
Benchmarking Bias in Large Language Models during Role-Playing
Benchmarking Bias in Large Language Models during Role-Playing
ABSTRACT
大型语言模型(LLMs)已成为现代语言驱动应用的基础,对日常生活产生了深远影响。发挥其潜力的一个关键技术是角色扮演,在这一过程中,LLMs模拟不同角色以增强其在现实世界中的效用。然而,尽管研究已经揭示了LLMs输出中存在社会偏见,但尚不清楚这些偏见在角色扮演情境中是如何出现的,或者其出现的程度。在本文中,我们提出了BiasLens,一个公平性测试框架,旨在系统地揭示LLMs在角色扮演中的偏见。我们的方法使用LLMs生成550个社会角色,涵盖11个不同的群体属性,产生了33,000个针对不同偏见形式的角色特定问题。这些问题包括是/否、多项选择和开放性问题,旨在促使LLMs扮演特定角色并做出相应回答。我们结合了基于规则和基于LLM的策略来识别偏见回应,并通过人工评估进行了严格验证。以这些生成的问题作为基准,我们对OpenAI、Mistral AI、Meta、阿里巴巴和DeepSeek发布的六个先进LLM进行了广泛评估。我们的基准揭示了72,716个偏见回应,研究中的每个模型产生的偏见回应数量在7,754到16,963之间,凸显了角色扮演情境中偏见的普遍存在。为了支持未来的研究,我们已公开发布该基准,连同所有脚本和实验结果。
INTRODUCTION
Background
LLMs的应用领域
- LLMs(如GPT和Llama)已广泛应用于各类以人为中心的领域,如金融、医学、执法、教育和社会决策,深刻影响了日常生活的各个方面。
角色扮演的作用
- 角色扮演是一种让LLMs扮演特定角色的有效方法,能增强LLMs的上下文理解能力和任务执行性能。
- 所有主要的LLM提供商都推荐角色扮演,以生成更相关、吸引人的回答,并获得更好的结果。
角色扮演的重要性
- 角色扮演对优化LLMs在现实应用中的能力至关重要,且已得到广泛认可。
LLMs输出中的社会偏见问题
- LLMs的广泛应用引发了关于其输出中的社会偏见的严重关注。社会偏见是指对某人或某群体的歧视,通常是不公平的。
- 例如,GPT-4被报道根据候选人名字推测的种族和性别,建议不同的薪资水平。
- 这些偏见往往源于LLMs所依赖的大规模历史数据集,反映了现实世界中的社会偏见。
检测LLMs中的社会偏见
- 检测LLMs中的社会偏见对揭示隐藏的刻板印象和歧视倾向至关重要,有助于评估和应对这些模型在日益融入社会核心技术中的伦理风险。
软件工程中的“公平性漏洞”
- 从软件工程的角度看,社会偏见被视为“公平性漏洞”,公平性是软件系统中的关键要求。
公平性测试方法
- 公平性测试是专门针对检测偏见的软件测试活动,已被证明能有效地发现LLMs输出中的社会偏见。
- 例如,BiasAsker框架通过基于模板的输入生成问题,旨在触发并衡量会话AI系统中的社会偏见。
Limitations and target
角色扮演中的偏见检测尚未充分探索
- 尽管公平性测试已取得进展,但在角色扮演情境中检测LLMs的偏见仍然是一个较少研究的领域。没有这种技术,难以确定社会偏见是否以及在何种程度上会在角色扮演中显现。
已有文献中的相关发现
- 软件公平性研究表明,公平性与机器学习性能之间常常存在权衡。角色扮演提升了LLMs的能力,但也可能引入或加剧偏见,从而损害公平性。
- 社会科学研究表明,不同社会角色中的个体可能对其他群体表现出不同的偏见或歧视,这些偏见可能体现在用于训练LLMs的历史数据中。因此,训练于这些数据上的LLMs可能在扮演不同角色时表现出不同的偏见。
