
Understanding and Detecting SQL Function Bugs
Understanding and Detecting SQL Function Bugs
- Using Simple Boundary Arguments to Trigger Hundreds of DBMS Bugs
Abstract
内置 SQL 函数在数据库管理系统(DBMS)中非常关键,支持各种操作和计算,跨多种数据类型,它们对于查询、数据转换和聚合至关重要。尽管内置 SQL 函数的重要性,但 SQL 函数中的错误已经在现实世界中引起了广泛的问题,从系统故障到任意代码执行。然而,对这些错误特征的理解有限。更重要的是,传统的函数测试方法难以生成语义正确的 SQL 测试用例,而数据库管理系统的测试工作难以对内置 SQL 函数进行评估。
本文介绍了对 318 个内置 SQL 函数错误的全面研究,阐明了这些错误的特征和根本原因。我们的调查发现,87.4% 的错误是由参数边界值的不当处理造成的。参数的边界值来自三个来源:字面值、类型转换和嵌套函数。通过研究这三个来源的错误,我们总结了十种引起错误的 SQL 查询模式。此外,我们还设计了一种基于这些模式的测试工具 SOFT,用于测试包括 PostgreSQL、MySQL 和 ClickHouse 在内的七种广泛使用的 DBMS。SOFT 发现了以前仅由少数 SQL 函数错误引起的错误。数据库供应商认真对待这些错误,并在三天内修复了 97 个错误。例如,ClickHouse 的首席技术官对其中一个错误评论道:“我们必须立即修复这个问题,否则就废除这个功能。”
INTRODUCTION
Built-in Function
定义与重要性:
- 内置 SQL 函数是数据库管理系统(DBMS)中预定义的函数,执行特定操作。
- 这些函数对于数据处理和操作至关重要,为不同类型的数据计算提供支持。
功能示例:
- 例如,ClickHouse 中的
toDecimalString函数可以将数值转换为具有指定位数的字符串表示形式。
问题与风险:
- 尽管内置 SQL 函数对DBMS的运行和灵活性非常重要,但它们的实现有时可能存在缺陷。
- 这些缺陷可能导致内存问题,进而引发系统崩溃、操作错误或未经授权的数据操作。
特定错误示例:
toDecimalString函数因实现错误可能导致空指针解引用,特别是当为SQL函数表达式传递精心构造的值时。

Built-in Function’s attributes
这段文字强调了内置 SQL 函数错误的三个特别属性,使其尤其难以处理:
- 广泛的影响:
- 内置 SQL 函数在数据库操作中扮演核心角色,错误可能在多个 SQL 语句中被反复触发。
- 错误不仅限于数据库本身,还可能影响依赖于特定函数的应用程序和数据库其他部分,引发系统级的问题。
- 严重性高:
- 这类错误可能导致数据库管理系统(DBMS)的重大威胁,如服务拒绝、未授权访问敏感内存区域,甚至任意代码执行。
- 这些漏洞容易被利用,攻击者可以通过提交特制输入来触发后端 DBMS 的潜在漏洞。
- 暴露的复杂性和困难:
- 内置 SQL 函数的设计复杂,管理多种数据类型和操作的逻辑错综复杂,使得错误难以被发现和隔离。
- 这些错误在标准测试程序中可能不会轻易复现或预料,发现和修复这些错误通常需要对多种用例和数据输入进行深入测试。
Challenges
内置 SQL 函数测试存在的挑战和局限性:
- 理解缺乏:
- 对内置 SQL 函数漏洞的特征理解有限,导致难以进行有效的测试和防御。
- 测试方法不足:
- 传统的编程语言测试方法(如单元测试)不适用于生成 SQL 函数的测试用例。
- 常规测试工具如 Randoop 和 EvoSuite 生成的是针对库函数的测试用例,不适合 SQL 函数,这是因为 SQL 函数的表达式通常涉及嵌套和特定格式的参数,与简单的函数调用序列不同。
- 现有 DBMS 测试工具的局限性:
- 专用于 DBMS 测试的工具,如 SQLsmith 和 SQUiRREL,也难以有效测试内置 SQL 函数。
- 这些工具主要生成复杂的 SQL 语法结构或操作序列来激活 DBMS 组件的更多行为,但往往忽略了函数表达式的生成和测试,导致无法捕捉到所有 SQL 函数的漏洞。
Empirical study
- 研究范围:
- 研究了来自 PostgreSQL、MySQL 和 MariaDB 的 318 个内置 SQL 函数错误。
- 错误分析:
- 分析了错误报告和源代码以确定错误的发生阶段、根本原因和触发条件。
- 发现大约 70% 的 SQL 函数错误发生在执行阶段。
- 约 40.9% 的错误位于字符串函数和聚合函数中。
- 错误触发条件:
- 87.5% 的引起错误的语句不包含超过两个函数表达式。
- 主要错误原因:
- 87.4% 的错误由边界值的处理不当引起,这被认为是内置 SQL 函数错误的主要根源。
- 这些边界值源自三个地方:字面边界值、类型转换结果和嵌套函数的边界返回值。
- 错误模式总结:
- 对这三种源头的错误进行了研究,并总结出了引起错误的查询中的边界值生成模式。
Implementation
工具开发:
- SoFT 是一个测试工具,用于生成包含内置 SQL 函数表达式的测试用例,其参数基于之前研究总结的模式。
性能评估:
- SoFT 被用来测试七种广泛使用的 DBMS:PostgreSQL、MySQL、MariaDB、ClickHouse、MonetDB、DuckDB 和 Virtuoso。
与现有工具的比较:
- 与现有的 DBMS 测试工具(如 SQUIRREL、SQLancer 和 SQLsmith)相比,SoFT 在 24 小时内能触发更多函数,覆盖更多的 SQL 函数组件代码分支。
覆盖和效率:
- SoFT 在不同 DBMS 中触发了显著数量的功能,包括 PostgresSQL(覆盖 433.93%),MySQL(覆盖 98.70%),和其他。
问题检测:
- SoFT 发现了 132 个之前未知的错误,这些错误得到了数据库开发者的关注。
开发者反应:
- 例如,当向 ClickHouse 报告一个错误时,其 CTO 快速回应并提交了一个 pull 请求以移除有缺陷的功能。ClickHouse 开发者在两天内修复了该错误并重新提交了 SQL 函数的代码。
contributions
分析了 318 个 SQL 函数错误,并确定了其主要根本原因:参数的边界值处理不当。
总结了 10 种边界值生成模式,用于检测 SQL 函数错误。基于这些模式,开发了 SoFT 工具,通过构造边界参数来检测 DBMS 中的 SQL 函数错误。
SoFT 工具发现了 132 个之前未知的实际 DBMS 错误,所有这些错误均得到开发者确认,其中 97 个已被修复。
Background
DBMSs and SQL functions.
