
DeepSeek-Coder: When the Large Language Model Meets Programming - The Rise of Code Intelligence
DeepSeek-Coder: When the Large Language Model Meets Programming - The Rise of Code Intelligence
Abstract
大型语言模型的快速发展革新了代码智能在软件开发中的应用。然而,闭源模型的主导地位限制了广泛的研究与开发。为此,我们推出DeepSeek-Coder系列模型——一组包含1.3B到33B参数规模的开源代码大模型,通过从头训练于2万亿token的高质量项目级代码语料库,并采用16K上下文窗口的填充空白预训练任务,显著提升了代码生成与补全能力。大量实验表明,DeepSeek-Coder不仅在多个基准测试中取得了开源代码模型的最优性能,更超越了如Codex和GPT-3.5等闭源模型。此外,DeepSeek-Coder系列采用宽松许可证,允许研究及无限制的商业使用。
Introduction
背景与挑战
- 大型语言模型(LLMs)正深刻改变软件开发,提升代码智能化水平。
- 这些模型可用于自动化编码任务,如错误检测和代码生成,提高生产力并减少人为错误。
- 现存挑战:开源模型 vs. 闭源模型的性能差距(闭源模型通常更强,但受限于专有性,不易获取)。
DeepSeek-Coder 系列概述
- 提供一系列 开源代码模型,参数规模从 1.3B 到 33B,包括基础版(Base)和指令微调版(Instruct)。
- 训练数据:2 万亿 tokens,涵盖 87 种编程语言,确保广泛的语言理解能力。
- 采用 存储库级数据组织,增强模型跨文件代码理解能力。
- 引入 Fill-In-Middle(FIM)训练,提升代码补全能力。
- 上下文长度扩展至 16K tokens,支持处理更长的代码输入,提高模型适应性。
实验与评估
- 采用多种 公开代码基准测试 进行评估。
- DeepSeek-Coder-Base 33B:在所有开源代码模型中表现最优。
- DeepSeek-Coder-Instruct 33B:超越 OpenAI GPT-3.5 Turbo,显著缩小开源模型与 GPT-4 之间的性能差距。
- DeepSeek-Coder-Base 7B:虽参数量较少,但性能可与 CodeLlama-33B(大 5 倍) 竞争。
主要贡献
- 推出 DeepSeek-Coder-Base 和 DeepSeek-Coder-Instruct,具备 87 种编程语言理解能力,并提供多种规模适配不同需求。
- 首创存储库级数据构造,增强跨文件代码生成能力。
- 深入分析 FIM 训练策略,揭示其对代码模型预训练的影响,为优化代码 LLMs 提供有价值的见解。
- 全面基准测试,结果显示 DeepSeek-Coder-Base 在开源模型中表现最佳,DeepSeek-Coder-Instruct 超越 OpenAI GPT-3.5 Turbo。
Data Collection
- 数据组成
- 87% 源代码
- 10% 英文代码相关自然语言语料(GitHub Markdown、StackExchange)
- 增强代码概念理解,提高库使用和错误修复能力。
- 3% 与代码无关的中文自然语言语料(高质量文章)
- 提升模型的中文理解能力。
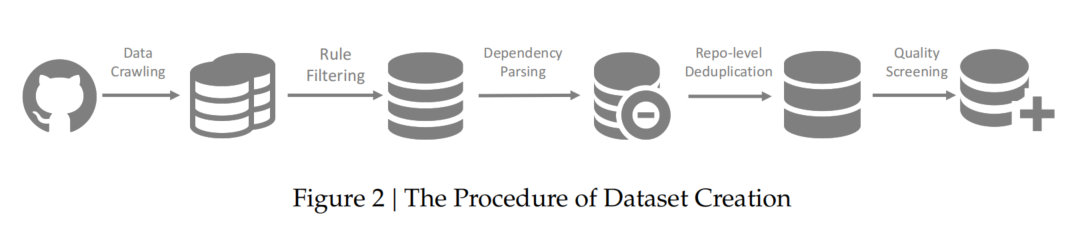
- 数据构建流程
- 数据爬取(Data Crawling)
- 规则过滤(Rule-based Filtering)
- 依赖解析(Dependency Parsing)
- 存储库级去重(Repository-level Deduplication)
- 质量筛选(Quality Screening)
这一流程确保训练数据的质量和多样性,使模型具备 代码理解、错误修复和跨语言处理能力。
2.1. GitHub Data Crawling and Filtering
- 数据收集
- 采集 GitHub 2023年2月前 创建的 87 种编程语言 的 公共存储库。
- 数据过滤规则(借鉴 StarCoder 项目)
- 减少低质量代码,最终数据量缩减至原始规模的 **32.8%**。
- 行长限制:
- 平均行长 > 100 字符 或 最大行长 > 1000 字符 → 过滤。
- 字符比例:
- 非字母字符占比 > 75% → 过滤。
- XML 相关规则:
- 除 XSLT 语言外,若文件前 100 个字符中包含
<?xml version=→ 过滤。
- 除 XSLT 语言外,若文件前 100 个字符中包含
- HTML 文件:
- 可见文本占比 ≥ 20% 且不低于 100 字符 → 保留。
- JSON / YAML 文件:
- 字符数 50 ~ 5000 → 保留(去除大部分数据型文件)。
该过滤策略有效 提升数据质量,减少 冗余和低效代码,为模型训练提供更高质量的数据集。
2.2. Dependency Parsing
- 问题与挑战
- 现有代码 LLM 主要在 文件级 进行预训练,忽略 了项目中 文件间的依赖关系。
- 这种方法在 处理整个项目级代码时 效果欠佳,难以捕捉实际的代码组织结构。
- 方法
- 解析项目内部文件依赖关系,确保代码上下文按照 依赖顺序 组织输入。
- 提高数据集的现实性和实用性,增强模型对 项目级代码的处理能力。
- 依赖解析步骤
- 识别文件间调用关系(基于正则匹配):
- Python:
import - C#:
using - C:
#include
- Python:
- 构建依赖图(Graph):
- 使用 邻接表(graphs) 记录依赖关系。
- 维护 入度字典(inDegree) 统计每个文件的依赖数量。
- 拓扑排序(Topological Sort):
- 处理 子图,按最小入度顺序排列文件,确保顺序合理。
- 解决 循环依赖 问题(不同于标准拓扑排序)。
- 数据组织:
- 按照依赖顺序 连接文件形成训练样本。
- 在每个文件开头 添加 文件路径注释,保留路径信息。
- 识别文件间调用关系(基于正则匹配):
优势
✅ 增强模型对跨文件代码的理解能力
✅ 优化代码组织顺序,使训练数据更符合实际开发习惯
✅ 提升项目级代码生成与补全能力

2.3. Repo-Level Deduplication
背景与必要性
- 研究表明,去重 可 显著提升 LLM 训练效果。
- 传统方法主要在 文件级 去重,但可能破坏存储库的整体结构。
方法
- 采用近似去重(Near-Deduplication),删除长重复子串,优化训练数据质量。
- 与以往不同之处:去重在 存储库级 进行,而非文件级。
- 具体操作:
- 将 整个存储库代码拼接为单一样本。
- 应用去重算法,确保 存储库结构完整,避免误删关键文件。
优势
✅ 减少冗余,提高模型训练效率
✅ 避免文件级去重带来的结构破坏
✅ 优化代码 LLM 在基准测试中的表现
2.4. Quality Screening and Decontamination
- 质量筛选(Quality Screening)
- 在 2.1 过滤规则 基础上,额外 采用以下方法提高数据质量:
- 编译器检测:剔除 语法错误 代码。
- 质量模型评估:过滤 可读性差、模块化低 的代码。
- 启发式规则(Heuristic Rules):进一步剔除低质量数据。
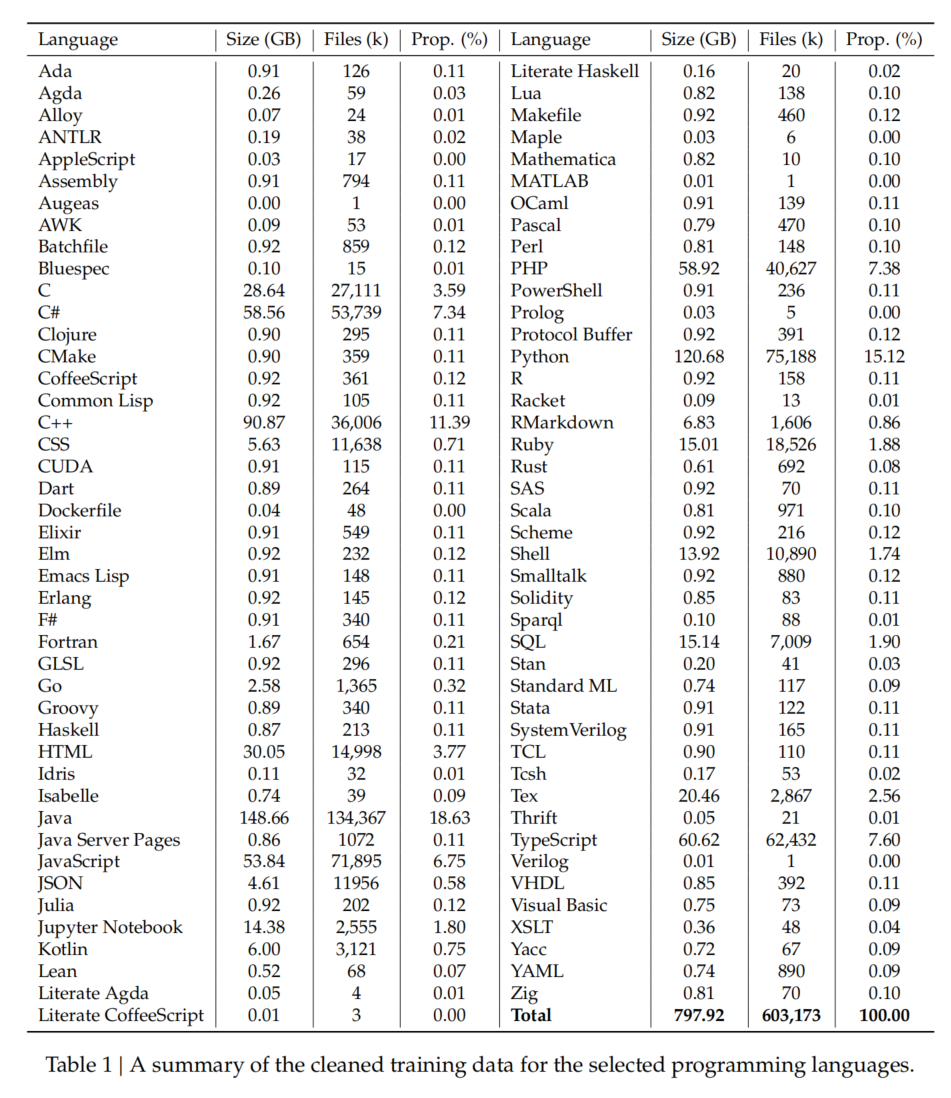
- 数据统计(Table 1):
- 87 种编程语言,总数据量 798GB,文件数 6.03 亿。
- 在 2.1 过滤规则 基础上,额外 采用以下方法提高数据质量:
- 去污染(Decontamination)
- 防止测试集泄露(避免训练数据中包含评测集的代码)。
- 采用 n-gram 过滤,剔除可能泄露的代码段:
- 匹配 10-gram 及以上 → 直接删除。
- 匹配 3-gram ~ 10-gram → 使用精确匹配剔除。
- 过滤的数据来源(测试集):
- HumanEval(Chen et al., 2021)
- MBPP(Austin et al., 2021)
- GSM8K(Cobbe et al., 2021)
- MATH(Hendrycks et al., 2021)
优势
✅ 剔除低质量代码,提高模型训练数据质量
✅ 防止测试集污染,确保评测结果可靠性
✅ 提升代码 LLM 的泛化能力
Training Policy
3.1. Training Strategy
3.1.1 下一个 Token 预测(Next Token Prediction)
- 目标:训练模型预测下一个 token,增强代码理解和生成能力。
- 方法:将多个文件拼接成固定长度输入,模型学习基于上下文的 token 预测能力。
3.1.2 填空式训练(Fill-in-the-Middle, FIM)
- 必要性:仅依赖下一个 token 预测难以处理 代码插入任务,因此引入 FIM 方法。
- 方法:将文本随机拆分为三部分,打乱顺序,并用特殊 token 连接,以模拟代码补全场景。
- FIM 模式:
- PSM(Prefix-Suffix-Middle):前缀 + 后缀 + 中间部分
- SPM(Suffix-Prefix-Middle):后缀 + 前缀 + 中间部分
- 实验:
- 使用 DeepSeek-Coder-Base 1.3B 进行测试,采用 HumanEval-FIM 基准测试(FIM 单行预测任务)。
- 评估 不同 FIM 率(0%、50%、100%) 以及 Masked Span Prediction(MSP) 方法的影响。
实验结果与优化策略
- 100% FIM 率 → 最强 FIM 性能,但代码补全能力最弱,表明两者存在权衡关系。
- 50% PSM 率 > MSP,最终选定 50% PSM 率 作为最佳训练策略。
- 实现细节:
- 引入 三种特殊标记(sentinel tokens)。
- 在数据打包前,先执行 文档级 FIM 处理,确保 FIM 任务的有效性。
优势
✅ 增强模型代码补全能力,适应不同结构的代码填充任务
✅ 优化 FIM 训练策略,兼顾插入预测和代码生成能力
✅ 使用特殊 token 提高模型对 FIM 任务的适应性
DeepSeek-Coder 训练过程示例
DeepSeek-Coder 的训练主要基于 无监督学习(Unsupervised Learning),因为它使用 大规模未标注的代码数据 进行训练,而不依赖人工标注的数据。主要训练方法包括:
- 自回归训练(Autoregressive Training) → Next Token Prediction(NTP)
- 填空式训练(Fill-in-the-Middle,FIM) → 代码插入任务
训练示例:Next Token Prediction(NTP)
目标:
训练模型在给定上下文的情况下预测下一个 token,类似 GPT 语言模型的训练方式。
示例数据(Python 代码片段):
2
return a +模型训练步骤:
- 输入:
- 模型接收
"def add(a, b): return a + "作为输入。- 目标(Ground Truth):
- 期望模型预测 下一个 token:
b- 训练方式:
- 计算模型输出
P(b | "def add(a, b): return a +")的概率,并与实际 tokenb对比,计算损失(如交叉熵)。- 通过 梯度下降 进行权重更新,使模型在类似场景下预测更准确。
训练示例:Fill-in-the-Middle(FIM)
目标:
让模型能够补全缺失的代码片段,而不仅仅是从左到右地预测下一个 token。
示例数据(Python 代码片段):
原始代码:
2
return a + bFIM 处理后(PSM 模式):
模型训练步骤:
- 输入:
- 模型接收
"def add(a, b):"(前缀Prefix)和"return a + b"(后缀Suffix)。- 目标(Ground Truth):
- 期望模型预测缺失的部分,即
return a + b(中间部分Middle)。- 训练方式:
- 计算
P("return a + b" | "def add(a, b):")并优化模型参数,提高 FIM 任务的准确性。训练方式总结
训练方法 目标 训练方式 Next Token Prediction (NTP) 预测下一个 token 传统自回归训练,适用于代码生成 Fill-in-the-Middle (FIM) 预测中间缺失代码 代码重组,适用于代码补全任务 DeepSeek-Coder 结合 NTP + FIM 训练,使模型既能 生成完整代码,又能 插入代码补全,从而更适用于实际编程场景。
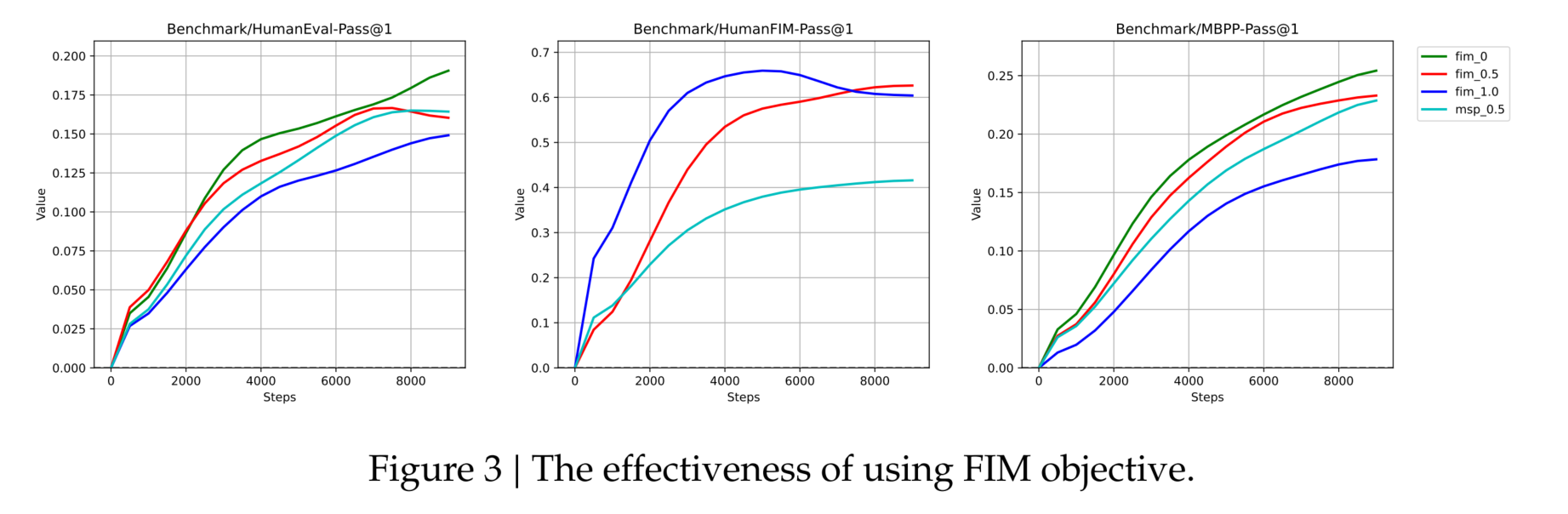
颜色与线型
- **绿色 (fim_0)**:仅使用 Next Token Prediction(无 FIM 目标)。
- **红色 (fim_0.5)**:50% 的训练任务为 FIM,其余为 Next Token Prediction。
- **蓝色 (fim_1.0)**:100% 的训练任务为 FIM。
- **青色 (msp_0.5)**:50% 的训练任务使用 MSP(Masked Span Prediction)。
MSP 更侧重于在原始文本中随机掩蔽出多个片段,并让模型通过上下文来恢复这些片段。
MSP(Masked Span Prediction)与 FIM(Fill-in-the-Middle)的主要区别
特点 MSP(Masked Span Prediction) FIM(Fill-in-the-Middle) 任务目标 在文本或代码中随机掩蔽多个片段,预测这些片段的内容。 将文本拆分为前缀、后缀和中间部分,预测中间部分。 掩蔽方式 随机掩蔽多个位置,可能是单词、代码片段或连续段落。 有结构性:固定预测中间部分,前缀和后缀作为上下文。 灵活性 较灵活,适合广泛场景,但结构性较弱。 更适合代码场景,能更好模拟真实的代码插入任务。 上下文结构 上下文可以是分散的、随机的。 上下文由固定的前缀和后缀组成,更强调语义和语法连续性。
示例比较
1. MSP 示例
原始代码:
2
3
result = a + b
return resultMSP 处理后:
2
3
[MASK]
return result模型任务:预测
[MASK]的内容,即result = a + b。特点:掩蔽的是代码中的某一部分,可能是变量声明、函数调用或其他内容。
2. FIM 示例
原始代码:
2
3
result = a + b
return resultFIM(PSM 模式)处理后:
模型任务:预测
<|fim_hole|>的内容,即result = a + b。特点:上下文明确分为 前缀(Prefix) 和 后缀(Suffix),模型需要根据两者预测中间部分。
模型任务:预测
<|fim_hole|>的内容,即result = a + b。特点:上下文明确分为 前缀(Prefix) 和 后缀(Suffix),模型需要根据两者预测中间部分。
总结
- MSP 更通用,适合广泛场景,但在代码生成中可能不够高效。
- FIM 设计更针对代码插入和补全任务,能更好地捕捉代码的上下文依赖关系。
- 两者可以结合使用,根据任务需求调整比例,达到最优效果。
3.2. Tokenizer
- 工具:
- 使用 HuggingFace Tokenizer 库 进行分词训练。
- 方法:
- 采用 Byte Pair Encoding (BPE) 分词算法(参考 Sennrich et al., 2015)。
- 基于训练语料的子集进行分词模型的训练。
- 结果:
- 最终配置的 词汇表大小(Vocabulary Size)为 32,000。
总结
BPE 分词方法结合了高效性与灵活性,适合处理代码和自然语言的混合语料,同时能够支持高效的模型训练和推理。
3.3. Model Architecture
- 模型范围:
- 提供多种模型,参数分别为 1.3B、6.7B 和 33B,满足不同应用需求。
- 架构框架:
- 所有模型均基于 DeepSeek Large Language Model (LLM) 框架,采用 Decoder-only Transformer 架构。
- 技术细节:
- **Rotary Position Embedding (RoPE)**:增强模型的位置信息表示(参考 Su et al., 2023)。
- **Grouped-Query-Attention (GQA)**:在 DeepSeek 33B 模型中使用,组大小为 8,提升训练与推理效率。
- FlashAttention v2:加速注意力机制的计算(参考 Dao, 2023)。
总结
DeepSeek-Coder 模型采用先进的架构设计与优化技术,旨在提升训练和推理效率,适应不同规模的应用需求。
3.4. Optimization
- 优化器:
- 使用 AdamW 优化器(Loshchilov 和 Hutter, 2019),设置 𝛽1 = 0.9 和 𝛽2 = 0.95。
- 批大小与学习率调整:
- 根据 DeepSeek LLM 的 缩放法则 调整批大小和学习率。
- 学习率调度:
- 实现 三阶段学习率调度策略:
- 包括 2000 步的预热阶段。
- 最终学习率设置为初始学习率的 **10%**。
- 每个阶段的学习率按 √1/10 缩小,遵循 DeepSeek LLM 指导原则。
- 实现 三阶段学习率调度策略:
总结
采用 AdamW 优化器和三阶段学习率调整策略,以优化训练过程并提高模型性能。
3.5. Environments
- 实验框架:
- 使用 HAI-LLM 框架(High-Flyer, 2023),该框架以高效和轻量化的方式训练大型语言模型。
- 并行化策略:
- 采用多种 并行化策略来优化计算效率:
- Tensor Parallelism(Korthikanti et al., 2023)。
- ZeRO 数据并行性(Rajbhandari et al., 2020)。
- PipeDream 流水线并行性(Narayanan et al., 2019)。
- 采用多种 并行化策略来优化计算效率:
- 硬件配置:
- 实验使用 NVIDIA A100 和 H800 GPUs 集群。
- A100 集群:每个节点配置 8 个 GPU,通过 NVLink 桥接连接。
- H800 集群:类似配置,每个节点也有 8 个 GPU,通过 NVLink 和 NVSwitch 技术互联,确保节点内数据传输高效。
- 为确保 节点间高效通信,采用 InfiniBand 互连技术,提供高吞吐量和低延迟。
总结
使用高效的 HAI-LLM 框架 和先进的并行化策略,结合强大的 NVIDIA GPU 集群 和 InfiniBand 网络,为大规模语言模型的训练提供了可靠的计算基础设施。
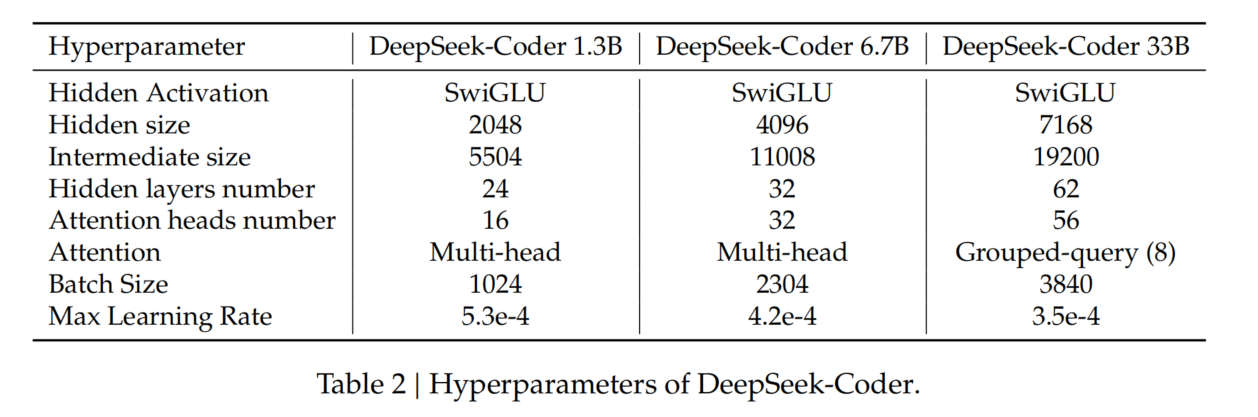
3.6. Long Context
- 目标:
- 提升 DeepSeek-Coder 处理长上下文的能力,特别是用于存储库级代码处理场景。
- 方法:
- 调整 RoPE 参数(Su et al., 2023):
- 缩放因子(Scaling Factor):从 1 增加到 4。
- 基频(Base Frequency):从 10,000 调整为 100,000。
- 训练设置:
- 额外进行 1000 步训练,批大小为 512,序列长度扩展至 16K tokens。
- 学习率与预训练最终阶段一致。
- 调整 RoPE 参数(Su et al., 2023):
- 理论与实验结果:
- 理论上支持处理 64K tokens 的上下文。
- 实验表明,模型在 16K tokens 范围内 输出最可靠。
- 未来工作:
- 进一步优化和评估长上下文适配方法,以提升模型在扩展上下文中的效率和实用性。
总结
通过调整 RoPE 参数和扩展训练,DeepSeek-Coder 具备处理长上下文的能力,尤其在 16K tokens 范围内表现最佳,为复杂代码场景提供了更强的支持。
3.7. Instruction Tuning
目标:
- 基于 DeepSeek-Coder-Base 进行指令微调,开发 DeepSeek-Coder-Instruct,提升模型对指令的理解和响应能力。
数据与格式:
- 使用高质量数据进行微调,数据由 Alpaca Instruction 格式(Taori et al., 2023)组织。
- 每轮对话以特殊分隔符
<|EOT|>标记结束,确保多轮对话结构清晰。
训练设置:
- 学习率:初始值为 1e-5,采用 余弦调度策略,包含 100 步预热阶段。
- 批大小:4M tokens,每轮训练使用 2B tokens。

Experimental Results
评估任务
DeepSeek-Coder 在以下四个任务上进行评估:
- 代码生成 (§4.1)
- FIM(填空式代码补全) (§4.2)
- 跨文件代码补全 (§4.3)
- 基于程序的数学推理 (§4.4)
对比模型
- CodeGeeX2
- 多语言代码生成模型的第二代版本,基于 ChatGLM2 架构开发。
- 使用大量代码示例数据增强性能。
- StarCoder
- 参数量 150 亿 的开源模型,训练于 Stack 数据集 的精心挑选子集。
- 覆盖 86 种编程语言,擅长多种代码任务。
- CodeLlama
- 基于 LLaMA2 的代码模型系列,参数规模分别为 7B、13B 和 34B。
- 训练数据包含 5000 亿 tokens 的代码语料,针对代码任务优化。
- code-cushman-001
- OpenAI 开发的 120 亿参数模型,为 Github Copilot 的初始版本。
- GPT-3.5 和 GPT-4
- 虽非专门为代码生成设计,但凭借其大规模参数展现出显著的代码生成能力。
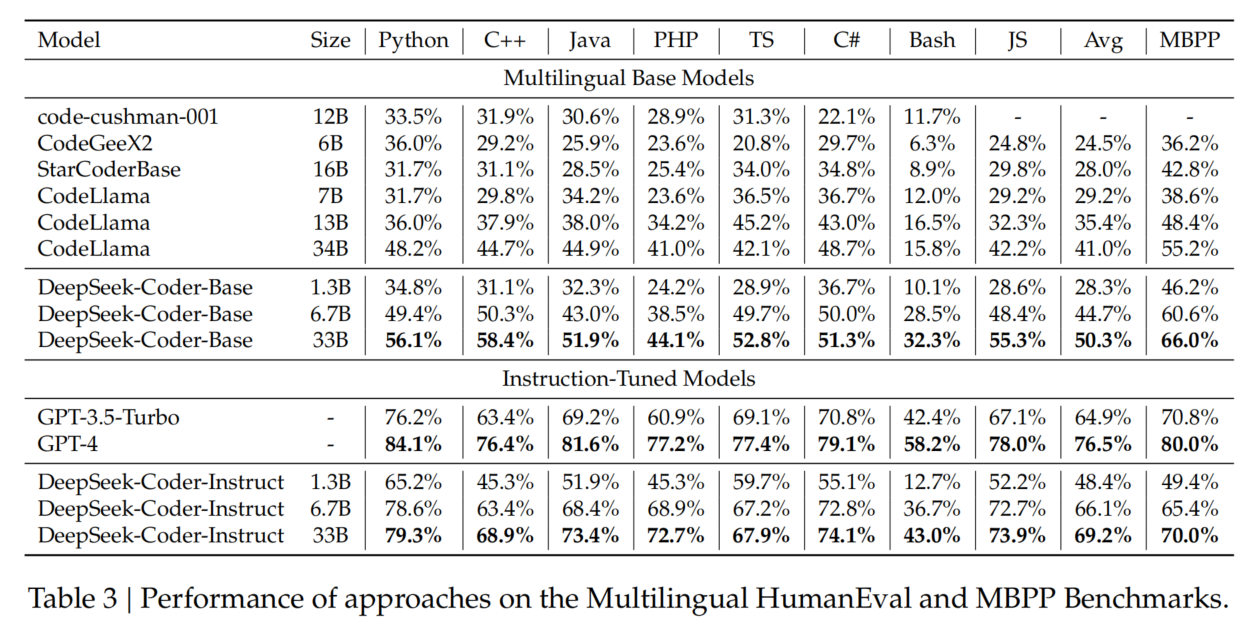
4.1. Code Generation
评测基准(Benchmarks)
- HumanEval & MBPP
- HumanEval:164 道手写 Python 题目,零样本(zero-shot)评估。
- MBPP:500 道编程题,少样本(few-shot)评估。
- 多语言扩展:将 HumanEval 任务扩展到 C++、Java、PHP、TypeScript、C#、Bash、JavaScript 等 7 种语言。
- 结果(Table 3):
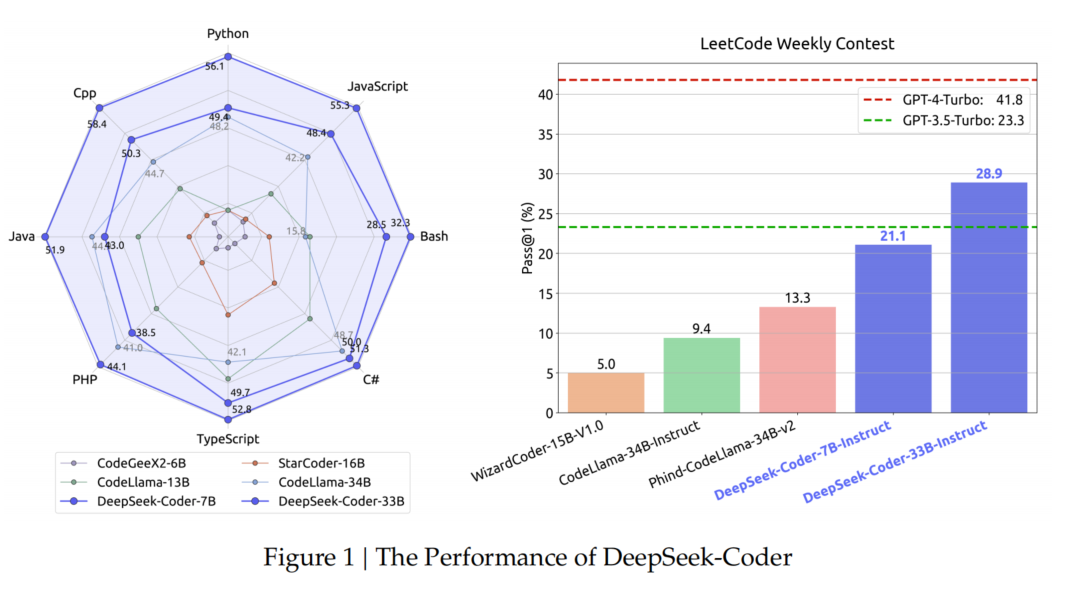
- **DeepSeek-Coder-Base 在 HumanEval 上达 50.3%,MBPP 上达 66.0%**,均为 SOTA(最优)性能。
- 相较 CodeLlama-Base 34B,分别提升 **9% 和 11%**。
- DeepSeek-Coder-Base 6.7B 甚至超过 CodeLlama-Base 34B。
- 指令微调后,DeepSeek-Coder-Instruct 超越 GPT-3.5-Turbo,显著缩小了开源模型与 GPT-4 之间的性能差距。
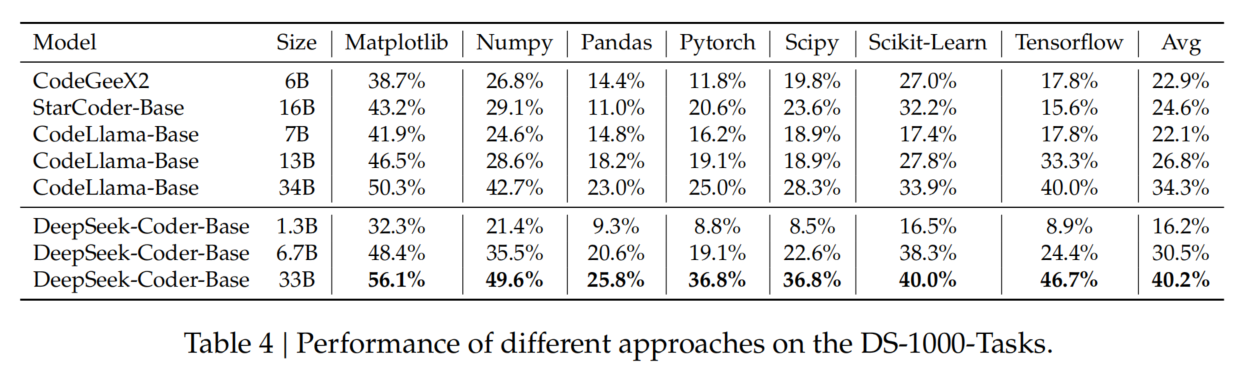
- DS-1000(数据科学代码生成)
- 问题:HumanEval & MBPP 过于基础,缺乏对真实数据科学任务的代表性。
- DS-1000:包含 Matplotlib、NumPy、Pandas、SciPy、Scikit-Learn、PyTorch、TensorFlow 七大库的 1000 个任务。
- 结果(Table 4):
- DeepSeek-Coder 在所有库上均取得较高准确率,证明其在 真实数据科学任务 中的代码生成能力。
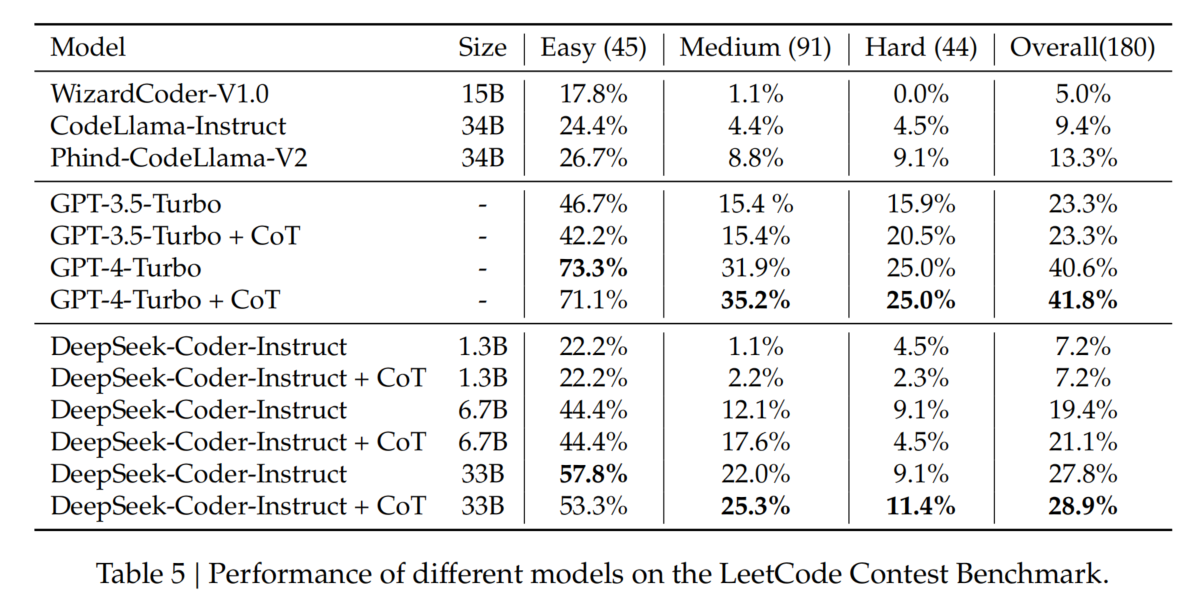
- LeetCode Contest(编程竞赛题目)
- 数据来源:
- 收集 2023 年 7 月至 2024 年 1 月 LeetCode 竞赛中的 180 道最新题目,避免数据污染。
- 每题包含 100 个测试用例 以确保覆盖度。
- 结果(Table 5):
- DeepSeek-Coder-Instruct 6.7B / 33B 的 **Pass@1 分别为 19.4% 和 27.8%**,超越所有现有开源模型(如 CodeLlama-33B)。
- DeepSeek-Coder-Instruct 33B 是唯一超过 OpenAI GPT-3.5-Turbo 的开源模型,但与 GPT-4-Turbo 仍有较大差距。
- 数据来源:
优化策略:Chain-of-Thought(CoT)
- 通过 CoT(思维链)提示(要求模型先写逻辑步骤,再写代码),可显著提升模型在复杂任务中的表现。
- 推荐使用 CoT 促进更系统的方法,提高代码生成的 逻辑性和准确性。
数据污染问题
- 可能存在数据污染风险,因 GPT-4-Turbo 和 DeepSeek-Coder 在 2023 年 7-8 月 LeetCode 竞赛中的表现异常优秀。
- 研究社区应关注此问题,在未来评估中谨慎处理。
总结
✅ DeepSeek-Coder-Base 领先所有开源模型,并在 HumanEval & MBPP 上实现 SOTA 结果。
✅ DeepSeek-Coder-Instruct 33B 超越 GPT-3.5-Turbo,在 LeetCode Contest 上表现最佳。
✅ 使用 CoT 提示可进一步提升复杂编程任务的代码生成质量。
✅ 尽管尽力避免数据污染,仍建议未来评估时审慎对待数据来源。
4.2. Fill-in-the-Middle Code Completion
FIM 训练策略
- DeepSeek-Coder 采用 0.5 FIM 率进行预训练,增强模型根据 前缀(prefix)和后缀(suffix) 预测中间代码的能力。
- 这一策略对 代码补全工具 尤为重要,使模型能更精准地完成代码片段。
对比模型
- SantaCoder(Allal et al., 2023)
- StarCoder(Li et al., 2023)
- CodeLlama(Roziere et al., 2023)
- 以上模型均为 主流开源代码补全模型,在 FIM 任务上具有较强能力。
评估基准
- 采用 Single-Line Infilling 基准测试(Allal et al., 2023)。
- 测试 多种编程语言,使用 行级精确匹配准确率(Exact Match Accuracy) 作为评测指标。
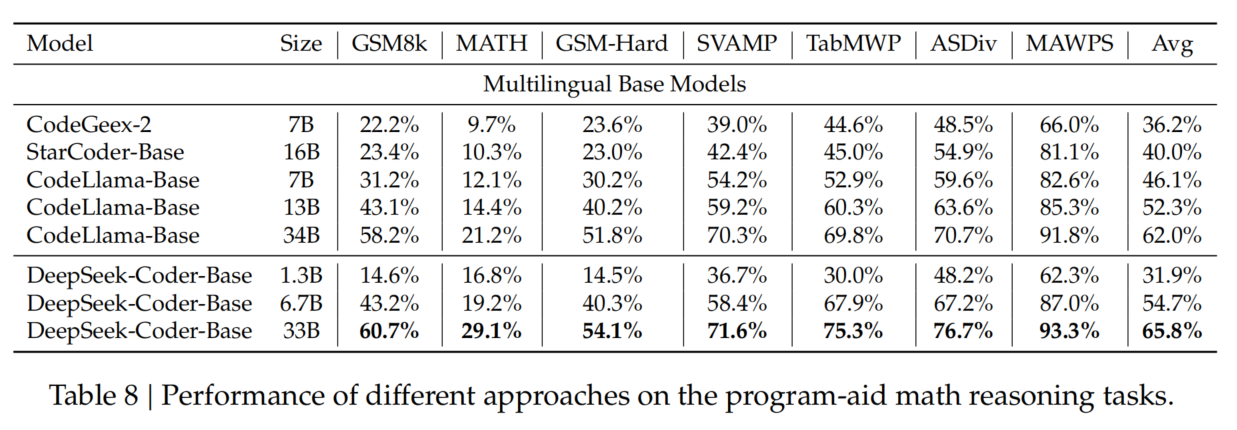
评估结果(Table 6)
- DeepSeek-Coder-1.3B 超越更大规模的 StarCoder 和 CodeLlama,表现最佳。
- 主要优势来源于高质量的预训练数据。
- 模型规模与补全性能呈正相关,即 模型越大,性能越好。
- 推荐使用 DeepSeek-Coder-Base 6.7B,因其 在效率与准确性之间达到最佳平衡,适合集成到代码补全工具中。
总结
✅ DeepSeek-Coder 在 FIM 任务中超越更大规模的开源模型,表现卓越。
✅ FIM 训练策略有效提升代码补全能力,适用于代码编辑器等工具。
✅ 建议使用 DeepSeek-Coder-Base 6.7B 以兼顾性能与效率。
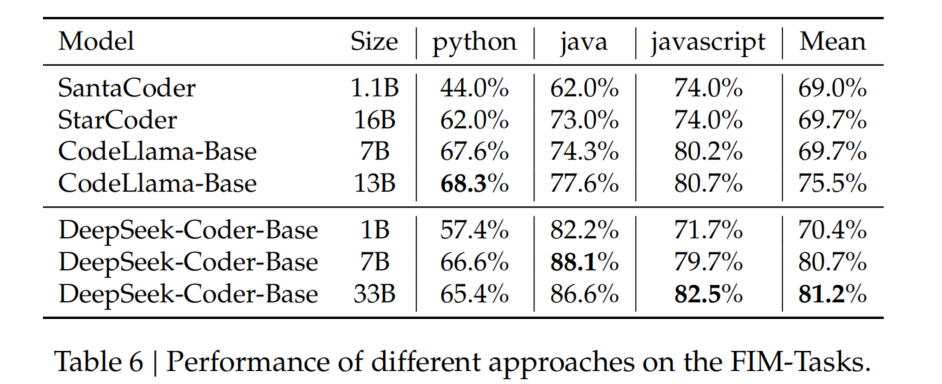
4.3. Cross-File Code Completion
任务特点
- 不同于代码生成任务,跨文件代码补全要求模型理解跨多个文件的依赖关系。
- 评估基准:采用 CrossCodeEval(Ding et al., 2023) 数据集,该数据集涵盖 Python、Java、TypeScript、C# 四种语言,并严格要求跨文件上下文以进行准确补全。
数据集特点
- 数据来源:真实世界的开源代码库,许可开放。
- 时间筛选:数据集来自 2023 年 3 月 - 6 月 创建的代码,而 DeepSeek-Coder 的训练数据截至 2023 年 2 月,避免了数据泄露的可能性。
评估设置
- 最大序列长度:2048 tokens
- 最大输出长度:50 tokens
- 跨文件上下文长度:512 tokens(基于 BM25 搜索结果 选取相关文件)
- 评测指标:
- Exact Match(精确匹配率)
- Edit Similarity(编辑相似度)
评估结果(Table 7)
- DeepSeek-Coder 在所有语言上均优于其他开源模型,表现最优。
- 取消存储库级预训练(w/o Repo Pre-training)后,Java、TypeScript、C# 语言的性能下降,说明存储库级预训练的有效性。
总结
✅ DeepSeek-Coder 在跨文件代码补全任务中表现最佳,优于其他开源模型。
✅ 存储库级预训练显著提升了跨文件代码理解和补全能力。
✅ 该能力适用于真实软件开发场景,提高代码编辑器和 IDE 的智能补全质量。
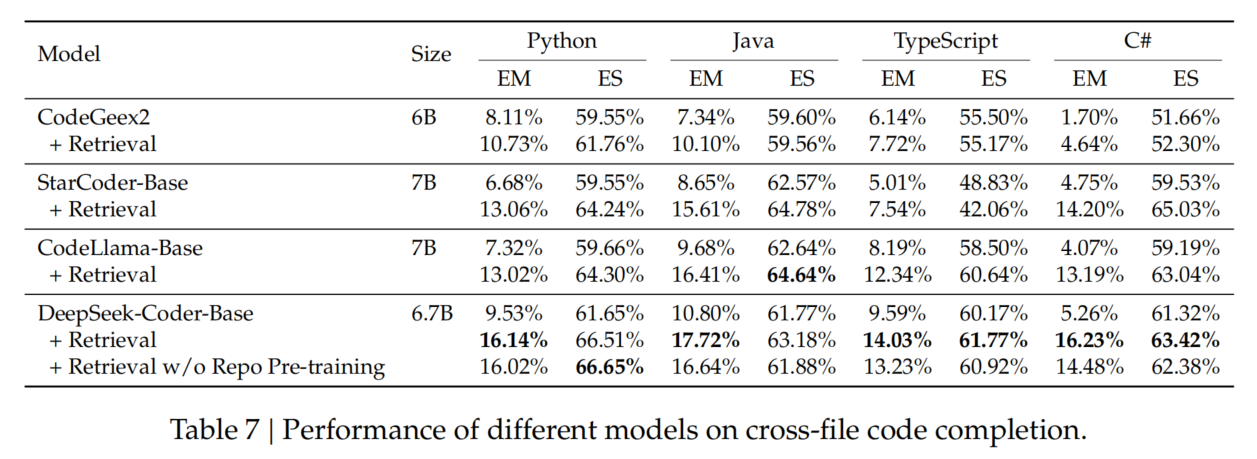
4.4. Program-based Math Reasoning
任务特点
- 评估模型 通过编程解决数学问题的能力,对 数据分析、科学计算 领域至关重要。
- 采用 Program-Aided Math Reasoning (PAL) 方法(Gao et al., 2023),要求模型 交替使用自然语言描述解题步骤,并用代码执行计算。
评测基准(Benchmarks)
涵盖 7 大数学推理数据集:
- GSM8K(Cobbe et al., 2021)
- MATH(Hendrycks et al., 2021)
- GSM-Hard(Gao et al., 2023)
- SVAMP(Patel et al., 2021)
- TabMWP(Lu et al., 2022)
- ASDiv(Miao et al., 2020)
- MAWPS(Gou et al., 2023)
评估结果(Table 8)
- DeepSeek-Coder 全系列模型在所有基准测试中均表现优异。
- DeepSeek-Coder-33B 版本表现尤为突出,展示了其在 复杂数学计算和问题求解 任务中的潜力。
总结
✅ DeepSeek-Coder 在数学推理任务中表现优越,尤其在复杂数学计算场景中展现出巨大潜力。
✅ PAL 方法结合自然语言和代码执行,提高了数学问题求解能力。
✅ DeepSeek-Coder-33B 适用于数据分析、科学计算等高精度计算任务。
Continue Pre-Training From General LLM
改进点
- 基于 DeepSeek-LLM-7B Base 进行额外预训练,处理 2 万亿 tokens 以增强 自然语言理解 和 数学推理能力。
- 不同于 DeepSeek-Coder,新版本 仅使用 Next Token Prediction 目标,并将 上下文长度设为 4K tokens。
评估对比
- 采用 DeepSeek-Coder-v1.5 7B vs. DeepSeek-Coder 6.7B 进行公平对比,重新运行所有基准测试。
- 评估任务分为 三大类:
- 编程(Programming):
- HumanEval(多语言代码生成)
- MBPP(Python 代码任务)
- 数学推理(Math Reasoning):
- GSM8K(基础数学推理)
- MATH(复杂数学推理)
- 自然语言理解(Natural Language):
- MMLU(通识知识)
- BBH(大规模推理任务)
- HellaSwag(常识推理)
- Winogrande(指代消解)
- ARC-Challenge(科学推理)
- 编程(Programming):
评估结果(Table 10)
- DeepSeek-Coder-Base-v1.5 代码性能略有下降,但在 数学推理和自然语言任务 上显著优于原始 DeepSeek-Coder-Base。
- 改进重点:增强了 数学推理(Math Reasoning)和 NLP 能力,适用于更广泛的任务。
总结
✅ DeepSeek-Coder-v1.5 7B 在数学推理和自然语言理解任务上大幅超越前代模型。
✅ 尽管代码性能略有下降,但整体智能水平提升,适用于更复杂的推理任务。
✅ 扩展上下文窗口至 4K tokens,提高模型对长文本和复杂任务的处理能力。
Conclusion
- DeepSeek-Coder 系列概述
- 包含 1.3B、6.7B、33B 三种规模的 代码专用 LLM。
- 采用 项目级代码语料 进行训练,并使用 填空式(Fill-in-the-Middle, FIM) 预训练目标,增强代码补全能力。
- 上下文窗口扩展至 16,384 tokens,提升长代码处理能力。
- 模型性能
- DeepSeek-Coder-Base 33B 超越所有现有开源代码模型,在多项标准测试中表现最佳。
- DeepSeek-Coder-Base 6.7B 规模虽小,但性能接近 CodeLlama-34B,证明预训练数据质量的重要性。
- 指令微调(Instruction Tuning)
- 通过高质量指令数据进行微调,推出 DeepSeek-Coder-Instruct 33B。
- 超越 OpenAI GPT-3.5 Turbo,在多个代码相关任务中展现卓越能力。
- DeepSeek-Coder-v1.5 版本
- 在 DeepSeek-LLM 7B 基础上 额外预训练,处理 200 亿 tokens(包含自然语言、代码、数学数据)。
- 增强自然语言理解能力,同时保持高水平代码性能,验证了强大的代码 LLM 需要构建在通用 LLM 之上。
- 未来展望
- 计划基于 更大规模的通用 LLM 开发更强大的 开源代码专用模型。
- 目标是持续推动代码 LLM 的发展,并开放更多先进模型。
总结
✅ DeepSeek-Coder 具备强大的代码补全、生成和理解能力,超越多款现有开源模型。
✅ DeepSeek-Coder-Instruct 33B 在指令任务上优于 GPT-3.5 Turbo,提升代码智能交互能力。
✅ DeepSeek-Coder-v1.5 兼顾代码性能与自然语言理解,验证了通用 LLM 作为代码 LLM 基础的有效性。
✅ 未来将开发更大规模、更强大的开源代码 LLM,推动代码智能化发展。