
LLM Hallucinations in Practical Code Generation: Phenomena, Mechanism, and Mitigation
LLM Hallucinations in Practical Code Generation: Phenomena, Mechanism, and Mitigation
Abstract
代码生成旨在根据输入需求自动生成代码,从而显著提升开发效率。近年来,基于大型语言模型(LLMs)的方法在代码生成任务上取得了显著成果,彻底改变了该领域。然而,尽管表现出色,LLMs 在代码生成场景中仍然容易产生幻觉(hallucinations),特别是在实际开发过程中需要处理复杂上下文依赖的情况下。虽然已有研究分析了 LLM 在代码生成中的幻觉问题,但其研究范围主要局限于独立函数的生成。在本文中,我们进行了一项实证研究,探讨 LLM 幻觉在更实际且更复杂的开发环境中的现象、机制及其缓解方法,重点关注仓库级代码生成场景。首先,我们手动检查六种主流 LLM 的代码生成结果,建立了一套 LLM 生成代码的幻觉分类体系。随后,我们详细阐述幻觉现象,并分析其在不同模型中的分布情况。接着,我们探究幻觉产生的原因,并识别出四个可能导致幻觉的关键因素。最后,我们提出了一种基于 RAG(Retrieval-Augmented Generation)的缓解方法,该方法在所有研究的 LLM 上均表现出稳定的效果。我们的复现包(包含代码、数据和实验结果)可在以下地址获取:
https://github.com/DeepSoftwareAnalytics/LLMCodingHallucination。
INTRODUCTION
Background and related work
代码生成的背景
- 代码生成是一种自动化技术,通过自然语言描述的规格高效生成代码,减少开发者的手动编码工作。
- 近年来,基于 Transformer 架构的大型语言模型(LLMs)取得了显著进展,并在代码生成任务上表现优异,如 GPT-4 在 HumanEval 和 MBPP 基准测试中取得了最先进的结果。
现实开发需求的复杂性
- 实际开发场景中的代码生成需求远比生成独立函数更复杂,需要处理上下文依赖(如调用用户自定义函数、项目定义的数据协议)。
- 为了更准确评估 LLM 在实际代码生成任务中的表现,提出了新的基准测试(CoderEval、ClassEval、EvoCodeBench)。
- 这些基准测试主要关注 LLM 代码生成的功能正确性(通过测试用例通过率衡量),但缺乏对失败原因的深入分析。
LLM 代码生成中的幻觉问题
- 现有研究表明,LLMs 在生成自然语言文本时存在幻觉问题,主要包括三种类型:
- 输入冲突幻觉(Input-Conflicting Hallucination)
- 事实冲突幻觉(Fact-Conflicting Hallucination)
- 上下文冲突幻觉(Context-Conflicting Hallucination)
- 在代码生成领域,Liu 等人的研究分析了 LLM 生成代码的幻觉问题,并基于 HumanEval 和 DS-1000 进行分类,发现如“死代码(Dead Code)”和“重复代码(Repetition)”等现象。
本研究的贡献
- 研究范围拓展:不同于 Liu 等人的研究仅针对独立函数/脚本的生成,本研究聚焦于 仓库级别的代码生成,分析更实际和复杂的开发环境中的幻觉问题。
- 研究视角扩展:从 现象(Phenomena)、机制(Mechanism)和缓解方法(Mitigation) 三个角度系统研究幻觉问题,而不仅仅是从问题表现角度分类。
- 研究目标:通过对 LLM 代码生成幻觉的全面研究,弥补现有研究的不足,提供对 LLM 代码生成能力的更深入理解。
Empirical Study
研究目标
本研究旨在揭示 LLM 代码生成中的幻觉现状及其根本原因,并围绕以下三个研究问题(RQs)展开分析:
- RQ1(幻觉分类): 代码生成中的幻觉表现形式及其分布情况如何?
- RQ2(LLM 比较): 不同 LLM 之间的幻觉发生率和模式有何差异?
