
Teaching Code LLMs to Use Autocompletion Tools in Repository-Level Code Generation
Teaching Code LLMs to Use Autocompletion Tools in Repository-Level Code Generation
ABSTRACET
摘要:近年来,大型代码语言模型(LLMs)在生成独立函数方面表现出色。然而,由于缺乏对仓库级依赖(如用户自定义属性)的感知,它们在仓库级代码生成中存在一定局限性,容易导致依赖性错误,例如未定义变量错误和缺少成员错误。在本研究中,我们提出了TOOLGEN方法,通过将自动补全工具集成到代码LLM的生成过程中,以解决这些依赖性问题。TOOLGEN包含两个主要阶段:触发器插入和模型微调(离线阶段),以及工具集成代码生成(在线阶段)。在离线阶段,TOOLGEN对给定代码语料库中的函数进行增强,加入一个特殊的标记符号,用于指示触发自动补全工具的位置。这些增强的函数及其对应的描述随后用于微调所选的代码LLM。在在线阶段,TOOLGEN通过微调后的LLM逐步预测生成函数的每个标记。当遇到标记符号时,TOOLGEN调用自动补全工具提供代码补全建议,并通过约束贪婪搜索选择最合适的建议。
我们进行了全面的实验,评估了TOOLGEN在三种代码LLM(CodeGPT、CodeT5和CodeLlama)上的仓库级代码生成效果。为了辅助评估,我们创建了一个包含671个真实代码仓库的基准数据集,并引入了两个新的依赖性指标:依赖覆盖率(Dependency Coverage)和静态有效率(Static Validity Rate)。实验结果表明,TOOLGEN在三种代码LLM上显著提升了依赖覆盖率(31.4%至39.1%)和静态有效率(44.9%至57.7%),同时在广泛认可的相似性指标(如BLEU-4、CodeBLEU、编辑相似度和精确匹配)上也保持了竞争性或更好的表现。在CoderEval数据集上,TOOLGEN在CodeT5和CodeLlama的测试通过率(Pass@1)上分别提升了40.0%和25.0%,同时在CodeGPT上保持了相同的通过率。此外,TOOLGEN在仓库级代码生成中表现出较高的效率,每个函数的生成延迟在0.63至2.34秒之间。进一步的通用性评估证实,TOOLGEN在不同代码LLM模型架构和规模上的表现始终保持一致。
INTRODUCTION
Background
代码生成的背景与发展:
- 代码生成一直是软件工程领域的重点研究方向。
- 最近的研究引入了多种基于Transformer模型架构的大型代码语言模型(LLMs),通过对大规模代码语料库的预训练或微调,实现了代码自动生成。
- 这些LLMs在代码块或函数的生成中表现出色,例如CodeLlama在HumanEval和MBPP等基准测试中达到了开源代码LLMs的最新性能。
现有代码LLMs的局限性:
- 实际代码仓库中超过70%的函数并非独立函数,而代码LLMs缺乏对仓库级依赖(如用户自定义函数和属性)的感知。
- 这种局限性会导致生成的代码中出现依赖性错误(如未定义变量错误和缺少成员错误),显著降低其可用性和有效性。
现代IDE的自动补全工具:
- IDE中的自动补全工具(如Jedi)通过程序分析,能分析当前不完整的函数状态和上下文,提供有效的代码补全建议。
- 这些工具可以推荐当前对象可访问的变量、属性和函数。例如:
- 在图1中,Jedi面对“self.”时,推荐了68个属性,其中包括目标建议“_registered_updates”。
外部工具与LLMs的结合尝试:
- ToolFormer:通过增强数据集,教会LLMs调用现有的外部工具(如算术计算器),显著减少涉及算术计算的文本生成错误。
- ToolCoder:设计用于指导LLMs在生成代码时使用基于信息检索(IR)的API搜索工具,主要解决独立函数的功能正确性,但其忽略了仓库级依赖。
- Repilot:利用代码补全工具过滤掉LLMs生成的无效修复建议,专注于单点错误修复(如生成单块补丁),但在函数级代码生成中会频繁调用自动补全工具,导致开销较大。
工具结合的挑战:
- 当前工具(如ToolCoder)未充分考虑仓库级依赖,难以解决依赖性错误。
- 对多候选建议的处理能力不足,使得这些工具在复杂场景下的应用效果有限。
Motivation example
图1示例说明:
问题
:在代码仓库“zomux/deepy”的文件“layers/layer.py”中,函数register_updates的生成场景。
- CodeLlama生成结果:预测了属性“_updates”,但因“self”对象没有该属性,导致“no-member error”错误。
- Jedi补全结果:推荐了68个属性,其中包含目标“_registered_updates”,可以有效避免上述错误。
