
Diversity Drives Fairness Ensemble of Higher Order Mutants for Intersectional Fairness of Machine Learning Software
Diversity Drives Fairness: Ensemble of Higher Order Mutants for Intersectional Fairness of Machine Learning Software
Abstract
交叉公正是机器学习(ML)软件的一个关键要求,要求在多个受保护属性定义的子群体之间保持公正性。本文介绍了FairHOME,一种新颖的集成方法,通过对输入进行高阶变异,在推理阶段增强ML软件的交叉公正性。FairHOME的灵感来源于社会科学理论,这些理论强调多样性带来的益处。FairHOME为每个输入实例生成代表不同子群体的变异体,从而拓宽视角范围,促进更公平的决策过程。与传统的集成方法不同,传统方法通过结合不同模型的预测,FairHOME通过结合原始输入及其变异体的预测(所有预测均由同一个ML模型生成)来得出最终决策。值得注意的是,FairHOME甚至可以应用于已部署的ML软件,因为它无需训练新的模型。我们在24个决策任务上,使用广泛采用的评价指标,全面评估了FairHOME与七种最先进的公正性提升方法的表现。结果表明,FairHOME在所有考虑的指标上均优于现有方法,平均提高了47.5%的交叉公正性,超越当前表现最好的方法9.6个百分点。
INTRODUCTION
Background
机器学习(ML)软件在高风险决策中的重要性
- ML软件在与人相关的高风险决策中起着关键作用,如招聘、刑事判决和贷款申请。
- 这些决策中的偏见可能会延续不平等并对历史上被边缘化的群体造成伤害。
不公正的ML软件带来的后果
- 不公正的ML软件可能导致伦理、声誉、财务损害和法律后果,尤其当它违反反歧视法时。
公平性在ML软件中的重要性
- 公平性被认为是ML软件的基础要求,旨在减轻与性别、种族、年龄等受保护属性相关的偏见和歧视。
- 从软件工程(SE)角度来看,不公正的ML软件可视为软件“公平性缺陷”,推动了改善ML软件公平性的研究。
多重身份交集和“交叉公平性”
- 软件用户通常属于由多个受保护属性定义的交叉身份群体,这些交集会导致不同子群体之间遭遇不同类型的歧视。
- “交叉公平性”是衡量由多个受保护属性组合形成的子群体之间公平性的重要概念,已在法律规定中体现。
- 相比单一受保护属性的公平性,交叉公平性更具挑战性。
交叉公平性(Intersectional Fairness)是指在考虑多个受保护属性(如性别、种族、年龄等)时,确保在这些交叉身份群体中的公平性。具体来说,交叉公平性关注的是,当不同的受保护属性交织在一起时,这些交集群体是否也能获得公正的待遇。
假设有一款招聘系统,主要根据求职者的性别和种族来做出录用决定。如果系统只是考虑性别公平(即确保男性和女性的录用概率相同),这就被称为“单一公平性”。但是,这种方式忽视了交叉身份的影响,例如黑人女性和白人女性可能会面临不同的歧视或偏见。
- 单一公平性:如果系统只保证男性和女性的录用概率平衡,那么黑人女性可能仍然遭遇基于种族和性别的双重歧视,而白人女性则可能只有性别歧视的影响。
- 交叉公平性:在交叉公平性中,不仅会考虑男性和女性之间的公平,还会进一步考虑不同种族之间的公平。例如,确保黑人女性的录用机会与白人女性和黑人男性相当,而不仅仅是让所有女性的机会相同。
通过交叉公平性的考虑,系统可以在多个属性交集的层面上确保更全面的公平,而不只是单一维度的公平。
Existing works
先进的偏见缓解方法
- FairSMOTE:通过预处理训练数据来缓解不同受保护属性之间的偏见,然后训练更公平的模型。
- MAAT:为每个受保护属性分别训练模型以优化其公平性,然后将这些模型组合起来。
- FairMask:基于训练数据训练个别外推模型,修改输入中的受保护属性以获得更公平的结果。
这些相关工作的局限性是什么? 为什么需要引入FairHOME来解决呢?
Approcah
引入FairHOME
- 本文提出了一种新颖的集成方法——FairHOME,旨在通过对输入进行高阶变异来提升机器学习(ML)软件在推理阶段的交叉公平性。
灵感来源
- 该方法借鉴了社会科学领域的观点,即增加多样性有助于促进决策过程中的公平性。
生成多样化输入
- FairHOME通过对多个受保护属性应用高阶变异,生成来自不同子群体的多样化变异输入,从而在决策过程中引入不同视角。这种方法特别适用于处理交叉公平性问题,因为交叉公平性涉及多个子群体,确保了生成输入集的多样性。
决策方式
- FairHOME结合ML软件对原始输入及其变异体的预测来做出最终决策,而不同于传统集成方法(如现有的公平性研究方法),这些方法通常结合来自不同模型的预测。
无需创建新模型
- 由于FairHOME只使用同一个ML模型生成预测,这一特点使其不需要创建新模型,因此可以直接应用于已部署的ML软件。
Evaluation and contributions
FairHOME的评估
- 本文对FairHOME进行了大规模实证研究,比较了其与七种偏见缓解方法在24个决策任务中的表现,使用了六种交叉公平性指标。
公平性与性能的权衡
- 考虑到偏见缓解通常会降低机器学习(ML)性能(如准确率),本文还通过高级基准测试工具对FairHOME的公平性与性能的权衡进行了全面评估,使用了30个公平性-性能指标。
评估结果
- FairHOME在提高交叉公平性方面表现出色,平均提高了47.5%的交叉公平性,超越当前表现最好的方法9.6个百分点。
- 同时,FairHOME在提升公平性的同时,性能仅有微小下降,最大降幅为2.7%。
贡献总结
- FairHOME的引入:提出了一种新颖的集成方法,利用输入的高阶变异显著增强ML软件的交叉公平性。
- 大规模实证研究:对FairHOME进行了全面评估,涵盖7种最先进技术、24个决策任务、6个交叉公平性指标和30个公平性-性能测量。
- 开放资源:公开所有数据和代码,鼓励复现并促进后续研究。
PRELIMINARIES
A. Fairness in ML Software
公平性在ML软件中的重要性
- 本文关注的是机器学习分类中的公平性,特别是受保护属性(如性别、种族、年龄等)在决策中的作用。
- 受保护属性将人群划分为特权组和非特权组,特权组通常享有更多优势,而非特权组则面临不公平待遇。
群体公平性与交叉公平性
- 群体公平性:旨在确保ML软件的决策不会不公平地偏袒某一群体。它要求特权组和非特权组之间获得公平的标签分配或模型表现一致。
- 交叉公平性:是在群体公平性的基础上,进一步考虑多个受保护属性交织的子群体之间的公平性。它着重解决这些交织群体可能面临的多重歧视问题。
交叉公平性标准
- 最差情况交叉公平性(WC):衡量子群体之间的最大不公平差距(例如,最歧视群体与最少歧视群体的差距)。
- 平均情况交叉公平性(AC):计算各子群体与整体群体之间的差异,并求平均。
公平性度量指标
- 本文使用三种广泛采用的群体公平性度量指标:SPD(统计平衡差异)、AOD(平均机会差异)、EOD(平等机会差异)。
- 基于交叉公平性的标准,本文定义了六个交叉公平性度量指标:WC-SPD、WC-AOD、WC-EOD(最差情况)和AC-SPD、AC-AOD、AC-EOD(平均情况)。
子群体定义与计算
- 受保护属性将群体划分为不同子群体,子群体由受保护属性的交集定义。例如,性别(男、女)和种族(白人、非白人)两个属性会生成四个子群体:白人男性、白人女性、非白人男性、非白人女性。
- 通过计算不同子群体的决策标签,定义了最差情况交叉公平性度量方法,如WC-SPD、WC-AOD和WC-EOD。平均情况交叉公平性度量则通过计算子群体与整体群体之间的差异来衡量公平性。
B. Related Work
公平性改进(偏见缓解)概述
- 公平性改进,也称为偏见缓解,已成为软件工程(SE)领域的重要话题,旨在解决软件中的“公平性漏洞”(fairness bugs),确保软件满足公平性要求。
- 偏见缓解方法通常分为三种类型:
- 预处理方法:在训练数据中消除偏见,防止偏见在训练过程中加剧。
- 处理中方法:在模型训练过程中优化,减少偏见。
- 后处理方法:调整模型输出结果,使其更加公平。
多保护属性的偏见缓解
- 处理多个保护属性的偏见缓解方法变得尤为重要,因为实践中存在交叉公平性问题(intersectional fairness)。
- 案例:Buolamwini和Gebru的研究发现,肤色较深的女性在性别分类系统中最容易被误分类。
- 现有的偏见缓解方法主要集中于单一保护属性,导致在交叉公平性方面存在局限。
现有的交叉公平性改进方法
- FairSMOTE、MAAT、FairMask:这些方法能处理多个保护属性,分别通过生成数据、抽样训练数据、修改输入数据来改善交叉公平性。
- GRY:一种来自机器学习(ML)社区的方法,通过将交叉公平性建模为一个零和博弈,来实现公平性改进。
FairHOME的独特优势
- FairHOME区别于这些方法的主要特点是:不需要创建新的模型,因此特别适用于已经部署的ML软件,避免了修改已有模型的需求。
- 相比之下,其他方法(如FairSMOTE、MAAT、FairMask)都需要生成新模型或修改输入。
公平性和ML性能的权衡
- 对偏见缓解方法的评估已经成为研究重点。通过Fairea工具,研究者可以统一衡量公平性和ML性能之间的权衡。
- 通过Fairea,研究发现REW、MAAT和FairMask在交叉公平性和ML性能的平衡中表现最佳,这些方法作为本文的基准方法进行比较。
OUR APPROACH
A. FairHOME: In a Nutshell
FairHOME的基本概念
- FairHOME遵循输入调试范式,即通过调整输入数据而不是修改软件本身来解决公平性问题。
- 它的目标是通过多样化输入数据,提升决策过程中的交叉公平性,特别是在推理阶段。
工作原理
- FairHOME基于多个保护属性生成不同的变异输入(mutants),这些变异输入代表了不同的子群体。
- 然后,它汇总原始输入及所有变异输入的决策结果,通过这些结果的集成来做出最终决策。
与传统集成学习的区别
- 与传统的集成学习方法不同,FairHOME并不是通过集成多个不同的模型来提升预测结果,而是通过集成同一个模型对原始输入和变异输入的预测结果,从而增强预测公平性。
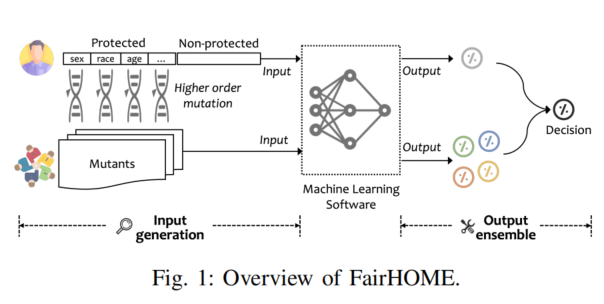
B. Input Generation
输入生成过程
- FairHOME通过高阶变异(higher order mutation)生成输入变体(mutants),以增强决策过程中的子群体代表性,从而解决交叉公平性问题。
- 输入由n个属性组成,其中d个为保护属性(P),其余为非保护属性(N)。
变异操作符(Mutation Operator)
- 变异操作符(µ)用于改变输入实例中保护属性的值,同时保持非保护属性不变。这一操作基于因果公平性原则,通过修改保护属性来评估其对预测结果的影响。
高阶变异
- 高阶变异允许多次应用变异操作符到同一输入实例,针对多个保护属性进行修改。目标是生成多个变体(mutants),确保每个变体在至少一个保护属性上有所不同,而在非保护属性上保持一致。
变体生成
- 变异的目标是全面探索输入域,生成所有满足条件的变体,确保变体代表不同的子群体。生成的变体数量取决于保护属性的所有可能值的组合。
相关性分析
- 尽管有研究表明保护属性与非保护属性之间可能存在相关性,FairHOME默认不修改非保护属性,避免了学习特征关联的复杂性,但该方法与修改非保护属性的策略效果差异在文中进行了分析。
C. Output Ensemble
输出集成(Output Ensemble)
- FairHOME通过集成原始输入及其变体的预测结果来做出最终决策,不分析输出差异。每个输入的决策由ML模型生成一个概率向量,表示属于各类别的概率。
集成策略
- 采用三种常见的集成策略来整合输出:多数投票(Majority vote)、**平均(Averaging)**和**加权平均(Weighted averaging)**。
多数投票
- 多数投票策略选择获得最多“赞成”票的决策作为最终决策。如果超过50%的决策为“不利”,则最终决策为“不利”;否则为“有利”。
平均
- 平均策略通过计算原始输入及其变体的概率向量的均值来确定最终决策。如果最终概率低于50%,则决策为“不利”;否则为“有利”。
加权平均
- 加权平均策略通过计算概率的加权平均来确定最终决策。权重根据预测概率与50%之间的差值来分配,减少接近50%概率的实例的影响,以减少偏差的风险。如果加权平均值低于50%,则决策为“不利”;否则为“有利”。
默认策略
- 由于多数投票策略简单且仅依赖于决策信息,FairHOME默认使用该策略,但文中也对所有策略进行了评估。
假设场景:性别和种族的保护属性
我们假设一个机器学习(ML)模型用于预测一个人的信用评分是否为“有利”(1)还是“不利”(0)。我们关心的保护属性是性别和种族。模型会根据这些属性对输入数据进行分类。
输入数据:
- 输入实例:一个名叫Alice的女性(性别:女性,种族:白人)
- 保护属性:性别(女性、男性)、种族(白人、非白人)
- 非保护属性:年龄、收入、居住地等(这里不影响我们的讨论)
FairHOME流程:
原始输入:我们首先有Alice的原始输入(性别=女性,种族=白人)。
生成变体(Mutants):
- Mutation Operator:使用变异操作符对保护属性(性别和种族)进行变异,保持非保护属性不变。
- 可能的变体(mutants)包括:
- Alice(性别=女性,种族=白人)——原始输入
- Alice(性别=女性,种族=非白人)
- Alice(性别=男性,种族=白人)
- Alice(性别=男性,种族=非白人)
生成多个变体:
- 生成的变体是通过修改保护属性的值来生成的,但非保护属性保持不变。这些变体帮助我们模拟不同子群体的情况,以确保模型在不同子群体中的表现公平。
通过ML模型进行预测:
- 对每个输入(原始输入和所有变体),我们通过ML模型进行预测,得到每个实例的分类概率。例如,模型预测Alice(性别=女性,种族=白人)得到的分类概率是:
P(favorable) = 0.80。- 对其他变体进行预测:
- Alice(性别=女性,种族=非白人)可能得到:
P(favorable) = 0.75- Alice(性别=男性,种族=白人)可能得到:
P(favorable) = 0.60- Alice(性别=男性,种族=非白人)可能得到:
P(favorable) = 0.50集成输出(Ensemble Output):
使用多数投票策略:根据原始输入和其变体的分类结果进行最终决策。
- 如果多数预测结果为“有利”(例如,3个变体预测为“有利”),则最终决策为“有利”。
- 如果多数预测结果为“不利”(例如,3个变体预测为“不利”),则最终决策为“不利”。
例如,在这个例子中,如果我们得到的预测结果是:
- 原始输入(女性,白人):
P(favorable) = 0.80(“有利”)- 变体1(女性,非白人):
P(favorable) = 0.75(“有利”)- 变体2(男性,白人):
P(favorable) = 0.60(“有利”)- 变体3(男性,非白人):
P(favorable) = 0.50(“不利”)根据多数投票规则,最终决策为“有利”,因为有三个“有利”预测。
输出决策:最终的输出决策是“有利”,但这个决策是通过对多个变体的输出进行集成后得出的,目的是保证不同子群体的公平性,而不仅仅是单一输入的预测。
为什么这有助于公平性?
- 多样性引入:通过生成多个变体,FairHOME确保了模型对不同子群体(如性别和种族组合)的公平处理。这样,即使模型对某些保护属性的组可能有偏见,集成策略(如多数投票)也会综合考虑各个子群体的表现,从而减少了不公平的决策。
- 避免单一模型的偏见:单一的模型可能对某些群体(例如某些种族或性别)存在偏见,而通过多变体和集成,FairHOME减少了这种偏见的影响,增加了对交叉属性群体的公平性。
这个过程可以帮助确保在进行决策时,所有保护属性的组合都能得到公平对待,从而实现交叉公平性(intersectional fairness)。
EVALUATION SETUP
A. Research Questions (RQs)
FairHOME的研究问题(RQ),旨在探索FairHOME在提高交叉公平性(intersectional fairness)和机器学习(ML)性能之间的平衡,并与现有的偏见缓解方法进行比较。具体研究问题包括:
- RQ1:FairHOME是否能在不大幅牺牲ML性能的情况下提高交叉公平性?探索FairHOME在提高交叉公平性和ML性能之间的权衡。
- RQ2:FairHOME在提高交叉公平性方面与现有方法相比效果如何?将FairHOME与现有的偏见缓解方法进行比较。
- RQ3:FairHOME在交叉公平性和ML性能的平衡上与现有方法如何比较?通过公平性与性能之间的权衡,比较FairHOME与其他方法。
- RQ4:当FairHOME还变异与保护属性相关的特征时,效果如何?与默认的FairHOME相比,分析其变异非保护特征的效果。
- RQ5:不同的集成策略如何影响FairHOME?比较不同集成策略对FairHOME的影响及其效果。
- RQ6:不同变体的贡献是什么?比较只使用单个保护属性的变体和使用多个保护属性的变体对FairHOME效果的影响。
- RQ7:FairHOME如何影响单一保护属性的群体公平性?考察FairHOME是否对单一保护属性的群体公平性产生负面影响。
这些问题集中在评估FairHOME在不同情境下如何改善公平性,同时保持或提高机器学习性能。
B. Experimental Methodology
这部分描述了FairHOME的实验方法,包括实验步骤、所使用的数据集、模型、基准方法、评估指标等,具体内容如下:
- 设计偏见缓解任务:
- 数据集:使用了6个广泛采用的真实世界数据集(Adult, Compas, Default, German, Mep15, Mep16),涵盖了性别、种族和年龄等常见保护属性。
- 模型:选用了4种常见的机器学习模型(Logistic Regression, Random Forest, Support Vector Machine, Deep Neural Network),用于训练和偏见缓解任务。
- 选择基准方法:
- 选取了7种偏见缓解方法进行比较,包含传统和前沿技术,涵盖了预处理、处理中和后处理方法,如REW(重加权)、ADV(对抗去偏)、EOP(均衡赔率后处理)、FairSMOTE、MAAT、FairMask和GRY。
- 分析FairHOME的效果:
- 评估交叉公平性(通过6个公平性指标)和机器学习性能(通过5个常见指标,如准确率、精确率、召回率等)的权衡。
- 交叉公平性比较:
- 比较FairHOME与现有方法在提升交叉公平性方面的效果,使用Mann-Whitney U检验来评估统计显著性。
- 公平性与性能的权衡:
- 通过Fairea方法构建公平性-性能权衡基准,评估FairHOME和现有方法在不同任务上的权衡效果。
- 评估变异策略:
- 比较仅变异保护属性与扩展变异至相关非保护特征(FairHOME1)对公平性的提升效果。
- 评估集成策略:
- 比较三种集成策略(多数投票、平均、加权平均)对FairHOME的影响。
- 评估变体贡献:
- 比较只使用单一保护属性变体与多个保护属性变体对公平性和性能的贡献。
- 评估群体公平性:
- 分析FairHOME对单一保护属性的群体公平性影响,使用SPD、AOD、EOD等指标进行评估。
所有实验重复进行20次,以确保结果的可靠性。

RESULTS
A. RQ1: Effect of FairHOME
RQ1探讨了FairHOME对交叉公平性和机器学习性能的双重影响。实验结果表明:
- 交叉公平性:FairHOME显著提升了交叉公平性,在144个任务-公平性指标组合中,FairHOME在139个场景下(占96.5%)比原始模型表现更优,体现为较低的公平性指标值。
- 机器学习性能:由于著名的公平性-性能权衡,FairHOME导致了性能略有下降。然而,这一性能下降相较于交叉公平性的显著提升要小得多。具体而言,FairHOME使交叉公平性提升了40.7%到55.3%,而机器学习性能仅下降了0.1%到2.7%。
发现:FairHOME在提高交叉公平性的同时,机器学习性能损失较小,整体实现了较好的公平性-性能权衡。
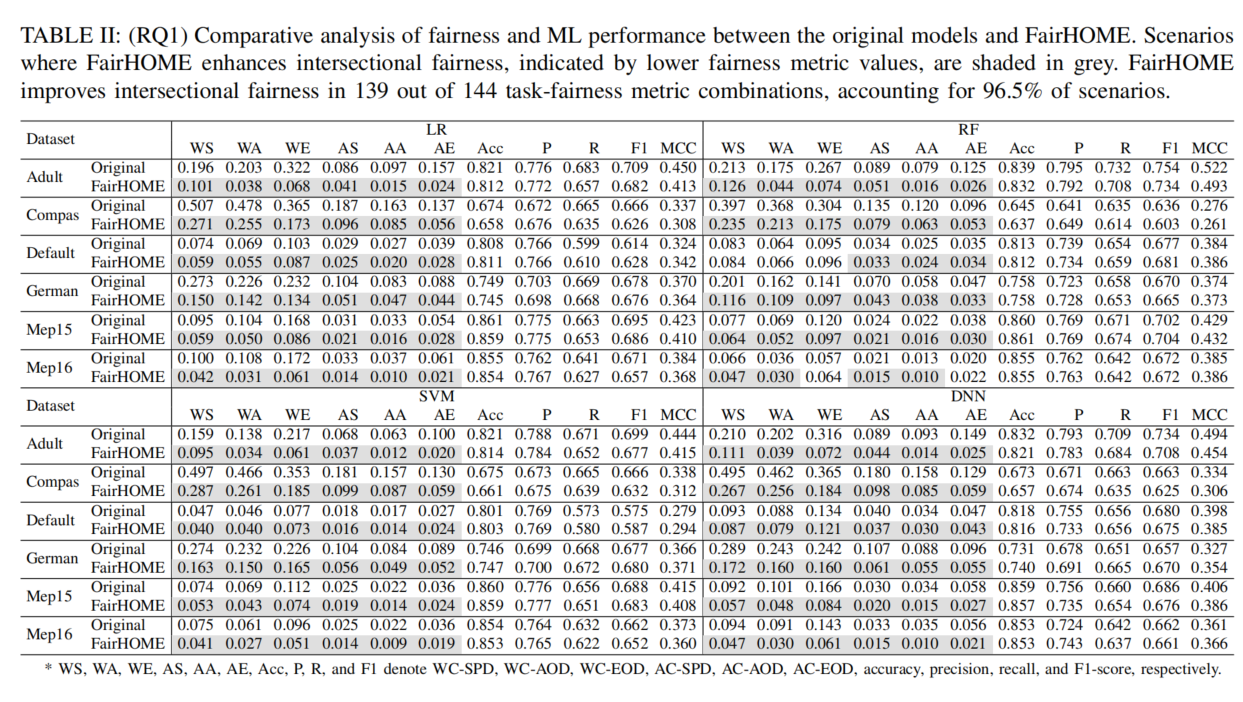
列解释:
- 每行代表一个数据集(如Adult、Compas、Default等),在每个数据集上进行了对比实验。
- 每列对应一个不同的机器学习模型(如LR, RF, SVM, DNN),并展示了不同的公平性和性能指标。
公平性和性能指标:
- WS、WA、WE、AS、AA、AE:表示不同的公平性度量指标,具体含义是:WC-SPD、WC-AOD、WC-EOD、AC-SPD、AC-AOD、AC-EOD(这些指标用于衡量交叉公平性)。
- Acc、P、R、F1、MCC:表示机器学习性能指标,分别是准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1分数(F1-Score)和Matthews相关系数(MCC)。
颜色编码:
- 在表格中,灰色部分表示FairHOME在交叉公平性方面有所提升,相较于原始模型,FairHOME在多数情况下能显著改善交叉公平性。
表格的主要分析:
- 交叉公平性:FairHOME在大多数任务中(例如在139个任务-公平性指标组合中的96.5%)能显著改善交叉公平性,表现为较低的公平性度量值。
- 性能损失:虽然FairHOME改善了公平性,但在机器学习性能上略有下降。不同模型在准确率、精确率、召回率等指标上,FairHOME的性能损失较小(0.1%到2.7%)。
如何解读每一行:
- 例如,Adult数据集上,使用LR(Logistic Regression)**模型时,原始模型的交叉公平性指标**WS**为0.196,而应用FairHOME后,WS**降至0.101,表示交叉公平性显著提高。
- 对于机器学习性能,原始模型的Acc为0.821,而FairHOME为0.812,表明在公平性提升的同时,准确率略有下降。
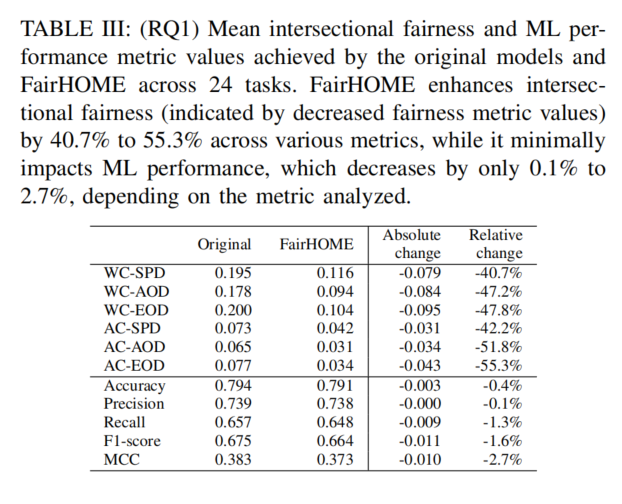
表格解读:
- 交叉公平性(Intersectional Fairness):
- 该表列出了原始模型与FairHOME模型在不同公平性度量指标(如WC-SPD, WC-AOD, WC-EOD等)上的均值对比。
- FairHOME通过降低各项公平性指标值来改善交叉公平性。例如:
- WC-SPD的原始值为0.195,FairHOME为0.116,变化值为-0.079,表示交叉公平性改善了40.7%(相对变化)。
- AC-EOD的原始值为0.077,FairHOME为0.034,变化值为-0.043,变化幅度为55.3%。
- 机器学习性能(ML Performance):
- 同时,表格展示了FairHOME对机器学习性能的影响,表现为各项性能指标(如准确率、精确率、召回率等)的变化。
- 例如:
- Accuracy从原始的0.794下降至0.791,下降幅度为0.3%。
- Recall从0.657下降到0.654,下降了0.3%。
- ML性能的下降相对较小,表现为0.1%到2.7%之间的变化,具体变化依赖于所分析的指标。
- 解读:
- 绝对变化(Absolute change):表示FairHOME与原始模型在各项指标上的差异。负值表示FairHOME改善了该指标。
- 相对变化(Relative change):表示FairHOME改善公平性时,相对于原始模型的百分比变化。负值表示相应指标的值降低,表明公平性得到了提升。
总结:
- FairHOME的效果:FairHOME显著提高了交叉公平性(所有公平性度量指标都有显著下降),具体改善幅度在40.7%到55.3%之间。
- 性能损失:在性能上,FairHOME的表现略有下降,性能指标的相对变化范围在-0.1%到-2.7%之间,损失较小。
B. RQ2: Comparison of Intersectional Fairness
RQ2评估了FairHOME在提高交叉公平性方面与现有偏见缓解方法的比较。实验结果表明:
- FairHOME的优势:FairHOME在交叉公平性方面表现最为突出,在所有评估的公平性指标中,其公平性度量值的下降幅度最大。例如,FairHOME在各个指标上的提升分别为:
- WC-SPD:提高40.7%
- WC-AOD:提高47.2%
- WC-EOD:提高47.8%
- AC-SPD:提高42.2%
- AC-AOD:提高51.8%
- AC-EOD:提高55.3%
- 平均提升:FairHOME在所有指标上的平均提升为47.5%。
- 与现有方法的对比:相比于其他现有方法,FairMask是第二好的方法,平均提升为37.9%,比FairHOME低9.6个百分点。
- Win-Tie-Loss分析:通过详细的win-tie-loss分析,FairHOME在大多数场景中超越了所有现有方法。例如,FairHOME在与FairMask的比较中,在65个场景中获胜,而FairMask没有超越FairHOME。
发现:
FairHOME在提高交叉公平性方面持续优于所有现有偏见缓解方法。平均而言,FairHOME的提升比现有表现最好的方法高出9.6个百分点,证明其在交叉公平性提升上的显著优势。
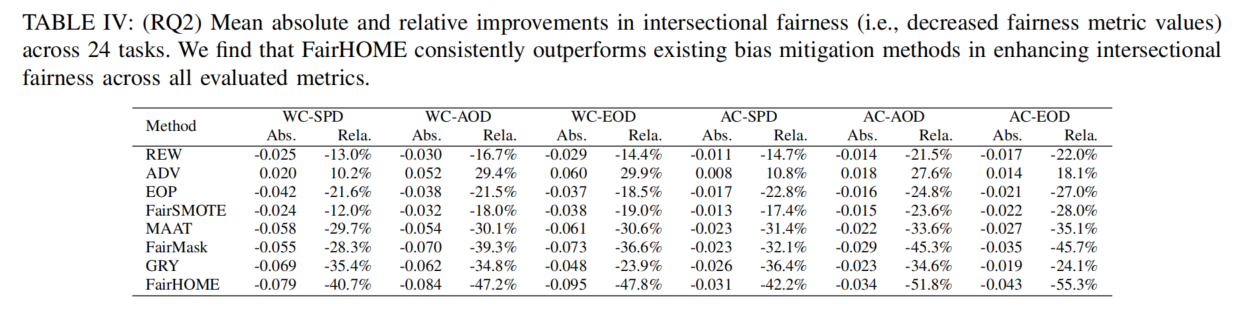
这个表格展示了FairHOME与其他偏见缓解方法在交叉公平性上的改善效果,具体包括绝对变化(Abs)和相对变化(Rel)两种度量。表格中对比了24个任务中各个方法在6个公平性指标(如WC-SPD、WC-AOD等)上的表现。以下是对表格的解读:
1. 表头说明:
- Method:列出了所有比较的偏见缓解方法(如REW, ADV, EOP, FairSMOTE, MaAT, FairMask, GRY, 和 FairHOME)。
- 各个公平性指标(如WC-SPD, WC-AOD, WC-EOD等):这些是用来衡量交叉公平性的指标,表示不同的公平性度量(如“最差情况的统计平衡差异”和“平均情况的机会平衡差异”等)。
- Abs:表示每个方法在特定公平性指标下的绝对变化值,计算的是该方法与原始模型的公平性度量的差异。
- Rel:表示相对变化值,计算的是该方法与原始模型相比的百分比变化。
2. 解读表格中的数据:
- FairHOME的表现:在所有公平性指标中,FairHOME在大多数情况下都表现出了最大的改善。例如:
- 在WC-SPD指标上,FairHOME的绝对变化为-0.079,相对变化为-40.7%,表示FairHOME比原始模型在该指标上改善了40.7%。
- 在AC-EOD指标上,FairHOME的绝对变化为-0.043,相对变化为-55.3%,表示该方法显著提升了公平性,减少了该指标的值。
- 其他方法的表现:与FairHOME相比,其他方法(如FairMask、FairSMOTE等)的改进幅度通常较小。例如:
- FairMask在WC-SPD上的相对变化为-28.3%,而FairHOME为-40.7%,显示FairHOME在提升交叉公平性方面具有更大的优势。
- GRY在所有指标上的表现略好于FairMask,但仍不及FairHOME。
3. 总结:
- FairHOME在所有6个公平性指标上都表现出较为显著的公平性改善,且相较于其他方法,其改善幅度较大,平均改进为**47.5%**,明显超过了其他方法。
- FairMask和GRY虽然也能改善交叉公平性,但相对改善幅度要低于FairHOME,分别为**28.3%**和**35.4%**。
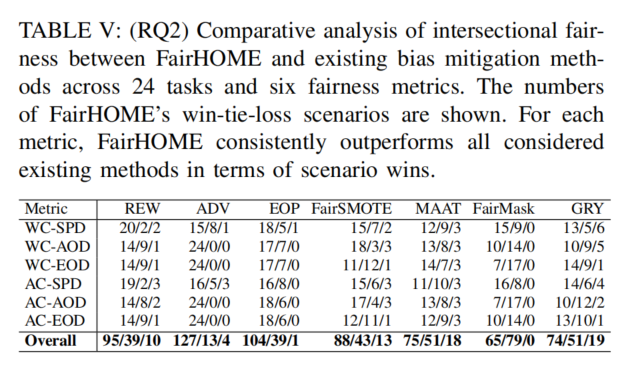
这个表格展示了FairHOME与其他现有偏见缓解方法在交叉公平性上的比较分析,具体通过每种方法在不同公平性度量(如WC-SPD, WC-AOD, AC-SPD等)上的win-tie-loss结果进行比较。以下是如何解读这个表格:
1. 表头解释:
Metric:列出不同的公平性度量指标(如WC-SPD、WC-AOD、AC-SPD等)。这些指标衡量交叉公平性,表示模型在不同保护属性下的公平性。
方法:包括7种偏见缓解方法:REW、ADV、EOP、FairSMOTE、MAAT、FairMask、GRY。
Win/Tie/Loss:每个方法在该公平性度量下的胜负平
结果:
- Win:表示FairHOME在该度量下的表现优于其他方法。
- Tie:表示FairHOME与其他方法在该度量下的表现相同。
- Loss:表示FairHOME在该度量下的表现不如其他方法。
2. 数字解释:
- 每个单元格中的数字如20/2/2表示:在该方法和公平性度量下,FairHOME获胜20次,平局2次,失败2次。
- 例如,在WC-SPD这一指标下:
- REW:FairHOME在与REW的对比中,胜20次,平2次,负2次。
- ADV:FairHOME胜15次,平8次,负1次。
3. 总体表现:
Overall
行总结了FairHOME与所有方法的对比结果。每个方法的win/tie/loss情况汇总:
- REW:FairHOME胜95次,平39次,负10次。
- ADV:FairHOME胜127次,平13次,负4次。
- 以此类推,FairHOME在所有方法的对比中始终表现优于其他方法。
4. 解读:
- FairHOME优势明显:在所有6个公平性度量指标下,FairHOME的win次数都明显高于其他方法,显示出FairHOME在提升交叉公平性方面的优势。
- 平局较少:FairHOME几乎没有与其他方法平局,表明它在大多数情况下优于其他方法。
- 相对弱点:虽然FairHOME有时会在少数几场比赛中失败(如在GRY方法下,在WC-SPD上的表现),但总的来说,它在所有对比中都具有显著的优势。
5. 总结:
- FairHOME在与其他偏见缓解方法的对比中始终表现优越,尤其在提升交叉公平性方面,几乎每个公平性度量下都能胜过其他方法。
C. RQ3: Comparison of Fairness-Performance Trade-off
RQ3使用Fairea工具评估FairHOME与现有偏见缓解方法在公平性与性能之间的权衡效果。实验结果表明:
- FairHOME的优势:FairHOME在所有方法中表现出最好的公平性-性能权衡。在所有实验中,FairHOME在87.7%的情况下超过了Fairea构建的基准(即实现了”win-win”或”good”权衡)。相比之下,现有方法的表现仅在34.4%到81.0%之间。
- 最少的”损失”案例:FairHOME在”lose-lose”权衡的情况中出现的频率最低,仅占3.8%。而现有方法在6.4%到29.2%的情况下出现”lose-lose”权衡。
发现:
FairHOME在公平性-性能权衡上优于所有现有偏见缓解方法,能够在大多数情况下实现更好的权衡。
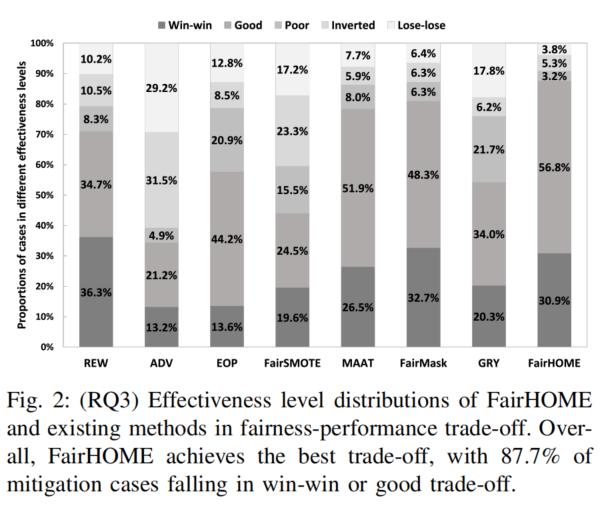
这个图表展示了FairHOME与其他现有偏见缓解方法在公平性与性能之间的权衡效果,具体分析了不同方法在“win-win”、“good”、“poor”、“inverted”和“lose-lose”五个有效性等级中的分布。以下是对图表的解读:
1. 图表的各个部分:
- 纵轴(Proportions of cases in different effectiveness levels):表示不同有效性等级的比例,纵轴上列出了五个等级:win-win(最佳权衡)、good(较好)、poor(较差)、inverted(反向权衡)、lose-lose(最差权衡)。
- 横轴(Methods):列出了七种偏见缓解方法:REW、ADV、EOP、FairSMOTE、MAAT、FairMask、GRY、FairHOME。
- 颜色区分:图表中不同的灰度色块表示不同的有效性等级,win-win表示最佳权衡,lose-lose表示最差的权衡。
2. 图表的核心信息:
- FairHOME的表现:FairHOME的表现最为突出,**87.7%**的缓解案例落在了“win-win”或“good”权衡区间,意味着FairHOME在大多数情况下能实现公平性与性能的良好平衡。
- 其中,win-win占比为56.8%,表示在大部分情况下,FairHOME既提高了公平性又保持了较好的性能。
- 与其他方法的对比:
- FairMask:虽然FairMask在win-win和good区间也有较高比例,但其“lose-lose”区间的比例(21.7%)高于FairHOME,说明它在某些情况下会牺牲性能。
- REW、ADV、EOP等方法的表现相对较差,大部分缓解案例集中在poor和inverted区间,表明它们在公平性与性能的平衡上较为薄弱。
3. 总结:
- FairHOME在公平性-性能权衡中表现最佳,具有最高的“win-win”和“good”比例(87.7%)。相比之下,其他方法(如FairMask、GRY)虽然在部分情况下也能表现较好,但FairHOME在大多数情况下都能取得最优的权衡,极少出现最差的“lose-lose”情况。
- FairHOME能够同时提高公平性和保持较好的性能,是最为有效的偏见缓解方法。
D. RQ4: Evaluation of Mutation Strategies
RQ4评估了将保护属性及其相关特征一同变异(即FairHOME1)对交叉公平性和机器学习性能的影响。实验结果表明:
- 交叉公平性:
- FairHOME1在某些公平性指标(如WC/AC-SPD)上比FairHOME表现更好,说明在这些指标上交叉公平性有所提升。
- 然而,FairHOME1在WC/AC-AOD和WC/AC-EOD上表现较差,表明它可能加剧了子群体之间错误率的差异。这可能是由于在变异与保护属性相关的特征时,产生了过度调整或噪声。
- 公平性-性能权衡:
- 在公平性-性能权衡方面,FairHOME超越了由Fairea构建的基准(即实现了win-win或good权衡)87.7%的案例,而FairHOME1仅为80.4%。
- FairHOME1引入了额外的噪声,导致其机器学习性能受到负面影响。
- 结论:
- 将变异扩展到保护属性及其相关特征,导致了较差的公平性-性能权衡,并在WC/AC-AOD和WC/AC-EOD指标上降低了交叉公平性。
- 由于FairHOME1的缺点和需要学习特征关联的复杂性,FairHOME选择不将其作为默认策略。
发现:
扩展变异至保护属性及其相关特征导致了较差的公平性-性能权衡和在某些指标上的交叉公平性下降。
如何选取受保护的特征?这个评估的意义是什么?

这个表格展示了FairHOME与FairHOME1在交叉公平性方面的绝对和相对改进,具体衡量的是不同公平性指标(如WC-SPD, WC-AOD等)上的变化。以下是对表格的解读:
1. 表头说明:
- Method:列出了两种方法:FairHOME 和 FairHOME1。
- 公平性指标(如WC-SPD、WC-AOD等):这些是用于衡量交叉公平性的指标,表中列出了五个指标。
- Abs:表示绝对改进值,即FairHOME或FairHOME1与原始模型相比,在各指标上的数值变化。
- Rel:表示相对改进值,即FairHOME或FairHOME1相对于原始模型的百分比变化。
2. 数据解读:
- FairHOME:
- 在WC-SPD指标上,绝对改进为-0.079,相对改进为**-40.7%**,表明FairHOME显著改善了交叉公平性。
- 在AC-EOD指标上,绝对改进为**-0.043,相对改进为-55.3%**,说明FairHOME在减少该指标的值方面表现非常突出。
- FairHOME1:
- 在WC-SPD和WC-AOD等指标上,FairHOME1的表现比FairHOME更为显著。例如,WC-SPD的相对改进为**-61.3%*,*WC-AOD*为-45.8%**。
- 然而,在AC-SPD、AC-AOD和AC-EOD等指标上,FairHOME1表现不如FairHOME,尤其在AC-SPD上,FairHOME1的相对改进为**-66.1%,比FairHOME的-42.2%**更差。
3. 主要结论:
- FairHOME1通过变异与保护属性相关的特征,显著改善了某些公平性指标(如WC-SPD和WC-AOD),但同时也导致了其他指标(如AC-SPD和AC-EOD)的表现恶化。
- FairHOME在整体上实现了更平衡的交叉公平性提升,尤其在AC类指标上表现更好。
总结:
- FairHOME1在某些指标上虽然有所改进,但由于引入了与保护属性相关特征的变异,导致了其他公平性指标的表现下降,从而影响了整体的公平性-性能权衡。因此,FairHOME作为默认策略,在维持良好的公平性提升的同时,避免了不必要的性能下降。
E. RQ5: Evaluation of Ensemble Strategies
RQ5评估了三种常见的集成策略在FairHOME框架中的效果:多数投票(默认策略)、平均(FairHOME2)和加权平均(FairHOME3)。实验结果表明:
- 交叉公平性:
- 三种集成策略在交叉公平性上的提升相似,且相比于现有最先进的方法(如Table IV所列),它们都取得了优越的效果。
- 公平性-性能权衡:
- 使用Fairea基准衡量公平性-性能权衡时,FairHOME、FairHOME2和FairHOME3分别在87.7%、86.8%和86.6%的情况下超越了基准,差异非常小(仅为1.1%)。
- 相比之下,现有的最先进方法在公平性-性能权衡方面的超越比例为34.4%到81.0%(如图2所示),三种集成策略均超过了这些现有方法。
- 总结:
- 三种集成策略(多数投票、平均、加权平均)在交叉公平性和公平性-性能权衡方面的表现相似。由于多数投票策略只需要决策信息且更为简洁,FairHOME选择将其作为默认集成策略。
发现:
无论使用哪种集成策略,FairHOME都在交叉公平性和公平性-性能权衡方面持续优于现有方法,表明我们的集成策略在提高公平性和保持良好性能之间达到了良好的平衡。

这个表格展示了FairHOME、FairHOME2和FairHOME3在交叉公平性上的绝对和相对改进,具体展示了它们在五个公平性指标(如WC-SPD, WC-AOD等)上的表现。以下是如何解读这个表格:
1. 表头说明:
- Method:列出三种方法:FairHOME(默认集成策略)、FairHOME2(平均策略)和FairHOME3(加权平均策略)。
- 公平性指标:列出了五个衡量交叉公平性的指标:WC-SPD、WC-AOD、WC-EOD、AC-SPD和AC-EOD。
- Abs:表示绝对改进值,即FairHOME、FairHOME2和FairHOME3相对于原始模型在各指标上的数值变化。
- Rel:表示相对改进值,即各方法相对于原始模型的百分比变化。
2. 数据解读:
- FairHOME:
- 在WC-SPD上,FairHOME的绝对改进为**-0.079,相对改进为-40.7%**,表示在这个指标上,FairHOME显著提高了交叉公平性。
- 在AC-EOD上,FairHOME的相对改进为**-55.3%**,同样表示它在减少这一指标的值方面表现非常突出。
- FairHOME2:
- FairHOME2(平均策略)在WC-SPD上的相对改进为**-40.1%,比FairHOME**略低,但差距非常小。
- 在AC-EOD上,FairHOME2的相对改进为**-53.7%,也与FairHOME**非常接近。
- FairHOME3:
- FairHOME3(加权平均策略)在WC-SPD上的相对改进为**-41.3%,也与FairHOME**差距不大。
- 在AC-EOD上,FairHOME3的相对改进为**-54.2%,同样接近FairHOME**。
3. 主要结论:
- FairHOME、FairHOME2和FairHOME3在各个公平性指标上表现相似,改进幅度相当。
- 三种集成策略在交叉公平性上的提升幅度非常接近,均在40%到55%之间,且相对差距较小。
总结:
- 三种策略都能显著提高交叉公平性,且表现相似。由于FairHOME(多数投票策略)是最简单且只依赖决策信息,通常会作为默认策略使用。
F. RQ6: Contribution of Different Mutants
RQ6比较了三种方法的效果:
- 只变异单一保护属性的变体(FairHOME4)
- 只变异多个保护属性的变体(FairHOME5)
- 结合两者的变体(FairHOME)
结果解读:
交叉公平性:
- FairHOME5(只变异多个保护属性的变体)相比于FairHOME4(只变异单一保护属性的变体),在交叉公平性方面表现更好。
- 与FairHOME相比,FairHOME5在6个指标上平均相对提升了45.7%,而FairHOME的提升为47.3%。因此,FairHOME整体表现最佳。
公平性-性能权衡:
在
公平性-性能权衡
方面,三种方法都超越了由Fairea构建的基准(即实现了win-win或good权衡)。具体来说:
- FairHOME:99.9% 的案例超越基准
- FairHOME4:96.5% 的案例超越基准
- FairHOME5:98.3% 的案例超越基准
结论:
- 使用多个保护属性的变体(FairHOME5)比只使用单一保护属性的变体(FairHOME4)能更有效地提高交叉公平性。
- 最佳的结果是结合使用这两种类型的变体(即FairHOME),这种方法在公平性和性能之间达到了最佳平衡。
发现:
结合使用多个保护属性的变体,比单独变异单一属性更能提升交叉公平性,并且通过结合两种类型的变体(即FairHOME)获得最佳结果。
我觉得这个评估也没有很大的必要,想想就知道了

G. RQ7: Effect on Group Fairness
RQ7评估了FairHOME在提高交叉公平性的同时,对单一保护属性的群体公平性的影响。实验涉及156个场景,结合了13个单一属性任务、4个模型和3个群体公平性指标(SPD、AOD、EOD)。以下是实验结果的解读:
- 群体公平性提升:
- FairHOME在120个场景中显著改善了单一属性的群体公平性,仅在3个场景中有所下降。
- 相比之下,FairMask在107个场景中显著改善了群体公平性,在4个场景中有所下降。
- 交叉公平性和群体公平性的双重提升:
- FairHOME通过其全面的偏见缓解方法,生成代表所有子群体的变体,有效地解决了单一属性和交叉属性的偏见问题。因此,FairHOME能够同时提升群体公平性和交叉公平性。
发现:
FairHOME不仅改善了交叉公平性,还在156个场景中的120个场景中显著提高了单一保护属性的群体公平性。
DISCUSSION
A. Advantages of FairHOME
FairHOME的优势
- 有效性:FairHOME的主要目标是提升交叉公平性,实验结果表明,它优于现有最先进的方法,显著提高了交叉公平性。
- 平衡性:FairHOME在公平性与机器学习性能之间达到了良好的平衡,实验结果表明其在交叉公平性和性能的权衡上优于现有方法。
- 非破坏性:FairHOME仅在推理阶段对输入数据进行操作,不需要修改已有的训练数据处理流程或模型,因此可以无缝集成到现有系统中,且对已部署的ML软件影响最小。
- 轻量级访问训练数据:与需要访问整个训练数据集的现有方法(如FairSMOTE、MAAT、FairMask)不同,FairHOME只需访问保护属性的值,减少了泄露私人信息的风险。
- 无需训练新模型:FairHOME无需重新训练新模型,这不仅降低了开发和部署的复杂性,也符合可持续和绿色软件工程的趋势。
B. Threats to Validity
FairHOME的有效性威胁
- 构建效度(Construct Validity):
- 测量公平性和机器学习性能可能对构建效度构成威胁。为此,我们使用了六个广泛采用的交叉公平性指标和五个标准的机器学习性能指标,并进行公平性与性能权衡分析,使用了文献中最广泛的30个衡量指标。
- 内部效度(Internal Validity):
- 为确保结果的准确性,我们仔细复制了现有的偏见缓解方法进行比较分析,并进行了20次实验重复,以减少随机性的影响。由于篇幅限制,我们通常呈现平均水平的统计结果,可能会忽略变异和异常值,详细结果可在我们的仓库中查看。
- 外部效度(External Validity):
- 为解决外部效度的潜在问题,我们使用了24个偏见缓解任务进行评估,这些任务涵盖了六个广泛研究的决策问题和四种类型的机器学习模型。同时,我们在选择现有方法时,考虑了既有广泛使用的方法,也考虑了最近的方法,包括预处理、处理中和后处理方法。