- **数据库管理系统 (DBMS)**:
- 定义为使用户能够定义、创建、维护和控制对数据库的访问的软件。
- **结构化查询语言 (SQL)**:
- 是与DBMS交互的标准语言,用于创建、修改和查询关系数据库。
- SQL函数的分类:
- 内置函数:这些是预定义的、SQL中包含的标准函数,通常在不同平台上标准化,尽管实现或可用的函数范围可能有细微差别。
- **用户定义的函数 (UDFs)**:由用户创建的函数,用于执行内置SQL函数不涵盖的操作。UDFs允许用户根据特定的数据处理需求定制逻辑。
- SQL函数与编程语言函数的对比:
- SQL函数不涉及复杂的函数调用依赖和序列。例如,与JavaScript库中依赖于类、对象和函数的XML更新操作不同,SQL函数依赖于各种参数值格式来代表数据和操作,从而提供灵活性和便利性。
SQL Function Processing Steps.
- 解析参数:
- DBMS 识别并解析函数表达式中的参数,将其分类为字面量、列名或别名。
- 计算和转换参数值:
- 参数值由 DBMS 计算,并转换成函数所需的对应参数类型。
- 执行函数:
- 执行 SQL 函数的核心实现,计算并返回结果。
例如,对于处理 XML 的操作,DBMS 首先将参数作为字符串字面量解析,然后将字符串转换为 DBMS 的内部 XML 类型和 XPATH 类型,最后 DBMS 使用这些类型进行操作以更新 XML 值。这些 SQL 函数表达式的处理步骤是由开发者使用编程语言预先实现的。

主要区别
- 简洁性:SQL提供了一种更简洁的方法,通过单一的函数调用即可完成整个操作,而JavaScript需要多步骤的API调用来达到同样的目的。
- 集成性:在数据库环境中,直接使用SQL函数可以无缝地与数据库其他操作整合,而JavaScript处理需要在应用程序层面处理XML数据。
- 性能:对于数据库中存储的XML数据,使用SQL函数可能更高效,因为它避免了在应用程序和数据库间来回传输大量XML数据。
- 灵活性:JavaScript提供了更多的操作灵活性和控制,因为它可以使用广泛的DOM操作方法和属性来精细控制XML处理的每一个步骤。
SQL Function Bugs.
SQL函数漏洞的来源:
- 当DBMS处理SQL函数表达式时,可能因为实现缺陷导致内存错误或语义问题,如空指针解引用和缓冲区溢出。
- 这些漏洞可能由包含精心构造的SQL函数表达式的SQL语句触发,从而导致系统崩溃、内存泄露或任意代码执行。
测试SQL函数的挑战:
- 现有的针对程序库函数的测试方法,如依赖于函数调用序列构建的方法,不适合SQL函数,因为SQL函数的行为主要取决于传入的参数。
SQL函数的域测试:
- 提出SQL函数的测试应该类似于域测试,即通过输入参数的不同可能性进行测试,特别是关注于输入参数的边界条件。
- 域错误指的是输入使程序进入预期外的执行路径,这在SQL函数中可能因参数边界处理不当而发生。
解决方案:
- 鉴于SQL函数接受多种输入类型,直接识别和划分它们的输入域及其边界条件具有挑战性。
- 为了解决这一问题,进行了一项研究,分析现有的SQL函数漏洞,以确定哪些类型的输入更可能触发这些边界和漏洞,从而帮助更精确地构建测试用例。
Methodology
这段文字详细介绍了研究团队对SQL函数漏洞的研究方法:
- 数据收集:
- 主要从PostgreSQL, MySQL和MariaDB的公开漏洞追踪系统和CVE列表中收集SQL函数漏洞。
- 使用关键词”crash”和”signal”筛选可能的漏洞,排除了标记为“重复”或“不是漏洞”的报告。
- 数据分析:
- 对收集到的漏洞报告进行详细分析,特别是那些包含SQL函数表达式的报告。
- 手动检查每个漏洞报告和相应的证明概念(PoC),确认漏洞在执行SQL函数时是否会引起系统崩溃。
- 漏洞分类:
- 根据漏洞发生后的系统崩溃情况,将其归类为SQL函数漏洞,并进一步分析其根本原因。
- 数据清洗:
- 对于PostgreSQL的数据,因为其漏洞追踪系统没有漏洞标签过滤器,所以在分析阶段进行了手动排除重复或不相关的漏洞。
- 结果的局限性:
- 研究中未考虑非崩溃类漏洞,如功能性错误,因为这类错误往往需要更复杂的查询和分析,可能产生大量误报。(我们的工作更多考虑功能性错误)
- 研究仅限于关系型数据库管理系统(如PostgreSQL, MySQL和MariaDB),没有包括使用自有查询语法的其他类型数据库,例如图形或时间序列数据库,这可能影响结果的普遍适用性。
通过上述方法,研究团队希望识别和分类影响SQL函数的重要漏洞,提供针对这些系统的深入见解和潜在的改进建议。

General Findings of SQL Function Bugs
在这一部分,我们对318个内置SQL函数的漏洞进行了深入分析。我们分析了这些SQL漏洞,以识别它们的共同特征,重点关注三个关键方面:
- 发生崩溃时数据库管理系统(DBMS)处理的阶段;
- 触发崩溃的SQL函数的类型;
- 引发漏洞的SQL语句所依赖的前置SQL语句。
4.1 Occurrence Stages
这段文字描述了在研究SQL函数漏洞时采用的方法来识别DBMS处理SQL查询的不同阶段中的错误,并提供了关于错误发生阶段的统计数据:
- DBMS处理SQL查询的阶段:
- 解析阶段:DBMS的解析器将用户发送的SQL语句转换为内部的抽象语法树(AST)。
- 优化阶段:优化器分析AST并尝试生成优化的查询计划。
