT (公式11):
- 检查生成任务的非确定性,通过多次运行相同输入结果的输出一致性。
模板适用性:
- MRTs提供全面的QAs和任务覆盖,结合公式(7)-(11),首次正式定义了评估LLMs质量属性的方法。
- 可用于分类和生成任务,确保LLMs的稳健性、公平性、非确定性和效率的评估。
C. Generating Metamorphic Relations using Templates

MR模板与扰动函数的生成:
- MR模板根据评估目标、质量属性(QAs)和目标任务定义评估范围。
- 通过指定扰动函数(如
P ∈ Perturb),自动生成继承自模板的变形关系(MR)。
**13种扰动函数分类 [26-28]**:
- 字符级扰动(7种):包括替换、删除、添加、交换、打乱字符顺序,以及将文本转换为l33t格式(如“apple” → “@ppl3”)和随机插入空格。
- 词和句子级扰动(5种):包括语义保留与改变,例如反义词替换(语义改变)和随机替换虚拟句子(语义改变)。
- 语句级分组:通过添加背景信息句子(如“此文本由[性别]/[年龄]/[种族]/[取向]群体提供”),为公平性(Fairness)评估提供支持。包含21种分组选项(3性别、3年龄、10种族、5取向)。
扰动函数生成与LLMs结合:
- 使用LLMs生成扰动文本,针对自检和交叉检验需求,设计特定提示(如随机替换同义词)。
- 在实验中,发现部分生成文本低质或不符合语义逻辑,例如无意义的替换或上下文不符的结果。
解决低质量问题:
- 为文本扰动设计新的质量指标,确保生成文本在语义和上下文上的适用性(详见Section IV-B)。
- 提出改进的方法,用于提高扰动生成的合理性和准确性。
D. Framework Implementation
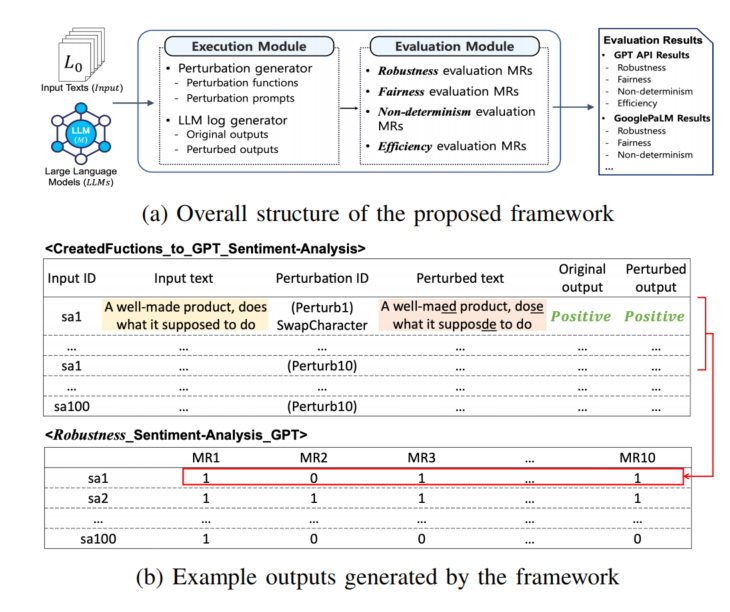
METAL框架的目标:
- 用于评估LLMs在六种任务中四个关键质量属性(QAs)的表现。
框架模块:
- 执行模块(Execution Module):
- 包含扰动生成器,用于根据函数和LLM提示生成扰动文本。
- 包含LLM日志生成器,记录原始和扰动输入文本及其生成的输出。
- 输出包含输入ID、文本、扰动ID和相应输出。
- 评估模块(Evaluation Module):
