
Sequence-Oriented DBMS Fuzzing
Sequence-Oriented DBMS Fuzzing
ABSTRACT
SQL规范包括数百种语句类型,这给DBMS模糊测试带来了困难:现有的工作通常重复使用预定义类型的语句;这些有限的类型无法覆盖完整的输入空间,从而无法有效测试相应的逻辑。本文提出了一种名为LEGO的模糊测试器,旨在生成具有丰富类型的SQL序列,以提高DBMS模糊测试的覆盖率。序列生成的关键思想是类型亲和性,即SQL类型对(例如INSERT和SELECT)之间的有意义出现。在每次模糊测试迭代中,LEGO首先主动探索不同类型的SQL语句,并根据覆盖反馈分析类型亲和性。接下来,当发现新的亲和性时,LEGO会逐步合成包含这些类型的新SQL序列。
我们在PostgreSQL、MySQL、MariaDB和Comdb2上评估了LEGO,并与SQLancer、SQLsmith和SQUIRREL进行了对比。基于序列的模糊测试帮助LEGO在分支覆盖率上超越了其他模糊测试器,提升幅度为44%–198%。更重要的是,在持续的模糊测试过程中,LEGO发现了102个新漏洞,并得到了相关厂商的确认,其中包括6个PostgreSQL的漏洞、21个MySQL的漏洞、42个MariaDB的漏洞和33个Comdb2的漏洞。其中,22个漏洞因其严重的安全影响已被分配了CVE编号。
INTRODUCTION
Background
DBMS的重要性:
- 数据库管理系统(DBMS)对现代数据密集型系统至关重要。
- DBMS作为用户和数据库之间的中介,负责优化和管理数据的存储与检索。
DBMS的安全漏洞:
- 安全漏洞,尤其是内存漏洞(如缓冲区溢出),对DBMS特别危险,可能导致信息泄露、数据篡改、系统崩溃和重大损失。
现有研究的关注点:
- 现有研究主要集中在DBMS中的逻辑错误、性能问题和内存漏洞。
- 逻辑和性能错误的测试通常使用差异测试。
- 许多模糊测试方法专注于检测DBMS的内存漏洞,特别是生成有效的SQL查询。
SQL类型序列的关键作用:
- 生成的测试用例中包含的SQL类型序列对DBMS的模糊测试至关重要。
- 测试用例由一系列SQL语句组成,每个SQL语句都有特定的类型。
SQL类型的定义与分类:
- SQL语句有数百种类型,按功能分为不同类别,如SELECT和INSERT。
- SQL类型序列是测试用例中每个SQL语句类型的顺序。
SQL类型序列的重要性:
- SQL类型序列隐含了测试用例的语义特征,其丰富性对覆盖目标DBMS的功能至关重要。
- 特定DBMS逻辑的触发:
- 某些DBMS逻辑必须通过特定类型的语句触发,例如,仅测试SELECT语句无法触发INSERT语句的逻辑。
- 语句顺序的影响:
- 某些DBMS逻辑必须通过特定顺序的语句触发,如先创建表再插入数据才有意义,而先插入数据后创建表则会导致第一个语句无效。
SQL类型序列的丰富性:
- SQL类型序列的丰富性取决于语句类型的组合和排列。
Limitations and challenges
现有模糊测试的局限性:
- 现有的模糊测试工作主要关注生成有效的测试用例,忽视了丰富SQL类型序列。
- 模糊测试器一般分为基于生成的模糊测试器和基于变异的模糊测试器。
- 基于生成的模糊测试器:根据自定义规则生成测试用例,语句类型和序列之间的关系受限,导致覆盖面有限。 SQLSmith。
- 基于变异的模糊测试器:从输入池中选择测试用例(种子),通过变异生成新输入,如果触发新的代码区域,则将输入保存回池中。多数模糊测试器关注单个语句内部结构的变异,未能增加SQL类型序列的丰富性。 Squirrel。
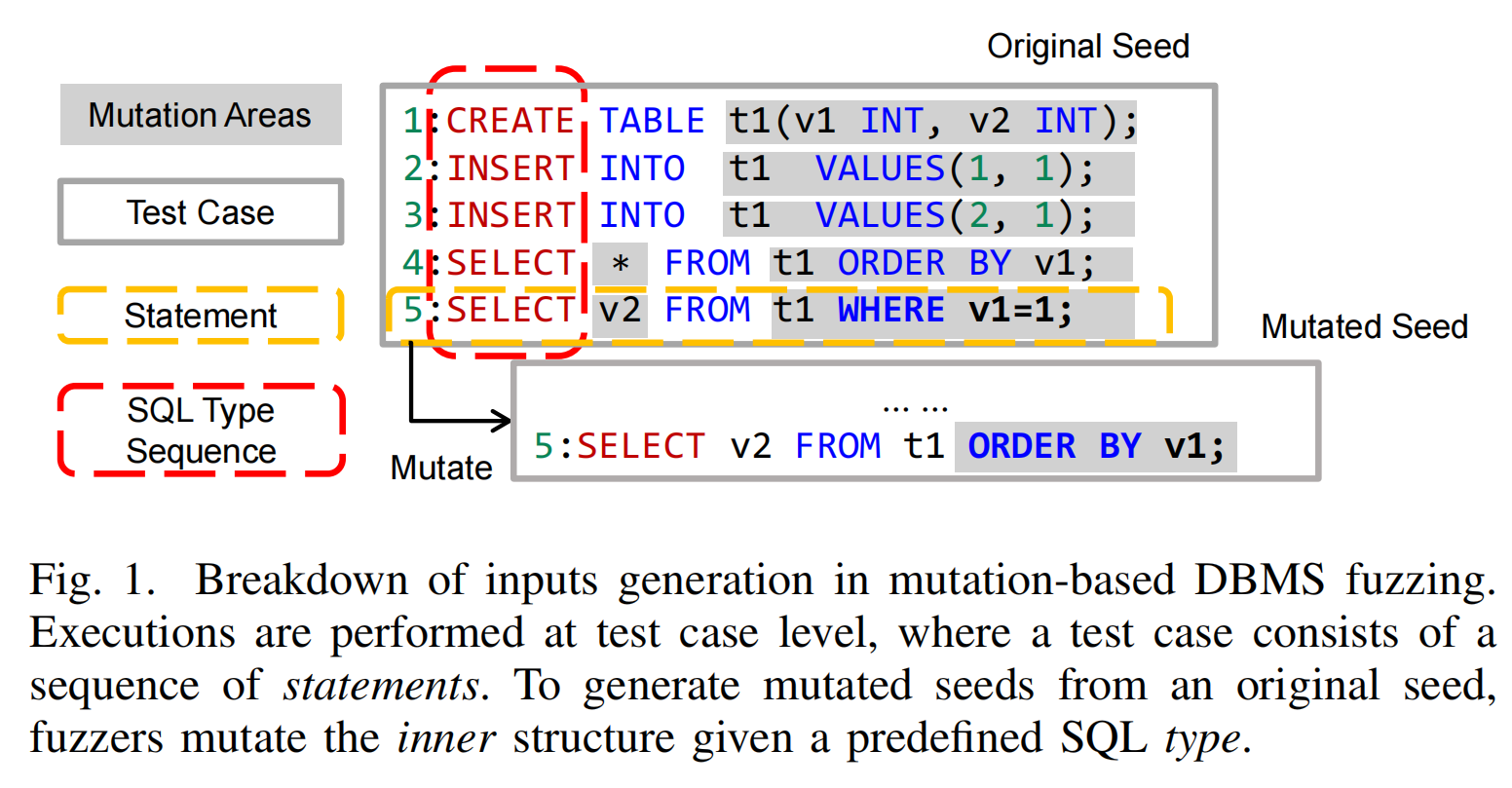
现有模糊测试器的局限性:
- 现有模糊测试器通常生成的SQL类型序列不会增加,无法探索完整的输入空间和覆盖目标DBMS中的逻辑。
- SQLsmith等生成器主要生成SELECT语句,限制了其探索的状态空间。
生成丰富SQL类型序列的挑战:
- 状态爆炸:DBMS通常有数百种SQL语句类型,尽管限定序列长度,可能的序列数量仍然极为庞大。例如,假设有100种语句类型,限制序列为5条语句时,可能的唯一序列将达到100亿。
- 低相关性序列:许多语句序列缺乏逻辑关联,可能不适用于有效测试。例如,一个创建触发器的语句与一个修改数据访问权限的语句之间亲和性低,组合后的序列对测试效果贡献较小。
- 不适合的测试用例:生成的SQL类型序列的测试用例可能过长且包含重复子序列,这会导致模糊测试器在处理时遇到困难。