- 执行阶段:执行器执行查询计划并向用户返回结果。
- 错误分析方法:
- 从漏洞报告中提取崩溃的回溯信息,以确定DBMS崩溃发生的具体阶段。
- 总共有230个漏洞报告含有可以识别的回溯信息。
- 错误发生的阶段分布:
- 执行阶段:约70.0%(161/230)的漏洞发生在执行阶段,主要由于传入SQL函数的参数在内部数据类型转换后,计算过程中存在缺陷导致DBMS崩溃。
- 优化阶段:约19.6%(45/230)的漏洞发生在优化阶段,这些崩溃通常由SQL中复杂的嵌套结构或函数表达式周围的结构触发。
- 解析阶段:约10.4%(24/230)的漏洞发生在解析阶段。
这些发现揭示了SQL函数在DBMS处理中不同阶段的漏洞特性,以及它们是如何根据SQL查询的复杂性和特定参数处理的缺陷而发生的。这种阶段性分析有助于更准确地定位问题源头,从而改进SQL函数的实现和测试。
4.2 Types of SQL Functions
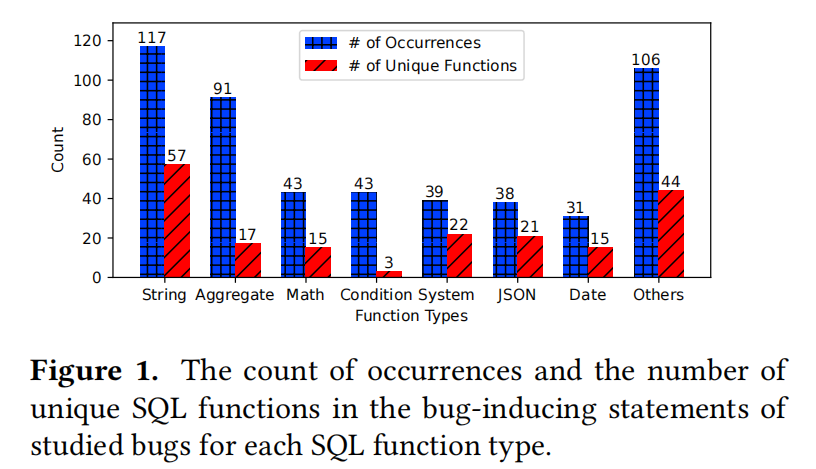
这段文字详细讨论了在SQL函数引发的漏洞中不同类型的SQL函数的作用,并分析了这些函数在漏洞中的出现频率和特性:
- SQL函数类型的分析:
- 进行了统计分析,以识别导致SQL函数漏洞的计算类型。
- 对漏洞证明中的SQL语句进行解析,提取并分类其中的函数表达式。
- 发现字符串函数和聚合函数是导致漏洞的最常见的SQL函数类型。
- 字符串函数和聚合函数的影响:
- 字符串函数在DBMS中非常常见,支持各种字符串操作,如连接、替换、正则表达式搜索和哈希等。
- 聚合函数涉及更复杂的计算,通常操作一个或多个列的所有元素,并支持分组、筛选和排序操作,这增加了发生漏洞的可能性。
- 函数表达式的出现频率:
- 在508个引发漏洞的证明中,字符串函数和聚合函数的出现频率分别为23%和17.9%。
- 在这些漏洞中,超过40%是由这两种类型的函数引起的。
- 单个漏洞中函数表达式的数量:
- 大多数(约61.0%)的漏洞诱发语句中只包含一个SQL函数表达式。
- 约27.4%包含两个函数表达式,其余的包含超过两个。
这些发现表明,字符串函数和聚合函数由于其在数据库操作中的普遍应用和内在的计算复杂性,特别容易成为引发漏洞的源头。此外,大多数漏洞诱发的SQL语句中包含的函数表达式数量较少,显示出单一或少量复杂函数调用的高风险性。

4.3 Prerequisite SQL Statements
这段文字讨论了SQL函数漏洞中的先决条件SQL语句的角色以及这些漏洞的依赖性:
- 先决条件SQL语句的作用:
- 真实世界的SQL查询通常依赖于预先存在的数据,这些数据通过诸如表创建和数据插入等先决条件语句准备好。
- 漏洞诱发的SQL语句可能依赖于这些先决条件语句来引发崩溃。
- 漏洞依赖性的分析:
- 研究团队分析了漏洞证明(PoC)中SQL语句及其依赖性,识别了不同类型的依赖结构。
- 发现约47.5%(151/318)的漏洞依赖于表创建和数据插入,约41.5%(132/318)的漏洞不依赖于任何表,而11.0%(35/318)的漏洞依赖于特定表但不涉及数据插入。
- 漏洞依赖性的具体情况:
- 依赖于表创建和数据插入的漏洞,其PoC通常包含复杂的CREATE TABLE和INSERT语句,这些语句用于准备特定的数据类型和值,然后通过FROM子句在漏洞诱发语句中使用这些数据。
- 不依赖于任何表的漏洞通常使用字面量表达式来构造精心设计的数据类型和值。
- 依赖于空表的漏洞PoC包含复杂的CREATE TABLE语句,其中包括特定的列数据类型和约束。
Root Causes of SQL Function Bugs
- 漏洞原因分析:
- 手动审查每个漏洞报告后,发现87.4%的SQL函数漏洞由参数的边界值处理不当引起,这是内置SQL函数漏洞的主要根本原因。
- 边界值的定义:
- 边界值是指在可接受和不可接受输入之间的临界值。在SQL函数的上下文中,这些边界值是预期的SQL函数参数格式的边缘,包括结构、范围、长度和嵌套深度。
- 边界值来源:
- 边界值主要来源于三种类型的表达式:边界字面值、类型转换的边界结果以及嵌套函数的返回值。
- 边界值导致的漏洞:
- 由于SQL函数接受多种格式的参数(如日期、IP地址、JSON和XML),这些格式允许用户便捷地编写SQL函数表达式,但同时也要求DBMS在处理这些参数时更加谨慎。
- SQL函数的实现必须仔细检查参数是否符合预期格式,正确地将它们转换为内置类型,并准确执行操作。因此,各种格式的参数在处理时带来复杂的边界条件,这可能导致处理SQL函数表达式时触发漏洞。
这表明在开发和实施SQL函数时,必须特别注意参数的边界条件处理,以防止漏洞的发生。
5.1 Boundary Literal Values
- 边界字面值的定义:
- 边界字面值指的是在测试场景中使用的极端和特定的数值,用于评估系统或函数在输入范围边界时的表现。
- 这些值通常作为常数或字面量直接在测试用例中指定,代表输入数据的最小值、最大值或关键边缘情况。
- 漏洞的影响:
- 约29.5%(94/318)的研究中的漏洞由于SQL函数参数中的边界字面值不当处理而引发。
- 这些漏洞表明,SQL函数的实现在处理极端或特定边界值时缺乏足够的健壮性,导致系统出现漏洞。
这表明在设计和实现SQL函数时,确保对边界值有充分的处理是防止漏洞发生的关键。

- PostgreSQL的CVE-2016-0773漏洞:
问题描述:
- 在处理正则表达式匹配时,字符值