意义: 通过结合像Jedi这样的自动补全工具,能够显著提高代码生成的正确性,解决依赖性错误的问题。

Approach
目标
将基于程序分析的代码自动补全工具集成到代码LLMs的生成过程中,以支持仓库级代码生成。
主要挑战
- 触发自动补全工具的时机:
- LLMs逐步解码生成代码,每步生成一个标记,但函数可能包含数十到数百个标记,不可能在每步都调用补全工具。
- 现有方法(如ToolFormer、ToolCoder)通过标注特殊标记来触发工具,但对仓库级依赖的处理效果不佳,需精准定位用户自定义变量等依赖的位置。
- 从推荐建议中选择目标补全:
- 补全工具(如Jedi)通常返回多个建议(如图1中有68个),目标建议可能并不在列表前列。
- 需要基于生成的代码评估建议,选择最合适的补全,同时保证生成过程的高效性和连贯性。
解决方案:TOOLGEN
TOOLGEN分为两个主要阶段:
- 离线阶段:
- 触发器插入:
- 分析代码仓库中的源文件,通过抽象语法树(AST)提取函数定义。
- 在函数中插入特殊标记
<COMP>,标记可能触发补全工具的位置(如涉及仓库依赖的标识符)。
- 模型微调:
- 使用带有
<COMP>标记的增强函数及其描述,微调选定的代码LLM。
- 使用带有
- 触发器插入:
- 在线阶段:
- 工具集成代码生成:
- 基于给定描述,通过微调后的LLM逐步生成函数。
- 遇到
<COMP>标记时,调用自动补全工具并基于当前仓库上下文获取补全建议。 - 使用约束贪婪搜索算法评估建议,选择最合适的补全并添加到生成的代码中。
- 持续预测标记,直至满足终止条件。
- 工具集成代码生成:
关键创新
通过触发器插入和约束搜索的结合,TOOLGEN解决了仓库级依赖问题和补全建议选择的难题,显著提高了仓库级代码生成的准确性和效率。
Evaluation and contributions
实验设计与评估
- 评估对象:
- 在三种代码LLMs(CodeGPT、CodeT5、CodeLlama)上评估TOOLGEN在仓库级代码生成中的效果。
- 数据集:
- Benchmark:包含12,406个Python函数(来自671个真实代码仓库)和176个来自CoderEval数据集的编程任务。
- 新定义的指标:
- 依赖覆盖率(Dependency Coverage):衡量生成函数中成功覆盖的仓库级依赖的比例。
- 静态有效率(Static Validity Rate):衡量生成函数通过依赖错误检查的比例。
- 实验结果:
- 相似性指标:TOOLGEN在BLEU-4、CodeBLEU、编辑相似度和精确匹配等标准指标上表现出与现有方法相当或更优的效果。
- 依赖覆盖率:提升31.4%至39.1%。
- 静态有效率:提升44.9%至57.7%。
- 测试通过率(Pass@1):
- 在CoderEval任务上,CodeT5和CodeLlama分别提升40.0%和25.0%。
- CodeGPT的通过率保持不变。
- 效率:生成效率较高,平均延迟为0.63至2.34秒。
- 通用性:
- TOOLGEN在不同模型架构和规模的代码LLMs上表现一致。
主要贡献
- 提出TOOLGEN:
- 功能:将自动补全工具无缝集成到代码LLMs的生成过程中。
- 方法:
- 离线阶段:通过触发器插入和模型微调生成增强数据集(249,298个Python函数,来自12,231个代码仓库),每个函数插入特殊标记
<COMP>,标记适合调用补全工具的位置。 - 在线阶段:通过工具集成代码生成,实现仓库级代码生成。
- 离线阶段:通过触发器插入和模型微调生成增强数据集(249,298个Python函数,来自12,231个代码仓库),每个函数插入特殊标记
- 建立评估基准:
- 包括12,406个Python函数和176个CoderEval任务。
- 引入两项新仓库级指标:依赖覆盖率和静态有效率。
- 实验验证:
- TOOLGEN显著提升依赖覆盖率和静态有效率,在CodeT5和CodeLlama的测试通过率上也表现突出,同时保持较高生成效率。
总结:TOOLGEN是一种创新方法,显著提升了代码LLMs在仓库级代码生成中的性能,同时在多种模型架构上表现出色。
PRELIMINARIES
A. Code LLMs
代码LLMs分类
- 两种主要模型类别:
- Decoder-only 模型:
- 如图2a所示,这类模型(例如CodeGPT和CodeLlama)仅包含Transformer架构的解码器部分。
- 通过将描述文本(docstring)分解为一系列标记(tokens),逐步生成函数,每一步基于描述文本和前一步生成的上下文预测下一个标记。
- Encoder-Decoder 模型:
- 如图2b所示,这类模型(例如CodeT5和CodeT5+)包含Transformer架构的编码器和解码器部分。
- 描述文本先由编码器处理生成中间表示,然后解码器根据这个中间表示以及前面生成的上下文逐步生成函数。