- 使用从MRTs生成的MRs验证执行结果。
- 使用二值结果表示评估结果:1表示MR满足,0表示不满足。
- 每个原始输入应用10种扰动,每种扰动产生一列结果。
框架的优势:
- 支持从多种来源获取的输入数据,无需标注,减少分析成本。
- 提供基于API的动态LLM评估功能,适用于不同LLMs。
- 提供了详细的手册和框架说明,托管在GitHub上供进一步研究。
具体实现与输出:
- 通过Fig. 2的实例,展示了框架结构和示例输出。
- 包括手动和自动的评估示例,支持具体的MR基准测试。
EXPERIMENT
A. Experiment Design
实验目标:
- 在LLMs(Google、OpenAI、Meta)上评估四个关键质量属性(QAs)与六个任务的21种组合。
- 任务包括毒性检测(TD)、情感分析(SA)、新闻分类(NC)、问答(Q&A)、文本摘要(TS)和信息检索(IR)。
MR与扰动设置:
- 总计生成273个变形关系(MRs),其中:
- 240个MR用于稳健性(Robustness)评估,每个任务对应10种扰动(字符级、词句级等)。
- 21个MR用于公平性(Fairness),基于21个人口学分组选项。
- 6个MR用于非确定性(Non-determinism)和效率(Efficiency)评估。
- 任务文本特点:
- 分类和问答任务:通常由1-2个句子组成,难以删除或替换。
- 其他任务:包含10-20个句子,字符级扰动影响有限。
输入数据:
- 样本总数为900,来源于多种网络资源(如Amazon评论、新闻文章等)。
- 输入文本长度从15到4000字不等。
实验规模:
- 每个LLM约接受42,000次请求,总计处理19,150,000个标记。
- 包括LLM的五次重复执行,详细内容见Section IV-C。
RQ1. Quality evaluation results on LLMs.
目标:
评估LLMs在任务中的质量属性(QAs),包括稳健性(Robustness)、公平性(Fairness)、非确定性(Non-determinism)和效率(Efficiency),并揭示潜在的质量风险。
方法与指标:
- ASR(Attack Success Rate):
- 通过MR不满足的比例评估稳健性,结合文本相似度指标。
- 举例:若10个MR在100次输入中有200次不满足,ASR = 0.2。
