
Explaining Structured Queries in Natural Language
Explaining Structured Queries in Natural Language
Abstract
摘要——许多应用程序为普通用户提供了一种基于表单的环境,使其无需熟悉数据库模式或结构化查询语言即可访问数据库。用户的交互会被翻译成结构化查询并执行。然而,由于用户不太可能了解表单中各字段之间的底层语义关系,因此为用户提供查询的文本解释通常是有用的。在本文中,我们采用一种基于图的方式来解决查询翻译问题。我们将各种形式的结构化查询表示为有向图,并使用可扩展的模板机制为图的边添加模板标签。我们提出了多种图遍历策略,用于高效地探索这些图并生成查询的文本描述。最后,我们通过实验展示了所提方法在效率和效果上的表现。
INTRODUCTION
Background and motivation
问题背景:结构化查询语言(SQL)的局限性
- SQL 对高级用户和开发者是强大的工具,但大多数普通用户不熟悉。
- 为此,许多应用提供基于表单的查询环境,简化了数据库搜索和操作。
应用场景
- 基于表单的查询在以下领域常见:
- 博物馆门户网站
- 数字图书馆
- 电子商务网站
- 新兴的 DIY 数据库驱动的 Web 应用平台允许非程序员通过可视化界面快速创建和修改应用。
用户交互与查询翻译
- 用户与界面的交互会被翻译成结构化查询。
- 在查询的结果与用户预期不同的情况下,解释这些隐式生成的查询变得至关重要。
文本解释的必要性
- 辅助用户正确生成查询
- 即使不熟悉接口或查询语言,通过叙述形式翻译用户选择可以帮助其生成正确查询。
- 简化复杂表单中的字段语义关系
- 文本解释可以弥补用户对表单字段语义连接的不了解。
- 检查查询含义是否正确
- 在执行查询前,用更易理解的语言呈现查询帮助确认其是否表达了用户意图。
文本解释的具体应用
- 帮助理解错误查询
- 通过叙述而非错误代码,帮助用户理解查询错误原因。
- 分析空结果
- 当查询返回空结果时,文本解释有助于定位问题部分。
- 优化结果量过大的查询
- 当结果过多时,解释可以帮助用户重写查询以减少无用结果。
文本解释的广泛适用性
- 在需要解释查询的任何情况下,文本解释都非常有用且有效。
- 插入、删除和更新操作,特别是涉及复杂条件或嵌套结构的操作,受益于自然语言翻译。
- 视图定义和完整性约束,由于它们的语法大部分源自查询,因此也需要文本解释。
不同查询语言的适用性
- 虽然本文聚焦于 SQL,但类似的论点也适用于其他查询语言,如:
- RDF 查询(SPARQL 或 RQL)
- Datalog 程序等。
当前趋势的推动
- 自动化计算机与人类语言之间的翻译被认为是未来 25 年内最重要的 IT 挑战之一,且将对人类生活的各个方面产生广泛影响。
Challenges
查询翻译成叙述的忽视
- 将查询翻译为自然语言叙述的研究尚未得到充分重视。
- 传统上,自然语言处理(NLP)技术在信息系统中的应用是单向的,从自然语言请求到生成查询,而不是反向操作。
现有方法的局限
- 目前,NLP 工具试图将自然语言查询与 SQL 查询模式匹配,这限制了将 SQL 查询翻译为自然语言的功能。
研究问题
- 问题是:给定一个针对数据库 D 的查询 q,我们希望生成一个叙述,捕捉 q 的意图或目标。
查询翻译为文本的挑战
- 结构化查询转为文本的难点:
- SQL 语义不足。
- 查询的复杂性(如嵌套查询、复杂条件、不同查询构造如
group-by、order-by等)。 - 一个查询在正式语言中有多个等效表达(基于结合律、交换律等代数性质)。
翻译的难点
- 要捕捉查询元素的正确顺序,使得生成的文本表达自然且有意义,即使用户表达方式不同,也很具有挑战性。
现有方法的局限:没有人研究SQL-to-Question的问题
Approach and contributions
图基方法
- 使用基于图的方法将各种形式的结构化查询表示为有向图。
- 通过扩展的模板机制为图元素添加标签。
三种翻译策略
- BST算法:翻译过程由多个子句组成,每个子句专注于查询的特定语义。
- MRP算法:翻译是整体性的,查询图的各个部分在遍历图时被融合在一起。
- TMT算法:使用预定义的、更加丰富的模板翻译查询部分,以生成更简洁的翻译。
研究挑战
- 查询语言与口语语言的语义不同,某些查询(特别是复杂或表达能力强的查询)可能无法有效翻译。
- 使用预定义模式处理一些难以翻译的查询。
贡献
- 提出了一个新的查询图模型,用于捕捉查询的可能语义。
- 通过扩展模板机制,为查询图的边添加标签,为查询的各个部分赋予语义。
- 提出了不同的、与领域无关的图遍历策略,用于高效探索查询图并生成自然语言短语的查询描述。
- 提出了一个算法,用于选择最佳模板来翻译给定查询,处理可能重叠的查询部分模板。
- 通过实验结果比较了翻译算法,并展示了它们的适用性和有效性。
QUERY REPRESENTATION
我们专注于关系数据库和SQL查询。在本节中,我们将介绍我们捕获查询元素及其语义关联的查询图表示。
A. Database Graph
数据库图的定义
数据库 D 包含一组关系(relations),每个关系 Ri 有一组属性(attributes)。
数据库图 G(V,E) 是数据库模式的有向图表示,扩展了属性在查询中的基本角色。
图的节点 V 包括:
- 关系节点 R:每个关系对应一个节点。
- 属性节点 A:每个属性对应一个节点。
图的边 E
包括三种类型:
- **成员边 (Eμ)**:连接属性节点与其所属关系节点。
- **选择边 (Eσ)**:连接关系节点与其属性,表示基于条件选择的可能性。
- **谓词边 (Eθ)**:连接两个属性节点,表示基于属性的关系连接。
数据库图的特性
- 数据库模式图是一个有向图 G(V,E),其中 V=R∪A,E=Eμ∪Eσ∪Eθ。
- 图捕获了查询语义,包括关系和属性间的各种可能连接。

数据库示例
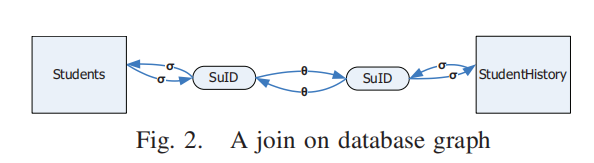
图 1 显示了一个课程数据库的关系及其属性,例如:
Students:表示学生信息(属性有SuID、Name、Class、GPA)。StudentHistory:记录学生的课程历史(属性有SuID、CourseID、Year、Term、Grade)。这些关系之间可以通过键(例如
SuID)进行连接。
数据库图中的路径
为了在数据库图中表达
Students和StudentHistory之间的连接,可以通过以下两种路径:
- 路径 1(从
Students到StudentHistory):
- 解释:从
Students表中选择SuID,然后通过谓词边(θ)连接到StudentHistory表中的SuID,最终选择与StudentHistory相关的信息。- 路径 2(从
StudentHistory到Students):
- 解释:反向操作,从
StudentHistory表中选择SuID,通过谓词边连接到Students表,最终选择与Students相关的信息。操作上的等价性
在操作层面,这两种路径可能是等价的,例如在等值连接(equi-join)的情况下,这两条路径都会返回同样的查询结果。
语义上的差异
虽然结果相同,但两条路径的语义翻译可能不同,取决于查询的意图。例如:
- 路径 1: 可以解释为“学生选择的课程”(侧重于
Students)。- 路径 2: 可以解释为“学生通过的课程”(侧重于
StudentHistory)。路径的选择取决于查询的语义需求和翻译目标。
关键点总结
- 数据库图可以灵活表示关系间的连接,捕捉查询的语义。
- 不同路径可能在操作上等价,但语义翻译会不同。
- 翻译选择依赖于查询的具体意图和上下文,例如区分“选择的课程”和“通过的课程”。
B. Query Graphs
SPJ 查询图的全称是 Selection-Projection-Join Query Graph(选择-投影-连接查询图)。
它是一种用于表示关系数据库中基本查询操作的图模型,涵盖了以下三种核心操作:
- Selection(选择):从关系中选择满足某些条件的元组(记录)。