- Decoder-only 模型:
- 特殊标记(
)的引入 :- 为了让模型识别和预测特殊标记
<COMP>,首先将其加入LLM的词汇表中,扩展后的词汇表用V表示。 - 描述文本或代码片段的标记化(tokenization)和下一标记预测的过程被定义为数学形式:
- 标记化过程:将字符序列转化为标记序列。
- 预测过程:基于描述和当前不完整的函数生成一个概率分布,其中每个标记都有对应的预测概率。
- 为了让模型识别和预测特殊标记
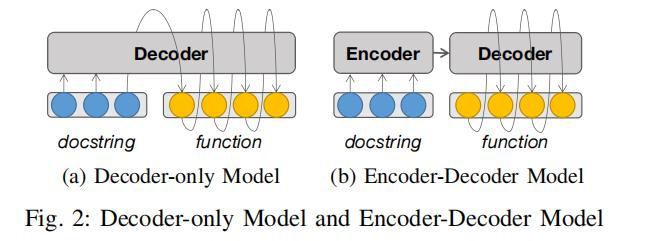
图2对比了两种模型结构在代码生成中的处理方式:
- 图2a(Decoder-only 模型):
- 模型直接从描述文本中提取信息,并在生成函数的过程中仅依赖解码器的上下文信息。
- 优势:结构简单,专注于生成阶段。
- 局限性:描述信息仅通过初始标记传递,信息可能随生成过程逐渐丢失。
- 图2b(Encoder-Decoder 模型):
- 模型使用编码器先对描述文本进行更深层次的语义分析,然后解码器基于中间表示生成函数。
- 优势:编码器提供了全局的上下文表示,更适合复杂的描述和代码依赖。
- 局限性:模型结构更复杂,训练和推理时间可能较长。
图2旨在说明这两种模型在处理描述文本(docstring)到函数生成的不同机制,为理解TOOLGEN的实现提供背景支持。
B. Autocompletion Tools
自动补全工具的功能
输入和输出:
- 输入:自动补全工具需要一个代码仓库和光标位置(由文件名、行号、列号组成的元组)。
- 输出:提供一个补全建议列表,包括可能的标识符(identifiers)。
定义形式:
自动补全过程被定义为:
TOOL-COMPLETE : (Σrepo, Σpos) → Σ∗idenΣrepo:代码仓库的集合。Σpos:光标位置的集合。Σiden:所有可能的标识符集合,Σ∗iden为标识符列表。
限制范围:
- 在本研究中,自动补全工具仅关注标识符级别的补全,不包括以下内容:
- 关键词:因为关键词易于被代码LLMs预测。
- 部分标识符:被完整标识符补全所覆盖。
- 在本研究中,自动补全工具仅关注标识符级别的补全,不包括以下内容:
示例说明
- 在图1中,给定代码仓库和光标位置,Jedi自动补全工具为不完整的函数
"... self."提供了86个补全建议。
意义
此部分主要说明自动补全工具的工作机制和研究中所聚焦的标识符补全,为研究如何集成自动补全工具到代码生成提供基础支持。
APPROACH
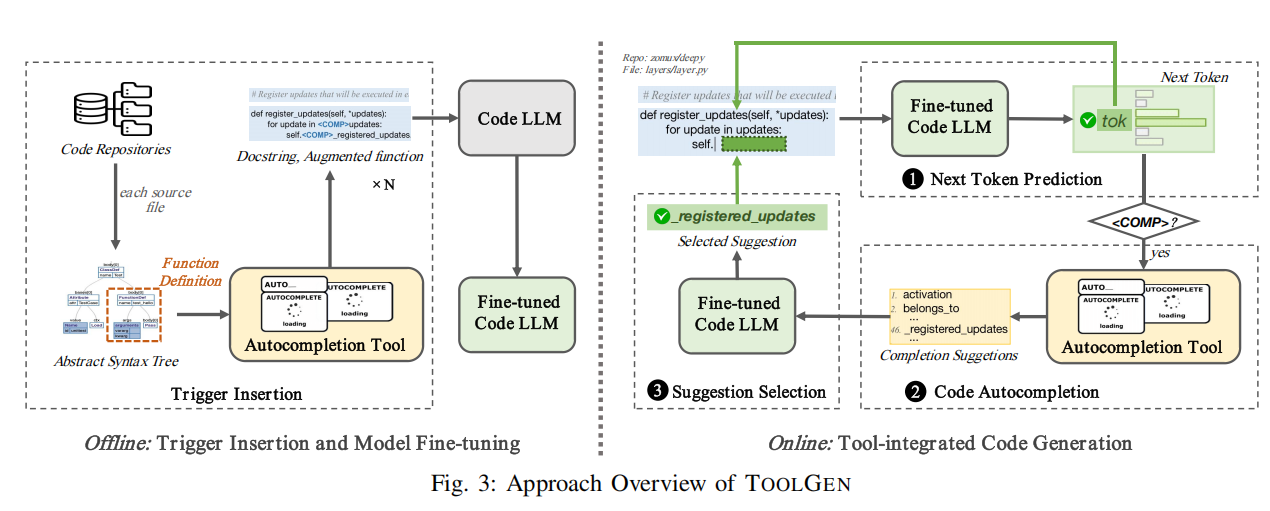
A. Overview
TOOLGEN包含两个主要阶段:
- 触发器插入与模型微调(离线阶段)
- 将代码仓库中的每个源文件解析为抽象语法树(AST),并从中提取函数定义。
- 对每个提取的函数定义,使用自动补全工具生成带有特殊标记
<COMP>的增强函数,标记调用自动补全工具的位置。 - 将描述文本与增强后的函数组合成对。
- 使用这些描述与增强函数对,微调代码LLM,使其能够在适当位置预测
<COMP>,从而触发自动补全工具。
- 工具集成代码生成(在线阶段)
- TOOLGEN通过迭代过程生成函数,每步包括以下操作:
- 预测下一个标记:
- 微调后的代码LLM接收描述和当前不完整的函数作为输入,预测下一个标记。
- 将预测的标记添加到不完整的函数中。
- 触发补全工具:
- 如果预测标记为
<COMP>,触发自动补全工具,返回一个基于当前仓库上下文的补全建议列表。
- 如果预测标记为
- 选择补全建议:
- TOOLGEN通过微调后的代码LLM选择最合适的补全建议,并将其添加到不完整的函数中。
- 预测下一个标记:
- TOOLGEN通过迭代过程生成函数,每步包括以下操作:
意义
TOOLGEN通过离线阶段的标记插入和模型微调,使代码LLM能够自动调用补全工具;在线阶段通过动态集成补全工具和标记预测,有效提升了仓库级代码生成的准确性和效率。
B. Trigger Insertion and Model Fine-tuning
触发器插入与模型微调
触发器插入(Trigger Insertion):
- 目标:通过插入特殊标记
<COMP>,帮助代码LLM学习在何时调用自动补全工具。 - 过程:
- 遍历代码仓库中的每个源文件,解析为抽象语法树(AST),提取函数定义。
- 对每个函数的函数体进行分析,利用算法定位需要触发自动补全工具的位置(具体为标识符)。
- 条件判断:
- 标识符:使用
ISIDENTIFIER检查是否为标识符。 - 非内置属性:使用
ISBUILTIN排除内置属性(如__dict__)。
- 标识符:使用
- 调用自动补全工具获取建议列表
C,若C中包含目标标识符t,则在t前插入<COMP>。
- 结果:
- 生成增强函数代码
Faug,并将其与函数签名和文档字符串(docstring)的组合形成数据对(D, Faug)。 - 如果函数缺少文档字符串,则跳过,因为生成任务依赖描述文本作为输入。