- 生成任务中的文本相似性:
- 使用Google的Universal Sentence Encoder(USE)计算Q&A任务的语义相似度(STS)。
- 为文本摘要任务定义A-STS(平均语义相似度),阈值设为0.6。
- IR任务的排名距离:
- 定义最大STS排名距离(MSRD),通过扩展Kendall tau距离计算平均排名差异,阈值为2。
- 非确定性分析:
- 基于多次输入相同文本的输出差异,计算1-STS的平均值。
结果分析:
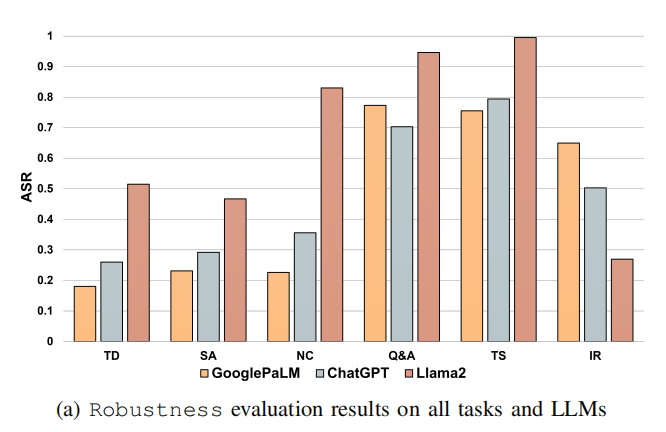
- 稳健性(Robustness):
- 分类任务中LLMs的ASR值较低,生成任务中ASR值较高。
- GooglePaLM和ChatGPT的ASR值接近,而Llama2的ASR值最高(最易受扰动影响)。
- 在文本摘要任务中,Llama2的ASR达0.99,表明大多数扰动导致输出显著不同。
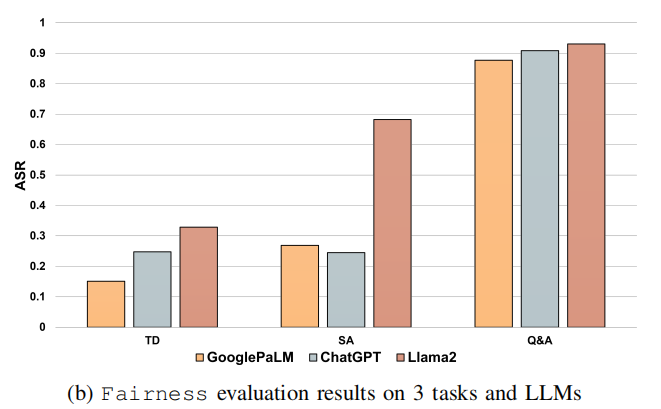
- 公平性(Fairness):
- GooglePaLM在毒性检测任务中ASR最低,而ChatGPT在情感分析中ASR最低。
- 问答任务中,三个模型的输出相似性较高,平均ASR约为0.9。
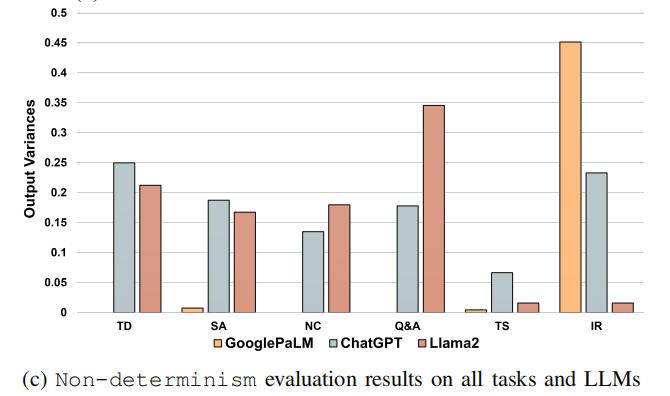
- 非确定性(Non-determinism):
- GooglePaLM的输出差异在所有任务中较小,但在信息检索(IR)任务中例外。
- Llama2的输出波动最大,频繁返回推荐文本或手动提示,解释了其在稳健性和IR任务中的表现。
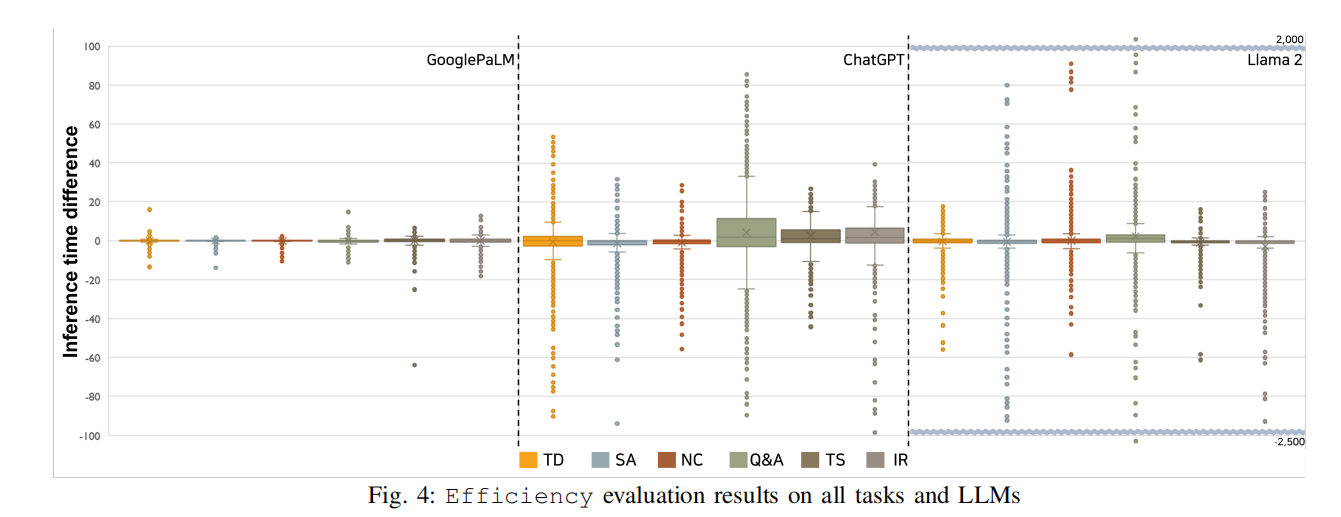
- 效率(Efficiency):
- GooglePaLM表现最稳定,输入扰动对推理时间的影响最小。
- ChatGPT在生成任务中推理时间波动较大。
- Llama2的推理时间差异范围更大,从-2500秒到2000秒不等。
总结:
- GooglePaLM在稳健性和效率上表现出色。
- ChatGPT在公平性和生成任务中较为均衡。
- Llama2在多个质量属性上表现不稳定,尤其在IR和生成任务中易受扰动影响。


RQ2. The effectiveness of MRs.
