
Domain Adaptation for Code Model-Based Unit Test Case Generation
Domain Adaptation for Code Model-Based Unit Test Case Generation
Abstract
最近,基于深度学习的测试用例生成方法被提出,用以自动生成单元测试用例。在本研究中,我们利用基于Transformer的代码模型,通过领域适应(Domain Adaptation,DA)在项目级别上生成单元测试。具体而言,我们使用CodeT5,这是一种相对较小的在源代码数据上训练的语言模型,并将其微调用于测试生成任务。接着,我们对每个目标项目数据应用领域适应,以学习项目特定的知识(项目级别DA)。我们使用Methods2test数据集微调CodeT5以进行测试生成任务,并使用Defects4j数据集进行项目级别的领域适应和评估。我们将我们的方法与以下基线进行比较:(a) 没有DA的CodeT5微调测试生成,(b) A3Test工具,以及(c) GPT-4,在Defects4j数据集的五个项目上进行了实验。结果表明,使用DA生成的测试相较于上述(a)、(b)和(c)基线,可以分别提高18.62%、19.88%和18.02%的行覆盖率,并提高16.45%、16.01%和12.99%的变异得分。总体结果显示,在解析率、编译率、BLEU和CodeBLEU等指标上有一致的提升。此外,我们展示了我们的方法可以作为现有基于搜索的测试生成工具(如EvoSuite)的补充解决方案,平均提高了34.42%的行覆盖率和6.8%的变异得分。
Introduction
challenges in unit test case generation
自动生成单元测试用例方面的挑战,具体包括以下几个方面:
- 模型的鲁棒性挑战:生成代码时稍微的错误可能会导致程序出错,生成单元测试用例的难度比常规代码生成更高,因为测试用例往往涉及细微的代码差异。例如,插入一行断言或实例化对象的代码可能使程序处于可测试的状态。
- 测试用例的评估复杂性:要正确评估生成的测试用例,需要执行这些测试并计算测试充分性指标,这个过程非常耗时且通常需要手动操作来处理依赖关系等问题。
- 领域转移问题:预训练模型可能无法在新项目上有效传递其代码知识,因为不同项目中的代码分布差异较大。
我觉得不是那么make sense? 没有引用也没有例子。
advantages of test case generation based on code modes
可读性和可维护性:由于这些模型是基于人工编写的代码进行训练的,生成的测试用例更接近人类编写的代码,因此相比其他自动生成的测试用例,更具有可读性和可维护性。
开发者偏好:文献表明,开发者更倾向于使用神经网络模型生成的测试用例,因为这些测试用例比其他自动生成的方法更易读、易懂。
错误检测的差异:神经网络生成的测试用例能够检测到与开发者编写的测试用例类似的错误,而基于搜索的方法通常更关注代码覆盖率的最大化。
approach
这段文字主要介绍了一种应对预训练代码模型在生成测试用例时存在的性能不足、评估不充分以及领域转移问题的新方法。该方法采用了两种不同层次的微调/领域适应技术:任务级和项目级。
- 任务级领域适应:首先对CodeT5模型进行微调,使用特定任务的数据集来定制模型,以生成针对特定测试方法的单元测试用例。
- 项目级领域适应:通过项目特定的数据集进行领域适应,模型可以学习项目的特定知识,从而生成更高质量的测试用例,减少领域转移问题的影响。
此外,研究还通过充分评估测试充分性和文本相似度指标来解决评估不足的问题。该方法显示,即使模型相对较小(CodeT5仅有220M参数),其性能仍然优于更大的模型(如GPT-4)。通过自动化的后处理步骤,研究还解决了兼容性和可执行性问题,并使用Defects4j数据集对生成的测试用例进行评估。
相比于不使用领域适应的方法,该方法在所有评估指标上均取得了优异的效果,尤其在行覆盖率和变异分数上表现突出。
limitations: low performance、insufficient evaluation and domain shift前面都没有解释,怎么能用i.e,给出呢
“To address the shortcomings of pre-trained code models for test case generation, i.e., low performance, insufficient evaluation, and domain shift, we propose a simple yet novel technique by adopting two different levels of fine-tuning/domain adaptation: task and project.