- 累积处理后的所有数据对构成增强数据集。
- 生成增强函数代码
示例(图4):
- 在一个增强函数中,共插入了4个
<COMP>标记,分别标记了自动补全工具推荐列表中包含的标识符:updates、_registered_updates、add和update。 - 作用:这些标记明确了调用自动补全工具的位置,确保代码LLM能准确预测并处理仓库级依赖。
- 目标:通过插入特殊标记
模型微调(Model Fine-tuning):
- 目标:使用增强数据集优化代码LLM的参数,使其学习如何准确预测
<COMP>并触发补全工具。 - 过程:
- 将每对数据
(D, Faug)标记化,输入到基础代码LLM中,进行逐步生成。 - 在每一步,计算下一个标记的预测概率分布与真实标记之间的交叉熵损失。
- 将每对数据
- 参数高效微调(LoRA):
- 对于大规模模型(如CodeLlama-7B),微调所有参数的计算成本高。
- 使用LoRA方法,仅在特定Transformer层的投影矩阵中引入可训练的低秩矩阵,其余参数保持冻结状态,从而实现参数高效的权重更新。
- 目标:使用增强数据集优化代码LLM的参数,使其学习如何准确预测
示例(图4)详解
- 场景:一个增强函数代码中,插入了4个
<COMP>标记。 - 标记位置:
- **
updates**:在补全工具推荐列表中定位到了用户自定义变量。 - **
_registered_updates**:确认该标识符是目标,并在其前插入标记。 - **
add和update**:类似地,通过补全工具识别并标记。
- **
- 意义:
- 插入标记明确了触发工具的时机,有效减少依赖错误。
- 提供清晰的上下文,优化LLM的仓库级代码生成能力。

C. Tool-integrated Code Generation
工具集成代码生成
- 总体流程(Algorithm 2):
- 输入:代码仓库
R、插入位置P、描述文本D。 - 过程:
- 初始化生成序列
F,从<BOS>开始。 - 使用微调后的代码LLM预测下一个标记
tok,基于概率分布选取最高概率标记并加入到F中。 - 如果
tok为<EOS>,生成结束,返回最终函数。 - 如果tok为
: - 触发自动补全工具,基于代码仓库
R和插入位置返回补全建议列表C。 - 使用
LLM-SELECT过程,从C中选择最合适的补全建议并将其加入到F中。
- 触发自动补全工具,基于代码仓库
- 初始化生成序列
- 结果:最终生成函数
F。
- 输入:代码仓库
- 补全建议选择(Algorithm 3,LLM-SELECT):
- 输入:补全建议列表
C。 - 过程:
- 将每个建议标记化并插入前缀树(trie)。
- 基于微调代码LLM的预测,在前缀树中以贪婪方式选择最优路径,对每一步预测进行概率筛选。
- 将选定路径对应的标记序列加入到生成函数
F中。
- 结果:生成包含补全建议的完整函数。
- 输入:补全建议列表
示例解释
- 示例场景(图1):
- 未完成的代码片段为
"... self."。 - 微调后的代码LLM预测下一个标记为
<COMP>,触发自动补全工具。 - 补全工具返回建议列表,包括68个可能的补全项。
- 未完成的代码片段为
- 选择过程(图5):
- 在补全建议生成的前缀树中(图5展示),微调后的代码LLM逐步预测并选择标记。
- 通过贪婪搜索沿着前缀树的绿色路径,最终选择了补全建议
"_registered_updates"。 - 该补全建议被加入到函数中,生成完整的代码片段。
意义
- 工具集成生成:
- 通过动态调用自动补全工具和
<COMP>标记,确保生成的代码适配仓库级依赖。 - 解决LLM单独生成时难以捕捉依赖关系的问题。
- 通过动态调用自动补全工具和
- 补全建议选择的优化:
- 使用前缀树结构对补全建议进行高效管理,结合LLM预测进行筛选,显著提高生成准确性。
- 示例中,从68个建议中精准选择了目标标识符
"_registered_updates",展现了方法的有效性。
- 实际效果:
- 工具集成生成和建议选择策略有效减少了依赖性错误,提高了仓库级代码生成的实用性和精度。
EVALUATION SETUP
A. Research Questions
- RQ1 - 基于相似性的有效性:
TOOLGEN生成的代码在常见相似性指标(如BLEU、CodeBLEU等)下,与真实代码的匹配程度如何? - RQ2 - 基于依赖性的有效性:
TOOLGEN在多大程度上能覆盖仓库级依赖(如用户自定义函数和属性),并减少依赖错误? - RQ3 - 基于执行的有效性:
TOOLGEN生成的代码功能是否正确,并能通过测试用例? - RQ4 - 效率:
TOOLGEN生成单个函数的平均时间是多少? - RQ5 - 泛化性:
TOOLGEN在不同的代码LLMs上是否仍能表现出色的代码生成能力?