Approach and evaluation
提出的方案:LEGO:
- LEGO旨在通过增加SQL类型序列的丰富性来提高DBMS模糊测试在发现内存安全漏洞方面的有效性。
- 关键概念是类型亲和性,即描述两个SQL语句类型之间的时间顺序关系。
LEGO的工作原理:
- LEGO采用逐步推进的方法,通过DBMS实现代码覆盖反馈指导的主动亲和性分析,探索类型亲和性。
- 在每次模糊测试迭代开始时,LEGO从现有测试用例中挑选一个,修改其中每个语句的类型,并通过覆盖分析来评估其重要性。若修改导致新的代码覆盖,则记录该亲和性。
- LEGO通过合成新序列来利用亲和性,进一步增加覆盖率。每当发现新的亲和性时,LEGO会对包含该亲和性的所有SQL类型序列进行排列组合,生成可执行的测试用例。
实验评估:
- LEGO在PostgreSQL、MySQL、MariaDB和Comdb2的最新版本上进行了评估,并与SQLancer、SQLsmith和SQUIRREL进行了对比。
- 基于序列的模糊测试使LEGO在分支覆盖率上分别比SQLancer、SQLsmith和SQUIRREL高出198%、44%和120%。
漏洞发现与贡献:
- 在持续模糊测试中,LEGO发现了102个新漏洞,而其他模糊测试器总共只发现了11个漏洞。
- 这些漏洞包括PostgreSQL的6个漏洞、MySQL的21个漏洞、MariaDB的42个漏洞和Comdb2的33个漏洞,其中22个漏洞已被确认并分配了CVE编号。
SQL TYPE SEQUENCE
Basic concepts.
数据库管理系统(DBMS):
- 管理数据库中数据存储和检索的软件。
结构化查询语言(SQL):
- 一种与DBMS交互的领域特定语言。
- 用于管理DBMS中的数据。
SQL语句:
- 输入到DBMS中的最小执行单元。
- 用于执行查询或更新数据等操作。
测试用例或查询:
- DBMS模糊测试器的输入对象。
- 由一系列SQL语句组成。
- 用于DBMS的测试,特别是基本操作如变异测试。
种子(Seeds):
- 测试用例的另一种说法。
- 作为DBMS模糊测试中的输入对象,用于操作的执行。
SQL statements types.
SQL语句类型:
- SQL语句有数百种类型,每种语句类型定义了对特定对象进行特定操作。
主要的SQL语句类型:
- 数据定义语言(DDL):如CREATE TABLE,用于定义数据库对象。
- 数据查询语言(DQL):如SELECT,用于查询数据。
- 数据操作语言(DML):如INSERT,用于操作数据。
- 数据控制语言(DCL):如GRANT,用于控制数据库权限。
事务相关语句:
- 如COMMIT,用于处理数据库中的事务操作。
Definition.
SQL语句类型序列(SQL Type Sequence):
- 是测试用例中每个SQL语句类型的序列,通过类型抽象出SQL语句的执行顺序。
示例:
- 测试用例Q1的SQL类型序列为:“CREATE TABLE → INSERT → INSERT → SELECT”。
- 测试用例Q2的SQL类型序列为:“CREATE TABLE → SELECT → INSERT → INSERT”。
区别:
- 虽然两个测试用例包含相同的SQL语句,但它们的SQL类型序列不同。
Importance of abundant SQL Type Sequences.
SQL类型序列的重要性:
- SQL类型序列隐含地表征了测试用例的语义,是进行充分DBMS模糊测试的关键。
SQL类型序列的丰富性:
- 序列中的类型丰富性是覆盖DBMS各类功能的前提。
- 即使SQL语句相同,执行顺序的不同也会覆盖不同的代码区域,从而影响测试结果。例如,Q1和Q2虽然有相同的SQL语句组合,但执行顺序不同,导致结果不同。
有助于模糊测试的丰富类型序列:
- 丰富的SQL类型序列与语句级结构和数据变异相结合,有助于更深度的模糊测试。
- 大多数现有DBMS模糊测试器擅长单个SQL语句的变异,但较少关注序列的变异。丰富的类型序列能增加探索的状态空间宽度,并通过细粒度变异进一步提升深度。
总结:
- 生成丰富的SQL类型序列有助于促进模糊测试器状态空间的探索,从而发现更多潜在的BUG。然而,生成丰富类型序列面临挑战。
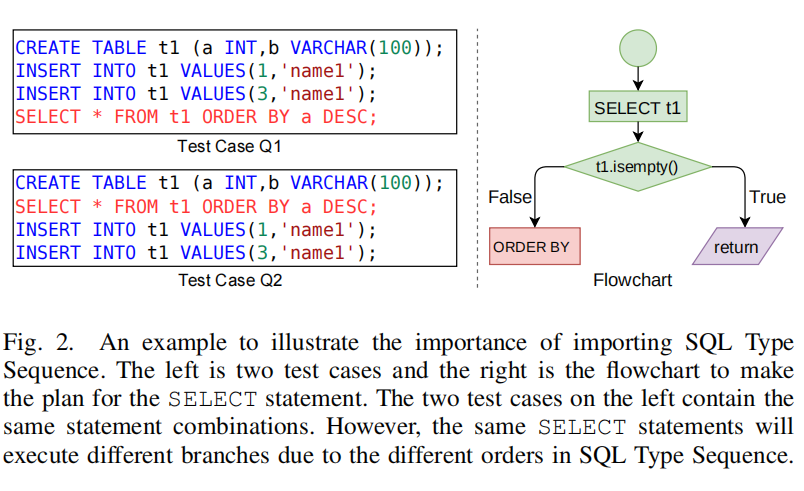
Challenge in generating abundant SQL Type Sequences.