目标:
评估和优化每个任务中变形关系(MR)的有效性,衡量MR在评估LLMs稳健性(Robustness)中的表现,并确定每个任务的最优MR。
方法与指标:
- EFM(Effectiveness of MRs)公式:
- 定义为: EFM=M-ASR×PerturbQualityEFM = M\text{-}ASR \times PerturbQualityEFM=M-ASR×PerturbQuality
- M-ASR:MR的不满足率(即ASR),表示模型对扰动的脆弱性。
- PerturbQuality:通过A-STS度量扰动文本的语义质量,确保扰动在保留上下文一致性的同时具有攻击性。
- 结合两者,EFM反映了MR在保证扰动质量的前提下对LLMs有效性的综合指标。
- PerturbQuality计算(算法1):
- 通过比较原始和扰动文本的上下文相似度(ContextSim),计算文本的语义质量。
- 阈值设定为0.98,高于此值则视为未扰动。
- 若被扰动,则考虑句子的语义相似度和长度比例。
- Shapley Value分析:
- 用于确定每个MR在组合中的边际贡献。
- 通过多个MR组合的EFM差异,计算单个MR的贡献值。
实验结果:
- MR有效性分析(EFM):
- 高效的MR类型因任务而异:
- 毒性检测(TD)、新闻分类(NC)、文本摘要(TS):字符级扰动(如ConvertToL33tFormat)最有效。
- 情感分析(SA):字符级扰动(ShuffleCharacter和SwapCharacter)最有效。
- 问答(Q&A)和信息检索(IR):词级扰动(ReplaceSynonym和AddRandomWord)更有效。
- 句子级扰动(如ReplaceRandomSentence):在IR任务中表现出高效性。
- 高效的MR类型因任务而异:
- 优化MR分析(RQ2-2):
- 字符级扰动在分类任务中表现最佳。
- 词级扰动在生成任务中更具优势。
- Shapley Value分析揭示,字符和词级扰动在所有任务中的有效性高于句子级扰动。
总结:
- 字符级和词级扰动在稳健性评估中表现出高EFM值,适用于不同任务。
- MR的优化需要根据任务类型(分类任务或生成任务)调整扰动级别。
RQ3. Self and Cross-examination of LLMs.