B. Implementation
TOOLGEN 实现细节
- 语言与模型选择:
- 语言支持:TOOLGEN被设计为语言无关,但目前开发了专注于Python的原型。
- 基础模型: TOOLGEN使用三种代码LLM,涵盖不同的模型架构和参数规模:
- CodeGPT:
- Decoder-only 模型,基于CodeSearchNet的Python语料库(1.1百万Python函数)预训练。
- 使用CodeGPT-small版本,124M参数。
- CodeT5:
- Encoder-decoder 模型,同样基于CodeSearchNet的Python语料库预训练。
- 使用CodeT5-base版本,220M参数。
- CodeLlama:
- Decoder-only 模型,专注代码任务,基于Llama2开发。
- 预训练于更大规模的Python语料库(1000亿标记)。
- 使用CodeLlama-7b版本,7B参数。
- TOOLGEN变体:TOOLGEN的不同版本分别对应上述模型(TOOLGEN-gpt、TOOLGEN-t5、TOOLGEN-llama)。
- CodeGPT:
- 自动补全工具:
- 使用Jedi作为补全工具,支持静态分析和生成与仓库级依赖(如用户定义的属性和函数)相关的补全建议。
- 触发器插入(Trigger Insertion):
- 数据来源:基于CodeSearchNet数据集的Python语料库,通过爬取数据集列出的代码仓库获取完整代码。
- 过程:
- 提取代码仓库中的Python函数,并按照预定流程对函数进行增强,插入特殊标记
<COMP>。 - 生成增强数据集,包含249,298对描述和增强函数,来自12,231个Python代码仓库。
- 提取代码仓库中的Python函数,并按照预定流程对函数进行增强,插入特殊标记
- 数据统计:
- 描述平均标记数为10.98,增强函数平均标记数为55.31。
- 每个增强函数平均插入5.54个
<COMP>标记。
- 模型微调(Model Fine-tuning):
- 策略:
- CodeGPT和CodeT5:采用全参数微调。
- CodeLlama:使用LoRA参数高效微调,优化3.86%的可训练参数。
- 设置:
- 学习率:5E-6。
- 批量大小:32。
- 微调周期:CodeGPT和CodeT5为10轮,CodeLlama为3轮。
- 一致性:为确保可复现性,所有随机函数设置种子为42。
- 策略:
总结
TOOLGEN通过使用不同架构和规模的模型(CodeGPT、CodeT5、CodeLlama)与Jedi自动补全工具相结合,构建了一个基于Python的增强数据集并进行了微调,实现了仓库级代码生成的优化。其中,LoRA技术显著提高了大规模模型微调的效率。
C. Evaluation Benchmark
- 数据集:
- CodeSearchNet:
- 用于评估基于相似性和依赖性的有效性(RQ1 和 RQ2)。
- 数据集由CodeSearchNet测试集中的代码仓库构建,包含12,406个Python函数,来自671个代码仓库。
- 描述的平均标记数为10.66,函数的平均标记数为54.54。
- CoderEval:
- 用于评估基于执行的有效性(RQ3)。
- 包含176个任务,由43个Python代码仓库中的任务构成,任务包括自然语言描述、真实代码片段和测试用例。
- 按运行级别分类:包括独立运行、自定义依赖运行、文件级运行等。
- 从CoderEval中移除了与训练集重叠的任务。
- CodeSearchNet:
- **基线模型 (Baselines)**:
- Vanilla Baselines:
- 对基础模型(CodeGPT、CodeT5、CodeLlama)进行微调,不包含工具集成。
- 微调基于增强数据集中的原始函数(未包含
<COMP>标记),设置与TOOLGEN一致。 - 分别命名为:
VANILLA-gpt、VANILLA-t5、VANILLA-llama。
- **RAG Baselines (检索增强生成)**:
- 使用REPOCODER框架,结合相似性检索和代码生成。
- 创建三个变体:
REPOCODER-gpt、REPOCODER-t5、REPOCODER-llama,分别使用不同基础模型。
- RAG-TOOLGEN变体:
- 将TOOLGEN与REPOCODER结合,创建
ragTOOLGEN-gpt、ragTOOLGEN-t5和ragTOOLGEN-llama。
- 将TOOLGEN与REPOCODER结合,创建
- Vanilla Baselines:
- **评估指标 (Metrics)**:
- 基于相似性的指标:
- BLEU-4:评估生成代码与真实代码在n-gram上的相似度。
- CodeBLEU:考虑代码特定词汇和结构的生成质量评估。
- **Edit Similarity (EditSim)**:通过编辑操作评估代码片段的字符级相似性。
- Exact Match:衡量生成代码与真实代码完全匹配的比例。