- RQ3(幻觉根因): 代码生成中的幻觉产生的根本原因是什么?
研究方法
- 选取 六种主流 LLM(ChatGPT、CodeGen、PanGu-α、StarCoder2、DeepSeekCoder、CodeLlama)并基于 CoderEval 数据集 进行实验。
- 采用 开放编码(open coding) 方法,对 LLM 生成的代码进行手动标注,逐步构建 幻觉分类体系。
- 通过 迭代标注(初始标注 10%,然后扩展至 90%)完善分类体系,并围绕研究问题进行深入分析。
研究发现
- LLM 代码生成的幻觉可以分为三大类(任务需求冲突、事实知识冲突、项目上下文冲突),并进一步细分为 八个子类别:
- 任务需求冲突:功能需求违背(Functional Requirement Violation)、非功能需求违背(Non-Functional Requirement Violation)
- 事实知识冲突:背景知识冲突(Background Knowledge Conflicts)、库知识冲突(Library Knowledge Conflicts)、API 知识冲突(API Knowledge Conflicts)
- 项目上下文冲突:环境冲突(Environment Conflicts)、依赖冲突(Dependency Conflicts)、非代码资源冲突(Non-code Resource Conflicts)
- 不同 LLM 的幻觉分布分析:所有模型中最常见的幻觉类型是 任务需求冲突。
- 幻觉的四个潜在原因:
- 训练数据质量(Training Data Quality)
- 任务意图理解能力(Intention Understanding Capacity)
- 知识获取能力(Knowledge Acquisition Capacity)
- 仓库级上下文感知能力(Repository-Level Context Awareness)
幻觉的缓解方法
基于 RAG(Retrieval-Augmented Generation)
的轻量级缓解方法:
- 构建检索库,从仓库中提取与当前任务相关的代码片段。
- 通过 相似度匹配,将相关代码片段作为提示词,辅助 LLM 代码生成。
- 实验结果表明,该方法能 稳定提升所有研究 LLM 的代码生成表现。
Contributions
实证研究:分析 LLM 在真实开发场景中的幻觉类型,并构建 LLM 代码生成幻觉分类体系。
幻觉现象分析:详细研究幻觉的表现,并分析其在不同 LLM 中的分布情况。
幻觉成因分析:识别并归纳导致幻觉的 四个关键因素。
缓解方法提出:基于幻觉成因,提出 RAG(检索增强生成) 方法,并在多个 LLM 上实验其有效性。
复现包发布:提供 代码、数据、实验结果,支持后续研究(项目地址)。
BACKGROUND & RELATED WORK
A. LLM-based Code Generation
真实开发场景:
- 开发者通常依赖 代码仓库 进行编程,公司出于安全性和功能性考虑,往往构建 内部代码仓库,其中包含许多 私有 API,LLM 训练时无法接触到这些 API。
- 现实开发中的代码往往 依赖已有的 API 和函数,而不仅仅是基于函数描述和签名独立生成代码。