只说了怎么做的,why do that? So what?
Contributions
这段文字概括了领域适应(Domain Adaptation)在测试用例生成中的应用及其主要贡献:
- 使用领域适应的提升:通过领域适应,行覆盖率平均提高了18.62%到19.88%,变异得分提高了12.99%到16.45%,分别优于没有领域适应的CodeT5、A3Test和GPT-4基线。此外,与EvoSuite工具结合使用时,行覆盖率和变异得分分别平均提高了34.42%和6.8%。
- 主要贡献:
- 提出了一种基于领域适应的行级神经测试用例生成框架,生成的测试用例具有良好的可编译性、类似于人工编写且测试充分。
- 进行了基于Defects4j数据集的实证研究,证明了该方法相对于现有的AthenaTest、A3Test和GPT-4具有更好的性能。
- 证明了该方法能够覆盖开发人员编写的测试用例和基线搜索工具无法覆盖的代码行,并能够比搜索工具消灭更多的变异体。
- 与相关工作不同,该方法执行生成的测试用例并使用测试充分性指标(如代码覆盖率和变异得分)进行评估,展示了相比于BLEU和CodeBLEU更高的评价标准。
Background and Related Work
2.1 Search-Based Software Testing
这段文字主要介绍了基于搜索的软件测试(Search-Based Software Testing,SBST)。在SBST中,测试用例生成问题被转化为一个针对测试充分性标准(如代码覆盖率)的优化问题。以EvoSuite为例,它是一个SBST工具,利用遗传算法生成测试用例,旨在优化语句或分支覆盖率,并通过最少的测试覆盖更多代码。
虽然SBST工具在有效性方面表现出色,但研究指出它们在理解性、可读性、质量以及在生成的单元测试用例中实际检测缺陷的能力方面存在一些限制。
2.2 Domain Adaption
这段文字介绍了领域适应(Domain Adaptation)的概念。领域适应是一种通过修改已在一个领域训练好的模型,使其在不同但相关的领域上表现良好的技术。其目标是利用源领域的知识来提高目标领域的性能,特别是在目标领域标注数据有限的情况下。领域适应属于迁移学习的一种,旨在将知识从一个任务转移到另一个任务。
随后,文中提到了几项与领域适应相关的研究:
- **TCA+**:一种新型的跨项目缺陷预测的迁移学习方法,通过减少源项目和目标项目之间的数据分布差异来提高预测性能。
- Patel等人对领域适应在视觉识别中的应用进行了综述,讨论了各种方法的优缺点。
- Farahani等人回顾了领域适应的主要类别和挑战,重点介绍了无监督领域适应的方法。
- Zirak等人提出了一种针对自动程序修复的领域适应框架,采用了全微调、轻量级适配器调优和课程学习三种方法。
总结来说,领域适应的核心在于通过跨领域迁移知识,提高目标领域的模型表现,尤其是在目标数据有限时,这对各种应用场景具有重要意义。
2.3 Neural Models for Unit Test Generation
这段文字介绍了使用神经网络模型进行单元测试生成的研究进展。主要分为两个类别:测试断言生成(Test Oracle Generation)和单元测试用例生成(Unit Test Case Generation)。
- 测试断言生成:
- 主要是生成有意义的断言语句(例如断言语句、try-catch块等),确保程序达到测试状态。断言生成是单元测试的一部分。
- 提到的工具包括ATLAS(用于生成断言,BLEU-4得分61.85%)、TOGA(使用统一的变换模型生成try-catch块和断言,断言的准确率为86%)、以及其他研究的生成模型,显示出生成测试断言的高准确性。