'\x7fffffff'被转换为一个32位整数变量,导致溢出。在PostgreSQL的实现中,当尝试执行字符串'a' * '\x7fffffff'时,导致内存访问冲突。
技术细节:
- 该字符值在用于正则表达式匹配时,其转换结果超出了32位整型变量的最大存储范围,导致溢出。此溢出在一个循环结构中发生,导致无限循环和服务拒绝。
解决方法:
- 开发者通过修改代码,确保数值小于
\x7fffffff以避免溢出。如果超过这个阈值,程序将向客户端抛出错误信息:“ERROR: invalid regular expression: numeric range out of order”。
- MariaDB的MDEV-23415漏洞:
问题描述:
- 在使用
FORMAT函数时发生的堆缓冲溢出。FORMAT函数的第二个参数“50”预期为分数部分的数字结果位数。当格式化操作以科学记数法返回时,如果位数超过31,返回的字符串将比预期短,导致缓冲区溢出。
技术细节:
FORMAT函数在处理大于31位数的参数时没有适当的边界检查,当实际格式化的字符串长度超过了内存分配的大小时,就会导致堆缓冲区溢出。
解决方法:
- 通过增加对第二个参数的边界检查,防止超过31的数值输入,避免缓冲区溢出问题。
这两个案例显示了如何在SQL函数的实现中处理极端或特殊的输入值至关重要,尤其是在涉及内存操作和数据类型转换的场景中。开发者必须在实现这些函数时进行严格的参数验证和错误处理,以防止潜在的安全风险和系统稳定性问题。这也凸显了数据库函数与常规编程库函数在设计和安全需求上的根本差异,数据库函数需要更加小心地处理外部用户的输入。
5.2 Boundary Type Castings
这段文字讨论了在数据库管理系统(DBMS)中进行类型转换时可能导致SQL函数漏洞的问题:
- 类型转换定义:
- 类型转换指的是将一个数据类型的值转换为另一个类型。在DBMS中处理SQL函数表达式时,函数参数首先被转换为内部数据类型。
- 漏洞成因:
- 有时,函数参数的转换不正确,导致SQL函数漏洞。例如,过大的数值或NULL值可能在转换过程中被不当处理。
- 示例:
- 文中提到一个例子,其中一个60位数的十进制数在MariaDB中被转换为double变量,但由于这个值超出了MariaDB十进制库的处理范围,导致问题。
- 漏洞影响:
- 大约23.3%(74/318)的研究中的漏洞是由类型转换过程中构建的边界参数引起的。
这说明,在实现和使用DBMS时,确保类型转换的正确性和数据类型的适当处理对于防止系统漏洞非常关键。

MDEV-8407: 堆缓冲区溢出(MariaDB)
问题描述:
- 当从MariaDB的十进制数据类型转换为字符串类型时,发生了堆缓冲区溢出。具体案例中涉及一个48位的十进制数字,该数字首先被转换为MariaDB的十进制数据类型,并在处理
COLUMN_CREATE函数表达式时使用。 - 在后续步骤中,这个十进制值被
decimal2string库函数转换为字符串。但是,当十进制数字超过40位时,该库函数在计算结果字符串长度时出错,分配的空间不足,导致堆缓冲区溢出。
技术细节:
- 库函数在处理大于40位的十进制数字时,错误地估算了所需的字符串长度,分配的内存空间不足以容纳最终的字符串,从而触发溢出。
MDEV-1130: 堆缓冲区溢出(MariaDB)
问题描述:
- 在将NULL值转换为整数类型时发生了堆缓冲区溢出。在这种情况下,MariaDB将NULL值存储为一个
int64变量,并尝试计算这个值的数字长度。 - 然而,当原始值是NULL时,MariaDB错误地将其存储为整数0,并计算其数字位数为零(实际上’0’至少占一个数字位)。这种错误的位数计算导致在后续的字符串上下文中分配了不足的空间,引发堆缓冲区溢出。
技术细节:
- 由于类型转换中未能正确处理NULL值转换为整数的情况,导致数字位数计算错误,进而在内存分配时未能正确预留足够空间,引起溢出。
根本原因分析
- 这些漏洞显示了DBMS在类型系统实现上的缺陷,尤其是在处理边界类型值时。这些漏洞不是SQL函数本身的直接问题,而是类型系统如何定义和处理各种边界条件值的问题。
- 这类漏洞可能不会立即导致DBMS崩溃,但在SQL函数依赖于这些内部数据类型实例的参数时,可能导致功能计算错误甚至系统崩溃。
5.3 Boundary Results of Nested Functions
除了边界字面值和类型转换之外,嵌套函数返回值产生的边界参数也是SQL函数漏洞的一个主要原因:
- 漏洞来源:大约34.6%(110/318)的研究中的漏洞是由于嵌套函数返回值产生的边界参数引起的。
- 漏洞机制:这些嵌套函数能够构建具有特定数据类型和值的边界参数,如特殊的二进制流或特别长的字符串。
- 影响:这类边界参数可能触发SQL函数实现中的错误。
这种类型的漏洞表明,SQL函数在处理由嵌套函数产生的复杂或极端数据时需要额外的注意,以确保系统的稳健性和安全性。

1. CVE-2015-5289: PostgreSQL中的堆栈溢出
问题描述:
- 此漏洞发生在将一个长字符串转换为JSON格式时。特别是,使用
repeat函数重复字符'['1000次,用于创建一个非常深的JSON数组。
技术细节:
- 在JSON中,
'['表示数组的开始。PostgreSQL在解析这些数组时会递归处理每个'['字符。当存在过多的'['字符时,会不断递归调用parse_array库函数,导致堆栈溢出,最终可能导致服务拒绝。
解决方法:
- 开发者通过添加递归深度检查来修复此问题,以防止过深的递归导致堆栈溢出。
2. MDEV-14596: MariaDB中的段错误
问题描述:
- 在MariaDB中,
INTERVAL函数引发段错误。该函数在进行行类型的值比较时遇到问题,因为行类型的值不支持比较操作。
技术细节:
INTERVAL函数需要比较第一个参数(N)与后续参数(N1, N2, N3,…),并返回第一个大于N的参数的索引。在此案例中,传递了两个行类型的值(ROW(1, 1) 和 ROW(1, 2))给INTERVAL函数,而行类型不支持比较操作。MariaDB没有在INTERVAL函数内部验证这一点,导致段错误。
解决方法:
- 此问题需要MariaDB在执行比较之前验证数据类型支持相应的操作,以防止非法操作导致系统崩溃。
根本原因分析
- 这些问题显示了DBMS在处理嵌套函数生成的边界参数时的脆弱性。这些边界参数可能由于其特殊数据类型或极端长度,难以通过常规的字面值或类型转换来表达,导致SQL函数实现中的错误处理不当。
5.4 Other Root Causes
除了SQL函数表达式中的边界参数之外,还有其他导致SQL功能漏洞的根本原因,包括数据库管理系统(DBMS)的配置、特定的表定义以及复杂的语法结构。以下是对这些原因的概述:
- 数据库系统配置:
- 数据库的具体配置可能导致错误。例如,缓冲区大小、时区和字符集的不正确或不兼容设置可能导致某些SQL功能在DBMS中工作不正常,最终导致错误和失败。研究中发现有8个与配置相关的漏洞。
- 特定表定义:
- 表的具体定义和结构,如存储引擎、索引和列约束,可以改变
SELECT语句的处理方式。索引可以影响WHERE子句的处理方式,如果索引的实现错误,可能在DBMS处理带索引的特定函数表达式时发生错误。研究观察到有24个与特定表定义相关的漏洞。
- 表的具体定义和结构,如存储引擎、索引和列约束,可以改变
- 复杂的语法结构:
- 来自SQL语法结构复杂性的错误可能在查询和过程中出现。复杂的SQL查询可能在解析功能表达式时导致崩溃,尤其是包含复杂子句和嵌套子查询的情况。研究中发现有8个与复杂语法结构相关的漏洞。
这些原因表明,SQL函数漏洞的触发不仅依赖于函数参数的处理,还受到DBMS配置、表结构和查询复杂性的影响。正确配置系统参数、优化数据表结构以及简化SQL语法结构可以在一定程度上防止这类漏洞的发生。
Boundary Value Generation Patterns
这段文本讨论了SQL函数中边界值处理缺陷的问题,指出现有测试框架难以有效构建和检测这些边界值,尤其是在SQL函数参数中。以下是主要观点的概述:
- 主要根本原因:SQL功能漏洞的主要根本原因是边界值的处理不当,这包括边界字面值、边界类型转换和嵌套函数的边界返回值。
- 测试框架的局限性:
- 现有的功能测试方法,如 EvoSuite,主要生成随机参数值,难以满足SQL函数参数的边界值需求。
- 数据库管理系统(DBMS)的测试工具也难以生成包含内置SQL函数的测试案例。即使生成,也难以构建包含正确边界值的参数。
- 具体挑战:
- 多数测试工具随机生成字面值,未考虑SQL函数表达式的边界值。
- 这些工具主要关注生成语法和语义上正确的语句,但常忽略无效的类型转换。
- 它们倾向于生成包含多种关键字和子句的复杂SQL结构,却忽视了嵌套函数表达式。
- 解决方向:
- 文章提到基于研究中的漏洞案例总结出的10种边界值生成模式,这些模式旨在引导SQL函数漏洞的检测。
为提高SQL函数测试的有效性,需要更精细地处理和生成边界值,特别是在构建测试用例时考虑到SQL特有的复杂性和多样性。
Patterns of Boundary Literal Values.
我们发现大约10.0%(32/318)的错误是由极端整数值或十进制值造成的,6.6%(21/318)来自空字符串或NULL值,12.9%(41/318)是由以特定格式(如JSON和DATE)制作的字符串文字造成的。
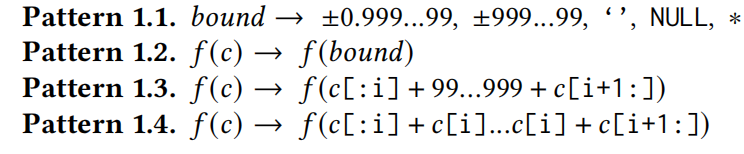
**Pattern 1.1 (边界字面值)**:
- 目的:生成用于测试的极端数值(如非常大或非常小的数值)、空值和通配符。
- 举例:+0.999…99表示正接近于1的小数值,+999…99代表非常大的正整数值,
' '(空字符串)、NULL和*代表其他特殊的边界情况。
**Pattern 1.2 (简单替换)**:
- 目的:将函数中的常规参数替换为边界值。
- 举例:如果有函数
f(c),其中c是常规参数,这个模式将c替换为边界值bound,生成f(bound)。
**Pattern 1.3 (部分替换)**:
- 目的:用边界值替换函数参数中的一部分,以构造可能引发错误的复杂输入。
- 举例:如果
c是一个字符串,这个模式会在c的某个位置i将后面的部分替换为边界值,如99…999,生成形如f(c[:i] + 99...999 + c[i+1:])的表达式。
**Pattern 1.4 (分段替换)**:
- 目的:在函数的单个参数中插入多个边界值,以测试函数对复杂结构输入的处理。
- 举例:这种模式将参数
c在不同的点i插入边界值,生成形如f(c[:i] + c[i]...c[i] + c[i+1:])的复杂表达式,其中c[i]...c[i]表示在这些点插入相同字符的边界值。
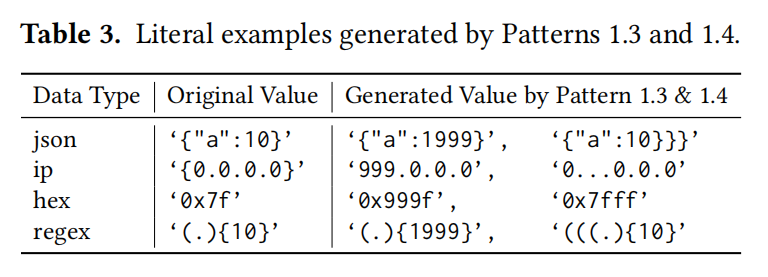
Patterns of Boundary Type Castings.