- Projection(投影):从关系中选择特定的属性(列)。
- Join(连接):将两个或多个关系按照某些条件组合在一起。
SPJ 查询图扩展了基本的数据库图,通过节点和边捕捉查询的结构和语义:
- 节点:表示关系、属性和具体值。
- 边:描述查询中关系、属性之间的语义关系,例如成员关系、选择条件和谓词(比较或连接条件)。
扩展SPJ查询图
- 从基本的 SPJ 查询(选择、投影、连接)开始,逐步扩展到处理包含函数、分组以及子查询的查询图。
SPJ查询图的节点
- 关系节点(relation nodes):表示查询中每个关系或元组变量。
- 属性节点(attribute nodes):表示查询中的每个属性,若属性出现在查询的不同部分,可能会重复。
- 值节点(value nodes):表示查询中限定条件指定的值或值集。
SPJ查询图的边(Eq)
- 成员边(membership edges):
- 用于表示从关系 Ri投影的属性 Aji。
- 形式:
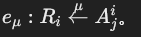
- 谓词边(predicate edges):
- 用于表示谓词
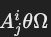 ,其中 Ω 可以是值、值集或另一个属性,θ 是比较运算符(如 =, <, >, <>, LIKE)。
,其中 Ω 可以是值、值集或另一个属性,θ 是比较运算符(如 =, <, >, <>, LIKE)。 - 两种情况:
- 如果 Ω 是值或值集,则为选择谓词边
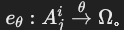 。
。 - 如果 Ω\OmegaΩ 是另一个属性,则为连接谓词边:
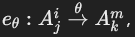 ,同时记录逆向边:
,同时记录逆向边: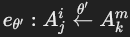 (逆运算符,如 > 的逆是 ≤)。
(逆运算符,如 > 的逆是 ≤)。
- 如果 Ω 是值或值集,则为选择谓词边
- 用于表示谓词
- 选择边(selection edges):
- 如果谓词
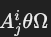 中 Ω 是值或值集:
中 Ω 是值或值集:- 边:
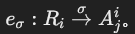
- 边:
- 如果 Ω 是属性:
- 边:

- 边:
- 如果谓词
总结
SPJ 查询图通过定义不同类型的节点和边扩展了数据库图的表示能力,能够捕捉查询的复杂语义,如投影、谓词(比较、连接)和选择操作。

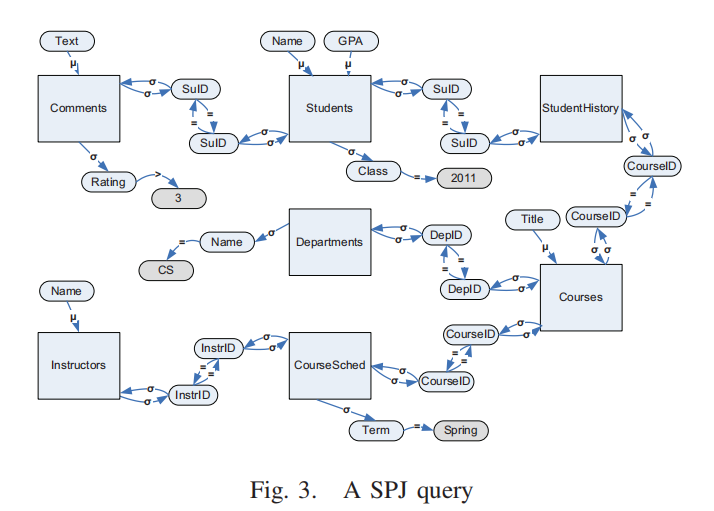
Fig. 3 展示了一个 SPJ 查询的图形表示,反映了查询中涉及的关系、属性、值,以及它们之间的连接和条件。
主要内容:
- 查询中的连接(Join)表示:
- 每个关系之间的连接在图中表示为两条方向相反的路径(双向路径)。
- 例如,Students 和 StudentHistory 通过属性 SuID 相连,这种连接通过两条边展示:
- 一条从
Students到StudentHistory的边。- 另一条从
StudentHistory到Students的反向边。- 条件的表示:
- 图中也捕捉了查询条件中涉及的属性和值。例如:
- 条件 s.class = 2011 表示为两条边:
- 选择边(Selection edge):从
Students到属性class。- 谓词边(Predicate edge):从属性
class到值2011,并标注了比较运算符=。- 查询元素的图表示:
- 关系(Relation): 图中的矩形节点(如
Students、Courses)表示查询涉及的关系。- 属性(Attribute): 椭圆形节点(如
class、DepID)表示查询中使用的属性。- 值(Value): 椭圆形节点中带具体值(如
2011、Spring)表示查询条件中涉及的具体值。- 边(Edge): 图中的箭头表示查询中关系与属性、属性与值之间的连接和条件。
- 查询语义的图表示特点:
- 图中的路径表示查询的语义,清晰捕捉了关系之间的连接、属性的选择条件以及与值的比较关系。
- 例如:
Students −→ σ class −→ = 2011捕捉了选择条件class = 2011。- 关系之间的连接,如
Courses与Departments通过DepID属性相连。- 实际用途:
- 图中的表示方式帮助理解查询的结构与逻辑,同时也为查询的自然语言翻译提供了基础。
结论:
Fig. 3 通过关系节点、属性节点、值节点,以及多种类型的边(如选择边、谓词边),完整捕捉了一个 SPJ 查询的结构和语义,使得查询的逻辑表达清晰易懂,同时也为后续的翻译和优化奠定了基础。
为了扩展查询图,使其能够捕捉函数、表达式、重命名操作,以及 ORDER BY、GROUP BY 和 HAVING 子句,定义了以下新增的节点和边类型:
- 新增节点类型
- 函数节点(function nodes):
- 表示应用于属性(或属性集)上的函数、表达式或重命名操作。
- 函数节点(function nodes):
- 新增边类型
- 转换边(transformation edges):
- 表示属性和函数节点之间的连接:
- 若属性在
SELECT子句中: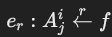 。
。 - 若属性在
WHERE子句中: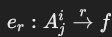 。
。
- 若属性在
- 表示属性和函数节点之间的连接:
- 排序边(order edges):
- 表示结果集的排序:
- 从关系节点到排序的第一个属性:
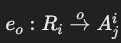 。
。 - 其他排序属性之间的连接:
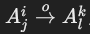 ,显示升序或降序。
,显示升序或降序。
- 从关系节点到排序的第一个属性:
- 表示结果集的排序:
- 分组边(grouping edges):
- 表示分组属性:
- 从关系节点到分组的第一个属性:
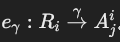 。
。 - 其他分组属性之间的连接:
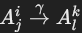 。
。
- 从关系节点到分组的第一个属性:
- 表示分组属性:
- HAVING 边(having edges):
- 表示 HAVING 子句中的属性:
- 从关系节点到每个参与属性:
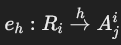 。
。
- 从关系节点到每个参与属性:
- 表示 HAVING 子句中的属性:
- 转换边(transformation edges):
通过新增函数节点和转换、排序、分组、HAVING 边,扩展了查询图的表示能力,能够捕捉更复杂的查询语义,如函数应用、排序、分组以及聚合条件等高级查询操作。

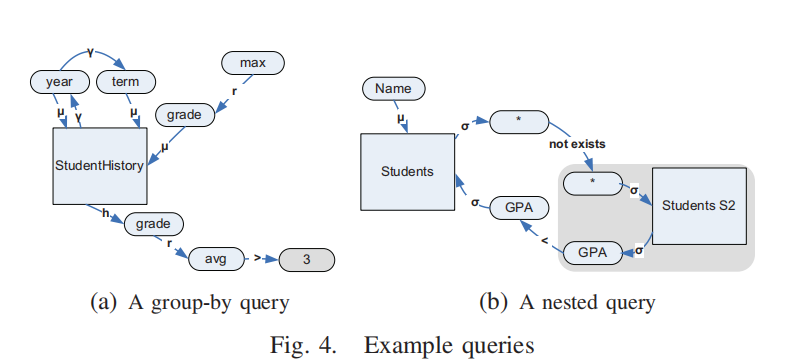
(a) 一个包含
GROUP BY的查询
- 分组属性(Grouping Attributes):
- 查询根据
year和term进行分组。- 分组边 (γ):
- 从
StudentHistory关系连接到属性year。- 从
year再连接到term,表示分组顺序。- 投影属性(Projecting Attributes):
- 查询投影(显示)属性包括:
year、term和grade。- 其中:
year和term是普通投影属性。grade是一个聚合属性,与聚合函数max通过转换边(r)相连。- HAVING 子句:
- 查询对
grade的平均值(avg)进行了条件限制(HAVING avg(grade) > 3)。- 图表示:
- HAVING 边(h):连接
