
Validating LLM-Generated Programs with Metamorphic Prompt Testing
Validating LLM-Generated Programs with Metamorphic Prompt Testing
Abstract
软件开发领域的最新范式转变,通过大型语言模型(LLMs)带来的创新和自动化,尤其是生成式预训练变换器(GPT),展示了其自主生成代码的卓越能力,显著减少了各种编程任务所需的人工投入。尽管LLM生成代码的潜在好处十分广泛——尤其是在提升效率和快速原型开发方面——但随着LLM越来越多地被集成到软件开发生命周期以及由此产生的供应链中,由此产生的复杂且多方面的挑战浮现出来。这些挑战源于由此类语言模型生成的代码在质量和正确性方面存在的重大疑问。因此,研究需要全面探讨围绕LLM生成代码的这些关键问题。
在本文中,我们提出了一种称为变形提示测试(Metamorphic Prompt Testing)的新方法,以应对这些挑战。我们的直观观察是,在正确代码片段之间总是存在内在的一致性,但在存在缺陷的代码片段之间可能不存在这种一致性,因此通过检测不一致性,我们可以发现代码中的缺陷。为此,我们可以通过改写将一个提示扩展为多个提示,并让LLM生成多个版本的代码,以便通过交叉验证验证生成代码中的语义关系是否依然成立。我们在HumanEval上的评估表明,变形提示测试能够检测出GPT-4生成的75%有误的程序,误报率为8.6%。
INTRODUCTION
Background
LLMs的能力与潜力:
- 大型语言模型(LLMs)可以根据自然语言提示生成代码。
- 示例:GPT-4在HumanEval测试中对164个自然语言提示生成正确代码的比例达到84%。
- 这项能力能够显著减少软件开发中的人工投入。
质量与正确性的问题:
- 生成代码的质量和正确性引发了严重担忧。
- 现有代码库(如GitHub)中可能包含缺陷,这些缺陷会通过模型训练传递到生成代码中。
- 不一致的代码合成可能引入新的漏洞。
LLMs生成代码的局限性:
- LLMs的代码生成过程目前无法完全解释。
- 无法确定其生成的代码是否会带来额外的缺陷。
开发者的挑战:
- 缺乏适当的评估方法使开发者难以放心将LLM生成的代码整合到项目中。
- 如果缺陷代码被整合到项目中,可能会导致系统故障和严重后果。
Existing Work
现有方法的局限性:
- 当前用于验证模型和代码质量的技术(如HumanEval、EvalPlus)依赖预定义的规范解决方案(ground truth programs),只能用于评估LLM的生成能力,而非实际场景中LLM生成代码的有效性。
- 现实中并不存在规范解决方案,因此上述方法在实际应用中不适用。
人类审核的挑战:
- 在其他AI领域,人类通常用于双重检查AI生成的内容,但代码生成领域情况特殊:
- 源代码本身难以理解。
- 开发者理解和修复AI生成代码的成本往往高于自行编写代码。
静态代码分析工具的作用:
- 工具如SpotBugs和SonarQube能够基于模式识别检测已知缺陷(如错误使用hashcode函数、SQL拼接漏洞)。
- 这些工具仅关注通用软件缺陷,无法检测LLM生成代码的特定任务语义一致性。
自动化测试方法的不足:
- 自动化测试(如模糊测试、基于搜索的测试)可以生成大量输入,测试运行时错误(如死循环和崩溃),但缺乏测试断言(test oracle),无法检测逻辑或语义错误。
- 评估显示GPT-4生成代码很少触发运行时错误,更多的是断言错误(程序运行成功但输出错误)。
总结:
- 当前技术在评估和验证LLM生成代码的质量方面存在重大不足。
- 主要挑战在于缺乏适合实际应用的测试方法和评估工具。
Approach
研究背景与问题:
- 验证LLM生成代码的质量面临挑战,尤其是缺乏规范解决方案或可靠的测试输出。
- 现有方法(如变形测试)利用已知输入与输出之间的关系检查一致性,但难以为任意程序找到适用的变形关系。
变形提示测试(Metamorphic Prompt Testing)概述:
- 该方法提出了一种基于提示的变形测试新技术。
- 核心关系:具有相同语义的提示应生成语义一致的程序。
变形提示测试的步骤:
- 步骤1:基于NLP技术对原始提示进行改写,生成多个变体提示(paraphrase prompts)。
- 步骤2:将原始提示输入LLM生成目标程序(target program)。
- 步骤3:将所有变体提示输入LLM生成一组变体程序(paraphrase programs)。
- 步骤4:利用自动测试生成技术创建随机输入,分别输入目标程序和变体程序,检查其输出是否一致。
- 输出无需完全一致,算法会处理由改写和生成过程引入的噪声。
方法的意义:
- 变形提示测试提供了一种有效的新途径,在没有明确测试断言的情况下验证LLM生成代码的语义一致性。
Evaluation
实验结果:
- 在HumanEval基准上评估变形提示测试(Metamorphic Prompt Testing)。
- 方法能够检测出GPT-4生成的24个有误程序中的平均75%(保守配置下可达83%),误报率为8.6%。
- 开发者仅需检查30个LLM生成的程序即可识别其中18个错误程序(包含12个误报),漏掉的错误程序仅为6个。
- 将该方法作为GPT-4的后处理步骤,可将程序准确率从85.4%提升至89.0%。
论文贡献:
- 提出了无需规范解决方案或测试输出的新方法,用于验证LLM生成程序的质量。
- 开发了一种基于提示改写的冲突输出检测算法,用于报告错误。
- 在HumanEval基准上对所提方法进行了实验验证并报告了结果。
HumanEval数据集
Background
2.1 AI-based Code Generation
AI生成代码的概述:
背景:AI生成代码是支持软件开发的最新进展,具有改变编程任务处理方式的潜力。
发展历程:
- 从API方法建议和代码补全开始(基于传统机器学习模型和深度神经网络)。
- 最近通过训练大型代码模型(LLMs)和使用大量代码数据进一步发展。
核心能力:能够理解从简单命令到复杂问题描述的广泛自然语言输入,并生成语法正确、逻辑可靠的代码。
AI生成代码的优势:
提高效率:加速编码过程,减少人工错误。
可访问性:帮助有限编码经验的用户开发解决方案,同时支持教育用途。
协助开发者:为有经验的开发者提供优化建议和调试协助,如代码自动化的助手。
AI生成代码的局限性:
依赖输入质量和训练数据:低质量输入或训练数据会导致错误输出。
错误的不确定性:开发者难以判断输出代码是否有误,且程序错误可能导致严重后果。
主要障碍:这种不确定性阻碍了开发者对AI生成代码的信任和使用。
研究目的:
- 本文旨在探索一种潜在的解决方案,解决AI生成代码中的质量验证和错误判断问题。
2.2 Metamorphic Testing
1. 变形测试的概念:
- 目标:软件测试的关键阶段,确保软件的可靠性与正确性。
- 传统方法的局限性:依赖测试断言(test oracles),在复杂系统(如机器学习模型、科学计算、数据分析应用)中,确定预期输出通常非常困难甚至不可能。
- 变形测试的特点:
- 利用输入和输出之间的变形关系(metamorphic relations),而非直接寻找输出的正确值。
- 重点是当输入在受控情况下变化时,输出应如何变化。
2. 变形测试的流程:
- 识别变形关系:确定定义输入变化如何影响输出的规则,基于应用逻辑。
- 生成测试用例:根据变形关系修改原始输入,生成多个测试用例。
- 验证输出变化:运行原始和修改后的输入,比较输出是否符合变形关系,而非验证输出的绝对正确性。