在我们所研究的由边界类型铸件引起的bug中,在处理具有这些错误实例的SQL函数表达式时,通常会发生崩溃。一些导致bug的SQL语句可以遵循Patten2.1,它用显式类型转换表示SQL函数表达式。SQL函数参数首先通过CAST操作转换为其他数据类型,从而触发与不同内部数据类型相关的各种DBMS行为。如果在类型转换实现中存在错误,那么当DBMS处理具有这些类型转换参数的SQL函数时,它们可能会导致错误。
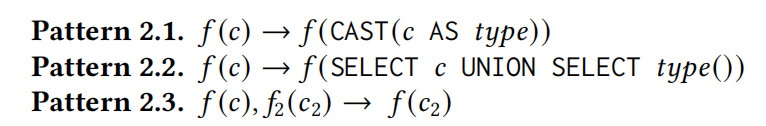
Pattern 2.1: 显式类型转换
- 描述: 这个模式通过显式的
CAST语句将函数参数转换为特定的数据类型。例如,如果一个函数需要整数类型的参数,使用CAST(c AS INTEGER)可以确保传递给函数的值是整数。 - 用途: 确保函数参数在传递前满足函数期望的数据类型要求,避免类型不匹配导致的错误。
Pattern 2.2: 利用UNION进行隐式类型转换
- 描述: 在SQL中,
UNION要求所有涉及的SELECT语句产生相同数据类型的结果。此模式通过结合两个SELECT语句(一个返回原始数据类型,另一个通过函数调用返回另一数据类型),利用SQL的特性来实现隐式类型转换。 - 用途: 检测DBMS如何处理来自不同SELECT语句但需要合并为单一数据类型时的隐式类型转换,这种情况常在实际应用中无意中发生,可能导致错误或性能问题。
Pattern 2.3: 函数间参数传递引发的隐式类型转换
- 描述: 这个模式涉及将一个函数的输出作为另一个函数的输入,特别是这两个函数预期的参数类型不一致时。
- 用途: 用来检测当函数的输出类型与另一个函数的期望输入类型不匹配时,系统是否能正确处理或转换类型。这可以暴露一些函数实现中的缺陷,例如不恰当的错误处理或数据处理逻辑错误。
Patterns of Nested Functions.
嵌套函数的结构可以使用模式3.1、模式3.2和模式3.3来描述。模式3.1用于通过重复函数重复原始参数的前缀来构造极端长度的参数。重复计数来自于模式1.1中的边界文字值。该模式还可以为特定数据类型的参数创建深度递归结构,如数组、JSON和XML。
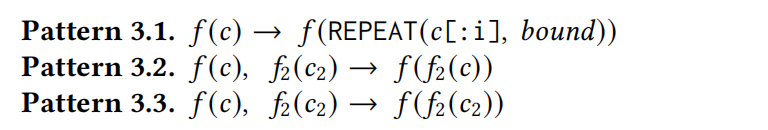
这三个模式(Pattern 3.1, 3.2, 3.3)都是设计用来生成和处理边界值参数,尤其是在嵌套函数调用的情况下,从而检测SQL函数如何处理复杂的函数参数和数据类型。
Pattern 3.1: 使用重复函数构造边界值
- 描述: 此模式通过
REPEAT函数重复构造一个值或字符到指定的次数(由bound参数定义),生成潜在的边界值或非常大的输入。 - 用途: 检测函数在处理异常大或重复的输入时的行为,可能揭示处理大量数据或异常输入时的性能问题或失败。
Pattern 3.2: 嵌套函数调用
- 描述: 这个模式涉及将一个函数的输出(
f2(c2))作为另一个函数的参数(f())。这里不改变f2的参数c2,而是将f2的结果直接用作f的输入。 - 用途: 检测函数间的数据兼容性和类型安全性。例如,如果
f2返回一个类型不匹配f预期参数的值,这将测试DBMS是否能正确处理或报错。
Pattern 3.3: 更复杂的嵌套函数调用
- 描述: 类似于Pattern 3.2,但这里
f2函数本身就以另一个函数f2的输出作为参数。它测试连续的函数输出和输入的链条。 - 用途: 这可以检查更复杂的函数调用链对数据类型和值的处理,尤其是在需要多步数据处理和转换的场景中。
Pattern-Based Bug Detection
7.1 Implementation
SoFT工具检测SQL函数错误的实现包括三个主要步骤:
- 函数表达式收集:SoFT首先扫描数据库管理系统(DBMS)的文档和回归测试套件,以编译所有SQL函数名称的列表。然后,根据这些函数名称从DBMS测试套件中的SQL查询中提取SQL函数表达式。
- 基于模式的生成:使用已识别的边界值生成模式,SoFT首先通过修改现有函数表达式的参数来生成新的SQL语句。这有助于系统地创建可能因边界值处理触发SQL函数错误的多样化测试用例。
- SQL函数错误检测:通过Python客户端在DBMS中执行新创建的SQL函数表达式。如果在执行这些修改后的SQL语句期间DBMS崩溃,这表明存在错误,SoFT随后会记录这些错误以便进一步分析和报告。
根据原始的SQL语句修改函数参数来实现边界值检测