- 单元测试用例生成:
- 相关研究较少,已有的工作着重于自动化生成测试用例。
- 例如,Liu等人和Sae的研究分别生成了移动应用界面和Java方法的测试用例,使用JUnit测试框架,生成的测试用例通过率高达86.69%。
- 另外,研究提出了AthenaTest和A3Test两种工具,分别基于自然语言和代码语料生成单元测试,AthenaTest能够正确测试43%的目标方法,A3Test则整合了断言生成机制,覆盖更多方法。
- LLM在单元测试生成中的应用:
- 近年来,利用大型语言模型(LLM)进行测试生成得到了更多关注,CodaMOSA和TestPilot是利用LLM生成测试的工具。ChatTester和TeCo则通过执行反馈和代码语义模型生成更准确的测试用例。
本研究提出了一种新的方向,结合项目级领域适应来提高现有工具(如AthenaTest和A3Test)的性能。与现有研究不同,本文更关注代码覆盖率和变异得分等与生成测试用例充分性相关的指标,而不是简单的BLEU得分。尽管有很多相关工作,但生成出能揭示实际缺陷的有效测试用例仍然面临挑战。
Test Case Generation with Project Level Domain Adaptation
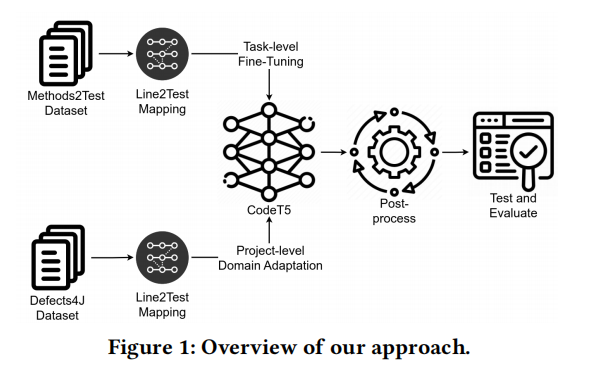
该框架包含两个主要步骤:
- 微调CodeT5模型:在任务级别的数据集上对CodeT5模型进行微调,以便其适应特定的测试生成任务。
- 领域适应(DA):在项目级别的数据集上应用领域适应,确保模型能够学习项目特定的知识。
该框架旨在生成高质量的测试用例,确保测试效果充分,基于开发人员编写的测试用例来进行学习。
3.1 Fine-Tuning on Test Case Generation Task
创建覆盖率数据库:从现有的测试套件中收集行级覆盖率数据,以评估哪些测试用例覆盖了哪些代码行。
Line2test映射:将源代码中的每一行映射到相应的单元测试方法,提取所有测试用例的类路径。
微调CodeT5模型:使用Methods2Test数据集对CodeT5模型进行微调。该数据集包含与目标方法、上下文信息(例如类名、字段等)和关联测试方法的元组。此步骤使用条件代码生成技术,适应特定任务。
后处理步骤:对生成的测试用例进行处理,解决模型生成的代码可能存在的换行符和重复定义等问题。之后,利用解析器修复编译错误,如缺少括号或分号等。最后,通过Defects4j框架逐个测试添加和编译,确保生成的测试用例是可解析和可编译的。
微调过程是通过将预训练模型(如CodeT5)适应特定的任务来优化的。在这个例子中,CodeT5被微调用于生成单元测试用例。下面将详细说明数据生成和微调的过程。
1. 微调数据生成
微调数据的来源是 Methods2Test 数据集,它包含以下信息的元组:
- 目标方法(Focal Method):需要生成测试用例的方法。例如,一个Java方法
int add(int a, int b)。- 上下文信息(Focal Context):包括目标方法所在的类名、类字段、方法签名等,帮助模型了解目标方法的环境。例如,
public class Calculator {}。- 关联测试方法(Associated Test Method):已经编写好的单元测试用例,用于帮助模型学习如何为目标方法生成相应的测试用例。例如,