- C1:SQL类型序列的状态空间巨大:
- 随机排列或列举所有可能的组合只能探索有限空间,导致状态爆炸。
- 例如,PostgreSQL有188种SQL语句类型,若测试用例包含20个语句,则所有可能的序列数量为$3 \times 10^{45}$。即使SQUIRREL每秒执行10到60个测试用例,也需要超过$10^{35}$年才能执行所有可能的SQL类型序列。
- C2:许多SQL类型序列没有意义:
- 列举所有序列或随机排列可能生成没有意义的SQL类型序列,无法增加丰富性。
- 无意义的表现为:
- 某些语句序列容易引起语义错误,导致覆盖面低。例如,执行
SELECT * FROM t2之前若没有创建表t2,会导致语义错误。 - 许多语句类型没有紧密关联,形成的序列不会覆盖新的逻辑,如创建表与更改数据访问权限的语句之间没有直接关系。
- 某些语句序列容易引起语义错误,导致覆盖面低。例如,执行
- C3:生成的SQL类型序列不适合模糊测试:
- 模糊测试需要大量执行生成的测试用例来寻找BUG,因此更倾向于高覆盖率且执行速度快的种子。
- 即使测试用例有丰富的SQL类型序列,可能仍不利于模糊测试。例如,SQUIRREL的测试种子包含945条SQL语句,重复调用多个类似的
INSERT语句,虽然增加了工作负载,但对覆盖面贡献不大,导致测试执行时间过长,甚至导致程序挂起。
Status of existing fuzzers.
现有模糊测试器的现状:
- 现有模糊测试器主要集中在生成语法和语义正确的种子,忽视了生成丰富的SQL类型序列。
两种主要的模糊测试方法:
- 生成型模糊测试器(如SQLsmith、SQLancer):
- 基于自定义规则生成种子。
- 为了应对挑战C1和C2,常通过手动添加大量规则来生成序列,但这种方法费时且丰富性有限。
- 为了应对C3,简化规则可以提高执行速度,但可能降低覆盖率。
- 变异型模糊测试器(如SQUIRREL、RATEL):
- 通过修改已有种子来变异种子,通常只改变单个语句的结构或数据,因此测试用例的序列和关系不会改变。
- Griffin是变异语句的顺序? 和 LEGO的区别是什么?
面临的挑战:
- C1和C2:生成有意义且丰富的SQL类型序列是技术难点,现有模糊测试器缺乏有效的解决方法。
- C3:现有方法包括选择执行快速的种子或根据覆盖率裁剪种子,但仍可能生成大型种子,导致测试卡住。
Basic Idea of LEGO
LEGO的基本思路:
- LEGO通过探索SQL类型空间,主动分析类型之间的关联性(type-affinity),并利用这些关联性生成高质量的测试用例,增加SQL类型序列的丰富性,并适合模糊测试。
解决挑战C1和C2:
- LEGO引入类型关联性(type-affinity)来抽象生成有意义SQL类型序列的问题。
- 类型关联性是相邻SQL语句类型之间的时间关系。LEGO通过类型关联性决定在现有语句后应连接哪些类型的语句,从而探索广泛的状态空间并确保生成有意义的序列。
- LEGO通过对现有测试用例进行序列化变异来探索新的类型关联性,并仅对覆盖新分支的种子进行关联性分析,以确保关联性有意义。
解决挑战C3:
- 为适应模糊测试并生成丰富的序列,LEGO限制最大序列长度,同时使用序列合成来适应不同的序列长度。
- 尽管某些BUG只能通过长时间重复的SQL序列触发,但处理这些序列可能会降低模糊测试器的性能,甚至导致卡死。
Motivation Example

SQL类型序列表示:
- LEGO使用1到6的数字表示不同的SQL语句类型:
- 1:
DROP TABLE - 2:
CREATE TABLE - 3:
INSERT - 4:
SELECT - 5:
CREATE TRIGGER - 6:
ALTER SYSTEM
- 1:
- 图中展示的原始测试用例较长,但为了简化,仅显示了其中的一部分。
关联性分析:
- LEGO分析测试用例中的SQL类型序列,提取出类型关联性。类型关联性是指SQL语句类型之间的关系,它们通常会一起出现在序列中。
- 例如,在第8到第11行之间,子序列是“1 → 2 → 3 → 6”(即
DROP TABLE → CREATE TABLE → INSERT → ALTER SYSTEM),而在第231到第234行之间,子序列是“4 → 3 → 5 → 4”(即SELECT → INSERT → CREATE TRIGGER → SELECT)。
新类型关联性的发现:
- LEGO发现了一个新的类型关联性:“
INSERT语句后可以跟随CREATE TRIGGER语句”(即3 → 5)。这种SQL语句类型之间的关系被认为是一个有用的序列,值得进一步探索。
序列合成:
- 基于新的类型关联性,LEGO合成新的SQL类型序列。这些序列通常较短,SQL结构简单,但包含丰富的SQL类型。
- 新生成的序列可能覆盖新的代码路径或直接触发崩溃。例如,合成的测试用例“2 → 3 → 5 → 4”(即
CREATE TABLE → INSERT → CREATE TRIGGER → SELECT)比原始测试用例要短,但覆盖了不同的类型,可能触发崩溃。
触发崩溃:
- 最终,新的合成测试用例触发了MySQL服务器的崩溃。通过生成和执行像这样的种子,LEGO帮助模糊测试器更高效地探索状态空间,发现潜在的BUG。
DESIGN OF LEGO