- 基于依赖性的指标:
- **Dependency Coverage (DepCov)**:计算生成函数对仓库级依赖(如用户自定义函数和属性)的覆盖率。
- **Static Validity Rate (ValRate)**:衡量生成代码在静态检查中通过的比例,主要检查
no-member和undefined-variable错误。
- 基于执行的指标:
- **Test Pass Rate (Pass@1)**:计算生成函数通过所有对应测试用例的比例,在CoderEval数据集上评估。
- 基于相似性的指标:
RESULTS AND ANALYSES
A. RQ1: Similarity-based Effectiveness
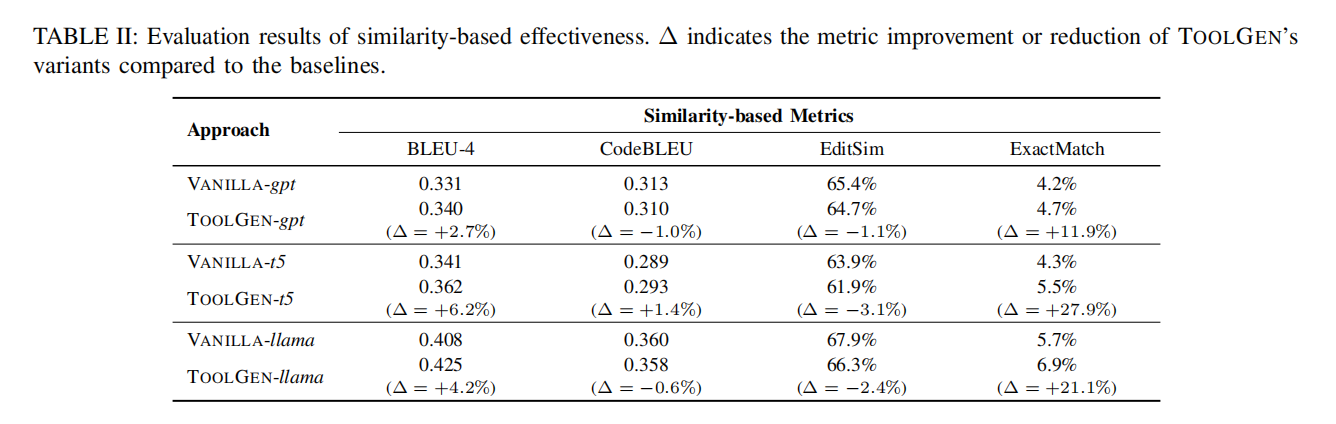
- 评估结果(表II):
- TOOLGEN在相似性指标(BLEU-4、CodeBLEU、Edit Similarity、Exact Match)上的表现与基线模型(VANILLA变体)相当或有所提升。
- CodeGPT 基础模型:
- TOOLGEN-gpt相比VANILLA-gpt:
- BLEU-4提升2.7%,Exact Match提升11.9%。
- CodeBLEU下降1.0%,Edit Similarity下降1.1%。
- TOOLGEN-gpt相比VANILLA-gpt:
- CodeT5 基础模型:
- TOOLGEN-t5相比VANILLA-t5:
- BLEU-4提升6.2%,CodeBLEU提升1.4%,Exact Match提升27.9%。
- Edit Similarity下降3.1%。
- TOOLGEN-t5相比VANILLA-t5:
- CodeLlama 基础模型:
- TOOLGEN-llama相比VANILLA-llama:
- BLEU-4提升4.2%,Exact Match提升21.1%。
- CodeBLEU下降0.6%,Edit Similarity下降2.4%。
- TOOLGEN-llama相比VANILLA-llama:
- Exact Match 分析:
- 尽管Exact Match的提升幅度(0.5%-1.2%)较小,但由于测试集规模大(12,406样本),对应的完全匹配函数增加了62到149个。
- 指标变化原因:
- BLEU-4 与 CodeBLEU:
- 差异源于两种指标使用不同的标记化方法。
- BLEU-4基于代码LLM的标记器,而CodeBLEU使用基于空格的简单拆分法,可能导致匹配n-gram统计的不准确性。
- Edit Similarity:
- 基于字符级别计算,对变量名等语义无关元素非常敏感。
- 不同变量名的字符级相似性显著低于标记级相似性。
- BLEU-4 与 CodeBLEU:
- 总结:
- TOOLGEN在BLEU-4和Exact Match上表现出色,在CodeBLEU和Edit Similarity上表现可比。
- 结果表明,TOOLGEN在相似性指标上具有竞争力,尤其是在生成代码与真实代码的完全匹配方面表现突出。
B. RQ2: Dependency-based Effectiveness
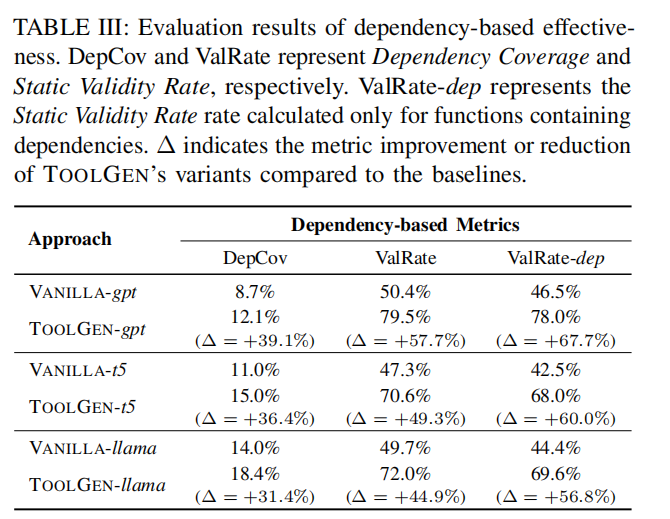
- 依赖覆盖率(Dependency Coverage):
- TOOLGEN在仓库级依赖覆盖率上显著优于基线模型:
- CodeGPT:提升**39.1%**。
- CodeT5:提升**36.4%**。
- CodeLlama:提升**31.4%**。
- 效果说明:
- TOOLGEN通过工具集成生成过程(借助Jedi),增强了对仓库级依赖的感知。
- 示例:在图1中,CodeLlama无法识别
self的有效属性,而TOOLGEN通过补全工具识别候选项,选择最合适的依赖项(如用户定义的属性)。
- 局限性:
- 生成顺序从左到右的暴露偏差问题(Exposure Bias)会导致错误逐步累积。
- 特别是在生成较长函数时,模型可能无法正确触发
<COMP>标记,影响依赖覆盖。
- TOOLGEN在仓库级依赖覆盖率上显著优于基线模型:
- 静态有效率(Static Validity Rate):
- TOOLGEN在仓库级静态分析中的有效率显著高于基线模型:
- ValRate(整体有效率):
- CodeGPT:提升**57.7%**。
- CodeT5:提升**49.3%**。
- CodeLlama:提升**44.9%**。
- ValRate-dep(依赖函数的有效率):
- CodeGPT:提升**67.7%**。
- CodeT5:提升**60.0%**。
- CodeLlama:提升**56.8%**。
- ValRate(整体有效率):
- 效果说明:
- TOOLGEN仅考虑由Jedi推断的有效补全建议,避免了生成无效标识符(如
no-member或undefined-variable错误)。 - 示例:在图1中,CodeLlama可能预测不存在的属性(如