void testAdd() { assertEquals(5, add(2, 3)); }。这些数据元组提供了上下文、目标代码和关联测试代码的信息,帮助模型学习如何生成相似的测试用例。
2. 微调方式
微调过程的关键步骤如下:
输入格式化:模型的输入包括目标方法及其上下文。为了方便模型理解,目标方法和其上下文信息被转换成一个序列格式。例如,目标方法的上下文可以是类名、字段和方法签名,这些信息被输入到模型中。例如:
2
Method: int add(int a, int b)输出格式化:输出是生成的测试用例,也被格式化为序列,例如:
条件代码生成:在微调过程中,模型学习如何在特定上下文下生成相应的测试用例。通过对目标方法进行条件性代码生成,模型可以将源方法的上下文映射到生成的测试代码中。这与传统的自然语言处理中的“序列到序列”生成类似,但在这里,输入是源代码,输出是测试用例代码。
损失函数:在微调过程中,模型通过计算生成的测试用例与真实测试用例之间的损失(如交叉熵损失)进行优化。模型试图最小化生成测试用例与真实测试用例之间的差异。例如,如果模型生成的测试用例与真实用例的差异很大,损失值就会很高,模型会通过反向传播调整参数。
3. 实际微调示例
假设我们有一个名为
Calculator的类,其中有一个方法add(int a, int b):目标方法:
2
3
return a + b;
}上下文信息:
2
Fields: none已有的测试用例:
2
3
4
public void testAdd() {
assertEquals(5, calculator.add(2, 3));
}微调过程:
输入到模型:模型接收到目标方法及其上下文信息,格式化后的输入可能是:
期望输出:模型根据输入生成相应的测试用例,输出格式为:
在这个过程中,模型会学习如何从类似的目标方法生成测试用例。在模型训练时,它会通过多次训练逐步优化生成的测试用例,使其更加准确和合理。
4. 后处理
微调后的模型生成测试用例时,可能存在一些编译或语法问题,比如括号不匹配、换行符处理不当等。为了确保生成的测试用例能够编译和执行,微调过程中的后处理会进行自动修复,例如:
- 修复缺少的括号或分号;
- 处理测试用例中的重复名称;
- 确保测试类包含必要的依赖和辅助方法等。
这些修复步骤确保生成的测试用例可以在实际项目中使用,并且能够编译通过。
3.2 Domain Adaptation on Project Specific Knowledge
这段文字主要介绍了在项目级别应用领域适应(Domain Adaptation)的过程,以解决模型在不同项目中的领域转移问题。关键内容如下:
- 领域转移问题:当模型应用于新项目时,由于不同项目之间的上下文差异较大,模型可能会生成不准确的测试用例。为此,使用已有的开发者编写的测试用例来帮助模型适应新项目,生成项目特定的数据集。
- 数据集生成:从项目的源代码中提取信息,生成三个不同的输出:文件结构中的方法名、方法体,以及上下文信息(类名、构造函数、公共字段和方法等)。这些信息被用来创建项目特定的数据集,进一步与
Line2test映射结合,确保每一行代码与其相应的测试方法相匹配。 - 领域适应过程:利用生成的项目特定数据集,在微调后的模型上进行轻量级的再训练,以使模型适应新的项目。这一过程使模型能够在新的项目上生成更准确且具有更高编译率的测试用例。
- 计算成本:项目级别的领域适应只需在每个项目上执行一次,计算成本相对较低。虽然这种方法相比搜索基测试方法(SBST)需要更多的训练时间,但在推理阶段节省了大量时间。
总结来说,项目级别的领域适应通过现有测试用例生成项目特定数据集,轻量级再训练模型,从而提高了生成测试用例的准确性和可编译性。
