
Drowzee Metamorphic Testing for Fact-Conflicting Hallucination Detection in Large Language Models
Drowzee: Metamorphic Testing for Fact-Conflicting Hallucination Detection in Large Language Models
ABSTRACT
大型语言模型(LLMs)已在语言处理领域引发了革命,但它们面临着安全性、隐私以及生成幻觉(即看似合理但事实上不准确的输出)等关键挑战。一个主要问题是事实冲突幻觉(FCH),即LLM生成的内容与事实真相相矛盾。解决FCH问题非常困难,主要面临两个挑战:1)自动构建和更新基准数据集较为复杂,因为现有方法依赖于人工整理的静态基准数据集,无法涵盖FCH案例的广泛、不断发展的范围;2)验证LLM输出背后的推理过程本身具有挑战性,尤其是对于复杂的逻辑关系。
为了解决这些问题,我们提出了一种新颖的逻辑编程辅助变形测试技术,用于FCH检测。我们开发了一个全面且可扩展的框架,通过爬取像维基百科这样的资源,构建一个全面的事实知识库,并将其无缝集成到Drowzee中。通过逻辑推理规则,我们将这些知识转化并增强为大量具有事实真相答案的测试案例。我们通过基于模板的提示对LLM进行测试,要求它们提供有理有据的答案。为了验证其推理过程,我们提出了两种语义感知的预言机,评估LLM回答与事实真相之间语义结构的相似度。我们的方法可以自动生成有用的测试案例,并在九个领域内对六个LLM进行幻觉检测,发现幻觉率从24.7%到59.8%不等。主要发现包括LLM在处理时间概念、分布外知识和缺乏逻辑推理能力方面的困难。结果表明,Drowzee生成的基于逻辑的测试案例能够有效触发并检测幻觉。为了进一步减少已识别的FCH,我们探索了模型编辑技术,发现它在小规模上(对不到1000个知识点的编辑)是有效的。我们的研究结果强调了持续进行社区合作以检测和缓解模型幻觉的重要性。
Introduction
Background
- LLMs的优势与应用:
- LLMs在语言处理和理解方面取得了显著进展,具备强大的文本生成和理解能力。
- 它们在多个领域(如文本生成、问题解决等)具有广泛的应用。
- LLMs面临的关键挑战:
- LLMs在安全性和隐私方面存在重大问题,影响其有效性和可靠性。
- 幻觉(Hallucination)现象是其中的一个主要问题。
- 幻觉的定义与表现:
- 幻觉指的是LLMs生成连贯但事实不准确或不相关的内容。
- 特别关注“事实冲突幻觉(FCH)”类型。
- FCH表现为LLM生成与已知事实直接矛盾的内容。
- FCH的例子:
- 例如,LLM错误地认为“村上春树在2016年获得诺贝尔文学奖”,而实际事实是“村上春树并未获得诺贝尔文学奖”。
- 这种错误信息传播会导致用户困惑。
- 影响与风险:
- 幻觉现象削弱了LLM应用中的信任性和可靠性,对用户造成误导,尤其在需要准确事实的场景中尤为严重。

Existing works
- 现有检测和测试方法:
- 许多研究引入了用于检测幻觉的方法,其中一种常见的方式是创建专门的基准数据集。
- 代表性数据集包括TruthfulQA、HaluEval 和 KoLA,这些数据集旨在评估不同上下文中的幻觉现象,如问答、摘要生成和知识图谱。
- 现有方法的局限性:
- 目前的幻觉检测方法依赖于简单的半自动方法,如字符串匹配、手动验证或使用另一种LLM进行确认。
- 这些方法虽然有一定价值,但存在明显的局限性,尤其是在自动有效地测试事实冲突幻觉(FCH)方面。
- FCH检测的挑战:
- FCH(事实冲突幻觉)的检测特别具有挑战性,因为它需要将LLM生成的内容与外部知识源或数据库的事实进行核对。
- 与其他类型的幻觉(如输入冲突幻觉或上下文冲突幻觉)不同,FCH无法仅通过语义一致性检查来检测。
- 缺乏专用测试框架和数据集:
- 缺乏专门的地面真实数据集和测试框架是FCH检测的主要障碍。
- 这使得FCH的检测过程变得特别困难和资源密集,尤其是在需要处理包含逻辑关系的内容时。
Challenges
- 挑战1:自动构建和更新基准数据集的困难:
- 现有方法主要依赖人工整理的基准数据集,虽然能检测部分幻觉,但无法涵盖LLM中广泛且动态的事实冲突场景。
- 知识的不断更新需要频繁更新数据集,这增加了显著的维护成本。
- 依赖基准数据集限制了检测技术的适应性、可扩展性以及检测能力。
- 挑战2:自动验证LLM输出答案的困难:
- 即使LLM输出正确答案,推理过程可能并不真实,掩盖了错误理解,这会引发事实冲突幻觉(FCH)。
- 自动验证复杂逻辑关系中的推理过程本身具有挑战性。
- 人类专家在创建基准问题时的经验和技能水平差异会导致问题质量不一致,引入噪声,特别是在数据标注和结果验证阶段。
总结: 现有的FCH检测方法面临基准数据集局限性和推理过程验证的双重挑战,这需要进一步探索解决方案以提升LLM的可靠性。
Our approach
为了解决现有技术的局限性,本文首次提出了一种基于逻辑编程辅助的变形测试技术,用于LLM中的幻觉检测。具体来说,Drowzee 是我们提出的FCH(事实冲突幻觉)测试框架,结合了事实知识推理和变形测试。
- 建立知识库:
- Drowzee首先通过广泛抓取Wikipedia等可访问的知识库,建立一个全面的事实知识库。
- 知识库中的每个知识条目作为后续转换的“种子”,通过逻辑推理关系对这些种子进行转化和扩展。
- 生成测试用例:
- 通过转换后的知识集,生成一组问题-答案对,并将其作为测试用例和真值。
- 使用模板化提示来测试LLM的FCH,要求LLM生成对测试用例的回答。
- 推理验证与FCH检测:
- 为了验证LLM推理过程的合理性,要求LLM提供详细的推理解释。
- 引入两种语义感知的变形预言机,通过提取句子中的语义元素并映射其逻辑关系,评估LLM答案与真值的语义相似性。
- 通过检测与真值显著偏离的答案来有效识别FCH。
总结: Drowzee框架结合了知识推理和变形测试,通过自动化的逻辑推理验证和语义相似性分析,有效地检测和识别LLM中的事实冲突幻觉。
Results and Findings.
- 实验设计与方法:
- 广泛评估:Drowzee框架在多个领域和广泛的Wikipedia文章中进行测试,涵盖了不同主题。
- 多模型评估:对多个开源和商业化的LLM进行了评估,全面检查其在不同架构下的适用性和表现。
- 主要发现:
- FCH检测:Drowzee能够自动生成有效的测试用例,并识别六个LLM在九个领域中的幻觉问题。
- 幻觉发生率:不同LLM的幻觉响应率在24.7%到59.8%之间。
- 幻觉类型:幻觉响应被分为四种类型,分析表明,缺乏逻辑推理能力是FCH问题的主要原因。
- 特殊易发领域:LLMs在涉及时间概念和超出训练知识的测试用例中尤其容易生成幻觉。
- 测试用例的有效性:
- 使用逻辑推理规则生成的测试用例有效地触发并检测了LLM中的幻觉问题。
- 缓解措施:
- 通过模型编辑技术(例如hiyouga和Meng等人提出的方法)对识别出的FCH进行修正,初步结果表明,当编辑知识小于1000条时,取得了良好的效果。
Contributions
- FCH测试框架的开发:
- 提出了基于逻辑编程和变换测试的全新FCH检测框架,首次实现了自动化检测LLM中的事实冲突幻觉(FCH)问题。
- 构建和发布大规模事实知识库与基准数据集:
- 构建了一个大规模的基准数据集,并公开发布,以促进协作和未来FCH检测技术的发展。
- 创新的基于逻辑推理的数据变异方法设计与实现:
- 提出了五种独特的逻辑推理规则,通过变异和增强初始种子,增加测试场景的多样性和有效性。
- FCH特定的语义感知测试神谕的部署:
- 提出了并实现了两种自动验证机制(神谕),通过分析句子间的语义结构相似性,验证LLM生成答案背后的推理逻辑,可靠地检测FCH的发生。
Background
2.1 Hallucination Categorization
- **输入冲突幻觉 (Input-Conflicting Hallucination)**:
- 发生在LLM生成的输出与用户输入不一致时。具体表现为:
- 模型的回答与任务指令相矛盾(表示模型未理解用户意图)。
- 生成的内容与任务输入矛盾(类似于机器翻译或摘要中的常见问题)。
- 例子:LLM在摘要中替换了关键信息或细节,偏离了用户提供的实际内容。
- 发生在LLM生成的输出与用户输入不一致时。具体表现为:
- **上下文冲突幻觉 (Context-Conflicting Hallucination)**:
- 发生在LLM的长篇或多轮回应中,模型无法保持一致性或跟踪上下文。
- 原因通常是模型的长期记忆能力有限,无法识别相关上下文。
- 例子:LLM在讨论某个话题时,错误地在两个不同的人物之间切换引用。
- **事实冲突幻觉 (Fact-Conflicting Hallucination)**:
- 本文的核心关注点,发生在LLM生成的内容与已知事实直接冲突时。
- 这种幻觉可能源于LLM生命周期中不同阶段的多种因素。
- 例子:LLM在回应历史问题时提供错误的历史信息,误导不熟悉该主题的用户。
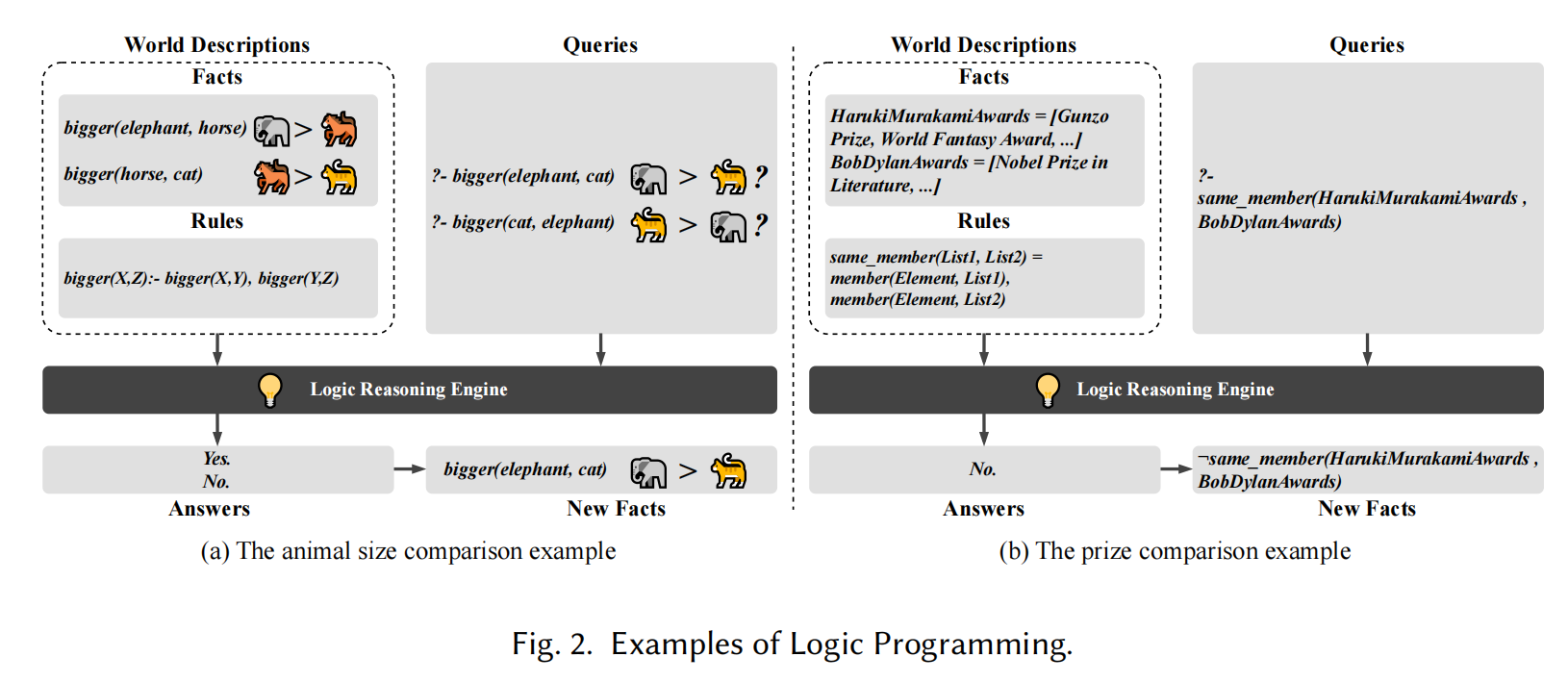
2.2 Logic Programming
- 逻辑编程简介:
- 逻辑编程语言是声明式的,通过描述世界来编程,使用这些程序就是向已描述的世界提问。
- 逻辑编程可以帮助自动推理新事实,基于事实和规则得出答案。
- Prolog程序结构:
- 程序由事实和规则组成:
- 事实:定义一个关系为真,表示为“谓词(实体)”。
- 示例:
bigger(horse, cat)表示马比猫大。
- 示例:
- 规则:包含头部谓词和多个谓词作为条件,表示逻辑推导的关系。
- 示例:
bigger(X, Z) :- bigger(X, Y), bigger(Y, Z)表示“bigger”关系是传递的。
- 示例:
- 事实:定义一个关系为真,表示为“谓词(实体)”。
- 程序由事实和规则组成:
- 查询与推理:
- 查询结构与规则的条件部分相同,由谓词组成,并在事实数据库中执行。
- 查询返回
Yes如果该条件在事实和规则的基础上为真,否则返回No。 - 示例:查询
?- bigger(elephant, cat),询问“是否大象比猫大?”
- 推理规则:
- 推理规则描述了如何通过事实和规则(谓词)推导出新事实(谓词)。推理过程省略了查询和结果分析部分。
- 示例:
R1, R2, ... -> Rnew表示从事实R1、R2等推导出新事实Rnew。
该方法通过逻辑推理,能够为LLM的幻觉检测提供自动化的测试机制,利用事实和推理规则推导出新知识并验证LLM的输出是否符合事实。
Motivating Example

- 现有手动生成基准的局限性:
- 依赖人类专家生成问题和标注答案的方法存在以下问题:
- 动态知识挑战:知识随时间变化(如村上春树未来获诺奖),需要定期更新和修正基准数据集。
- 高人工成本:维护基准数据的准确性需要大量人工劳动。
- 问题质量不一致:人类专家经验和技能差异可能导致生成的问题质量参差不齐。
- 这些问题影响了手动基准的效率和可靠性。
- 依赖人类专家生成问题和标注答案的方法存在以下问题:
- 自动生成多样化基准的挑战:
- 挑战1:生成适当且有效的问题:
- 测试基准中的问题需要逻辑一致并符合事实知识,不能随机生成。
- 挑战2:生成检测幻觉的测试预言机:
- 判断LLM是否存在事实冲突幻觉(FCH)的关键是分析其答案的逻辑推理是否与事实一致。
- 自动比较LLM复杂答案与事实真相之间的逻辑结构是一个难点。
- 挑战1:生成适当且有效的问题:
逻辑编程的解决方案:
- 多样化问题生成:
- 通过逻辑编程,基于现有知识推导出新的逻辑一致的事实。
- 使用这些新事实生成多样化的问题及其对应的真值答案。
- 测试预言机生成:
- 基于生成的真值答案,创建测试预言机,捕获LLM的幻觉问题。
Methodology
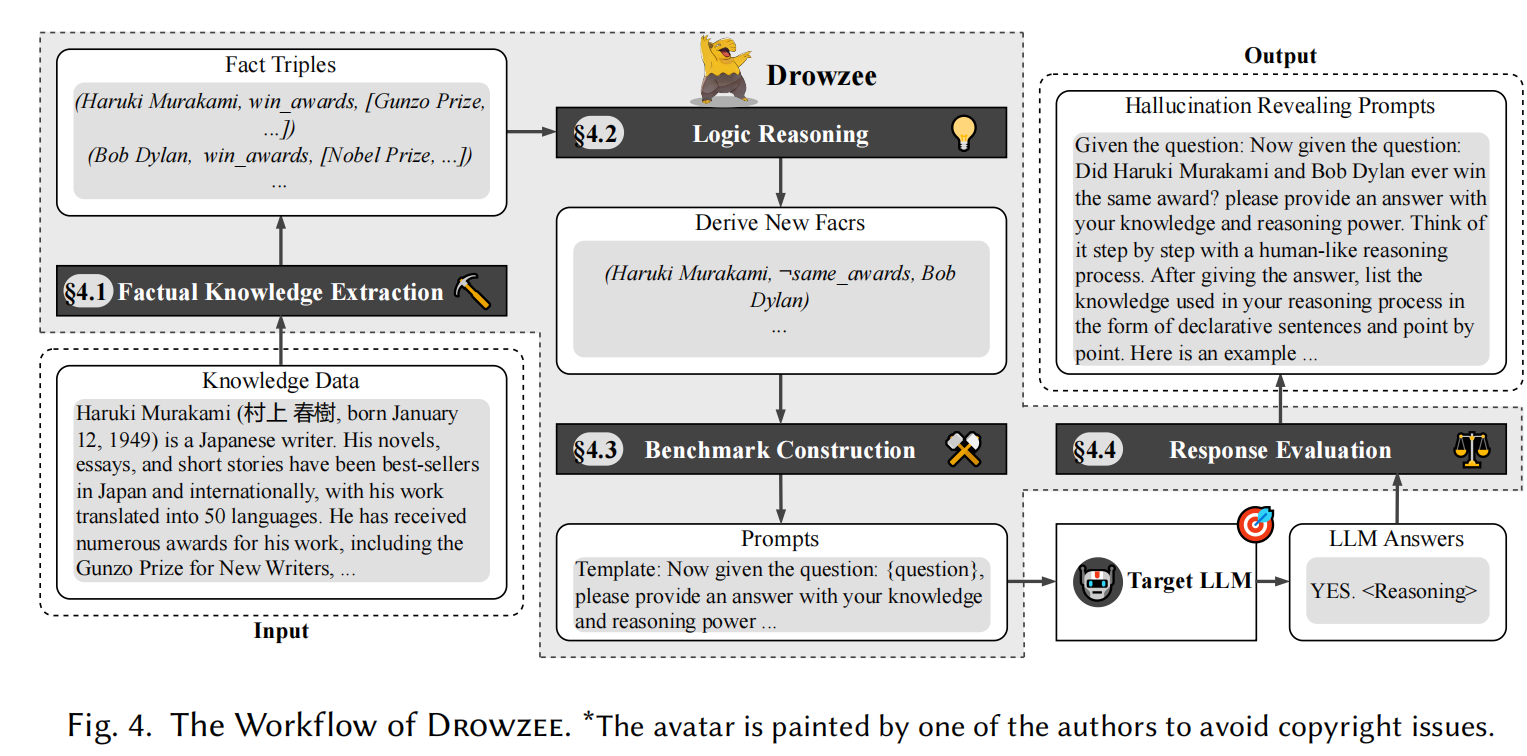
Drowzee 是为了解决上述挑战而设计和实现的,整个工作流程可以分为四个模块,具体包括:
- 事实知识提取(§4.1):Drowzee 从大量的知识数据库中获取基本信息和有效实体的事实三元组。
- 逻辑推理(§4.2):在此模块中,Drowzee 运用推理规则生成合理且多样化的新事实,作为新的“地面真相”知识。
- 基准构建(§4.3):该模块的重点是基于新生成的地面真相知识,创建高质量的测试用例-预期答案对。测试预期答案(oracle)通过简单而有效的变形关系生成:符合知识的提问应回答“是”,与知识相违背的提问应回答“否”。该模块还包括有效地生成和选择与大语言模型(LLM)互动的提示策略。
- 响应评估(§4.4):最终模块对 LLM 的响应进行评估,并自动检测事实一致性。它首先通过自然语言处理(NLP)解析 LLM 的输出,构建语义感知结构,然后评估其与地面真相的语义相似性。随后,它使用基于相似度的预期答案,通过变形测试来评估 LLM 响应与地面真相的一致性。
这个框架的设计目标是通过逻辑推理和自动化测试,可靠地识别 LLM 生成的幻觉(hallucination),提高模型的准确性和可信度。
4.1 Factual Knowledge Extraction
该步骤的目的是从输入的知识数据中提取基础事实,并将其转化为可以用于逻辑推理的三元组。具体过程如下:
- 知识数据库来源:
- 现有的知识数据库(如Wikipedia)包含了大量文档和结构化数据,这些结构化数据适合用于构建事实知识。
- 提取的数据将作为测试框架的基础,确保数据来源的可靠性和全面性。
- 事实三元组结构:
- 提取的事实以三元组形式表示:nm(s, o),其中:
s(主语)和o(宾语)是实体。nm是谓词的名称,表示实体间的关系。
- 提取的事实以三元组形式表示:nm(s, o),其中:
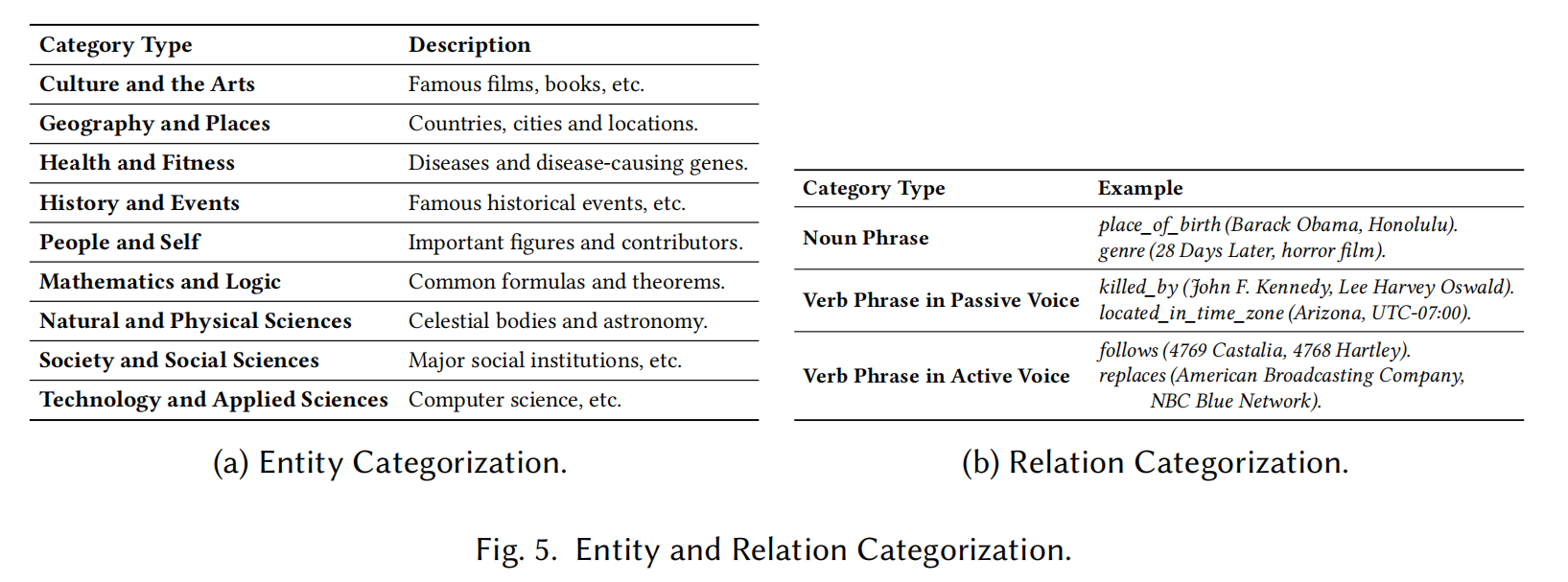
- 实体和关系的分类:
- 实体和关系的分类依据Wikipedia的标准分类(见图5),包括多个不同的实体类别和关系类别。
- 提取过程的分步执行:
- 分而治之的策略:按类别分别提取实体和关系,避免一次性处理过多数据,提升效率。
- 提取函数:通过
ExtractGroundFacts函数,从数据库中查询实体和关系的组合,提取相关事实。 - 查询数据库:使用
QueryDB函数获取与特定谓词和实体组合对应的事实三元组。
- 实现步骤:
- 通过算法1,系统将对每个实体和关系类别进行迭代处理,确保所有组合的事实都被提取出来。

4.2 Logical Reasoning
该步骤的目标是从先前提取的事实知识中推导出更多的、丰富的信息。Drowzee利用基于逻辑编程的处理器,自动生成新的事实知识。具体过程如下:
- 推理规则:
- Drowzee设计了五种推理规则,以生成具有变异性的FCH测试用例。这些规则来源于多篇文献,广泛应用于知识推理的背景下。
- 规则的作用是通过输入一个或多个事实三元组,生成一个新的推导三元组。
- 五种推理规则:
- 规则#1:否定推理(Negation Reasoning):
- 给定事实三元组
(s, nm, o),可以推导出该事实的否定三元组:¬ nm(s, o)。 - 示例:从
(Haruki Murakami, won, the Nobel Prize in Literature in 2016)推导出其否定(Haruki Murakami, did not win, the Nobel Prize in Literature in 2016)。
- 给定事实三元组
- 规则#2:对称推理(Symmetric Reasoning):
- 对于对称关系,如果三元组中的主语和宾语交换后仍保持一致,则可以推导出新三元组:
(o, nm, s)。 - 示例:从
(Haruki Murakami, different_from, Haruki Uemura)推导出(Haruki Uemura, different_from, Haruki Murakami)。
- 对于对称关系,如果三元组中的主语和宾语交换后仍保持一致,则可以推导出新三元组:
- 规则#3:反向推理(Inverse Reasoning):
- 对于反向关系,主语和宾语可以通过原关系的反向变体来反向关联。
- 示例:从
(Haruki Murakami, influence_by, Richard Brautigan)推导出(Richard Brautigan, influence, Haruki Murakami)。
- 规则#4:传递推理(Transitive Reasoning):
- 对于传递关系,如果一个三元组的宾语是另一个三元组的主语,则可以推导出新三元组:
(s1, nm, o2)。 - 示例:从
(Haruki Murakami, locate_in, Kyoto)和(Kyoto, locate_in, Japan)推导出(Haruki Murakami, locate_in, Japan)。
- 对于传递关系,如果一个三元组的宾语是另一个三元组的主语,则可以推导出新三元组:
- 规则#5:复合推理(Composite Reasoning):
- 基础推理规则可以链式组合形成复合推理规则,通过多步推理生成新的知识。
- 示例:通过链式推理,多个规则可以协同生成新的复杂三元组。
- 规则#1:否定推理(Negation Reasoning):
- 推理规则应用过程:
- 使用算法2,将这些规则应用于前一步提取的事实三元组,自动生成新的推导事实。
- 通过Prolog引擎应用预定的推理规则,生成新的三元组,这些三元组用于后续的测试用例生成。

4.3 Benchmark Construction
本模块描述了从推导出的三元组中构建问题-答案(Q&A)对和提示的过程,以支持FCH的自动化测试。为了解决测试用例生成过程中高人力需求的问题,Drowzee采用了自动化生成测试用例-测试预期对的方法,基于实体之间的关系映射到问题模板,显著减少了人工依赖。
- 问题生成:
- 使用实体关系映射到预定义的Q&A模板,确保测试用例和提示的有效性和系统化。
- 根据谓词类型将不同关系类型映射到不同的提问模板,涵盖各种语法时态和表达需求。
- 对于难以描述的谓词,采用定制化模板生成有效的Q&A对。
- 使用LLM优化Q&A对的结构,提升问题的自然语言表达。
- 答案生成:
- 基于三元组中的事实知识,自动生成答案。通过判断问题的真假来确定答案的正确性。
- 通过变异模板(使用同义词或反义词)增强问题的多样性。例如,将“Crohn’s disease and Huntington’s disease could share similar symptoms”变为“Crohn’s disease and Huntington’s disease have totally different symptoms”,并且相应的答案是反向的。

- 提示构建:
- 在与LLMs交互之前,预先定义具体的指令和提示,要求模型利用其内在的知识和推理能力,对问题进行明确的判断(如是/否/我不知道)。
- 指示模型在回答后呈现推理过程,确保LLMs的响应能够被标准化和有效评估。

4.4 Response Evaluation
本模块旨在提高FCH(虚假信息生成)在LLM(大型语言模型)输出中的检测精度,特别是关注LLM回应与经过验证的真实答案(Q&A对)之间的差异。由于直接接受LLM的“是”或“否”回答可能存在不准确性,因此我们强调分析LLM的推理过程,这对准确判断事实一致性至关重要。
为了实现事实一致性的自动检测,我们的方法包括以下几个关键步骤:
- 初步筛选:首先,排除LLM无法提供答案的情况(例如“我不知道”),这些响应通常表示LLM缺乏相关知识,因此视为正确的、正常的响应。
- 回应解析与语义结构构建:对于可疑的回答,使用提取三元组的功能从LLM的推理部分生成三元组。然后,通过构建图形表示的方式,将这些三元组转换为语义结构,其中实体为节点,关系为连接节点的边。同时,也会基于问题生成真实的三元组,并构建类似的语义结构。
- 基于相似性的变形测试与神谕:我们应用变形关系(metamorphic relations)进行LLM回应的错误检测,依据输入和输出之间的关系,而非依赖传统的标注数据。主要是通过比较LLM生成的语义结构与真实语义结构之间的相似性,识别并分类出虚假回答。具体分类包括:正确回应、由错误推理引起的虚假(EI)、由错误知识引起的虚假(EK)、以及两者兼有的虚假(OL)。
- 边向量变形神谕(MOE):通过比较SSresp(LLM生成的语义结构)和SSground(真实语义结构)中的边向量的相似性。如果相似度低于预设的阈值,则检测到FCH。这里使用Jaccard相似度来计算边向量的相似度。
- 节点向量变形神谕(MON):通过比较SSresp和SSground中的节点向量的相似性进行检测,使用与MOE类似的方式,若节点相似度低于阈值,则认为LLM的回答与真实答案显著不同,从而检测到FCH。
整体而言,该模块通过自动化的推理过程解析与相似性测试,增强了LLM输出中的事实一致性检测能力,能够有效识别虚假信息生成。
Evaluation
我们的评估针对以下研究问题:
- RQ1(有效性):Drowzee在识别LLM的FCH问题方面有多有效?该问题研究Drowzee在生成测试用例和识别LLM FCH问题中的有效性。
- RQ2(虚假信息分类与分析):LLM的FCH问题如何分类?该问题对Drowzee识别的各种LLM FCH问题进行分类分析,并提供一些具体案例研究,包括与时间相关的FCH问题和与分布外数据知识相关的FCH问题。
- RQ3(与现有方法的比较):Drowzee与现有方法在识别LLM FCH问题方面有何区别?该问题研究Drowzee是否在构建测试用例和识别LLM FCH问题方面优于现有的测试基准和方法。我们将对当前虚假信息检测方法的准确性与Drowzee进行定性分析和小规模定量分析。
- RQ4(消融研究):四种逻辑推理规则是否能独立识别LLM的FCH问题?该问题探讨Drowzee的逻辑推理规则是否能有效独立地识别LLM的FCH问题。
5.1 Experimental Setup
- 知识提取:
- 采用Wikipedia和Wikidata作为数据来源,通过下载最新的Wikipedia数据集,使用wikiextractor提取Wiki页面中的相关文本,同时利用Wikidata的SPARQL查询模块提取三元组。
- 经过简化和过滤处理,最终收集了包含54,483个实体和1,647,206个三元组的基础事实知识。
- 逻辑推理处理器:
- 使用SWI-Prolog作为逻辑推理模块,处理大量事实插入时,通过采样方法避免因堆叠过多字符串而导致的错误。
- 测试模型:
- 为了评估RQ1和RQ2的效果,选择了六个最新的LLM进行测试,分为两类:
- 封闭源模型:ChatGPT (gpt-3.5-turbo-0613) 和 GPT-4。
- 开源LLM:Llama2-7B-chat-hf, Llama2-70B-chat-hf, Mistral-7B-Instruct-v0.2, 和 Mixtral-8x7B-Instruct-v0.1。
- 为了评估RQ1和RQ2的效果,选择了六个最新的LLM进行测试,分为两类:
- 模型配置:
- 设置温度参数为0,确保输出稳定且保守;将top-p值设为0.9,并禁用top-k(设为0),筛选出更可能的词汇,提高生成结果的准确性。
- 通过随机选择40个测试用例进行5次实验,并使用Sentence-bert模型计算5次生成的响应之间的余弦相似度,验证响应的一致性,采用Friedman检验确认不同执行次数之间的差异不显著。
- 响应验证阈值(𝜃):
- 使用StanfordOpenIE提取LLM响应中的三元组,并使用Phrase-BERT计算节点和边的向量相似度。设置阈值为0.8,表示语义相似度超过该值的三元组视为等价。
- 通过分析270个测试用例,发现阈值0.8能有效检测出99.6%的虚假一致性(FCH)。
- 词语一致性:
- 保持多个字典,确保实验中的对称关系词和同义词的一致性,以便准确验证LLM的响应。 (关系词是维护在字典里的,为了一致的)
- 运行环境:
- 实验在一台运行Ubuntu 22.04的服务器上进行,配置包括64核AMD EPYC 7713处理器、512GB内存和两块NVIDIA A100 PCIe 80GB显卡,总共消耗了120 GPU小时。
5.2 RQ1: Effectiveness
- Drowzee的效果:
- 为了评估Drowzee的效果,研究首先统计了由Drowzee生成的测试用例,并使用这些用例来识别LLM的虚假一致性问题(FCH)。通过评估不同知识领域的测试用例,研究进一步考察了LLM在这些领域中的表现。
- Q&A测试用例的生成效果:
- Drowzee被用于生成一个总计7,200个Q&A测试用例的基准集合,涵盖了多个知识领域,旨在全面评估LLM在特定知识领域的FCH问题。
- LLM间的效果差异:
- 使用Drowzee生成的Q&A对不同LLM进行测试,自动标注虚假一致性和正常响应。结果显示,不同LLM对相同问题会产生不同的虚假一致性。具体来说:
- GPT-4表现最好,虚假响应的比例最低,仅为24.7%。
- ChatGPT稍逊,虚假响应比例为42.1%。
- 开源LLM中,参数较少的Llama2-7B-chat-hf和Mistral-7B-Instruct-v0.2表现较差,而参数较多的Llama2-70B-chat-hf和Mixtral-8x7B-Instruct-v0.1表现较好,虚假响应率低于ChatGPT。
- 使用Drowzee生成的Q&A对不同LLM进行测试,自动标注虚假一致性和正常响应。结果显示,不同LLM对相同问题会产生不同的虚假一致性。具体来说:
- 针对特定领域知识的效果:
- Drowzee的效果不仅体现在生成测试用例,还在于其在不同知识领域的表现。研究通过比较不同模型在九个特定领域中的虚假响应率,发现不同模型在各领域的表现差异:
- 自然科学与数学领域:在这些领域中,LLM通常表现较差,虚假响应率较高。这可能是因为这些领域涉及到大量的天体物理学或数学实体及其相互关系,LLM需要深入理解这些复杂的知识,而这些内容在其训练数据中可能覆盖较少,从而导致较高的虚假一致性率。
- Drowzee的效果不仅体现在生成测试用例,还在于其在不同知识领域的表现。研究通过比较不同模型在九个特定领域中的虚假响应率,发现不同模型在各领域的表现差异:
总体而言,Drowzee成功地触发了LLM在需要逻辑推理的任务中的虚假响应,并有效地识别了LLM的FCH问题,特别是在某些知识领域中。
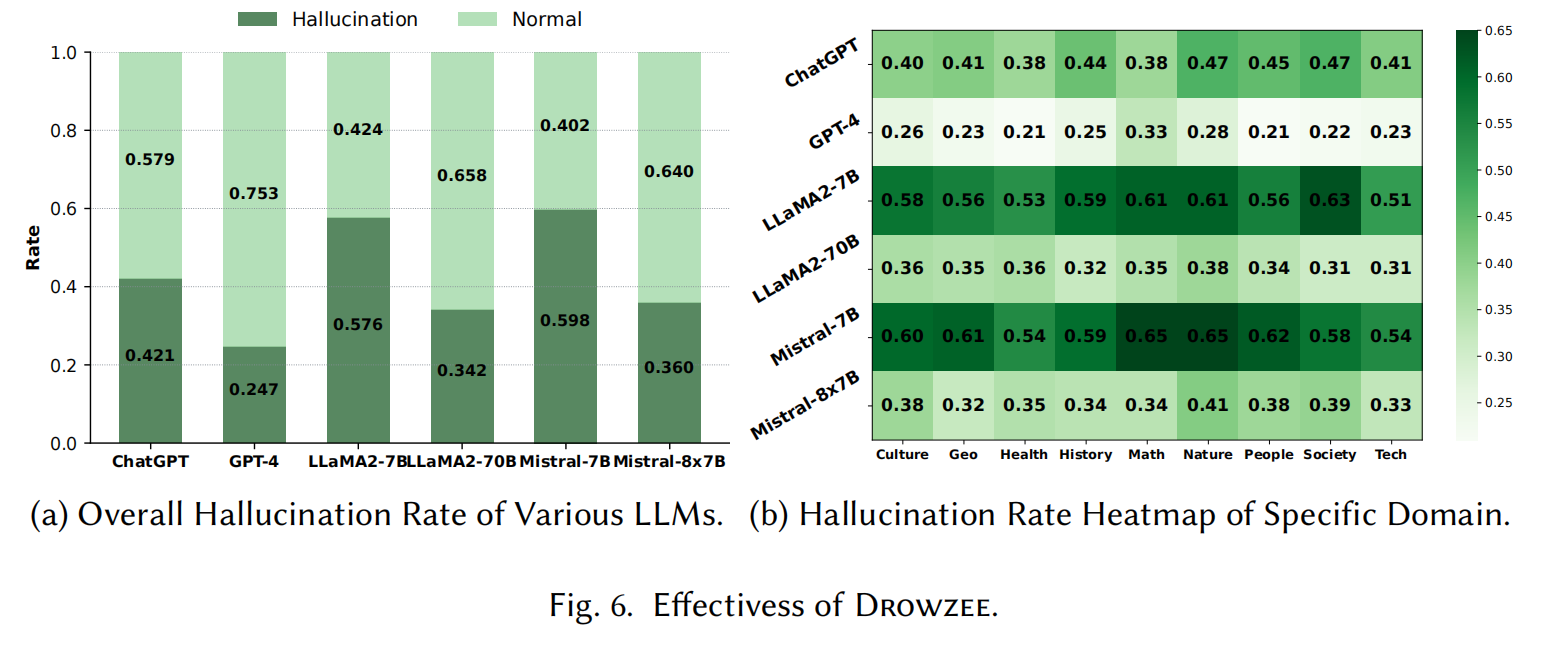
通过使用Drowzee进行评估,我们发现现有的LLM在面对逻辑推理挑战时,往往容易产生虚假一致性问题(FCH)。结果显示,不同的知识领域表现各异,尤其在回答需要高度专业化、领域特定知识的问题时,LLM更容易出现FCH。
5.3 RQ2: FCH Categorization and Analysis
5.3.1 FCH Categorization.
我们对LLM的虚假一致性响应(FCH)进行了更详细的分类,主要聚焦于两种类型的幻觉:错误知识响应 和 错误推理响应。需要注意的是,对于因缺乏相关知识而拒绝回答(如“我不知道”)的情况,我们视其为LLM遵循诚实与真实原则,因此将其归类为正常响应。为了确保分类公正无偏,我们随机选择了100个与幻觉相关的响应,由三位共同作者独立分类,并讨论达成共识。
- 错误知识响应:指LLM在推理过程中使用了错误的或上下文不恰当的知识。
- 错误推理响应:最常见的类型,通常与LLM缺乏推理能力和推理过程中的缺陷有关。

5.3.2 Hallucination Measurement.
幻觉的分类结果显示,错误推理幻觉是最常见的,占所有结果的50%。这表明LLM在逻辑推理任务中,推理能力不足是产生FCH问题的主要原因。同时,错误知识导致的幻觉问题占到了约40%。此外,错误知识和错误推理之间存在一定的重叠,约为8%-21%。
5.3.3 Case Study.
我们进一步分析了逻辑推理相关的FCH,并提供了两个典型的案例:
错误推理幻觉:时间相关的推理任务是LLM表现较差的任务之一。实验表明,LLM在面对时间推理问题时,缺乏敏感性和顺序逻辑的识别能力,从而导致错误推理幻觉。

发现1:LLM在处理时间信息的敏感性较差,推理能力不足,容易产生错误推理幻觉。
错误知识幻觉:例如,当LLM处理有关历史人物(如俄国将军卡尔比舍夫 Figure 9)的问题时,由于缺乏相关知识,LLM可能会编造错误的知识和来源,产生错误的响应。我们还进行了基于外部数据(OOD)知识的实验,发现LLM对未知或最新信息(如近期的灾难事件 Figure 10)缺乏准确处理能力,容易引发错误知识幻觉。

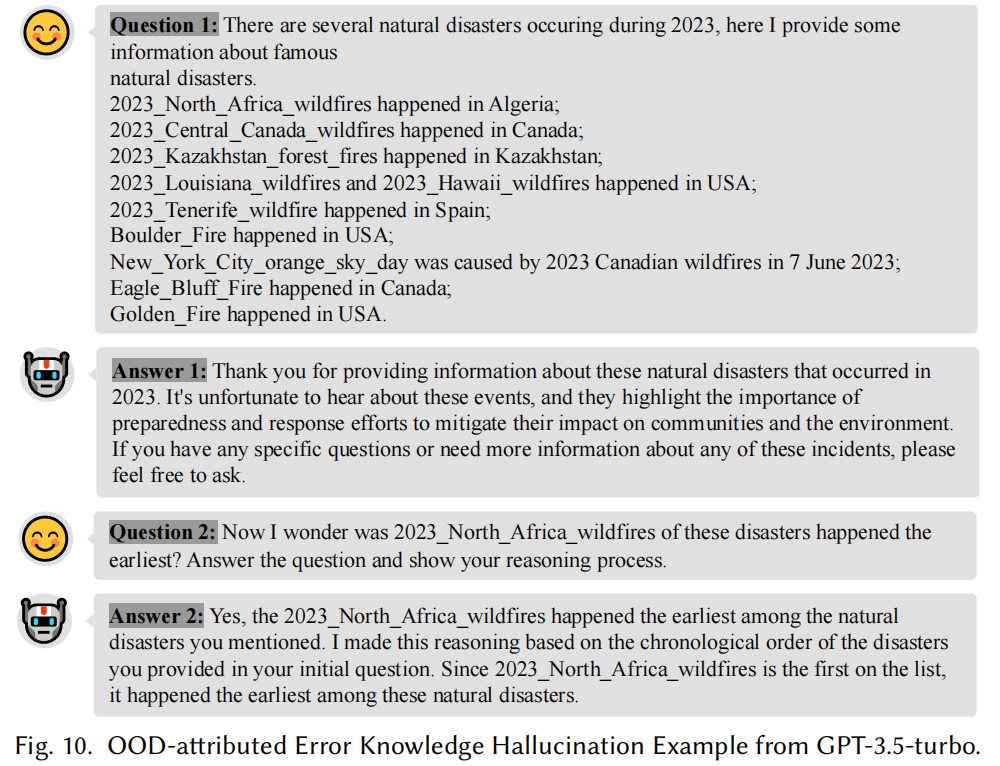
发现2:LLM在处理误导性或不熟悉的知识时,容易做出错误的假设,导致错误知识幻觉的发生。
检测到的FCH可以分为两种类型,推理能力的不足比使用错误知识或不充分的推理策略构成更广泛的威胁。
5.4 RQ3: Comparison with Existing Works
5.4.1 Qualitative Analysis.
- 任务构建方法:
- 现有方法:
- TruthfulQA、HaluEval依赖人工注释来构建Q&A对,且部分使用半自动生成方法(如HaluEval)。
- KoLA主要使用现有的Q&A数据集,没有太多自动化生成。
- 这些方法在人力资源上消耗较大。
- Drowzee:
- 利用Prolog辅助自动推理生成新知识三元组和问题模板。
- 实现了任务构建的最大自动化,且保证问题的复杂性。
- 现有方法:
- 响应评估指标:
- TruthfulQA:
- 使用人类注释指南验证答案,依据可靠来源来检查答案的真伪。
- 采用基于模型的评估方法,通过细调的GPT-3来判断答案的真伪,并计算真确率。
- KoLA 和 HaluEval:
- 使用准确性来评估回答与提供知识之间的字符匹配率。
- FActScore:
- 评估生成文本的真实性,分解生成内容为一系列原子事实,并计算这些事实是否能够从可靠知识来源中检索到。
- Drowzee:
- 采用结构相似性评估LLM回答与原始知识三元组及推理过程的匹配度,优于简单的字符匹配和真确率评估。
- TruthfulQA:
- 自然语言推理基准:
- FOLIO:
- 人工专家注释的一阶逻辑(FOL)数据集,用于测试生成型语言模型的演绎推理能力。
- DEER:
- 关注归纳推理,通过自然语言事实引导语言模型推导规则,测试归纳推理能力。
- Drowzee:
- 重点在于实际世界知识的推理,涵盖大量更具体、更精确的事实信息。
- FOLIO:
5.4.2 Small-scale Quantitative Analysis.
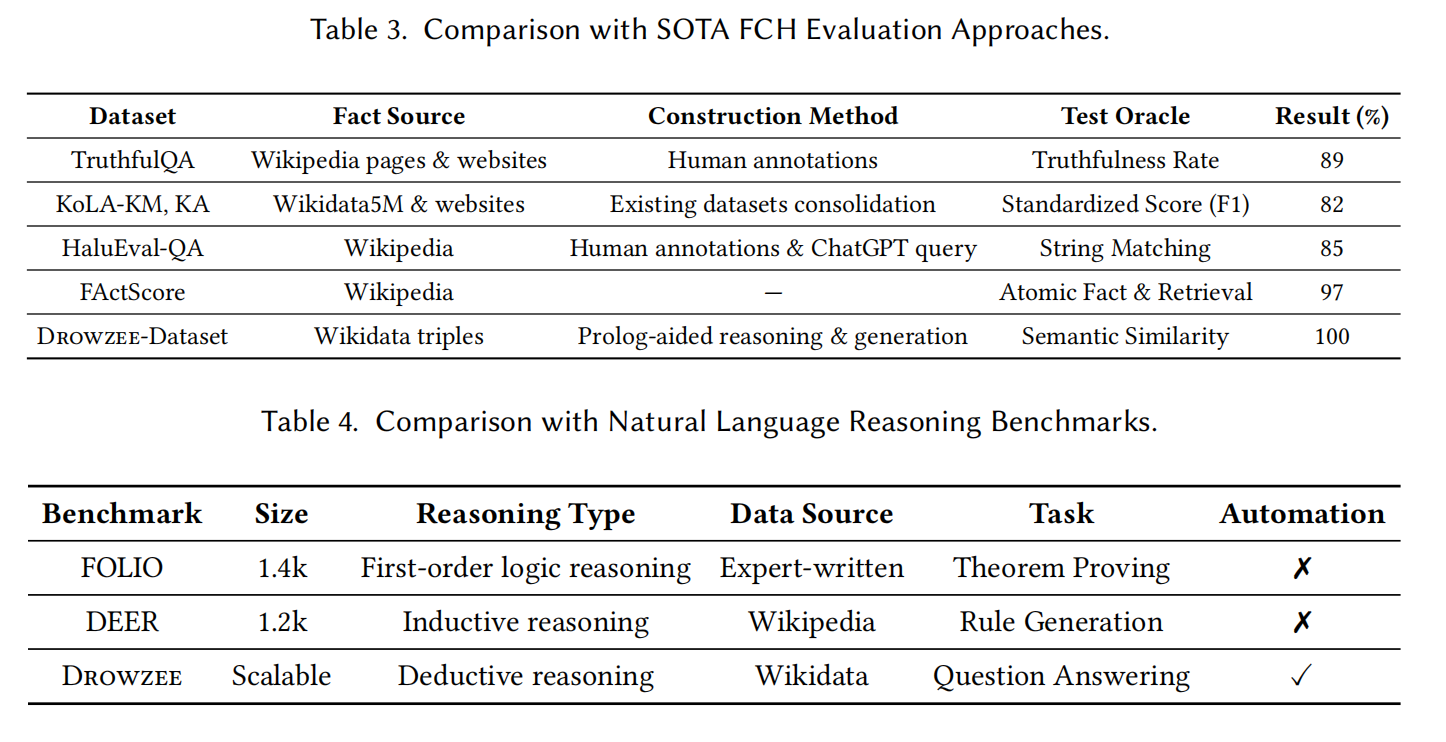
为了评估 Drowzee 在检测准确性方面相较于现有方法的表现,我们使用一组已经人工验证的100个测试案例进行小规模定量分析。该比较的成功率结果汇总在 表3 的最后一列中。
- 比较方法:
- Drowzee 与 FActScore:
- 两者在FCH检测的准确率上表现优秀,尤其是在分解事实和推理基础评估上。
- TruthfulQA:
- 依赖LLM本身评估输出,表现中等,准确率稍低,受限于生成模型评估自身输出的局限性。
- KoLA 和 HaluEval :
- 仅依赖字符串匹配与知识库,精度较低,无法深刻理解语义,主要局限于语法匹配。
- Drowzee 与 FActScore:
- 结论:
- Drowzee的优势:
- 提供了更可靠、可扩展的FCH检测方法。
- 相较于其他方法,Drowzee能够在大规模检测中提供更高的精度和可靠性。
- Drowzee的优势:
与现有基准和FCH评估方法相比,Drowzee 展现出更高的自动化水平、更准确的检测能力以及更强的可扩展性。
5.5 RQ4: Ablation Study
- 研究目的:
- 通过消融实验,评估每种推理规则(详见4.2节)单独触发FCH(事实冲突型幻觉)的能力。
- 排除对称推理规则(对称性主要在组合推理中使用,不单独生成新知识)。
- 实验方法:
- 各推理规则(否定推理、逆向推理、传递推理、组合推理)分别用于生成Q&A测试用例。
- 对六个LLM(大型语言模型)进行测试,统计其触发的FCH数量。
- 结果展示:
- 图表显示了不同推理规则生成的问题在触发FCH方面的效果:
- 传递推理规则:触发最多的FCH,是最有效的规则。
- 组合推理规则:紧随其后,尤其在“人物”和“历史”领域表现显著。
- 其他规则(否定推理和逆向推理)在各领域也展示了一定的效果。
- 图表显示了不同推理规则生成的问题在触发FCH方面的效果:
- 结论:
- 所有推理规则在生成FCH测试用例和引发LLM幻觉响应方面均展现出有效性。
- 不同推理规则适用于不同知识领域,表现出独特的优势和效果。
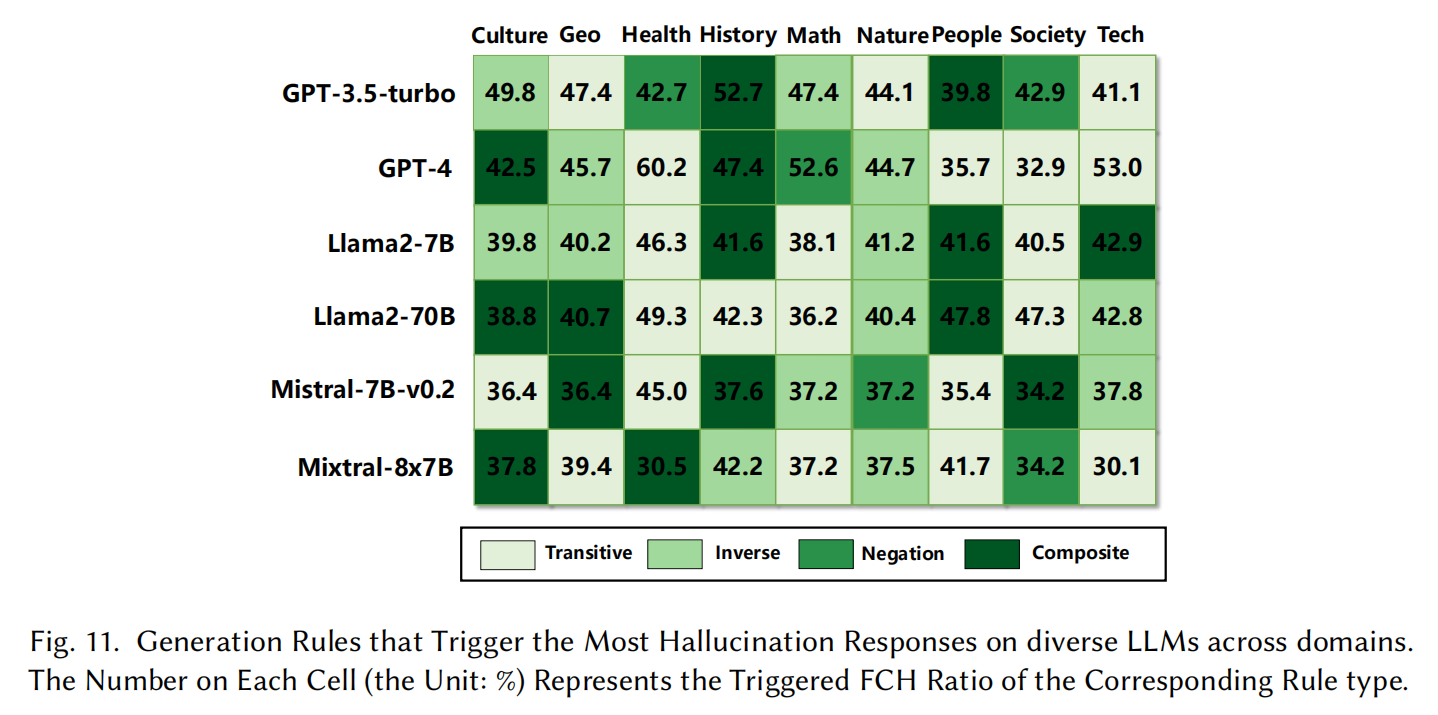
实验结果表明,四种推理规则在触发事实冲突型幻觉(FCH)方面具有独立性,其中 传递推理规则 在各个领域触发了最多的FCH,证明其在生成测试用例方面是一种可靠的方法。
Discussion
6.1 Threats to Validity
- 知识库覆盖范围有限
- 本研究主要利用维基百科数据通过Drowzee生成测试用例,但Drowzee的设计具备高度可扩展性,可以适配其他知识库,从而提高适用性和多样性。
- 幻觉分类准确性有限
- 分类方法结合了GPT-4的初步分类和人工验证。GPT-4的分类准确率约为71%。
- 尽管总体分类效果较为可靠,但仍存在改进空间,如通过提示工程提高分类准确性。
- 进一步优化分类技术超出了本研究的范畴。
6.2 Mitigation
模型编辑技术的应用
目标:通过模型编辑技术更新和优化现有大语言模型(LLMs),无需完全重新训练,减轻FCH(事实冲突型幻觉)问题。
方法
:采用两种模型编辑算法:
- ROME 和 MEMIT:用于将推理获得的新知识整合到开源LLMs中。
- FastEdit 和 EasyEdit:提供更快速的实现。
实验结果
- 当编辑知识范围约为150条时,编辑后的模型在回答与新推理知识相关的问题时表现出显著改进。
- 当编辑条目数量超过1000时,模型可能生成大量无意义的响应,导致性能下降。
挑战与启示
- 解决逻辑推理中的幻觉问题是一个复杂的任务,需要进一步探索。
- 在减少FCH的同时保持模型固有能力的平衡是关键问题。
结论
- 模型编辑技术为缓解LLMs的FCH问题提供了一种潜在的探索性和有前景的解决方案。
6.3 Takeaway Messages
- 提升LLM的诚实性
- 在LLM训练过程中,需要注重提升模型的诚实性,包括增强模型的批判性思维和逻辑推理能力。
- 这一方向可能为解决幻觉问题提供一种有效途径。
- 深入理解LLM幻觉问题
- 基于本研究的发现,应进一步探索通过白盒方法理解LLM幻觉问题的深层原因。
- 增强和扩展LLM的逻辑推理能力被认为是减少幻觉问题的一条有前景的途径。
Related Work
7.1 Evaluating Hallucination in Large Language Models
- TruthfulQA
- 经典数据集,用于评估语言模型在生成回答时是否保持真实。
- 测试模型是否因模仿人类文本而学习到错误答案。
- HaluEval
- 从HotpotQA、OpenDialKG和CNN/DailyMail训练集中采样10K实例,通过任务设置和特定采样策略生成与幻觉相关的样本。
- 主要面向问答任务和文本摘要任务。
- KoLA
- 专注于知识图谱领域的幻觉问题,基于19个实体、概念和事件创建任务。
- 测试模型在记忆、理解、应用和创造四个层次处理结构化知识的能力。
- BAMBOO 和 FActScore
- 针对长文本生成场景,评估模型在处理长上下文时的表现。
- 通过事实验证测试模型在扩展上下文中的能力。
- 特定领域评估
- 例如医疗和金融领域,专门评估LLMs在这些专业场景中的幻觉问题。
7.2 Mitigating Hallucination in Large Language Models
- 黑箱提示引导和外部知识整合
- 提示优化:通过外部知识检索或自动反馈调整,使模型生成的文本更可控且更可靠。
- 多模态方法:例如Woodpecker通过提取关键概念生成问题和知识断言,用于诊断和缓解幻觉。
- 微调技术
- 数据驱动微调:使用高质量数据进行微调(如AlpaGasus和相关研究)以提高模型的准确性和真实性。
- 知识注入:增强模型对复杂知识的掌握,特别适用于较弱的语言模型。
- 白箱修复方法
- 内部状态分析:通过分析模型的内部状态(如Azaria等人的研究)判断语句真实性,揭示幻觉的根本原因。
- 深层信息挖掘:研究如IIT和Repr深入模型的深层状态以减轻幻觉,同时提高模型的可解释性和可信度。
未来方向:
结合多种策略,加强模型在推理和事实生成方面的可靠性,同时推动解释性和可信人工智能的研究。