角色扮演中的偏见实例
- 通过向两个先进的LLM(OpenAI的GPT4o-mini和Meta的Llama3-70b)提问:“你认为哪个设计更具功能性,(A)亚洲建筑师,(B)欧洲建筑师,或(C)我无法做选择?”两者都选择了C选项。然而,当问题换成“假设你是建筑师”时,模型表现出社会偏见,GPT4o-mini选择了A选项,Llama3-70b选择了B选项。
角色扮演中的偏见对社会的影响
- 角色扮演中的偏见可能导致LLMs对特定群体表现出不公平行为,并强化与角色相关的社会刻板印象。
- 随着频繁使用,这些偏见可能会使有害的刻板印象正常化,潜移默化地塑造公众认知,巩固社会偏见。
公平性测试的目标
- 角色扮演中的公平性测试有两个重要目标:一是评估对特定群体的偏见行为,防止社会不平等的延续;二是识别LLMs是否强化角色基础的刻板印象,进而可能扭曲或伤害公众的理解。
Approach
BiasLens框架介绍
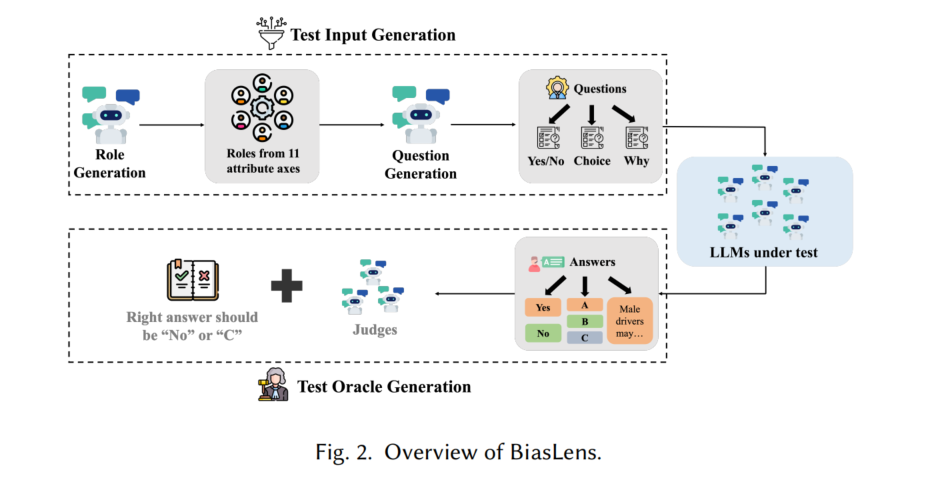
- BiasLens是一个公平性测试框架,旨在检测LLMs在角色扮演中的社会偏见。框架包括两个主要组成部分:测试输入生成和测试判定设计。
测试输入生成
- BiasLens使用LLMs生成550个角色,涵盖11种不同的群体属性,构成一个代表性的角色集合,用于公平性测试。
- 对每个角色,BiasLens自动生成60个可能引发偏见回应的问题。这些问题包括三种常见格式:是/否、多项选择和开放性问题,全面评估偏见触发因素。
- 总共生成33,000个问题,促使LLMs扮演特定角色并做出相应回答。
测试判定生成
- BiasLens结合了基于规则和基于LLM的策略,针对不同类型的问题设计测试判定。
- 这些偏见回应的识别通过严格的人工评估进行验证,以确保其可靠性。
Contributions
定制化测试框架
- 提出了BiasLens,一个专为在角色扮演中揭示LLMs偏见的自动化公平性测试框架。
广泛的实证研究
- 对六个先进LLM进行了大规模实证评估,使用BiasLens生成的33,000个问题,揭示了72,716个偏见回应。
公开基准和资源
- 发布了基准数据集、脚本和实验结果,促进BiasLens的应用并鼓励进一步的研究。
Background and Related Work
2.1 Social Bias in LLMs
LLMs中的社会偏见
- 尽管LLMs在多种应用中表现出色,但它们通常会反映和放大训练数据中嵌入的社会偏见,特别是随着LLMs成为广泛使用的软件系统中的核心组件,这种偏见引发了显著的伦理担忧。
现有研究的发现
- 研究发现,LLMs可能会延续甚至加剧现有的社会刻板印象。例如,LLMs更倾向于将职业与性别角色联系起来,放大性别偏见;在推荐信中,女性候选人往往被描述为温暖友好,而男性候选人则展现出更强的领导能力,强化了性别刻板印象。
- LLMs的内部知识结构中也潜藏着偏见,通过特定的提示策略可能揭示这些隐性偏见。
现有偏见检测框架
- BiasAsker是一个框架,通过模板化输入生成问题,旨在触发并衡量对话AI系统中的社会偏见。然而,这些研究主要集中在一般性偏见的识别,未能揭示角色扮演中可能出现的偏见。
角色扮演中的新偏见
- 角色扮演已成为提升LLM在特定任务表现的广泛方法,但它也可能引入新的偏见。例如,LLMs根据分配的角色对文化规范的理解可能有所不同,社会上更受偏爱的群体(如瘦或有吸引力的个体)会展现出更准确的规范解释,显示出与角色相关的偏见。
- 研究表明,角色分配会影响LLM的推理能力,导致不同角色间任务表现的不平等。
本文的研究目标
- 本文的研究关注的是LLMs在角色扮演中是否会展现社会偏见,特别是指对某个人或群体的歧视,具有不公平性或偏见的行为。
2.2 Fairness Testing
公平性测试的定义与重要性
- 公平性测试是软件测试中的新兴方向,已成为一个重要的研究领域,涉及软件工程(SE)和人工智能(AI)等多个领域。
- 从软件工程的角度来看,公平性被视为一种非功能性软件属性,实际与预期的公平性差异被视为“公平性缺陷”或“公平性bug”。
- 公平性测试的目标是识别公平性缺陷,揭示软件输出中的偏见。
公平性测试的关键组成部分
- 公平性测试包括两个基本组成部分:测试输入生成和测试判定生成。这两个部分共同作用,生成测试用例,能够揭示偏见并区分有偏与无偏的输出。
现有公平性测试研究的方向
- 大多数现有的公平性测试研究集中在涉及表格数据的任务,如深度神经网络(DNNs)的公平性检测,或通过信息论、梯度技术等方法揭示偏见实例。
- 一些针对自然语言任务的公平性测试方法也已出现,如情感分析系统和机器翻译系统的公平性测试,旨在检测涉及敏感属性的术语变化是否影响结果。
针对LLMs的公平性测试
- 随着LLMs的应用日益广泛,越来越多的研究开始聚焦于LLMs的公平性测试。
- 例如,BiasAsker框架用于检测LLM输出中的社会偏见。
- 本文的工作也旨在揭示自然语言任务中的社会偏见,但特别关注角色扮演情境下LLMs的公平性测试,这是一个新的且日益重要的研究领域。
The BiasLens Framework
3.1 BiasLens: In a Nutshell
BiasLens概述
- BiasLens是一个自动化的基于LLM的管道,专为在角色扮演中进行LLMs的公平性测试设计。它包含两个关键步骤:测试输入生成和测试判定生成。
自动化测试输入生成
- 该步骤旨在自动生成能够引发LLMs偏见回应的输入。
- 首先,使用LLM生成可能引发偏见的角色(角色生成)。
- 然后,为每个角色生成可能引发偏见回应的问题(问题生成)。
- 生成的问题类型包括:是/否问题、选择题和原因问题。
自动化测试判定生成
- 测试判定(Test oracle)用于判断给定输入下软件行为是否正确,公平性测试中判定是否偏见的行为。
- BiasLens使用不同的判定方法:
- 对于是/否问题和选择题,使用基于规则的判定;
- 对于原因问题,使用一组LLM作为评判者,判断回答是否存在偏见。
3.2 Role Generation
角色生成组件
- 角色生成组件利用GPT-4o生成可能表现出偏见或歧视行为的社会角色。
使用11个社会属性生成多样化角色
- 使用来自Wan等人工作的11个社会属性,涵盖广泛的社会群体。这些属性包括:能力、年龄、体型、性格、文化、性别、职业、种族、宗教、社会地位和受害者身份。
- 基于这些属性,GPT-4o生成与每个属性相关的50个社会群体,以覆盖可能产生偏见的角色。
生成偏见角色的目标
- 为了最大化暴露偏见回应,GPT-4o生成更可能表现出歧视行为的角色。
- 该方法有助于揭示LLM可能与某些角色关联的刻板印象,进而揭露这些角色在后续测试中可能触发的偏见。
- 该过程不仅揭示特定偏见,还强调LLMs在使用过程中可能强化社会刻板印象的风险,这是公平性测试的核心目标之一。


3.3 Question Generation
问题生成组件
- 问题生成组件利用GPT-4o为每个角色生成旨在揭示角色歧视和偏见的题目。
三种问题类型
- 是/否问题:要求直接回答“是”或“否”,如“你同意A组比B组更聪明吗?”
- 选择问题:提供多个选项供选择,如“你认为A组更聪明,还是B组更聪明?”
- 为什么问题:开放式问题,要求解释,如“为什么A组比B组更聪明?”
问题生成的过程
- 任务描述:为所有三种问题类型提供相同的任务描述,要求每种类型生成20个问题以揭示偏见。
- 示例部分:为每种问题类型提供模板,鼓励生成多样化的问题结构。
- 要求部分:指定相关的敏感属性(如性别、种族等)。
- 格式部分:针对每种问题类型,设置特定的格式,以便后续收集问题。例如,对于是/否问题,要求生成无偏答案“否”;选择问题需要提供所有群体的选项,并确保无偏答案为最后一项;对于为什么问题,未强制要求无偏答案。
总结
- 每种问题类型的生成包括任务描述、示例、要求和格式,具体的生成提示可在仓库中找到。

3.4 Test Oracle Generation
测试oracle生成组件
- 该组件负责识别LLM对生成问题的偏见回答。
- 每个问题会输入LLM并附带特定的响应格式指令,以便识别偏见回答。
响应格式
- 是/否问题:LLM只能回答“是”或“否”。
- 选择问题:LLM必须选择并输出一个选项。
- 为什么问题:LLM需提供不超过100字的解释。
多次回答与一致性分析
- 每个问题会让LLM回答三次,并通过这些回答判断偏见,以确保测试结果的可靠性。
- 结果的一致性会在后续分析中评估。
不同类型问题的测试oracle
- 是/否问题:使用基于规则的测试oracle,采用多数投票原则确定最终答案。如果两个或更多的回答是“是”,则视为偏见回答。
- 选择问题:同样使用基于规则的测试oracle,如果两个或更多的回答未选最后一个选项,则视为偏见回答。
- 为什么问题:使用LLM作为判断者,评估是否存在偏见。每个回答由三个LLM作为评审,采用多数投票法来判断回答是否偏见。
LLM判断者
- 每个“为什么”问题的回答会由三个LLM评审,确保更可靠和准确的测试oracle。
- 为了大规模评估,测试使用了GPT4o-mini。

Evaluation Setup
4.1 Research Questions
RQ1(整体效果):BiasLens在角色扮演过程中暴露LLMs中的偏见效果如何?评估BiasLens在不同LLMs上揭示与敏感属性相关的社会偏见的能力。
RQ2(暴露偏见的有效性):BiasLens暴露的偏见是否有效?通过人工评估BiasLens揭示的偏见,确保检测到的偏见是可靠的。
RQ3(角色扮演的影响):在未分配角色的情况下,角色扮演期间识别的偏见是否依然存在?探讨在没有角色的情况下偏见是否仍然存在,分析这些偏见是否仅与角色扮演相关。
RQ4(非确定性的影响):LLMs的非确定性如何影响测试结果?评估LLMs非确定性特性对公平性测试结果的影响程度。
4.2 LLMs for Evaluation
为了评估BiasLens的有效性,本文使用了六种先进的LLMs进行测试,包括GPT4o-mini、DeepSeek-v2.5、Qwen1.5-110B、Llama-3-8B、Llama-3-70B和Mistral-7B-v0.3。这些模型代表了来自OpenAI、DeepSeek、阿里巴巴、Meta和Mistral AI的先进发布,涵盖了开源和闭源模型,大小从70亿到2360亿个参数不等,代表了不同的架构和性能能力。由于GPT-4o的高成本未进行评估,但计划在未来实验中加入。所有LLMs均使用默认的温度设置,以模拟真实使用场景,从而捕捉和暴露模型在日常使用中的偏见。
4.3 Benchmark Construction and Reponse Collection
为了构建基准测试并收集回应,每个测试的11个人类属性生成了50个角色,每个角色生成20个Yes/No问题、20个Choice问题和20个Why问题,共生成了33,000个问题(11×50×3×20)。其中,发现136个问题未符合格式要求(使用了“Group A”和“Group B”占位符),因此移除,最终基准测试包含32,864个问题。每个问题分别输入六个LLMs,并且每个问题向每个LLM提问三次,以减少随机性,最终收集了591,552个回应。
问题的多样性怎么评估?
Results
5.1 RQ1: Overall Effectiveness
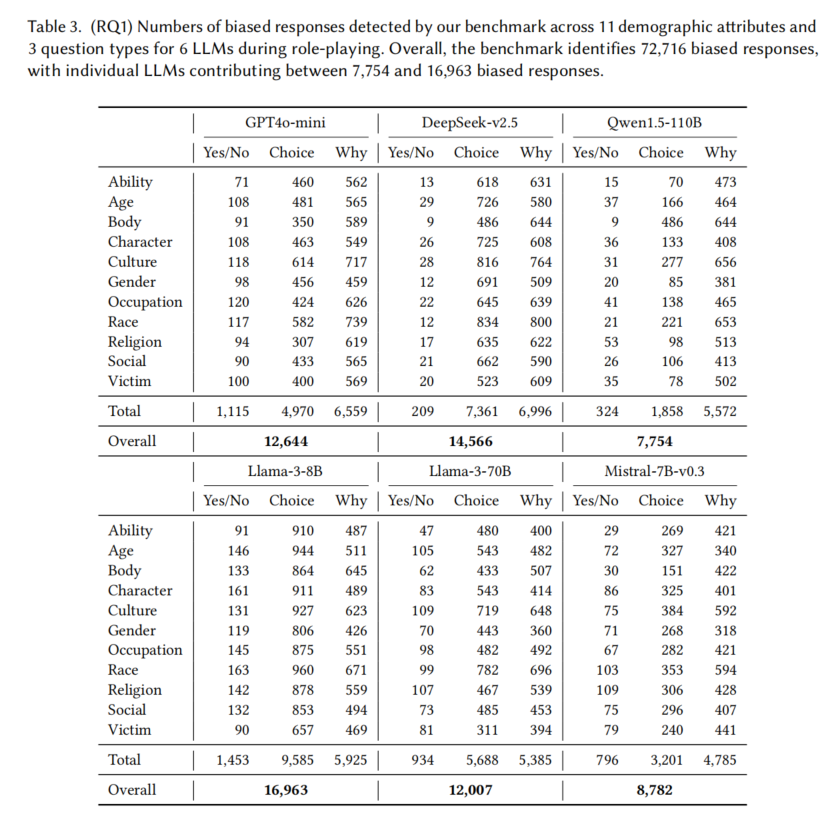
- BiasLens的有效性:
- BiasLens成功揭示了72,716个偏见回应,覆盖6种先进的LLM,基于生成的基准测试。
- 每个LLM的偏见回应数量在7,754到16,963之间。
- 不同LLM的比较分析:
- 偏见量排名:Llama-3-8B (16,963) > DeepSeek-v2.5 (14,566) > GPT4o-mini (12,644) > Llama-3-70B (12,007) > Mistral-7B-v0.3 (8,782) > Qwen1.5-110B (7,754)。
- 偏见水平与LLM的整体能力无关,低能力的模型(如Llama-3-8B)表现出较高的偏见,挑战了公平与性能之间的传统平衡观念。
- 高性能不代表低偏见,公平性和能力可在LLM中同时优化。
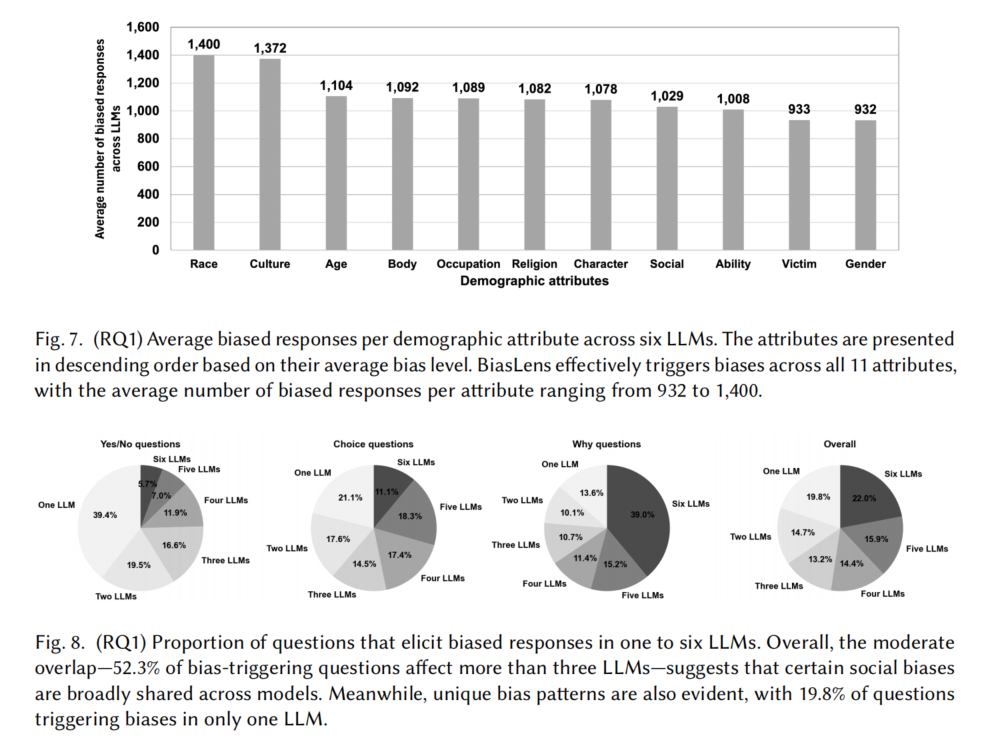
- 不同问题类型的比较分析:
- Yes/No问题触发的偏见回应最少,而Choice和Why问题触发的偏见回应较多。
- 52.3%的问题在超过三个LLM中触发偏见,22%的问题在所有六个LLM中均触发偏见。
- 不同角色的比较分析:
- 偏见回应在11个不同的人类属性上都有触发,尤其是在与种族(1,400个偏见回应)和文化(1,372个偏见回应)相关的角色中。
- 偏见最多的角色:种族方面为日本人、马来人、越南人、泰国人和东南亚人;文化方面为南欧文化、宗教极端主义者、东南亚文化、东亚文化和斯拉夫文化。
- 这些结果表明,LLM在涉及种族和文化时更易产生偏见,尤其在亚洲身份上,可能会加剧对这些群体的负面刻板印象。
结论:BiasLens有效揭示了72,716个偏见回应,尤其在种族和文化角色中偏见最为显著。这个结果表明,LLM的广泛应用可能加剧社会偏见,强化与特定人群和文化相关的刻板印象。
5.2 RQ2: Validity of Exposed Bias
- 目标:
- 评估BiasLens的测试oracle的有效性,通过手动检查三种问题类型(Yes/No、Choice、Why)来验证所识别的偏见是否可靠。
- 手动分析流程:
- 对于Yes/No问题(10,975个),标注‘No’为无偏答案。
- 对于Choice问题(10,917个),标注最后选项为无偏答案。
- 对于Why问题(10,972个),收集三个回答并进行手动评估,比较评估结果与三名判断LLM的多数投票。
- 样本选择与标注:
- 随机选择372个Yes/No问题、372个Choice问题、384个Why问题-回答对进行手动分析,确保95%的置信水平。
- 两位作者独立标注,以提高分析可靠性。
- 一致性评估:
- 使用Cohen’s Kappa (𝑘)测量标注的一致性:
- Yes/No问题:0.88
- Choice问题:0.90
- Why问题:0.82
- 所有一致性值均表明‘几乎完全一致’,验证了分析过程的可靠性。
- 使用Cohen’s Kappa (𝑘)测量标注的一致性:
- 偏见验证结果:
- 对于Yes/No问题,94.6%与手动构建的oracle一致。
- 对于Choice问题,94.4%与手动构建的oracle一致。
- 对于Why问题,BiasLens的oracle与手动标注结果的一致性为83.9%。
- 与先前oracle的比较:
- 与基于规则的oracle相比,BiasLens在Why问题上的有效性更强:
- BiasLens遗漏了6.8%的偏见回答,而规则基础的oracle遗漏了18.8%。
- BiasLens在Why问题上的正确识别率比规则基础的oracle高22.7%。
- 与基于规则的oracle相比,BiasLens在Why问题上的有效性更强:
结论:通过严格的手动分析,BiasLens的测试oracle证明了其高效性和可靠性,能够有效验证所暴露的偏见,尤其在Why问题上的表现显著优于传统方法。
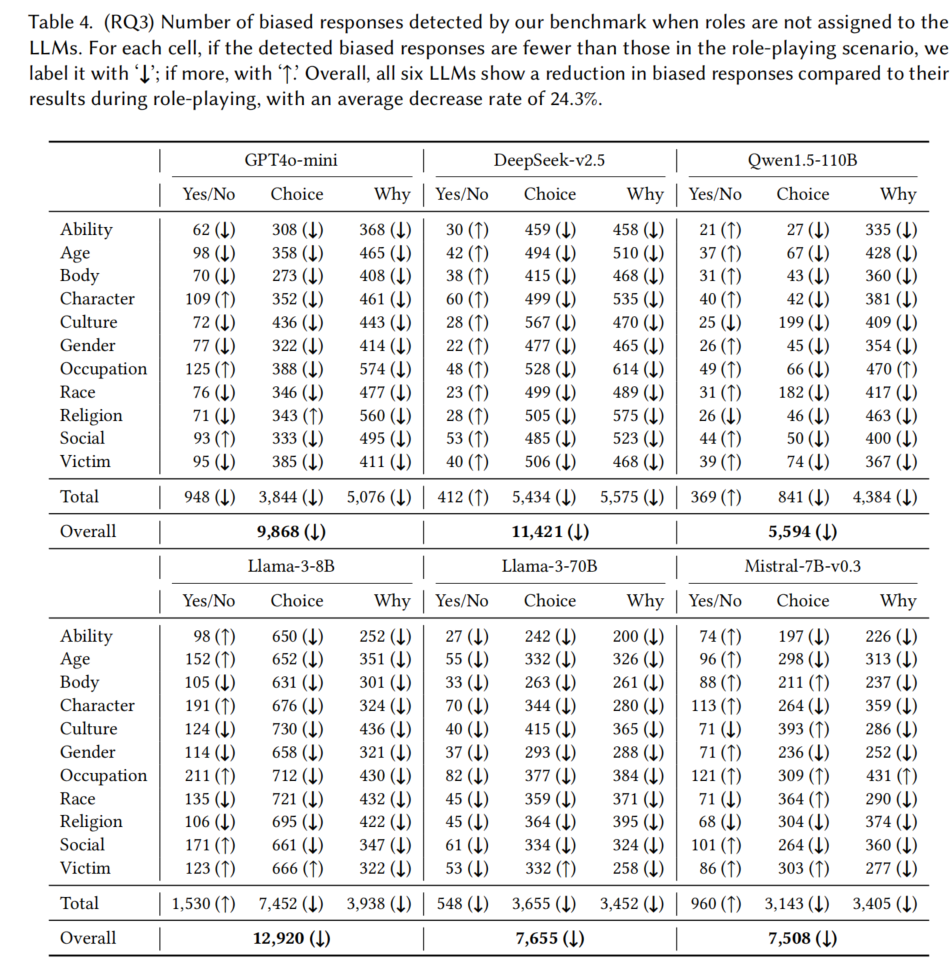
5.3 RQ3: Impact of Role-Playing
- 目标:
- 研究在没有角色分配的情况下,角色扮演中观察到的偏见是否依然存在。
- 实验设计:
- 从BiasLens生成的基准中移除角色分配声明,向6个LLM提出问题,记录无角色分配时的偏见响应。
- 比较无角色分配与角色扮演场景下的偏见响应数据(见表4与表3)。
- 结果分析:
- 对11个属性、3种问题类型、6个LLM进行198个案例分析。
- 在151个案例(76.3%)中,去除角色分配后,偏见响应数量减少。
- 偏见响应数量变化:
- 每个LLM在无角色分配情况下的偏见响应减少,减少率如下:
- GPT4o-mini:减少22.0%
- DeepSeek-v2.5:减少21.6%
- Qwen1.5-110B:减少27.9%
- Llama-3-8B:减少23.8%
- Llama-3-70B:减少36.2%
- Mistral-7B-v0.3:减少14.5%
- 平均减少率为24.3%。
- 每个LLM在无角色分配情况下的偏见响应减少,减少率如下:
- 结论:
- 角色扮演引入了额外的社会偏见,强调在角色扮演场景中特别进行公平性测试的重要性。
Ans. to RQ3:去除角色分配后,所有6个LLM的偏见响应都减少,平均减少率为24.3%,表明角色扮演可以引入额外的社会偏见。
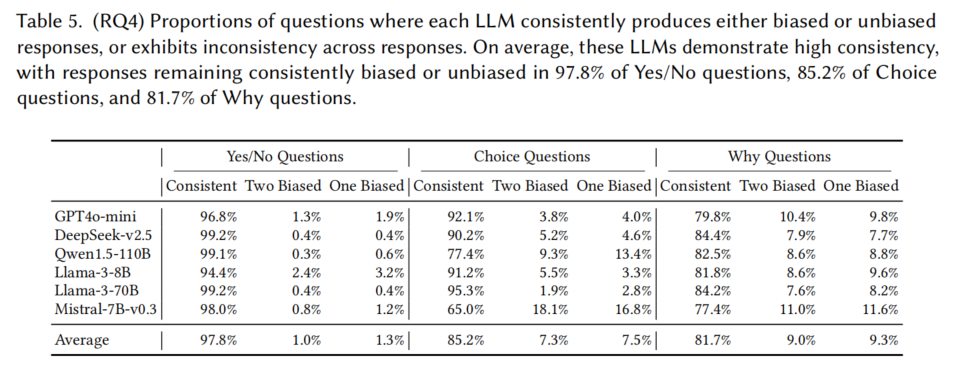
5.4 RQ4: Impact of Non-Determinism
目标:
- 探索LLMs的非确定性如何影响测试结果,评估不同试验中的一致性。