3. 应用范围:
- 变形测试能够处理未知输出,已被用于测试非确定性输出的AI模型。
- 示例:在NLP模型测试中,用于检测潜在的偏差。
4. 限制与改进:
- 限制:变形测试依赖变形关系的识别,这需要大量人工干预,难以直接应用于任意LLM生成代码。
- 改进:本文将变形测试提升至提示层级,解决这一问题。
Approach
Overview
- 输入:
- 该方法仅以提示(prompt)作为输入,不需要额外信息。
- 核心步骤:
- 提示改写:
- 将原始提示输入到提示改写组件,生成一组改写提示(paraphrase prompts)。
- 代码生成:
- 原始提示输入到LLM,生成目标程序(target program)。
- 改写提示也输入到LLM,生成改写程序(paraphrase programs)。
- 自动测试生成:
- 对目标程序应用自动测试生成工具,创建一组测试输入(无需测试断言)。
- 交叉验证:
- 将目标程序、改写程序及测试输入结合,进行交叉验证以判断目标程序是否有误。
- 提示改写:
- 主要组件:
- 提示改写。
- 自动测试生成。
- 交叉验证。
- (LLM在此方法中被视为黑盒)。
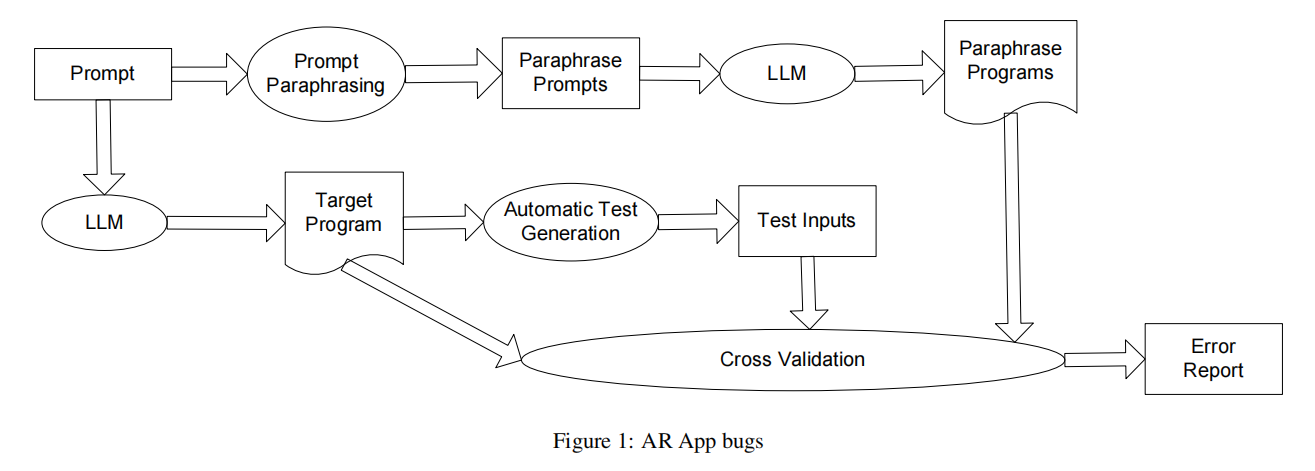
3.1 Generation of Paraphrase Programs
1. 原始提示的结构:
每个原始提示包括以下部分:
- 导入语句:声明所需的Python库类型。
- 函数签名:描述要实现的函数的输入和输出类型。
- 功能描述:自然语言描述函数的语义。
- 示例:提供一些输入和对应的输出示例。
2. 生成改写提示的关键要求:
- 为确保所有改写程序能使用相同的测试输入:
- 保持函数签名和示例部分不变。
- 仅改写描述部分(功能描述)。
3. 改写提示的过程:
- 使用相同的LLM改写描述部分:
- 在描述前添加提示语,例如“Can you paraphrase the following paragraph?”。
- 将生成的改写描述替换原始描述,形成新的改写提示。
4. 生成改写程序:
- 将原始提示和改写提示分别输入LLM,生成目标程序和改写程序。
- 为确保生成的是代码实现而非测试或注释,在提示中添加语句,例如“Can you generate python code for the following function?”。
5. 目的:
通过改写提示部分生成多种改写程序,便于后续验证LLM生成代码的一致性和质量。
此方法确保改写仅影响功能描述部分,而不会改变函数逻辑和语义。

3.2 Automatic Test Generation
1. 目标:
- 为验证目标程序,需要创建测试用例。
- 测试用例应覆盖目标程序的多数路径,实现高代码覆盖率。
2. 方法:
- 自动化测试工具的选择:
- 使用Python-AFL(基于AFL的Python版本),一种先进的覆盖引导模糊测试工具。
- 模糊测试过程:
- 随机输入数据用于发现程序中的错误或漏洞。
- 覆盖引导的模糊测试通过反馈程序执行的信息(代码覆盖率)来生成新的测试输入。
- 增强测试范围,探索程序中未覆盖的区域。
3. 实现:
- Python-AFL的优势:
- 性能强大,生成测试输入速度快。
- 利用测试反馈信息生成有效的测试用例。
- 限制生成的测试输入数量为20,以保证与HumanEval原始测试集规模一致。
4. 方法改进性:
- 方法具有可扩展性,可结合更先进的测试生成工具进一步优化。
总结:
通过使用覆盖引导模糊测试工具,该方法有效生成高覆盖率的测试用例,为验证LLM生成代码提供了全面测试支持。
3.3 The Cross Validation Algorithm
1. 目标:
- 通过交叉验证算法验证目标程序和改写程序的输出一致性,从而判断目标程序是否存在错误。
2. 最保守策略:
- 任何改写程序的输出与目标程序的输出不同即报告错误。
- 局限性:严格一致性可能受到改写生成过程中的噪声影响(如改写引入语义偏差)。
3. 平衡策略(改进算法):
- 基本思路:
- 仅在大多数改写程序的输出与目标程序输出不一致时报告错误。
- 输入:
- 目标程序(Target)。
- 改写程序集合(Paraprog)。
- 测试输入集合(Tests)。
- 执行流程:
- 对每个测试输入,分别运行目标程序和所有改写程序。
- 比较改写程序的输出与目标程序的输出。
- 如果发现不同,将对应的改写程序加入差异集合(DiffSet)。
- 检查差异集合的大小是否超过改写程序总数的一半。
- 若超过,则返回“目标程序有误”;否则返回“目标程序正确”。

Experiments
4.1 Research Questions
在我们的评估中,我们尝试回答以下研究问题:
- RQ1:我们的方法在检测LLM生成的错误代码方面的效果如何?
- RQ2:与其变体相比,我们的方法在检测LLM生成的错误代码方面表现如何(消融研究)?
- RQ3:我们的方法正确和错误检测出的LLM生成错误代码分别具有哪些特征?
4.2 Evaluation Metrics
1. 评估指标:
为了衡量方法的有效性,采用以下常用指标:
- 准确率(Accuracy):衡量方法整体性能。
- 召回率(Recall):衡量方法发现错误LLM生成程序的能力。
- 误报率(False Positive Rate):衡量方法发出错误警报的可能性。
- 精确率(Precision):衡量方法警报的准确性。
2. 术语定义:
- True Positives (TP):
- 实际为错误的LLM生成程序且被正确检测为错误。
- False Positives (FP):
- 实际为正确的LLM生成程序但被错误标记为错误。
- True Negatives (TN):
- 实际为正确的LLM生成程序且被正确标记为正确。
- False Negatives (FN):
- 实际为错误的LLM生成程序但被错误标记为正确。
3. 公式:
- Accuracy:(TP+TN)/(TP+FP+TN+FN)
- Precision:TP/(TP+FP)
- Recall:TP/(TP+FN)
- False Positive Rate:FP/(FP+TN)
4. 指标解释:
- Accuracy:衡量方法整体的正确性。
- Recall:反映方法检测到错误程序的能力。
- Precision/False Positive Rate:反映方法误报的可能性,误报会浪费开发者时间和精力。
4.3 Evaluation Setup
数据集:
- 使用广泛采用的HumanEval数据集(Chen et al., 2021)。
- 数据集包含164组人类编写的提示和对应的规范解法(canonical solutions)作为标准答案。
- 提供每个提示的测试用例,用于验证LLM生成程序的正确性。
使用方式:
- 规范解法和测试用例仅用于评估方法的效果,不用于方法本身的实现。
LLM模型:
- 使用OpenAI提供的gpt-4-1106-preview模型。
- 选择GPT-4作为评估模型,因为其是代码生成领域的最先进模型,且使用了其最新版本。
4.4 Experiment Results
1. 针对RQ1的实验结果:
- 最佳配置:
- 使用5个提示时,方法平均能检测出75%的错误程序(保守配置下可达83%),误报率为8.6%。
- 开发者需检查30个程序以找到18个真正的错误程序(漏报6个,误报12个)。
- 不同提示数量的影响:
- 使用3个提示:召回率和误报率较低,提示数量少限制了生成多样化改写程序的能力。
