
Vision: Identifying Affected Library Versions for Open Source Software Vulnerabilities
Vision: Identifying Affected Library Versions for Open Source Software Vulnerabilities
ABSTRACT
漏洞报告在减少开源软件风险中起着至关重要的作用。通常,漏洞报告包含受影响的软件版本。然而,尽管安全专家已经验证了漏洞并且厂商也进行了审查,但受影响的版本并不总是准确的。特别是在处理多个版本及其差异时,保持版本的准确性变得更加复杂。虽然已经有一些方法用来识别受影响的版本,但它们仍然面临一些限制。首先,某些现有的方法是基于代码托管平台(如 GitHub)来识别受影响的版本,但这些版本与包注册表中的版本(如 Maven)并不总是保持一致。其次,现有的方法未能区分多个方法和变更块中漏洞方法与修补语句的重要性。
为了解决这些问题,本文提出了一种新的方法——Vision,旨在准确识别漏洞的受影响库版本(ALVs)。Vision使用来自包注册表的库版本作为输入。为了区分漏洞方法和修补语句的重要性,Vision通过关键方法选择和关键语句选择来优先考虑重要的变更及其上下文。此外,漏洞签名通过加权的跨过程程序依赖图(IPDG)来表示,这些图结合了关键方法和语句。Vision根据这些加权图之间的相似性来确定受影响的库版本。我们的评估表明,Vision优于现有的方法,精度达到 0.91,召回率为 0.94。此外,评估还显示了Vision在修正现有漏洞数据库中的受影响版本方面的实际有效性。
NTRODUCTION
Background
- 开源软件的重要性:
- 开源软件(OsS)促进了创新的分享。
- 开源软件加速了软件开发。
- 开源软件已成为现代行业的关键基础设施。
- 开源软件带来的风险:
- 开源软件存在安全风险。
- 开源软件中的漏洞可以被攻击者利用来发起攻击,降低下游软件的安全性。
- 开源软件漏洞问题:
- 根据Sonatype的一项研究,大约有12.5%的开源软件下载中含有已知漏洞。
- 检测开源软件中的漏洞对于确保软件安全至关重要。
- 开源软件漏洞数据库:
- 存在开源软件漏洞数据库,这些数据库包含由安全专家提供的漏洞报告。
- 这些数据库帮助下游客户确定他们的应用程序是否受到漏洞的影响,通过匹配数据库中的漏洞版本与应用程序中使用的版本。
Problem
- 问题概述:
- 手动编译的漏洞报告存在不准确性的问题。
- 不准确性的具体领域:
- 受影响版本字段(指示漏洞的脆弱版本和安全版本)特别容易出现不准确。
- 原因分析:
- 安全专家能够积极识别和确认漏洞。
- 但跨多个版本进行检查既耗时又费力,不符合他们的主要目标。
- 影响:
- 这些不准确性对漏洞报告的消费者(如OSS漏洞管理应用程序)产生显著影响。
Existing Approaches.
关于识别受影响库版本(ALV)的现有方法:
- Dong等人[14]的研究提出了使用命名实体识别技术从漏洞描述中提取ALV的方法,但这种方法受限于漏洞描述的质量。
- Dai等人[13]利用跟踪指导的模糊测试(trace-guided fuzzing)来检测和验证ALV,虽然这种方法能提供令人信服的验证,但计算密集且耗时。
- Shi等人[48]通过污点分析(taint analysis)来识别ALV,但这种方法需要手动筛选危险函数,因此仅适用于某些类型的漏洞。
- 研究人员正越来越多地关注通过匹配漏洞补丁或脆弱克隆来静态分析源代码的方法。特别是,基于补丁的方法[2, 27, 38, 55]通过追踪版本历史中的代码变化来识别ALV;而基于克隆的方法[31, 65-67, 70]则从漏洞中修改的方法生成基于克隆的指纹,如果ALV中存在匹配的指纹,则报告ALV。
[55] VERJava: Vulnerable Version Identification for Java OSS with a Two-Stage Analysis.
[31] Vuddy [66] Movery [70]MVP
[65] V1SCAN: Discovering 1-day Vulnerabilities in Reused C/C++ Open-source Software Components Using Code Classification Techniques
[67] V0Finder: Discovering the Correct Origin of Publicly Reported Software Vulnerabilities.
Limitations
- 现有方法的局限性:
- 现有方法在识别仓库托管平台(如GitHub)上的库版本时存在问题。
- 具体问题:
- (a) 忽略平台间库版本差异:
- 现有方法未能考虑仓库托管平台与包注册表(如Maven仓库)之间库版本的差异。
- 导致包注册表中库版本的漏检。
- 由于大量下游消费者从这些注册表中获取库,因此对漏洞检测工具的有效性产生显著影响。
- (b) 基于补丁的方法的局限性:
- 依赖于补丁中的变化类型(添加或删除的行),当补丁不包含删除的行时无法报告受影响库版本(ALVs)。
- 不包含漏洞的上下文(依赖和被依赖的语句),容易导致误报。
- (c) 基于克隆的方法的局限性:
- 通过结合程序切片添加了漏洞上下文。
- 但对所有修复方法(用于修补漏洞的方法)赋予相同的重要性。
- 不区分修复方法的重要性,也不对修复方法内变化的语句分配不同的优先级。
- (a) 忽略平台间库版本差异:
Our Approach.
- 新方法提出:
- 我们提出了一种名为Vision的新方法,用于识别开源软件(OSS)漏洞的受影响库版本。
- 分析来源:
- Vision从包注册表(如Maven)分析库版本,克服现有方法的局限性。 (a)
- Maven仓库的重要性:
- Maven仓库是Maven包管理器的默认仓库,提供全面的库版本列表。
- 核心见解:
- Vision认为不同的方法或语句包含关于漏洞的不等量的语义知识。
- 签名生成:
- Vision为每个漏洞生成漏洞签名和补丁签名。
- 使用删除的行生成漏洞库版本的漏洞签名和候选库版本的漏洞潜力签名。
- 使用添加的行生成修补库版本的补丁签名和候选库版本的补丁潜力签名。
- 加权IPDGs:
- Vision生成加权的程序间程序依赖图(IPDGs),将方法和语句的关键性编码到图表示中。
- 版本检测:
- Vision通过比较IPDGs之间的相似性来检测受影响的库版本。
- 比较候选库版本与漏洞代码的相似性,同时确保其与修补代码的不相似性。
- 处理无删除行情况:
- Vision能在无删除行的情况下利用原始上下文生成漏洞签名,解决现有方法的局限性。 (b)
- 克服另一局限性:
- Vision采用Hyperlink-Induced Topic Search算法(HITS)在方法引用图(MRGs)上选择关键方法,克服另一局限性。 (c)
- 关键语句和路径识别:
- Vision通过从补丁中识别关键变量,在加权的IPDGs中高亮显示关键语句和路径。