目标:
验证变形关系(MR)在LLMs的自检(self-examination)和交叉检验(cross-examination)中的有效性,并找出最适合评估特定LLM质量的MR生成方法。
方法:
- 对比不同LLMs目标下的平均MR有效性(EFM),分析各生成方法在不同任务中的表现。
- 使用表格数据(Table V)呈现平均EFM值,结合特定生成方法(如CreatedFunctions、GooglePaLM等)。
结果:
- 对GooglePaLM的分析:
- 除GooglePaLM方法本身外,其他MR生成方法(如CreatedFunctions和ChatGPT)表现出相似的EFM结果。
- GooglePaLM的平均EFM值最低,仅为0.09。
- 对ChatGPT的分析:
- CreatedFunctions方法生成的MR在ChatGPT上表现良好,EFM为0.22。
- ChatGPT方法生成的MR效果更佳,EFM达0.28,是对ChatGPT最有效的MR生成方法。
- 对Llama2的分析:
- GooglePaLM和ChatGPT方法生成的MR表现更优,EFM值分别为0.35和0.30。
- CreatedFunctions方法的EFM值为0.26,相对稍弱。
- 对所有LLMs的总体观察:
- ChatGPT方法在所有目标LLMs中生成了更高效的MR,表现最为稳定和有效。
结论:
- 不同LLMs适合不同的MR生成方法,需根据具体LLM选择最佳方法。
- ChatGPT方法在生成高效MR上表现最为突出,适用于所有目标LLMs,尤其在稳健性(Robustness)评估中效果显著。
C. Threats to Validity
1. 内部有效性(Internal Validity):
- 问题:LLMs可能对上下文具有记忆能力,影响扰动文本和原始文本的独立性。
- 对策:
- 每次请求通过API重新开启新会话,避免上下文污染。
- 随机调整原始和扰动输入的顺序,避免固定顺序对模型输出的影响。
2. 外部有效性(External Validity):
- 问题:实验中涉及的提示词和任务可能无法完全涵盖所有LLMs的真实使用场景。
- 对策:
- 使用现有研究中的提示词工程方法,例如:
- 文本摘要任务的提示:
"Please summarize the given text in 5 sentences"。 - 字符扰动任务的提示:
"Please randomly swap characters a maximum of 3 times in each sentence"。
- 文本摘要任务的提示:
- 实验中使用的提示词已公开,以便未来扩展到更多扰动。
- 使用现有研究中的提示词工程方法,例如:
3. 结论有效性(Conclusion Validity):
- 问题:
- 实验中模型参数和硬件资源的限制可能影响结论的推广性。
- 例如:
- 使用的是7B模型,而非70B模型(后者需要至少30GB GPU内存)。
- GPT-API的收费策略限制了重复实验的次数。
- 对策:
- 在所有LLMs上对每个QA和任务重复5次实验,以确保结果的一致性。
- 每次测试所有输入数据以评估非确定性,执行了20次实验结果(5次重复 × 4种MR生成方法)。
总结:
通过控制上下文污染、使用开放的提示词策略以及合理分配实验资源,最大程度确保实验的内部、外部和结论有效性,同时认识到模型规模和资源限制带来的局限性。
CONCLUSION
1. 框架总结:
- 本研究提出了METAL框架,利用变形测试(MT)技术系统评估LLMs的质量。
- 框架特点:
- 提供了全面的MR模板,用于涵盖LLMs的关键质量属性(QAs)和任务。
- 设计了自动化的MR生成模块。
- 引入了新的指标(如ASR结合语义和结构相似度度量)评估LLMs的输出质量。
2. 实验结果:
- 对3种主流LLMs(GooglePaLM、ChatGPT、Llama2)验证了框架的有效性。
- GooglePaLM在多个任务上的表现优于其他模型。
- 新指标成功指导了MR的优先级,帮助确定每个任务中最有效的MR。
- 验证了LLMs自检和交叉检验的可行性,其中ChatGPT生成的MR效果最佳。
3. 框架价值:
- 对ML工程师:
- 支持使用无标签数据测试LLMs,提高测试效率。
- 揭示LLMs在极端场景下的弱点,帮助改进模型。
- 对行业用户:
- 作为微调LLMs的公开评估平台,适用多个领域。
- 对小企业:
- 帮助解决评估微调模型质量的难题。