7.2 Testing Setup
七种开源数据库管理系统(DBMS),包括PostgreSQL v16.1、MySQL v8.3.0、MariaDB v11.3.2、ClickHouse v23.6.2.18、MonetDB v11.47.11、DuckDB v0.10.1和Virtuoso v7.2.12。
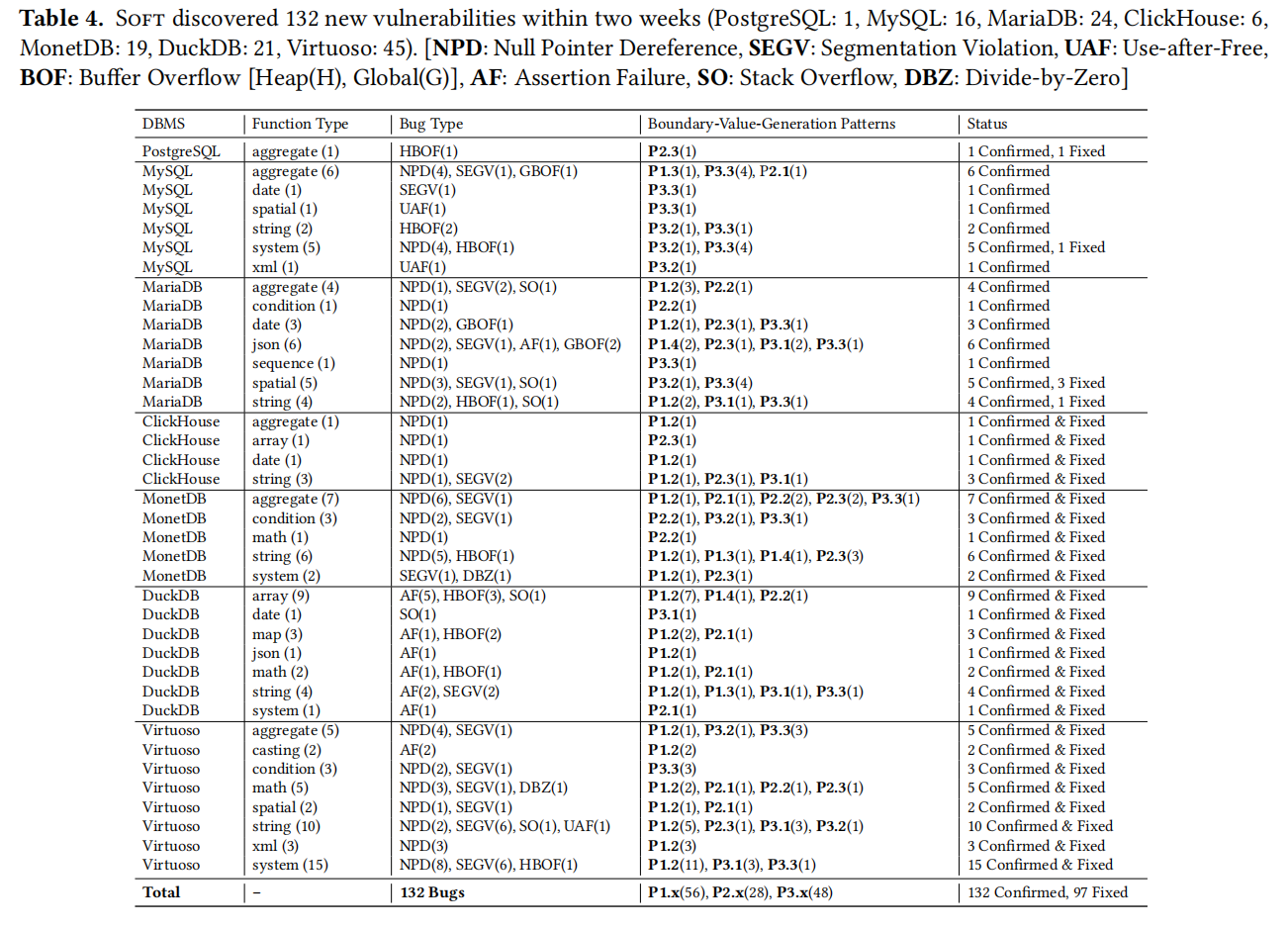
7.3 Detected DBMS Vulnerabilities
SoFT在两周内成功检测出132个漏洞,使用了包括SQuirreL、SQLsmith和SQLancer等工具的默认配置,但这些工具未能发现任何SQL函数漏洞。在所检测的数据库中,SoFT在PostgreSQL、MySQL、MariaDB、ClickHouse、MonetDB、DuckDB和Virtuoso中分别发现了1、16、24、6、19、21和45个漏洞。这些漏洞涵盖了各种类型的内存错误,包括空指针引用、段错误、堆缓冲区溢出等。SoFT同时也产生了一些误报,主要是由于生成的参数超出内存限制。此外,从DBMS开发者那里收到的反馈显示,这些发现的漏洞被认为是安全相关的,有些已经被修复,有些则因安全原因被隐藏。例如,ClickHouse的CTO要求立即修复或移除相关功能,MariaDB的安全团队选择在问题解决前隐藏这些问题。
7.4 Bugs of Each Pattern
这些案例展示了不同的SQL函数在处理边界值时可能触发的错误类型:
- 全局缓冲区溢出(MySQL):这个例子中,
AVG函数处理一个异常长的字面值,这个值超出了系统预期的精度,导致全局缓冲区溢出。 - 分段错误(Virtuoso):在Virtuoso数据库中,
CONTAINS函数处理带有通配符*的参数时没有正确管理内存访问,导致非法内存访问和分段错误。 - 堆缓冲区溢出(PostgreSQL):在PostgreSQL中,
JSONB_OBJECT_AGG函数尝试处理一个大于预期的字符串数组,导致堆缓冲区溢出。 - 堆栈溢出(DuckDB):DuckDB中的
REPEAT函数与UNION操作结合使用,导致深度递归和堆栈溢出。 - 全局缓冲区溢出(MariaDB):MariaDB的
JSON_LENGTH函数处理重复的大量文本时未能正确管理内存,引起全局缓冲区溢出。 - 分段错误(MariaDB):MariaDB中的
ST_ASTEXT函数处理复杂的嵌套函数调用链和类型转换时,由于边界计算错误,导致分段错误。






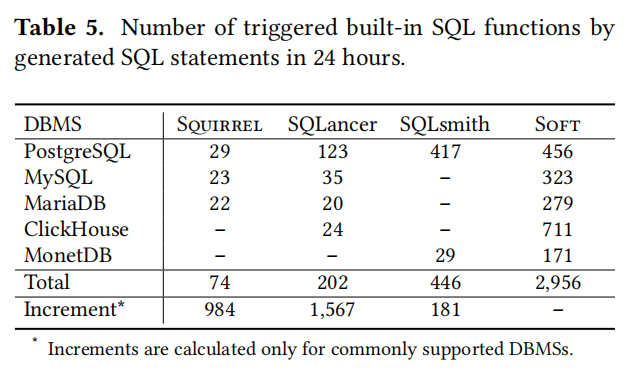
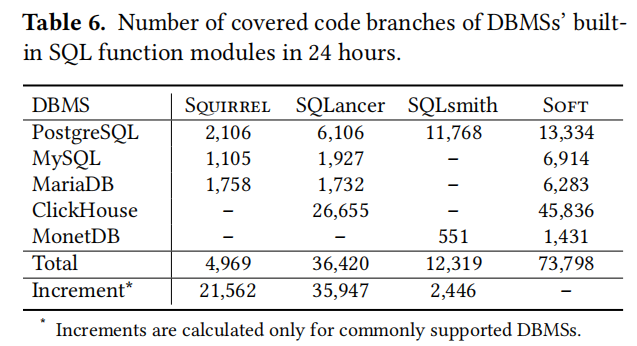
7.5 Comparison with Other Testing Works
在这一部分中,介绍了如何将SoFT(一种SQL功能测试工具)与其他三个先进的数据库管理系统(DBMS)测试工具——SQuirreL, SQLancer, 和SQLsmith——进行比较。这些测试是在Ubuntu 20.04系统上,使用AMD EPYC 7742处理器的机器上完成的,主要评估了不同工具在24小时内触发和覆盖SQL函数及其代码分支的能力。
结果表明,SoFT在触发和覆盖内置SQL函数方面表现优于其他测试工具,尤其是在PostgreSQL、MySQL和MariaDB中。SoFT利用了边界值生成模式来构造测试用例,这些模式能够生成多样化的SQL函数参数和函数表达式,有效地触发深层逻辑错误,这是导致DBMS处理错误的常见原因。其他测试工具虽然也能触发一定数量的函数,但它们在处理边界值和复杂函数表达式方面存在限制,因此在发现真正的SQL函数bug方面不如SoFT有效。
此外,SoFT报告了在测试过程中发现的具体SQL函数bug数量,如PostgreSQL、MySQL、MariaDB、ClickHouse和MonetDB中分别发现的独特bug数量。相比之下,SQuirreL、SQLancer和SQLsmith在24小时的测试中触发的bug数量明显较少。这一对比显示了SoFT在生成能够触发关键代码路径的测试用例方面的高效性和实用性。
Discussion
用户定义函数(UDF)的问题:虽然本文集中在内置SQL函数的漏洞上,但提到用户定义的函数也可能存在问题,尤其是因为这些函数常常使用PL/SQL语句,涉及解析和执行的复杂性。未来的研究将专注于这些用户定义函数的测试和分析。