grade和其所属关系StudentHistory。- 转换边(r):连接
grade和函数节点avg。- 谓词边(θ):连接
avg函数节点和值3,表示比较条件。- 注意点:
- 同一个属性(grade)根据其不同角色(聚合和 HAVING)被表示为两个节点:
- 一个用于
max聚合。- 一个用于
avg聚合。- 如果一个函数涉及多个属性,那么这些属性节点都会通过转换边连接到同一个函数节点。
我们现在考虑使用嵌套的查询。
嵌套查询的特点和表示:
嵌套查询指在主查询(“父查询”)中包含子查询的情况。子查询可以出现在以下位置:
- FROM 子句:子查询被视为一个虚拟表,与其他表进行连接。
- SELECT 子句:子查询作为属性集供主查询投影。
- WHERE 或 HAVING 子句:子查询被视为一个值列表或单个值,参与谓词条件。
谓词类型:
谓词的形式为 AjiθΩ,其中:
- θ 表示比较运算符(如 =, <, > 等)或集合比较运算符(如 (NOT) EXISTS, (NOT) IN, θ′ ANY, θ′ ALL)。
子查询在图中的表示:
子查询 qm 被表示为一个独立的子图,作为“虚拟关系”连接到父查询的图中。具体连接方式如下:
- 子查询返回单个属性
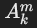 的情况:
的情况:- 谓词形式为
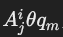 ,子查询返回属性
,子查询返回属性 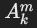 。
。 - 图中路径:
- 父查询中的属性
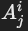 通过选择边连接到其关系
通过选择边连接到其关系  。
。 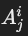 通过谓词边连接到子查询返回的属性
通过谓词边连接到子查询返回的属性 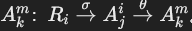 。
。
- 父查询中的属性
- 谓词形式为
- 子查询作为虚拟表的情况(FROM 子句):
- 谓词形式为
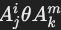 ,子查询返回的属性
,子查询返回的属性 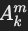 被视为一个虚拟表的属性。
被视为一个虚拟表的属性。 - 图表示与通常的连接相同。
- 谓词形式为
- 关联子查询的情况:
- 子查询
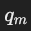 中的谓词涉及父查询中的属性
中的谓词涉及父查询中的属性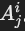 。
。 - 图中路径:
- 子查询属性
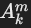 通过选择边连接到其关系
通过选择边连接到其关系 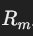 。
。 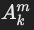 通过谓词边连接到父查询中的属性
通过谓词边连接到父查询中的属性 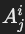 。
。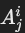 通过选择边连接到父查询中的关系
通过选择边连接到父查询中的关系 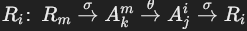 。
。
- 子查询属性
- 子查询
应用示例:
- 子查询出现在 WHERE 子句 中时,通常属于第一种情况;如果是关联查询,则属于第三种情况。
- 子查询出现在 FROM 子句 中时,属于第二种情况。
嵌套查询通过独立的子图和“虚拟关系”表示,其与主查询的连接方式取决于子查询的上下文(如 WHERE、FROM 或 SELECT 子句),并通过选择边和谓词边系统地捕捉嵌套关系的语义。

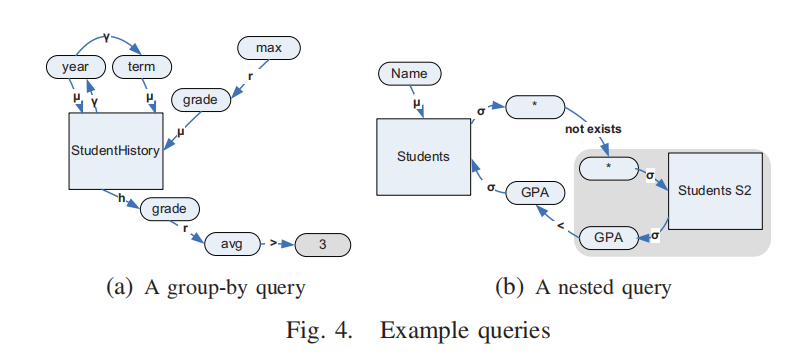
查询内容
Fig. 4(b) 展示了一个嵌套查询的图表示,其中:
- 主查询操作在
Students表上。- 子查询出现在主查询的
WHERE子句中,并使用了NOT EXISTS条件。- 子查询的作用是检查
Students S2表中是否存在符合条件的记录。
查询结构表示
- 主查询部分:
- 主查询涉及
Students表,并通过属性GPA设置筛选条件。- 图中,
Students关系通过选择边 (σ\sigmaσ) 连接到其属性GPA。- 子查询部分:
- 子查询引用了主查询的
GPA属性,构成一个关联查询(Correlated Query)。- 子查询中,
Students S2表作为一个虚拟关系,连接到属性GPA。NOT EXISTS条件:
- 条件
NOT EXISTS意味着子查询并不返回任何具体属性。- 图中:
- 使用了两个“虚拟属性节点”(Dummy Attribute Nodes)来表示:
- 一个与子查询子图相连。
- 一个与主查询图相连。
- 图中存在两条路径:
- 第一条路径:从主查询到子查询,表示子查询作为
NOT EXISTS条件的一部分。- 第二条路径:从子查询回到主查询,表示子查询与主查询属性之间的关联。
查询图中的多关系实例
- 子查询中的
Students S2是对Students表的另一个实例化,表示该表被多次引用。- 图中清晰区分了
Students和Students S2,展示了关系的多实例映射。
总结
Fig. 4(b) 中嵌套查询的图表示特点:
- 捕捉了嵌套查询在
WHERE子句中的位置。- 处理了
NOT EXISTS条件,通过虚拟属性节点表达子查询不返回具体属性的语义。- 展示了主查询与子查询之间的关联路径,以及关系多实例的图表示。
- 图表示清晰捕捉了嵌套查询和关联查询的复杂语义结构。
CAPTURING QUERY SEMANTICS
在本节中,我们将描述一个模板机制,它允许我们表示查询图元素的语义。
Labels.
节点和边的标签(Labels)
- 节点的标签定义:
- 每个节点 v 在查询图中的标签 l(v) 代表其概念含义:
- 关系节点:表示实体类型。例如,
Students的概念含义是“学生”。 - 属性节点:标签源自属性名称。例如,
Name属性节点的标签可能是“name”。 - 函数节点:标签代表函数的输出含义。例如,
max函数的标签是“the greatest”。 - 表达式或未知函数:使用默认标签,例如“an expression on”或“a function of”。
- 值节点:被视为字面量,标签直接是其值。
- 关系节点:表示实体类型。例如,
- 每个节点 v 在查询图中的标签 l(v) 代表其概念含义:
- 边的标签定义:
- 边的标签描述了源节点和目标节点之间关系的自然语言含义:
- 成员边(Membership edge):如
Students与Name之间的边标签是“of”。 - 谓词边(Predicate edge):如
Students和Courses的连接表示“have taken”。
- 成员边(Membership edge):如
- 边的标签描述了源节点和目标节点之间关系的自然语言含义:
- 标签的存储:
- 数据库图的每个节点和边都存储了标签,查询图从数据库图继承这些标签。
标签生成和优化:
- 自动生成:
- 节点标签可以通过数据库模式匹配和实体解析技术从数据库结构名称中提取。
- 边标签有默认值,例如“of”用于成员边。
- 人工调整:
- 系统设计者可以校正或补充自动生成的标签,提供更精确的描述。
- 优化翻译:
- 使用细化的标签可以使查询图的翻译结果更加描述性和准确。
总结
- 标签为节点和边赋予了自然语言含义,使查询图的语义清晰可读。
- 自动生成和设计者调整相结合的方法确保标签的准确性和实用性。
- 细化的标签提高了查询图翻译的质量,增强了表达的描述性和易理解性。
Templates.