依赖函数的普遍性:
- 研究分析了 GitHub 上 100 个最受欢迎的 Java 和 Python 项目,发现 超过 70% 的函数是依赖函数,需要调用代码仓库中的 API,而非独立实现。
现有基准测试与 LLM 表现:
- CoderEval、ClassEval、EvoCodeBench 等基准测试通过收集 真实代码仓库的代码片段与描述,并使用 测试用例 检验代码正确性。
- LLMs 在这些基准上的表现极差,主要问题:
- 无法基于问题描述生成正确代码。
- 倾向于生成独立代码段,而不是使用当前开发环境中的已有函数。
B. Hallucinations in LLMs
幻觉的定义(NLP 领域)
- 幻觉指 模型生成的文本与输入或预期输出环境不一致、缺乏意义或违背事实 的现象。
- 在文本生成任务(如文本补全、摘要生成、机器翻译)中尤为明显,影响输出的一致性和可靠性。
- 根据幻觉的性质,可分为三类:
- 输入冲突幻觉(Input-Conflicting Hallucinations):输出内容偏离原始输入,可能源于错误解析或内部表示不准确。
- 上下文冲突幻觉(Context-Conflicting Hallucinations):输出内容自相矛盾,反映模型难以保持上下文一致性。
- 事实冲突幻觉(Fact-Conflicting Hallucinations):输出内容与现实世界的知识或事实不符,可能由训练数据质量、知识更新滞后或推理能力不足导致。
代码生成领域的幻觉问题
- 现有研究 缺乏对代码生成幻觉的深入定义和研究。
- 尽管已有许多基于 LLM 的代码生成优化方法,但这些工作 未明确界定代码生成中的幻觉问题。
- 幻觉会影响代码的质量、可维护性,并可能引发 性能问题、安全漏洞,威胁软件的稳定性和安全性。
现有研究的不足
- 之前的研究 [8] 为代码生成任务定义了新的幻觉分类 (共五种类型),但 未考虑真实开发环境中的关键因素,如:
- 开发环境
- 系统资源
- 外部约束
- 代码仓库依赖
- 这些因素导致 LLM 在实际开发中的可用性和准确性较低。
本研究的贡献
- 本研究 基于真实开发数据集 进行实证分析,定义新的幻觉类型,弥补现有研究的不足。
- 研究成果为 探索 LLM 代码生成幻觉问题提供新思路,推动后续研究。
EVALUATION SETUP
A. Dataset
数据来源:基于 CoderEval 基准测试,选取真实 Python 代码仓库中的编程任务。
数据规模:包含 230 个 Python 代码生成任务,覆盖不同类型的项目。
数据组成:每个任务包括:
- 自然语言描述
- 标准代码片段(ground-truth code)
- 测试用例
- 与任务相关的项目环境上下文
目的:更好地模拟实际开发场景,以评估 LLM 代码生成能力。
B. Studied LLMs
研究范围:使用 6 种主流 LLM 进行代码生成,涵盖 开源与闭源 模型,参数规模多样。
具体模型:
- **ChatGPT (GPT-3.5-Turbo)**:多语言通用模型,代码生成能力强。
- CodeGen-350M-Mono:专用于程序合成的自回归模型系列。
- PanGu-α-2.6B:支持多语言代码生成的模型。
