
AGENTLESS: Demystifying LLM-based Software Engineering Agents
Agentless:Demystifying LLM-based Software Engineering Agents
近年来,大型语言模型(LLMs)的进展显著推动了软件开发任务的自动化,包括代码合成、程序修复和测试生成。最近,研究人员和行业从业者开发了各种自治LLM代理,以执行端到端的软件开发任务。这些代理具备使用工具、运行命令、观察环境反馈和规划未来行动的能力。然而,这些基于代理的方法的复杂性,以及当前LLM的能力限制,提出了一个问题:我们真的需要使用复杂的自治软件代理吗?为了尝试回答这个问题,我们提出了AGENTLESS——一种无需代理的自动化软件开发问题解决方法。与基于代理方法的冗长复杂设置相比,AGENTLESS采用了简单的三阶段流程:定位、修复和补丁验证,且无需让LLM决定未来的行动或使用复杂工具。我们在流行的SWE-bench Lite基准测试中的结果表明,令人惊讶的是,简单的AGENTLESS不仅能达到最高的性能(32.00%,96个正确修复),还具有较低的成本($0.70),与现有所有开源软件代理相比表现更佳!事实上,AGENTLESS已被OpenAI采纳,作为展示GPT-4o和新发布的OpenAI o1模型在实际编程任务中表现的首选方法。此外,我们手动分类了SWE-bench Lite中的问题,并发现了一些具有准确地面真值补丁或不足/误导性问题描述的问题。因此,我们构建了SWE-bench Lite-S,排除了这些有问题的内容,以进行更严格的评估和比较。我们的工作突出了当前被忽视的简单且具成本效益的技术在自治软件开发中的潜力。我们希望AGENTLESS能够帮助重设自治软件代理的基准、起点和前景,并激发未来在这一重要方向上的研究工作。我们已经开源了AGENTLESS,地址:https://github.com/OpenAutoCoder/Agentless
INTRODUCTION
Background
大型语言模型(LLMs)的应用:
- LLMs已成为代码生成的首选工具,如GPT-4和Claude 3.5 Sonnet。
- 这些LLMs在根据用户描述生成代码片段方面表现出色。
当前应用的局限性:
- 相较于简单、独立的问题评估设置,LLMs在处理仓库级别的软件工程任务(如特性添加、程序修复和测试生成)方面的研究较少。
- 这些任务需要对不仅是文件内容(包含成千上万行代码)的信息,还需要对跨文件的仓库级依赖有深入的理解。
SWE-bench基准测试的提出:
- 为了填补这一研究空白,评估工具自动解决实际软件工程问题的能力,提出了SWE-bench基准测试。
- 在SWE-bench中,每个问题包括一个真实的GitHub问题描述和对应的Python仓库。
- 任务是修改仓库以解决问题,可能是修复bug或引入新特性。
SWE-bench Lite的发布:
- 最近,SWE-bench的子集SWE-bench Lite(300个问题)被发布,进一步筛选,专注于bug修复问题。
Limitations of Agent-based Approach
Agent-based方法的研究背景:
- 为了解决SWE-bench中的实际软件开发问题,学术界和工业界大量研究了基于代理的方法,灵感来源于Devin AI Software Engineer。
- 这些方法通常给LLMs配备一组工具,允许代理通过迭代方式自动执行操作、观察反馈并规划下一步。
Agent-based方法的工具使用与设计:
- 工具包括开/写/创建文件、搜索代码行、运行测试和执行shell命令等。
- 代理执行问题解决任务时,会有多个回合,每回合包括执行一个操作,后续回合依赖于前一回合的操作和环境反馈。
Agent-based方法的局限性:
- 工具使用与设计复杂:
- 现有的代理方法通过抽象层将代理与环境之间的工具使用进行连接(例如,通过API调用),但这种抽象和API调用设计可能导致工具使用不当或不精确,特别是当操作空间复杂时。迭代的特点使得工具使用不当可能导致性能下降并增加额外的成本。
- 决策规划缺乏控制:
- 代理方法将决策过程委托给代理,让代理根据前一步的反馈决定当前操作。然而,由于可能的操作空间和反馈的多样性,代理可能会陷入困惑并做出次优的选择。问题的解决可能需要多达30到40个回合,导致决策过程难以理解,也难以调试错误决策。
- 自我反思能力有限:
- 现有代理缺乏自我反思能力,无法有效地过滤或修正无关、不正确或误导性的信息。这使得错误步骤容易被放大,进而影响后续的决策。
Approach
问题提出:
- 文章提出在软件开发中,不应急于开发越来越复杂的LLM代理工具,而是应首先反思是否真的需要使用复杂的自治软件代理。
AGENTLESS方法:
- 为回答这一问题,提出了AGENTLESS——一种无需代理的方法来自动解决软件开发问题。
- AGENTLESS的解决过程包括三个简单的阶段:定位、修复和补丁验证。
- 定位:通过层级化的过程定位问题,从文件到相关类/函数,最终到细粒度的编辑位置,结合LLM和经典信息检索方法。
- 修复:基于定位结果生成多个候选补丁,并生成重现测试以帮助选择补丁。
- 补丁验证:重新排序所有剩余补丁,并选择一个提交以修复问题。
设计理念:
- AGENTLESS避免了复杂的代理设计,不让LLM自主决定未来行动或使用复杂工具,保持简洁且易于理解。
- 这种设计有助于避免LLM代理在软件开发中的一些限制,如复杂工具使用和决策规划问题。
实验结果:
- 在SWE-bench Lite基准测试中,AGENTLESS不仅在所有开源方法中表现最佳(32.00%的修复率),还以极低的成本实现。
数据集分析:
- 对SWE-bench Lite数据集进行了细致的手动分析,发现一些问题存在准确的地面真值补丁(4.3%)、缺少解决问题所需的关键信息(10.0%)、以及误导性的解决方案(5.0%)。
- 基于这些问题,构建了SWE-bench Lite-S,去除了这些有问题的问题,提供了更严格的基准测试。
总结与展望:
- 本文强调了在追求排行榜名次的时代,简单、成本效益高的技术在自治软件开发中的被忽视的潜力。
- AGENTLESS的提出希望能够重新设定自治软件代理的基准,启发未来在这一方向的研究。
Background and Related Work
2.1 Agent-based Software Engineering
Agent-based软件工程:
- 随着代理框架的兴起,研究人员和行业从业者开始开发基于代理的方法来解决软件工程任务。
典型的Agent-based框架:
- Devin:首个端到端的LLM代理框架,使用代理进行任务规划,并利用文件编辑器、终端和网页搜索工具执行任务。
- SWE-agent:设计了一个自定义的代理-计算机接口(ACI),让LLM代理与代码库环境交互,执行文件读取、编辑和运行bash命令等操作。
- Aider:通过静态和调用图分析提供详细的代码库地图,帮助LLM定位需要编辑的文件,生成简单的diff格式补丁,并使用回归测试验证修复效果。
- Moatless:另一个开源工具,通过代码搜索工具和LLM构建的查询获取相关代码位置,生成补丁并提交。
- AutoCodeRover:提供代码搜索API帮助LLM代理定位错误位置,迭代检索代码上下文。
- SpecRover:在AutoCodeRover的基础上进一步改进,通过生成函数摘要、反馈消息和重现测试来推断程序行为并选择最终补丁。
AGENTLESS的创新与优势:
- 相比这些复杂的代理方法,AGENTLESS提供了一个简单、可解释、成本效益高的解决方案。
- AGENTLESS的设计包括明确的定位、修复和补丁验证阶段,而无需让LLM代理决定未来的行动或使用复杂的工具。
- AGENTLESS首次证明了无需代理的方法也能在解决实际软件工程问题时取得非常竞争力的表现,并避免了复杂工具和环境行为建模的额外负担。
2.2 Fault Localization and Program Repair
故障定位(Fault Localization,FL):
- 动态故障定位:包括基于频谱的FL(SBFL)和基于变异的FL(MBFL)。SBFL通过计算测试覆盖的源代码位置来判定更可能出现故障的位置,MBFL则进一步考虑每个代码位置对测试结果的影响。
- 静态故障定位:利用信息检索(IR)技术将故障定位问题转化为搜索问题,通过代码元素与错误报告的文本相似度进行比较。
- 基于学习的故障定位:结合动态和静态信息,使用机器学习技术进行故障定位,如DeepFL、FLUCCS、TRANSFER等。
- LLM-based故障定位:近年来,LLM-based方法利用现代LLM强大的代码和自然语言理解能力进行故障定位。然而,这些方法通常无法执行仓库级的故障定位,或依赖于复杂和高成本的代理设计。
- 相比之下,AGENTLESS采用简洁的分层故障定位方法(结合LLM和IR),高效地计算细粒度的编辑位置。
程序修复(Program Repair):
- 传统的自动化程序修复(APR)技术:可以分为基于模板、启发式和约束的工具。尽管有效,但传统APR工具存在可扩展性问题,并且补丁种类有限。
- 基于学习的APR工具:使用神经机器翻译(NMT)模型或预训练LLM进行修复,LLM-based APR工具因其强大的编程能力而成为当前的最佳方法。
- 代理基础APR技术:最近也提出了基于代理的APR技术,灵感来源于现有的LLM-based APR工具。
- AGENTLESS的修复方法:AGENTLESS与LLM-based APR工具相似,采样多个候选补丁以增加修复成功的概率。
- 不同于大多数LLM-based APR方法,AGENTLESS生成简单的diff格式补丁,避免生成完整代码,专注于产生成本效益高的小修补,从而提高修复的可靠性和准确性。AGENTLESS还针对更复杂的仓库级问题,解决跨多个位置的复杂故障。
2.3 LLM-based Test Generation
LLM在测试生成中的应用:
- LLM已被应用于测试生成领域,尤其是模糊测试(fuzz testing),用于生成大量输入以暴露系统中的bug。研究者们在深度学习库、操作系统内核、编译器、网络协议和移动应用等领域应用LLM进行模糊测试,取得了较传统模糊测试工具更好的效果,发现了许多传统模糊测试无法检测的bug。
- 除了模糊测试,LLM还被用于单元测试生成,测试单独的软件单元(如方法/类),如CodeMosa、ChatTester、TestPilot和CoverUp等工具。
Bug重现:
- Bug重现是调查bug报告的关键步骤,并已集成到许多最近的软件工程代理中。例如,SpecRover首先生成一个测试来重现bug报告中描述的问题,然后通过该测试引导上下文检索和修复过程。
AGENTLESS的不同之处:
- 与基于代理的方法不同,AGENTLESS通过简单执行多个采样的测试来验证是否重现了问题,而不是依赖LLM代理决定测试是否正确。
AgentLess Approach
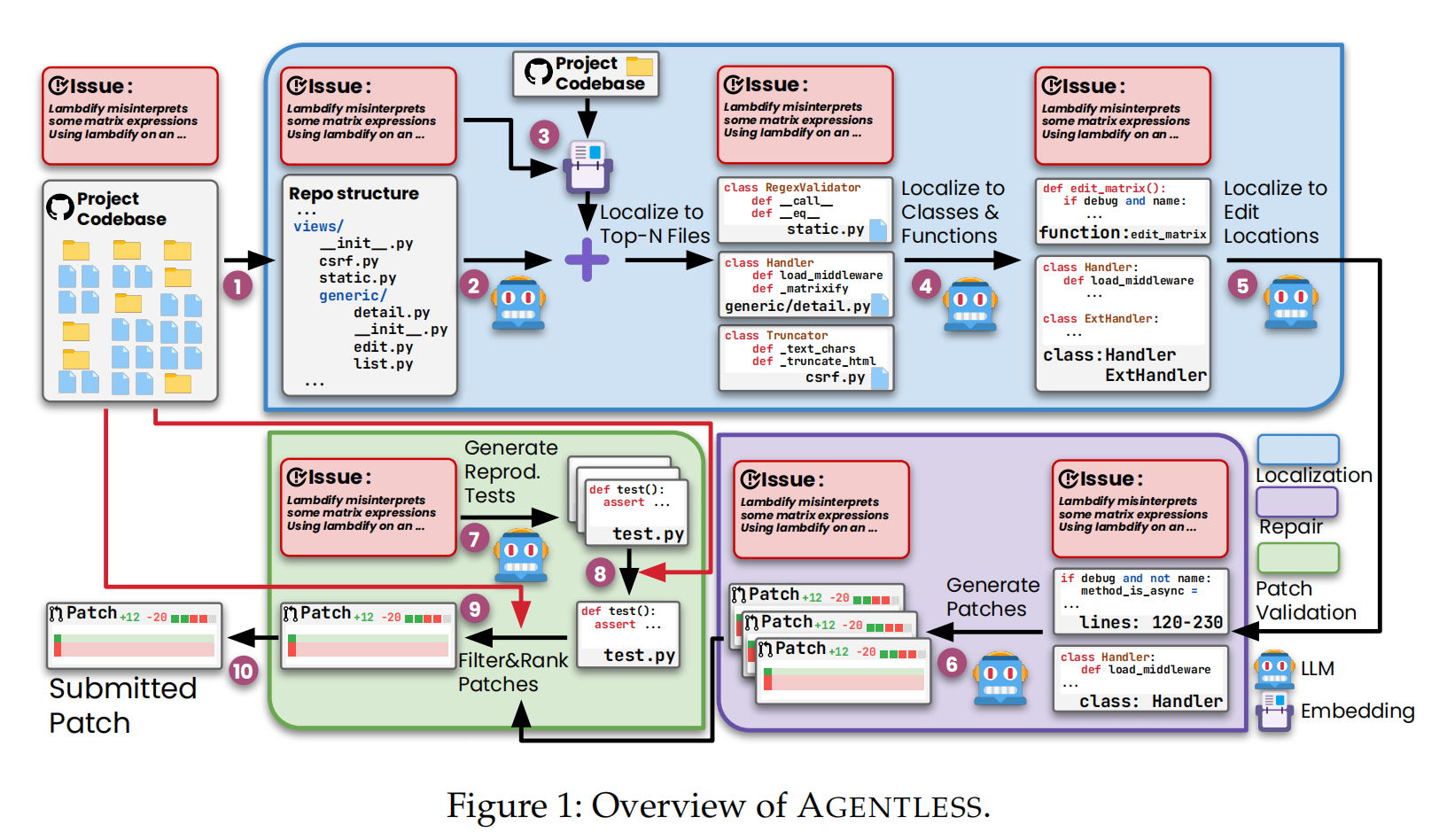
AGENTLESS概述:
- AGENTLESS包括三个主要阶段:定位、修复和补丁验证。
定位阶段:
- 输入:问题描述和现有项目代码库。
- 首先将项目代码库转化为树状结构,展示每个文件的位置。
- 使用该结构和问题描述提示LLM定位并排名最有可能需要编辑的N个文件。
- 通过嵌入式检索获取与问题描述最相关的代码片段,并将这些文件与LLM定位的文件结合,得到最终的可疑文件列表。
- 进一步提供每个文件的类和函数声明头信息,询问LLM需关注的类和函数。
- 最后,提供完整的代码内容并请LLM确定具体的编辑位置(如类、函数或特定行)。
修复阶段:
- 提供定位到的代码片段和问题描述,提示LLM生成多个补丁来修复问题。
补丁验证阶段:
- 让LLM生成多个重现测试,以验证是否能重现原始问题。
- 根据执行结果选择最佳的重现测试。
- 结合重现测试和回归测试对补丁进行排名和选择。
- 最终选择排名最高的补丁作为最终提交的修复补丁。
总结:
- AGENTLESS通过这三个阶段:定位、修复和补丁验证,自动化解决软件开发中的问题,并确保补丁的正确性。
3.1 Localization
定位的重要性:
- 在修复或实现新功能时,首先需要确定源代码中的正确位置,因为没有正确的定位就无法进行有效的修改。
挑战:
- 代码库可能包含数百个文件和成千上万行代码,而需要编辑的只是少数几行或函数。
AGENTLESS的解决方案:
- AGENTLESS采用简单的三步分层定位过程:
- 定位到可疑文件;
- 在每个文件中定位到相关的类、函数和变量;
- 定位到具体的代码编辑位置。
3.1.1 Localize to suspicious files.
定位到可疑文件:
- 第一步:AGENTLESS通过构建简洁的代码库文件和目录结构表示(类似Linux的tree命令)来缩小潜在位置范围。这个“代码库结构格式”展示了根文件夹及其下的文件和文件夹层次关系,供LLM使用。
- 第二步:AGENTLESS将处理后的代码库结构和问题描述输入LLM,要求它识别出需要进一步检查或修改的前N个可疑文件。
嵌入式检索补充定位:
- 为了补充基于提示的定位方法,AGENTLESS使用简单的嵌入式检索方法来识别额外的可疑文件。首先,AGENTLESS通过提供代码库结构,要求LLM生成不需要进一步检查的无关文件夹列表,并移除这些无关文件夹中的文件。
- 接着,将剩余文件分块,并计算每个代码块的嵌入。AGENTLESS还将原始问题描述进行嵌入,并计算查询嵌入与每个代码块嵌入的余弦相似度,以检索出与查询最相关的文件。
最终文件列表:
- AGENTLESS结合基于提示的方法和嵌入检索的方法,选择出前N个最常见的文件,生成最终的相关文件列表。
3.1.2 Localize to related elements.
定位到相关元素:
- 在获取到可疑文件列表后,AGENTLESS进入第二部分:定位文件中的相关元素。
- 直接提供文件的完整上下文可能过于庞大,因此AGENTLESS构建了一种压缩格式,称为**”骨架格式”**(skeleton format),只包含类、函数或变量的声明。
- 在骨架格式中,AGENTLESS仅提供类和函数的头部信息。对于类,还包括类字段和方法(仅限签名)。此外,还会保留类和模块级别的注释以提供更多信息。
- 与提供完整文件上下文相比,骨架格式更加简洁,特别是在文件包含大量行时,处理整个文件可能不切实际或成本过高。骨架格式使得LLM可以在一次提示中处理所有可疑文件,帮助模型分析相关信息并决定最相关的元素。

3.1.3 Localize to edit locations.
定位到相关元素:
- 在获取到可疑文件列表后,AGENTLESS进入第二部分:定位文件中的相关元素。
- 直接提供文件的完整上下文可能过于庞大,因此AGENTLESS构建了一种压缩格式,称为**”骨架格式”**(skeleton format),只包含类、函数或变量的声明。
- 在骨架格式中,AGENTLESS仅提供类和函数的头部信息。对于类,还包括类字段和方法(仅限签名)。此外,还会保留类和模块级别的注释以提供更多信息。
- 与提供完整文件上下文相比,骨架格式更加简洁,特别是在文件包含大量行时,处理整个文件可能不切实际或成本过高。骨架格式使得LLM可以在一次提示中处理所有可疑文件,帮助模型分析相关信息并决定最相关的元素。
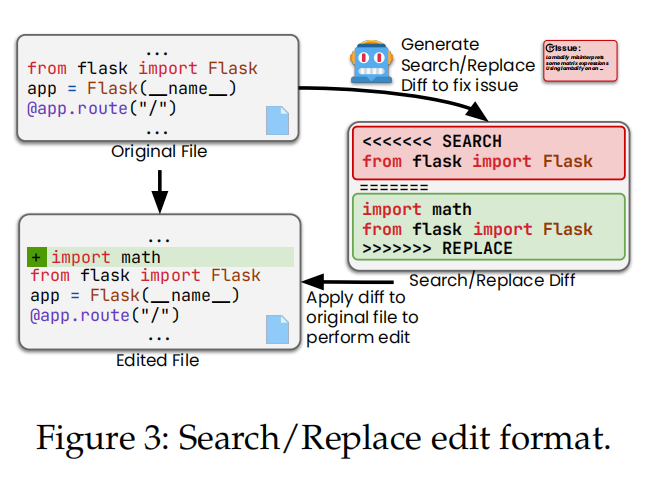
3.2 Repair
修复阶段目标:
- 目标是生成正确的补丁来解决问题,AGENTLESS借鉴了现有的LLM-based程序修复方法。
上下文窗口构建:
- 使用已定位的编辑位置,AGENTLESS为LLM构建一个代码片段的上下文窗口。若定位位置为40到78行,则创建一个上下文窗口[40 - x, 78 + x],其中x为上下文窗口的大小,旨在为LLM提供相关的上下文信息。
多位置修复:
- 若有多个编辑位置,AGENTLESS将多个上下文窗口连接起来,使用“…”表示中间缺失的上下文。
生成补丁:
使用代码片段,AGENTLESS要求LLM生成补丁来修复问题,但不直接生成完整的代码,而是要求生成一个Search/Replace
格式的补丁。
- Search:表示原始代码片段,需要被替换的部分。
- Replace:表示替换的代码片段。
这种简单的diff格式专注于生成小的修改,既提高了成本效益,也增加了修复的可靠性和准确性。
生成多个补丁:
- 对每个问题,AGENTLESS让LLM生成多个候选补丁,首先使用贪心策略生成补丁,然后使用更高温度进行多样化采样。
3.3 Patch Validation
3.3.1 Reproduction test generation.
重现测试生成:
- 由于AGENTLESS生成多个候选补丁,需要一种方法来选择最终的补丁提交。
- 在SWE-bench设置下,原始项目代码库仅能提供回归测试,而没有bug触发测试,因此无法访问触发问题的测试。
生成重现测试:
- AGENTLESS借鉴之前的工作,生成额外的重现测试来帮助补丁选择。
- AGENTLESS利用LLM合成一个完整的测试文件,试图重现描述中的问题,并验证问题是否已解决。
- 重现测试的输出应当在重现问题时打印“Issue reproduced”,而在问题解决时打印“Issue resolved”。
重现测试执行:
- AGENTLESS还提供原始问题描述的重现测试示例,并执行每个候选重现测试来过滤掉未能重现问题的测试。
- 测试会经过标准化(去除注释、额外的空格等),并选择测试结果最佳的重现测试作为最终测试。

3.3.2 Patch selection.
补丁选择过程:
- 初步测试:AGENTLESS首先运行代码库中所有现有的测试,识别通过的测试。这些通过的测试并非都应作为回归测试,因为修复问题可能涉及更改现有功能。
- 去除非回归测试:AGENTLESS将通过的测试提供给LLM,要求其识别哪些测试不应运行,以验证问题是否已修复,并去除这些非回归测试。
- 回归测试:然后运行剩余的回归测试,选择回归失败最少的补丁。
- 重现测试验证:AGENTLESS运行所选的重现测试,确保输出为“Issue resolved”,并剔除未通过重现测试的补丁。如果没有补丁通过重现测试,AGENTLESS会仅依据回归测试结果进行选择。
补丁标准化和选择:
- 为了忽略表面级差异(如空格、新行和注释),AGENTLESS对每个补丁进行标准化处理,解析并重新格式化代码,最终计算标准化后的差异作为补丁。
- 使用多数投票法对补丁进行重新排序,并选择出现次数最多的补丁作为最终提交的补丁。
AGENTLESS的优势:
- AGENTLESS采用简单的三阶段方法:定位、修复和验证,无需依赖代理进行决策。
- 通过层级化的定位方式,AGENTLESS高效地计算出细粒度的编辑位置。
- 采用简单的diff格式进行修复,并使用生成的重现测试来辅助验证补丁的有效性。
Experimental Setup
数据集:
- AGENTLESS和基准方法在流行的SWE-bench数据集上进行评估,专注于SWE-bench Lite版本(包含300个高质量问题)。此外,还对SWE-bench Lite进行详细研究,识别潜在问题和偏差,并构建一个更严格的过滤问题集。
实现:
- 使用GPT-4o实现AGENTLESS,并采用贪心解码和采样温度为0.8。通过LlamaIndex实现基于嵌入的检索方法,使用OpenAI的text-embedding-3-small模型来计算嵌入。
- 在定位阶段,每个问题首先定位到前3个可疑文件,然后进一步定位相关类和函数,并生成4个编辑位置样本,每个样本生成10个补丁。
- 生成40个重现测试样本,并进行回归测试来识别非回归测试。
基准对比:
- 将AGENTLESS与26种基于代理的方法进行比较,包括开源和闭源方法。还包括一个简单的无代理基线方法(RAG),它使用LLM直接生成补丁。
评估指标:
- 评估指标包括:1) 解决问题的百分比(% Resolved),2) 平均成本(Avg. $ Cost),3) 平均输入输出token数(Avg. # Tokens),以及4) 正确定位的百分比(% Correct Location),评估补丁是否覆盖正确的编辑位置,包括文件、函数和行级别。
方法说明:
- 基准方法的结果直接取自SWE-bench的官方排行榜或相关工具的官方论文/仓库。
Evaluation
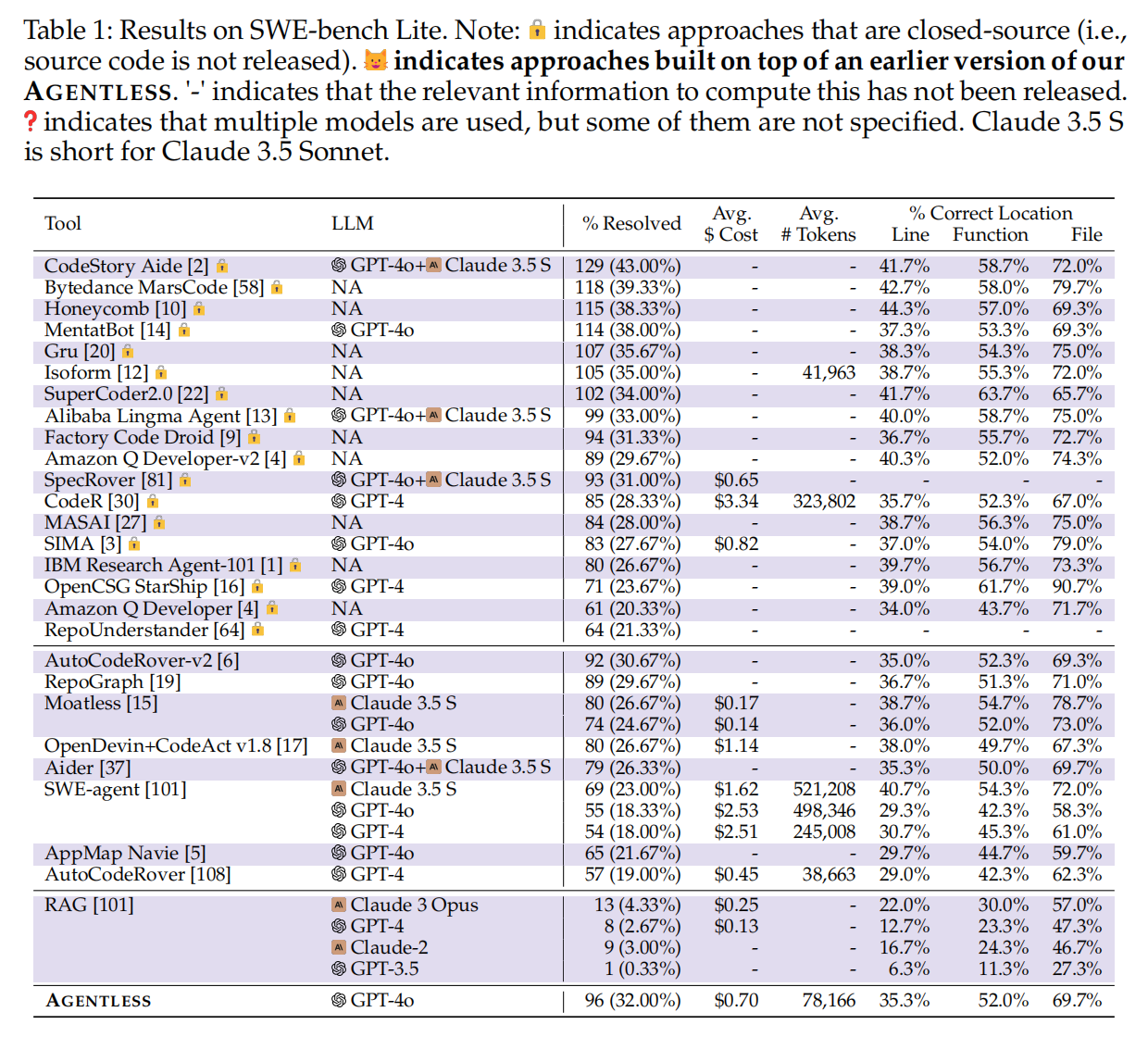
5.1 Performance on SWE-bench Lite
SWE-bench Lite评估结果:
- AGENTLESS解决了300个问题中的96个(32.00%),虽然这一解决率不是最高,但相较于现有的基于代理的方法,AGENTLESS在使用更简单的设计和技术的情况下仍表现得非常有竞争力。
- 很多顶级方法是闭源/商业工具,没有发布源代码以供复现实验或验证。
- 相较于所有开源方法,AGENTLESS在SWE-bench Lite上的表现最高,解决了32.00%的问题。
成本效益:
- AGENTLESS的平均成本为$0.70,低于大多数基于代理的方法。
- 相比RAG无代理基线方法,虽然AGENTLESS的成本略高,但其能够修复更多问题。
5.1.1 Unique issues fixed.
独特问题修复:
- 图5展示了AGENTLESS与顶级闭源/商业和开源工具相比解决的独特问题。
- 相比于开源的基于代理的工具,AGENTLESS能够修复2个其他工具无法解决的问题,展示了使用简单无代理方法在解决难题上的成功。
- 即使与表现优秀的商业工具相比,AGENTLESS仍能提供独特的修复,证明其在解决特定问题上的能力。
AGENTLESS的独特优势:
- AGENTLESS解决了少量独特问题,这些问题也被某些现有工具部分或完全解决,这些工具可能是基于AGENTLESS或受到其启发(如Bytedance MarsCode)。
- 尽管如此,结果表明AGENTLESS仍具有竞争力,并能与现有代理工具互补。

5.1.2 Localization performance.
定位性能:
- 在实际的软件开发中,除了直接修复问题外,提供正确的编辑位置对开发人员调试非常有帮助。因此,本文比较了每种技术生成的补丁与地面真值补丁的位置。
- 表1展示了每个工具在行、函数和文件级别上正确位置的百分比。
定位结果分析:
- 观察发现,正确位置的百分比与问题解决率高度相关。对于文件级位置,OpenCSG StarShip的结果最高,达到90.0%,但其解决率较低(23.67%)。由于OpenCSG StarShip是一个商业产品,且未提供源代码或详细轨迹,难以解释其定位与修复性能之间的巨大差异。
AGENTLESS的竞争力:
- 通过采用简单的分层定位方法,AGENTLESS在定位性能上与先前的基于代理的方法相比仍具有很强的竞争力。
5.1.3 Reproduction test results.
重现测试结果:
- AGENTLESS使用回归测试和生成的重现测试来筛选最终提交的补丁,因此需要评估生成的重现测试的质量。
- 在SWE-bench Lite的300个问题中,AGENTLESS成功生成了213个重现测试,这些测试在原始代码库中输出了所需的重现信息。
问题与解决:
- 尽管生成了许多重现测试,只有94个测试在应用地面真值补丁后成功输出“Issue resolved”信息。此下降可部分归因于问题描述可能没有提供足够信息来生成完整的测试用例以验证正确解决方案。
问题缓解措施:
- AGENTLESS采取保守方法,要求所有补丁首先通过回归测试,如果补丁通过生成的重现测试但未通过回归测试,则会被移除。这减少了错误的重现测试选中正确补丁的可能性。
- 如果所有生成的补丁都无法通过重现测试,AGENTLESS将仅依赖回归测试结果进行选择。
后续研究:
- 第5.2.3节将深入探讨回归测试和重现测试在补丁选择中的组合对性能的影响。
5.1.4 Adoption of AGENTLESS.
AGENTLESS的采用情况:
- 虽然AGENTLESS最近才发布,但已经得到广泛采用。
- RepoGraph是一个开源工具,结合了AGENTLESS和仓库级图形,Isoform是一个闭源商业工具,也基于AGENTLESS构建。此外,Bytedance MarsCode部分受到AGENTLESS启发,OpenDevin正在将AGENTLESS集成到他们的生态系统中。
- AGENTLESS已被OpenAI作为默认方法,用于展示GPT-4o在新SWE-bench验证基准上的表现,并且在该基准中AGENTLESS取得了最佳表现。
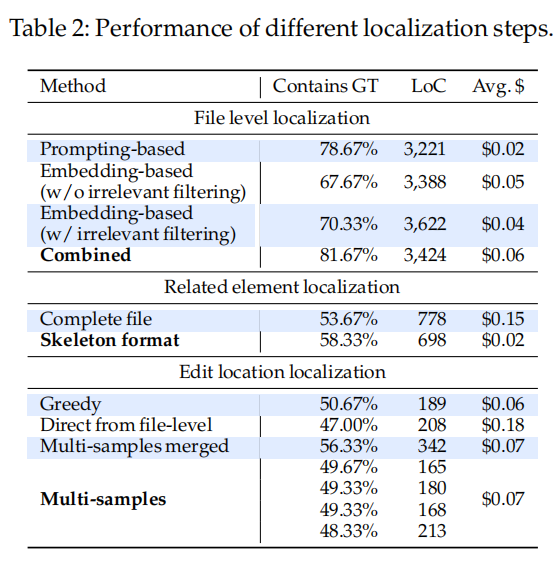
表格2:不同定位步骤的性能:
- 文件级定位:多种方法的表现比较,包括基于提示、基于嵌入的定位方法和组合方法。组合方法的正确率为81.67%,且成本最低($0.06)。
- 相关元素定位:包括完整文件和骨架格式。骨架格式表现较好,正确率为58.33%,成本仅为$0.02。
- 编辑位置定位:不同采样方法的性能比较,包括贪心方法和多样本合并方法。贪心方法表现较为突出,正确率为50.67%,成本为$0.06。
AGENTLESS的优势:
- AGENTLESS在所有基于代理的方法中表现最佳,且OpenAI已将其作为展示GPT-4o性能的标准方法。
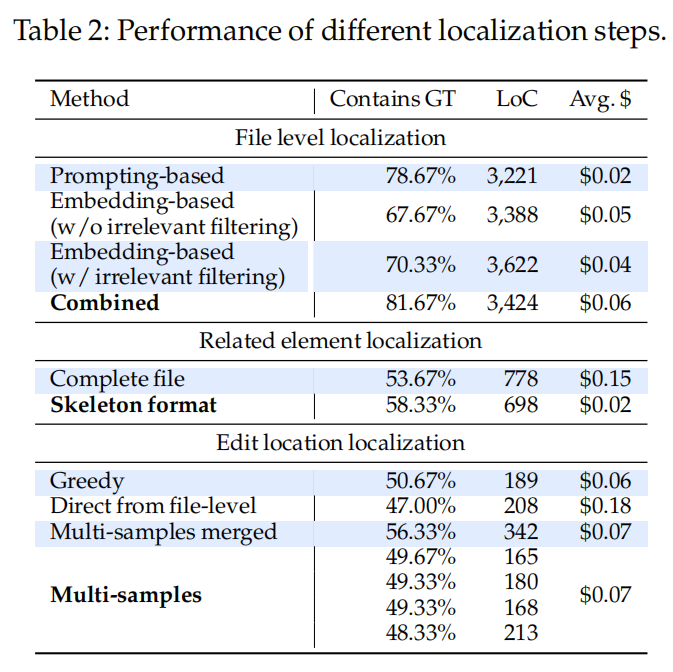
5.2 Ablation study on components of AGENTLESS
5.2.1 Localization ablation.
定位步骤的性能与成本:
- 表2展示了AGENTLESS定位阶段的三个步骤的性能和成本,包括每个步骤在定位地面真值编辑位置后的百分比、每个定位集的平均代码行数和每个步骤的平均成本。粗体方法表示AGENTLESS的默认设置。
不同配置的效果:
- 文件级定位:AGENTLESS通过嵌入式检索方法取得了较好的性能,分别在78.7%和67.7%的案例中定位到正确文件,结合提示和嵌入方法后达到81.7%的正确文件定位。
- 相关元素定位:AGENTLESS通过使用骨架格式减少了上下文窗口,性能有所提升,相比完全文件内容方法减少了代码行数和成本。
编辑位置定位:
- 方法比较:使用贪心方法、从文件级别直接定位和多样本合并等方法进行比较,发现直接从文件级定位到编辑位置效果较差,而多样本合并的效果更好,但成本也更高。
- 默认设置:AGENTLESS采用多次采样的方法以确保良好的定位性能,并通过分层定位减少成本,同时确保定位准确。
总结:
- AGENTLESS通过层次化的定位方法,在确保准确性的同时,也有效地控制了成本,且能够处理复杂的定位任务。
5.2.2 Repair ablation.
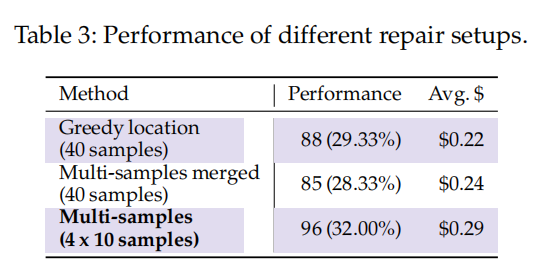
修复步骤的影响:
- 表3展示了不同修复设置的性能和成本。使用贪心定位集生成的编辑位置已经能够修复超过88个问题。通过将多个位置集合并为一个,性能也可以达到类似水平。
- 通过分别考虑每个采样位置并生成多个候选补丁,性能进一步提高,达到了96个问题修复。
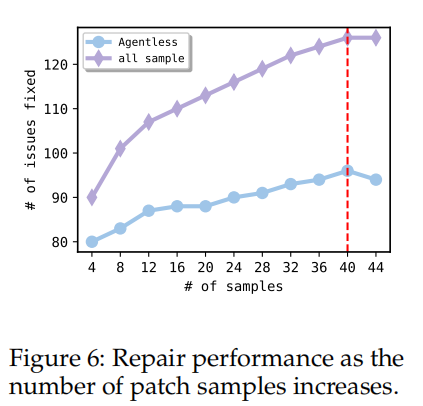
采样对性能的影响:
- 图6展示了增加采样数目对修复性能的影响。使用1个贪心样本时,AGENTLESS已经能够修复80个问题。随着样本数的增加,修复性能逐步提高,但当样本数达到40时,性能趋于平稳,新增样本对性能的提升较小。
- 由于使用多数投票法选择最终补丁,后续样本可能被忽略,因为它们难以影响已投票选中的补丁。
潜力和未来改进:
- 如果考虑所有补丁样本而非只选取一个,AGENTLESS可以解决126个问题(占42%),这表明AGENTLESS具有很大的潜力。未来的工作可以通过更好的补丁重排序和选择技术进一步提升整体性能。
5.2.3 Patch validation ablation.
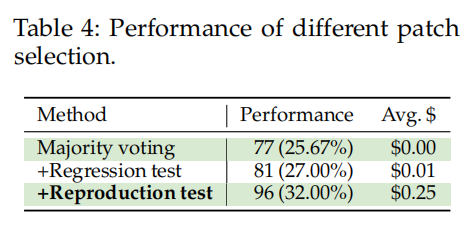
补丁选择的影响:
- 表4展示了不同补丁选择方法的性能和成本。通过仅使用多数投票,AGENTLESS能够修复77个问题。加入回归测试后,修复数量提升至81个。最显著的性能提升是通过引入重现测试进行额外的过滤,最终修复了96个问题。
- 重现测试的使用提高了AGENTLESS的补丁选择能力,但也增加了额外的成本,因为AGENTLESS需要生成这些测试。
重现测试生成的效果:
- 图7展示了增加重现测试样本数对修复性能的影响。随着候选重现测试数的增加,成功修复的问题数量逐步提升,但重现测试的可行性并未显著增加(除了从1到5个样本的提升)。这一现象可能是因为问题描述的模糊性,导致缺少足够的信息来验证问题是否已解决。
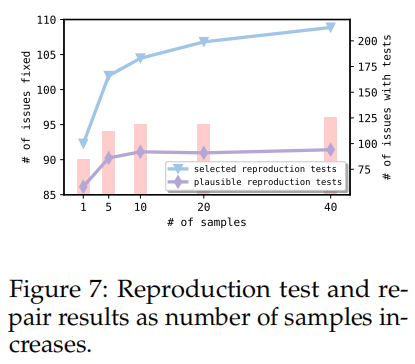
最终结果:
- 随着增加候选重现测试样本的数量,AGENTLESS修复了96个问题,显示出较高的性能上限。
Additional Analysis on SWE-bench Lite
6.1 Problem Classification
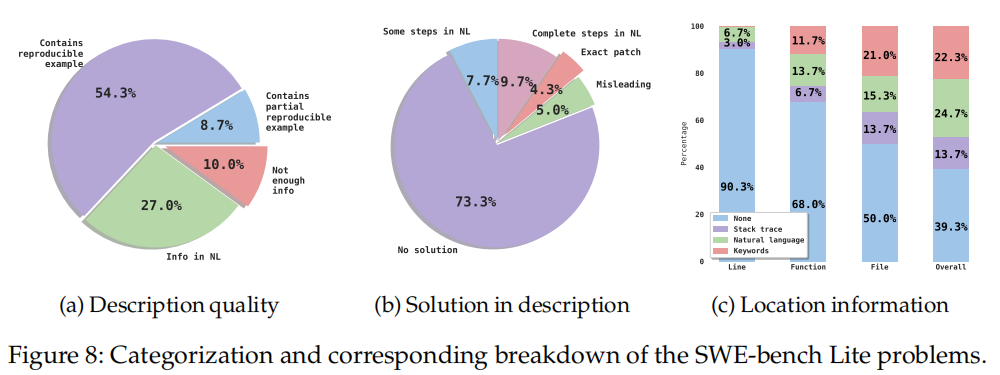
问题分类:
- 为了更好地理解SWE-bench Lite中的问题,AGENTLESS和其他方法的性能,进行了手动分类,基于问题描述和开发者补丁进行分析。
分类维度:
- 描述质量:
- 分类为:足够信息(如自然语言描述和可重现的失败示例)、部分可重现的示例、不足够信息(如问题要求特定名称的函数或错误消息)。约10%的问题缺少足够信息,这会导致测试失败,尽管功能可能实现正确。
- 描述中的解决方案:
- 分类为:无解决方案、部分解决方案、完整解决方案、精确补丁、误导性解决方案。发现4.3%的问题描述中包含了准确的补丁,9.7%提供了正确的解决步骤。但也有5.0%的问题描述提供了与开发者补丁不符的解决方案,可能导致错误的生成解决方案。
- 位置描述:
- 分类为:自然语言中提供精确位置、在失败堆栈中提供精确位置、提供相关关键字、未提供位置。仅少数问题提供精确的行号,但随着粒度增大(到函数和文件级别),大约一半的问题提供了文件级别的编辑位置。
潜在问题:
- SWE-bench Lite中存在无法解决的问题、误导性解决方案以及问题难度差异较大的情况,这些问题在基准创建和先前方法中未得到充分考虑。
总结:
- 这些分类为后续分析AGENTLESS和基准方法的修复性能提供了有用的见解,尤其是描述中提供的位置信息对修复结果的影响。
6.2 SWE-bench Lite-S
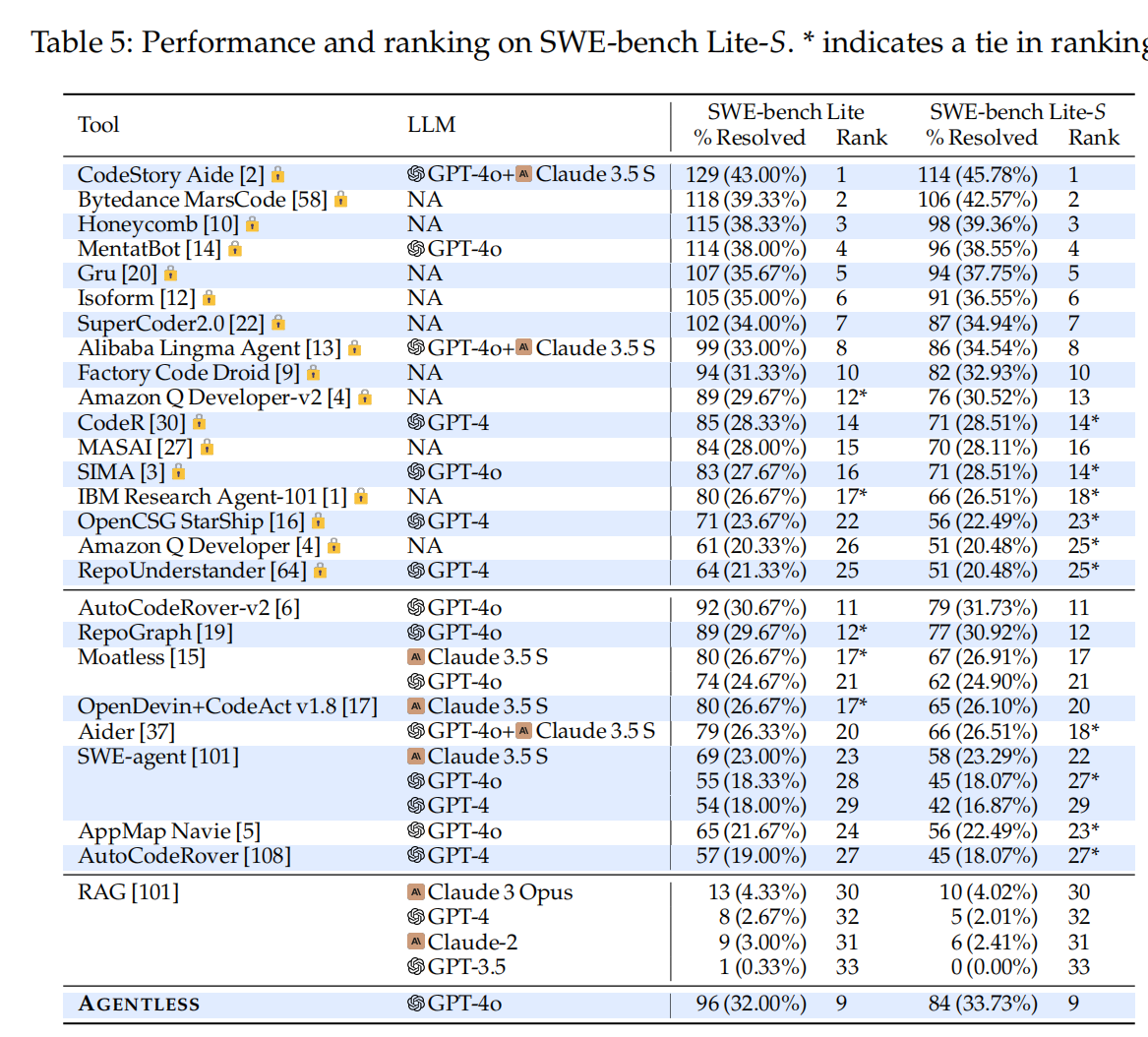
SWE-bench Lite-S的构建:
- 基于前述的问题分类,AGENTLESS和现有方法进行了更严格的比较。通过移除问题描述中已提供准确补丁、误导性解决方案或缺乏足够信息的问题,构建了一个包含249个问题的子集,称为SWE-bench Lite-S。这个子集规范了基准的难度级别。
- SWE-bench Lite-S相比于原始的SWE-bench Lite,提供了更准确的自动化软件开发工具能力反映。
SWE-bench Lite-S的评估:
- 表5展示了在SWE-bench Lite-S基准上的结果,并与原始300个问题的结果进行了比较。虽然所有方法的排名大体相同,但过滤后的SWE-bench Lite-S基准更准确地反映了工具的真实能力。
分类结果与工具表现:
- 可重现的代码示例:当问题描述中提供了可重现的代码示例时,所有先前方法的解决率下降。然而,AGENTLESS在这些问题上的表现仍然很高,因为它能更好地利用这些可重现的代码示例,这突显了测试生成阶段在补丁选择中的重要性。
- 问题描述中的解决方案:提供自然语言解决步骤的问题表现较好,AGENTLESS和其他方法在这类问题上有较好的表现。
- 位置线索:问题描述中提供的位置信息对解决率有显著影响。提供自然语言位置或堆栈跟踪的位置问题解决率较高。对于没有位置信息的问题,AGENTLESS和闭源方法相比,后者在没有位置线索的情况下表现更好,突显了代理工具在解决这些复杂问题中的优势。
总结与展望:
- AGENTLESS在解决包含可重现代码示例的问题时表现优异,但在没有位置信息的复杂问题中,代理工具显示了其优势。未来的工作可以进一步优化AGENTLESS,特别是在没有位置线索的复杂问题上的表现。
6.3 SWE-bench Verified
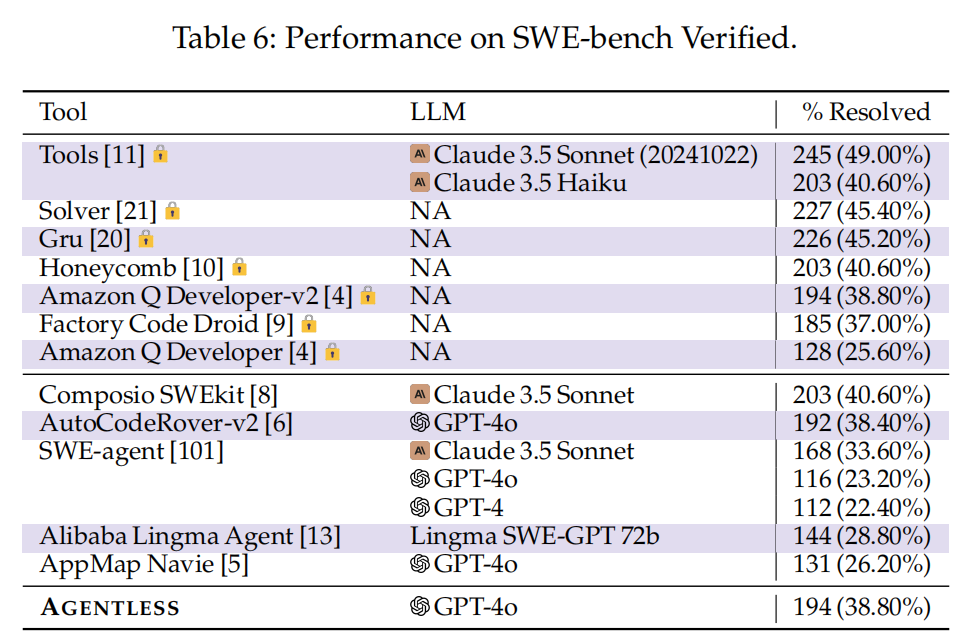
SWE-bench Verified数据集:
- 受6.1节的启发,OpenAI生成了经过人工开发者验证的新过滤数据集SWE-bench Verified,确保每个问题都包含足够的信息可以解决。
AGENTLESS在SWE-bench Verified的表现:
- 在SWE-bench Verified数据集上,AGENTLESS能够解决500个问题中的194个(38.80%),保持了强劲的表现。
- AGENTLESS在所有开源方法中排名第二,且表现优于许多闭源/商业方法。
AGENTLESS的优势:
- AGENTLESS在所有使用GPT-4o作为LLM的技术中表现最佳。
Threats to Validity
内部有效性威胁:
- 数据泄露问题:SWE-bench Lite中的ground truth开发者补丁可能被用作GPT-4o训练数据的一部分。由于GPT-4o是闭源模型,无法访问其训练数据。不过,先前的研究大多使用类似的闭源LLM(如GPT-4o、GPT-4、Claude-3.5等),AGENTLESS在相同模型下的表现优于所有开源解决方案。
- GPT-4的知识截止日期前后的比较研究表明,问题解决率没有显著差异。为了完全解决这一威胁,可能需要从头开始重新训练GPT-4o,但这对于学术项目来说是不可行的。
外部有效性威胁:
- 评估数据集:SWE-bench Lite是最流行的评估数据集,包含多种问题,但AGENTLESS的性能可能无法普遍适用于其他数据集。然而,OpenAI在多个基准(SWE-bench Lite、SWE-bench和SWE-bench Verified)上对AGENTLESS进行了独立评估,进一步确认AGENTLESS优于所有其他开源方法。
- 未来计划:为了进一步解决外部威胁,计划在其他基准上评估AGENTLESS的表现。