模板标签的定义与作用
模板标签(Template Labels):
- 用于解释查询图中节点和边之间的关系,以生成更自然的描述。
- 模板标签可以应用于单条边 (v,u)或更广泛的路径连接 v 和 u。
标签结构:
通用模板标签的形式:
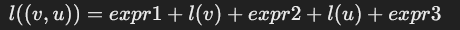
- expr1,expr2,expr3:字母数字表达式,用于连接节点标签 l(v) 和 l(u)。
模板语言和宏
- 模板语言:
- 提供支持变量、循环、函数和宏的机制,用于创建和管理模板标签。
- 示例宏:
- **
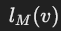 **:生成包含节点 v 所有成员边的模板信息。
**:生成包含节点 v 所有成员边的模板信息。 - **
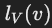 **:生成从 v 到值节点之间所有路径的模板信息。
**:生成从 v 到值节点之间所有路径的模板信息。 - **
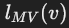 **:组合
**:组合 的结果,为 v 提供完整的翻译。
的结果,为 v 提供完整的翻译。
- **
模板类型
- 通用模板(Generic Templates):
- 自动生成,独立于具体数据库,具有通用性。
- 例如:
对选择边 ,通用模板可能生成 “students whose name”。
,通用模板可能生成 “students whose name”。 - 支持操作符标签,如
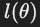 表示谓词操作符的标签。
表示谓词操作符的标签。 - 使用模板变量(如
CONJ_NOUN)增强可扩展性,便于结合短语。
- 特定模板(Specific Templates):
- 人工定义,适用于特定边或路径。
- 能够生成高质量、简洁的文本。例如:
- 对
 ,特定模板可以定义为“students named”。
,特定模板可以定义为“students named”。
- 对
模板优先级与方向
- 优先使用特定模板:
- 特定模板因其手动定义的高质量描述,在查询翻译中优先于通用模板。
- 方向性:
- 模板标签遵循边的方向。如果两节点间存在反向边,则可为两条边分别分配模板标签。
总结
模板标签通过通用和特定的机制,为查询图的边和路径提供自然语言描述,提高查询翻译的精确性和可读性。通用模板具有通用性,特定模板则更精炼且适合特定需求。模板语言和宏的支持增强了模板定义和扩展的灵活性。

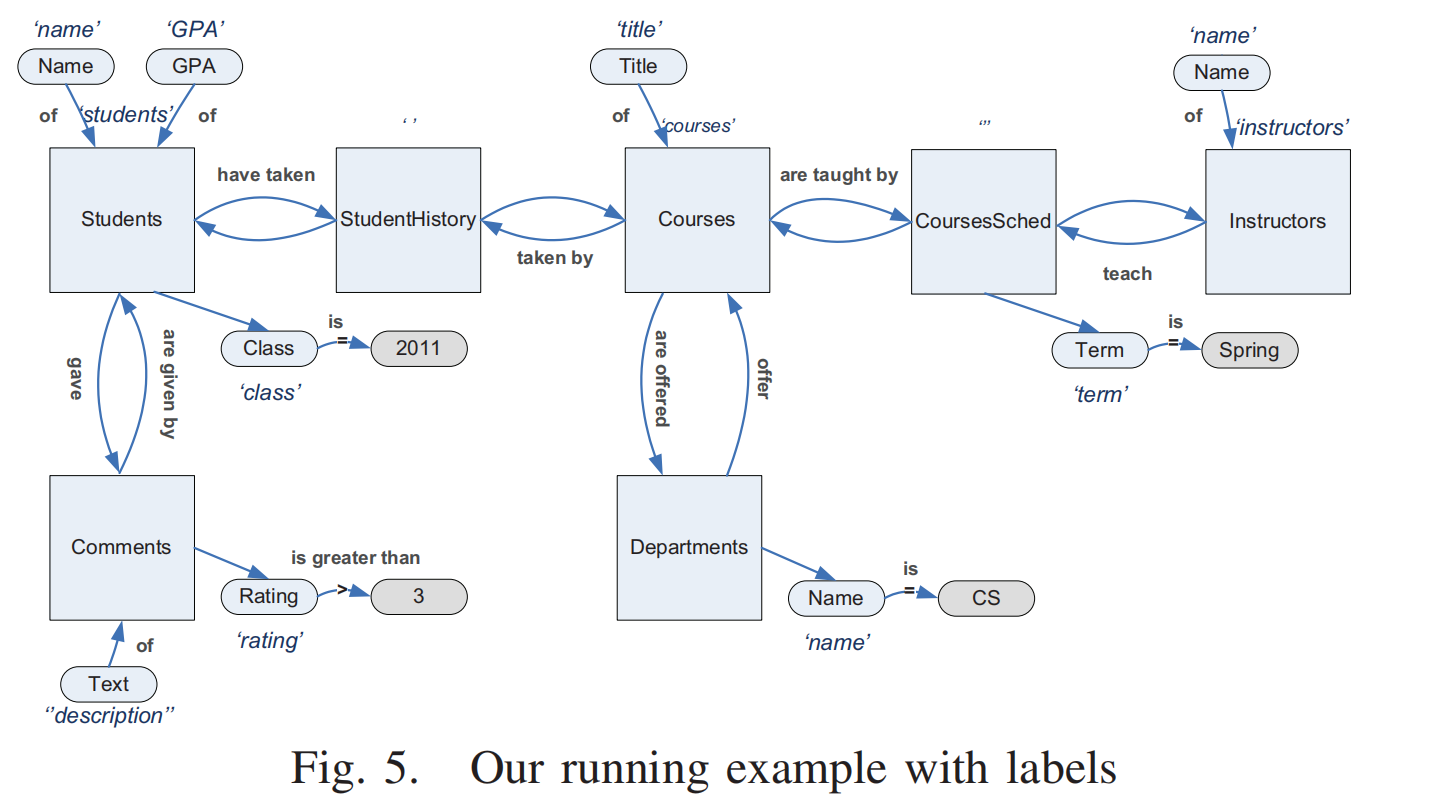
QUERY TRANSLATION
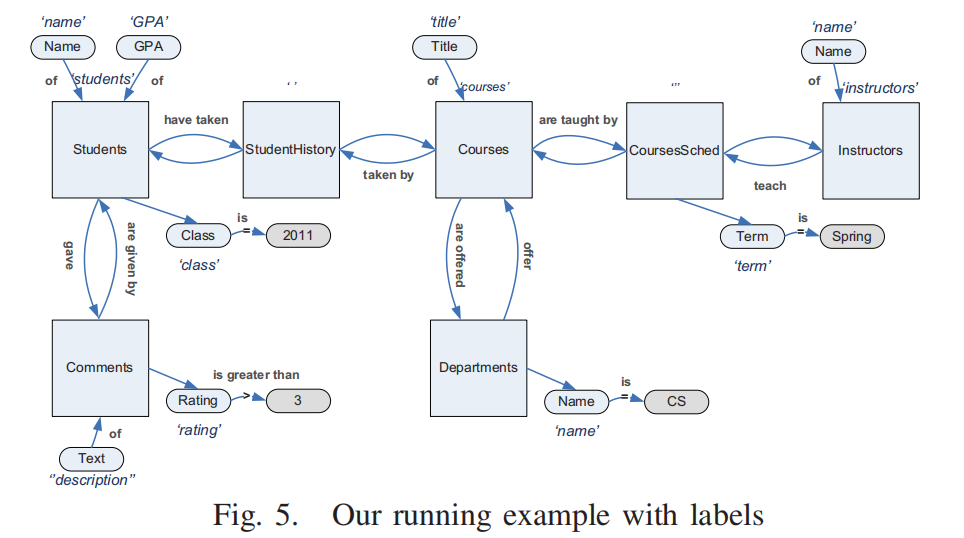
在本节中,我们将介绍SPJ查询的算法。我们首先讨论查询主题的选择,即查询中感兴趣的主要实体,然后我们提出三种策略来翻译我们希望知道的关于主题和主题资格的信息,即哪些特定实体感兴趣。示例1中描述的查询及其查询图(图3)将作为参考示例。图5描述了一个标注有标签的图的简化版本,其中每个连接路径都被一条“虚拟”边所取代。在第IV-D节中,我们将转换算法扩展到分组和排序语义。
A. Query Subject
查询主题(Query Subject)的概念和重要性
定义:
- 查询主题是查询的中心实体,决定了查询图的遍历方向和生成的子句类型。
- 通常是
SELECT子句中投影属性的关系节点。 - 在多关系投影属性的情况下,仅根据
SELECT子句无法唯一确定查询主题。
主关系和次关系的定义:
- 主关系(Primary Relation, RP): 存储同类实体信息的关系(如
Students)。 - 次关系(Secondary Relation, RS): 存储不同实体之间关系的关系(如
StudentHistory)。 - 主关系可通过数据库模式或 E/R 图识别,其余关系为次关系。
查询主题的选择标准:
- 查询主题是投影属性中“中心性”最强的主关系。
- “中心性”通过最短路径长度计算:选择使最大最短路径长度最小的主关系作为查询主题。
- 如果有多个候选关系,优先选择投影属性最多的关系;若仍有冲突,则提供多种翻译。
查询主题的正式定义和例子
正式定义:
查询主题是投影属性中的主关系 Rq,满足:
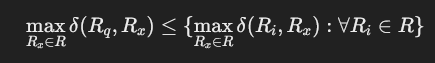
- 其中
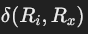 是查询图中 Ri 和 Rx 之间的最短路径长度。
是查询图中 Ri 和 Rx 之间的最短路径长度。
- 其中
例子(Fig. 5):
- 主关系包括:
Students、Courses、Comments、Instructors。 (Select句子投影的结点) - 它们的最长路径长度分别为:12、9、15、15。 (使用 广度优先搜索(BFS) 遍历查询图,找到每个关系节点到其他所有关系节点的 最短路径长度。)
- 不知道是怎么算的?上述Definition的定义是为什么?不make sense。查询主题结点对于后面的查询翻译的意义是什么?