- DeepSeekCoder-6.7B:开源模型,在多种编程语言和基准测试中表现良好。
- CodeLlama-7B-Python-hf:专为代码生成预训练和微调的模型。
- StarCoder2-7B:专注于代码生成的开源 LLM。
实验设置:
- 每个任务 生成 10 个代码片段。
- 采用 核采样策略(nuclear sampling),温度设为 0.6,与 CoderEval 设定一致。
C. Taxonomy Annotation
初始开放编码(Initial Open Coding)
- 选取 CoderEval 数据集的 10%(23 个任务) 进行初步分析。
- 使用 6 种 LLM(ChatGPT、CodeGen、PanGu-α、DeepSeekCoder、CodeLlama、StarCoder2),每个任务生成 10 个代码片段,共 1,380 个代码片段。
- 在实际开发环境中测试代码正确性,并由 两位研究者 比较 LLM 生成代码与标准代码,讨论并记录潜在幻觉现象。
初步分类构建(Preliminary Taxonomy Construction)
- 记录 幻觉类型及其在代码中的位置,每个代码片段可能包含多个幻觉。
- 通过讨论对 相似幻觉进行归类,形成初步幻觉分类体系,明确幻觉类型及其含义。
完整分类构建(Full Taxonomy Construction)
- 由 三名具有丰富 Python 经验的志愿者(两名 10+ 年经验,一名 4 年经验)对剩余代码片段进行独立标注。
- 如果发现新的幻觉类型,标注者需撰写描述,并进行讨论,扩展和完善分类体系。
EVALUATION RESULTS

A. RQ1: Hallucination Taxonomy
本研究通过手动标注,构建了 LLM 代码生成幻觉分类体系,包含 3 大类别、8 个子类别,并分析其分布情况。
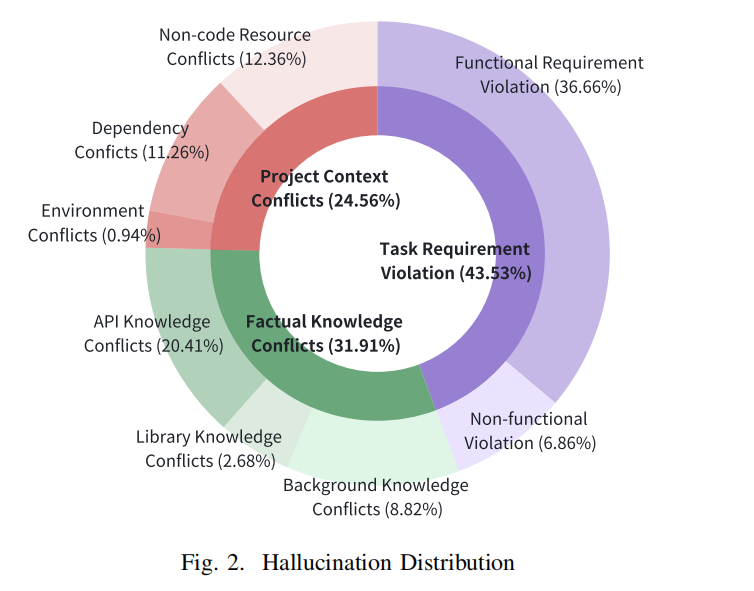
1. 任务需求冲突(Task Requirement Conflicts,43.53%)
描述:生成的代码未满足任务的功能或非功能需求,对应于 NLP 领域的 输入冲突幻觉。
- 功能需求违背(Functional Requirement Violation,36.66%):
- 代码未能正确实现预期功能,可能导致逻辑错误或运行时错误。
- 进一步细分为 错误功能(Wrong Functionality) 和 缺失功能(Missing Functionality)。

- 非功能需求违背(Non-functional Requirement Violation,6.86%):
- 代码不符合 安全性、性能、编码风格、代码质量 要求,可能引入安全漏洞或降低可维护性。
- 例如,LLM 生成代码可能错误地使用 不安全的 YAML 解析函数,引发安全风险。

2. 事实知识冲突(Factual Knowledge Conflicts,31.91%)
描述:代码不符合 已有背景知识、库/框架知识、API 规范,对应于 知识冲突幻觉。
- 背景知识冲突(Background Knowledge Conflicts,8.82%):
- 代码违背特定领域的标准或规范,如 汽车软件 AUTOSAR 规范。

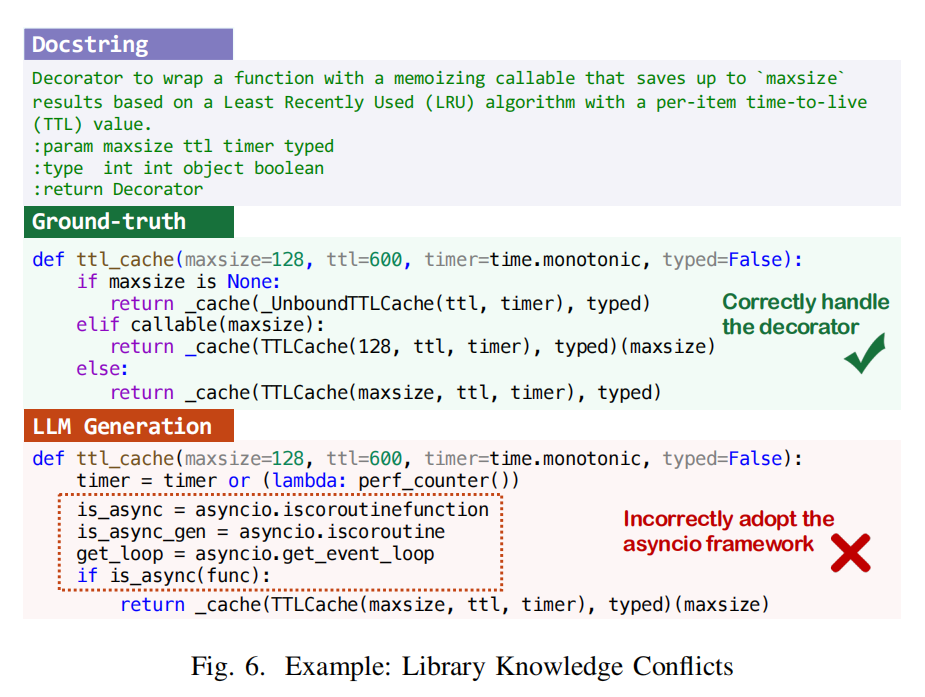
- 库知识冲突(Library Knowledge Conflicts,2.68%):
- 误用第三方库(如错误调用 asyncio API,导致异步处理问题)。
- API 知识冲突(API Knowledge Conflicts,20.41%):
- API 参数错误、条件检查错误、错误/废弃 API 调用、异常处理不当,可能导致功能错误或系统不稳定。

3. 项目上下文冲突(Project Context Conflicts,24.56%)
描述:生成的代码未正确使用 项目特定的环境、依赖和非代码资源,属于 上下文冲突幻觉。
- 环境冲突(Environment Conflicts,0.94%):
- 代码不兼容当前开发环境(如 Python 版本不支持的语法)。

- 依赖冲突(Dependency Conflicts,11.26%):
- 代码调用了 未定义或未导入的函数、变量、API,导致运行错误。

- 非代码资源冲突(Non-code Resource Conflicts,12.36%):
- 代码错误处理 数据、配置、资源文件、网络连接,可能导致文件访问失败、数据不一致或安全问题。

总结
- 任务需求冲突(43.53%) 是最常见的幻觉类型。
- 事实知识冲突(31.91%) 和 项目上下文冲突(24.56%) 也广泛存在,影响 LLM 代码生成的可靠性。
- 本研究构建的 LLM 代码生成幻觉分类体系 提供了更全面的分析框架,为未来优化 LLM 代码生成提供指导。
B. RQ2: LLM Comparison
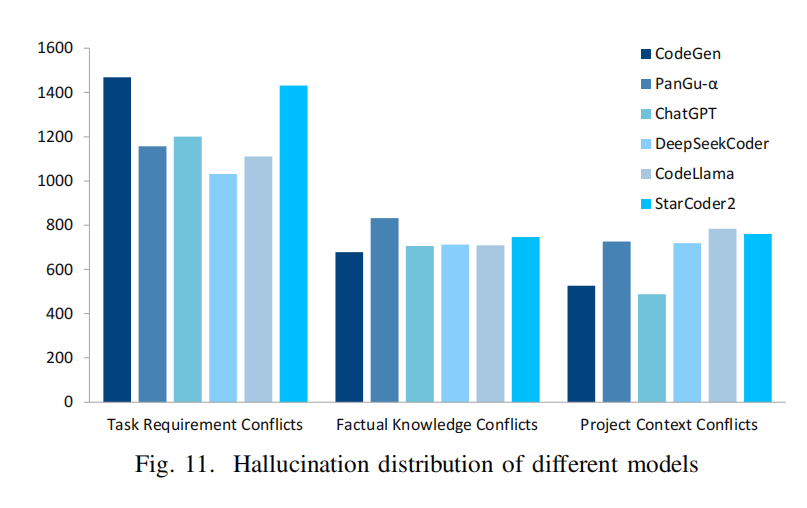
- 任务需求冲突(Task Requirement Conflicts)最常见:
- 所有 LLM 中,该类型幻觉发生频率最高。
- CodeGen 和 StarCoder2 在此类别的幻觉最严重,而 DeepSeekCoder 和 CodeLlama 发生率最低。
- 可能原因:模型对任务需求的理解能力不同,受 模型大小、训练语料 影响。
- 事实知识冲突(Factual Knowledge Conflicts)和项目上下文冲突(Project Context Conflicts)频率相近:
- PanGu-α 的事实知识冲突最多,可能因为其主要基于 中文语料训练,对 英语领域的特定知识 了解有限。
总结
- 任务需求冲突是所有 LLM 最常见的幻觉类型,尤其在 CodeGen 和 StarCoder2 中更为明显。
- 模型训练数据的广度和多样性影响幻觉发生率,例如 DeepSeekCoder 和 CodeLlama 由于 同时训练于广泛的代码和文本数据,幻觉发生率较低。
C. RQ3: Root Cause Analysis
本研究进一步分析 LLM 代码生成幻觉的可能成因,并归纳出 四个关键因素。
1. 训练数据质量(Training Data Quality)
- 影响:训练数据的质量直接影响 LLM 的推理能力。
- 问题:
- 训练数据中可能存在 错误注释、低效或不安全的代码、API 误用、过时的库文档等。
- LLM 在训练过程中 学习了这些错误模式,导致幻觉生成。
- 影响的幻觉类型:主要导致 任务需求冲突(Task Requirement Conflicts) 和 事实知识冲突(Factual Knowledge Conflicts)。
- 优化方向:需要 构建高质量的代码训练数据 以减少幻觉。
2. 任务意图理解能力(Intention Understanding Capacity)
- 影响:LLMs 难以准确理解用户需求,影响代码生成的准确性。
- 问题:
- LLM 依赖模式匹配 而非深度理解任务需求,可能遗漏关键信息。
- 复杂逻辑、多步骤操作 需求难以被正确解析,导致代码 部分实现正确但不满足完整业务逻辑。
- 案例:如某任务要求处理 LocalTime,但 LLM 忽略该需求,未在代码中正确实现。
- 优化方向:提升 LLM 对复杂需求的理解能力,减少需求偏差导致的幻觉。
3. 知识获取能力(Knowledge Acquisition Capacity)
- 影响:LLMs 可能学习错误知识,或缺乏最新领域知识。
- 问题:
- 由于训练数据质量问题,LLM 可能 学习到错误或过时的事实知识,导致幻觉。
- 训练后的 LLM 无法主动更新知识,导致其对新技术、库更新 无法适应。
- 案例:某任务要求生成符合 OCFL 规范 的数据存储代码,但 LLM 生成的代码 不符合最新规范,可能因其 未见过最新 OCFL 相关知识。
- 优化方向:
- 引入 RAG(检索增强生成) 机制,使 LLM 可获取最新知识并进行补充校正。
4. 仓库级上下文感知能力(Repository-Level Context Awareness)
- 影响:LLM 难以有效利用代码仓库的上下文信息,导致代码与项目不匹配。
- 问题:
- Transformer 架构存在 Token 长度限制(如 8K、12K),难以完整输入整个代码仓库。
- 直接输入所有项目上下文 可能引入大量无关信息,影响 LLM 代码生成的准确性。
- 优化方向:
- 采用 静态分析工具 或 RAG 机制,从仓库中检索与当前任务最相关的上下文,提高 LLM 的代码适配性。
总结
本研究识别了 四个导致 LLM 代码生成幻觉的主要因素:
- 训练数据质量(数据错误或低质量导致幻觉)
- 任务意图理解能力(LLM 无法准确解析需求)
- 知识获取能力(LLM 无法更新或正确获取领域知识)
- 仓库级上下文感知能力(LLM 无法有效利用项目上下文信息)
优化方向:提升数据质量、改进任务解析、引入 RAG 机制,以减少幻觉在实际开发中的影响。
MITIGATION APPROACH
A. Motivation
LLM 代码生成幻觉的根本问题
LLM 代码生成中的幻觉主要源于 推理阶段 的三个关键限制:
- 对任务需求理解不足(Incorrect/insufficient task requirement understanding)。
- 缺乏与任务相关的事实知识(Lack of factual knowledge)。
- 无法访问仓库中的代码和非代码资源(Inability to access necessary repository resources)。
这些限制 严重影响 LLM 在实际开发环境中的代码生成能力。
研究思路
- 借鉴现有研究 [26]–[35],特别是 仓库级代码生成研究 [62],寻找优化方案。
- 探索 RAG(检索增强生成)方法,通过提供与任务相关的代码片段,帮助 LLM:
- 更准确地理解任务需求。
- 获取更精准的事实知识。
- 适应具体的项目上下文,减少幻觉发生。
B. RAG-based Mitigation
1. 代码检索库构建
- 数据来源:从 CoderEval 数据集 中收集所有代码仓库。
- 方法:遵循 RepoCoder 方法 [62],使用 滑动窗口 处理代码文件:
- 窗口大小:20 行代码。
- 滑动步长:2 行代码。
- 防止泄露答案:排除包含或紧邻 ground-truth 代码 的代码行。
- 结果:为每个代码仓库构建 检索语料库(retrieval corpus),存储代码片段。
2. 代码片段检索
- 检索机制:使用 稀疏词袋模型(Bag-of-Words, BOW) 计算文本相似度。
- 计算方法:
- 将 查询(query) 和 候选代码片段 转换为 token 集合。
- 使用 Jaccard 指数 衡量相似度(交集大小 / 并集大小)。
- 选择 前 10 个得分最高的代码片段,作为 LLM 生成代码的提示信息(prompt)。
目的
- 通过 检索相关代码片段,帮助 LLM 更好地理解任务需求、获取事实知识、适应项目上下文,从而 减少幻觉发生。
C. Evaluation
1. 评估方法
- 数据集:在 CoderEval 数据集 上评估 6 种 LLM(CodeGen、PanGu-α、ChatGPT、DeepSeekCoder、CodeLlama、StarCoder2)。
- 对比方法:
- Raw 方法:仅提供 docstrings 和函数签名 作为输入。
- RAG 方法:在提供 docstrings 和函数签名的基础上,检索 10 个相关代码片段 作为 LLM 生成代码的提示信息(prompt)。
- 评估指标:
- 使用 Pass@1 评估代码的功能正确性,即 生成代码是否能通过测试用例。
2. 结果分析
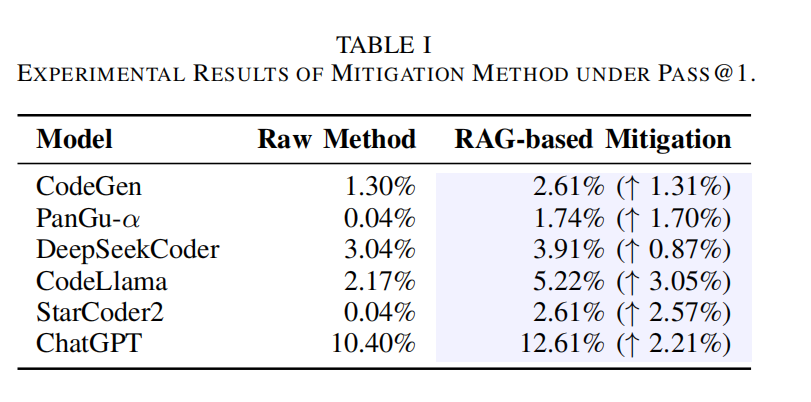
- 表 1 结果:RAG 方法在 所有 6 个 LLM 上均能提高 Pass@1 分数,表明其 有效减少幻觉。
- 提升幅度有限:由于当前方法仍处于 初步探索阶段,未来可进一步研究 模型微调(fine-tuning) 或 多智能体框架(multi-agent framework with tool use) 以提高效果。
3. 案例分析
- 案例 1(功能需求冲突缓解):
- Raw 方法:CodeGen 错误使用 replace() 函数,未能正确将脚本转换为单行命令。
- RAG 方法:CodeGen 正确使用 splitlines() 函数,符合 ground-truth 需求。
- 案例 2(项目上下文冲突缓解):
- Raw 方法:ChatGPT 错误调用 self.items.popitem()(仓库中不存在),导致幻觉代码。
- RAG 方法:ChatGPT **正确使用 self.pop()**,符合仓库上下文要求。
4. 总结
- RAG 方法能 有效缓解 LLM 代码生成中的幻觉问题,提升代码正确性。
- 未来可探索 更高级的缓解策略(如 模型微调、多智能体框架)以进一步优化 LLM 代码生成质量。

DISCUSSION
1. 幻觉识别技术的开发
- 本研究发现 3 大类 LLM 代码生成幻觉,部分可通过 静态分析(如未定义变量) 或 动态测试(如运行时错误) 检测。
- 但某些幻觉(如 功能不完整、安全漏洞)难以检测,可能通过所有测试,最终进入生产环境,带来 系统不稳定和安全风险。
- 现有 LLM 自反馈检测方法 [71], [72] 有一定效果,但 受限于模型自身能力,无法根本解决训练数据缺陷。
- 未来研究方向:开发 更精准和高效的幻觉识别技术,快速定位 LLM 生成代码中的幻觉问题。
2. 更有效的幻觉缓解技术
- 本研究探索了 基于 RAG 的轻量化方法,可缓解部分幻觉(如未定义属性),但仍存在局限:
- 仅基于当前代码仓库 构建检索库,未能覆盖 背景知识冲突 等问题。
- 改进方向:未来可整合 在线搜索引擎、API 文档、StackOverflow 讨论 等更全面的知识源。
- 除 RAG 之外,还可探索其他缓解策略:
- 输入查询优化(Input Query Refinement) [4], [49],提升 LLM 对任务需求的理解。
- 多智能体系统(Multi-Agent Systems) [73],构建 迭代优化流程:
- 明确任务需求
- 生成代码
- 运行测试
- 缓解幻觉
- 关键挑战:需要 设计合理的智能体交互协议,结合 搜索引擎、静态分析工具,并采用 合适的提示策略(Prompting Strategies)。
总结
未来研究可从 幻觉识别 和 缓解技术 两个方向入手,结合 更全面的知识源、多智能体系统、查询优化 等方法,提升 LLM 代码生成的准确性与可靠性。
THREATS TO VALIDITY
1. 外部有效性(External Validity)
- 潜在威胁:研究结果的 通用性 可能受限于以下因素:
- 研究仅基于 Python 代码,未涵盖其他编程语言。
- 采用的 CoderEval 数据集规模有限(230 个任务)。
- 缓解措施:
- 未来研究方向:构建 多语言幻觉分类体系 并进行对比分析。
- 选取 6 个 LLM,每个生成 10 个代码片段,确保标注数据的充足性。
2. 内部有效性(Internal Validity)
- 潜在威胁:手动标注过程中可能存在 主观偏差,影响幻觉分类的准确性。
- 缓解措施:
- 无正式一致性度量 → 通过 标注者会议讨论并统一标注标准,确保一致性。
- 可能存在模型偏差 → 在标注前 混合 6 个 LLM 的生成结果,减少对特定模型的偏见。
- 额外审查:一位作者对所有标注数据进行二次复核。
3. 构造有效性(Construct Validity)
- 潜在威胁:幻觉缓解方法的评估方式可能存在局限性。
- 缓解措施:
- 采用 CoderEval 数据集的测试用例 作为 标准代码正确性评估方法,确保实验可靠性。
总结
本研究采取了多种措施 减少研究偏差,但未来仍需扩大数据规模、涵盖多种编程语言,并进一步优化标注和评估方法,以提高研究的通用性和可信度。