- 使用7个提示:与5个提示的召回率相同,但误报率更高,因为更多提示可能引入噪声(如生成的改写并非真实改写)。
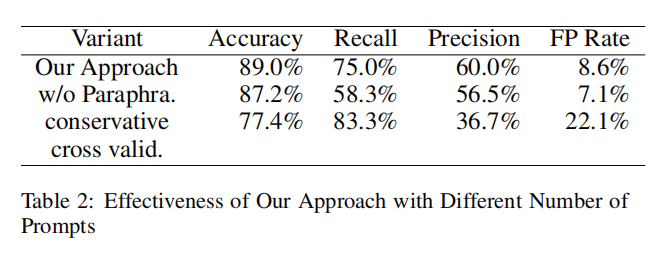
2. 针对RQ2的消融研究结果:
- 消融实验变量:
- 不使用提示改写:将相同提示多次输入LLM,生成的程序与目标程序相似,减少了误报,但召回率显著降低。
- 使用保守的交叉验证:当任一改写程序输出与目标程序不同时即报告错误,召回率提高,但精确率下降。
- 观察结果:
- 不使用提示改写:
- 更少误报,但因缺乏提示多样性,召回率较低,无法有效检测错误程序。
- 保守交叉验证:
- 召回率更高,但精确率较低(36.7%),开发者平均需审查2个误报才能发现1个真正错误程序。
- 误报率22.1%,尽管高于默认方法,但仍能筛除78%的无误程序。
- 不使用提示改写:
3. 结论:
- 默认配置在召回率、精确率和误报率之间达到了良好的平衡。
- 不同配置在特定场景下具有应用价值,例如保守交叉验证在关键任务中可以帮助发现更多错误。
4.5 Qualitative Analysis
1. 针对RQ3的定性分析结果:
(1) 假阴性(False Negatives)的原因:
- 高相似性改写:
- 改写提示之间高度相似,导致生成的改写程序也相似。
- 这些相似程序共享相同的错误语义,无法通过交叉验证检测出错误。
- 案例示例:
- 示例中列出的三条改写提示在语义上几乎没有差异,未能提供足够多样的改写程序。

(2) 假阳性(False Positives)的原因:
- 改写聚类效应:
- 改写提示之间的高相似性导致改写程序输出一致(即使它们都是错误的)。
- 因错误代码占大多数,导致方法将其误报为目标程序错误。

2. 观察与改进建议:
- 关键观察:
- 改写提示的相似性在方法的有效性中起重要作用。
- 高相似性改写提示降低了方法检测错误的能力,同时可能增加误报风险。
- 改进方向:
- 测量相似性:可以通过测量改写提示的相似性,判断方法是否适用于特定场景。
- 增加多样性:尝试生成更具多样性的改写提示,以提高方法的鲁棒性和检测能力。
总结:
改写提示的多样性是改进方法有效性的重要因素,未来工作可以关注改写提示生成的优化,以进一步提升检测性能。
4.6 Threats to Validity
1. 构建效度威胁:
- 问题:实验设置是否与实际应用一致。
- 解决:
- 方法仅以提示为输入,实验设置也完全遵循这一点,确保一致性。
2. 内部效度威胁:
- 问题:实现过程中的潜在错误或脚本中的漏洞可能影响实验结果。
- 解决:
- 仔细检查所有代码和脚本,确保无错误。
- 多次运行实验以验证结果的一致性。
3. 外部效度威胁:
- 问题:评估仅基于GPT-4和HumanEval数据集(164个Python代码生成提示),可能无法推广到其他LLMs、数据集或编程语言。
- 解决:
- 使用最先进的GPT-4模型和广泛采用的HumanEval基准。
- 计划未来扩展到更多LLMs和其他编程语言的数据集进行评估。
5 Future work
未来工作方向:
- 扩展实验范围:
- 在更多基准测试(不同编程语言)和更多LLMs(超越GPT-4)上进行实验。
- 研究方法的通用性和适用性。
- 优化改写提示:
- 研究改写提示的相似性如何影响方法的有效性。
- 开发新技术来扩大改写提示之间的差异,以减少假阳性和假阴性。
- 探索如何根据改写提示的相似性预测方法是否适用。
- 探索更多变形关系:
- 除提示改写外,研究其他变形关系,例如“否定关系”。
- 扩展用于验证LLM生成代码的提示集合。
- 反馈与模型优化:
- 将错误检测结果反馈到LLM或代码生成模型中。
- 使用检测结果微调基于LLM的代码生成模型。