- 因此,
Courses是查询主题,因为它的最长路径最短。
- 主关系包括:
B. Query graph traversal
BST 算法概述
- BST(Breadth-First Search with Templates)算法用于将查询图翻译为自然语言文本,通过递归遍历查询图的节点和边生成三个部分的文本:
- pStr:描述查询中每个关系的成员属性。
- fStr:描述查询中关系间的连接(
FROM子句的翻译)。 - wStr:描述值节点(
WHERE子句的翻译)。
翻译步骤
- 从查询主题节点开始遍历(Depth-First):
- 从查询主题节点 Rq 开始,递归遍历查询图,翻译所有相关节点和边。
- 翻译路径到值节点(
wStr):- 如果路径的终点是值节点,则生成描述该路径的子句并加入
wStr。 - 例如:
- 对于
Students → CLASS → 2011,生成子句:“students whose class is 2011”。
- 对于
- 如果有多个路径,子句之间使用连接词(如 “and”)组合。
- 如果路径的终点是值节点,则生成描述该路径的子句并加入
- 翻译关系连接(
fStr):- 如果路径不以值节点结束,而是用于连接两个关系节点(即
FROM子句的连接),生成描述连接的子句并加入fStr。 - 例如:
- 对于
Courses,生成子句:“courses that are taught by instructors and are offered by departments”。
- 对于
- 如果路径不以值节点结束,而是用于连接两个关系节点(即
- 翻译成员属性(
pStr):- 对于每个节点,检查其输入边(成员边),翻译出该节点的成员属性并加入
pStr。 - 例如:
- 对于
Students,生成子句:“the gpa and name of students”。
- 对于
- 对于每个节点,检查其输入边(成员边),翻译出该节点的成员属性并加入
- 结果优化:
- 使用简单的查找替换机制(RCE)消除重复信息,使文本更流畅。
- 组合最终文本:
- 将 pStr 、 fStr 和 wStr 组合成完整的自然语言翻译,格式为:
- “Find [pStr] for [fStr]. Return results only for [wStr].”
- 将 pStr 、 fStr 和 wStr 组合成完整的自然语言翻译,格式为:
示例结果(基于 Fig. 5)
对 Fig. 5 的查询图应用 BST 算法,最终生成的自然语言文本为: “Find the title of courses, the name of instructors, the gpa and name of students, and the description of comments for courses that are taught by instructors, are taken by students that gave comments, and are offered by departments. Return results only for courses whose term is spring, students whose class is 2011, comments whose rating is greater than 3, and departments whose name is CS.”
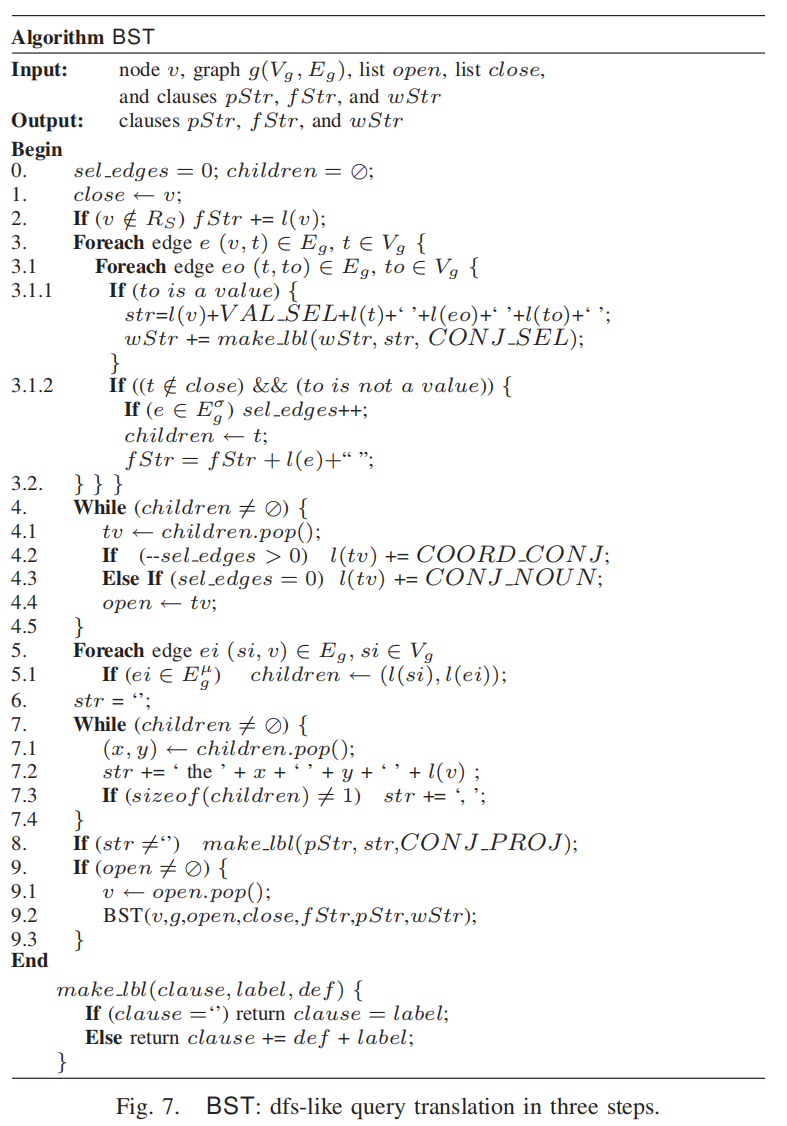
MRP 算法概述
MRP(Multi Reference Points)算法是一种改进的翻译策略,与 BST 不同,它将所有信息(投影属性、选择条件、连接条件)融合在一起进行翻译。它通过在查询图中定义多个“参考点”(Reference Points, RPs)对翻译进行语义分割,避免生成过长和不自然的句子。
关键概念:参考点(Reference Points, RPs)
- 定义:参考点是查询图中的某个关系节点,满足以下任意条件:
- (a) 主关系节点,包含成员边 (μ)。
- (b) 分叉节点,即连接多个其他关系节点的分支点。
- (c) 叶子节点,即没有指向其他关系的路径。
- (d) 距离最近的参考点超过预设阈值 ψ。
- 作用:通过定义参考点,将查询图分成若干子图进行翻译,从而控制翻译的语义长度和复杂性。
MRP 算法的工作原理
- 遍历查询图:
- 从查询主题节点开始,对查询图进行类似深度优先搜索(DFS)的遍历。
- 当到达一个参考点时,翻译连接该参考点与上一个参考点的子图。
- 翻译方向:
- 若参考点没有成员边 (μ): 从上一个参考点 pr 翻译到当前参考点 rp。
- 若参考点有成员边 (μ): 从当前参考点 rp 翻译到上一个参考点 pr。
- 这种方向选择是为了确保参考点之间的语义连接自然且符合逻辑。
- 翻译内容:
- 包括投影属性、值节点的路径,以及连接条件。
- 翻译时加入协调连词(如 “and”)、从句连接词(如 “that”)等,使文本更流畅。
示例(基于 Fig. 5)
对于 Fig. 5 的查询图:
- 假设起始点是
Students,参考点是Students、Courses和Instructors。 - 翻译结果为: “Find the title of courses for courses that are offered by departments whose name is CS, and also, the gpa and name of students for students whose class is 2011 and that have taken these courses, and also, the description of comments for comments whose rating is greater than 3 and that are given by these students, and also, the name of instructors that teach courses whose term is spring.”
- 在翻译过程中,额外的连词(如 “and” 和 “that”)被加入以改善句子结构。
C. Template Selection
模板选择算法旨在根据查询图动态构建最佳的模板组合,以生成清晰的查询翻译。目标是通过尽可能少且适合组合的大模板覆盖整个查询图,这样可以避免生成过于碎片化、不自然的描述。
模板的分类与特性
- 通用模板(Generic Templates):
- 自动定义在查询图的单条边上。
- 描述局部关系,但规模较小。
- 特定模板(Specific Templates):
- 由设计者提供,定义在路径或子图上。
- 通常规模更大,描述更具体。
- 模板图(Template Graph):
- 模板被分配到一个模板图 ggg,它是一个有向无环图(DAG)。
- 每个模板图包含一组参考点 R(g)R(g)R(g),表示模板图的关键连接点,用于连接模板。
模板的可组合性(Composeability)
- 定义:
- 两个模板 g 和 g′ 可组合(composeable),当且仅当它们的参考点集 R(g) 和 R(g′) 有非空交集。
- 参考点是模板间连接的关键节点。
- 例子:
- 图中模板 ga 和 gb 的参考点不同(学生和教师 vs. 课程和部门),因此不可组合。
- 模板 gc 的参考点与 ga 和 gb 均有交集,因此可以与二者组合。
算法目标与挑战
- 目标:
- 给定查询图 Gq 和一组模板,算法需要:
- 找到最小数量的可组合模板集,覆盖整个查询图。
- 确定模板组合的顺序,确保模板能够正确拼接。
- 给定查询图 Gq 和一组模板,算法需要:
- 挑战:
- 模板不能随意组合,必须根据模板的可组合性和查询图的结构以正确顺序拼接。
算法的工作机制
- 模板组合的核心是将模板看作拼图的“块”,需要通过参考点“拼接”成完整的描述。
- 通过选择最少的模板覆盖查询图,并按照可组合性确定拼接顺序,生成最终翻译。
1) TS algorithm:
TS 算法旨在从模板集中选择最小数量的可组合模板图,以覆盖整个查询图 Gq(Vq,Eq)G_q(V_q, E_q)Gq(Vq,Eq),确保翻译结果自然、简洁且完整。
关键概念
模板图(Template Graphs):
模板图是定义在查询图的子图上的翻译模板,可以是单条边、路径或更复杂的子图。
查询图 Gq 是这些模板图的超级图。
例如:如果
GqG_qGq
是一个查询描述了学生、课程和教师的关系,模板图可能包括:
Students → Courses(表示学生修过的课程)。Courses → Instructors(表示课程由哪些教师教授)。
可组合模板(Composeable Templates):
- 模板图之间需要共享至少一个参考点(如关系节点),才能被视为可组合。
- 例如:
- 模板 1:
Students → Courses - 模板 2:
Courses → Instructors - 因为两者共享
Courses这一参考点,所以是可组合的。
- 模板 1:
候选解(Candidate Solution):
- 一个候选解由一组可组合模板图组成,表示为:
- gcom:模板图集合。
- Esat:这些模板覆盖的查询图边集。
- Rg:这些模板的参考点集合。
- 一个解的大小为模板图的数量(∣gcom∣),目标是找到最小的解。
- 一个候选解由一组可组合模板图组成,表示为:
算法步骤
第一步:确定候选模板图
索引模板:
- 创建一个反向索引 I,记录每条查询图边属于哪些模板图。
- 例如:
- 查询图边
Students → Courses存在于模板图T1和T3中。 - 查询图边
Courses → Instructors存在于模板图T2和T3中。
- 查询图边
构建矩阵 M[][]M[][]M[][]:
行表示查询图的边,列表示模板图。
如果边 eee 存在于模板图 ggg 中,则 M[e][g]=1。
例如:
1
2
3M:
Students → Courses: T1, T3
Courses → Instructors: T2, T3
筛选模板图:
- 仅保留能覆盖查询图全部边的模板图集合。
- 例如:
- 如果模板图 T3T3T3 同时覆盖了
Students → Courses和Courses → Instructors,则保留 T3T3T3。
- 如果模板图 T3T3T3 同时覆盖了
第二步:寻找最小可组合模板集
- 初始化候选解:
- 从最大模板图(边数最多的模板图)开始,初始化候选解列表 QP。
- 扩展候选解:
- 按模板图的大小(优先选择边数最多的模板图)扩展候选解。
- 如果某个候选解覆盖了查询图的所有边,则停止扩展,输出结果。
- 剪枝:
- 如果某个候选解无法扩展成完整解(即无法覆盖查询图的所有边),则剪枝。
输出最优解
- 输出包含最少模板图的候选解。
查询图
假设查询图 Gq描述:
Students → Courses:学生修过的课程。Courses → Instructors:课程由哪些教师教授。模板集合
- T1T1T1:覆盖
Students → Courses。- T2T2T2:覆盖
Courses → Instructors。- T3T3T3:覆盖
Students → Courses和Courses → Instructors。算法执行
- 筛选模板图:
- T1 和 T2 仅部分覆盖查询图。
- T3 完全覆盖查询图。
- 寻找最优解:
- 优先选择 T3,因为它覆盖了所有边,且是单一模板图(最小解)。
输出
- 最优解为 T3。
TS 算法通过筛选和组合模板图,确保以最少的模板数覆盖查询图,同时考虑模板间的可组合性,最终生成高效、简洁的翻译方案。

2) TMT algorithm:
TMT 算法的目的是使用 TS 算法生成的可组合模板集 gt来对查询图 Gq进行翻译。它通过动态策略确定模板的组合顺序,并生成自然流畅的查询翻译文本。
关键概念
- 模板图(Template Graphs):
- 来自 TS 算法的模板图集 gt,包括特定模板(描述子图)和通用模板(描述单条边)。
- 特定模板可以生成更简洁、自然的文本。
- 根节点(Root Node):
- 查询图中一个没有入边(除了可能的成员边)的关系节点,被选为翻译的起点。
- 例如,在 Fig. 5 中,
Students是根节点。
- 超级边(Super Edge):
- 模板图(尤其是特定模板)可以被视为连接其参考点的“超级边”,可能对应查询图的子图而不是单条边。
算法步骤
- 选择根节点(Root Node):
- 找到查询图中没有入边的关系节点 ri,作为翻译的起点。
- 例如,对于 Fig. 5 的查询图,
Students是根节点。
- 构建 DAG(Directed Acyclic Graph):
- 从根节点 ri出发,逐步扩展 DAG Gri,加入能够与 ri 组合的模板图。
- DAG 中的每条边(超级边)对应一个模板图(特定模板或通用模板)。
- 拓扑排序(Topological Sort):
- 对构建的 DAG Gri 进行拓扑排序,确定模板图的处理顺序。
- 优先级规则:
- 优先处理成员边(membership edges)。
- 然后处理指向值节点的选择边(selection edges)。
- 最后处理其他边。
- 翻译子图(Partial Translation):
- 按拓扑排序依次翻译模板图,生成局部翻译短语 cStri。
- 如果某个模板图有多个子模板图,则使用连词(如 “and”)连接翻译结果。
- 组合翻译结果:
- 对于每个根节点 ri 生成的 DAG,重复上述步骤,生成相应的翻译短语 cStri。
- 最终将所有局部翻译短语 cStri 合并,形成完整的翻译文本 cStr。
示例
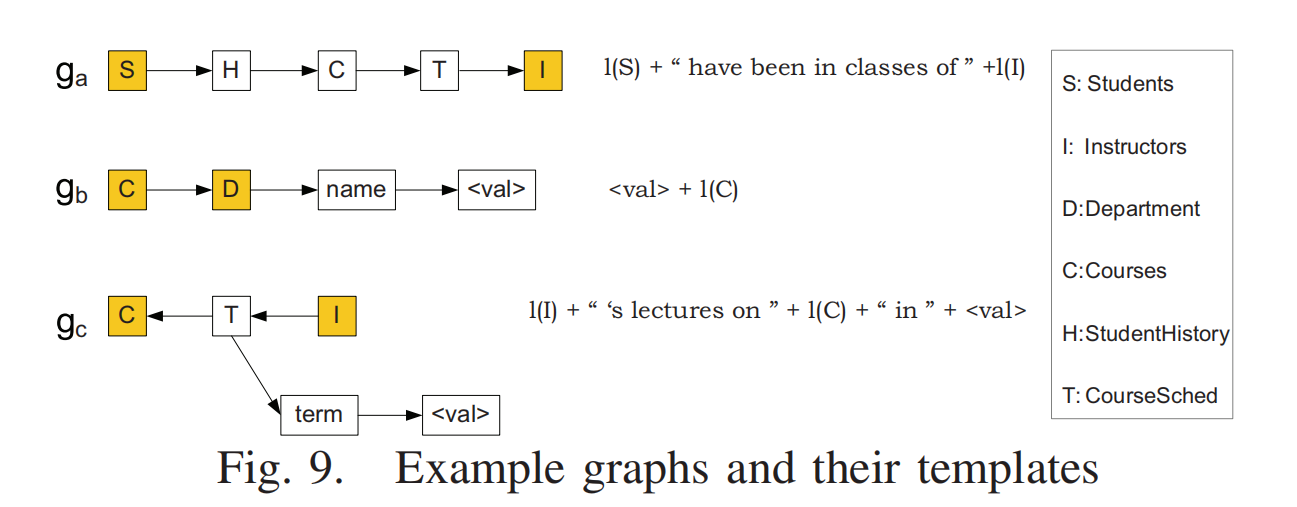
对于 Fig. 5 的查询图,假设使用 Fig. 9 中的模板:
根节点选择:
Students是根节点。DAG 构建:
- 模板 ga:描述
Students和Instructors之间的关系。 - 模板 gbg_bgb:描述
Courses和Departments的关系。 - 模板 gcg_cgc:连接
Students和Courses。 - 通过模板组合,构建一个 DAG。
- 模板 ga:描述
拓扑排序:
- 按规则排序模板,例如:ga → gc → gb。
生成翻译文本:
- 使用模板翻译生成:
- ga:“Find the gpa and name of students whose class is 2011 and have been in classes of instructors”。
- gc:“Find the title of these CS courses”。
- gb:“and the description of comments whose rating is greater than 3”。
- 合并所有翻译结果: “Find the gpa and name of students whose class is 2011 and have been in classes of instructors and find the title of these CS courses and the description of comments whose rating is greater than 3.”
- 使用模板翻译生成:
总结
- TMT 的核心:
- 动态组合 TS 输出的模板图,通过 DAG 构建和拓扑排序生成翻译。
- 特定模板优先,生成更自然的翻译文本。
- 优点:
- 通过模板组合生成的翻译更加简洁流畅。
- 能处理复杂查询图,支持特定模板和通用模板的混合使用。
- 适用场景:
- 复杂查询图,尤其是包含多关系和多条件的查询。
D. Discussion
1. 算法适用范围
- 目前的算法主要适用于 SPJ 查询(包括路径、嵌套等),但对于分组(GROUP BY)和排序(ORDER BY)的查询部分没有详细讨论。
- 分组和排序通过路径上的 γ(分组边)或 o(排序边)处理,生成相应短语 gStr 和 oStr。
- 对于嵌套查询,这些短语可能会与翻译文本的其他部分融合,但由于篇幅限制,未深入讨论。
2. 其他查询结构的处理
- 函数和计算(如 r 边和函数 f):
- 没有详细讨论,但可以按照类似的方式进行处理。
- 析取谓词(Disjunctive Predicates):
- 与联合谓词类似,只需要调整协调词(如用 “or” 代替 “and”)。
- 需要注意操作符的优先级。
3. “复杂”查询的处理
- 复杂查询特点:
- 包含大量连接链(joins)和投影属性。
- 生成的翻译文本可能过长且不美观,这对技术熟练的用户可能不够有用。
- 解决方法:
- 使用模板生成 “查询摘要”,作为翻译的起点,帮助用户理解查询。
- 可以限制投影属性的数量,通过 “heading attributes”(如
Students的name属性)代表关系的特征属性,生成简洁的初始翻译,然后根据用户需求扩展翻译。
4. 对复杂谓词的支持
- 特殊谓词例子:
having count(distinct year) = 1:隐含“所有”的语义,如“找到所有课程都在同一年上的学生”。where year < all (<subquery>):隐含“最早”的语义,如“找到参加最早年份课程的学生”。
- 解决方法:
- 对于这些复杂谓词,TMT 算法尤其有效,因为它允许通过模板捕获额外的语义知识。
5. 讨论总结
- TMT 算法不仅适用于常见的 SPJ 查询,还能处理复杂查询(如包含分组、排序、复杂谓词的查询)。
- 对于技术用户的复杂查询,翻译可能不够实用,但生成摘要可以用于查询文档化或初步理解。
- TMT 特别擅长处理需要语义推理的复杂谓词(如隐含 “all” 或 “earliest” 的查询),为查询翻译提供了更强的灵活性。
总结
讨论部分指出了当前算法的适用范围、未深入处理的部分(如分组、排序)、对复杂查询的应对方法(如查询摘要)以及 TMT 在复杂查询场景中的优势。它强调了模板的灵活性和语义推理的重要性,使得翻译更加智能和实用。
EXPERIMENTS
系统工具与实现
- SQL 查询解析:
- 使用 General SQL Parser 工具,将 SQL 查询解析为 XML 格式的语法树。
- 查询翻译模块:
- 将 XML 解析结果转换为查询图,使用 C++ 实现。
- 利用 Boost 图形库(Boost Graph Library)处理查询图。
实验目标
实验旨在评估所提方法的性能和有效性,研究以下查询特性对翻译的影响:
- 深度(Depth): 查询图中最长路径上的关系数量。
- 出度(Out-degree): 查询图中某关系节点指向其他关系节点的边数量(将查询图转为 DAG 时计算)。
- 成员边数量(μ-degree): 查询图中总的成员边数。
- 值节点数量(σ-degree): 查询图中总的值节点数。
- 紧凑度(Compactness):
- 计算公式:紧凑度=(关系总数)/(最长路径上的关系数量)。
对具体算法的研究
- BST(Breadth Search Translation):
- 研究查询主题对翻译的影响。
- MRP(Multi Reference Points):
- 研究参考点数量对翻译的影响。
- TMT(Template Matching and Translation):
- 研究模板数量对翻译的影响。
实验环境
- 使用 CourseRank 数据库的模式进行实验:
- 包含 20 个关系,每个关系平均有 5 个字段。
实验通过研究查询的深度、出度、边数量、紧凑度等特性,分析了翻译算法在不同条件下的性能和有效性。结合 BST、MRP 和 TMT 的具体特性,对查询主题、参考点和模板数量的影响进行了详细探讨。
A. Effectiveness
实验目标
实验旨在评估三种翻译算法(BST、MRP 和 TMT)的有效性,分为两部分:
- SQL → NL(SQL 查询到自然语言): 测试翻译算法生成的自然语言解释的质量和可理解性。
- NL → SQL(自然语言到 SQL 查询): 测试用户从生成的自然语言描述反推 SQL 查询的难易程度。
1. SQL → NL 实验
实验设置:
- 使用 SQL 专家作为实验对象,评估查询翻译的可理解性和自然性(评分 1 到 10)。
- 比较 BST、MRP 和 TMT 的翻译效果,以及专家手动翻译(USER)结果。
- 重点分析查询特性对翻译结果的影响:深度(depth)、投影属性数(μ-degree)、值节点数(σ-degree)和紧凑度(compactness)。
实验结果:
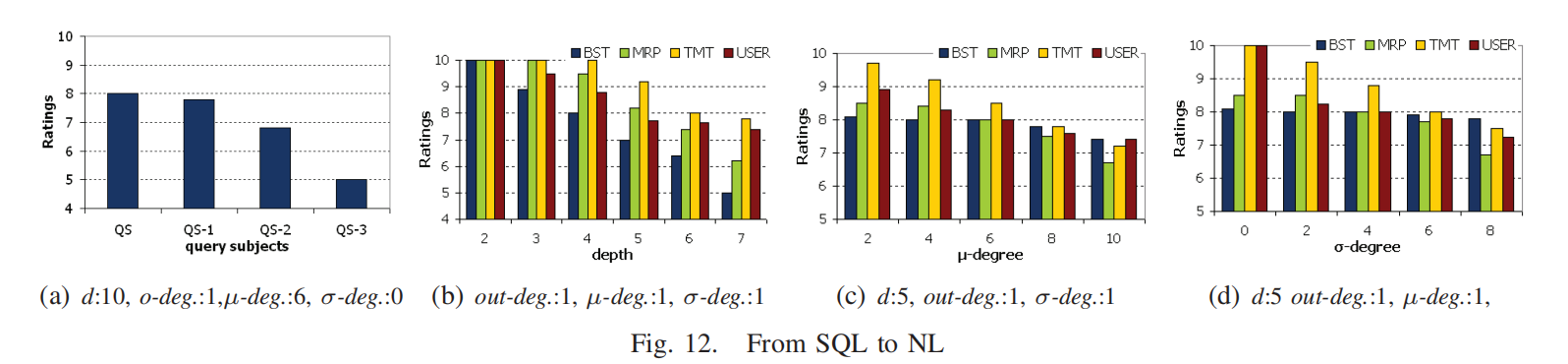
- 查询主题的影响(Fig. 12(a)):
- BST 的查询主题(Query Subject, QS)越“中心”(即更靠近查询图的其他节点),生成的子句更平衡、信息更集中。
- 手动设置的非中心查询主题(如偏离中心 1、2…步)会降低翻译质量。
- 深度的影响(Fig. 12(b)):
- 随着查询图深度增加,所有翻译方法的评分下降。
- BST 受深度影响最大:长路径导致翻译结果不自然。
- MRP 通过插入参考点改善了长路径问题,但效果略逊于 TMT。
- TMT 使用特定模板减少了模板数量,即使查询复杂性增加,翻译仍较为流畅。
- 投影属性数的影响(Fig. 12(c)):
- BST 对属性数的变化更“免疫”,在属性数多时表现最好。
- TMT 由于模板局限性(尤其在处理投影时),翻译质量随投影数增加而下降。
- 用户(USER)翻译倾向于 BST 风格,即先描述投影,再处理值选择。
- 值节点数的影响(Fig. 12(d)):
- BST 处理值节点最不受影响,因为值选择被单独放在翻译末尾。
- MRP 将值选择融入翻译中,效果平滑,但在值节点多时稍逊于 BST。
- 用户翻译结果介于 BST 和 MRP 之间。
- 紧凑度的影响(Fig. 15):
- 查询图越紧凑(更多分支,中心关系更明显),BST 和 MRP 翻译质量越高。
- 对非常紧凑的查询图,MRP 不需要参考点,效果与 BST 接近。
- TMT 的优势:
- TMT 翻译常比用户手动翻译评分更高,尤其是小型查询。
- TMT 通过模板生成更具表现力、自然流畅的翻译文本,但依赖模板的设计质量。
2. NL → SQL 实验
实验设置:
- 用户从生成的自然语言描述中反推 SQL 查询,测量正确率和难易度评分(1 到 10)。
- 比较 BST、MRP 和 TMT 翻译文本在 SQL 重构任务中的效果。
实验结果:
- BST 的优势:
- BST 翻译将投影、连接、值选择分开生成单独子句,逻辑清晰,用户更易理解和重构 SQL。
- MRP 的特点:
- MRP 翻译通过参考点分段描述查询,适合简单查询,但对于多个投影的查询,用户重构难度增加。
- TMT 的不足:
- TMT 提供更高层次的抽象描述,帮助用户理解查询语义,但增加了映射到 SQL 具体操作的复杂性。
- 有时 TMT 翻译可能导致语义等价但形式不同的 SQL(如嵌套查询的情况)。
结论
- 针对不同需求选择翻译方法:
- TMT: 如果愿意设计高质量的特定模板,TMT 可生成更自然、流畅的翻译文本,适合解释查询语义或文档化。
- BST: 全自动化方法,适合需要逻辑清晰、易重构为 SQL 的场景。
- MRP: 平衡方法,结合了 BST 的自动化和 TMT 的结构性,适合需要中等复杂度的翻译。
- 未来改进方向:
- 探索混合翻译方法(结合 TMT 的模板优势与 BST/MRP 的逻辑性)。
- 通过用户反馈优化模板设计,进一步提升翻译质量和可用性。
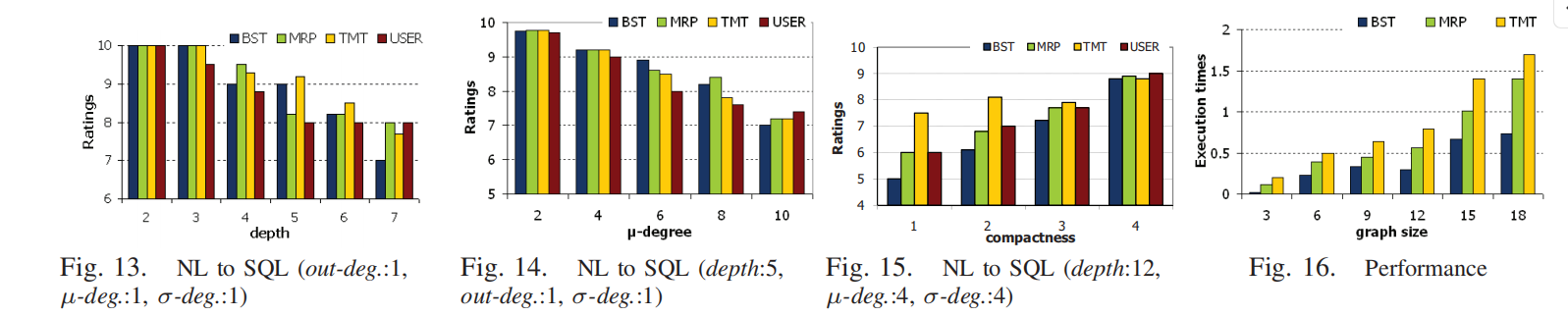
B. Performance
影响性能的主要因素
- 查询图的规模:
- 性能主要受查询图规模的影响,包括:
- 关系节点的数量。
- 属性节点的数量。
- 值节点的数量。
- 模板数量对性能的影响较小(在实验中的模板数据库中未观察到明显的性能开销)。
- 性能主要受查询图规模的影响,包括:
- 算法间的性能比较:
- BST(最快):
- 仅对查询图进行一次遍历,因此效率最高。
- MRP(中等速度):
- 为寻找和连接参考点,需在图中往返遍历部分连接(joins),增加了时间开销。
- TMT(最慢):
- 为找到候选模板和确定模板组合顺序,需要多次读取查询图的边,因此耗时最长。
- BST(最快):
实验结果
- 图 16 显示了三个算法的执行时间:
- BST 时间最短,效率最高。
- MRP 次之,因为它需要多次遍历部分图。
- TMT 时间最长,由于多次模板匹配和组合处理增加了开销。
总结
- BST 适合对性能要求高的场景,尤其是快速生成翻译结果。
- MRP 在性能和翻译质量之间平衡较好。
- TMT 的性能开销最高,但它能生成更自然、更精确的翻译,适合对翻译质量要求高的场景。
RELATED WORK
1. 自然语言与数据库(NL and DB)
- 早期的研究主要集中在与本研究相反的方向,例如:
- 自然语言查询(NL Querying)[4]。
- 自然语言与模式设计(NL and Schema Design)[11]。
- 自然语言数据库接口(NL and Database Interfaces)[12]。
- 问答系统(Question Answering)[13]。
- 过去的研究中:
- 翻译小型数据库的内容或查询答案[8]。
- 探讨了将 SQL 查询翻译为叙述的实用性[5]。
- 与内容翻译的区别:
- 查询翻译更难,因为查询的规模和复杂性没有上限,而数据库内容受模式结构限制,有上限。
2. 查询图表示法(Query Graph Representations)
- 查询图在查询优化中已有广泛应用[6]、[14]、[7]:
- 例如,查询图模型(QGM)提供了 SQL 查询的概念化表示[7]。
- 查询图用于表示与查询优化和处理相关的信息(如操作和数据流)。
- 本研究的区别:
- 关注查询的语义(“查询描述了什么”)而非操作(“如何生成答案”)。
- 查询图模型捕捉了查询的语义元素及其关联。
3. 图和集合问题(Graph and Set Problems)
模板选择问题
分为两个子问题:
- 图包含问题(Graph Containment):
- 受到大规模图数据库索引和剪枝方法研究的启发[15]。
- 采用精确匹配方法,适用于模板图数据库的规模。
- 图覆盖问题(Graph Cover):
- 给定查询图 ggg 和一组子图 {g1,g2,…}{g_1, g_2, …}{g1,g2,…},找到最小的可组合子图集以覆盖 ggg。
- 可组合性:子图需共享特定节点。
- 图包含问题(Graph Containment):
与其他问题的区别:
- 与图分解(Graph Decomposition)不同,后者将图分解为边集不重叠的子图[16]、[17]。
- 与集合覆盖问题(Set Cover)类似,但在本研究中,集合不能自由组合,需考虑可组合性约束。
总结
本研究在自然语言和数据库的交互、查询图的语义表示以及图/集合覆盖问题的基础上进行了扩展:
- 将重点从操作层面转向语义层面。
- 设计了专门的算法解决具有约束的图覆盖问题,用于支持查询翻译。
CONCLUSIONS AND FUTURE WORK
1. 研究工作总结
- 本文探索了 将 SQL 查询翻译为自然语言文本 的新问题。
- 提出了一个将结构化查询表示为有向图的模型,通过为图的边注释模板标签来捕获查询语义。
- 将查询翻译问题映射为图问题,并提出了多种图遍历策略,用于高效探索查询图并生成文本描述。
- 提出的算法能够捕获数据库实体之间的重要语义关联,为数据库模式提供更高层次的抽象。
- 实验结果表明,该方法具有很好的潜力,是将结构化查询翻译为自然语言的首次尝试。
2. 未来研究方向
- 自适应翻译方法:
- 研究一种能够根据查询特性动态调整翻译策略的自适应方法。
- 模板推荐:
- 研究通过分析查询日志挖掘查询中的有趣或常见关联,为模板分配提供建议。