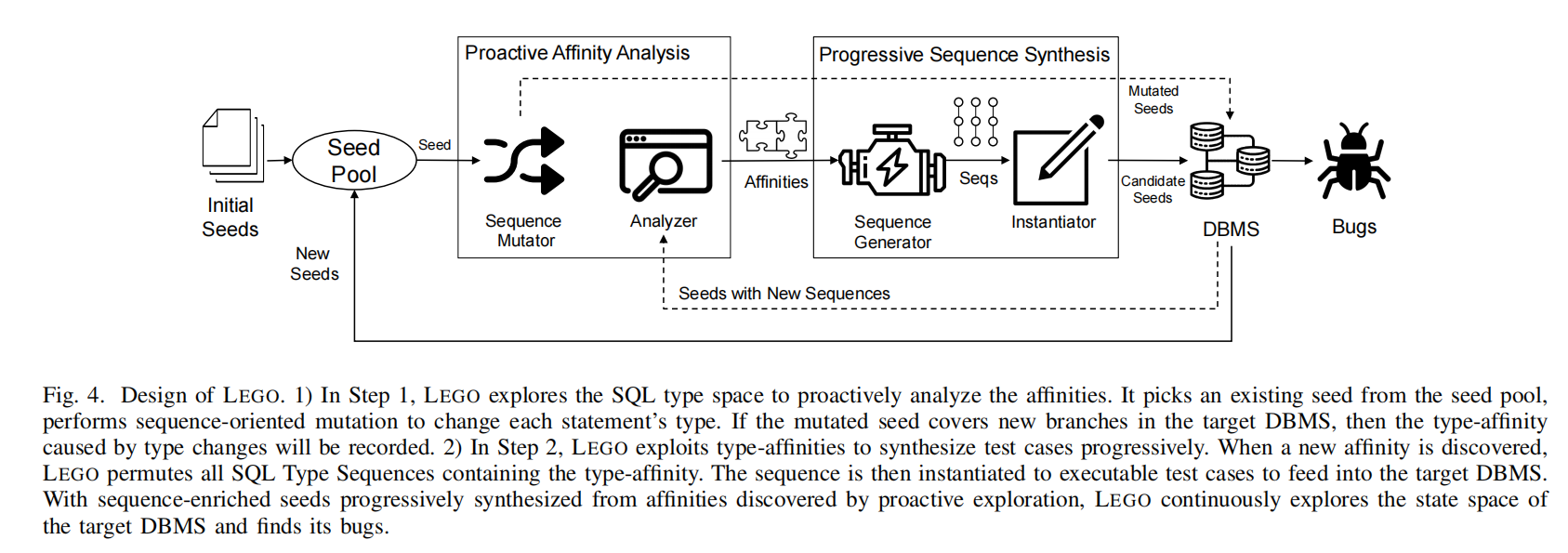
步骤1:主动关联性分析(Proactive Affinity Analysis)
- Seed Pool(种子池):首先,LEGO从种子池中选择一个现有的种子。种子是测试用例的起始SQL语句集合。
- Sequence Mutator(序列变异器):LEGO执行基于序列的变异操作,改变每个语句的类型。如果变异后的种子能够覆盖目标DBMS中的新分支(即新代码路径),则记录产生的类型关联性(type-affinity)。
- Analyzer(分析器):分析变异后的SQL类型序列,提取类型关联性(affinities),这些关联性表示了哪些SQL类型序列经常一起出现。
步骤2:渐进式序列合成(Progressive Sequence Synthesis)
- Sequence Generator(序列生成器):在发现类型关联性后,LEGO生成所有包含这些类型关联性的SQL类型序列。
- Instantiator(实例化器):将生成的SQL类型序列实例化为可执行的测试用例,并准备将这些测试用例输入到DBMS中。
- Candidate Seeds(候选种子):生成的种子包含了新的SQL类型序列,并作为候选种子被进一步测试。
- DBMS:将这些候选种子输入到目标DBMS中进行执行。
- Bugs(错误):如果输入的测试用例触发了错误或崩溃,LEGO就能发现这些BUG,并进一步探索DBMS的状态空间。
A. Proactive Affinity Analysis
生成丰富的SQL类型序列可以提升DBMS模糊测试的效果,但随机排列或组合不同类型的语句往往无法形成有意义的序列,同时可能导致状态空间过大。LEGO通过主动生成新序列,利用基于序列的变异操作解决这一问题。
1) Type-Affinity
类型关联性(Type-Affinity):
- 定义:在测试用例中,SQL语句的类型序列通常具有一定的模式。例如,“CREATE TABLE → INSERT → SELECT”是一种常见模式,用于创建、更新和查询数据。类型关联性描述了相邻语句类型之间的时间关系,表示某种类型的语句可能紧跟另一种类型的语句。例如,如果
INSERT语句紧跟在CREATE TABLE语句之后,则认为INSERT与CREATE TABLE之间存在类型关联性。 - 表示:用部分有序的元组
(type1, type2)表示这种关系,表示type1可以被type2跟随。
2) Proactive Sequence-Oriented Mutation
主动序列变异(Proactive Sequence-Oriented Mutation):
- LEGO通过序列变异探索SQL类型序列的状态空间,以生成不同于当前测试用例的SQL类型序列。LEGO采用覆盖引导的模糊测试原则,即通过反馈的覆盖信息逐步探索程序状态空间。当变异后的SQL类型序列发现新的分支时,认为该序列是有意义的,并记录下由此产生的类型关联性供进一步合成序列使用。
- 如果生成的序列没有覆盖新分支,则认为该序列对扩展覆盖面没有帮助,将被丢弃。

这个算法(Algorithm 1)展示了LEGO的基于序列的变异过程。以下是对每个步骤的解释:
输入:
- 输入种子(Q):原始测试用例,包含一系列SQL语句。
- 类型关联性(T):在种子中已经分析出的SQL类型序列之间的关联关系。
- 目标DBMS(D):要执行和测试的数据库管理系统。
过程:
算法通过三种不同的变异方法(替换、插入和删除)逐一处理输入种子中的每个SQL语句(statement)。
- 替换(Substitution):
- 对当前语句进行变异,替换成一个新的语句。
- 步骤:首先随机选择一个不同的语句类型,并实例化它以替换当前的语句。然后,通过分析依赖关系来修复可能出现的语义错误,类似SQUIRREL的处理方法,填充SQL数据。
- 类型变化:类型的变化会导致SQL类型序列的变化。如果变异后的种子触发了新的代码分支(即覆盖了新的状态),则保留该种子并分析其类型关联性。
- 插入(Insertion):
- 在当前语句后面插入一个新的SQL语句。
- 步骤:随机选择一个SQL语句类型,实例化它作为新的语句插入到当前语句之后。同样,需要修复可能的语义错误。
- 类型关联性:如果变异后的种子覆盖了新的代码分支,则保留该种子并记录其类型关联性。
- 删除(Deletion):
- 删除当前的SQL语句,从而生成一个新的测试用例。
- 步骤:删除语句后,生成的测试用例会进行验证,并用实际数据填充。
- 类型关联性:如果删除操作导致新的代码分支被覆盖,LEGO会分析删除操作引入的类型关联性。
总结:
- 该算法通过三种变异方式(替换、插入和删除)变异SQL语句,并在每次变异后检查是否覆盖了新的代码分支。如果覆盖了新的分支,变异后的种子会被保存,并且相关的类型关联性会被分析和记录。
- 这样,LEGO能够在庞大的SQL类型序列状态空间中寻找有意义的序列,并帮助模糊测试器更有效地发现潜在的BUG。

原始种子(Original Seed):
- 原始的SQL测试用例包含5个语句,SQL类型序列为:“CREATE TABLE → INSERT → INSERT → UPDATE → SELECT”。
替换(Substitution):
- 在变异过程中,假设我们将第4个语句(UPDATE)替换为一个DELETE语句。
- 变异后的SQL类型序列变为:“CREATE TABLE → INSERT → INSERT → DELETE → SELECT”。
- 通过这次变异,生成了两个新的类型关联性:
- “INSERT → DELETE”
- “DELETE → SELECT”
- 这些新的类型关联性帮助我们识别了更有意义的SQL语句组合。
插入(Insertion):
- 接下来,在第4个语句后插入一个DELETE语句。
- 变异后的SQL类型序列变为:“CREATE TABLE → INSERT → INSERT → UPDATE → DELETE → SELECT”。
- 插入操作生成了两个新的类型关联性:
- “UPDATE → DELETE”
- “DELETE → SELECT”
删除(Deletion):
- 最后,删除第4个语句(UPDATE)。
- 变异后的SQL类型序列变为:“CREATE TABLE → INSERT → INSERT → SELECT”。
- 删除操作创建了一个新的类型关联性:
- “INSERT → SELECT”
3) Type-Affinity Analysis
类型关联性分析(Type-Affinity Analysis):
- 类型关联性帮助我们抽象不同SQL语句组合的原则,通过分析这些关联性,我们可以列出SQL语句类型的新排列组合,从而生成丰富且有意义的SQL类型序列。
序列变异:
- 基于类型关联性,序列变异主动探索各种可能的SQL类型序列,生成不同的测试用例。
提取类型关联性:
- 提取测试用例的类型关联性,首先需要准确识别语句的SQL类型。由于DBMS可能有多种或独特的语句类型,识别这些类型是一个挑战。
- 例如,PostgreSQL定义了188种SQL语句类型、1025个关键词和349个子句类型(如表达式和“WITH”子句)。
解决方案:
- 使用抽象语法树(AST)模型来准确识别SQL语句类型,该模型基于DBMS的语法规范构建,支持识别所有语句类型和其他结构。

Algorithm 2)展示了类型关联性分析的过程。以下是对该算法的详细解释:
输入:
- **Test case (Q)**:测试用例,包含一系列SQL语句。
- **Type-affinity map (T)**:类型关联性映射,一个字典,键是SQL语句的类型,值是一个集合,表示可以紧跟在该类型后面的其他类型。
过程:
- 初始化:
lastType用于记录上一个语句的类型,初始值为NULL。
- 遍历测试用例中的每个语句:
- 对于测试用例中的每个SQL语句,首先通过
parse(s)获取当前语句的类型并保存在currentType中(第3行)。
- 对于测试用例中的每个SQL语句,首先通过
- 检查当前语句的类型与上一个语句类型是否相同:
- 如果
lastType != NULL,即之前已经有语句类型记录过,并且当前语句的类型与上一个语句类型相同(第5行),则跳过当前语句(第6-7行)。这避免了相同类型的连续语句对SQL类型序列的贡献有限。
- 如果
- 记录类型关联性:
- 如果
lastType不在类型关联性映射T中(即之前没有记录该类型),则为该类型创建一个新的集合(第8行),并将其加入映射T(第9行)。 - 将当前语句的类型(
currentType)加入到lastType对应的集合中,表示lastType → currentType这种类型关联性(第12行)。
- 如果
- 更新:
- 完成当前语句处理后,更新
lastType为当前的currentType,并继续处理下一个SQL语句(第14行)。
- 完成当前语句处理后,更新
- 结束:
- 经过所有语句处理后,
T中将记录所有在测试用例中出现的类型关联性。
- 经过所有语句处理后,
总结:
- 该算法的目标是分析测试用例中的类型关联性。它遍历每个SQL语句,识别相邻语句类型之间的关系,并记录这些关联性。
- 最终,生成的类型关联性映射
T能够帮助识别哪些SQL语句类型常常一起出现,从而为生成丰富的SQL类型序列提供支持。
B. Progressive Sequence Synthesis
分析出的类型关联性为合成丰富且有意义的SQL类型序列提供了可能性。LEGO从特定的起始语句类型(如CREATE TABLE)开始,逐步合成所有可能的、长度不超过指定值的SQL类型序列。
合成过程:
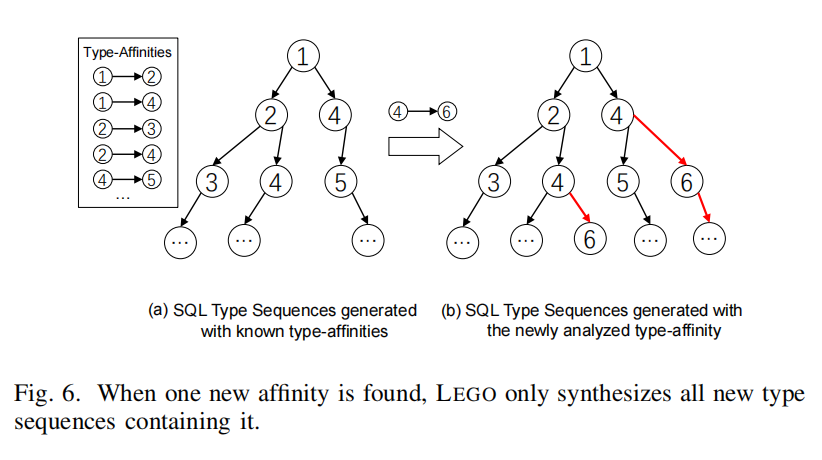
- 在图6(a)中,假设根节点表示一个起始类型,每条从根节点到其他节点的路径代表一个SQL类型序列。LEGO根据分析得到的类型关联性合成所有SQL类型序列,并将这些序列实例化为测试用例,以探索目标DBMS的状态空间。
新类型关联性的发现:
- 当新的类型关联性(如“4 → 6”)被发现时,LEGO不会重新合成所有SQL类型序列,而是只合成包含此新关联性的序列(如图6(b)中的红色箭头部分)。
前缀序列(Prefix Sequence)数据结构:
- 为了实现渐进式合成,设计了一种数据结构——前缀序列,用于记录所有已生成的、指定长度且以某个SQL语句类型结尾的序列。
- 具体而言,使用向量S存储所有已生成的、长度不超过LEN的序列。前缀序列是一个映射,键为一对(
τ,λ),值为一个向量,存储所有以类型τ结尾且长度为λ的序列的索引。 - 当LEGO发现新类型关联性
t1 → t2时,它将根据前缀序列查找所有以t1结尾且长度小于LEN的序列,然后合成所有包含此新类型关联性的序列。

这个算法(Algorithm 3)展示了当发现新的类型关联性(t1 → t2)时,如何合成新的SQL类型序列。以下是该算法的详细解释:
输入:
- LEN:目标序列的最大长度。
- t1 → t2:新发现的类型关联性,表示某类型语句(t1)后可以跟随另一类型语句(t2)。
- PS:前缀序列,用于记录已生成的序列。
- T:类型关联性映射,存储各个SQL类型及其可接续的类型。
- S:生成的序列向量,存储所有已合成的序列。
过程:
- 初始化:
- 遍历所有可能的序列长度,从1到LEN-1(第1行)。
- 查找前缀序列:
- 对于当前长度
level,从前缀序列中查找以t1结尾的所有序列(第2行)。 - 如果没有找到,则继续检查下一个长度(第3-5行)。
- 对于当前长度
- 合成新序列:
- 如果找到了以
t1结尾的前缀序列seq,则在每个序列后加上t2,并将序列seq的克隆版本添加到S中(第6-9行)。 - 同时,将生成的序列索引记录到前缀序列
PS中(第10行)。
- 如果找到了以
- 递归合成所有可能的序列:
- 使用递归函数
listSeq,以seq为基础,生成所有可能的SQL类型序列(第11行)。 listSeq函数(第14-25行)通过当前语句类型和所有类型关联性,逐步合成所有可能的下一个类型,并记录每个生成的序列。- 一旦生成的序列长度达到目标长度
LEN,算法就会返回,继续尝试下一个组合。
- 使用递归函数
- 例子:
- 假设目标序列的长度为2,当前序列为“CREATE TABLE”,类型关联性为“CREATE TABLE → [INSERT, SELECT]”,则生成的所有长度为2的序列为:“CREATE TABLE, INSERT”和“CREATE TABLE, SELECT”。
总结:
- 该算法通过逐步合成新的SQL类型序列,利用类型关联性
t1 → t2,确保所有可能的、符合要求的序列都被生成。生成的序列将被保存在序列向量S中,并通过递归方法合成所有可能的序列组合。
如何确保语义正确性?
目标:
- LEGO通过实例化SQL类型序列生成可执行的测试用例,面临的挑战是如何确保从类型生成的SQL语句在语法和语义上都正确。
解决方案:
- 抽象语法树(AST):LEGO使用AST作为测试用例和类型之间的中间表示。在实例化过程中,分析并维护语句之间的依赖关系。
实例化过程:
- 步骤一:AST合成:当发现新种子时,LEGO解析每个语句,提取AST结构并保存到全局库中。在实例化时,为每个SQL类型序列的条目随机选择一个类型匹配的结构,构建AST。
- 步骤二:语句连接:LEGO将每个AST条目翻译为SQL语句,并将它们连接成候选SQL测试用例。
- 步骤三:验证:候选测试用例被重新翻译为AST,分析不同数据之间的依赖关系,并填充满足所有依赖关系的具体值。然后,将AST转换为可执行的测试用例并提交给目标DBMS。
多次实例化:
- 由于随机选择结构,一个SQL类型序列会被多次实例化,从而增加AST结构和类型序列组合的多样性。
示例:
- 对于“PRAGMA → CREATE TABLE → INSERT”序列,LEGO首先构建SQL语句框架并随机实例化数据,但可能包含语义错误,如表v2不存在。然后,LEGO通过构建数据依赖图修复这些错误,最终生成正确的测试用例:“PRAGMA foreign keys=ON; CREATE TABLE v0(x INT PRIMARY KEY, y INT REFERENCE); INSERT INTO v0(x) VALUES(100);”。
IMPLEMENTATION
- 实现基础:
- LEGO基于AFL++实现,包含两个主要组件:**类型关联性分析器(Affinity Analyzer)**和**序列合成器(Sequence Synthesizer)**。
- 类型关联性分析器实现了算法1和2,用于分析并记录新的类型关联性。
- 序列合成器实现了算法3,用于合成新的SQL类型序列。
- LEGO将这两个组件作为AFL++的自定义变异器(mutator)集成。
- 支持组件:
- AST解析器(AST Parser):为类型关联性分析器和序列合成器提供支持,使用SQUIRREL定义的中间表示(IR)。AST解析器基于Bison 3.3.2和Flex 2.6.4实现,确保支持最新DBMS的特性和方言。
- 数据库支持:
- 对MariaDB和MySQL的解析器使用了748个Flex令牌定义、852个声明和2855个规则;对PostgreSQL和Comdb2使用了494个、695个声明和3179个规则等。
- 适应性与转换:
- 为了适应DBMS,LEGO还编写了逻辑来将这些新规则转换为IR,并能够将IR转换回SQL语句。
- LEGO使用AFL++的持久模式编写了特定DBMS的模糊测试驱动程序。
EVALUATION
我们评估了LEGO在发现新漏洞以及在探索目标DBMS状态空间方面的效率。评估的目的是回答以下研究问题:
- RQ1:LEGO能否发现新的漏洞?
- RQ2:LEGO是否优于其他先进的DBMS模糊测试工具?
- RQ3:基于序列的算法效果如何?
A. Evaluation Setup
- 测试的DBMS和对比的模糊测试器:
- 为评估LEGO的通用性和效率,使用了四个流行的开源DBMS:PostgreSQL、MySQL、MariaDB和Comdb2,涵盖了广泛应用于工业和学术研究的数据库系统。
- 将LEGO与其他流行的模糊测试器进行对比,包括来自学术界的SQUIRREL和SQLancer,以及来自工业界的SQLsmith。
- 基本设置:
- 实验在一台运行64位Ubuntu 20.04的机器上进行,配备128个核心(AMD EPYC 7742处理器,2.25 GHz)和488 GiB内存。
- 所有DBMS都使用了AddressSanitizer(ASAN)进行检测。每个模糊测试器使用其默认配置。
- 每个DBMS与一个模糊测试器一起运行24小时,以进行全面对比。每个模糊测试器实例单独在docker中运行,并使用一个CPU核心。
- 兼容性问题:
- 由于SQLsmith未官方支持MySQL、MariaDB和Comdb2的语法,实验仅在PostgreSQL上将LEGO与SQLsmith进行对比。
- 错误识别与分析:
- 通过比较调用栈,区分不同的BUG。为了提高准确性,还进行了手动分析。
B. DBMS Vulnerability Detection
- 总体结果:
- 四个测试的DBMS广泛使用且已被工程师广泛测试,发现新漏洞较为困难。尽管如此,LEGO在连续模糊测试中检测到102个漏洞,而其他工具总共只发现了11个漏洞。具体来说,SQLancer和SQLsmith没有发现任何漏洞,SQUIRREL在MySQL中发现了3个漏洞,在MariaDB中发现了8个漏洞。
- LEGO分别在PostgreSQL、MySQL、MariaDB和Comdb2中发现了6、21、42和33个漏洞。
- 漏洞详情:
- 在102个漏洞中,有61个是高危漏洞,包括17个缓冲区溢出、7个释放后使用、29个段错误和8个使用后污染漏洞,这些漏洞可以被攻击者远程利用,导致任意代码执行、系统控制或权限提升。
- 还有6个空指针解引用、13个断言失败和22个未定义行为,表明DBMS内部错误,可能导致拒绝服务或其他意外损害。
- 漏洞报告与确认:
- 所有漏洞已报告给相应的DBMS供应商并获得确认反馈。在撰写论文时,22个漏洞已在美国国家漏洞数据库(NVD)中确认,并成为CVE。根据CVSS评分,其中8个CVE被标记为高风险,8个为中风险,6个由于其高危性和复杂性按供应商要求被保留(尚未公开且未评分)。
- 总结:
- 结果表明,基于序列的模糊测试有助于LEGO探索DBMS中的意外状态,这些状态可能导致严重的漏洞。通过分析漏洞,发现许多漏洞与意外的SQL类型序列相关。

漏洞为何仅被LEGO检测到:
- 该漏洞是由一个意外的SQL类型序列引发的,这种序列测试者很少使用,因此漏洞长期未被发现。
- LEGO通过分析类型关联性,合成包含预期序列的丰富SQL类型序列。基于合成种子的类型序列,LEGO有效地变异这些种子,最终合成出特定的测试用例来触发该漏洞。
- 其他模糊测试器难以构建特定的SQL类型序列,因此无法发现这个漏洞。具体而言:
- SQLsmith主要生成
SELECT语句,忽略了由不同类型的SQL语句组成的漏洞。 - SQLancer基于自定义规则生成测试用例,主要针对
SELECT语句,能够生成的SQL类型序列有限。 - SQUIRREL通过改变单个语句的结构或数据生成测试用例,难以生成新的SQL类型序列,无法覆盖现有种子中未包含的序列。因此,包含新SQL类型序列的漏洞未被它们发现。
- SQLsmith主要生成
C. Comparison with Other DBMS Fuzzers
评估标准:
- 使用覆盖的分支和触发的漏洞两个指标来评估模糊测试器的表现。评估时,比较了LEGO与SQLancer、SQLsmith和SQUIRREL的效果。
覆盖率:
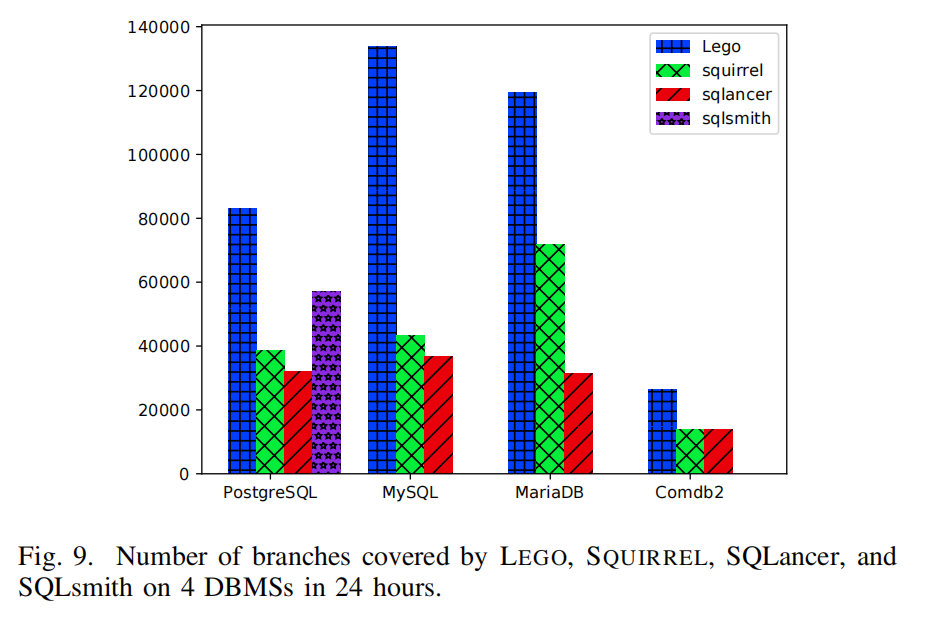
- 图9显示了24小时模糊测试中不同模糊测试器覆盖的分支数量。结果表明,LEGO在覆盖率上表现优异,分别比SQLancer、SQLsmith和SQUIRREL多覆盖了198%、44%和120%的分支。
- LEGO的优势在于它生成丰富的SQL类型序列,能够敏感地反映SQL语句的执行顺序,从而覆盖更多的代码区域并触发隐藏的漏洞。相比之下,SQLancer和SQLsmith生成的SQL类型序列有限,难以覆盖所有代码区域。
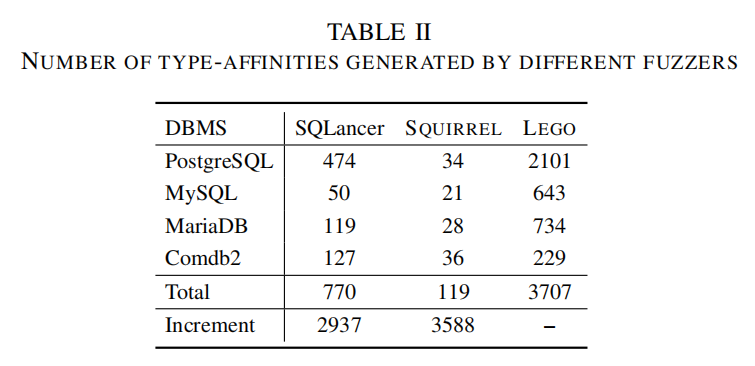
类型关联性:
- 表II显示了不同模糊测试器生成的种子在24小时内包含的类型关联性。LEGO通过主动探索类型序列空间并分析变异种子中的新关联性,生成更多有意义的序列,从而提高了SQL类型序列的丰富性,进而提高了覆盖率。
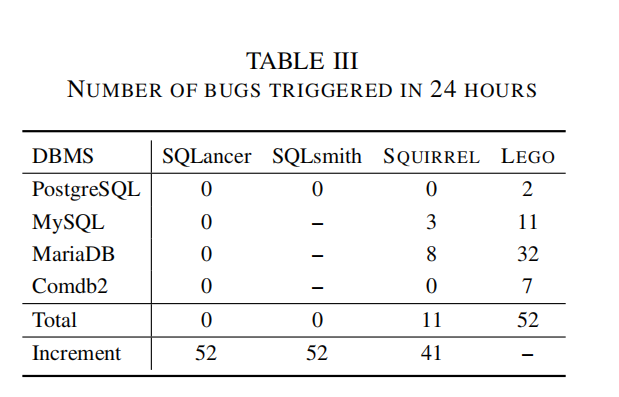
漏洞检测:
- 表III显示了每个模糊测试器发现的漏洞数量。LEGO分别比SQLancer、SQLsmith和SQUIRREL多发现了52、52和41个漏洞。
- SQLancer主要检测逻辑漏洞,但由于预定义规则的限制,它未能触发最新版本DBMS中的漏洞。SQLsmith生成的语句类型有限,尤其是
SELECT语句,虽然确保了语法正确性,但未能在PostgreSQL的最新版本中发现漏洞。 - LEGO通过更广泛的状态空间探索发现了更多漏洞,且很多漏洞是由意外的SQL类型序列引发的。LEGO通过分析有意义的测试用例中的类型关联性,合成丰富的SQL类型序列,从而发现了更多漏洞。
D. Effectiveness of Sequence-Oriented Algorithms in LEGO
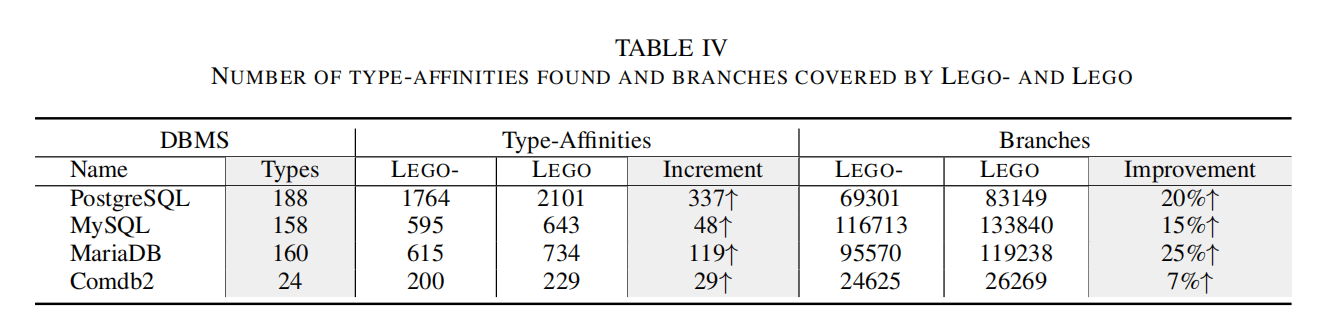
为了评估序列导向模糊测试算法的有效性,并排除其他因素的干扰(如AST解析器的扩展),我们实现了一个对比版本**LEGO-**,禁用了序列导向算法,包括主动的类型关联性分析和渐进的序列合成。然后,我们将LEGO与LEGO-在PostgreSQL、MySQL、MariaDB和Comdb2上进行了24小时对比。
- 类型关联性的发现:
- LEGO能发现比LEGO-更多的类型关联性。具体来说,LEGO在PostgreSQL、MySQL、MariaDB和Comdb2上分别比LEGO多发现337、48、119和29个类型关联性。
- 禁用序列导向算法后,LEGO-的常规变异方法仅限于改变测试用例中的单个语句,而LEGO通过主动探索类型关联性来增加SQL类型序列的丰富性,从而发现更多类型关联性。
- 分支覆盖率:
- 由于发现更多类型关联性,LEGO能够在四个DBMS上覆盖更多的分支。具体来说,LEGO在PostgreSQL、MySQL、MariaDB和Comdb2上分别比LEGO多覆盖20%、15%、25%和7%的分支。
- 更多的类型关联性帮助LEGO合成更多有意义的SQL类型序列,增加了序列的丰富性,从而触发了更多的DBMS功能,导致覆盖更多分支。
- 类型关联性与分支覆盖率的关系:
- 结果表明,DBMS的语句类型越多,LEGO在发现类型关联性和覆盖分支方面的改进也越大。具体来说,当一个DBMS具有更多的语句类型时,LEGO能够发现更多的类型关联性,从而提高覆盖率。
- 例如,LEGO在PostgreSQL上比LEGO多发现337个类型关联性,并且在分支覆盖率上提高了20%。对于Comdb2,由于其语句类型较少,LEGO的改进较小,但依然在类型关联性和分支覆盖率上有所提升。
总结:
- 序列导向算法显著提高了LEGO在发现类型关联性和覆盖分支方面的表现,尤其是在语句类型较多的DBMS中,LEGO比LEGO-取得了更大的改进。
DISCUSSION
冗余类型关联性:
- 在主动的类型关联性分析中,除了SQL类型的变化外,数据的变化或非相邻SQL语句的组合可能会触发新的覆盖并产生冗余的类型关联性。尽管如此,这对LEGO的影响有限。LEGO通过逐步合成包含新类型关联性的序列来避免冗余关联性浪费过多资源。对于非相邻SQL语句的组合产生的冗余关联性,LEGO可以通过传递关系学习到,例如,如果
A→B和B→C被发现,LEGO也能推断出A→B→C。
合成测试用例的语义丰富性:
- LEGO在合成过程中通过解析AST结构并与SQL类型序列结合,重构了语义信息。然而,某些语义信息仍可能丢失。未来计划自动学习语义信息(如语句间的依赖关系)并用来指导序列合成。
限制序列长度可能错过一些漏洞:
- 一些漏洞只能通过长时间重复的序列触发,但处理这些长序列可能导致性能下降或使模糊测试器挂起。为了平衡,LEGO限制了序列长度。在对MariaDB进行的实验中,LEGO在不同长度设置下分别找到了30、35和27个漏洞,表明过短或过长的序列都会错过一些漏洞。未来计划将长序列拆分为多个等效的短序列,以检测这类漏洞。
LEGO的适应性:
- LEGO的方案适用于大多数DBMS。要适应新DBMS,LEGO需要学习该DBMS特定的SQL类型信息,这可以通过提供原始语法规范来实现。LEGO将自动从语法规范中推导SQL类型信息,并重用现有的类型关联性基础设施。然而,语句类型的数量会影响LEGO的性能。例如,LEGO在Comdb2上的改进较小,未来计划通过增加合成序列的多样性来解决这一问题。
扩展现有模糊测试器的可行性:
- 直接将LEGO的解决方案简单地应用到现有模糊测试器上并不容易。可以通过使用LEGO发现的类型关联性来扩展现有模糊测试器。对于基于生成的模糊测试器,可以添加LEGO的类型关联性转化规则;对于基于变异的模糊测试器,可以在LEGO类型关联性的指导下添加变异操作符。然而,现有工作如果没有LEGO的结果,则需要重新实现LEGO的逻辑来有效增加丰富性。