updates),而TOOLGEN通过工具集成避免了该问题。
- TOOLGEN仅考虑由Jedi推断的有效补全建议,避免了生成无效标识符(如
- TOOLGEN在仓库级静态分析中的有效率显著高于基线模型:
- 总结:
- 依赖覆盖率:TOOLGEN在所有模型上提升显著(31.4%-39.1%)。
- 静态有效率:TOOLGEN有效减少无效标识符的生成,提升幅度从44.9%到57.7%不等。
- 意义:
- TOOLGEN显著增强了代码生成对仓库级依赖的感知能力。
- 有效解决了传统代码LLMs在仓库级代码生成中常见的依赖识别和标识符有效性问题。
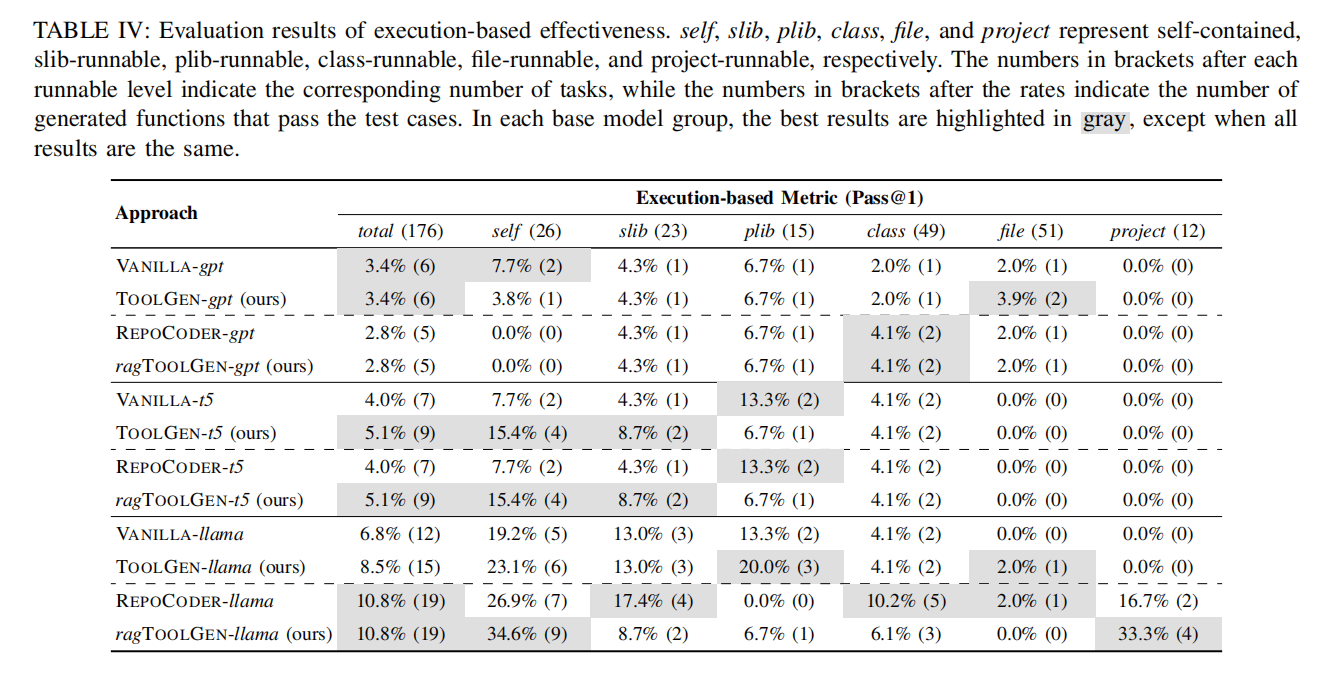
C. RQ3: Execution-based Effectiveness
与VANILLA基线的比较:
- Pass@1改进:
- TOOLGEN-gpt:生成的功能正确函数与VANILLA-gpt相同(0个额外提升),提升幅度为**0%**。
- TOOLGEN-t5:生成了2个额外的功能正确函数,Pass@1提升**40.0%**。
- TOOLGEN-llama:生成了3个额外的功能正确函数,Pass@1提升**25.0%**。
- 任务类型改进:
- TOOLGEN-gpt:改进了文件级任务,但降低了独立任务的通过率。
- TOOLGEN-t5:改进了库依赖(slib-runnable)和文件级任务。
- TOOLGEN-llama:改进了独立任务、公共库依赖(plib-runnable)和类级任务。
与REPOCODER基线的比较:
- 表现波动:
- REPOCODER-gpt和REPOCODER-t5在Pass@1上表现不稳定,未表现出明显提升或有所下降。
- REPOCODER-llama表现突出,Pass@1显著高于VANILLA-llama。
- TOOLGEN对比:
- TOOLGEN-gpt和TOOLGEN-t5分别生成1和2个额外的功能正确函数,相较于REPOCODER-gpt和REPOCODER-t5表现更好。
- TOOLGEN-llama的通过率(15个函数通过)低于REPOCODER-llama(19个函数通过),可能因REPOCODER更好地利用了CodeLlama的参数规模和长序列支持。
与RAG集成的效果:
- ragTOOLGEN-gpt和ragTOOLGEN-t5未显示改进。
- ragTOOLGEN-llama在项目级任务(project-runnable)中表现突出,生成4个额外的功能正确函数,但整体Pass@1未提升。
总结:
- TOOLGEN相较于VANILLA基线模型在Pass@1上有显著提升:
- 改进幅度为0%、40.0%、25.0%(TOOLGEN-gpt、TOOLGEN-t5、TOOLGEN-llama)。
- 与REPOCODER相比,TOOLGEN和REPOCODER在不同模型和依赖级别任务上各有优势。
- TOOLGEN与RAG的结合在某些依赖任务上显示潜力,但整体表现未显著改善,表明不同方法在处理依赖问题时具有互补特性。
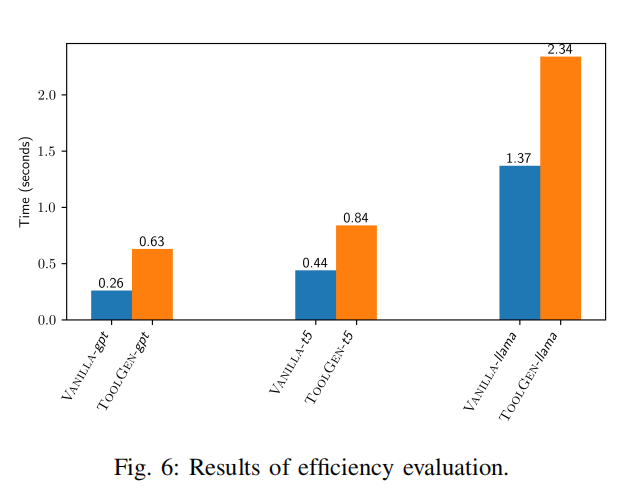
D. RQ4: Efficiency
- 效率评估结果:
- 在NVIDIA H100 Tensor Core GPU(80GB内存)上测试,TOOLGEN在CoderEval数据集的176个任务中,每个函数的生成时间范围为0.63到2.34秒。
- 与基线相比,TOOLGEN的生成时间约为基线的两倍。
- 效率来源:
- 离线优化:
- 触发器插入和模型微调在离线阶段完成,减少了在线生成时的计算负担。
- 触发器预测:
- 自动补全工具仅在预测到
<COMP>标记时被触发,避免了不必要的工具调用。 - 每个任务平均触发
标记的次数: - CodeGPT:5.02次。
- CodeT5:6.24次。
- CodeLlama:7.05次。
- 触发次数远低于函数的平均长度。
- 自动补全工具仅在预测到
- 缓存机制:
- 对重复对象(如
self)的补全建议进行缓存,避免对相同对象的重复调用。
- 对重复对象(如
- 离线优化:
- 总结:
- TOOLGEN在仓库级代码生成中表现出高效性:
- 平均生成延迟为0.63至2.34秒。
- 效率提升得益于触发器标记的预测机制和补全建议的缓存机制,显著减少了工具调用的冗余。
- TOOLGEN在仓库级代码生成中表现出高效性:
E. RQ5: Generalizability
性能表现:
- 依赖性指标:
- TOOLGEN在所有模型架构(Decoder-only和Encoder-Decoder)和参数规模(124M到7B)下,依赖覆盖率和静态有效率均有显著提升。
- 相似性指标:
- TOOLGEN在相似性指标上表现与基线模型相当。
- 执行指标:
- TOOLGEN在Pass@1上有所改进或保持相同水平,同时生成延迟保持在可接受范围内(详见表IV和图6)。