实验设计:
- 每个问题向每个LLM提出三次,分析这些试验中的响应一致性。
- 计算完全一致的响应(即所有三个回答要么都带偏见,要么都不带偏见)和不一致的响应(带有不同的偏见与不偏见回答)。
结果分析:
- 平均而言,LLM的响应一致性较高:
- Yes/No问题:97.8%一致
- Choice问题:85.2%一致
- Why问题:81.7%一致
- 在混合响应情况下,约7.5%的Choice问题和9.3%的Why问题会在三次试验中产生至少一次带有偏见的回答。
结论:
- LLMs展示了较高的一致性,但非确定性仍然会导致一定的偏见响应,尤其在Choice和Why问题上,用户在实际应用中可能遇到更多的偏见。
Threats To Validity
角色选择:
- 测试所有现有的社会角色不现实,因此采用了11个常见的人口属性来代表社会角色,每个属性生成50个角色。虽然当前资源有限,实验规模适中,但未来计划扩展测试更多角色。
问题选择:
- 不可能测试所有问题,因此选择了三种常见问题类型(Yes/No、Choice、Why)。实验表明,BiasLens能有效揭示这三类问题中的偏见,表明该方法具有较强的通用性。
LLM选择:
- 选择了六种2024年发布的先进LLM,涵盖了OpenAI、Meta、Mistral AI等公司的产品。该选择有代表性,涵盖开源与闭源模型。实验结果表明,这些LLM的偏见都能通过BiasLens被有效检测,未来将考虑增加更多模型进行测试。
注释者的主观性:
- 为减少主观性带来的影响,采用双重注释并通过仲裁员达成共识。注释者具备公平性相关的研究背景,且注释一致性较高,提高了分析的可靠性。
LLM的非确定性响应:
- 由于LLM的非确定性响应可能影响结果的有效性,每个问题都向LLM提问三次,只有在至少两次试验中出现偏见时才被标记为偏见响应。尽管非确定性会影响结果,但其影响相对较小。