Evaluation
- 评估方法:
- 我们通过对比Vision与两种最先进的基于补丁的方法和三种高级的基于克隆的方法,在涉及79个库和12,073个版本对的102个CVE上评估了其有效性。
- 评估结果:
- Vision的精确度为0.91,召回率为0.94,分别比最先进的方法高出至少12.3%和154.1%。
- 错误报告:
- 在重叠库版本中,Vision报告了357个假正例和184个假反例;在完整的真实数据中,报告了418个假正例和258个假反例。
- 相比之下,基于补丁的方法在重叠库版本中平均报告了1,031个假正例和1,654个假反例,在完整的真实数据中平均报告了1,720个假正例和2,961个假反例。
- 基于克隆的方法在完整的真实数据中平均报告了286个假正例和3,826个假反例。
- 消融研究和阈值敏感性分析:
- 这些分析证实了Vision中各组件对其整体有效性的贡献。
- 泛化能力:
- 我们将Vision应用于V-SZZ和VerJava的原始数据集,并取得了可比的有效性(精确度为0.90,召回率为0.92),证明了其泛化能力。
- 实际应用:
- 我们使用Vision分析了五个漏洞数据库中标记有错误受影响库版本的漏洞,并向五个供应商报告了这些漏洞。
- 三个供应商已回复并分别修复了39、42和8个漏洞,证明了Vision的实际实用性。
Contributions:
- 提出Vision方法:我们提出了Vision方法,用于识别开源软件(OSS)漏洞中受影响的库版本。该方法接受来自Maven的库版本,并将漏洞中方法和语句的关键性编码为加权IPDGs,以实现准确识别。
- 实验验证:通过实验,我们证明了Vision方法的有效性和实用性。在精确度和召回率方面,Vision方法分别比最先进的方法高出至少12.3%和154.1%。
MOTIVATION
2.1 Inaccurate Affected Library Versions in Vulnerability Databases
这段话讨论了漏洞数据库中“不准确的受影响库版本”(Inaccurate Affected Library Versions,ALVs)问题。具体来说,这些数据库中的受影响库版本信息可能包含错误的版本或缺失的版本。这一问题已被广泛认知,并且依然是一个重要的挑战。文中通过一个实例(Armeria和CVE-2021-43795)来说明这一点,展示了不同漏洞数据库在报告受影响库版本时的差异。通过对源代码的手动检查,得出了“真实”版本信息,其中只有两个数据库提供了正确的受影响版本范围。此种差异强调了仅依赖漏洞数据库来获得准确的受影响库版本的困难。
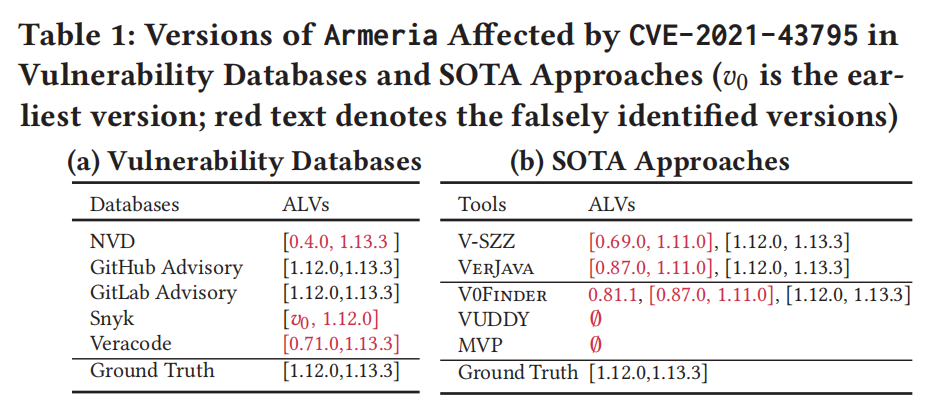
2.2 Limitations of Existing Works
Library Versions from Repository-Hosting Platforms.
问题概述:
存储库托管平台(如Maven和GitHub)上的库版本存在差异。
例如,
spring-boot-actuator-logview 和 spring-integration-zip
两个库在Maven和GitHub上的版本数量不同,且版本没有重叠:
- spring-boot-actuator-logview:
- Maven 上发布了 15 个版本,GitHub 上仅有 7 个版本。
- spring-integration-zip:
- Maven 上发布了 21 个版本,GitHub 上发布了 47 个版本。
- 两者的版本重叠为零。
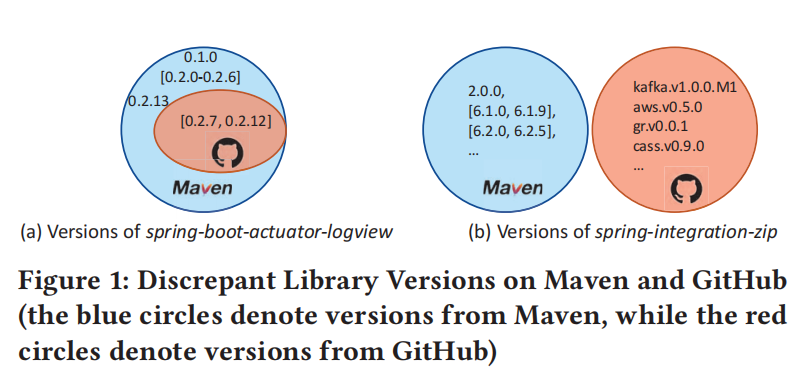
- spring-boot-actuator-logview:
实证分析:
- 研究者选择了539个Maven库,并找到了对应的434个GitHub仓库,分析了1,083个与Java库相关的CVE。
- 重点分析了 Maven 和 GitHub 上的库版本,并进行了版本对比。
版本差异的发现:
- 版本差异情况:
- 94.8% 的 Maven 库和 93.8% 的 GitHub 仓库存在版本差异。
- 这些版本差异占所有版本的 **28.0%**(15,341/54,713)。
- 差异的持续性:
- 特别是在过去三年(2021年7月至2024年7月)发布的版本中,差异仍然普遍存在。
- 在新版本中,87.4% 的 Maven 库和 86.4% 的 GitHub 仓库存在版本差异。
- 版本差异情况:
结论:
- 该研究揭示了在不同的存储库托管平台和包注册中心之间,库版本的差异性依然是一个普遍且持续存在的问题,影响了准确获取版本信息的难度。
Equal Importance to Changed Methods.
这段话主要比较了两种基于补丁的方法(V-SZZ 和 VER-Java)与三种基于克隆的方法(VOFINDER、Vuppy 和 MVP)在识别受影响库版本(ALVs)时的效果,并探讨了它们的不同表现及其原因。
关键点总结:
- 实验设置:
- 比较了两种补丁方法(V-SZZ 和 VER-Java)与三种克隆方法(VOFINDER、Vuppy 和 MVP),所有方法使用相同的漏洞数据(来自 2.1 节)。 (只有一个CVE-2021-43796)
- 对补丁方法,库版本信息来自 GitHub 仓库;对克隆方法,库版本信息来自 Maven。
- 结果比较:
- 补丁方法:
- V-SZZ:报告 49 个受影响版本
- VER-Java:报告 68 个受影响版本
- 克隆方法:
- VOFINDER:报告 69 个受影响版本
- Vuppy 和 MVP 没有报告任何受影响版本。
- 其中,错误标识的库版本被标记为红色。
- 补丁方法:
- 根本原因分析:
- 漏洞根源存在于 Armeria 的 commit a38@cf,并在 commit e2697a 中修复。
- 在 commit e2697a 中有多个方法发生了变化,但如果所有变化的方法都被同等对待,检测工具可能会错误地追溯到早期的提交,从而导致错误的版本标识。
- 例如,V-SZZ 错误地将
appendHexNibble()方法中的删除语句标记为漏洞,并追溯到 commit bf1ee5,导致版本 0.69.0 到 1.12.0 被错误标记为受影响版本。 - VER-Java 和 VOFINDER 也因为将不重要的方法错误地标识为漏洞而报告了错误的版本。
- Vuppy 和 MVP 没有报告任何受影响版本,因为它们未能识别出任何方法。
- 例如,V-SZZ 错误地将
- 重要结论:
- 强调了在检测受影响版本时,需要关注重要的、关键的方法。实验结果表明,选择关键方法对于避免错误标识至关重要。

[43] NVD. 2024. CVE-2021-43795. Retrieved May 25, 2024 from https://github.com/line/armeria/pull/3855/files/a380cf982f665459b79909555b5d4b024d7daf1a
[44] NVD. 2024. CVE-2021-43795. Retrieved May 25, 2024 from https://github.com/line/armeria/commit/e2697a575e9df6692b423e02d731f293c1313284z
Equal Importance to Changed Statements
CVE-2022-22976 漏洞修复中的方法修改,特别是 spring-security 项目中的 crypt_raw 方法的补丁。具体概括如下:
背景介绍:
- 漏洞修复涉及 spring-security 中的
crypt_raw方法。通过对该方法进行修改,修复了 CVE-2022-22976 漏洞。 - 在该方法的修复补丁中,修改的部分被明确标出,帮助理解漏洞的根本原因以及修复方法。
- 漏洞修复涉及 spring-security 中的
补丁分析:
- 补丁的具体内容通过图3呈现,其中包括:
- (a) 表示
crypt_raw方法修改前 的代码。 - (b) 表示 **
crypt_raw方法修改后的代码。 - 红色背景 表示删除的代码行,绿色背景 表示新增的代码行。
- (a) 表示
图3展示了在 commit a40f735 中对
crypt_raw方法进行的具体修改。通过标记删除和添加的代码行,可以看到方法中的逻辑和结构发生了调整,这有助于修复漏洞。- 补丁的具体内容通过图3呈现,其中包括:
方法修复过程:
- 修复过程中,重要的代码行进行了修改,以避免漏洞被利用。通过图3中对比修改前后的代码,可以看到在安全性方面的增强。
- 例如,修改了代码中的一些逻辑判断和加密相关的操作,确保在运行时不会导致潜在的安全漏洞。
总结:
- 图3帮助理解了如何通过补丁修复漏洞,强调了代码修改的细节,包括哪些部分被删除(红色背景)以及哪些部分被新增(绿色背景)。
- 这种修复方式不仅改进了代码的安全性,还展示了如何通过精确的代码变更来解决漏洞问题。
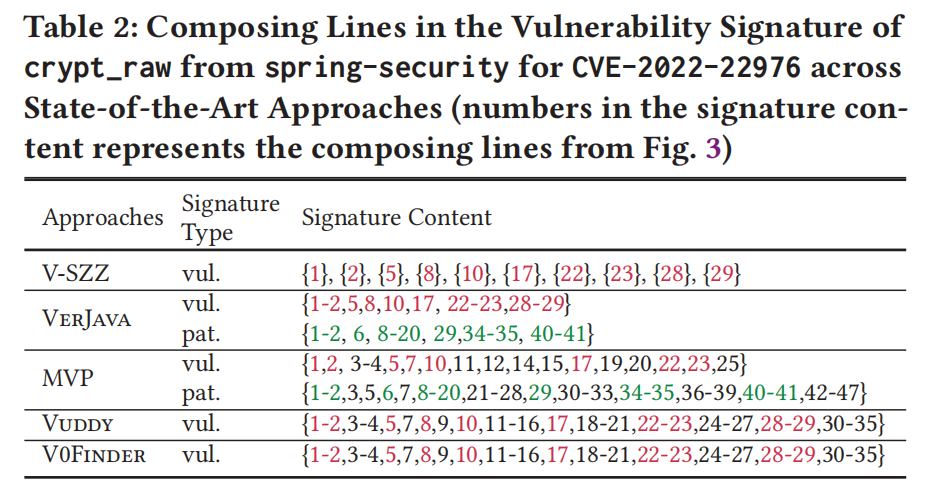
这段话主要探讨了五种不同方法(V-SZZ、VERJAVA、VOFINDER、Vuppy 和 MVP)如何选择代码中的语句,以生成其漏洞签名,并比较了它们在漏洞检测中的表现。以下是详细概括:
- 漏洞签名的类型:
- **Vulnerable signature (“vul.”)**:用于匹配漏洞。
- **Patch signature (“pat.”)**:用于验证漏洞是否已经被修复。
- 表格与图示:
- 使用 图3 中的行号表示生成漏洞签名的元素。
- “vul.” 签名 来自图3(a)(即修复前的方法代码),“pat.” 签名 来自图3(b)(即修复后的方法代码)。
- 不同方法的选择差异:
- V-SZZ、Vuppy 和 VOFINDER:
- 这些方法通过分析 修复前的代码 来生成漏洞签名。
- 具体来说:
- V-SZZ 专注于删除的行。
- Vuppy 和 VOFINDER 则处理修复前的整个方法。
- VERJAVA 和 MVP:
- 这两种方法同时利用 vul. 和 pat. 签名 来检测漏洞并确认是否修复。
- VERJAVA 使用修改过的语句来生成签名。
- MVP 使用程序切片技术,通过识别修改的上下文(例如:在 “pat.” 签名中的第3行、第5行和第7行)来生成签名。
- V-SZZ、Vuppy 和 VOFINDER:
- 漏洞签名的语义对齐:
- 要实现精确的受影响库版本(ALVs)检测,漏洞签名需要与其语义意义对齐。这意味着,签名不仅要标识漏洞代码的变化,还需理解这些变化的上下文,以确保漏洞的准确检测和修复验证。
APPROACH
Vision 方法概述:
- 核心思想:
- Vision 通过区分不同方法和语句的重要性,来生成更精确的漏洞签名。与现有方法将所有方法和语句看作同等重要不同,Vision 根据语句和方法的重要性为它们加权,形成加权的跨过程程序依赖图(IPDGs)。
- 通过比较 IPDG 之间的相似性,Vision 能够有效检测受影响的库版本。
主要模块:
- 漏洞和修复签名生成:
- 给定一个 GitHub 仓库中的漏洞修复提交,首先识别漏洞版本(𝑅𝑃pre)和修复版本(𝑅𝑃pos)。
- 使用漏洞版本(𝑅𝑃pre)生成漏洞签名(𝑆𝑖𝑔vul),使用修复版本(𝑅𝑃pos)生成修复签名(𝑆𝑖𝑔pat)。
- 漏洞描述帮助选择关键方法,进一步生成漏洞签名。
- 漏洞潜力和修复潜力版本签名生成:
- 给定候选库版本,生成漏洞潜力签名(𝑆𝑖𝑔vul )和修复潜力签名(𝑆𝑖𝑔pat )。
- 根据具体漏洞,Vision 精确选择要匹配的特征(如方法和语句)。这种签名定制化的策略,确保漏洞潜力签名与漏洞匹配,修复潜力签名与修复匹配。
- 受影响库版本检测:
- Vision 计算漏洞签名(𝑆𝑖𝑔vul)与候选库版本的漏洞潜力签名(𝑆𝑖𝑔vul )之间的相似性,以及修复签名(𝑆𝑖𝑔pat)与修复潜力签名(𝑆𝑖𝑔pat )之间的相似性。
- 如果候选库版本的漏洞潜力签名与漏洞签名(𝑆𝑖𝑔vul)更相似,则判定该版本受漏洞影响;如果与修复签名(𝑆𝑖𝑔pat)更相似,则认为该版本未受影响。
总结:
Vision 方法通过精细化的签名生成过程和基于语义的相似性比较,能够准确检测受影响的库版本,并区别于传统方法的一视同仁的方式。
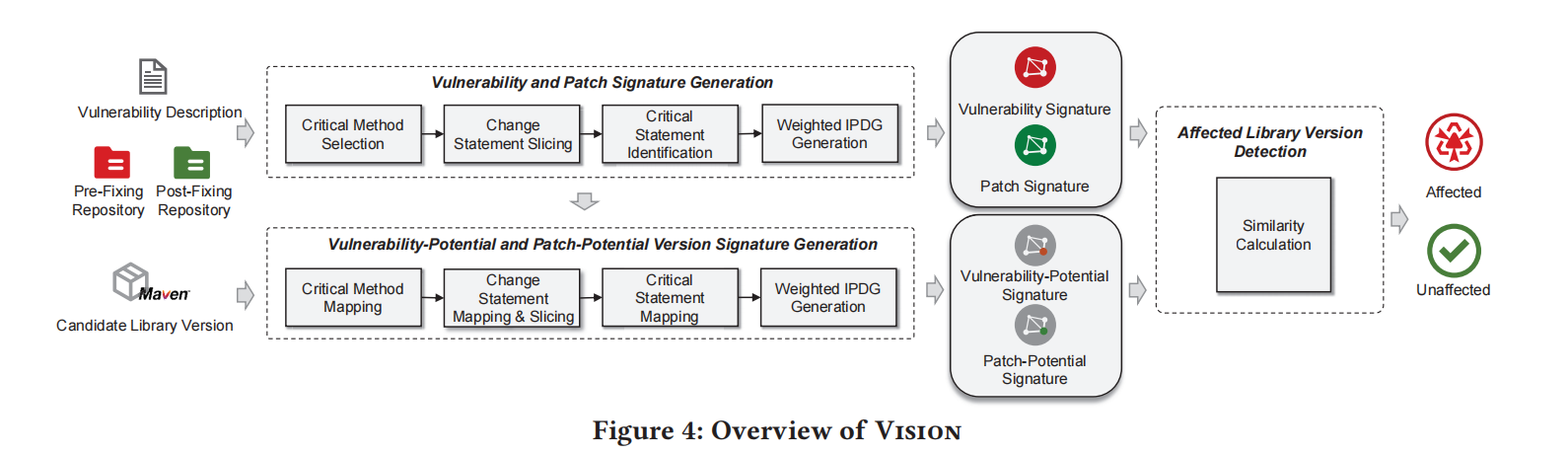
3.1 Vulnerability and Patch Signature Generation
3.1.1 Critical Method Selection
1. 关键方法选择
Vision 通过两步过程来识别 𝑅𝑃pre 和 𝑅𝑃pos 中的关键方法:
- 第一步:生成方法引用图(MRGs)。
- 第二步:在这些图中识别关键方法。
在此过程中,关键方法分为:
- 关键变动方法(𝑀𝑐vul, 𝑀𝑐pat):在漏洞和修复版本中发生变化的关键方法。
- 关键未变方法(𝑀𝑢vul, 𝑀𝑢pat):在漏洞和修复版本中未发生变化的关键方法。
2. 方法引用图(MRGs)生成
- MRGs 用于捕捉与漏洞相关的上下文,结合了 方法调用图 和 漏洞描述中的类/方法名。
- 这有助于更好地理解漏洞,并选择相关的关键方法:
- 构建调用图:使用 Joern 构建程序的调用图,选取与漏洞相关的变动方法及其调用方法。
- 提取漏洞描述中的类和方法:从 CVE 描述和 提交描述 中提取方法和类名,并将其与调用图进行匹配。如果描述中提到的方法是专家引用的,那么在 MRG 中会创建一个 “虚拟方法调用者”,从而建立与方法之间的引用关系。
3. 关键方法选择(基于MRGs)
- 使用 HITS 算法来评估方法的权威性(authority) 和 枢纽性(hub),进而识别关键方法:
- 权威方法 是最终会被恶意触发(或清理器)到达的方法。
- 枢纽方法 是触发(或清理器)方法,通常会被遍历。
- 算法通过迭代计算方法的 权威值 和 枢纽值,直到收敛。
- 如果一个方法的 权威值 和 枢纽值 的总和超过一个预定阈值,则认为该方法为关键方法。
4. 关键方法的调用关系
在识别出关键方法后,Vision 会获取这些方法的调用关系和相应的调用语句,具体为:
- 在𝑅𝑃pre中的调用关系:𝑬𝑐𝑎𝑙𝑙vul 和 𝑆𝑐𝑎𝑙𝑙vul。
- 在𝑅𝑃pos中的调用关系:𝑬𝑐𝑎𝑙𝑙𝑝𝑎𝑡 和 𝑆𝑐𝑎𝑙𝑙𝑝𝑎𝑡。
总结:
通过生成方法引用图并结合 HITS 算法,Vision 能够有效地识别和选择漏洞修复中的关键方法,为进一步的漏洞检测和修复分析提供支持。
我们假设一个简单的漏洞修复场景,其中涉及一个小型的库
LibraryX,该库有两个版本:漏洞版本RPpre和修复版本RPpos。其中的漏洞涉及一个 SQL 注入漏洞,而修复版本通过修改一个方法的实现来修复该漏洞。步骤1:生成方法引用图(MRGs)
构建调用图: 假设在
RPpre(漏洞版本)中,有两个方法:
methodA:这个方法执行了一个数据库查询,但没有对输入进行充分的检查,导致 SQL 注入漏洞。methodB:这个方法调用了methodA。在
RPpos(修复版本)中:
methodA被修复,增加了对用户输入的检查,防止 SQL 注入。methodB仍然存在,并且依然调用了methodA。Vision 使用 Joern 工具生成调用图,并从中选择与漏洞相关的变动方法(
methodA)以及其调用方法(methodB)。这些方法及其调用关系被添加到 MRG 中。提取漏洞描述中的类和方法: 假设漏洞描述中提到
methodA是导致 SQL 注入的关键方法。因此,在生成 MRG 时,除了实际的调用关系,还会从漏洞描述中提取出methodA和相关的类名,并在 MRG 中创建一个 “虚拟方法调用者”,将描述中提到的类和方法添加到图中。在
RPpre中,methodA被视为关键方法,因为它是 SQL 注入的根源。而在RPpos中,methodA被修复,因此它不再是漏洞的一部分。步骤2:使用 HITS 算法选择关键方法
计算权威性和枢纽性: Vision 使用 HITS 算法 来计算每个方法的 权威性(authority) 和 枢纽性(hub):
methodA作为一个受影响的方法,属于 权威方法,因为它是 SQL 注入的目标。methodB作为触发方法,属于 枢纽方法,因为它调用了methodA。HITS 算法会迭代计算每个方法的 权威值 和 枢纽值。具体来说:
- 在第一轮迭代中,
methodB的 枢纽值 可能会影响methodA的 权威值,因为methodB调用了methodA。methodA的 权威值 反过来也会影响methodB的 枢纽值,因为methodB依赖于methodA的执行。迭代过程: 计算的过程会进行多轮迭代,直到所有方法的权威值和枢纽值收敛。最终,
methodA和methodB都会得到权威值和枢纽值,这些值可以帮助我们判断它们是否为关键方法。步骤3:判断关键方法
- 判断关键方法: 如果
methodA的 权威值 和 枢纽值 的总和超过了一个全局阈值(t_thits),则它被认为是 关键方法。在这个例子中,methodA是 SQL 注入漏洞的核心,因而它被认为是关键方法。
- 在
RPpre中,methodA是漏洞的一部分,具有较高的 权威值,因此被标记为 关键变动方法(𝑀𝑐vul)。- 在
RPpos中,methodA已经被修复,其 权威值 降低,因此它不再是关键方法。此时,methodB可能依然是 关键未变方法(𝑀𝑢pat),因为它依赖于methodA。步骤4:提取调用关系
提取调用关系和调用语句
: 在识别出关键方法后,Vision 会进一步提取这些方法的调用关系和相关的调用语句。例如:
- 在
RPpre中,methodA被认为是漏洞的根源,methodB作为触发方法与methodA相关联,因此它们的调用关系和调用语句(Ecall_vul和Scall_vul)会被提取。- 在
RPpos中,修复后的methodA被认为不再是漏洞的一部分,而methodB可能会作为修复后方法的调用者之一被提取(Ecall_pat和Scall_pat)。
3.1.2 Change Statement Slicing
Change Statement Slicing 主要描述了 Vision 方法中如何通过 程序依赖图(PDG) 和 程序切片(program slicing) 技术,来识别和提取与关键变动方法相关的关键语句。
具体过程如下:
- 关键方法选择:首先,Vision 识别出关键变动方法
𝑀𝑐vul和𝑀𝑐pat,分别位于漏洞版本𝑅𝑃pre和修复版本𝑅𝑃pos的 方法引用图(MRG) 中。 - 生成程序依赖图(PDG):Vision 使用工具 Joern 生成 程序依赖图(PDG),该图是一个二元组
𝑆和𝐸,其中:𝑆是图中的语句集合。𝐸是语句间的依赖关系,表示语句之间的控制或数据依赖。
- 程序切片:
- Vision 在 PDG 上执行 前向切片 和 后向切片 操作,目标是提取与变动方法相关的语句。
- 变动语句(改变了的语句)通过数据依赖或控制依赖与其他语句相连,所有与这些变动语句有依赖关系的语句都会被切入到部分 PDG 中。
- 切片结果:最终,Vision 得到一个部分的 PDG,包含所有与关键变动方法相关的语句及其依赖关系。
简而言之,Change Statement Slicing 通过分析关键方法所在的程序依赖图,提取与变动语句相关的语句及其依赖关系,从而帮助确定与漏洞相关的具体代码片段。
3.1.3 Critical Statement Identification
Critical Statement Identification 旨在通过识别关键变量并进行 污染分析(taint analysis),进一步确定与漏洞相关的关键语句。具体步骤包括两个主要部分:关键变量识别 和 污染分析。
- 关键变量识别:
Vision 通过处理代码更改块(change hunks)来识别关键变量,具体分为以下三种情况:
- 新增变量(Added Hunks):当一个块中只包含新增语句时,Vision 识别新增的变量,这些变量通常与漏洞修复相关。通过分析新增语句的子 抽象语法树(AST) 来提取新引入的变量。
- 删除变量(Deleted Hunks):当块中只包含删除的语句时,Vision 识别在旧版本(
𝑅𝑃pre)中存在但在新版本(𝑅𝑃pos)中被移除的变量,这些变量可能与漏洞代码相关。通过分析删除语句的子 AST 来识别这些变量。 - 修改变量(Modified Hunks):当块中既有新增语句也有删除语句时,Vision 识别因代码变动而修改的变量,如方法参数或条件语句的改变。通过对比两个版本中的变量集合,识别出那些有变化的关键变量。
- 污染分析(Taint Analysis):
识别出关键变量后,Vision 进一步应用污染分析,追踪这些变量从方法的入口点到出口点的流动,并确定在流动过程中涉及的关键语句。
- 回溯污染分析(Backward Taint Analysis):从每个关键变量开始,向方法入口点回溯,找到影响关键变量值的语句,并将这些语句标记为关键语句。
- 前向污染分析(Forward Taint Analysis):从关键变量开始,向方法的出口点(如 return、throw、assert 等语句)追踪,分析这些变量如何影响其他语句。
最终,Vision 记录关键语句及其依赖关系,分别表示为:
- 在漏洞版本(
𝑅𝑃pre)中的关键语句:𝑆taintvul和𝐸vultaint。 - 在修复版本(
𝑅𝑃pos)中的关键语句:𝑆pattaint和𝐸pattaint。
通过以上过程,Vision 精确识别了与漏洞相关的关键语句,帮助发现漏洞的根本原因。
3.1.4 Signature Generation
Signature Generation 过程的目标是生成一个加权的跨过程程序依赖图(IPDG),用于表示漏洞和修复签名。这个签名由一个三元组组成:(𝑆, 𝐸, 𝑊),其中:
𝑆是语句集合,𝐸是语句之间的依赖关系集合,𝑊是每个语句及其依赖关系的权重。
生成漏洞签名 (𝑆𝑖𝑔vul) 或修复签名 (𝑆𝑖𝑔pat) 的过程包括以下几个步骤:
- 连接 PDG 成为 IPDG:
- Vision 为每个关键方法生成程序依赖图(PDG)。对于有更改的关键方法,使用在 change statement slicing 中生成的部分 PDG。
- 对于没有变化的关键方法,Vision 将其 PDG 压缩成一个单一的函数节点,忽略内部的程序依赖关系。
- 然后,通过从 关键方法选择 中获得的函数调用关系,将这些部分 PDG 和单一方法节点连接起来,形成跨过程程序依赖图(IPDG)。在这些连接中,跨过程调用关系从调用方法中的调用语句开始,到被调用方法中的 PDG 入口。
- 为 IPDG 分配权重:
- 默认情况下,IPDG 中的每个顶点和边的权重都为 1。
- 接下来,Vision 通过关键方法和关键语句来赋予更高的权重:
- 为关键方法中的调用语句和调用关系分配权重(
𝑤𝑐𝑟𝑖_𝑚)。 - 为关键语句及其依赖关系分配权重(
𝑤𝑐𝑟𝑖_𝑠)。
- 为关键方法中的调用语句和调用关系分配权重(
- 最终,通过这种加权过程生成漏洞签名 (
𝑆𝑖𝑔vul) 和修复签名 (𝑆𝑖𝑔pat),它们都表现为加权的 IPDG。
3.2 Vulnerability-potential and Patch-potential Version Signature Generation
3.2.1 Critical Method Mapping
Critical Method Mapping 过程的目标是通过与候选库版本中的相似方法匹配,帮助识别潜在的漏洞。具体步骤如下:
- 反编译库版本:首先,Vision 使用 Java Decompiler 对候选库版本进行反编译。
- 使用代码克隆检测工具:然后,Vision 利用 NiCad(一个流行的代码克隆检测工具)来识别候选库版本中与
𝑅𝑃pre和𝑅𝑃pos中的方法相似的方法。 - 通过克隆检测匹配相似方法:不同于直接比较方法签名,Vision 使用代码克隆检测来处理更复杂的重构情况。这种方法可以识别出在重构过程中可能发生的变化,从而更全面地匹配相似方法。
通过这种方法,Vision 能够发现与漏洞相关的相似方法,从而为漏洞识别提供证据。
3.2.2 Change Statement Mapping & Slicing
Change Statement Mapping & Slicing 过程旨在通过计算原始方法和映射的关键方法之间语句的相似性来识别和处理变化的语句。具体步骤如下:
- 语法差异归一化:为了处理反编译可能引起的语法差异,Vision 对原始方法和映射方法的语句进行归一化处理,包括重新排序操作数、将条件语句(如 IfStatement)中的操作符进行标准化(例如将 “>” 转换为 “<”),以及统一 ForStatement 中的条件表达式。
- 计算语法相似性:使用 Levenshtein 距离 来计算语句之间的语法相似性。如果相似度超过预设的阈值(默认阈值为 0.55),则 Vision 会将两者的语句匹配成一对。
- 构建删除和添加语句的映射集:一旦找到了匹配的语句,Vision 会构建删除语句和添加语句的映射集。
- 执行程序切片:随后,Vision 对这些映射的语句集合进行前向和后向的程序切片操作,进一步分析关键语句的依赖关系。
通过这些步骤,Vision 可以有效地处理变化的语句,识别出关键的修改语句,并对其进行依赖分析。
3.2.3 Critical Statement Mapping
Critical Statement Mapping 过程通过以下步骤识别原始方法中的关键语句:
- 识别关键变量:Vision 首先识别原始方法中包含关键变量的语句。
- 构建程序依赖图(PDG):基于识别的关键语句,Vision 构建相应的程序依赖图(PDG)。
- 执行污点分析:对映射的变量进行污点分析,追踪关键变量的流向。
- 形成关键语句集合:通过污点分析,Vision 确定哪些语句对关键变量有影响,从而构成原始方法中的关键语句集合。
这一过程帮助 Vision 精确地识别出原始方法中与关键变量相关的关键语句。
3.2.4 Signature Generation
Signature Generation 过程与漏洞和修复签名生成过程相似,具体步骤如下:
- 使用映射的关键方法和关键语句:Vision 利用映射后的关键方法(来自 3.2.2 节)和关键语句(来自 3.2.3 节)进行签名生成。
- 连接 PDGs 到 IPDGs:将程序依赖图(PDGs)连接成跨过程依赖图(IPDGs)。
- 赋予权重:为每个语句及其依赖关系分配权重。
最终,生成漏洞潜在签名(𝑆𝑖𝑔vul)和修复潜在签名(𝑆𝑖𝑔pat)。
3.3 Affected Library Versions Detection
3.3.1 Similarity Calculation
Vision 通过比较 漏洞签名 (𝑆𝑖𝑔vul) 和 **漏洞潜力签名 (𝑆𝑖𝑔vul’)**,以及 补丁签名 (𝑆𝑖𝑔pat) 和 补丁潜力签名 (𝑆𝑖𝑔pat’) 的相似度来识别 ALVs (可能存在的漏洞)。具体步骤如下:
语义嵌入计算:首先,Vision 使用 UniXcoder(一种跨模态的编程语言预训练模型)来生成代码的语义嵌入。对于来自原始签名 𝑆𝑖𝑔vul 或 𝑆𝑖𝑔pat 中的语句集合(在方法合并为单一节点时),Vision 生成每个语句的语义嵌入向量,并通过 L2 正则化来标准化这些向量。
计算相似度:接着,Vision 计算原始 IPDG 和映射的 IPDG 中的每对语句 𝑠𝑖 和 𝑠𝑗 之间的余弦相似度。根据语句的相似度和它们的权重(𝑤𝑠𝑖 和 𝑤𝑠𝑗),计算两者的距离(公式 3)。对于边的相似度,计算源节点和目标节点之间的节点距离,并通过公式 4 求得边的距离。
最小化总距离:通过最小化语句和边的距离,Vision 解决了一个二分匹配问题。最终,计算两个签名之间的相似度(公式 5),其中包括语句距离和边距离的加权平均。
确定是否为 ALV:Vision 计算漏洞相似度 𝑠𝑖𝑚𝑣 和补丁相似度 𝑠𝑖𝑚𝑝。如果满足以下条件,则视为 ALV:
- 𝑠𝑖𝑚𝑣 > 𝑡ℎ𝑠(漏洞相似度高于阈值)
- 𝑠𝑖𝑚𝑣 > 𝑠𝑖𝑚𝑝(漏洞签名比补丁签名更相似)
如果这些条件满足,Vision 判定候选库版本为 受影响,否则为 未受影响。
Evaluation
我们使用了 11.4K 行 Python 代码和 1.6K 行 Java 代码实现了 Vision。我们设计了以下研究问题:
- RQ1: 效能评估:与现有的先进方法相比,Vision 在识别 ALV(潜在漏洞)方面的有效性如何?
- RQ2: 消融研究:Vision 中每个组件对整体有效性的贡献如何?
- RQ3: 参数敏感性:参数的变化如何影响 Vision 的有效性?
- RQ4: 泛化性评估:将 Vision 应用到其他数据集时,其泛化性如何?
- RQ5: 效率评估:Vision 的时间开销如何?
- RQ6: 有用性评估:Vision 的有用性如何?
4.1 Evaluation Setup
- Ground Truth 建立
实验使用 Maven 中的 Java 库作为研究对象,因其受欢迎且具有较高复杂度。Ground truth 的建立遵循严格的四步流程:
- 收集漏洞信息:从 1999 年 1 月到 2024 年 5 月,收集了 1,083 个 CVE(公共漏洞与曝光),并获取了相关补丁信息(如 GitHub 提交记录)。收集的 CVE 数据包括了 V-SZZ 和 VerJava 等现有数据集。
- 收集测试用例/漏洞证明及创建测试用例:手动检查补丁中包含的测试用例,如果没有测试用例,则通过 CVE ID 和相关漏洞的“利用”或“证明概念(PoC)”在 GitHub 上查找相关提交。分析这些触发逻辑,并将其转化为 JUnit 测试用例,共获得了 102 个 CVE 对应的测试用例。
- 运行测试用例验证库版本:自动切换 Maven 库版本并运行测试用例,以验证漏洞是否被触发。如果测试用例执行不成功,手动检查并修改代码以保证其与相应版本兼容。
- 人工检查:对于无法通过测试用例验证的库版本,手动检查这些版本,查看是否存在漏洞方法或修复方法,最终确认漏洞是否存在。
- 一致性检验:通过 Cohen’s Kappa 系数检验,确保两位作者在漏洞检测上有较高的一致性(Kappa 值为 0.879)。若有争议,第三位作者进行裁定。最终收集到 12,073 个库版本与 102 个 CVE 相关,涵盖了 79 个库。
- 基准比较(Baselines)
本实验将 Vision 与现有的补丁和克隆基于方法进行比较:
- 补丁基准方法:
- V-SZZ 和 VerJava,作为当前主流的 ALV 检测工具。
- 不与 AFV(专注于 PHP 的特定漏洞)进行比较。
- 克隆基准方法:
- V0Finder、VUDDY 和 MVP,比较 Vision 与这些工具的效果。VUDDY 被修改为支持 Java。
- 不与 V1Scan 和 Movery 进行比较,因为它们依赖于多个漏洞版本的范围进行聚合签名生成,这在只有一个漏洞版本时会影响其效果。
- 评估指标与环境
实验使用传统的评估指标:真阳性(TP)、假阳性(FP)、假阴性(FN)、精确度和召回率。此外,引入了“完全识别漏洞”(Perfectly Identified Vulnerability, PV)的新指标,用于衡量工具是否完全正确地识别出 ALV(即零假阳性和零假阴性)。
总结而言,该实验的设置包括了详尽的 Ground truth 构建过程,基准工具的比较,并采用了多种传统的评估指标,以确保结果的准确性和可信度。
4.2 Effectiveness Evaluation (RQ1)
实验设置:
- 评估方法:
- 使用 ground truth 数据集,与五种基线方法(V-SZZ、VerJava、V0Finder、VUDDY、MVP)进行比较。
- 评估包括 GitHub 仓库中的重叠库版本(O)和我们完整的 ground truth 数据集(C)。
- 修改 VerJava 以支持 Maven 上的完整库版本,称为 VerJava*。
- 数据集:
- 重叠库版本:GitHub 和 ground truth 数据集中的公共版本。
- 完整库版本:包括所有相关版本的数据。
- 评估维度:
- CWE 类型:按照 12 个组对漏洞类型进行分类,包含 83 个标记了 CWE 的漏洞和 19 个未标记的漏洞。
- 更改类型:包括混合更改和仅添加更改(没有删除的变化)。
- 最优参数:根据灵敏度分析选择。
整体结果:
- 精确度与召回率:
- Vision:
- 重叠库版本:精确度 0.91,召回率 0.95。
- 完整库版本:精确度 0.91,召回率 0.94。
- VerJava(重叠库版本):精确度 0.78,召回率 0.58。
- V0Finder(完整库版本):精确度 0.81,召回率 0.25。
- Vision:
- **完美识别的漏洞 (PVs)**:
- 重叠库版本:Vision 识别了 66 个 PVs(64.7%),超过 VerJava 的 37 个(36.3%)。
- 完整库版本:Vision 识别了 62 个 PVs(60.8%),超过 V0Finder 的 46 个(287.5%)。
- 假阳性与假阴性:
- Vision:
- 重叠库版本:357 个假阳性,184 个假阴性,56 个非 PV 漏洞。
- 完整库版本:418 个假阳性,258 个假阴性,40 个非 PV 漏洞。
- Vision:
错误分析:
- CVE 或提交描述误导:
- 包含不相关的修复方法,影响了关键方法的选择。
- Joern 切片误差:
- 程序切片中的错误数据或控制依赖,影响了关键语句的选择。
- 版本修复逻辑不同:
- 不同分支上可能存在不同的修复逻辑,导致补丁签名未能准确反映。
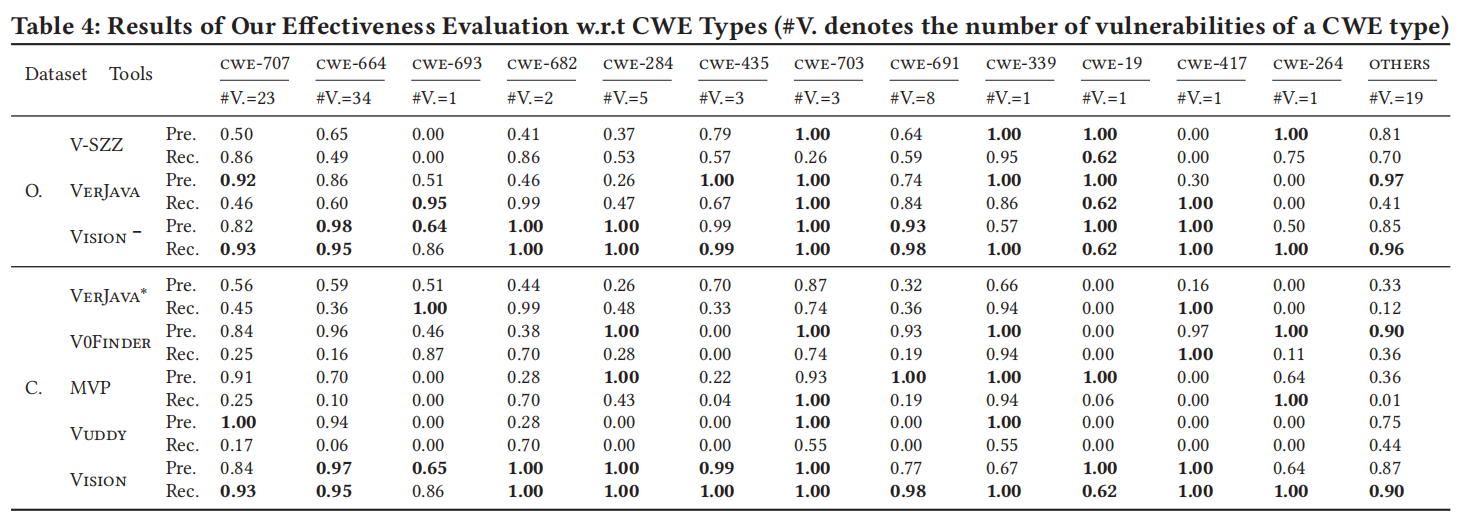
按 CWE 类型的有效性:
- 重叠库版本:
- Vision 超越 VerJava 在 8 个 CWE 类型的精确度,12 个类型的召回率。
- 在 6 个 CWE 类型中,Vision 达到 100% 的精确度或召回率。
- 平均精确度:Vision 0.87,VerJava 0.78。
- 平均召回率:Vision 0.95,VerJava 0.58。
- 完整库版本:
- Vision 超越 Vuddy 在 8 个 CWE 类型的精确度,12 个类型的召回率。
- 平均精确度:Vision 0.88,Vuddy 0.84。
- 平均召回率:Vision 0.94,Vuddy 0.91。
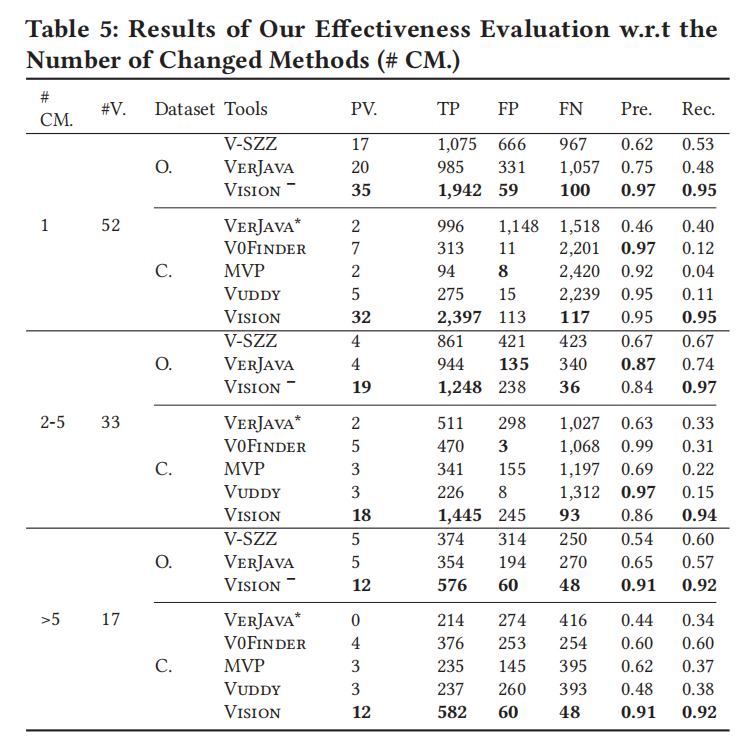
按更改方法的有效性:
- 重叠库版本:
- Vision 精确度:0.84 到 0.97,召回率:0.92 到 0.95。
- 比基线工具表现更好,特别在精确度上。
- 完整库版本:
- Vision 精确度:0.86 到 0.95,召回率:0.92 到 0.95。
- 相比 Vuddy,精确度略低,但在更多变化的情况下,Vision 超越了 Vuddy。
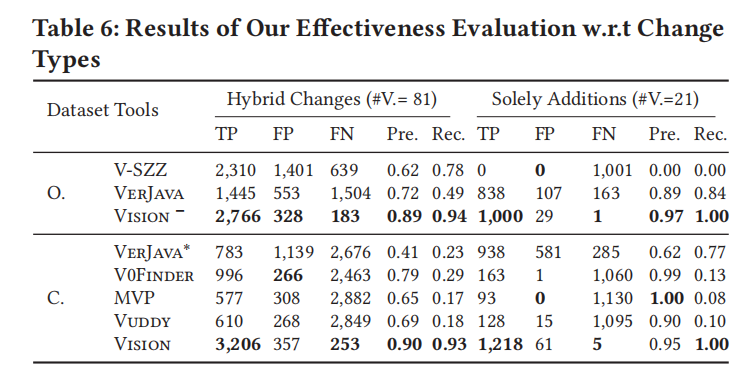
按更改类型的有效性:
- 混合更改:
- Vision 在混合更改上超越 V-SZZ,精确度提高 0.27,召回率提高 0.16。
- 仅添加更改:
- V-SZZ 对于仅添加的更改失败,而 Vision 表现优越。
总结:
- Vision 在所有评估维度上表现出色,尤其在处理不同类型和数量的漏洞修复时,展示了较高的精确度和召回率。
- Vision 在处理混合更改和仅添加更改时均超过了现有的基线方法,特别是在处理复杂漏洞修复时的稳定性和有效性。
总结:Vision 在完整库版本和重叠库版本中均取得了最高的精确度和召回率,分别为 0.91 和 0.94,以及 0.91 和 0.95,平均精确度比现有的最先进方法高出 0.23(33.8%),召回率高出 0.71(308.7%)。相比于最先进的方法,Vision 平均识别了 3,352 个(312.7%)更多的真实 ALV。Vision 在不同的 CWE 类型、变更方法数量和变更类型上均表现出色。
4.3 Ablation Study (RQ2)
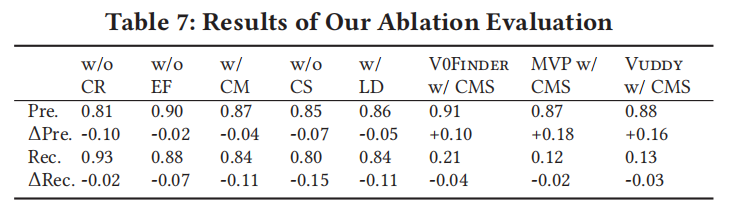
RQ2 设置: 为了研究 Vision 各个组成部分的贡献,创建了五个消融版本:
- w/o CR:仅保留专家参考中识别的关键方法,消除调用关系。
- w/o EF:保留调用关系,但不使用专家参考来识别关键方法。
- w/ CM:用变更方法代替关键方法进行选择。
- w/o CS:将关键语句标记为普通语句,设定权重为 1。
- w/ LD:将 UniXcoder 替换为 Levenshtein 距离计算相似度。
另外,消融实验还涉及在基于克隆的方法中应用关键方法选择(V0Finder w/ CMS, MVP w/ CMS, Vuddy w/ CMS)。
整体结果:
- 所有消融版本的精确度和召回率均有所下降。
- w/o CS:精确度下降 0.07,召回率下降 0.15,表明选择关键语句对性能至关重要。
- w/ CM:精确度下降 0.04,召回率下降 0.11,凸显了关键方法选择的重要性。
- w/o CR 和 w/o EF:去除调用关系或专家参考后,精确度和召回率均有所下降,表明两者对 Vision 的有效性有重要贡献。
- w/ LD:将 UniXcoder 替换为 Levenshtein 距离后,精确度和召回率均有所下降。
- 基于克隆的方法(V0Finder, MVP, Vuddy)在使用关键方法选择后,精确度分别提升了 0.10、0.18 和 0.16,但召回率轻微下降(分别为 0.04、0.02 和 0.03)。
总结:移除 Vision 的任何组件都会导致精确度和召回率的明显下降。去除关键语句导致召回率下降最大,下降幅度为 0.15;而移除调用关系则导致精确度下降最大,下降幅度为 0.10。通过使用我们的关键方法选择,基于克隆的方法在精确度上平均提高了 0.15,但召回率平均略微下降了 0.03。
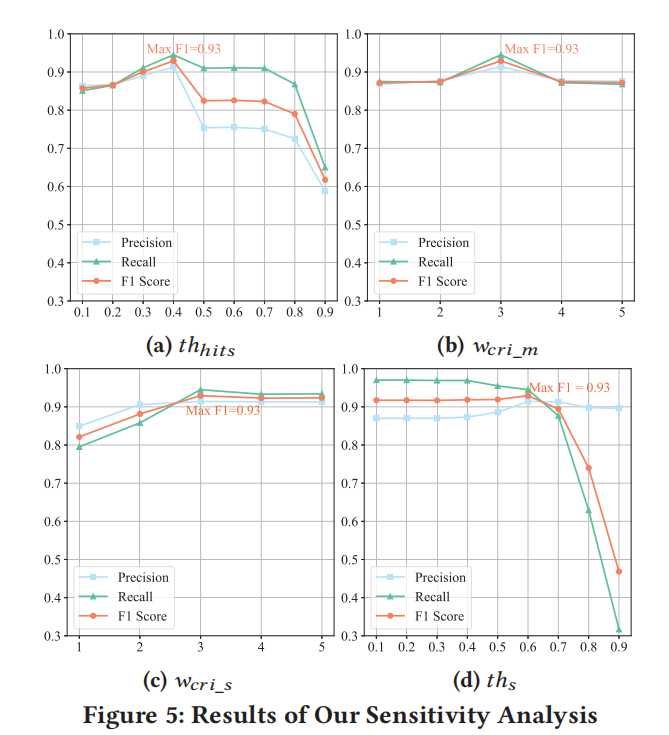
4.4 Parameter Sensitivity (RQ3)
RQ3 设置:
Vision 中有四个可配置的参数:
- 选择关键方法的阈值 (𝑡ℎℎ𝑖𝑡𝑠)
- 关键方法间的程序间调用权重 (𝑤𝑐𝑟𝑖_𝑚)
- 关键语句的权重 (𝑤𝑐𝑟𝑖_𝑠)
- 识别漏洞的相似度阈值 (𝑡ℎ𝑠)
默认值分别为:0.4, 3, 3 和 0.6。为了评估这些参数对 Vision 准确度的灵敏度,我们分别调整一个参数,并将其他三个保持固定。
总体结果:
通过灵敏度分析,Vision 在以下配置下达到最佳性能:
- 𝑡ℎℎ𝑖𝑡𝑠 = 0.4
- 𝑤𝑐𝑟𝑖_𝑚 = 3
- 𝑤𝑐𝑟𝑖_𝑠 = 3
- 𝑡ℎ𝑠 = 0.6
4.5 Generality Evaluation (RQ4)
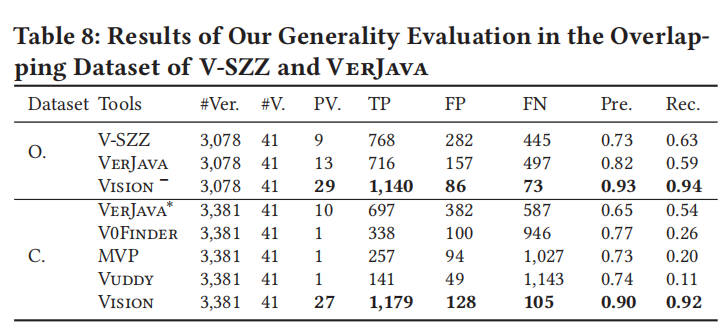
- RQ4 设置:
将 Vision 应用于 V-SZZ 和 VerJava 的原始数据集。选择了 V-SZZ 和 VerJava 重叠集中的 50%(41/81)的 CVE,得到了 3,381 个完整库版本(C.)和 3,078 个重叠库版本(O.)。 - 总体结果:
- 性能对比:
- Vision, Vision −, MVP, V0Finder, 和 Vuddy 在这两个数据集上表现相似。
- V-SZZ, VerJava 和 VerJava∗ 在它们自己的数据集上表现出更高的精度和召回率。
- 精度和召回率变化:
- Vision 的精度下降了 1%,召回率下降了 2%。
- Vision − 的精度略微上升了 2%,召回率下降了 1%。
- 这表明 Vision 在外部数据集上的泛化能力。
- Vision − 与 VerJava 比较:
- Vision − 相比于 VerJava 提高了 0.11(13.41%)的精度和 0.35(59.32%)的召回率。
- Vision − 在重叠库版本中识别了 29 个(70.73%)完全识别的漏洞(PVs),超越了 VerJava 的 16 个(123.08%)。
- 性能对比:
4.6 Efficiency Evaluation (RQ5)
RQ5 设置:
- 测量了每个漏洞以及每个库版本识别 ALVs 所需的平均时间。
总体结果:
Vision
的时间成本如下:
- 平均需要 9.24 秒 来处理一个候选库版本并判断其是否受到影响。
- 平均需要 1,094.11 秒 来处理所有库版本对应一个漏洞的情况。
虽然 Vision 的时间成本高于现有工具,但由于其在识别漏洞影响版本方面的卓越效果,这一时间成本是可以接受的。
时间成本的增加主要是由于需要反编译 JAR 文件、生成用于关键方法选择的调用图,以及进行相似度计算等过程。
4.7 Usefulness Evaluation (RQ6)
RQ6 设置:
- 本研究将 Vision 与五个漏洞数据库进行比较:NVD、Veracode、GitHub、GitLab 和 Snyk。
- 排除任何未知的 CVE 以及在我们的真实数据集中不存在的库版本。
- 使用与 RQ1 相同的度量标准评估这些数据库的准确性,同时评估 Vision 在这些数据库中的表现,并计算 Vision 相较于各数据库的准确性提升。
总体结果:
- Vision 在所有五个数据库中均提高了精度和召回率:
- 在 GitHub 和 GitLab 中,Vision 的精度提升最大,达到了 0.22。
- 在 NVD 中,Vision 的召回率提升最大,达到了 0.14。
- Vision 帮助识别了更多完全正确的漏洞(PVs):
- 在 Snyk 中增加了至少 19 个 PVs,在 NVD 中最多增加了 27 个 PVs。
- Vision 在识别不准确的漏洞时,提供了帮助:
- 将 Vision 错误标记的漏洞报告给各数据库:52 个给 NVD、31 个给 Veracode、46 个给 Snyk,并通过创建问题将 39 和 42 个错误漏洞报告给 GitHub 和 GitLab。
- 目前,GitHub 和 GitLab 已解决了所有错误的库版本,NVD 修复了 8 个漏洞,剩余的漏洞仍在审查中。
- 值得注意的是,GitLab 表示对我们的工具在 ALV 检测方面非常感兴趣。
4.8 Discussion
- 威胁:
- 构建真实数据集的威胁: 真实数据集的构建可能存在人工错误,尽管我们尽最大努力通过验证受影响的库版本来确保其准确性。为了减少这一威胁,数据集的构建过程涉及了三位作者的参与。
- 数据集规模的影响: 评估结果受数据集规模的影响。我们构建了一个包含102个漏洞和12,073个受影响与未受影响的库版本的数据集,这一数据集的构建耗时约800人小时,是目前为止最大的评估数据集。
- 局限性:
- 依赖语言特定工具: Vision 依赖于一些语言特定的工具,如 Java Decompiler 和 Joern,因此其适用性有限,主要针对特定的编程语言,不能广泛应用于其他编程语言。
- 缺乏漏洞解释: Vision 没有提供预测的受影响库版本的解释。未来我们计划通过增加基于关键方法和语句的可视化漏洞原因和修复的解释来解决这一问题。
- 补丁输入的多次提交问题: Vision 接受补丁提交作为输入,但目标补丁可能包含多个提交,这可能导致忽略漏洞签名和补丁签名,进而可能产生假阳性和假阴性。