Experiment Settings
4.1 Research Questions
这段文字介绍了本文研究的三个研究问题(Research Questions,RQs),目的是评估代码模型在生成单元测试用例中的有效性,尤其是项目级领域适应的效果。主要内容如下:
- RQ1 (Performance):评估CodeT5在没有领域适应的情况下生成单元测试用例的效果。
- 动机:代码模型(如CodeBERT和CodeT5)已经被应用于软件工程任务,如评论生成、缺陷预测和程序修复。然而,针对测试用例生成的研究较少,现有研究主要依赖静态指标(如BLEU)评估生成的测试用例,但缺乏执行测试的有效性评估。
- RQ2 (Effectiveness):研究项目级领域适应如何提升CodeT5生成测试用例的质量。
- 动机:RQ1的结果显示,模型无法学习项目特定的知识。项目级领域适应是为了应对新项目中的领域转移问题。在RQ2中,研究对比了其他基线模型,如GPT-4和A3Test,评估使用项目级领域适应的效果。
- RQ3 (Impact):探讨提出的测试用例生成方法与基于搜索的测试用例生成方法(如EvoSuite)相比的影响。
- 动机:基于搜索的测试生成方法,如EvoSuite,是生成测试用例的常用技术。本文提出的基于Transformer的测试生成方法可以与基于搜索的工具结合使用,以覆盖不同类型的测试用例,并且在运行时间上具有优势。通过实验,研究对比了使用两种方法生成的测试用例在杀死新变异体上的表现。
4.2 Datasets
这段文字介绍了研究中使用的两个数据集:Methods2Test和Defects4j,分别用于微调模型和项目级领域适应。
- Methods2Test:用于微调模型生成测试用例的任务。该数据集包含从9,410个开源库中提取的780,944个Java方法实例。这些方法与其相应的测试用例进行映射。数据集提供了方法的上下文信息,包括方法签名、类名、构造函数和公共字段等,以帮助模型生成可编译的、有意义的测试用例。
- Defects4j:这是一个包含真实项目和实际缺陷的Java项目数据集,用于软件工程研究。每个项目都有一套完整的测试套件,用于评估模型在生成测试用例时的表现。研究使用了该数据集的5个项目来进行项目级领域适应和测试生成输出的评估。
4.3 Pre-Trained Code Model
为什么在研究中选择CodeT5作为代码模型,原因如下:
- 模型选择:没有选择较新的大型语言模型(如GPT-4、PaLM和LLaMA),因为这些模型虽然强大,但体积过大,微调成本高。而CodeT5较小,性能能够达到这些大型模型的水平,同时成本更为合理。
- 基于T5架构:CodeT5基于T5架构,这是一种编码器-解码器模型,适合既需要理解又需要生成的任务。相比之下,BERT是编码器模型,GPT是解码器模型,不适合生成任务。CodeT5能有效处理测试用例生成任务。
- 代码感知能力:CodeT5能处理代码数据中的标记类型信息,而其他模型通常只采用NLP预训练技术,忽略了代码的结构性信息。CodeT5对代码功能有更深层次的理解。
- 模型配置:CodeT5有两种配置:CodeT5-small(60M参数)和CodeT5-base(220M参数)。研究中选择了CodeT5-base,并通过CONCODE任务微调模型,以生成测试用例。CONCODE任务(从文本到代码生成)被认为比代码翻译任务更适合生成测试用例。
4.4 Baselines
本文研究使用的两个基线模型,用于与研究结果进行对比:
- GPT-4:一个高级的大型语言模型,能够模仿人类的语言表达和推理能力,擅长解决复杂问题、生成创意内容,并在各种专业和学术基准测试中表现出人类水平的能力。
- A3Test:一种测试用例生成方法,利用任务级别的领域适应技术进行断言生成(oracle generation),然后将学到的知识扩展到整个单元测试用例生成。
通过使用这两个基线,研究旨在评估项目级领域适应与最先进的LLM(GPT-4)以及任务级别领域适应技术(A3Test)在测试用例生成中的对比效果。
4.5 Evaluation Metrics
第4.5节介绍了评估测试用例生成性能的七个评价标准:
- Parse和Compile Rate:评估生成测试用例的语法正确性和可编译性,使用Tree-sitter解析器来检查生成代码的语法错误,并将可解析的测试用例注入项目以检查它们是否可编译。
- 行覆盖率和变异分数:用于评估测试充分性,计算生成的测试用例对项目代码的行覆盖率。研究还计算了标准变异得分,评估测试用例发现缺陷的能力,使用Clover工具分析生成测试用例覆盖的代码行。
- BLEU和CodeBLEU:这两个指标衡量生成测试用例与真实用例的相似度,主要计算N-Gram共现。BLEU仅评估文本相似度,而CodeBLEU则考虑了代码的语法匹配和数据流的语义匹配,因此更适合代码生成任务。
研究中,行覆盖率和变异分数被认为是评估测试用例生成效果的更实际的标准,而BLEU和CodeBLEU则用于比较领域适应前后的效果。
4.6 Configurations and Environment Setup
模型配置:使用CodeT5-base模型,通过CONCODE下游任务进行微调。模型在Methods2Test数据集上进行微调,并使用Defects4j项目和EvoSuite生成的测试进行评估。所有超参数使用CONCODE的默认配置,批量大小设置为4,这是GPU内存能够支持的最大值。
微调设置:在领域适应阶段,模型的所有层都进行了20个epoch的微调。
硬件环境:实验运行在ComputeCanada的Beluga节点上,节点配置包括4个32GB V100 GPU、10个CPU核心和80GB内存。虽然实验默认使用此配置,但通过调整批次大小和训练时间,实验也可以在16GB GPU、1个CPU核心和10GB内存的环境下运行。
Results and Analysis
5.1 RQ1: Effectiveness of CodeT5 without DA
RQ1 研究了 CodeT5 在没有领域适应(DA)的情况下生成测试用例的有效性。主要内容包括:
- 实验设计:研究使用 Defects4j 数据集将项目数据划分为训练集和测试集,采用了 leave-one-out 评估方法,随机选取20%的测试用例进行评估,确保训练集和测试集中没有数据泄漏。测试生成的测试用例是否能成功编译,并计算它们的行覆盖率和变异得分。
- 结果:
- 发现大多数模型生成的测试用例无法编译,原因是生成的测试用例缺少依赖或生成了未定义对象,导致无法解析。
- 另外,由于 CodeT5 每个样本的输出长度限制(512个token),部分生成的测试用例被截断。
- 相比于其他基于静态指标(如BLEU)的研究,模型生成的测试用例在测试充分性指标(如行覆盖率和变异得分)上的表现不如预期,远低于其他工具(如AthenaTest)的结果。
总结:CodeT5 在没有领域适应时生成的测试用例编译率较低,测试充分性指标也不理想,表明仅靠微调模型生成测试用例效果有限。
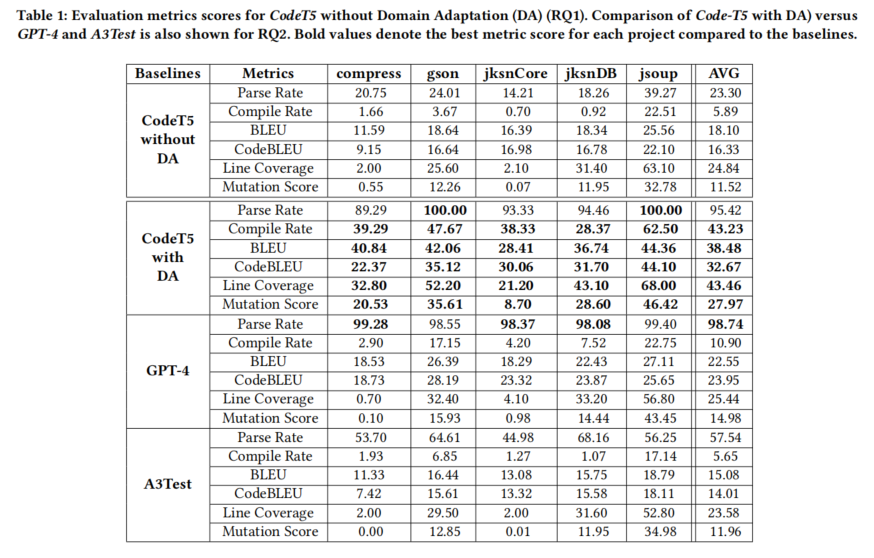
compress、gson怎么在论文没有解释呢?