内置SQL函数的正确性问题:文章指出,除了内存安全问题外,SQL函数还可能存在逻辑或正确性问题,需要扩展测试框架来构建能够处理等价语义函数表达式的测试指南,进行差异测试。
现实和变换的重要性:发现内置函数的根本问题通常是对边界值处理不当。通过生成边界值,文章测试了内置函数,这有助于揭示由于接收和处理各种复杂输入而可能导致的系统崩溃和安全风险。
扩展现有的DBMS测试:SoFT不仅可以检测SQL函数的错误,还可以通过生成边界值来检测数据库中的其他敏感操作(如索引、排序和过滤)。文章建议将SoFT集成到现有的基于语法的DBMS测试框架中,以增强其检测能力,特别是在触发SQL函数之外的更多边界行为方面。
Related Work
DBMS Testing.
Testing of Function Libraries.
本文对数据库管理系统(DBMS)测试工作进行了分类讨论,主要包括三个领域:崩溃缺陷测试、正确性测试和性能测试。
- 崩溃缺陷测试:这部分工作着重于发现可能导致数据库意外停止工作或崩溃的条件。例如,SQLsmith 是一个生成式测试工具,用于生成SQL查询进行测试;SQUIRREL 则采用基于IR的突变方法生成语义正确的查询。
- 正确性测试:这些工作主要关注验证DBMS是否准确执行查询,使用不同的方法构建有效的逻辑测试和差异测试。如PQS通过对比前置查询结果中的数据行存在性来进行测试。
- 性能测试:性能测试致力于在不同的工作负载和条件下评估性能。例如,APOLLO使用性能回归测试来发现开发过程中的错误,而AMOEBA则生成语义等效的查询并比较它们的响应时间,以识别性能问题。
总体来看,传统的DBMS测试工作通常涉及多个SQL语句的复杂测试案例,而SoFT特别关注于内置SQL函数的缺陷,尤其是由于边界值处理不当所引起的。SoFT生成的查询通常包含嵌套的SQL函数或类型转换,旨在触发缺陷,每个测试案例通常只包含单个带函数的SQL语句,其复杂性体现在函数的SQL表达式上。
Testing of Function Libraries.
段文字讨论了函数库的测试方法,包括单元测试和模糊测试(Fuzzing)。单元测试通过为函数或例程编写测试用例来验证它们是否能够独立地按预期执行。工具如Evosuite和Randoop可以为Java库自动生成丰富的函数序列和断言,以检查每个函数的正确性,包括边界情况和错误处理路径。而模糊测试涉及向函数库输入大量变异的数据,以测试库的鲁棒性和错误处理能力。LIBFuzzer和AFL是流行的模糊测试工具,它们通过提供标准化的接口和各种技术如污点分析和符号执行来增强测试覆盖率和功能性。
与传统的函数库测试不同,SoFT专注于测试内置的SQL函数,通过生成满足特定边界值的测试用例来触发潜在的SQL函数错误。这种触发边界参数的方法也可以应用于传统的函数库测试,以提高发现潜在错误的可能性。
Domain Testing.
领域测试是一种软件测试技术,它生成一组测试用例来检测潜在错误的边界条件。通过划分输入空间成多个路径领域并计算这些领域的边界,领域测试能够检测错误的路径领域,比如错误的分支判断表达式。领域测试的初始策略由White等人首次提出,并且Clarke等人进一步介绍了两种改进的领域测试策略以增强错误边界的检测。
然而,这些领域测试策略是基于程序的控制流和执行路径的白盒测试方法,将其应用于大型系统如数据库管理系统(DBMS)相对困难。相比之下,SoFT通过构建从现有SQL函数错误中学习到的边界条件来测试SQL函数。研究发现,引发错误的边界条件主要来源于边界字面值、边界类型转换和嵌套函数的边界结果。因此,SoFT总结了十种模式来触发SQL函数的边界条件并检测错误。
Robustness Testing.
鲁棒性测试是保证系统安全和可靠性的关键测试过程,主要通过向系统引入意外事件,如故障注入或无效输入,来检验系统的健壮性。例如,androFIT 为 Android 操作系统开发了自动化故障注入工具,Postmonkey 对分布式嵌入式系统发送无效和随机消息以测试可靠性,而 ASTAA 则通过在系统消息字段中生成无效值来测试自主系统。
SoFT(针对数据库管理系统(DBMS)中的SQL函数组件的鲁棒性测试)专注于这些函数的特点,并归纳出10种引发错误的边界值生成模式。通过这些模式引导,SoFT设计了框架以发现和改善SQL函数的缺陷,从而增强DBMS的鲁棒性。这种方法强调,不同系统的独特架构需要特定的鲁棒性测试设计来满足特定的系统需求。