模型适用性:
- TOOLGEN适用于多种基础模型和参数规模,表现出良好的泛化能力。
总结:
- TOOLGEN在依赖性和执行性指标上持续提升或保持,且相似性指标具备竞争力。
- 其方法的通用性和高效性表明,该工具集成生成方法具有在其他基础模型和仓库级代码生成场景中广泛应用的潜力。
DISCUSSION
A. Case Study
Figure 7展示了VANILLA-llama和TOOLGEN-llama在三个具体例子中的表现,每个例子包括描述、真实代码(ground truth)、VANILLA-llama生成的代码和TOOLGEN-llama生成的代码。
- 示例 1:
- TOOLGEN的表现:成功预测了类
Counter中的成员_value。 - VANILLA的表现:错误预测为未定义成员
value,导致no-member error。 - 原因:TOOLGEN通过自动补全工具识别用户定义的属性/成员依赖,避免了类似错误。
- TOOLGEN的表现:成功预测了类
- 示例 2:
- 结果:VANILLA和TOOLGEN都生成了错误代码,未能通过测试用例。
- 原因:描述质量低,未完整表达功能需求。
- 描述仅提到将
w:st="替换为w-st="。 - 实际需求是处理匹配模式
\bw:[a-z]{1,}="的所有字符串。
- 描述仅提到将
- 发现:低质量描述在现实代码生成中是主要挑战,且现有基准中存在描述不准确的问题。
- 示例 3:
- 依赖性分析:
- 正确依赖为
cls._get_service()和ServiceName.PLUGINS_MANAGER。 - VANILLA的表现:预测了不存在的依赖(如
cls._plugins_manager和PluginManager()),导致生成代码无法通过检查和测试。 - TOOLGEN的表现:成功预测
cls._get_service(),但在预测参数时选择了错误的cls而非ServiceName,未能正确生成ServiceName.PLUGINS_MANAGER。
- 正确依赖为
- 发现:
- TOOLGEN虽然能解决部分依赖性问题,但生成过程中任意一步的关键错误都会导致代码最终出错。
- 这表明即使集成了自动补全工具,代码LLMs在实际代码生成中仍然面临重大挑战。
- 依赖性分析:
总结
- TOOLGEN通过集成自动补全工具,在依赖预测方面比VANILLA更有效,但仍受描述质量和生成过程中错误传播的影响。
- 案例突出了:
- 高质量描述的重要性。
- 代码LLMs在处理复杂依赖关系时的局限性,即便使用了工具集成。

B. Limitations
静态补全工具对动态类型语言的局限:
- TOOLGEN目前专注于Python(动态类型语言),其使用的静态分析工具有时无法处理某些仓库级依赖。
- 例如:当函数参数类型无法通过静态分析明确推断时,工具可能无法识别参数类型中的属性。
- 未来计划:探索结合学习型类型推断工具,进一步提升Python代码生成能力。
贪婪预测策略的限制:
- 在生成过程中,TOOLGEN采用贪婪策略(使用ARGMAX函数选择最高概率的标记)。
- 这一策略可能导致选择次优标记,影响后续生成质量。
- 未来计划:引入更高级的解码方法,如束搜索(Beam Search)和其他策略,缓解贪婪预测的缺陷。
依赖性评估指标的局限:
- 依赖覆盖率(Dependency Coverage)和静态有效率(Static Validity Rate)计算依赖静态分析工具。
- 静态工具可能引入一定的不准确性,但对TOOLGEN的相对有效性影响有限,因为基线指标也基于相同的静态分析。
与SOTA闭源LLMs的集成与比较:
- TOOLGEN可应用于任何Encoder-Decoder或Decoder-only模型,但难以集成至如GPT-3.5和GPT-4等闭源LLMs中。
- 原因:闭源模型无法微调,也难以嵌入触发器和工具集成过程。
- 未来计划:研究无需微调的方式,将自动补全工具集成至闭源LLMs。
- 当前评价:评估仅限于TOOLGEN、VANILLA和REPOCODER在相同基础模型下的比较,未与SOTA闭源LLMs进行直接对比。
C. Threats to Validity
- 内部威胁(Internal Threats):
- 数据质量问题:
- 数据质量可能影响学习效果。
- 缓解措施:使用被广泛采用的CodeSearchNet数据集构建增强数据集和评估基准,确保数据来源可靠。
- 数据泄露风险:
- CodeLlama的预训练可能包含评估基准中的部分代码仓库,导致数据泄露。
- 缓解措施:通过泛化性评估(RQ5),验证TOOLGEN在不同模型下的一致性能,表明TOOLGEN-llama的改进并非源于数据泄露。
- 数据质量问题:
- 外部威胁(External Threats):
- 语言特异性:
- TOOLGEN的实现和评估目前仅针对Python,可能无法推广到其他编程语言。
- 未来方向:探索工具集成生成过程在其他编程语言中的应用。
- 语言特异性: