
Fuzzing JavaScript Interpreters with Coverage-Guided Reinforcement Learning for LLM-Based Mutation
Fuzzing JavaScript Interpreters with Coverage-Guided Reinforcement Learning for LLM-Based Mutation
Abstract
JavaScript解释器对现代网络浏览器至关重要,需要一种有效的Fuzzing方法来识别安全相关的漏洞。然而,输入的严格语法要求呈现出重大挑战。最近将语言模型整合到上下文感知的突变Fuzzing中的努力是有前景的,但缺乏必要的覆盖指导以充分发挥效用。本文提出了一种新的技术,名为CovRL(基于覆盖率的强化学习),它将大型语言模型(LLMs)与基于覆盖反馈的强化学习(RL)相结合。我们的Fuzzer,CovRL-Fuzz,通过利用词频-逆文档频率(TF-IDF)方法将覆盖反馈直接整合到LLM中,构建了一个加权覆盖图。该图是计算Fuzzing奖励的关键,然后将此奖励应用于基于LLM的突变器通过强化学习。CovRL-Fuzz通过这种方法,能够生成更有可能发现新覆盖区域的测试用例,从而提高漏洞检测效率,同时最小化语法和语义错误,而无需额外后处理。我们的评估结果表明,CovRL-Fuzz在增强代码覆盖和识别JavaScript解释器中的漏洞方面超越了现有最先进的Fuzzer:CovRL-Fuzz在最新的JavaScript解释器中识别了58个实际安全相关的漏洞,其中包括50个以前未知的漏洞和15个CVEs。
Introduction
Traditional Method for fuzzing
JavaScript解释器对于现代Web和嵌入式应用至关重要,负责解析、编译和执行JavaScript代码。
JavaScript作为客户端编程语言,在全球范围内被广泛使用,确保其解释器的安全性至关重要。
解释器中的漏洞可能导致严重的安全威胁,如信息泄露和安全措施的绕过。
JavaScript解释器模糊测试的两种主要方法:
- 语法层次模糊测试:生成语法正确的输入,确保符合语法规则。
- 词法层次模糊测试:通过操作令牌序列,采取更灵活的方法,不严格遵循语法规则。
模糊测试的目标:
- 通过覆盖率引导模糊测试(如AFL)来提高模糊测试的有效性,促进代码路径的全面检测。
面临的挑战:
- JavaScript语言的不断演变:JavaScript的语法持续更新,给模糊测试带来显著挑战。
- 语法层次模糊测试的局限性:过于关注语法规则,限制了变异的多样性,可能减少程序路径的探索。
- 词法层次模糊测试的难点:灵活性较高,但在多次变异过程中,容易产生语法错误,影响更深层次错误的发现。
模糊测试的优缺点:
- 语法层次模糊测试:能生成符合语法规则的输入,但限制了变异的多样性。
- 词法层次模糊测试:更灵活,能够产生更多变异,但难以保持语法正确性,可能导致语法错误。
LLM for Fuzz
新进展:LLM(大语言模型)在模糊测试中的应用:
- 采用LLM生成语法正确、符合上下文的输入,提升了编译器和JavaScript解释器的模糊测试效果。
- 例如,Fuzz4All利用预训练的代码LLM进行编译器模糊测试,这些模型基于广泛的编程语言数据集进行训练,能够生成语法正确且具有上下文相关性的输入。
LLM在模糊测试中的优势:
- 不需要额外微调即可应用LLM进行变异,能够增强模糊测试的有效性。
- LLM能够理解语言的上下文,生成语法准确且语义相关的输入。
现有LLM模糊测试方法的局限性:
- 当前的LLM模糊测试方法通常是黑盒模糊测试,缺乏与程序内部信息(如代码覆盖率)的集成。
与覆盖率引导模糊测试的对比:
- 覆盖率引导模糊测试利用程序内部数据(如代码覆盖率)来增强模糊测试效果,采用进化策略生成“有趣”的种子,推动程序覆盖的扩展,从而提高发现bug的几率。
- 覆盖率引导模糊测试比传统的黑盒模糊测试更高效,但这种方法也面临一定挑战。
Problem
LLM基于的突变器的操作:
- LLM通常在词语层面生成句子,因此基于LLM的突变操作通常假定在令牌级别进行。
对传统突变器的替代:
- 用预训练的LLM突变器替代传统的随机突变器在覆盖率引导的Fuzzing中可以减少错误率,但没有显著提高覆盖率。
实验结果:
- 使用AFL Fuzzing工具的实验结果显示,在V8引擎上进行五小时的测试,使用LLM突变器通常会导致比基线低12-16%的覆盖率。即使在覆盖率有所提升的情况下,增长也很小。
突变器的局限性:
- LLM基于的突变器虽然减少了错误,但由于其预测受限,可能会限制输入的多样性和整体效果。
多样性和有效性的考量:
- 基于LLM的突变器通常聚焦于上下文,倾向于预测常见的令牌,这无意中减少了突变的多样性。这与以语法准确性为目标的语法级突变类似,后者也会限制变体的多样性。
结论:
- 尽管LLM基于的突变器减少了错误,其对多样性的降低使得它们在实际应用中可能不如随机Fuzzing有效。

Approach
- 提出的新方法:CovRL-Fuzz:
- 旨在解决LLM(大语言模型)变异方法的局限性,提出一种新的技术,将覆盖率引导反馈直接整合到变异过程中。
- 该方法利用程序的内部信息,通过强化学习(使用TF-IDF)来增强模糊测试的效果。
- CovRL-Fuzz通过直接向LLM提供代码覆盖率反馈和奖励机制,突破了仅注重语法正确性的限制,生成多样化的变异,增强了BUG检测能力。
- CovRL-Fuzz的优势:
- 与其他LLM模糊测试方法不同,CovRL-Fuzz是首个将LLM变异与覆盖率引导模糊测试有效结合的方法。
- 该方法无需额外的后处理,提升了覆盖率并改善了BUG检测能力。
- 贡献:
- 引入了CovRL方法,通过强化学习结合代码覆盖率反馈并使用TF-IDF权重。
- 实现了CovRL-Fuzz,一个新的JavaScript解释器模糊测试工具,在代码覆盖率和BUG检测方面优于现有方法。
- CovRL-Fuzz发现了58个实际的安全相关BUG,其中包括50个未知BUG(15个CVE)。
- 发布了CovRL-Fuzz的实现,供未来研究使用:GitHub链接。
Background
2.1 JavaScript Interpreter Fuzzing
JavaScript解释器模糊测试的挑战:
- 模糊测试是一种强大的自动化方法,用于发现软件缺陷,但在JavaScript解释器中面临挑战,主要因为输入必须严格符合语法。
- 如果输入语法不正确,解释器会返回语法错误;而语义错误(如引用、类型、范围或URI错误)可能导致语义错误,但在这两种情况下,解释器的内部逻辑未被执行。
模糊测试方法:
- 语法层次模糊测试:通过将种子转换为中间表示(IR),确保语法正确性,但过于依赖语法规则,限制了变异多样性,难以发现由于语法违反或意外输入模式引起的BUG。 –> 对标Squirrel
- 词法层次模糊测试:通过将输入分解为令牌并选择性替换,提供了更大的灵活性,增强了BUG检测能力。然而,由于随机替换令牌的方法,它通常难以保持语法正确性,因为未考虑令牌之间的关系。 –> 对标AFL 框架
LLM(大语言模型)在模糊测试中的应用:
- 最近,深度学习中的语言模型(LM)被用于克服传统方法的局限性。最初使用基于RNN的LM进行种子变异,现在使用像GPT和StarCoder等LLM进行种子生成和变异,这些模型经过大量编程语言数据集的训练。
覆盖率引导模糊测试:
- 覆盖率引导模糊测试利用覆盖率反馈探索多样的代码路径,相比传统黑盒方法,已被证明更有效于发现软件BUG,特别是在安全漏洞检测中。
- AFL等工具通过突变最大化代码覆盖率,取得了显著成效。
LLM模糊测试的局限性:
- 现有的LLM模糊测试方法(如COMFORT和Fuzz4All)主要使用黑盒方法,未能将覆盖率引导模糊测试与JavaScript解释器结合,因为这些方法通常不将覆盖率反馈纳入变异过程。
2.2 Large Language Models for Code
LLM在编程语言中的应用:
- 随着LLM在自然语言处理(NLP)任务中的成功,大型语言模型(Code-LLMs)**在编程语言领域也取得了显著进展,如**CodeT5+、Codex**、InCoder和StarCoder**等。
- 这些进展推动了代码补全、程序合成、程序修复等多种下游任务的发展。
LLM在模糊测试中的变异应用:
- Code-LLMs在模糊测试中表现出了高效的种子生成和变异能力,变异方法可分为两类:
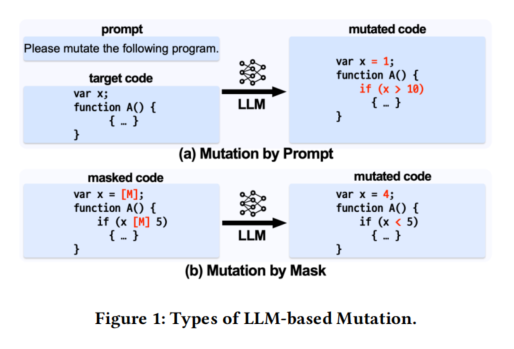
- 通过提示变异 Mutation by prompt:将代码和变异请求提示输入预训练的Code-LLM,生成变异后的种子。
- 通过掩码变异 Mutation by mask:在代码中插入或替换掩码,让模型仅填写部分代码,进行更精确的变异。
通过掩码变异的优势:
- 在覆盖率引导模糊测试中采用掩码变异,它能够保持代码结构的完整性,同时对特定令牌进行变异,逐步增加覆盖率,探索新的代码路径,并节省资源。
- 相较于通过提示进行的变异,掩码变异能够实现更精准的调整。
LLM的微调方法:
- LLM的微调方法包括:监督微调(SFT)、指令微调和基于强化学习的微调(RL)。
- RL微调通过反馈优化模型的输出效果,已被证明在提高事实一致性和减少有害生成方面有效。最近有研究将RL微调应用于Code-LLMs,以生成不仅语法正确而且能够解决复杂编码任务的单元测试。
RL微调的步骤:
- 奖励建模:训练基于LLM的奖励模型,评估输出结果的适宜性。奖励可以通过多种方式进行反馈,如使用oracle、深度学习模型或人类反馈。
- 强化学习:常采用基于KL散度的优化方法,优化奖励的最大化与训练分布的偏差最小化之间的平衡。

Design
CovRL-Fuzz的设计:
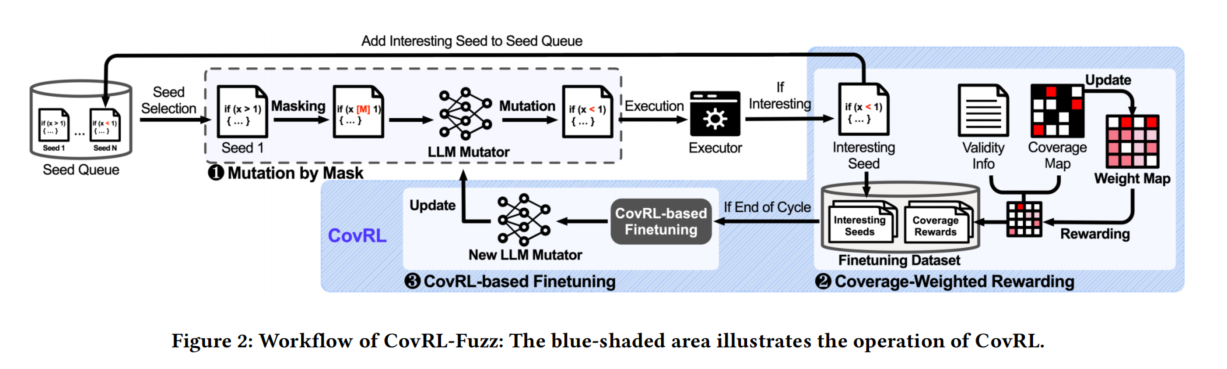
- CovRL-Fuzz的核心成就在于将覆盖率引导反馈直接集成到LLM(大语言模型)变异过程中,使得变异不仅语法正确,还具有多样性,从而提升模糊测试效果。
CovRL-Fuzz的工作流程:
- CovRL-Fuzz的流程分为三个阶段,基于覆盖率引导模糊测试:
- 选择种子:从种子队列中选择一个种子,进行LLM变异。使用掩码变异方法对特定令牌进行掩码预测,生成新的测试用例。
- 执行与覆盖率反馈:执行变异后的测试用例,如果发现新覆盖的代码路径,则将其视为有趣种子,加入种子队列继续变异。同时记录覆盖率地图和测试用例的有效性(是否出现语法或语义错误)。
- 奖励与微调:基于有效性信息对产生语法或语义错误的输入进行惩罚,并根据覆盖率地图生成奖励信号。通过覆盖率加权的奖励信号,对LLM进行微调,使用PPO算法来优化模型,避免语法和语义错误,促进发现新的代码路径。
优化与微调:
- CovRL-Fuzz在变异过程中仅使用CovRL微调,没有进行额外的启发式后处理。通过奖励信号引导LLM优化,减少错误率,进一步提高代码覆盖率。
效果:
- 在第5.2节中,实验结果显示,使用CovRL进行微调的错误率低,与其他最新的JavaScript解释器模糊测试技术相当。
3.1 Phase 1. Mutation by Mask
这段内容可以概括为以下几点:
- 掩码变异策略:
- CovRL-Fuzz在第一阶段通过掩码变异对种子进行处理,采用三种主要技术:
- 插入(Insert):随机选择位置,将
[MASK]插入输入中。 - 覆盖(Overwrite):随机选择位置,用
[MASK]替换已有令牌。 - 拼接(Splice):将种子分段,一部分替换为另一个种子的片段,用
[MASK]标记替换的位置。
- 插入(Insert):随机选择位置,将
- CovRL-Fuzz在第一阶段通过掩码变异对种子进行处理,采用三种主要技术:
- 掩码变异过程:
- 输入序列通过掩码策略生成掩码序列 W \MASK。
- 使用基于LLM的掩码语言模型(MLM)推断掩码位置的内容,生成变异后的种子。
- MLM的设计与损失函数:
- CovRL-Fuzz的变异设计基于能够预测可变长度掩码的MLM。
- MLM的损失函数表示为:
- 目标:
- 通过优化模型参数,改进变异生成过程,同时保持种子的结构完整性并探索新的代码路径。

3.2 Phase 2. Coverage-Weighted Rewarding
这段话主要描述了 CovRL-Fuzz 第二阶段的覆盖率加权奖励方法 (Coverage-Weighted Rewarding, CWR) 的设计和实现。以下是详细概括及对每个例子的解释:
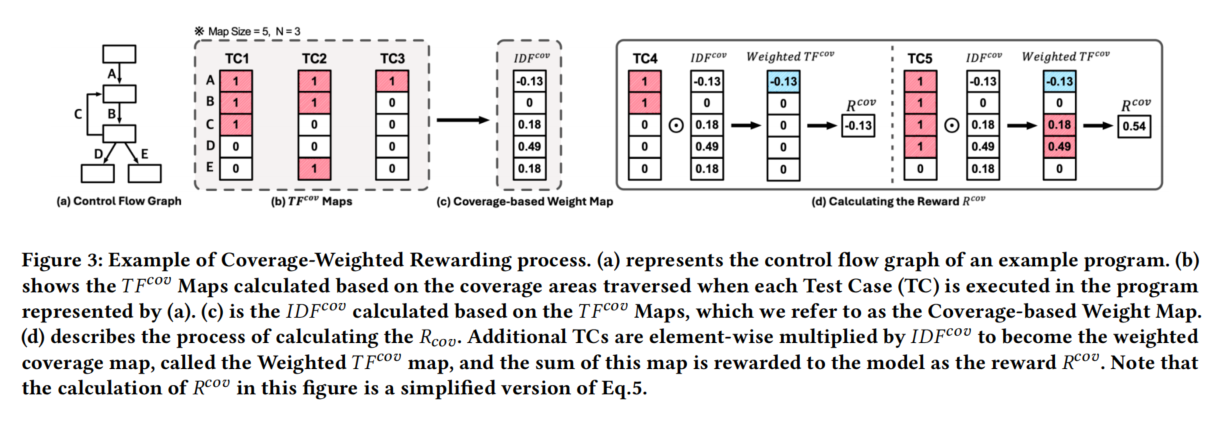
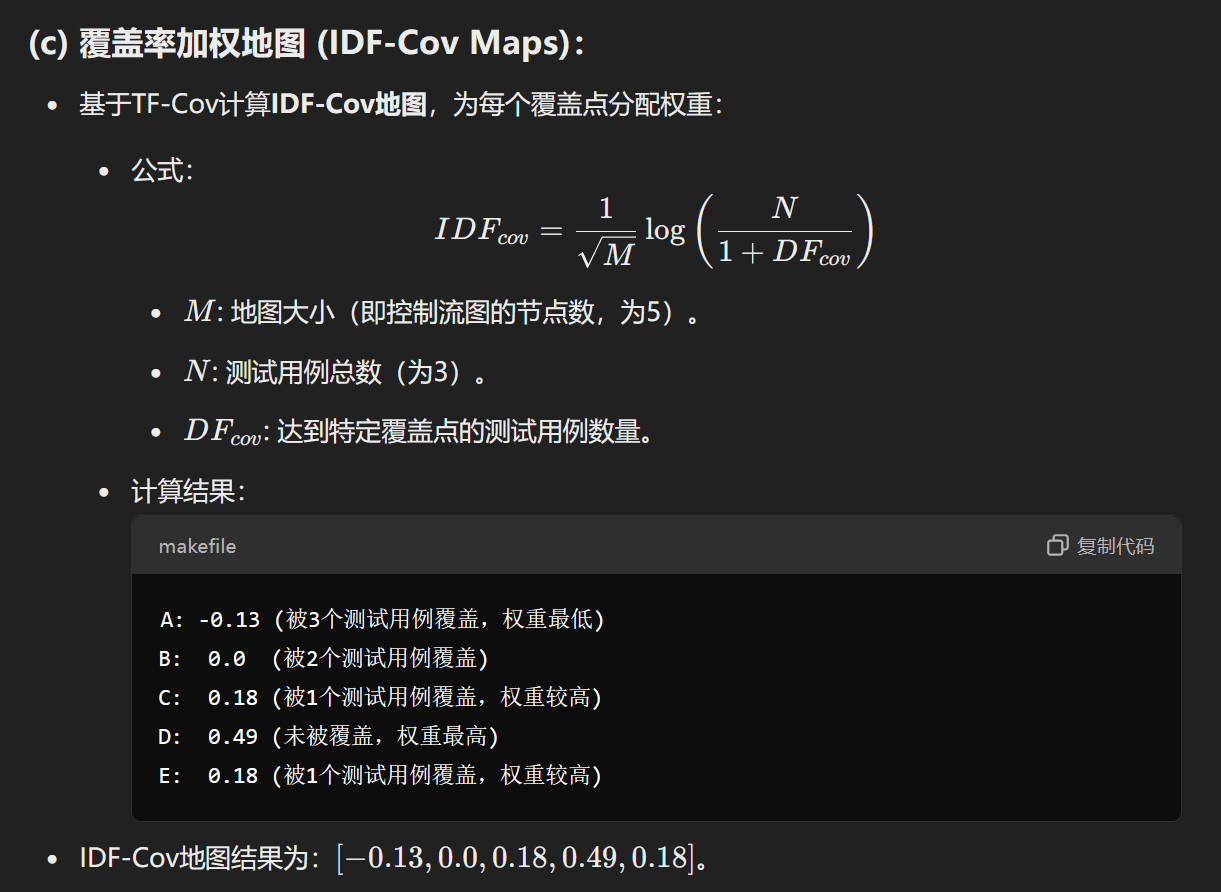
覆盖率加权奖励方法的核心思想:
目标:引导LLM变异器生成测试用例,探索更多未被覆盖的代码路径。
TF-IDF的作用:
- 使用TF-IDF方法为覆盖率点赋权。
- 罕见的覆盖点被赋予更高权重,而频繁出现的覆盖点权重较低。
- 通过这一方法创建加权覆盖率地图,强调对未充分探索区域的检测。
错误分类与奖励机制:
奖励机制根据输入测试用例的结果进行奖励或惩罚:
- 语法错误:奖励值为-1.0(惩罚)。
- 语义错误(包括引用、类型、范围或URI错误):奖励值为-0.5(轻惩罚)。
- 通过测试:奖励值为RcovR_{cov}Rcov,即覆盖率奖励信号。
示例1:在控制流图(CFG)中,程序执行覆盖了一些代码路径(如分支D、E和循环C)。奖励信号根据覆盖率点的稀有性动态调整,以更有效地引导变异器发现未被探索的代码。




3.3 Phase 3. CovRL-Based Finetuning




总结
- CovRL-Based Finetuning 通过强化学习优化变异器,结合覆盖率奖励和KL正则项,确保生成的测试用例具有语法正确性和更大的代码覆盖率。
- 模糊测试循环逐步迭代,基于奖励信号不断更新奖励器和变异器,提高模糊测试的效率和效果。
Implementation
实现框架
- 使用以下工具和库实现了 CovRL-Fuzz 的原型:
- PyTorch v2.0.0
- Transformers v4.38.2
- AFL 2.52b 作为基础。
数据集
- 数据来源:
- 来自多个JavaScript解释器的回归测试套件,包括 V8、JavaScriptCore、ChakraCore、JerryScript、Test262 和 js-vuln-db。
- 截止到2022年12月,共收集了 52K 个独特的JavaScript文件。
- 数据处理:
- 删除注释、过滤语法错误、简化标识符。
- 使用 UglifyJS 工具的
-m和-b参数进行预处理。
训练
- 模型选择:
- 使用 CodeT5+ (220M) 作为预训练的Code-LLM,既充当变异器(Mutator)又作为奖励器(Rewarder)。
- 微调(Finetuning):
- 每次变异循环训练1个epoch。
- 批量大小:256。
- 学习率:1×10−41 \times 10^{-4}1×10−4,使用AdamW优化器并结合学习率线性预热(Linear Warmup)。
- 奖励器训练:
- 奖励器通过 CodeT5+ 的编码器,采用分类方法预测奖励信号。
- 使用对比搜索(Contrastive Search),引入动量因子 (α=0.6\alpha = 0.6α=0.6) 和 top-k 值设定为32。
- 覆盖率地图设置:
- 覆盖率地图大小与AFL的建议一致,使用缩放因子 M。
- 中等规模软件(约10K行代码):地图大小为 2162^{16}216。
- 大型软件(超过50K行代码):地图大小为 2172^{17}217,在粒度和性能之间实现平衡。
- 覆盖率地图大小与AFL的建议一致,使用缩放因子 M。
关键参数
- 微调周期、动量因子 (α\alphaα) 和其他超参数的详细分析请参考附录。
总结
- CovRL-Fuzz 的实现依赖预处理过的JavaScript数据集和预训练的CodeT5+模型,结合AFL工具优化覆盖率地图的设置。
- 使用先进的训练方法(如对比搜索和AdamW优化器)和精确的覆盖率调整,实现了高效的模糊测试工具。
Evaluation
在评估 CovRL-Fuzz 时,设置了以下四个研究问题(RQs):
- RQ1:CovRL-Fuzz 是否比其他 JavaScript 解释器模糊测试工具更高效?
- RQ2:CovRL-Fuzz 是否比其他基于 LLM 变异的模糊测试工具更高效?
- RQ3:CovRL-Fuzz 的各个组件如何分别对其高效性作出贡献?
- RQ4:CovRL-Fuzz 是否能够发现 JavaScript 解释器中的真实漏洞?
5.1 Experimental Design
实验设置:
- 系统环境:
- 操作系统:64位 Ubuntu 20.04 LTS。
- 硬件:Intel Xeon Gold 6134 CPU (64核),3张 NVIDIA GeForce RTX 3090 GPU。
- 测试对象:
- 主要测试的4个 JavaScript 解释器(截至2023年1月的最新版本):
- JavaScriptCore (2.38.1)
- ChakraCore (1.13.0.0-beta)
- V8 (11.4.73)
- JerryScript (3.0.0)
- 额外测试的5个 JavaScript 解释器(用于真实漏洞检测实验):
- QuickJS (2021-03-27), Jsish (3.5.0), escargot (bd95de3c), Espruino (2v20), Hermes (0.12.0)。
- 配置:每个解释器均启用了 Address Sanitizer (ASAN) 和调试模式,用于检测内存访问错误和未定义行为。
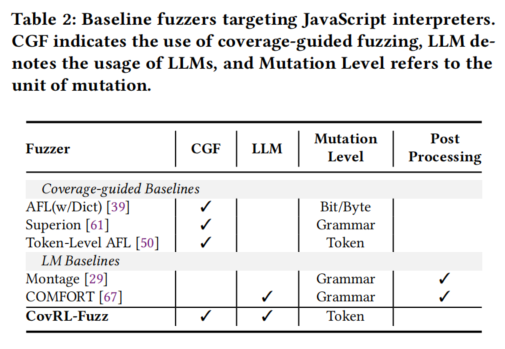
- 主要测试的4个 JavaScript 解释器(截至2023年1月的最新版本):
模糊测试流程:
- 种子集:所有实验使用相同的100个有效种子。
- CPU核心使用:
- RQ1、RQ2 和 RQ4:使用3个CPU核心。
- RQ3:使用1个CPU核心。
- 重复实验:每个模糊测试工具运行5次,并取覆盖率结果的平均值。
- 微调时间:
- 每2.5小时进行一次微调,平均每次耗时10分钟。
- 默认配置:所有工具均在解释器的默认配置下运行。
评价指标:
- **代码覆盖率 (Code Coverage)**:
- 表示测试用例执行到的代码范围。
- 使用来自AFL的边覆盖率(bitmap),并分为两类:
- 总覆盖率:所有测试用例的覆盖范围。
- 有效覆盖率:仅统计有效测试用例的覆盖范围。
- 使用 Mann-Whitney U-test 检测统计显著性,确保 p 值均小于 0.05。
- **错误率 (Error Rate)**:
- 测量生成测试用例中的语法错误和语义错误。
- 提供每种方法探索目标软件核心逻辑的有效性。
- 语义错误分类:
- 类型错误、引用错误、URI错误和内部错误(基于ECMA标准)。
- 测量方法:
- 使用 JavaScript 解释器直接测量语法和语义错误率。
- 与 COMFORT 的方法不同(仅使用 jshint 测量语法错误)。
- **漏洞检测 (Bug Detection)**:
- 衡量模糊测试工具发现漏洞的能力。
5.2 RQ1. Comparison with Existing Fuzzers
实验目标
评估 CovRL-Fuzz 相对于其他 JavaScript 解释器模糊测试工具(覆盖率引导和基于LLM的工具)的性能,包括:
- 代码覆盖率
- 语法和语义错误率
- 漏洞检测能力
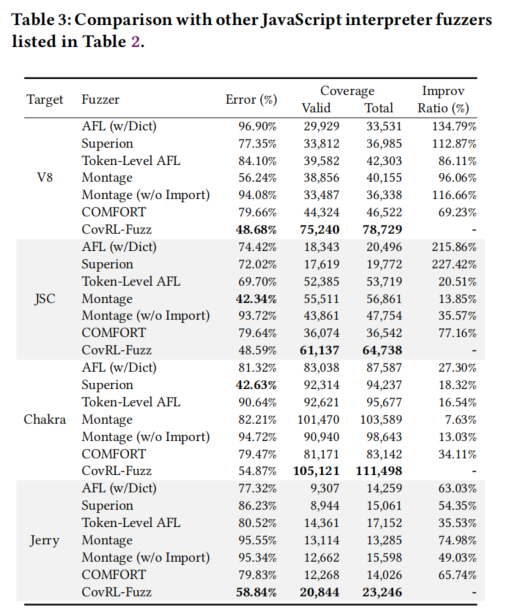
实验结果
1. 代码覆盖率 (Code Coverage)
- CovRL-Fuzz 的表现:
- 在所有目标解释器中实现了最高的覆盖率。
- 平均覆盖率增长:
- 边覆盖率分别提高 **102.62%/98.40%/19.49%/57.11%**(针对不同解释器)。
- 覆盖率增长趋势(如图4所示):CovRL-Fuzz 在每次实验中都能更快达到更高的覆盖率,与其他模糊测试工具相比显著优于覆盖率引导和LLM基线。
- 与 Montage 的对比:
- Montage 的代码导入策略使得其覆盖率较高,但当移除代码导入功能(Montage w/o Import)后,CovRL-Fuzz 的覆盖率明显高于 Montage。
- CovRL-Fuzz 的覆盖率随时间持续增长,而 Montage 的覆盖率趋于收敛。
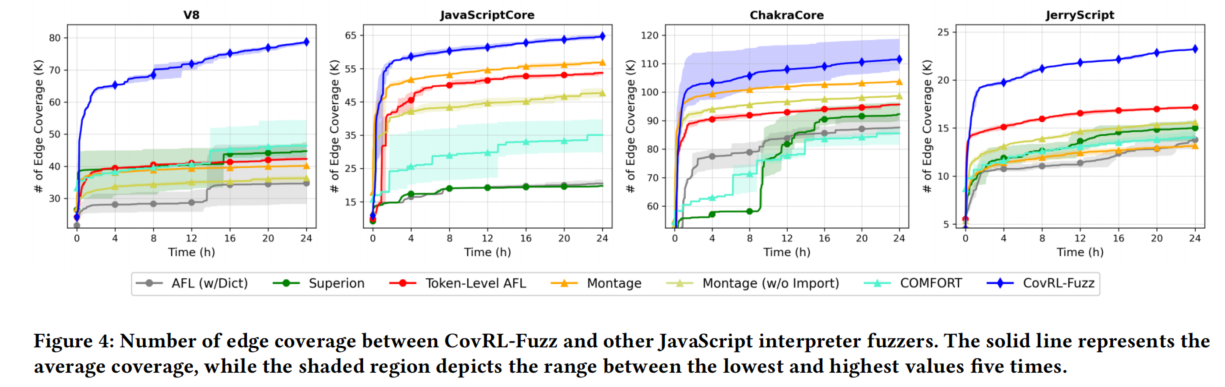
2. 语法和语义错误率 (Syntax and Semantic Correctness)
- CovRL-Fuzz 无需后处理即可获得较低的错误率:
- 与 Token-Level AFL 比较:CovRL-Fuzz 的错误率显著更低。
- 与其他模糊测试工具比较:在大多数工具中表现更优,但在 JavaScriptCore 和 ChakraCore 上未达到最低错误率。
- 错误类型分析(如图5所示):
- CovRL-Fuzz 触发的语法错误少于覆盖率引导工具。
- 与 LLM 基线工具相比,CovRL-Fuzz 即使不进行后处理,语法和语义错误也更少。
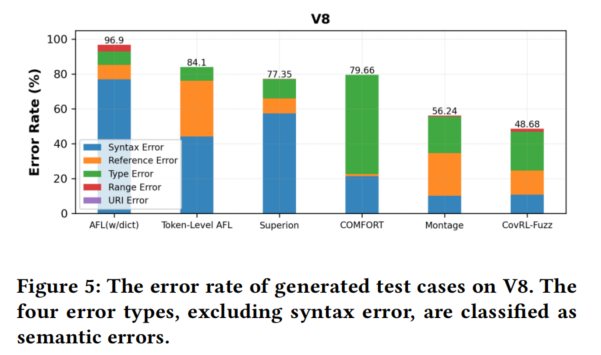
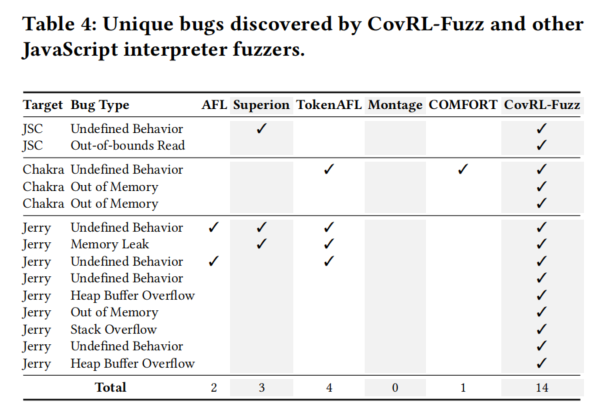
3. 漏洞检测能力 (Finding Bugs)
- 漏洞发现:
- CovRL-Fuzz 在调试模式下发现了最多的独特漏洞(14个),其中9个是仅由 CovRL-Fuzz 检测到的,包括栈溢出和堆缓冲区溢出。
- 趋势分析:
- LLM工具通常覆盖率较高但发现的漏洞较少。
- 启发式工具覆盖率较低但发现的漏洞更多。
- CovRL-Fuzz 同时在覆盖率和漏洞检测方面表现出色,打破了上述趋势。
结论
CovRL-Fuzz 在代码覆盖率、语法与语义正确性以及漏洞检测能力方面显著优于其他模糊测试工具,展示了其综合性能和实用性:
- 覆盖率:持续增长并达到最高值。
- 错误率:无需后处理即实现较低错误率。
- 漏洞发现:发现最多的独特漏洞,特别是复杂类型漏洞。
5.3 RQ2. Comparison of Fuzzers Using LLM-Based Mutation
实验目标
比较 CovRL-Fuzz 与现有基于LLM变异的模糊测试工具(如 Fuzz4All)在覆盖率、错误率和漏洞检测方面的表现。由于 TitanFuzz 和 FuzzGPT 的变异方法专为深度学习库设计,难以直接应用于 JavaScript 解释器,因此未纳入对比。
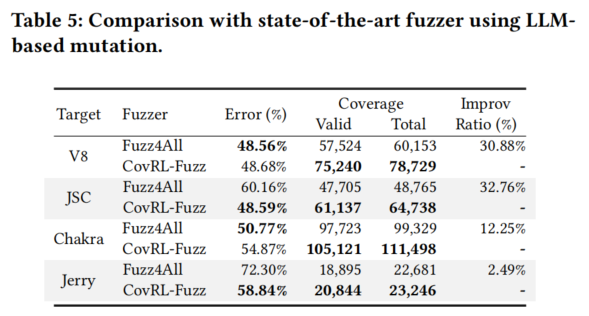
实验结果
- 代码覆盖率和错误率:
- 结果对比(表5):
- CovRL-Fuzz 和 Fuzz4All 的覆盖率和错误率没有显著差异。
- Fuzz4All 的覆盖率和错误率虽然与 CovRL-Fuzz 接近,但其覆盖率提升和错误率的降低未显著提升漏洞检测能力。
- 结果对比(表5):
- 漏洞检测能力:
- 结果对比(表6):
- CovRL-Fuzz 发现的漏洞数量远多于 Fuzz4All。
- Fuzz4All 发现的漏洞仅是 CovRL-Fuzz 所发现漏洞的子集。

- 结论:
- CovRL-Fuzz 通过结合覆盖率引导模糊测试和基于LLM的变异(通过 CovRL 方法),在漏洞检测上更为高效和有用。
- 结果对比(表6):
5.4 RQ3. Ablation Study
研究目标
通过消融研究分析 CovRL-Fuzz 的两个关键组件(CovRL 和 CWR)对代码覆盖率和错误率的影响。
实验结果
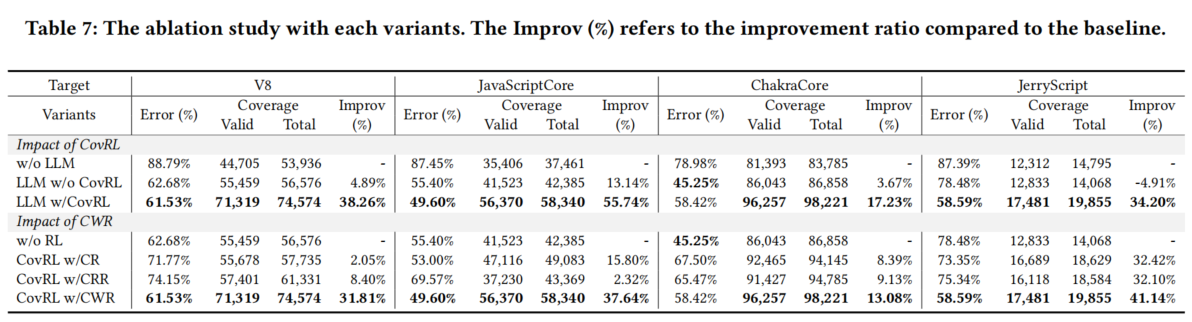
1. CovRL 的影响
- 实验设计:
- 比较三种方法:
- w/o LLM:使用启发式的令牌级变异(TokenAFL)。
- LLM w/o CovRL:仅将 LLM 变异应用于覆盖率引导模糊测试,不使用 CovRL。
- LLM w/ CovRL:完整的 CovRL-Fuzz。
- 比较三种方法:
- 结果:
- LLM w/o CovRL:相比 w/o LLM,错误率下降,但覆盖率没有显著提升,甚至略有下降。
- LLM w/ CovRL:在所有目标解释器中覆盖率均有显著提升。
- 结论:
- 在覆盖率引导模糊测试中,结合 LLM 变异和 CovRL 是提升覆盖率的有效方法。
2. CWR 的影响
- 实验设计:
- 比较四种奖励机制:
- w/o RL:不使用强化学习。
- w/ CR:简单的二值奖励(发现新覆盖时奖励1,否则为0)。
- w/ CRR:传统RL奖励(当前覆盖率与累计覆盖率的比值)。
- w/ CWR:使用 CovRL 中的 CWR。
- 比较四种奖励机制:
- 结果:
- w/ CR 和 w/ CRR:覆盖率提升不明显,与 w/o RL 相差不大。
- w/ CWR:在有效覆盖率和总覆盖率上均达到最高值,同时错误率最低。
- 结论:
- 使用 CWR 的覆盖率引导模糊测试技术显著提升了 LLM 变异的效果,促进覆盖率的提升和错误率的降低。
总结
- CovRL 显著提升覆盖率,表明将 LLM 变异与强化学习相结合的有效性。
- CWR 是 CovRL 中的核心组件,优于其他奖励机制,进一步增强了 LLM 变异的性能。
5.5 RQ4. Real-World Bugs
实验目标
评估 CovRL-Fuzz 在检测真实漏洞中的表现,特别是:
- 能发现多少真实漏洞?
- 是否能发现此前未知的漏洞?
实验结果
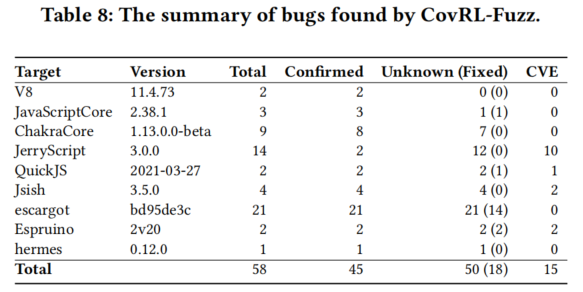
- 漏洞总数:
- CovRL-Fuzz 在所有目标解释器中共发现 58个漏洞。
- 50个为此前未知的漏洞,其中 15个已注册为 CVEs。
- 确认和修复:
- 45个漏洞 已被开发者确认,其中 18个漏洞 已修复。
- CVEs 平均风险评分为 7.5(CVSS v3.1),最高达到 9.8。
- 漏洞类型:
- 包括未定义行为(如断言失败)和内存错误(如缓冲区溢出、Use-After-Free)。
- 详见附录中的漏洞列表。
- 实验条件:
- 使用仅 3个CPU核心,每个目标解释器运行2周。
- 对比其他模糊测试工具的设置(通常使用约30核心,测试一个月),CovRL-Fuzz 在资源有限的条件下仍然表现出色。
- 结论:
- CovRL-Fuzz 在 JavaScript 解释器中表现出卓越的漏洞检测能力,即使在短时间和有限资源的情况下也能发现大量未知漏洞。
案例分析
- ChakraCore漏洞:
- CovRL-Fuzz 生成的最小化测试用例引发了 越界读取(Out-of-Bounds Read),导致解释器异常终止。
- 变异内容:
- 修改了种子的变量赋值和
await语句。 - 添加了
if条件,反复调用await n();,最终触发漏洞。
- 修改了种子的变量赋值和
- JerryScript漏洞:
- CovRL-Fuzz 生成的测试用例导致了 堆缓冲区溢出(Heap Buffer Overflow)。
- 漏洞原因:
- 在一个类的静态初始化块后紧接着声明函数时,解析器无法正确识别静态块范围,导致内存损坏。
- CovRL-Fuzz 的上下文感知变异功能帮助发现了该漏洞。

总结
- CovRL-Fuzz 能有效发现真实世界中的复杂漏洞,包括高危漏洞(如 CVEs)。
- 其 上下文感知变异 和 语法自由性 是发现这些漏洞的关键。
- 即使在资源有限的条件下,CovRL-Fuzz 的漏洞检测效果显著优于其他模糊测试工具。
Discussion
1. 模糊测试与微调时间分配
- 微调时间:
- 每2.5小时的模糊测试包含10分钟的微调时间。
- 即便将微调时间计入实验,CovRL-Fuzz 仍实现了高覆盖率并降低了错误率。
2. 性能瓶颈
- 观察到的问题:
- CovRL-Fuzz 的生成速度比 Token-Level AFL 慢约两倍。
- 原因:73%的测试用例生成时间用于 LLM 变异处理。
- 优势:
- 尽管变异速度较慢,但 LLM 变异带来的性能提升(如更高覆盖率和更低错误率)弥补了处理时间的不足。
- 结果表明 LLM 变异的效率远高于传统方法的性能损失。
3. 微调中的灾难性遗忘
- 应对策略:
- 使用小学习率微调。
- 部分原始种子数据参与微调。
- 结果:
- 实验中避免了灾难性遗忘,但无法完全排除未来发生的可能性。
- 此问题是 LLM 微调的通用问题,未来可以借助更先进的预防技术解决。
4. 对其他目标的支持
- 语言无关性:
- CovRL-Fuzz 的核心思想是通过 LLM 变异器引导覆盖率信息,与具体语言无关。
- 可以推广至其他语言解释器或编译器。
- 当前工作:
- 本研究聚焦于 JavaScript 解释器,以验证技术适用性和影响力。
- 对其他语言的扩展留待未来工作探索。
5. 对其他 LLM 的应用
- 模型无关性:
- CovRL-Fuzz 是通用策略,适用于多种开源 LLM。
- 本研究选择 CodeT5+(尽管模型最小,但结果最优)。
- 限制与展望:
- 由于资源限制,本实验使用最大规模为1B的 LLM。
- 未来可探索更大规模的模型,以进一步提升性能。