5.2 RQ2: Effectiveness of CodeT5 with DA
RQ2 研究了 CodeT5 在应用了领域适应(DA)后的测试用例生成效果。主要内容包括:
- 实验设计:研究使用与RQ1相同的Defects4j数据集进行实验,通过项目级领域适应,使用Defects4j的训练集微调 CodeT5 模型,并在相同的评估集上计算行覆盖率和变异得分。实验还与两个基线模型(GPT-4 和 A3Test)进行对比。
- 结果:
- 领域适应显著提高了 CodeT5 的表现。行覆盖率范围为21.20%到68%,平均43.46%;变异得分范围为8.07%到46.42%,平均27.97%。相比没有领域适应的情况,行覆盖率中位数提高了16.65%,变异得分中位数提高了16.45%。
- 与基线模型相比, CodeT5 应用领域适应后在大部分指标上表现优于A3Test和CodeT5无DA,特别是在编译率、BLEU、CodeBLEU、行覆盖率和变异得分等方面。然而,GPT-4在解析率方面的表现最好,但由于没有项目特定的知识,其他指标上不及 CodeT5 。
- 结论:
- 领域适应能够显著提高 CodeT5 在生成项目特定测试用例上的效果,解析率提高了72.12%,编译率提高了37.34%,BLEU提高了20.38%,CodeBLEU提高了16.34%,行覆盖率提高了18.62%,变异得分提高了16.45%。
- CodeT5 的总体表现优于所有其他基线模型,除了GPT-4的解析率略胜一筹。
5.3 RQ3: Augmentation with SBST
RQ3 研究了将 CodeT5 与基于搜索的测试生成工具 EvoSuite 结合使用的效果。其目标不是替代 EvoSuite,而是作为补充,进一步提高测试覆盖率和变异得分。
实验设计:
- 使用与前面研究相同的训练-测试集,将 EvoSuite 默认设置(10分钟超时)生成的测试用例与模型生成的测试用例进行比较。通过计算行覆盖率和变异分数,评估 CodeT5 的增强效果。
- 实验特别关注 EvoSuite 未能覆盖的代码行(New CL列),以及模型生成的测试用例是否能够覆盖这些代码行。
结果:
- 表2展示了行覆盖率的比较:EvoSuite 的中位数和平均行覆盖率分别为23%和35.45%,而 CodeT5 模型的覆盖率更高,分别为58%和57.8%。在5个项目中,有3个项目模型生成的测试用例覆盖了更多代码行。
- 表3显示了变异得分的比较:模型生成的测试用例在部分项目中杀死了更多的变异体(如 jsoup 和 jacksonDatabind)。整体来看,模型的变异得分优于 EvoSuite。
结论:
- CodeT5 作为 EvoSuite 的补充可以提高行覆盖率和变异分数,特别是在 EvoSuite 无法覆盖的代码行上有明显的提升。建议将 CodeT5 作为现有工具的补充,以增强测试生成的整体效果。
总结:通过结合使用 CodeT5 和 EvoSuite,可以进一步提高测试生成任务中的覆盖率和有效性,证明了该方法能够有效增强现有的基于搜索的测试生成工具。